
高速音声検索の方法および装置
【課題】高速音声検索の方法および装置を提供する。
【解決手段】マルチプロセッサシステム内の大きい音声データベースを検索してターゲット音声クリップを特定する。大きい音声データベースは複数のより小さいグループに分割されて、これら複数の小グループがシステム内の複数の利用可能なプロセッサに対して動的にスケジューリングされる。プロセッサは、各グループを複数のより小さいセグメントに分割して、セグメントから音声特徴を抽出して、共通成分ガウス混合モデル(CCGMM)を用いてセグメントをモデル化することによって、スケジューリングされた複数のグループを並列に処理する。1つのプロセッサはさらに、ターゲット音声クリップから音声特徴を抽出してCCGMMを用いて抽出した音声特徴をモデル化する。ターゲット音声クリップと各セグメントとの間のKL距離に基づいて、セグメントがターゲット音声クリップに一致するか否か判断する。
【解決手段】マルチプロセッサシステム内の大きい音声データベースを検索してターゲット音声クリップを特定する。大きい音声データベースは複数のより小さいグループに分割されて、これら複数の小グループがシステム内の複数の利用可能なプロセッサに対して動的にスケジューリングされる。プロセッサは、各グループを複数のより小さいセグメントに分割して、セグメントから音声特徴を抽出して、共通成分ガウス混合モデル(CCGMM)を用いてセグメントをモデル化することによって、スケジューリングされた複数のグループを並列に処理する。1つのプロセッサはさらに、ターゲット音声クリップから音声特徴を抽出してCCGMMを用いて抽出した音声特徴をモデル化する。ターゲット音声クリップと各セグメントとの間のKL距離に基づいて、セグメントがターゲット音声クリップに一致するか否か判断する。
【発明の詳細な説明】
【技術分野】
【0001】
本開示内容は概して、信号処理およびマルチメディアアプリケーションに関する。より具体的には、これに限定されるわけではないが、高速音声検索および音声指紋の方法および装置に関する。
【背景技術】
【0002】
音声検索(例えば、音声クリップ用に大きな音声ストリームを検索することであって、当該音声ストリームが破損/歪曲していたとしても実行される)には数多くの用途があり、例えば、放送用音楽/コマーシャルの分析、インターネットでの著作権管理、または未分類の音声クリップ用のメタデータの特定等がある。典型的な音声検索システムは、シリアルで単一プロセッサシステム用に設計されている。このような検索システムでは通常、大きな音声ストリームにおいてターゲット音声クリップを検索するのに長時間かかってしまう。しかし、音声検索システムは大抵、大きい音声データベースに対して効率的に動作するよう求められており、例えば、非常に短時間で(例えば、略リアルタイムで)大きいデータベースを検索しなければならない。また、音声データベースは、その一部分またはすべてにおいて、歪曲、破損、および/または圧縮が発生している場合がある。このため、音声検索システムは、ターゲット音声クリップと同一の音声セグメントが歪曲、破損および/または圧縮されている場合であっても、その音声セグメントを特定するのに十分なロバスト性を有している必要がある。したがって、ターゲット音声クリップを大きい音声データベースから迅速且つロバストに検索できる音声検索システムが望まれている。
【図面の簡単な説明】
【0003】
開示する主題の特徴および利点は以下に記述する主題の詳細な説明から明らかとなる。
【0004】
【図1】音声検索モジュールに基づいてロバスト且つ並列な音声検索が実行され得るコンピューティングシステムの一例を示す図である。
【0005】
【図2】音声検索モジュールに基づいてロバスト且つ並列な音声検索が実行され得るコンピューティングシステムの別の例を示す図である。
【0006】
【図3】音声検索モジュールに基づいてロバスト且つ並列な音声検索が実行され得るコンピューティングシステムのさらに別の例を示す図である。
【0007】
【図4】ロバストな音声検索を実行する音声検索モジュールの一例を示すブロック図である。
【0008】
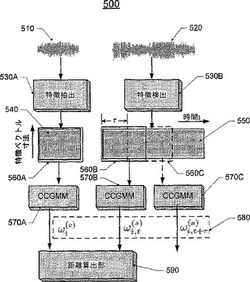
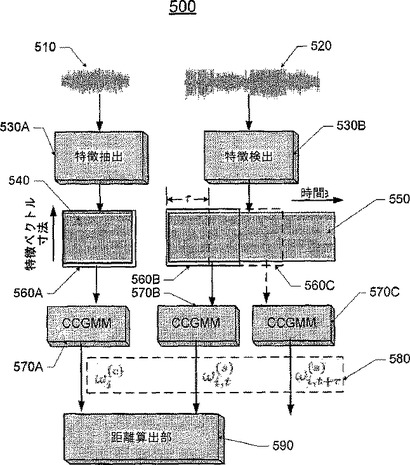
【図5】図4に示すロバストな音声検索モジュールの動作例を示す図である。
【0009】
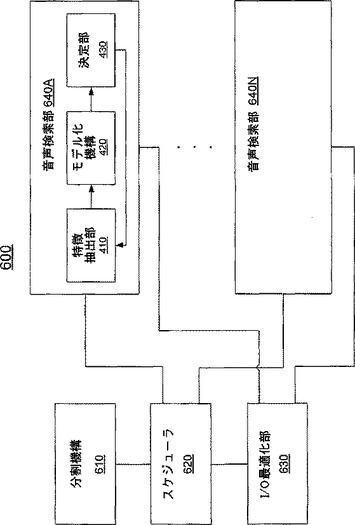
【図6】マルチプロセッサシステムにおいてロバスト且つ並列な音声検索を実行する音声検索モジュールの一例を示すブロック図である。
【0010】
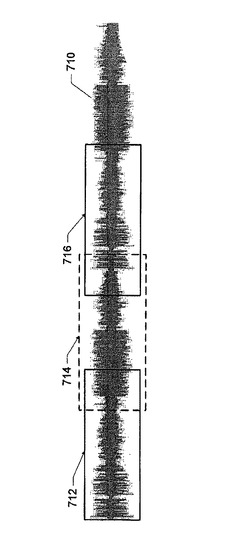
【図7A】マルチプロセッサシステムにおいてロバスト且つ並列な音声検索を実行するべく、大規模音声データベースを小グループに分割する方法を示す図である。
【図7B】マルチプロセッサシステムにおいてロバスト且つ並列な音声検索を実行するべく、大規模音声データベースを小グループに分割する方法を示す図である。
【図7C】マルチプロセッサシステムにおいてロバスト且つ並列な音声検索を実行するべく、大規模音声データベースを小グループに分割する方法を示す図である。
【0011】
【図8】マルチプロセッサシステムにおいてロバスト且つ並列な音声検索を実行するプロセスの一例を示す擬似コードを示す図である。
【発明を実施するための最良の形態】
【0012】
本願において開示される主題の実施形態によると、ロバスト且つ並列な検索方法を用いて、ターゲット音声クリップを求めて、マルチプロセッサシステム内の大きな音声ストリームまたは大きい音声データベースを検索し得る。大きい音声データベースを複数の小グループに分割するとしてもよい。これらの小グループを、マルチプロセッサシステム内で利用可能なプロセッサまたは処理コアによって修理されるべく、動的にスケジューリングするとしてもよい。プロセッサまたは処理コアは、スケジューリングされたグループを並列に処理するとしてもよい。このような並列処理は、各グループをより小さいセグメントに分割して、セグメントから音声特徴を抽出して、共通成分ガウス混合モデル(Common Component Gaussian Mixture Model:CCGMM)を用いてセグメントをモデル化することによってなされる。これらのセグメントの長さは、ターゲット音声クリップの長さと同一であるとしてもよい。どのグループを処理するよりも前に、1つのプロセッサまたは処理コアはターゲット音声クリップから音声特徴を抽出してCCGMMを用いてモデル化するとしてもよい。ターゲット音声クリップのモデルとグループの各セグメントとの間のカルバック・ライブラー(KL)距離またはKL最大距離をさらに算出するとしてもよい。当該距離が所定値以下であれば、対応するセグメントはターゲット音声クリップであると特定される。
【0013】
当該距離が所定値を超えている場合、プロセッサまたは処理コアは任意の数のセグメントを省略して、ターゲット音声クリップの検索を継続するとしてもよい。プロセッサまたは処理コアが1つのグループを検索し終わると、処理対象の新しいグループが与えられてターゲット音声クリップを検索し、すべてのグループについて検索を実行する。グループのサイズは、負荷インピーダンスおよび演算の重複を低減するように決定され得る。さらに、複数のプロセッサまたは処理コアが実行する音声グループの並列処理の効率を向上させるべく入出力(I/O)を最適化し得る。
【0014】
本明細書において「一実施形態」または「開示されている主題の実施形態」という表現は、当該実施形態に関連して説明される特定の特徴、構造または特性が、開示されている主題の少なくとも1つの実施形態に含まれていることを意味する。このように、「一実施形態」というフレーズが本明細書において何度も使用されるが、必ずしもすべてが同一の実施形態に言及しているわけではない。
【0015】
図1は、音声検索モジュール120に基づいてロバスト且つ並列な音声検索が実行され得るコンピューティングシステム100の一例を示す図である。コンピューティングシステム100は、システムインターコネクト115に結合される1以上のプロセッサ110を備える。プロセッサ110は、複数または多くの処理コアを有するとしてもよい(説明の便宜上、「複数のコア」という表現はこれ以降では複数の処理コアおよび多くの処理コアの両方を意味するものとする)。プロセッサ110は、複数のコアを用いてロバスト且つ並列な音声検索を実行する、音声検索モジュール120を有するとしてもよい。音声検索モジュールは、分割機構、スケジュール、および複数の音声検索部等、複数の構成要素を含むとしてもよい(より詳細な説明は図4から図6を参照しつつ後述する)。音声検索モジュールに含まれる1以上の構成要素が1つのコアに配置されて、他の構成要素は別のコアに配置されるとしてもよい。
【0016】
音声検索モジュールはまず、大きい音声データベースを複数の小グループに分割するとしてもよいし、または大きな音声ストリームを一部重複しているより小さいサブストリームに分割するとしてもよい。続いて、1つのコアが検索対象の音声クリップ(「ターゲット音声クリップ」)を処理して、ターゲット音声クリップのモデルを構築する。一方、音声検索モジュールは、複数のコアに対して音声小グループ/サブストリームを動的にスケジューリングする。複数のコアは、各グループ/サブストリームを複数のセグメントに分割して、各音声セグメントのモデルを構築する。これは並列に行われる。各セグメントのサイズは、ターゲット音声クリップのサイズと等しいとしてもよい。ターゲット音声クリップと音声データベース/ストリームの両方を含むすべての音声セグメントに共通な、複数のガウス成分を含むガウス混合モデル(Gaussian mixture model:GMM)を用いて、各音声セグメントとターゲット音声クリップとをモデル化するとしてもよい。音声セグメントのモデルが構築されると、当該セグメントのモデルとターゲット音声クリップのモデルとの間のカルバック−ライブラー(KL)距離またはKL最大距離を算出するとしてもよい。当該距離が所定値以下であれば、当該音声セグメントはターゲット音声クリップであると特定され得る。検索プロセスは、すべての音声グループ/サブストリームが処理されるまで継続されるとしてもよい。
【0017】
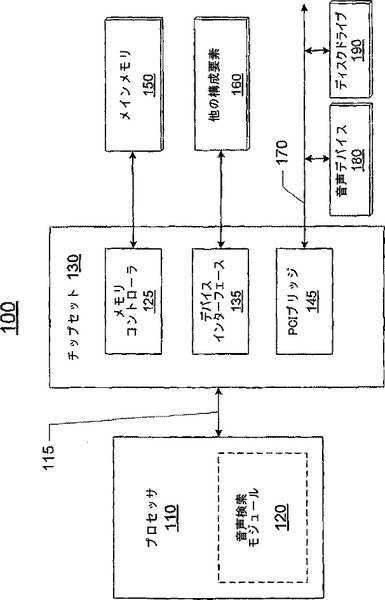
コンピューティングシステム100はさらに、システムインターコネクト115に結合されているチップセット130を備えるとしてもよい。チップセット130は、1以上の集積回路パッケージまたはチップを有するとしてもよい。チップセット130は、コンピューティングシステム100のその他の構成要素160との間のデータ転送をサポートするデバイスインターフェース135を1以上有するとしてもよい。その他の構成要素160は、例えば、BIOSファームウェア、キーボード、マウス、ストレージデバイス、ネットワークインターフェース等である。チップセット130は、周辺機器インターコネクト(PCI)バス170に結合されるとしてもよい。チップセット130はPCIバス170に対するインターフェースを提供するPCIブリッジ145を有するとしてもよい。PCIブリッジ145は、プロセッサ110およびその他の構成要素160と周辺機器との間にデータ経路を提供するとしてもよい。周辺機器は、例えば、音声デバイス180およびディスクドライブ190である。図1には図示されていないが、これら以外のデバイスもまたPCIバス170に結合され得る。
【0018】
また、チップセット130は、メインメモリ150に結合されているメモリコントローラ125を有するとしてもよい。メインメモリ150は、プロセッサ110の複数のコアまたは当該システム内のその他の任意のデバイスによって実行される命令列およびデータを格納するとしてもよい。メモリコントローラ125は、プロセッサ110の複数のコアおよびコンピューティングシステム100内のほかのデバイスに対応付けられるメモリトランザクションに応じてメインメモリ150にアクセスするとしてもよい。一実施形態によると、メモリコントローラ125はプロセッサ110またはその他の回路に配置されるとしてもよい。メインメモリ150は、メモリコントローラ125がデータの読み書きを行う、アドレス指定可能な格納位置を提供するさまざまなメモリデバイスを有するとしてもよい。メインメモリ150は、ダイナミックランダムアクセスメモリ(DRAM)デバイス、シンクロナスDRAM(SDRAM)デバイス、ダブル・データ・レート(DDR)SDRAMデバイスまたはその他のメモリデバイス等、1以上の異なる種類のメモリデバイスを有するとしてもよい。
【0019】
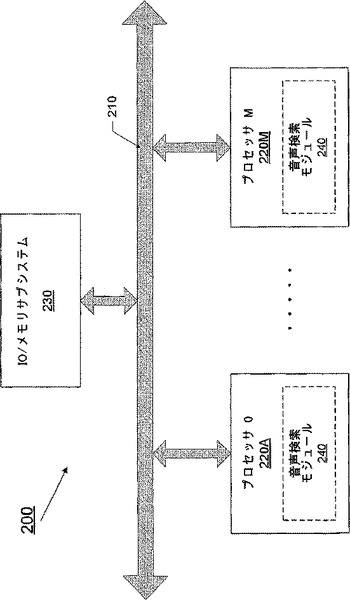
図2は、音声検索モジュール240を用いてロバスト且つ並列な音声検索が実行され得る別の例であるコンピューティングシステム200を示す図である。システム200は、プロセッサ0 220Aのような、複数のプロセッサを備えるとしてもよい。システム200内の1以上のプロセッサは、多くのコアを有するとしてもよい。システム200は、複数のコアによってロバスト且つ並列な音声検索を実行する音声検索モジュール240を備えるとしてもよい。音声検索モジュールは、分割機構、スケジュール、および複数の音声検索部等、複数の構成要素を含むとしてもよい(より詳細な説明は図4から図6を参照しつつ後述する)。音声検索モジュールに含まれる1以上の構成要素が1つのコアに配置されて、他の構成要素は別のコアに配置されるとしてもよい。システム200内のプロセッサは、システムインターコネクト210によって互いに接続されているとしてもよい。システムインターコネクト210は、フロントサイドバス(FSB)であってもよい。各プロセッサは、当該システムインターコネクトを介して、入出力(I/O)デバイスおよびメモリ230に接続されるとしてもよい。コアはすべて、メモリ230から音声データを受け取るとしてもよい。
【0020】
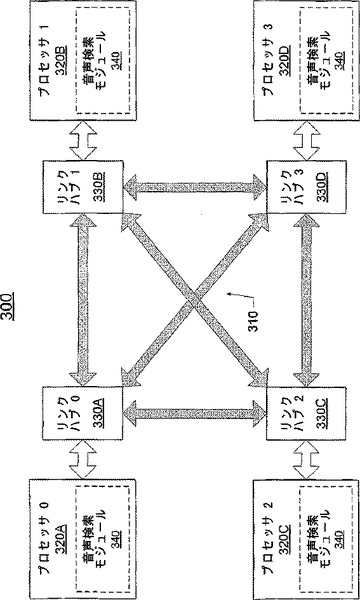
図3は、音声検索モジュール340を用いてロバスト且つ並列な音声検索を実行し得るさらに別の例であるコンピューティングシステム300を示す図である。システム300において、複数のプロセッサ(例えば、320A、320B、320Cおよび320D)を接続するシステムインターコネクト310は、リンクベースのポイント・ツー・ポイント接続である。各プロセッサは、リンクハブ(例えば、330A、330B、330Cおよび330D)を介してシステムインターコネクトに接続されているとしてもよい。一部の実施形態によると、リンクハブはメモリコントローラと同じ場所に配置されて、当該メモリコントローラがシステムメモリに対するトラフィックを調整するとしてもよい。1以上のプロセッサが多くのコアを含むとしてもよい。システム300は、複数のコアによってロバスト且つ並列な音声検索を実行する音声検索モジュール340を備えるとしてもよい。音声検索モジュールは、分割機構、スケジュール、および複数の音声検索部等、複数の構成要素を含むとしてもよい(より詳細な説明は図4から図6を参照しつつ後述する)。音声検索モジュールに含まれる1以上の構成要素が1つのコアに配置されて、他の構成要素は別のコアに配置されるとしてもよい。システム300内の各プロセッサ/コアは、システムインターコネクトを介して共有メモリ(図3には不図示)に接続されるとしてもよい。コアはすべて、共有メモリから音声データを受け取るとしてもよい。
【0021】
図2および図3において、音声検索モジュール(つまり、240および340)はまず、大きい音声データベースを複数の小グループに分割するとしてもよいし、または大きい音声ストリームを一部重複しているより小さいサブストリームに分割するとしてもよい。続いて、1つのコアが検索対象の音声クリップ(「ターゲット音声クリップ」)を処理して、ターゲット音声クリップのモデルを構築する。一方、音声検索モジュールは、複数のコアに対して音声小グループ/サブストリームを動的にスケジューリングする。複数のコアは、各グループ/サブストリームを複数のセグメントに分割して、各音声セグメントのモデルを構築する。これは並列に行われる。各セグメントのサイズは、ターゲット音声クリップのサイズと等しいとしてもよい。ターゲット音声クリップと音声データベース/ストリームの両方を含むすべての音声セグメントに共通な、複数のガウス成分のガウス混合モデル(Gaussian mixture model:GMM)を用いて、各音声セグメントとターゲット音声クリップとをモデル化するとしてもよい。音声セグメントのモデルが構築されると、当該セグメントのモデルとターゲット音声クリップのモデルとの間のカルバック−ライブラー(KL)距離またはKL最大距離を算出するとしてもよい。当該距離が所定値以下であれば、当該音声セグメントはターゲット音声クリップであると特定され得る。検索プロセスは、すべての音声グループ/サブストリームが処理されるまで継続されるとしてもよい。
【0022】
図4は、ロバストな音声検索を実行する音声検索モジュール400の一例を示すブロック図である。音声検索モジュール400は、特徴抽出部410と、モデル化機構420と、決定部430とを備える。特徴抽出部410は、入力音声ストリーム(例えば、ターゲット音声クリップ、大きい音声ストリームのサブストリーム等)を受け取って、入力音声ストリームから音声特徴を抽出するとしてもよい。入力音声ストリームが、ターゲット音声クリップを特定するべく検索されるべき音声ストリームである場合、特徴抽出部は当該音声ストリームに対してスライディングウィンドウ(sliding window)を適用して当該音声ストリームを複数の互いに重複するセグメントに分割するとしてもよい。ウィンドウはターゲット音声クリップと長さが同じである。入力音声ストリームの各セグメント(ターゲット音声ストリームが有するセグメントは1セグメントのみである)はさらに、複数のフレームに分割される。各フレームは、長さが同じで、隣接フレームと重複するとしてもよい。例えば、一実施形態によると、フレームの長さは20ミリ秒で、フレーム間の重複箇所は10ミリ秒であるとしてもよい。各フレームについて特徴ベクトルを抽出するとしてもよい。各フレームは、フーリエ係数、メル周波数ケプストラム係数、スペクトルフラットネス(spectral flattness)、およびこういったパラメータの平均、分散、その他の微分係数といった特徴を含み得る。音声セグメントの全フレームの特徴ベクトルにより、特徴ベクトルシーケンスが形成される。
【0023】
2つの隣接するセグメントが重複しているのは、2つの隣接するセグメント間でターゲット音声クリップを見逃す可能性を小さくするためである。重複箇所が長くなるほど、見逃す可能性が低くなる。一実施形態によると、どのような一致であろうと見逃さないように、重複箇所の長さは、フレームの長さをセグメントの長さから引いたものに等しくなるように設定してもよい。しかし、重複箇所が長くなると演算が増えてしまう。このため、演算負荷と見逃す可能性との間でバランスを取る必要がある(例えば、重複箇所の長さは、セグメントの長さの2分の1以下である)。いずれにしろ、2つのセグメント間で重複しているフレームの特徴ベクトルの場合、抽出は1回のみでよい。
【0024】
モデル化機構420は、特徴抽出部410が抽出した特徴ベクトルシーケンスに基づいて、音声セグメントのモデルを構築するとしてもよい。使用されるモデルに応じて、モデル化機構は該モデルのパラメータを推定する。一実施形態によると、共通成分ガウス混合モデル(「CCGMM」)に基づいて音声セグメントをモデル化するとしてもよい。CCGMMはすべてのセグメントにわたって共通している複数のガウス成分を含む。各セグメントについて、モデル化機構は、共通のガウス成分に対して一連の混合重み付け値を推定する。別の実施形態によると、他のモデル(例えば、隠れマルコフモデル)に基づいて音声セグメントをモデル化するとしてもよい。一実施形態によると、ターゲット音声クリップのみがモデル化されて、音声セグメントの特徴ベクトルシーケンスはそのまま、音声セグメントがターゲット音声クリップと略同一か否か決定するべく利用されるとしてもよい。
【0025】
決定部430は、入力音声ストリームに含まれる音声セグメントが十分に類似しており音声セグメントがターゲット音声クリップの複写と特定できるか否か判断するとしてもよい。このため、決定部は、音声セグメントのモデルとターゲット音声クリップのモデルとを比較することによって類似性測度を導き出すとしてもよい。一実施形態によると、類似性測度はこれら2つのモデル間で算出される距離であってもよい。別の実施形態によると、類似性測度は、音声セグメントのモデルとターゲット音声クリップのモデルとが同一である確率であってもよい。さらに別の実施形態によると、類似性測度は、音声セグメントの特徴ベクトルシーケンスとターゲット音声クリップのモデルとを比較することによって得られるとしてもよい。例えば、隠れマルコフモデル(HMM)に基づいてターゲット音声クリップをモデル化する場合、音声セグメントの特徴ベクトルシーケンスとターゲット音声クリップのHMMとに基づき、音声セグメントとターゲット音声クリップとの間の可能性スコアを算出するべくビタビベースのアルゴリズムを用いるとしてもよい。
【0026】
類似性測度の値に基づいて、決定部は、音声セグメントをターゲット音声クリップと特定できるか否か判断するとしてもよい。例えば、類似性測度の値が所定のしきい値以下であれば(例えば、類似性測度は音声セグメントモデルとターゲット音声クリップとの間の距離である)、音声セグメントはターゲット音声クリップと略同一であると特定され得る。同様に、類似性測度の値が所定しきい値以上であれば(例えば、類似性測度は音声セグメントがターゲット音声クリップと略同一である可能性スコアである)、音声セグメントはターゲット音声クリップと略同一であると特定され得る。一方、類似性測度によって音声セグメントがターゲット音声クリップとは大きく異なることが分かった場合には、当該音声セグメントの直後の任意の数のセグメントを省略するとしてもよい。実際に省略するセグメントの数は、類似性測度の値および/または実験に基づくデータに応じて決まる。類似性測度によって現在のセグメントがターゲット音声クリップと非常に異なることが分かる場合には、任意の数の後続セグメントを省略することによって、ターゲット音声クリップを見逃すことはあり得ない。これは、入力音声ストリームをセグメントに分割するべく利用されるウィンドウが徐々に前方向にスライドする結果、あるセグメントから次のセグメントへと移る際に類似性測度に連続性が認められるためである。
【0027】
図5は、図4に図示されるロバストな音声検索モジュールの動作例を示す図である。ターゲット音声クリップ510は、特徴抽出部に与えられて、複数のフレームに分割される。特徴抽出部はそして、ブロック530Aにおいて、フレーム毎の特徴ベクトルによって、特徴ベクトルシーケンス(540)を生成する。特徴ベクトルは、1以上のパラメータを含み得るので、x次元のベクトルであってもよい(ここで、x≧1)。ブロック570Aにおいて、特徴ベクトルシーケンス540は、以下のようなGMMを用いてモデル化されるとしてもよい。
【数1】

GMM
【数2】
は、M個のガウス成分を含み、
【数3】
は成分重みで、
【数4】
は平均で、
【数5】
は共分散であり、i=1、2・・・、Mであって、kはセグメントkを表し、N()はガウス分布を表す。ターゲット音声クリップについては、セグメントは1つのみであるので、セグメントを特定するためのkは利用する必要はない。しかし、入力音声ストリーム520については、セグメントは通常複数あるので、異なるセグメントについてGMMを特定するのが望ましい。
【0028】
図5に示す例では、カルバック−ライブラー(KL)距離またはKL最大距離を類似性測度として使用する。KL最大距離の算出を簡略化するべく、音声セグメントすべてに用いられるGMMではガウス成分共通群が共通している、つまり、i番目のガウス成分について、平均
【数6】
および分散
【数7】
は音声セグメントが変わっても同じである、と仮定される。このため、式(1)は以下のように変形される。
【数8】
各音声セグメントについて、1セットの重み付け
【数9】
のみを、共通ガウス成分について推定する必要がある。T個の特徴ベクトル、
【数10】
を持つセグメントkの特徴ベクトルシーケンスの場合、重みは以下のように推定され得る。
【数11】
ここで、
【数12】
はi番目またはj番目のセグメントについての普遍的な重みであって、いくつかのサンプル音声ファイルに基づいて実験により得られるとしてもよいし、乱数値によって初期化されるとしてもよい。
【0029】
ターゲット音声クリップ510を特定するべく検索される入力音声ストリーム520は、特徴抽出部に与えられるとしてもよい。ブロック530Bにおいて、特徴抽出部は入力音声ストリームを、互いに部分的に重複する複数のセグメントに分割する。特徴抽出部はさらに、各セグメントを、互いに部分的に重複する複数のフレームに分割して、フレーム毎に特徴ベクトルを抽出する。ブロック560は、入力音声ストリーム520の特徴ベクトルシーケンスを示すと共に、当該音声ストリームが互いに部分的に重複する複数のセグメントに分割されている様子を示す。例えば、ターゲット音声クリップの長さと同じサイズのウィンドウを入力音声ストリーム520に適用するとしてもよい。説明のために、セグメント560Aを得るべくターゲット音声クリップの特徴ベクトルシーケンスに対してウィンドウが図示されているが、この場合セグメントは1つしかないので、ターゲット音声クリップにウィンドウを適用する必要は通常ない。シフトするウィンドウを入力音声ストリームに適用すると、560Bおよび560Cのような部分的に重複する複数のセグメントが得られる。ウィンドウのシフト量は、セグメント560Bからセグメント560Cまでの間で時間τであり、ここでτはウィンドウサイズよりも小さい。
【0030】
各音声セグメントはCCGMMを用いてモデル化される。例えば、セグメント560Bはブロック570Bでモデル化され、セグメント560Cはブロック570Cでモデル化される。入力音声ストリーム520の各セグメントのモデルとターゲット音声クリップ510のモデルは、重みの組み合わせは異なるが共通のガウス成分を有する。一実施形態によると、特徴ベクトルは入力音声ストリーム全体からフレーム毎に抽出されて、入力音声ストリーム全体に対応する長い特徴ベクトルシーケンスが生成されるとしてもよい。続いて、N×FL(ここで、Nは正の整数でありFLはフレームの長さ)の長さを持つウィンドウが、当該長い特徴ベクトルシーケンスに適用される。ウィンドウ内の複数の特徴ベクトルは、一の音声セグメントの一の特徴ベクトルを構成し、この特徴ベクトルはCCGMMを構築するために利用される。ウィンドウは、時間τだけ前方向にシフトされる。
【0031】
セグメントがターゲット音声クリップと略同一か否か決定するべく、当該セグメントのモデルとターゲット音声クリップのモデルとの間のKL最大距離を以下のようにして算出するとしてもよい。
【数13】
このようにして算出されたKL最大距離が所定のしきい値未満の場合、音声クリップが検出されたとみなされるとしてもよい。入力音声ストリーム520に対して適用されるウィンドウが時間方向で前方向にシフトされていくと、距離は通常、1つのタイムステップから次のタイムステップまでの間で一定の継続性を示す。つまり、距離が大きすぎると、現在のセグメントの直後に続く1以上のセグメントがターゲット音声クリップに一致する可能性は低い。このため、距離の値によっては、同一音声ストリーム/サブストリーム内の直後の所定数のセグメントについては検索を省略するとしてもよい。
【0032】
図6は、マルチプロセッサシステムにおいてロバスト且つ並列な音声検索を実行する音声検索モジュール600の一例を示すブロック図である。音声検索モジュール600は、分割機構610と、スケジューラ620と、I/O最適化部630と、複数の音声検索部(例えば640A、・・・、640N)とを備える。分割機構610は、大きい音声ストリームを複数のより小さいサブストリームに分割、および/または、大きい音声データベースを複数の小グループに分割するとしてもよい。図7A、図7Bおよび図7Cは、マルチプロセッサシステムにおいてロバスト且つ並列な音声検索を実行するべく大きい音声データベースを小グループに分割する方法を示す図である。図7Aは、単一の大きな音声ストリーム710を含むデータベースの一例を示す図である。分割機構は、音声ストリーム710を複数のより小さいサブストリーム712、714および716に分割するとしてもよい。ここで、各サブストリームは1グループを構成している。各サブストリームの長さは互いに異なるとしてもよいが、処理を単純化するべく通常は均一な長さとする。ターゲット音声クリップの正確な検出を見落とすことのないように、各サブストリームは直後のサブストリームと重複しており、2つの隣接するサブストリーム(例えば、712および714、714および716)間での重複部分は、
【数14】
以上でなければならない。ここで、
【数15】
はターゲット音声クリップ内のフレーム総数である。
【0033】
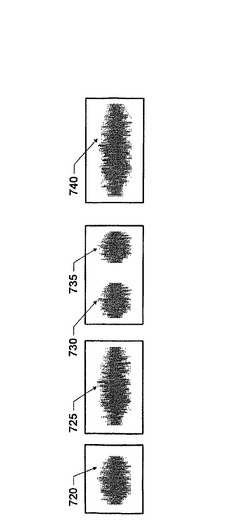
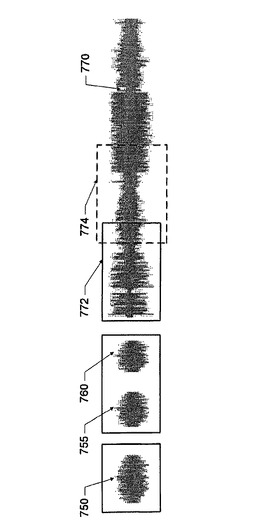
図7Bは、複数の比較的小さい音声ストリーム(例えば、720、725、730、735、および740)を含む別の例のデータベースを示す図である。一実施形態によると、分割機構610は当該データベースを、各グループが1つの音声ストリームのみを含むように、複数の小グループに分割するとしてもよい。別の実施形態によると、図7Bに示すように、分割機構はデータベースを、一部のグループはそれぞれが音声ストリームを1つのみ含み、他のグループはそれぞれが複数の小さい音声ストリームを含むように、複数の小グループに分割してもよい。図7Cは、複数の比較的小さい音声ストリーム(例えば、750、755および760)と大きな音声ストリーム(例えば770)とを含むさらに別の例のデータベースを示す図である。分割機構は、比較的小さい音声ストリームを、各グループが音声ストリーム1つのみを含むように複数のグループに分割するとしてもよいし、または、一部のグループは音声ストリームを1つのみ含み(例えば、750)他のグループは複数の小さい音声ストリームを含む(例えば、755および760を同じグループに入れるとしてもよい)ように複数のグループに分割するとしてもよい。770のような大きい音声ストリームについては、分割機構は、互いに部分的に重複する複数のより小さいサブストリーム(例えば、772および774)に分割するとしてもよい。ここで、図7Aに示した方法に従って、各サブストリームは1グループを構成するとしてもよい。
【0034】
また、分割機構は、演算の重複(大きな音声ストリームが互いに部分的に重複する複数のより小さいサブストリームに分割される場合)および複数のプロセッサによる並列処理における負荷の不均衡を低減するように、大きな音声データベースを複数の適切なサイズの複数のグループに分割する。グループのサイズが小さくなると、演算の重複部分が大きくなり得る一方、グループのサイズが大きくなると、負荷の不均衡が著しくなってしまうことがある。一実施形態によると、グループのサイズはターゲット音声クリップのサイズの約25倍であるとしてもよい。
【0035】
図6に戻って、スケジューラ620は、マルチプロセッサシステム内の複数のプロセッサに対して大きなデータベースの複数のグループを動的にスケジューリングして、各プロセッサが一度に1つの処理対象のグループを持つようにするとしてもよい。スケジューラは、当該システムの複数のプロセッサが利用可能か否かを定期的に確認して、利用可能なプロセッサそれぞれに対して音声グループを割り当てて、処理およびターゲット音声クリップの検索を実行させる。その後別のプロセッサが利用可能な状態になると、スケジューラはこのプロセッサに1つのグループを割り当てるとしてもよい。スケジューラはまた、プロセッサがその前に割り当てられたグループについて検索を終了した直後に、ほかのプロセッサが検索処理を終了したかどうかに関わらず、当該プロセッサに対してまだ検索がすんでいない音声グループを割り当てる。実際のところ、グループのサイズが同一であったとしても、検索処理を省略するセグメントの数はセグメント毎に異なる可能性があるので、同じターゲット音声クリップを検索するのに必要な時間はプロセッサごとに異なる場合がある。上述したような動的スケジューリングを利用することで、負荷の不均衡を効果的に低減し得る。
【0036】
I/O最適化部630は、システムインターコネクト(例えば、システムのプロセッサと共有システムメモリとを接続するシステムバス)上でのI/Oトラフィックを最適化するとしてもよい。I/O最適化部は、各プロセッサのデータ範囲が定義されている間、最初は、検索対象の音声データベース全体をディスクからメモリへロードしないと判断するとしてもよい。また、I/O最適化部は、メモリから受け取る割り当てられたセグメントを各プロセッサが読む際には、一度に一部分のみを読ませるとしてもよい。I/Oトラフィックを最適化することによって、I/O最適化部は、I/Oコンテンションを低減し、I/O処理および演算を重複させ、演算効率の向上に貢献するとしてもよい。この結果、音声検索のスケーラビリティを大きく改善することができる。
【0037】
音声検索モジュール600はさらに、複数の音声検索部640Aから640Nを備える。各音声検索部(例えば640A)は、一のプロセッサに配置されて、当該プロセッサに割り当てられるグループを処理してターゲット音声クリップを検索する。図4に図示されている音声検索モジュール400と同様に、音声検索部は、特徴抽出部(例えば410)と、モデル化機構(例えば420)と、決定部(例えば430)とを有する。各音声検索部は、自身に割り当てられた、ターゲット音声クリップを特定するための音声グループの連続能動型検索を実行する。これは、音声グループの音声ストリームを、互いに部分的に重複する複数のセグメントに分割し、各セグメントについて特徴ベクトルシーケンスを抽出して、式(1)から(4)で示したようにCCGMMに基づいて各セグメントをモデル化することによって行われる。ここで、セグメントの長さはターゲット音声クリップの長さと同じである。また、すべての音声検索部が利用する、ターゲット音声クリップ用のCCGMMは、音声検索部のうちの1つが一度推定すればそれでよい。各音声検索部は、各セグメントのモデルとターゲット音声クリップのモデルとの間のKL最大距離を算出する。このKL最大距離に基づいて、音声検索部はターゲット音声クリップが検出されるか否か判断するとしてもよい。さらに、各音声検索部は、現在のセグメントのKL最大距離がしきい値よりも大きい場合には、現在のセグメントに続く複数のセグメントを省略するとしてもよい。
【0038】
図8は、マルチプロセッサシステムにおいてロバスト且つ並列な音声検索を実行するためのプロセス800の一例を示す擬似コードを示す図である。ライン802において、音声検索モジュールは初期化されるとしてもよい。例えば、ターゲット音声クリップファイルおよび音声データベースファイルを開けて、グローバルパラメータを初期化するとしてもよい。ライン804において、大きな音声データベースを、図7A、図7Bおよび図7Cに図示しているように、NG個の小グループに分割するとしてもよい。ライン806において、モデル(例えば、CCGMM)をターゲット音声クリップについて構築するとしてもよい。ライン808において、NG個の音声グループを利用可能なプロセッサに対して動的にスケジューリングして、スケジューリングされたグループの並列処理を開始するとしてもよい。ライン808は、並列実装をセットアップする1つの命令を利用し、その他の並列実装命令もまた用いられ得る。
【0039】
ライン810からライン846は、マルチプロセッサシステムのプロセッサが並列に、NG個のグループのそれぞれをどのように処理し、且つどのように検索してターゲットを特定するかを示している。説明の便宜上、ライン812からライン846の処理は、第1番目のグループから最後のグループまでの、繰り返しとして図示されていることに留意されたい。実際には、複数のプロセッサが利用可能な場合、これらの利用可能なプロセッサによって複数のグループが並列に処理される。ライン814において、各グループの複数の音声ストリームのうち一部またはすべてを、これらのストリームがターゲット音声クリップよりも時間的に長い場合には、互いに部分的に重複するNS個のセグメントにさらに分割するとしてもよい。ライン816は、グループの各セグメントについて、ライン818から832に示すような、繰り返しプロセスを開始させる。ライン820において、特徴ベクトルシーケンス(フレーム毎に)をセグメントから抽出するとしてもよい。ライン822において、モデル(例えば、式(1)から式(3)に示すようなCCGMM)をセグメントについて構築するとしてもよい。ライン824において、セグメントのモデルとターゲット音声クリップのモデルとの間の距離(例えば、式(4)に示すようなKL最大距離)を算出するとしてもよい。ライン826において、セグメントがターゲット音声クリップと一致するか否かを、ライン824において算出された距離と所定のしきい値#1とに基づいて、判断するとしてもよい。距離がしきい値#1未満であれば、セグメントはターゲット音声クリップに一致する。ライン828において、同じ音声ストリーム/サブストリーム内の所定数の後続セグメント(例えば、M個のセグメント)の検索を省略するか否かを、ライン824において算出された距離と所定のしきい値#2とに基づいて、判断するとしてもよい。距離がしきい値#2よりも大きい場合には、M個のセグメントの検索を省略するとしてもよい。一実施形態によると、省略するセグメントの数は距離の値に応じて変わるとしてもよい。ライン830において、検索結果(例えば、各グループにおける一致セグメントのインデックスまたは開始時間)を、当該グループを処理するプロセッサに対してローカルなアレイに格納するとしてもよい。ライン842において、すべてのプロセッサから得られる、ローカルアレイに格納した検索結果を要約してユーザに出力するとしてもよい。
【0040】
図8に概略を示したロバスト且つ並列な検索ストラテジを、I/O最適化等のほかの技術と共に用いることによって、マルチプロセッサシステムにおいて大きな音声データベース内でターゲット音声クリップを検索するスピードを大きく改善し得る。1つの実験によると、27時間の音声ストリームにおいて15秒のターゲット音声クリップを検索するスピードは、16ウェイ(16−way)のユニシスシステムにおいて、同じターゲット音声クリップにおいて同じ音声ストリームを連続して検索する場合に比べると、11倍に早くなることが分かっている。
【0041】
一実施形態によると、変形された検索ストラテジが用いられ得る。このストラテジを用いると、ターゲット音声クリップの最初のK個(K≧1)のフレームに対して仮モデル(例えば、CCGMM)を構築して、ターゲット音声クリップ全体に対して完全モデルを構築するとしてもよい。このためまず、音声セグメントの最初のK個(K≧1)のフレームに対して仮モデル(例えば、CCGMM)が構築され得る。能動型検索において、各音声セグメントの最初のK個のフレームの仮モデルとターゲット音声クリップの最初のK個のフレームの仮モデルとがまず比較されて、仮類似性測度を生成する。仮類似性測度によってこれらの2つの仮モデルが非常に類似していることが分かれば、音声セグメント全体に対して完全モデルが構築されて、ターゲット音声クリップ全体の完全モデルに対して比較される。そうでない場合は、音声セグメントに対して完全モデルは構築されず、最初のK個のフレームに対して仮モデルをまず構築してこの仮モデルとターゲット音声クリップの仮モデルを比較することによって、次のセグメントを検索するとしてもよい。このような変形検索ストラテジは、さらに演算負荷を低減し得る。
【0042】
開示されている主題の実施形態例を図1から図8に示すブロック図およびフローチャートを参照しつつ説明したが、当業者であれば、開示されている主題はほかの多くの方法によっても実施され得ることが容易に理解できる。例えば、フローチャートにおけるブロックの実行順序は変更するとしてもよいし、および/または、説明したブロック図/フローチャートのブロックはその一部を変更、削除または合成するとしてもよい。
【0043】
前述の説明では、開示されている主題をさまざまな側面から説明した。説明に当たっては、主題を十分に説明することを目的として、具体的な数値、システムおよび構成を記載した。しかし、本開示内容を参考にすることによって、このような具体的且つ詳細な内容がなくても主題を実施し得ることは、当業者には明らかである。また、公知の特徴、構成要素またはモジュールは、開示されている主題をあいまいにすることを避けるべく、省略、簡略化、合成または分割した。
【0044】
開示されている主題のさまざまな実施形態は、ハードウェア、ファームウェア、ソフトウェアまたはそれらの組み合わせにおいて実装され得る。また、開示されている主題のさまざまな実施形態は、プログラムコードを参照することによって、またはプログラムコードと関連付けることによって記述され得る。プログラムコードは、例えば、設計のシミュレーション、エミュレーションおよび製造用の命令、機能、手順、データ構造、ロジック、アプリケーションプログラム、設計表現またはフォーマットであり、機械によってアクセスされると、機械はタスクを実行し、抽象データ型または低水準ハードウェアコンテキストを定義して、結果を生成する。
【0045】
シミュレーション用の場合、プログラムコードは、設計されたハードウェアがどのように動作するかを示すモデルを本質的に提供する、ハードウェア記述言語または別の機能記述言語を用いてハードウェアを表現するとしてもよい。プログラムコードは、アセンブリまたは機械言語、もしくはコンパイルおよび/または解釈され得るデータであってもよい。また、ソフトウェアとは、ある形態または別の形態によって、動作を実行するかまたは、結果を生じさせるものと認識することは当該技術分野では普通である。このような表現は、プロセッサに動作を実行させるか、または結果を生成させる処理システムによるプログラムコードの実行を簡単に説明するためのものに過ぎない。
【0046】
プログラムコードは、例えば、揮発性および/または不揮発性メモリに格納されるとしてもよい。揮発性および/または不揮発性メモリは、ストレージデバイスおよび/または関連付けられる機械可読または機械アクセス可能媒体であってよい。機械可読または機械アクセス可能媒体は、固体メモリ、ハードドライブ、フロッピーディスク、光学ストレージ、テープ、フラッシュメモリ、メモリスティック、デジタルビデオディスク、デジタル多用途ディスク(DVD)等であってよいし、機械アクセス可能な生物学的状態保存ストレージ等のより珍しい媒体であってもよい。機械可読媒体は、機械が読み出し可能な形式で情報を格納、送信または受信するどのような機構を有するとしてもよく、当該媒体は、プログラムコードを符号化している伝播信号または搬送波の電気的形態、光学的形態、音響的形態またはその他の形態を通過させる有形の媒体、例えば、アンテナ、光ファイバ、通信インターフェース等を有するとしてもよい。プログラムコードは、パケット、シリアルデータ、パラレルデータ、伝播信号等の形態で送信されるとしてもよく、圧縮または暗号化された形式で利用されるとしてもよい。
【0047】
プログラムコードは、プロセッサと、当該プロセッサによって読み出し可能な揮発性および/または不揮発性メモリと、少なくとも1つの入力デバイスおよび/または1以上の出力デバイスとを備える、移動可能または固定コンピュータ、携帯情報端末(PDA)、セットトップボックス、携帯電話およびポケットベル(登録商標)、ならびにその他の電子デバイスといった、プログラム可能な機械で実行されるプログラムにおいて実装されるとしてもよい。プログラムコードは、入力デバイスを用いて入力されたデータに対して適用されて、上述した実施形態を実行して出力情報を生成するとしてもよい。出力情報は、1以上の出力デバイスに適用されるとしてもよい。当業者であれば、開示されている主題の実施形態はさまざまなコンピュータシステム構成によって実施され得ることに想到し得る。そのようなコンピュータシステム構成は、マルチプロセッサまたはマルチコアプロセッサシステム、ミニコンピュータ、メインフレームコンピュータ、実質的にいかなるデバイスにも埋め込み得るパーベイシブ(pervasive)またはミニチュア型のコンピュータまたはプロセッサを含む。開示されている主題の実施形態はまた、タスクを実行するのは通信ネットワークを介してリンクされているリモート処理デバイスである分散コンピューティング環境において実施され得る。
【0048】
処理は順次実行されるものとして説明されているが、一部の処理については、実際には、並列に、同時に、および/または分散環境下において実行されるとしてもよく、プログラムコードは、シングルプロセッサ型またはマルチプロセッサ型の機械によってアクセスされるべく、ローカルおよび/またはリモートに格納されている。また、一部の実施形態によると、処理の順序は、開示されている主題の精神から逸脱することなく並び替え得る。プログラムコードは、埋め込まれているコントローラによって用いられるとしてもよいし、埋め込まれたコントローラと関連して利用されるとしてもよい。
【0049】
開示されている主題を実施形態例を参照しつつ説明してきたが、この説明は本発明を限定するものと解釈されるべきではない。実施形態例のさまざまな変形例および主題のその他の実施形態は、当業者には明らかであり、開示されている主題の範囲内に含まれるものとする。
【技術分野】
【0001】
本開示内容は概して、信号処理およびマルチメディアアプリケーションに関する。より具体的には、これに限定されるわけではないが、高速音声検索および音声指紋の方法および装置に関する。
【背景技術】
【0002】
音声検索(例えば、音声クリップ用に大きな音声ストリームを検索することであって、当該音声ストリームが破損/歪曲していたとしても実行される)には数多くの用途があり、例えば、放送用音楽/コマーシャルの分析、インターネットでの著作権管理、または未分類の音声クリップ用のメタデータの特定等がある。典型的な音声検索システムは、シリアルで単一プロセッサシステム用に設計されている。このような検索システムでは通常、大きな音声ストリームにおいてターゲット音声クリップを検索するのに長時間かかってしまう。しかし、音声検索システムは大抵、大きい音声データベースに対して効率的に動作するよう求められており、例えば、非常に短時間で(例えば、略リアルタイムで)大きいデータベースを検索しなければならない。また、音声データベースは、その一部分またはすべてにおいて、歪曲、破損、および/または圧縮が発生している場合がある。このため、音声検索システムは、ターゲット音声クリップと同一の音声セグメントが歪曲、破損および/または圧縮されている場合であっても、その音声セグメントを特定するのに十分なロバスト性を有している必要がある。したがって、ターゲット音声クリップを大きい音声データベースから迅速且つロバストに検索できる音声検索システムが望まれている。
【図面の簡単な説明】
【0003】
開示する主題の特徴および利点は以下に記述する主題の詳細な説明から明らかとなる。
【0004】
【図1】音声検索モジュールに基づいてロバスト且つ並列な音声検索が実行され得るコンピューティングシステムの一例を示す図である。
【0005】
【図2】音声検索モジュールに基づいてロバスト且つ並列な音声検索が実行され得るコンピューティングシステムの別の例を示す図である。
【0006】
【図3】音声検索モジュールに基づいてロバスト且つ並列な音声検索が実行され得るコンピューティングシステムのさらに別の例を示す図である。
【0007】
【図4】ロバストな音声検索を実行する音声検索モジュールの一例を示すブロック図である。
【0008】
【図5】図4に示すロバストな音声検索モジュールの動作例を示す図である。
【0009】
【図6】マルチプロセッサシステムにおいてロバスト且つ並列な音声検索を実行する音声検索モジュールの一例を示すブロック図である。
【0010】
【図7A】マルチプロセッサシステムにおいてロバスト且つ並列な音声検索を実行するべく、大規模音声データベースを小グループに分割する方法を示す図である。
【図7B】マルチプロセッサシステムにおいてロバスト且つ並列な音声検索を実行するべく、大規模音声データベースを小グループに分割する方法を示す図である。
【図7C】マルチプロセッサシステムにおいてロバスト且つ並列な音声検索を実行するべく、大規模音声データベースを小グループに分割する方法を示す図である。
【0011】
【図8】マルチプロセッサシステムにおいてロバスト且つ並列な音声検索を実行するプロセスの一例を示す擬似コードを示す図である。
【発明を実施するための最良の形態】
【0012】
本願において開示される主題の実施形態によると、ロバスト且つ並列な検索方法を用いて、ターゲット音声クリップを求めて、マルチプロセッサシステム内の大きな音声ストリームまたは大きい音声データベースを検索し得る。大きい音声データベースを複数の小グループに分割するとしてもよい。これらの小グループを、マルチプロセッサシステム内で利用可能なプロセッサまたは処理コアによって修理されるべく、動的にスケジューリングするとしてもよい。プロセッサまたは処理コアは、スケジューリングされたグループを並列に処理するとしてもよい。このような並列処理は、各グループをより小さいセグメントに分割して、セグメントから音声特徴を抽出して、共通成分ガウス混合モデル(Common Component Gaussian Mixture Model:CCGMM)を用いてセグメントをモデル化することによってなされる。これらのセグメントの長さは、ターゲット音声クリップの長さと同一であるとしてもよい。どのグループを処理するよりも前に、1つのプロセッサまたは処理コアはターゲット音声クリップから音声特徴を抽出してCCGMMを用いてモデル化するとしてもよい。ターゲット音声クリップのモデルとグループの各セグメントとの間のカルバック・ライブラー(KL)距離またはKL最大距離をさらに算出するとしてもよい。当該距離が所定値以下であれば、対応するセグメントはターゲット音声クリップであると特定される。
【0013】
当該距離が所定値を超えている場合、プロセッサまたは処理コアは任意の数のセグメントを省略して、ターゲット音声クリップの検索を継続するとしてもよい。プロセッサまたは処理コアが1つのグループを検索し終わると、処理対象の新しいグループが与えられてターゲット音声クリップを検索し、すべてのグループについて検索を実行する。グループのサイズは、負荷インピーダンスおよび演算の重複を低減するように決定され得る。さらに、複数のプロセッサまたは処理コアが実行する音声グループの並列処理の効率を向上させるべく入出力(I/O)を最適化し得る。
【0014】
本明細書において「一実施形態」または「開示されている主題の実施形態」という表現は、当該実施形態に関連して説明される特定の特徴、構造または特性が、開示されている主題の少なくとも1つの実施形態に含まれていることを意味する。このように、「一実施形態」というフレーズが本明細書において何度も使用されるが、必ずしもすべてが同一の実施形態に言及しているわけではない。
【0015】
図1は、音声検索モジュール120に基づいてロバスト且つ並列な音声検索が実行され得るコンピューティングシステム100の一例を示す図である。コンピューティングシステム100は、システムインターコネクト115に結合される1以上のプロセッサ110を備える。プロセッサ110は、複数または多くの処理コアを有するとしてもよい(説明の便宜上、「複数のコア」という表現はこれ以降では複数の処理コアおよび多くの処理コアの両方を意味するものとする)。プロセッサ110は、複数のコアを用いてロバスト且つ並列な音声検索を実行する、音声検索モジュール120を有するとしてもよい。音声検索モジュールは、分割機構、スケジュール、および複数の音声検索部等、複数の構成要素を含むとしてもよい(より詳細な説明は図4から図6を参照しつつ後述する)。音声検索モジュールに含まれる1以上の構成要素が1つのコアに配置されて、他の構成要素は別のコアに配置されるとしてもよい。
【0016】
音声検索モジュールはまず、大きい音声データベースを複数の小グループに分割するとしてもよいし、または大きな音声ストリームを一部重複しているより小さいサブストリームに分割するとしてもよい。続いて、1つのコアが検索対象の音声クリップ(「ターゲット音声クリップ」)を処理して、ターゲット音声クリップのモデルを構築する。一方、音声検索モジュールは、複数のコアに対して音声小グループ/サブストリームを動的にスケジューリングする。複数のコアは、各グループ/サブストリームを複数のセグメントに分割して、各音声セグメントのモデルを構築する。これは並列に行われる。各セグメントのサイズは、ターゲット音声クリップのサイズと等しいとしてもよい。ターゲット音声クリップと音声データベース/ストリームの両方を含むすべての音声セグメントに共通な、複数のガウス成分を含むガウス混合モデル(Gaussian mixture model:GMM)を用いて、各音声セグメントとターゲット音声クリップとをモデル化するとしてもよい。音声セグメントのモデルが構築されると、当該セグメントのモデルとターゲット音声クリップのモデルとの間のカルバック−ライブラー(KL)距離またはKL最大距離を算出するとしてもよい。当該距離が所定値以下であれば、当該音声セグメントはターゲット音声クリップであると特定され得る。検索プロセスは、すべての音声グループ/サブストリームが処理されるまで継続されるとしてもよい。
【0017】
コンピューティングシステム100はさらに、システムインターコネクト115に結合されているチップセット130を備えるとしてもよい。チップセット130は、1以上の集積回路パッケージまたはチップを有するとしてもよい。チップセット130は、コンピューティングシステム100のその他の構成要素160との間のデータ転送をサポートするデバイスインターフェース135を1以上有するとしてもよい。その他の構成要素160は、例えば、BIOSファームウェア、キーボード、マウス、ストレージデバイス、ネットワークインターフェース等である。チップセット130は、周辺機器インターコネクト(PCI)バス170に結合されるとしてもよい。チップセット130はPCIバス170に対するインターフェースを提供するPCIブリッジ145を有するとしてもよい。PCIブリッジ145は、プロセッサ110およびその他の構成要素160と周辺機器との間にデータ経路を提供するとしてもよい。周辺機器は、例えば、音声デバイス180およびディスクドライブ190である。図1には図示されていないが、これら以外のデバイスもまたPCIバス170に結合され得る。
【0018】
また、チップセット130は、メインメモリ150に結合されているメモリコントローラ125を有するとしてもよい。メインメモリ150は、プロセッサ110の複数のコアまたは当該システム内のその他の任意のデバイスによって実行される命令列およびデータを格納するとしてもよい。メモリコントローラ125は、プロセッサ110の複数のコアおよびコンピューティングシステム100内のほかのデバイスに対応付けられるメモリトランザクションに応じてメインメモリ150にアクセスするとしてもよい。一実施形態によると、メモリコントローラ125はプロセッサ110またはその他の回路に配置されるとしてもよい。メインメモリ150は、メモリコントローラ125がデータの読み書きを行う、アドレス指定可能な格納位置を提供するさまざまなメモリデバイスを有するとしてもよい。メインメモリ150は、ダイナミックランダムアクセスメモリ(DRAM)デバイス、シンクロナスDRAM(SDRAM)デバイス、ダブル・データ・レート(DDR)SDRAMデバイスまたはその他のメモリデバイス等、1以上の異なる種類のメモリデバイスを有するとしてもよい。
【0019】
図2は、音声検索モジュール240を用いてロバスト且つ並列な音声検索が実行され得る別の例であるコンピューティングシステム200を示す図である。システム200は、プロセッサ0 220Aのような、複数のプロセッサを備えるとしてもよい。システム200内の1以上のプロセッサは、多くのコアを有するとしてもよい。システム200は、複数のコアによってロバスト且つ並列な音声検索を実行する音声検索モジュール240を備えるとしてもよい。音声検索モジュールは、分割機構、スケジュール、および複数の音声検索部等、複数の構成要素を含むとしてもよい(より詳細な説明は図4から図6を参照しつつ後述する)。音声検索モジュールに含まれる1以上の構成要素が1つのコアに配置されて、他の構成要素は別のコアに配置されるとしてもよい。システム200内のプロセッサは、システムインターコネクト210によって互いに接続されているとしてもよい。システムインターコネクト210は、フロントサイドバス(FSB)であってもよい。各プロセッサは、当該システムインターコネクトを介して、入出力(I/O)デバイスおよびメモリ230に接続されるとしてもよい。コアはすべて、メモリ230から音声データを受け取るとしてもよい。
【0020】
図3は、音声検索モジュール340を用いてロバスト且つ並列な音声検索を実行し得るさらに別の例であるコンピューティングシステム300を示す図である。システム300において、複数のプロセッサ(例えば、320A、320B、320Cおよび320D)を接続するシステムインターコネクト310は、リンクベースのポイント・ツー・ポイント接続である。各プロセッサは、リンクハブ(例えば、330A、330B、330Cおよび330D)を介してシステムインターコネクトに接続されているとしてもよい。一部の実施形態によると、リンクハブはメモリコントローラと同じ場所に配置されて、当該メモリコントローラがシステムメモリに対するトラフィックを調整するとしてもよい。1以上のプロセッサが多くのコアを含むとしてもよい。システム300は、複数のコアによってロバスト且つ並列な音声検索を実行する音声検索モジュール340を備えるとしてもよい。音声検索モジュールは、分割機構、スケジュール、および複数の音声検索部等、複数の構成要素を含むとしてもよい(より詳細な説明は図4から図6を参照しつつ後述する)。音声検索モジュールに含まれる1以上の構成要素が1つのコアに配置されて、他の構成要素は別のコアに配置されるとしてもよい。システム300内の各プロセッサ/コアは、システムインターコネクトを介して共有メモリ(図3には不図示)に接続されるとしてもよい。コアはすべて、共有メモリから音声データを受け取るとしてもよい。
【0021】
図2および図3において、音声検索モジュール(つまり、240および340)はまず、大きい音声データベースを複数の小グループに分割するとしてもよいし、または大きい音声ストリームを一部重複しているより小さいサブストリームに分割するとしてもよい。続いて、1つのコアが検索対象の音声クリップ(「ターゲット音声クリップ」)を処理して、ターゲット音声クリップのモデルを構築する。一方、音声検索モジュールは、複数のコアに対して音声小グループ/サブストリームを動的にスケジューリングする。複数のコアは、各グループ/サブストリームを複数のセグメントに分割して、各音声セグメントのモデルを構築する。これは並列に行われる。各セグメントのサイズは、ターゲット音声クリップのサイズと等しいとしてもよい。ターゲット音声クリップと音声データベース/ストリームの両方を含むすべての音声セグメントに共通な、複数のガウス成分のガウス混合モデル(Gaussian mixture model:GMM)を用いて、各音声セグメントとターゲット音声クリップとをモデル化するとしてもよい。音声セグメントのモデルが構築されると、当該セグメントのモデルとターゲット音声クリップのモデルとの間のカルバック−ライブラー(KL)距離またはKL最大距離を算出するとしてもよい。当該距離が所定値以下であれば、当該音声セグメントはターゲット音声クリップであると特定され得る。検索プロセスは、すべての音声グループ/サブストリームが処理されるまで継続されるとしてもよい。
【0022】
図4は、ロバストな音声検索を実行する音声検索モジュール400の一例を示すブロック図である。音声検索モジュール400は、特徴抽出部410と、モデル化機構420と、決定部430とを備える。特徴抽出部410は、入力音声ストリーム(例えば、ターゲット音声クリップ、大きい音声ストリームのサブストリーム等)を受け取って、入力音声ストリームから音声特徴を抽出するとしてもよい。入力音声ストリームが、ターゲット音声クリップを特定するべく検索されるべき音声ストリームである場合、特徴抽出部は当該音声ストリームに対してスライディングウィンドウ(sliding window)を適用して当該音声ストリームを複数の互いに重複するセグメントに分割するとしてもよい。ウィンドウはターゲット音声クリップと長さが同じである。入力音声ストリームの各セグメント(ターゲット音声ストリームが有するセグメントは1セグメントのみである)はさらに、複数のフレームに分割される。各フレームは、長さが同じで、隣接フレームと重複するとしてもよい。例えば、一実施形態によると、フレームの長さは20ミリ秒で、フレーム間の重複箇所は10ミリ秒であるとしてもよい。各フレームについて特徴ベクトルを抽出するとしてもよい。各フレームは、フーリエ係数、メル周波数ケプストラム係数、スペクトルフラットネス(spectral flattness)、およびこういったパラメータの平均、分散、その他の微分係数といった特徴を含み得る。音声セグメントの全フレームの特徴ベクトルにより、特徴ベクトルシーケンスが形成される。
【0023】
2つの隣接するセグメントが重複しているのは、2つの隣接するセグメント間でターゲット音声クリップを見逃す可能性を小さくするためである。重複箇所が長くなるほど、見逃す可能性が低くなる。一実施形態によると、どのような一致であろうと見逃さないように、重複箇所の長さは、フレームの長さをセグメントの長さから引いたものに等しくなるように設定してもよい。しかし、重複箇所が長くなると演算が増えてしまう。このため、演算負荷と見逃す可能性との間でバランスを取る必要がある(例えば、重複箇所の長さは、セグメントの長さの2分の1以下である)。いずれにしろ、2つのセグメント間で重複しているフレームの特徴ベクトルの場合、抽出は1回のみでよい。
【0024】
モデル化機構420は、特徴抽出部410が抽出した特徴ベクトルシーケンスに基づいて、音声セグメントのモデルを構築するとしてもよい。使用されるモデルに応じて、モデル化機構は該モデルのパラメータを推定する。一実施形態によると、共通成分ガウス混合モデル(「CCGMM」)に基づいて音声セグメントをモデル化するとしてもよい。CCGMMはすべてのセグメントにわたって共通している複数のガウス成分を含む。各セグメントについて、モデル化機構は、共通のガウス成分に対して一連の混合重み付け値を推定する。別の実施形態によると、他のモデル(例えば、隠れマルコフモデル)に基づいて音声セグメントをモデル化するとしてもよい。一実施形態によると、ターゲット音声クリップのみがモデル化されて、音声セグメントの特徴ベクトルシーケンスはそのまま、音声セグメントがターゲット音声クリップと略同一か否か決定するべく利用されるとしてもよい。
【0025】
決定部430は、入力音声ストリームに含まれる音声セグメントが十分に類似しており音声セグメントがターゲット音声クリップの複写と特定できるか否か判断するとしてもよい。このため、決定部は、音声セグメントのモデルとターゲット音声クリップのモデルとを比較することによって類似性測度を導き出すとしてもよい。一実施形態によると、類似性測度はこれら2つのモデル間で算出される距離であってもよい。別の実施形態によると、類似性測度は、音声セグメントのモデルとターゲット音声クリップのモデルとが同一である確率であってもよい。さらに別の実施形態によると、類似性測度は、音声セグメントの特徴ベクトルシーケンスとターゲット音声クリップのモデルとを比較することによって得られるとしてもよい。例えば、隠れマルコフモデル(HMM)に基づいてターゲット音声クリップをモデル化する場合、音声セグメントの特徴ベクトルシーケンスとターゲット音声クリップのHMMとに基づき、音声セグメントとターゲット音声クリップとの間の可能性スコアを算出するべくビタビベースのアルゴリズムを用いるとしてもよい。
【0026】
類似性測度の値に基づいて、決定部は、音声セグメントをターゲット音声クリップと特定できるか否か判断するとしてもよい。例えば、類似性測度の値が所定のしきい値以下であれば(例えば、類似性測度は音声セグメントモデルとターゲット音声クリップとの間の距離である)、音声セグメントはターゲット音声クリップと略同一であると特定され得る。同様に、類似性測度の値が所定しきい値以上であれば(例えば、類似性測度は音声セグメントがターゲット音声クリップと略同一である可能性スコアである)、音声セグメントはターゲット音声クリップと略同一であると特定され得る。一方、類似性測度によって音声セグメントがターゲット音声クリップとは大きく異なることが分かった場合には、当該音声セグメントの直後の任意の数のセグメントを省略するとしてもよい。実際に省略するセグメントの数は、類似性測度の値および/または実験に基づくデータに応じて決まる。類似性測度によって現在のセグメントがターゲット音声クリップと非常に異なることが分かる場合には、任意の数の後続セグメントを省略することによって、ターゲット音声クリップを見逃すことはあり得ない。これは、入力音声ストリームをセグメントに分割するべく利用されるウィンドウが徐々に前方向にスライドする結果、あるセグメントから次のセグメントへと移る際に類似性測度に連続性が認められるためである。
【0027】
図5は、図4に図示されるロバストな音声検索モジュールの動作例を示す図である。ターゲット音声クリップ510は、特徴抽出部に与えられて、複数のフレームに分割される。特徴抽出部はそして、ブロック530Aにおいて、フレーム毎の特徴ベクトルによって、特徴ベクトルシーケンス(540)を生成する。特徴ベクトルは、1以上のパラメータを含み得るので、x次元のベクトルであってもよい(ここで、x≧1)。ブロック570Aにおいて、特徴ベクトルシーケンス540は、以下のようなGMMを用いてモデル化されるとしてもよい。
【数1】
GMM
【数2】
は、M個のガウス成分を含み、
【数3】
は成分重みで、
【数4】
は平均で、
【数5】
は共分散であり、i=1、2・・・、Mであって、kはセグメントkを表し、N()はガウス分布を表す。ターゲット音声クリップについては、セグメントは1つのみであるので、セグメントを特定するためのkは利用する必要はない。しかし、入力音声ストリーム520については、セグメントは通常複数あるので、異なるセグメントについてGMMを特定するのが望ましい。
【0028】
図5に示す例では、カルバック−ライブラー(KL)距離またはKL最大距離を類似性測度として使用する。KL最大距離の算出を簡略化するべく、音声セグメントすべてに用いられるGMMではガウス成分共通群が共通している、つまり、i番目のガウス成分について、平均
【数6】
および分散
【数7】
は音声セグメントが変わっても同じである、と仮定される。このため、式(1)は以下のように変形される。
【数8】
各音声セグメントについて、1セットの重み付け
【数9】
のみを、共通ガウス成分について推定する必要がある。T個の特徴ベクトル、
【数10】
を持つセグメントkの特徴ベクトルシーケンスの場合、重みは以下のように推定され得る。
【数11】
ここで、
【数12】
はi番目またはj番目のセグメントについての普遍的な重みであって、いくつかのサンプル音声ファイルに基づいて実験により得られるとしてもよいし、乱数値によって初期化されるとしてもよい。
【0029】
ターゲット音声クリップ510を特定するべく検索される入力音声ストリーム520は、特徴抽出部に与えられるとしてもよい。ブロック530Bにおいて、特徴抽出部は入力音声ストリームを、互いに部分的に重複する複数のセグメントに分割する。特徴抽出部はさらに、各セグメントを、互いに部分的に重複する複数のフレームに分割して、フレーム毎に特徴ベクトルを抽出する。ブロック560は、入力音声ストリーム520の特徴ベクトルシーケンスを示すと共に、当該音声ストリームが互いに部分的に重複する複数のセグメントに分割されている様子を示す。例えば、ターゲット音声クリップの長さと同じサイズのウィンドウを入力音声ストリーム520に適用するとしてもよい。説明のために、セグメント560Aを得るべくターゲット音声クリップの特徴ベクトルシーケンスに対してウィンドウが図示されているが、この場合セグメントは1つしかないので、ターゲット音声クリップにウィンドウを適用する必要は通常ない。シフトするウィンドウを入力音声ストリームに適用すると、560Bおよび560Cのような部分的に重複する複数のセグメントが得られる。ウィンドウのシフト量は、セグメント560Bからセグメント560Cまでの間で時間τであり、ここでτはウィンドウサイズよりも小さい。
【0030】
各音声セグメントはCCGMMを用いてモデル化される。例えば、セグメント560Bはブロック570Bでモデル化され、セグメント560Cはブロック570Cでモデル化される。入力音声ストリーム520の各セグメントのモデルとターゲット音声クリップ510のモデルは、重みの組み合わせは異なるが共通のガウス成分を有する。一実施形態によると、特徴ベクトルは入力音声ストリーム全体からフレーム毎に抽出されて、入力音声ストリーム全体に対応する長い特徴ベクトルシーケンスが生成されるとしてもよい。続いて、N×FL(ここで、Nは正の整数でありFLはフレームの長さ)の長さを持つウィンドウが、当該長い特徴ベクトルシーケンスに適用される。ウィンドウ内の複数の特徴ベクトルは、一の音声セグメントの一の特徴ベクトルを構成し、この特徴ベクトルはCCGMMを構築するために利用される。ウィンドウは、時間τだけ前方向にシフトされる。
【0031】
セグメントがターゲット音声クリップと略同一か否か決定するべく、当該セグメントのモデルとターゲット音声クリップのモデルとの間のKL最大距離を以下のようにして算出するとしてもよい。
【数13】
このようにして算出されたKL最大距離が所定のしきい値未満の場合、音声クリップが検出されたとみなされるとしてもよい。入力音声ストリーム520に対して適用されるウィンドウが時間方向で前方向にシフトされていくと、距離は通常、1つのタイムステップから次のタイムステップまでの間で一定の継続性を示す。つまり、距離が大きすぎると、現在のセグメントの直後に続く1以上のセグメントがターゲット音声クリップに一致する可能性は低い。このため、距離の値によっては、同一音声ストリーム/サブストリーム内の直後の所定数のセグメントについては検索を省略するとしてもよい。
【0032】
図6は、マルチプロセッサシステムにおいてロバスト且つ並列な音声検索を実行する音声検索モジュール600の一例を示すブロック図である。音声検索モジュール600は、分割機構610と、スケジューラ620と、I/O最適化部630と、複数の音声検索部(例えば640A、・・・、640N)とを備える。分割機構610は、大きい音声ストリームを複数のより小さいサブストリームに分割、および/または、大きい音声データベースを複数の小グループに分割するとしてもよい。図7A、図7Bおよび図7Cは、マルチプロセッサシステムにおいてロバスト且つ並列な音声検索を実行するべく大きい音声データベースを小グループに分割する方法を示す図である。図7Aは、単一の大きな音声ストリーム710を含むデータベースの一例を示す図である。分割機構は、音声ストリーム710を複数のより小さいサブストリーム712、714および716に分割するとしてもよい。ここで、各サブストリームは1グループを構成している。各サブストリームの長さは互いに異なるとしてもよいが、処理を単純化するべく通常は均一な長さとする。ターゲット音声クリップの正確な検出を見落とすことのないように、各サブストリームは直後のサブストリームと重複しており、2つの隣接するサブストリーム(例えば、712および714、714および716)間での重複部分は、
【数14】
以上でなければならない。ここで、
【数15】
はターゲット音声クリップ内のフレーム総数である。
【0033】
図7Bは、複数の比較的小さい音声ストリーム(例えば、720、725、730、735、および740)を含む別の例のデータベースを示す図である。一実施形態によると、分割機構610は当該データベースを、各グループが1つの音声ストリームのみを含むように、複数の小グループに分割するとしてもよい。別の実施形態によると、図7Bに示すように、分割機構はデータベースを、一部のグループはそれぞれが音声ストリームを1つのみ含み、他のグループはそれぞれが複数の小さい音声ストリームを含むように、複数の小グループに分割してもよい。図7Cは、複数の比較的小さい音声ストリーム(例えば、750、755および760)と大きな音声ストリーム(例えば770)とを含むさらに別の例のデータベースを示す図である。分割機構は、比較的小さい音声ストリームを、各グループが音声ストリーム1つのみを含むように複数のグループに分割するとしてもよいし、または、一部のグループは音声ストリームを1つのみ含み(例えば、750)他のグループは複数の小さい音声ストリームを含む(例えば、755および760を同じグループに入れるとしてもよい)ように複数のグループに分割するとしてもよい。770のような大きい音声ストリームについては、分割機構は、互いに部分的に重複する複数のより小さいサブストリーム(例えば、772および774)に分割するとしてもよい。ここで、図7Aに示した方法に従って、各サブストリームは1グループを構成するとしてもよい。
【0034】
また、分割機構は、演算の重複(大きな音声ストリームが互いに部分的に重複する複数のより小さいサブストリームに分割される場合)および複数のプロセッサによる並列処理における負荷の不均衡を低減するように、大きな音声データベースを複数の適切なサイズの複数のグループに分割する。グループのサイズが小さくなると、演算の重複部分が大きくなり得る一方、グループのサイズが大きくなると、負荷の不均衡が著しくなってしまうことがある。一実施形態によると、グループのサイズはターゲット音声クリップのサイズの約25倍であるとしてもよい。
【0035】
図6に戻って、スケジューラ620は、マルチプロセッサシステム内の複数のプロセッサに対して大きなデータベースの複数のグループを動的にスケジューリングして、各プロセッサが一度に1つの処理対象のグループを持つようにするとしてもよい。スケジューラは、当該システムの複数のプロセッサが利用可能か否かを定期的に確認して、利用可能なプロセッサそれぞれに対して音声グループを割り当てて、処理およびターゲット音声クリップの検索を実行させる。その後別のプロセッサが利用可能な状態になると、スケジューラはこのプロセッサに1つのグループを割り当てるとしてもよい。スケジューラはまた、プロセッサがその前に割り当てられたグループについて検索を終了した直後に、ほかのプロセッサが検索処理を終了したかどうかに関わらず、当該プロセッサに対してまだ検索がすんでいない音声グループを割り当てる。実際のところ、グループのサイズが同一であったとしても、検索処理を省略するセグメントの数はセグメント毎に異なる可能性があるので、同じターゲット音声クリップを検索するのに必要な時間はプロセッサごとに異なる場合がある。上述したような動的スケジューリングを利用することで、負荷の不均衡を効果的に低減し得る。
【0036】
I/O最適化部630は、システムインターコネクト(例えば、システムのプロセッサと共有システムメモリとを接続するシステムバス)上でのI/Oトラフィックを最適化するとしてもよい。I/O最適化部は、各プロセッサのデータ範囲が定義されている間、最初は、検索対象の音声データベース全体をディスクからメモリへロードしないと判断するとしてもよい。また、I/O最適化部は、メモリから受け取る割り当てられたセグメントを各プロセッサが読む際には、一度に一部分のみを読ませるとしてもよい。I/Oトラフィックを最適化することによって、I/O最適化部は、I/Oコンテンションを低減し、I/O処理および演算を重複させ、演算効率の向上に貢献するとしてもよい。この結果、音声検索のスケーラビリティを大きく改善することができる。
【0037】
音声検索モジュール600はさらに、複数の音声検索部640Aから640Nを備える。各音声検索部(例えば640A)は、一のプロセッサに配置されて、当該プロセッサに割り当てられるグループを処理してターゲット音声クリップを検索する。図4に図示されている音声検索モジュール400と同様に、音声検索部は、特徴抽出部(例えば410)と、モデル化機構(例えば420)と、決定部(例えば430)とを有する。各音声検索部は、自身に割り当てられた、ターゲット音声クリップを特定するための音声グループの連続能動型検索を実行する。これは、音声グループの音声ストリームを、互いに部分的に重複する複数のセグメントに分割し、各セグメントについて特徴ベクトルシーケンスを抽出して、式(1)から(4)で示したようにCCGMMに基づいて各セグメントをモデル化することによって行われる。ここで、セグメントの長さはターゲット音声クリップの長さと同じである。また、すべての音声検索部が利用する、ターゲット音声クリップ用のCCGMMは、音声検索部のうちの1つが一度推定すればそれでよい。各音声検索部は、各セグメントのモデルとターゲット音声クリップのモデルとの間のKL最大距離を算出する。このKL最大距離に基づいて、音声検索部はターゲット音声クリップが検出されるか否か判断するとしてもよい。さらに、各音声検索部は、現在のセグメントのKL最大距離がしきい値よりも大きい場合には、現在のセグメントに続く複数のセグメントを省略するとしてもよい。
【0038】
図8は、マルチプロセッサシステムにおいてロバスト且つ並列な音声検索を実行するためのプロセス800の一例を示す擬似コードを示す図である。ライン802において、音声検索モジュールは初期化されるとしてもよい。例えば、ターゲット音声クリップファイルおよび音声データベースファイルを開けて、グローバルパラメータを初期化するとしてもよい。ライン804において、大きな音声データベースを、図7A、図7Bおよび図7Cに図示しているように、NG個の小グループに分割するとしてもよい。ライン806において、モデル(例えば、CCGMM)をターゲット音声クリップについて構築するとしてもよい。ライン808において、NG個の音声グループを利用可能なプロセッサに対して動的にスケジューリングして、スケジューリングされたグループの並列処理を開始するとしてもよい。ライン808は、並列実装をセットアップする1つの命令を利用し、その他の並列実装命令もまた用いられ得る。
【0039】
ライン810からライン846は、マルチプロセッサシステムのプロセッサが並列に、NG個のグループのそれぞれをどのように処理し、且つどのように検索してターゲットを特定するかを示している。説明の便宜上、ライン812からライン846の処理は、第1番目のグループから最後のグループまでの、繰り返しとして図示されていることに留意されたい。実際には、複数のプロセッサが利用可能な場合、これらの利用可能なプロセッサによって複数のグループが並列に処理される。ライン814において、各グループの複数の音声ストリームのうち一部またはすべてを、これらのストリームがターゲット音声クリップよりも時間的に長い場合には、互いに部分的に重複するNS個のセグメントにさらに分割するとしてもよい。ライン816は、グループの各セグメントについて、ライン818から832に示すような、繰り返しプロセスを開始させる。ライン820において、特徴ベクトルシーケンス(フレーム毎に)をセグメントから抽出するとしてもよい。ライン822において、モデル(例えば、式(1)から式(3)に示すようなCCGMM)をセグメントについて構築するとしてもよい。ライン824において、セグメントのモデルとターゲット音声クリップのモデルとの間の距離(例えば、式(4)に示すようなKL最大距離)を算出するとしてもよい。ライン826において、セグメントがターゲット音声クリップと一致するか否かを、ライン824において算出された距離と所定のしきい値#1とに基づいて、判断するとしてもよい。距離がしきい値#1未満であれば、セグメントはターゲット音声クリップに一致する。ライン828において、同じ音声ストリーム/サブストリーム内の所定数の後続セグメント(例えば、M個のセグメント)の検索を省略するか否かを、ライン824において算出された距離と所定のしきい値#2とに基づいて、判断するとしてもよい。距離がしきい値#2よりも大きい場合には、M個のセグメントの検索を省略するとしてもよい。一実施形態によると、省略するセグメントの数は距離の値に応じて変わるとしてもよい。ライン830において、検索結果(例えば、各グループにおける一致セグメントのインデックスまたは開始時間)を、当該グループを処理するプロセッサに対してローカルなアレイに格納するとしてもよい。ライン842において、すべてのプロセッサから得られる、ローカルアレイに格納した検索結果を要約してユーザに出力するとしてもよい。
【0040】
図8に概略を示したロバスト且つ並列な検索ストラテジを、I/O最適化等のほかの技術と共に用いることによって、マルチプロセッサシステムにおいて大きな音声データベース内でターゲット音声クリップを検索するスピードを大きく改善し得る。1つの実験によると、27時間の音声ストリームにおいて15秒のターゲット音声クリップを検索するスピードは、16ウェイ(16−way)のユニシスシステムにおいて、同じターゲット音声クリップにおいて同じ音声ストリームを連続して検索する場合に比べると、11倍に早くなることが分かっている。
【0041】
一実施形態によると、変形された検索ストラテジが用いられ得る。このストラテジを用いると、ターゲット音声クリップの最初のK個(K≧1)のフレームに対して仮モデル(例えば、CCGMM)を構築して、ターゲット音声クリップ全体に対して完全モデルを構築するとしてもよい。このためまず、音声セグメントの最初のK個(K≧1)のフレームに対して仮モデル(例えば、CCGMM)が構築され得る。能動型検索において、各音声セグメントの最初のK個のフレームの仮モデルとターゲット音声クリップの最初のK個のフレームの仮モデルとがまず比較されて、仮類似性測度を生成する。仮類似性測度によってこれらの2つの仮モデルが非常に類似していることが分かれば、音声セグメント全体に対して完全モデルが構築されて、ターゲット音声クリップ全体の完全モデルに対して比較される。そうでない場合は、音声セグメントに対して完全モデルは構築されず、最初のK個のフレームに対して仮モデルをまず構築してこの仮モデルとターゲット音声クリップの仮モデルを比較することによって、次のセグメントを検索するとしてもよい。このような変形検索ストラテジは、さらに演算負荷を低減し得る。
【0042】
開示されている主題の実施形態例を図1から図8に示すブロック図およびフローチャートを参照しつつ説明したが、当業者であれば、開示されている主題はほかの多くの方法によっても実施され得ることが容易に理解できる。例えば、フローチャートにおけるブロックの実行順序は変更するとしてもよいし、および/または、説明したブロック図/フローチャートのブロックはその一部を変更、削除または合成するとしてもよい。
【0043】
前述の説明では、開示されている主題をさまざまな側面から説明した。説明に当たっては、主題を十分に説明することを目的として、具体的な数値、システムおよび構成を記載した。しかし、本開示内容を参考にすることによって、このような具体的且つ詳細な内容がなくても主題を実施し得ることは、当業者には明らかである。また、公知の特徴、構成要素またはモジュールは、開示されている主題をあいまいにすることを避けるべく、省略、簡略化、合成または分割した。
【0044】
開示されている主題のさまざまな実施形態は、ハードウェア、ファームウェア、ソフトウェアまたはそれらの組み合わせにおいて実装され得る。また、開示されている主題のさまざまな実施形態は、プログラムコードを参照することによって、またはプログラムコードと関連付けることによって記述され得る。プログラムコードは、例えば、設計のシミュレーション、エミュレーションおよび製造用の命令、機能、手順、データ構造、ロジック、アプリケーションプログラム、設計表現またはフォーマットであり、機械によってアクセスされると、機械はタスクを実行し、抽象データ型または低水準ハードウェアコンテキストを定義して、結果を生成する。
【0045】
シミュレーション用の場合、プログラムコードは、設計されたハードウェアがどのように動作するかを示すモデルを本質的に提供する、ハードウェア記述言語または別の機能記述言語を用いてハードウェアを表現するとしてもよい。プログラムコードは、アセンブリまたは機械言語、もしくはコンパイルおよび/または解釈され得るデータであってもよい。また、ソフトウェアとは、ある形態または別の形態によって、動作を実行するかまたは、結果を生じさせるものと認識することは当該技術分野では普通である。このような表現は、プロセッサに動作を実行させるか、または結果を生成させる処理システムによるプログラムコードの実行を簡単に説明するためのものに過ぎない。
【0046】
プログラムコードは、例えば、揮発性および/または不揮発性メモリに格納されるとしてもよい。揮発性および/または不揮発性メモリは、ストレージデバイスおよび/または関連付けられる機械可読または機械アクセス可能媒体であってよい。機械可読または機械アクセス可能媒体は、固体メモリ、ハードドライブ、フロッピーディスク、光学ストレージ、テープ、フラッシュメモリ、メモリスティック、デジタルビデオディスク、デジタル多用途ディスク(DVD)等であってよいし、機械アクセス可能な生物学的状態保存ストレージ等のより珍しい媒体であってもよい。機械可読媒体は、機械が読み出し可能な形式で情報を格納、送信または受信するどのような機構を有するとしてもよく、当該媒体は、プログラムコードを符号化している伝播信号または搬送波の電気的形態、光学的形態、音響的形態またはその他の形態を通過させる有形の媒体、例えば、アンテナ、光ファイバ、通信インターフェース等を有するとしてもよい。プログラムコードは、パケット、シリアルデータ、パラレルデータ、伝播信号等の形態で送信されるとしてもよく、圧縮または暗号化された形式で利用されるとしてもよい。
【0047】
プログラムコードは、プロセッサと、当該プロセッサによって読み出し可能な揮発性および/または不揮発性メモリと、少なくとも1つの入力デバイスおよび/または1以上の出力デバイスとを備える、移動可能または固定コンピュータ、携帯情報端末(PDA)、セットトップボックス、携帯電話およびポケットベル(登録商標)、ならびにその他の電子デバイスといった、プログラム可能な機械で実行されるプログラムにおいて実装されるとしてもよい。プログラムコードは、入力デバイスを用いて入力されたデータに対して適用されて、上述した実施形態を実行して出力情報を生成するとしてもよい。出力情報は、1以上の出力デバイスに適用されるとしてもよい。当業者であれば、開示されている主題の実施形態はさまざまなコンピュータシステム構成によって実施され得ることに想到し得る。そのようなコンピュータシステム構成は、マルチプロセッサまたはマルチコアプロセッサシステム、ミニコンピュータ、メインフレームコンピュータ、実質的にいかなるデバイスにも埋め込み得るパーベイシブ(pervasive)またはミニチュア型のコンピュータまたはプロセッサを含む。開示されている主題の実施形態はまた、タスクを実行するのは通信ネットワークを介してリンクされているリモート処理デバイスである分散コンピューティング環境において実施され得る。
【0048】
処理は順次実行されるものとして説明されているが、一部の処理については、実際には、並列に、同時に、および/または分散環境下において実行されるとしてもよく、プログラムコードは、シングルプロセッサ型またはマルチプロセッサ型の機械によってアクセスされるべく、ローカルおよび/またはリモートに格納されている。また、一部の実施形態によると、処理の順序は、開示されている主題の精神から逸脱することなく並び替え得る。プログラムコードは、埋め込まれているコントローラによって用いられるとしてもよいし、埋め込まれたコントローラと関連して利用されるとしてもよい。
【0049】
開示されている主題を実施形態例を参照しつつ説明してきたが、この説明は本発明を限定するものと解釈されるべきではない。実施形態例のさまざまな変形例および主題のその他の実施形態は、当業者には明らかであり、開示されている主題の範囲内に含まれるものとする。
【特許請求の範囲】
【請求項1】
マルチプロセッサシステムにおいて音声データベースを検索してターゲット音声クリップを特定する方法であって、
前記音声データベースを複数のグループに分割する段階と、
前記ターゲット音声クリップについてモデルを構築する段階と、
前記マルチプロセッサシステムの複数のプロセッサに対して前記複数のグループを動的にスケジューリングする段階と、
前記ターゲット音声クリップを検索するために、前記複数のプロセッサを用いて前記スケジューリングされた複数のグループを並列に処理する段階と
を備える方法。
【請求項2】
前記音声データベースを分割する段階は、前記複数のグループの並列処理における、負荷の不均衡および前記複数のグループ間で重複する演算の量を低減するように、前記複数のグループのそれぞれについてサイズを決定する段階を含む
請求項1に記載の方法。
【請求項3】
前記ターゲット音声クリップについてモデルを構築する段階は、前記ターゲット音声クリップから特徴ベクトルシーケンスを抽出する段階と、複数のガウス成分を含むガウス混合モデル(GMM)に基づいて前記特徴ベクトルシーケンスをモデル化する段階とを含む
請求項1に記載の方法。
【請求項4】
前記特徴ベクトルシーケンスをモデル化する段階は、前記複数のガウス成分のそれぞれについて混合重みを推定する段階を含む
請求項3に記載の方法。
【請求項5】
前記スケジューリングされた複数のグループを並列に処理する段階は、
前記スケジューリングされた複数のグループのそれぞれを少なくとも1つのセグメントに分割する段階と、
各セグメントについて、前記セグメントの特徴ベクトルシーケンスを抽出する段階と、
各セグメントについて、複数のガウス成分を含むガウス混合モデル(GMM)に基づいて前記特徴ベクトルシーケンスをモデル化する段階と
を含む
請求項1に記載の方法。
【請求項6】
前記少なくとも1つのセグメントのそれぞれの時間の長さは、前記ターゲット音声クリップの時間の長さと同じである
請求項5に記載の方法。
【請求項7】
音声ストリームに複数のセグメントがある場合、各セグメントは直前のセグメントと部分的に重複する
請求項5に記載の方法。
【請求項8】
前記複数のガウス成分は、複数の異なるセグメントおよび前記ターゲット音声クリップに共通している
請求項5に記載の方法。
【請求項9】
前記特徴ベクトルシーケンスをモデル化する段階は、前記複数のガウス成分のそれぞれについて混合重みを推定する段階を含む
請求項8に記載の方法。
【請求項10】
セグメント毎に、
前記セグメントのGMMと前記ターゲット音声クリップのGMMとの間でカルバック・ライブラー(KL)距離を算出する段階と、
前記KL距離が予め定められるしきい値よりも小さい場合には、前記セグメントが前記ターゲット音声クリップに一致すると決定する段階と
をさらに備える、請求項9に記載の方法。
【請求項11】
前記KL距離が予め定められる値よりも大きい場合には、前記KL距離の値に応じて決まる数のセグメントの処理を省略する段階
をさらに備える、請求項10に記載の方法。
【請求項12】
前記マルチプロセッサシステムは、前記複数のプロセッサが共有するメモリを有する
請求項1に記載の方法。
【請求項13】
マルチプロセッサシステムにおいて音声データベースを検索してターゲット音声クリップを特定する装置であって、
前記音声データベースを複数のグループに分割する分割モジュールと、
前記マルチプロセッサシステムの複数のプロセッサに対して前記複数のグループを動的にスケジューリングするスケジューラと、
前記複数のプロセッサを用いて前記スケジューリングされた複数のグループを並列に処理して前記ターゲット音声クリップを検索する、前記複数のプロセッサのそれぞれに対応する音声検索モジュールと
を備える装置。
【請求項14】
前記分割モジュールはさらに、前記複数のグループの並列処理における、負荷の不均衡および前記複数のグループ間で重複する演算の量を低減するように、前記複数のグループのそれぞれについてサイズを決定する
請求項13に記載の装置。
【請求項15】
音声検索モジュールは、
入力音声ストリームを少なくとも1つのセグメントに分割して、前記少なくとも1つのセグメントのそれぞれから特徴ベクトルシーケンスを抽出する特徴抽出部と、
複数のガウス成分を含むガウス混合モデル(GMM)に基づいて各セグメントに対する前記特徴ベクトルシーケンスをモデル化するモデル化モジュールと
を有し、
前記少なくとも1つのセグメントの時間の長さは、前記ターゲット音声クリップと同じであり、
前記複数のガウス成分は、前記セグメントの全てについて共通である
請求項13に記載の装置。
【請求項16】
音声検索モジュールのうちの1つはさらに、前記ターゲット音声クリップから特徴ベクトルシーケンスを抽出して、複数のガウス成分を含む前記GMMを用いて前記特徴ベクトルシーケンスをモデル化することによって、前記ターゲット音声クリップを処理し、前記複数のガウス成分は、前記ターゲット音声クリップおよび前記入力音声ストリームの複数のセグメントについて共通である
請求項15に記載の装置。
【請求項17】
音声検索モジュールはさらに、前記入力音声ストリームのセグメントのGMMと前記ターゲット音声クリップのGMMとの間でカルバック・ライブラー(KL)距離を算出し、前記KL距離に基づいて、前記セグメントが前記ターゲット音声クリップに一致するか否か決定する決定部を有する
請求項16に記載の装置。
【請求項18】
前記決定モジュールはさらに、前記KL距離に基づいて、処理を省略するセグメントの数を決定する
請求項17に記載の装置。
【請求項19】
複数の命令を格納する機械可読媒体を備える物品であって、前記複数の命令は、処理プラットフォームによって実行されると、前記処理プラットフォームに、
音声データベースを複数のグループに分割する段階と、
ターゲット音声クリップについてモデルを構築する段階と、
マルチプロセッサシステムの複数のプロセッサについて前記複数のグループを動的にスケジューリングする段階と、
前記ターゲット音声クリップを検索するために、前記複数のプロセッサを用いて前記スケジューリングされた複数のグループを並列に処理する段階と
を備える処理を実行させる
物品。
【請求項20】
前記音声データベースを分割する段階は、前記複数のグループの並列処理における、負荷の不均衡および前記複数のグループ間で重複する演算の量を低減するように、前記複数のグループのそれぞれについてサイズを決定する段階を含む
請求項19に記載の物品。
【請求項21】
前記ターゲット音声クリップについてモデルを構築する段階は、前記ターゲット音声クリップから特徴ベクトルシーケンスを抽出する段階と、複数のガウス成分を含むガウス混合モデル(GMM)に基づいて前記特徴ベクトルシーケンスをモデル化する段階とを含む
請求項19に記載の物品。
【請求項22】
前記特徴ベクトルシーケンスをモデル化する段階は、前記複数のガウス成分のそれぞれについて混合重みを推定する段階を含む
請求項21に記載の物品。
【請求項23】
前記スケジューリングされた複数のグループを並列に処理する段階は、
前記スケジューリングされた複数のグループのそれぞれを少なくとも1つのセグメントに分割する段階と、
各セグメントについて、前記セグメントの特徴ベクトルシーケンスを抽出する段階と、
各セグメントについて、複数のガウス成分を含むガウス混合モデル(GMM)に基づいて前記特徴ベクトルシーケンスをモデル化する段階と
を含む
請求項19に記載の物品。
【請求項24】
前記少なくとも1つのセグメントのそれぞれの時間の長さは、前記ターゲット音声クリップの時間の長さと同じである
請求項22に記載の物品。
【請求項25】
音声ストリームに複数のセグメントがある場合、各セグメントは直前のセグメントと部分的に重複する
請求項22に記載の物品。
【請求項26】
前記複数のガウス成分は、複数の異なるセグメントおよび前記ターゲット音声クリップに共通している
請求項22に記載の物品。
【請求項27】
前記特徴ベクトルシーケンスをモデル化する段階は、前記複数のガウス成分のそれぞれについて混合重みを推定する段階を含む
請求項26に記載の物品。
【請求項28】
前記処理は、
セグメント毎に、
前記セグメントのGMMと前記ターゲット音声クリップのGMMとの間でカルバック・ライブラー(KL)距離を算出する段階と、
前記KL距離が予め定められるしきい値よりも小さい場合には、前記セグメントが前記ターゲット音声クリップに一致すると決定する段階と
をさらに備える、請求項27に記載の物品。
【請求項29】
前記処理は、
前記KL距離が予め定められる値よりも大きい場合には、前記KL距離の値に応じて決まる数のセグメントの処理を省略する段階
をさらに備える、請求項28に記載の物品。
【請求項30】
前記マルチプロセッサシステムは、前記複数のプロセッサが共有するメモリを有する
請求項19に記載の物品。
【請求項1】
マルチプロセッサシステムにおいて音声データベースを検索してターゲット音声クリップを特定する方法であって、
前記音声データベースを複数のグループに分割する段階と、
前記ターゲット音声クリップについてモデルを構築する段階と、
前記マルチプロセッサシステムの複数のプロセッサに対して前記複数のグループを動的にスケジューリングする段階と、
前記ターゲット音声クリップを検索するために、前記複数のプロセッサを用いて前記スケジューリングされた複数のグループを並列に処理する段階と
を備える方法。
【請求項2】
前記音声データベースを分割する段階は、前記複数のグループの並列処理における、負荷の不均衡および前記複数のグループ間で重複する演算の量を低減するように、前記複数のグループのそれぞれについてサイズを決定する段階を含む
請求項1に記載の方法。
【請求項3】
前記ターゲット音声クリップについてモデルを構築する段階は、前記ターゲット音声クリップから特徴ベクトルシーケンスを抽出する段階と、複数のガウス成分を含むガウス混合モデル(GMM)に基づいて前記特徴ベクトルシーケンスをモデル化する段階とを含む
請求項1に記載の方法。
【請求項4】
前記特徴ベクトルシーケンスをモデル化する段階は、前記複数のガウス成分のそれぞれについて混合重みを推定する段階を含む
請求項3に記載の方法。
【請求項5】
前記スケジューリングされた複数のグループを並列に処理する段階は、
前記スケジューリングされた複数のグループのそれぞれを少なくとも1つのセグメントに分割する段階と、
各セグメントについて、前記セグメントの特徴ベクトルシーケンスを抽出する段階と、
各セグメントについて、複数のガウス成分を含むガウス混合モデル(GMM)に基づいて前記特徴ベクトルシーケンスをモデル化する段階と
を含む
請求項1に記載の方法。
【請求項6】
前記少なくとも1つのセグメントのそれぞれの時間の長さは、前記ターゲット音声クリップの時間の長さと同じである
請求項5に記載の方法。
【請求項7】
音声ストリームに複数のセグメントがある場合、各セグメントは直前のセグメントと部分的に重複する
請求項5に記載の方法。
【請求項8】
前記複数のガウス成分は、複数の異なるセグメントおよび前記ターゲット音声クリップに共通している
請求項5に記載の方法。
【請求項9】
前記特徴ベクトルシーケンスをモデル化する段階は、前記複数のガウス成分のそれぞれについて混合重みを推定する段階を含む
請求項8に記載の方法。
【請求項10】
セグメント毎に、
前記セグメントのGMMと前記ターゲット音声クリップのGMMとの間でカルバック・ライブラー(KL)距離を算出する段階と、
前記KL距離が予め定められるしきい値よりも小さい場合には、前記セグメントが前記ターゲット音声クリップに一致すると決定する段階と
をさらに備える、請求項9に記載の方法。
【請求項11】
前記KL距離が予め定められる値よりも大きい場合には、前記KL距離の値に応じて決まる数のセグメントの処理を省略する段階
をさらに備える、請求項10に記載の方法。
【請求項12】
前記マルチプロセッサシステムは、前記複数のプロセッサが共有するメモリを有する
請求項1に記載の方法。
【請求項13】
マルチプロセッサシステムにおいて音声データベースを検索してターゲット音声クリップを特定する装置であって、
前記音声データベースを複数のグループに分割する分割モジュールと、
前記マルチプロセッサシステムの複数のプロセッサに対して前記複数のグループを動的にスケジューリングするスケジューラと、
前記複数のプロセッサを用いて前記スケジューリングされた複数のグループを並列に処理して前記ターゲット音声クリップを検索する、前記複数のプロセッサのそれぞれに対応する音声検索モジュールと
を備える装置。
【請求項14】
前記分割モジュールはさらに、前記複数のグループの並列処理における、負荷の不均衡および前記複数のグループ間で重複する演算の量を低減するように、前記複数のグループのそれぞれについてサイズを決定する
請求項13に記載の装置。
【請求項15】
音声検索モジュールは、
入力音声ストリームを少なくとも1つのセグメントに分割して、前記少なくとも1つのセグメントのそれぞれから特徴ベクトルシーケンスを抽出する特徴抽出部と、
複数のガウス成分を含むガウス混合モデル(GMM)に基づいて各セグメントに対する前記特徴ベクトルシーケンスをモデル化するモデル化モジュールと
を有し、
前記少なくとも1つのセグメントの時間の長さは、前記ターゲット音声クリップと同じであり、
前記複数のガウス成分は、前記セグメントの全てについて共通である
請求項13に記載の装置。
【請求項16】
音声検索モジュールのうちの1つはさらに、前記ターゲット音声クリップから特徴ベクトルシーケンスを抽出して、複数のガウス成分を含む前記GMMを用いて前記特徴ベクトルシーケンスをモデル化することによって、前記ターゲット音声クリップを処理し、前記複数のガウス成分は、前記ターゲット音声クリップおよび前記入力音声ストリームの複数のセグメントについて共通である
請求項15に記載の装置。
【請求項17】
音声検索モジュールはさらに、前記入力音声ストリームのセグメントのGMMと前記ターゲット音声クリップのGMMとの間でカルバック・ライブラー(KL)距離を算出し、前記KL距離に基づいて、前記セグメントが前記ターゲット音声クリップに一致するか否か決定する決定部を有する
請求項16に記載の装置。
【請求項18】
前記決定モジュールはさらに、前記KL距離に基づいて、処理を省略するセグメントの数を決定する
請求項17に記載の装置。
【請求項19】
複数の命令を格納する機械可読媒体を備える物品であって、前記複数の命令は、処理プラットフォームによって実行されると、前記処理プラットフォームに、
音声データベースを複数のグループに分割する段階と、
ターゲット音声クリップについてモデルを構築する段階と、
マルチプロセッサシステムの複数のプロセッサについて前記複数のグループを動的にスケジューリングする段階と、
前記ターゲット音声クリップを検索するために、前記複数のプロセッサを用いて前記スケジューリングされた複数のグループを並列に処理する段階と
を備える処理を実行させる
物品。
【請求項20】
前記音声データベースを分割する段階は、前記複数のグループの並列処理における、負荷の不均衡および前記複数のグループ間で重複する演算の量を低減するように、前記複数のグループのそれぞれについてサイズを決定する段階を含む
請求項19に記載の物品。
【請求項21】
前記ターゲット音声クリップについてモデルを構築する段階は、前記ターゲット音声クリップから特徴ベクトルシーケンスを抽出する段階と、複数のガウス成分を含むガウス混合モデル(GMM)に基づいて前記特徴ベクトルシーケンスをモデル化する段階とを含む
請求項19に記載の物品。
【請求項22】
前記特徴ベクトルシーケンスをモデル化する段階は、前記複数のガウス成分のそれぞれについて混合重みを推定する段階を含む
請求項21に記載の物品。
【請求項23】
前記スケジューリングされた複数のグループを並列に処理する段階は、
前記スケジューリングされた複数のグループのそれぞれを少なくとも1つのセグメントに分割する段階と、
各セグメントについて、前記セグメントの特徴ベクトルシーケンスを抽出する段階と、
各セグメントについて、複数のガウス成分を含むガウス混合モデル(GMM)に基づいて前記特徴ベクトルシーケンスをモデル化する段階と
を含む
請求項19に記載の物品。
【請求項24】
前記少なくとも1つのセグメントのそれぞれの時間の長さは、前記ターゲット音声クリップの時間の長さと同じである
請求項22に記載の物品。
【請求項25】
音声ストリームに複数のセグメントがある場合、各セグメントは直前のセグメントと部分的に重複する
請求項22に記載の物品。
【請求項26】
前記複数のガウス成分は、複数の異なるセグメントおよび前記ターゲット音声クリップに共通している
請求項22に記載の物品。
【請求項27】
前記特徴ベクトルシーケンスをモデル化する段階は、前記複数のガウス成分のそれぞれについて混合重みを推定する段階を含む
請求項26に記載の物品。
【請求項28】
前記処理は、
セグメント毎に、
前記セグメントのGMMと前記ターゲット音声クリップのGMMとの間でカルバック・ライブラー(KL)距離を算出する段階と、
前記KL距離が予め定められるしきい値よりも小さい場合には、前記セグメントが前記ターゲット音声クリップに一致すると決定する段階と
をさらに備える、請求項27に記載の物品。
【請求項29】
前記処理は、
前記KL距離が予め定められる値よりも大きい場合には、前記KL距離の値に応じて決まる数のセグメントの処理を省略する段階
をさらに備える、請求項28に記載の物品。
【請求項30】
前記マルチプロセッサシステムは、前記複数のプロセッサが共有するメモリを有する
請求項19に記載の物品。
【図1】

【図2】
【図3】
【図4】
【図5】
【図6】
【図7A】
【図7B】
【図7C】
【図8】

【図2】
【図3】
【図4】
【図5】
【図6】
【図7A】
【図7B】
【図7C】
【図8】
【公開番号】特開2012−133371(P2012−133371A)
【公開日】平成24年7月12日(2012.7.12)
【国際特許分類】
【外国語出願】
【出願番号】特願2012−70(P2012−70)
【出願日】平成24年1月4日(2012.1.4)
【分割の表示】特願2009−516853(P2009−516853)の分割
【原出願日】平成18年7月3日(2006.7.3)
【公序良俗違反の表示】
(特許庁注:以下のものは登録商標)
1.フロッピー
【出願人】(591003943)インテル・コーポレーション (1,101)
【Fターム(参考)】
【公開日】平成24年7月12日(2012.7.12)
【国際特許分類】
【出願番号】特願2012−70(P2012−70)
【出願日】平成24年1月4日(2012.1.4)
【分割の表示】特願2009−516853(P2009−516853)の分割
【原出願日】平成18年7月3日(2006.7.3)
【公序良俗違反の表示】
(特許庁注:以下のものは登録商標)
1.フロッピー
【出願人】(591003943)インテル・コーポレーション (1,101)
【Fターム(参考)】
[ Back to top ]