
2次元図形マッチング方法
【課題】逐次性を有する高速な2次元図形マッチング方法を提供することを目的とする。
【解決手段】入力地図および参照地図に新たな点を挿入し(S102,S108)、入力地図および参照地図の局所特徴を抽出し(S104,S110)、抽出された参照地図の局所特徴を記憶し(S112)、抽出された入力地図内の局所特徴の一つをクエリとし、類似する参照地図内の局所特徴を検索し(S114)、検索結果から解候補としての仮説を含む仮説集合を生成し(S116)、仮説集合に含まれる各仮説の確からしさを評価する(S118)。この際、参照地図の局所特徴のLSH関数によるハッシュ値に対応するビンに記憶し(S112)、クエリに関する局所特徴のLSH関数によるハッシュ値に対応するビンを検索し(S114)、点と仮説との対である点仮説ペアを評価する順序を計画し(S118a)、最良の仮説を選出する(S118b)。
【解決手段】入力地図および参照地図に新たな点を挿入し(S102,S108)、入力地図および参照地図の局所特徴を抽出し(S104,S110)、抽出された参照地図の局所特徴を記憶し(S112)、抽出された入力地図内の局所特徴の一つをクエリとし、類似する参照地図内の局所特徴を検索し(S114)、検索結果から解候補としての仮説を含む仮説集合を生成し(S116)、仮説集合に含まれる各仮説の確からしさを評価する(S118)。この際、参照地図の局所特徴のLSH関数によるハッシュ値に対応するビンに記憶し(S112)、クエリに関する局所特徴のLSH関数によるハッシュ値に対応するビンを検索し(S114)、点と仮説との対である点仮説ペアを評価する順序を計画し(S118a)、最良の仮説を選出する(S118b)。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、点列で構成された2次元図形の位置合せをする2次元図形マッチングに関するものである。
【背景技術】
【0002】
点列で構成された2次元図形の位置合せをするマッチングに関し、各種技術(研究成果)が開示されている。例えば、入力図形及び参照図形のそれぞれに対して、図形上の線分あるいは点列から、接線方向あるいは法線方向を付加した点を所定の間隔で選択し、該選択点の位置と方向から定義される基底を用いて、該選択点の周囲に存在する他の選択点の位置と方向を座標変換し、該座標変換後の他の選択点の集合を該選択点のインデックスとして用いて幾何学的ハッシュ法を行い、入力図形と参照図形がマッチする相対位置姿勢の候補を求める線図形マッチング方法が提案されている(例えば、特許文献1参照)。
【0003】
また、逐次型マップマッチングと呼ばれる技術も提案されている(例えば、特許文献2参照)。さらに、2次元図形として地図を対象とした移動ロボット用地図作成システムも提案されている(例えば、特許文献3参照)。
【0004】
この他、大規模地図でのマップマッチングに関し、RANSAC(RANdom SAmple Consensus)に基づくマップマッチングの有効性が確認されている(例えば、非特許文献1参照)。なお、本出願の発明者においても、2次元図形に関するマッチングについて、幾つかの研究成果を報告している(例えば、非特許文献2〜4参照)。
【先行技術文献】
【特許文献】
【0005】
【特許文献1】特開2005−174062号公報
【特許文献2】特開2008−39698号公報
【特許文献3】特開2004−276168号公報
【非特許文献】
【0006】
【非特許文献1】Neira J., Tardos J.D., and Castellanos J.A. Linear time vehicle relocation in slam. IEEE International Conference on Robotics and Automation, 1:427-433, 2003.
【非特許文献2】Tanaka K. and Eiji K. A scalable algorithm for monte carlo localization using an incremental e2lsh-database of high dimensional features. IEEE Int. Conf. Robotics and Automation, pages 2784-2791, 2008.
【非特許文献3】Tanaka K and Kondo E. Incremental ransac for online vehicle relocation in large dynamic environments. Proc. IEEE Int. Conf. Robotics and Automation (ICRA), pages 1025-1030, 2006.
【非特許文献4】Takeshi Ueda and Kanji Tanaka. On the scalability of robot localization using high-dimensional features. IAPR International conference on pattern recognition, pages 1-4, 2008.
【発明の概要】
【発明が解決しようとする課題】
【0007】
近年、SLAM(Simultaneous Localization And Mapping)技術の進展により、移動ロボットのセンサデータ群を集約し大規模環境のランドマーク地図をリアルタイムに生成することが可能になってきた。それにともない、大規模地図を複数ロボット間で共有するセンサネットワークやロボットGISなどの試みがなされている。これらの枠組みに共通して、ロボットが地図上での自己位置を推定することは、最も基本的なタスクとなる。
【0008】
本発明は、以上を踏まえ、自己位置推定問題を対象とする。これまで様々な自己位置推定問題の研究がなされてきたが(例えば、上記非特許文献1参照)、それらの多くは、地図を所与とし、オフラインで地図データを構造化していた。これに対し、上記のように、最新の環境情報を反映してリアルタイムに構築・改変することのできる地図(以下、逐次型地図/2次元図形の一例)の需要が高まっている。
【0009】
本発明は、逐次性を有する高速な2次元図形マッチング方法を提供することを目的とする。
【課題を解決するための手段】
【0010】
上記課題に鑑みなされた本発明は、入力2次元図形に新たな点を挿入し、入力2次元図形の局所特徴を抽出し、参照2次元図形に新たな点を挿入し、参照2次元図形の局所特徴を抽出し、抽出された参照2次元図形の局所特徴を記憶し、抽出された入力2次元図形内の局所特徴の一つをクエリとし、記憶された参照2次元図形内で、クエリに関する局所特徴と類似する参照2次元図形内の局所特徴群を検索し、検索結果から解候補としての仮説を含む仮説集合を生成し、仮説集合に含まれる各仮説の確からしさを評価することとしたものである。
【0011】
この際、抽出された参照2次元図形の局所特徴を、LSH関数でハッシュ値に変換し、当該ハッシュ値に対応するハッシュ表の全てのビンに参照2次元図形の局所特徴を関連付けて記憶し、抽出された入力2次元図形内の局所特徴を、LSH関数でハッシュ値に変換し、当該ハッシュ値に対応するハッシュ表のビンにアクセスし、ハッシュ表中で入力2次元図形内の局所特徴に対応する局所特徴群を検索する。また、点と仮説との対である点仮説ペアの当該仮説のスコア値を計算し、計算されたスコア値に基づき、点仮説ペアを評価する順序を計画し、最良の仮説を選出する。
【0012】
本発明を反映した第1の課題解決手段は、点列で構成された2次元図形の位置合せをする2次元図形マッチング方法であって、入力2次元図形および参照2次元図形に新たな点を挿入する図形更新工程と、前記入力2次元図形および前記参照2次元図形各々の局所特徴を抽出する特徴抽出工程と、前記特徴抽出工程によって抽出された前記参照2次元図形の前記局所特徴を記憶する記憶工程と、前記特徴抽出工程によって抽出された前記入力2次元図形内の前記局所特徴の一つをクエリとし、前記記憶工程で記憶された前記参照2次元図形内で、前記クエリに関する前記局所特徴と類似する前記参照2次元図形内の局所特徴群を検索する検索工程と、前記検索工程での検索結果から解候補としての仮説を含む仮説集合を生成する仮説生成工程と、前記仮説集合に含まれる各仮説の確からしさを評価する仮説評価工程とを有し、前記記憶工程は、前記特徴抽出工程によって抽出された前記参照2次元図形の前記局所特徴を、LSH関数でハッシュ値に変換し、当該ハッシュ値に対応するハッシュ表の全てのビンに前記参照2次元図形の前記局所特徴を関連付けて記憶し、前記検索工程は、前記特徴抽出工程によって抽出された前記入力2次元図形内の前記局所特徴を、LSH関数でハッシュ値に変換し、当該ハッシュ値に対応する前記ハッシュ表の前記ビンにアクセスし、前記ハッシュ表中で前記入力2次元図形内の前記局所特徴に対応する前記局所特徴群を検索し、前記仮説評価工程は、点と仮説との対である点仮説ペアの当該仮説のスコア値を計算し、計算された前記スコア値に基づき、前記点仮説ペアを評価する順序を計画する順序ルール工程と、前記順序ルール工程で計算された前記スコア値に基づき更新された、前記仮説の前記スコア値の履歴をもとに、最良の仮説を選出する選択ルール工程とを有することを特徴とする2次元図形マッチング方法である。これによれば、逐次的に高速な2次元図形のマッチングを実行することができる。
【0013】
第2の課題解決手段は、第1の課題解決手段の2次元図形マッチング方法であって、前記仮説評価工程は、前記履歴が悪い仮説を、前記仮説集合から除外し、前記仮説集合が所定のサイズに納まるようにすることを特徴とする。これによれば、仮説集合のサイズを所定のサイズに納めることができる。
【発明の効果】
【0014】
本発明によれば、逐次性を有する高速な2次元図形マッチング方法を得ることができる。
【図面の簡単な説明】
【0015】
【図1】RANSACマップマッチングを説明する図である。
【図2】マップマッチングシステムを説明する図である。
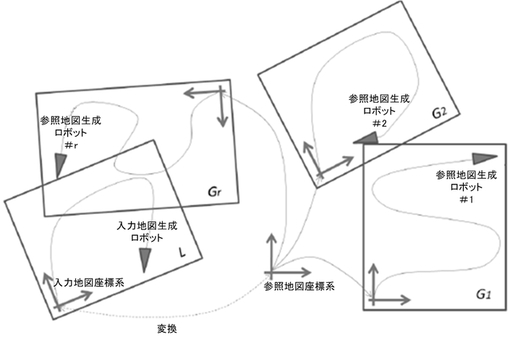
【図3】ロボットの作業環境の例を示す図である。
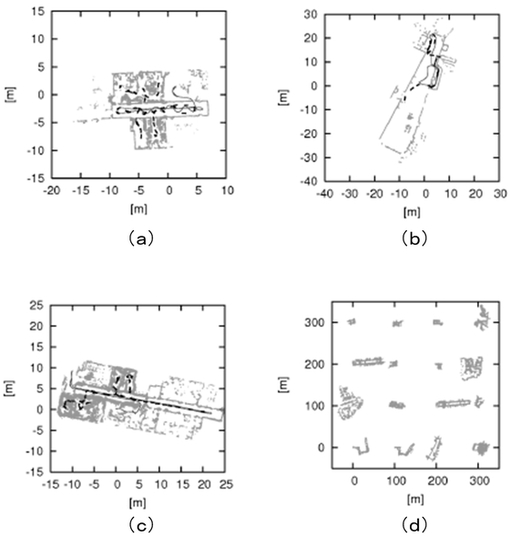
【図4】時間コストを示す図である。
【図5】最良仮説を生成するのに用いた基底(局所特徴)を時間の流れに沿って示した図である。
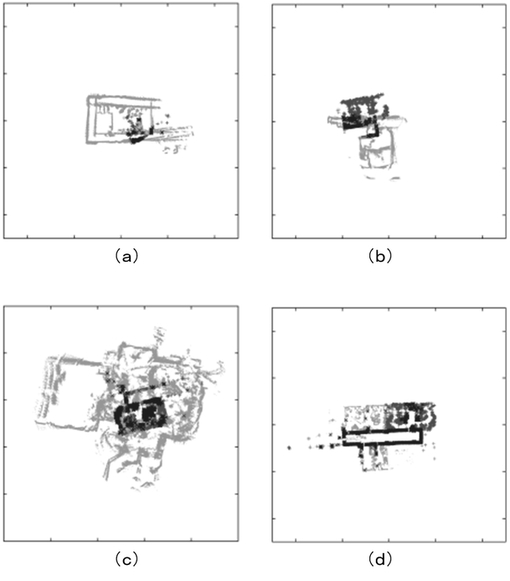
【図6】自己位置推定の様子を表す図である。
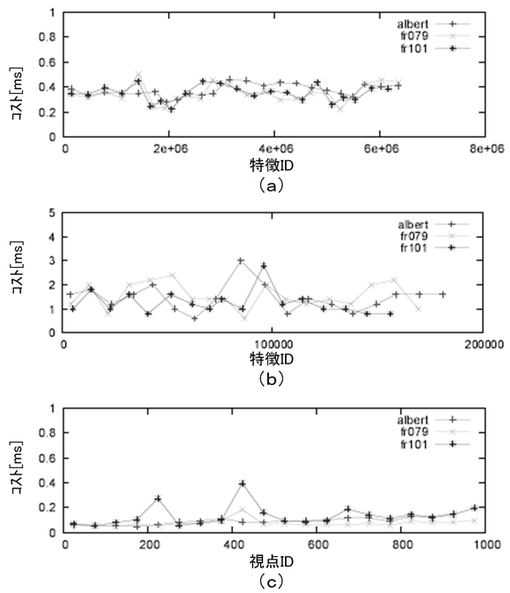
【図7】各時刻の最良仮説についてスコアと順位(ランク)が変化していく様子を追跡した図である。
【図8】自己位置推定の性能を示す図である。
【図9】LSHパラメータに対する感度を要約した図である。
【図10】マップマッチングシステムの機能ブロックを示す図である。
【図11】マップマッチングシステムで実行される処理のフローチャートを示す図である。
【発明を実施するための形態】
【0016】
本発明を反映した上記課題解決手段を実施するための実施形態について、図面を用いて以下に詳細に説明する。上記課題解決手段は、以下に記載の構成に限定されるものではなく、同一の技術的思想において種々の構成を採用することができる。例えば、以下に説明する各構成において、所定の構成を省略することもできる。
【0017】
(本実施形態の位置付け)
本実施形態の説明に先立ち、まず、本実施形態の位置付けについて説明する。なお、以下では、2次元図形として、地図を例に説明する。
【0018】
一般に、自己位置推定のアプローチには、外見ベースの方法と位置ベースの方法がある。この内、外見ベースの方法は、ランドマークの外見を色・模様などの高次元特徴(例:SIFT, shape context)により表現する。そして、地図生成時に、各ランドマークの外見を位置と関連付けて地図データベースに登録しておく。その上で、自己位置推定時に、ロボット周辺で観測されたランドマークと類似するものを地図中から検索し、自己位置を絞り込む。これは、大規模地図を高速に検索し、自己位置を大きく絞り込むのに有効な方法といえる。一方、位置ベースの方法は、自己位置推定時、ロボット周辺で観測された局所的なランドマーク配置を直接、地図と照合し、自己位置を絞り込む。これは、多数のランドマークを利用して詳細に自己位置を絞り込むのに有効な方法といえる。以上のように、2つの方法にはそれぞれ異なる長所があり、両者を融合する方法が注目されている。本発明は、この融合方法に分類される。
【0019】
本出願の発明者らは、上記非特許文献2において、逐次型地図に有効な外見ベース手法を開発した。従来、多くのシステムでは、全ての特徴を一括して構造化・インデクス付けするバッチ型の地図データベース(例:kd-tree法)が用いられた。これに対し、発明者らは、ハッシュ技術に基づく地図データベースを構成した。ハッシュ表は、木構造など他の多くのデータベース構造と異なり、データの挿入・削除を逐次的・高速に行うことができる。この点を利用し、非特許文献2では、逐次型地図に有効なLSH(Locality Sensitive Hashing)に基づく地図データベースを提案した。
【0020】
一方、発明者らは非特許文献3において、逐次型地図に有効な位置ベース手法を開発した。一般に、大規模地図に有効な位置ベース法として、ロボット周辺地図(局所地図)と参照地図との位置合せを行うマップマッチング法が知られている。上述したとおり、特に、RANSAC(RANdomSAmple Consensus)に基づくマップマッチングは大規模地図での有効性が確認されている。しかし、これらは、所与の地図を前提とし、逐次型地図を扱うことができなかった。これを踏まえ、非特許文献3では、逐次型地図に有効なiRANSAC(incremental RANSAC)と呼ぶ逐次型のRANSAC手法を提案した。
【0021】
従来の方法は、位置ベース法および外見ベース法としては素朴な方法を用いていた。本実施形態では、両者を融合し、LSH-RANSACと呼ぶ、外見ベース法および位置ベース法の両面に優れる方法を提案する。なお、本実施形態と同様、LSHとRANSACを融合するアプローチとして、エピポーラ幾何、形状マッチング、画像検索など、近年、重要な研究事例がある。しかし、従来、LSHを逐次型データベースとして利用する事例は少なかった。また、逐次型のLSH-RANSACや自己位置推定への応用事例はなかった。
【0022】
また、コンピュータビジョン分野の場所認識(location recognition)問題においても、最近、階層型k-meansなど、大規模地図に有効な方法が開発されている。しかし、それらの殆どは、地図データベースをオフラインで構築しており、逐次型地図を扱うことができない。また、SLAM分野の閉ループ(loop closure)問題においては、逐次型地図を用いた場所認識が研究される。しかし、この問題では、自己位置の追跡結果を事前知識として利用しており、本問題のような、自己位置が完全に未知の状況を扱ってはいない。
【0023】
また、外見ベース法に関連して、PCAや視覚語彙(visual vocabulary)など翻訳関数を用いて、高次元の外見特徴を視覚単語(visual word)などコンパクトな低次元データに予め翻訳しておく方法が知られている。しかし、これらの方法は、人為的な訓練環境、あるいは、ロボットが過去に訪れた別の環境において、翻訳関数を機械学習しておくことを前提にしている。従って、教示の必要性や訓練環境への過学習など、未知環境への適応性の面で課題が残る。
【0024】
一方、本実施形態の提案方法は、翻訳関数などの事前学習を前提としない点で、従来のハッシュ技術に基づく物体分類手法に似ている。従来では、高次元の特徴空間を規則的な格子で分割し、各格子点に固有の物体クラスを考える。その結果、クラス数が膨大となるが、それらをハッシュ表を用いて管理し、最先端の検索速度と精度を実現している。ただし、基本的に単一視点での物体分類問題を対象としており、本実施形態の自己位置推定問題のような、多視点での問題は検討がなされていなかった。
【0025】
また、位置ベース法に関連して、ロバスト推定RANSACは、コンピュータビジョン分野の標準方法として広く用いられている。特に、近年、randomized RANSACと呼ばれる様々な亜種が提案されている。これらの多くは、主に、与えられた目標精度を、できるだけ短い計算時間で達成することを目的とする。これに対し、preemptive RANSAC(pRANSAC)は、与えられた計算時間で、できるだけ高い推定精度を達成することを目的とする。これは、SLAMなどリアルタイム応用に適した考え方といえる。本実施形態のiRANSACは、このpRANSACを逐次型へと拡張したものである。
【0026】
(マップマッチング)
次に、基本的なRANSACマップマッチングについて、図1に基づき説明する。ここでは、簡単のため、ロボット周辺地図Lおよび参照地図Gが時間とともに変動しないものと仮定する。いま、R台の地図生成ロボットID=1,・・・,Rがいるものとし、各々のロボットが生成する地図をG={G1,・・・,GR}とする。このとき、本問題の目的は、地図Lを並進回転ψさせたときに最も大きく重なり合うような地図Grを見つけ、その最大重なりを与える座標変換ψを求めることにある。その解法として、我々は、標準的なRANSACマップマッチングを基礎とし、pRANSACスキームを用いた高速化を行う。これらのRANSACマップマッチングおよびpRANSACについて以下に説明する。
【0027】
(RANSACマップマッチング)
一般的なRANSACアルゴリズムを以下に示す。いま、N個のデータ点があるものとし、これらを集合U={xi}により表す。また、集合Uの部分集合Sをもとに、後述の方法により、モデルパラメータpを算出する関数(モデル関数)をfm:S→pとする。また、モデルパラメータpの一つのデータ点で1つのデータポイントxに対しコスト関数ρ(p,x)を定義する。このコスト関数は、xがモデルに対して整合する(インライア)ならば1を取り、それ以外では0を返す。このとき、RANSACによるパラメータ推定の目的は、コスト関数を最大限にするモデルパラメータp*およびそれを与えるコストC*を探索することにある。具体的には、RANSACアルゴリズムは、信頼できる仮説が見つかるまで、次のステップ(1)〜(3)を繰返す。
(1)部分集合Sk⊂Uをランダムに選択し、モデルパラメータ仮説pk=fm(Sk)を算出する。
(2)コストCkを求める。コストCkは、以下の式(1)によって算出される。
【数1】

(3)もしCk>C*ならばC*←Ck,p*←pkとする。
【0028】
このRANSACアルゴリズムは、直接にバッチ型マップマッチング問題に適用することができる。この問題設定においては、地図Lの特徴数をNと解釈する。また、地図L上の特徴をx、地図Lから地図Grへの変換をpと解釈する。変換pの下で、もし地図Lの特徴点xが地図G上の特徴点にマッチするならば、コスト関数ρ(p,x)は1を取り、そうでなければ、0を取る。またモデル関数fmは、L(Shape Contextのような)のローカル特徴からGのグローバル特徴への変換を表す。
【0029】
(pRANSACスキーム)
RANSACのさらなる高速化のために、rRANSACと呼ばれるRANSACの亜種が提案されており、それらの亜種の中でも、本実施形態では、リアルタイム性に優れるpRANSACを用いる。pRANSACの概要を以下に示す。pRANSACは、ある時点までに評価された全ての特徴仮説ペア(pj,xj)、および対応する得点結果
Cj=ρ(pj,xj)・・・(2)
の過程
H={(pj,xj,Cj)}・・・(3)
を保持し、これをもとに、各時点の処理を行う。また、2種類のユーザ定義関数、順序ルール
(p,x)=fo(H)・・・(4)
および選択ルール
p*=fp(H)・・・(5)
を用いる。順序ルールは、履歴Hが与えられたときに、次にどの特徴仮説ペアを評価すべきかを決定する。選択ルールは、履歴Hをもとに、最もよい仮説を選び出す。いま、ある特徴集合
U={xi}・・・(6)
および、仮説集合
V={pj}・・・(7)
が与えられたものとすると、pRANSACは、計算時間の許す限り次のステップ(1)および(2)を繰り返す。なお、ステップ(1)(以下、「pRANSACのステップ(1)」ともいう。)は、図11のフローチャートのS118aに相当する処理である。また、ステップ(2)(以下、「pRANSACのステップ(2)」ともいう。)は、同処理フローのS118bに相当する処理である。
(1)特徴仮説ペア(pk,xk)=fo(H)を選択し、スコアρ(pk,xk)を計算する。
(2)得点結果に基づき、特徴仮説ペアの当該仮説のスコア値の履歴Hを更新する。必要に応じて、最良の仮説p*=fp(H)を出力する。
【0030】
(幅優先ルール)
pRANSACの性能は、主に順序ルールfo(H)に依存する。ここで、プリエンプティブ(preemptive)幅優先ルールと呼ばれる順序ルールは、いくつかの魅力的な特性がある。第1に、その計算時間は、仮説集合サイズに比例した定数により制限される。第2に、評価は、ある絶対的な品質尺度ではなく仮説間の競合によって行われる。第3に、インライア・アウトライア・モデルという簡略化されたモデル下であるが、安定した性能が解析的に示されている。以下に、幅優先スキームに基づくpRANSACの概要を手短に示す。
【0031】
計算時間を節約するために、単調減少のプリエンプティブ関数fb(i)(p関数)を用いて、評価対象となる(アクティブな)仮説の数を制限する。このp関数は、まず、仮説ID1,・・・,Nおよび、特徴ID1,・・・,Mをランダムに並び替える。また、各々の仮説について、j(1≦j≦M)スコア値をCj=0に初期化する。そして、計算時間がなくなるまで、以下、ステップ(1)および(2)を繰返す。なお、ステップ(1)(以下、「幅優先ルールのステップ(1)」ともいう。)は、図11のフローチャートのS118に相当する処理である。また、ステップ(1)および(2)は、(以下、ステップ(2)について「幅優先ルールのステップ(2)」ともいう。)は、履歴Hが悪い仮説を、仮説集合から除外し、仮説集合が所定のサイズに納まるようにするための処理である。ステップ(2)は、各時刻(所定のタイミング)において、実行される。
(1)仮説j(1≦j≦fb(i))ごとにスコア値Cj←Cj+ρ(pj,xi)を算出する。
(2)仮説ID1,・・・,Nを整理し、スコア値Gjがトップfb(i)の中に納まるようにする。p関数fb(i)を式(8)に示す。
【数2】
Bは予め設定された定数である。
【0032】
このBは、「ブロックサイズ」と呼ばれる。以上の処理で、B回繰返すたびに仮説集合のサイズが半分になる。結果として、全体の時間コストは、O(BM)となる。
【0033】
(逐次型LSH-RANSACスキーム)
これまで、発明者らは、特徴と仮説の集合が固定されたバッチ問題を考えてきた。しかし、実際には、ロボットの自己位置推定タスクでは、特徴集合と仮説集合が逐次的に変化していく。このことを理解するために、我々は、典型的な自己位置推定タスクを以下に素描する。自己位置推定タスク中、自己位置推定プロセス(つまりマップマッチングプロセス)は最新のセンサデータを取り入れながら常に最良の解を探し続ける。自己位置推定プロセスは、自己位置推定タスクの始めにスタート視点で一度だけ初期化されて、空集合から始まる。その後、これらの集合および地図は、以下の2種類のイベントにより修正されていく。なお、第1イベントでの(a)は、図11のフローチャートのS100に相当し、(b)は、S102に相当し、(c)は、S114に相当し、(d)および(e)は、S116に相当する処理である。また、第2イベントでの(f)は、S108に相当し、(g)は、S110に相当し、(h)は、S112に相当する処理である。
(第1イベント)
(a)入力地図(局所地図)更新
(b)入力地図に新規特徴が追加される
(c)新規特徴を用いて外見データベースに検索質問(クエリ)を行う
(d)検索結果をもとに新規仮説を生成する
(e)仮説集合に新規仮説を追加する
(第2イベント)
(f)参照地図(大域地図)更新
(g)参照地図に新規特徴が追加される
(h)新規特徴を外見データベースに追加する
【0034】
以上のことから、リアルタイム自己位置推定問題を実現するためには、以下の2点が重要となる。第一に、仮説の数Mが無制限に成長するとともに、問題サイズはO(BM)の複雑さで増加し、効率的なpRANSACを用いても手に負えなくなる。これに対処するために、本実施形態では、外見特徴を手掛かりとし少数(例えば1,000個)の確からしい仮説のみを生成する。特に、本実施形態では、地図生成タスクにおいて、逐次的に構築・改変することのできる逐次型の外見データベースを提案する。
【0035】
第二に、マップマッチングに用いる入力地図(局所地図)および参照地図(大域地図)を逐次的に更新することが求められる。これに対処するために、本実施形態では、マップマッチングタスク中に新規の特徴を追加することのできる逐次型RANSAC(iRANSAC)スキームを応用する。特に、多くの生き残っている仮説(アクティブな仮説)を扱いやすいサイズに抑えるために、本実施形態では、プリエンプティブ幅優先ルールを逐次型へと拡張する。以下では、さらに詳細に上述の考えを実行する方法を説明する。
【0036】
(外見データベース)
外見データベースは、Locality Sensitve Hashing(LSH)に基づき構築する。LSHは、高次元空間中の或る質問点に対し、データベース中から近傍にある点を探索する。特に、E2LSH(Exact Euclidean Locality Sensitive Hashing)は、(R, cR)-Near Neighbor問題を扱う。これは、データベース点がqから距離Rの範囲内であるならば、ゴールは質問qから距離cRの中の点を返す、という性質を持つANN技術である。E2LSHはある近似ファクタρ(c)<1に対しO(nρ(c)log n)時間コストであり、他のANNアルゴリズムと比べても高速であることが示されている。本実施形態が、LSHを利用するもう一つの理由は、LSHがハッシュ表に基づく点にある。ツリーのような他のデータ構造とは異なり、ハッシュテーブルに基づく構造では、データベース要素の挿入/削除が頻繁かつ逐次的に行えるという利点がある。まず、LSHは、前処理において、K次元を備えたLハッシュ関数はp-stable分布(例えば正規分布)を用いて、確率的に生成する。そして、新しい特徴が参照地図(大域地図)に追加されるとき、以下のステップ(1)〜(3)によりデータベースを更新する。なお、新しい特徴が参照地図(大域地図)に追加されるとき(図11のフローチャートのS106:Yes参照)に実行される、ステップ(1)〜(3)は、図11のフローチャートのS112に相当する処理である。
(1)特徴の実世界位置を記憶する
(2)E2LSH関数により特徴をハッシュし、対応するビンにアクセスする、
(3)特徴の実世界位置とビンを関連付ける
【0037】
ただし、高次元特徴の本体を記憶すると、特徴次元に比例した膨大な空間コストがかかるので、特徴本体は忘却するものとし、ハッシュ値のみを記憶する。これは、単純な工夫だが、データベースの空間・時間コストを大幅に削減することが知られている。発明者らは、上記非特許文献2において、この手法をモンテカルロ自己位置推定に適用し、その性能を検証している。以上からも分かるように、データベースの更新手続きは、完全に逐次的に行うことができる。
【0038】
特徴の実世界位置はグリッドマップ上に記憶する。ただし、これを直接に行うと、大規模環境では、グリッドマップのセル数が膨大となり、記憶容量が不足するという問題がある。そこで、我々は、一次元ハッシュ表に、実世界位置を写像する普遍ハッシュ関数(UH)を利用する。一般に、適切なハッシュ表のサイズは、環境サイズ・特徴数に依存するが、衝突確率が十分に低くなるように設定するものとする。これは、衝突が生じるたびに、一つの特徴が誤った実世界位置にあると信じることになり、多数の衝突が生じると誤認識の危険性が高まるからである。現在の実装では、グリッドマップの空間コストに対し、近似されたハッシュ表のサイズの比率は、0.03である。なお、衝突確率は、この比率以下となることが保証される。
【0039】
(マップマッチング)
iRANSACアルゴリズムを以下に要約する。タスクの始めに、特徴集合および仮説集合を空集合U←φ,V←φへと初期化する。そして、タスク中、次のステップ(1)〜(3)を繰り返す。なお、ステップ(1)は、図11のフローチャートのS102に相当し、ステップ(2)は、S116に相当し、ステップ(3)は、S118に相当する処理である。
(1)新規特徴Unewが到着したとき、特徴集合をU←Unew∪Uのように修正する
(2)新規仮説Vnewが到着したとき、仮説集合をV←Vnew∪Vのように修正する
(3)pRANSACのステップ(1)および(2)(上記「(pRANSACスキーム)」の項参照)を実行する。
【0040】
幅優先ルールを逐次型へと修正し用いる。これは、繰り返しiごとに次のステップ(1)および(2)を実行する処理となる。なお、ステップ(2)は、履歴Hが悪い仮説を、仮説集合から除外し、仮説集合が所定のサイズに納まるようにするための処理である。
(1)iRANSACアルゴリズムのステップ(1)および(2)(この「マップマッチング」の項に記載の上記ステップ(1)および(2)参照)を実行する
(2)オリジナルの幅優先ルールのステップ(1)および(2)(上記「(幅優先ルール)」の項参照)を実行する。その際、式(9)の形式のプリエンプティブ(Preemption)関数fb(i)を用いる。
【数3】
ただし、m(i)は、i番目の繰り返しが終了した時点での仮設数を表す。
【0041】
選択ルールにも、少しだけ修正を加える。逐次的な問題設定では、仮説の評価数が仮説間で大きく異なりうる。若い仮説は、古いものより短い時間で不当に高い評価を得る可能性がある。そこで、公正な比較のために、単純にスコア値Cjを評価するのではなく、正規化されたスコア値Cj/Njを評価する。さらに、最良の仮説を選ぶ際、スコア値が閾値Coより小さい若い仮説は候補とみなさない。
【0042】
以上のように修正を加えた幅優先ルールは、仮説集合が固定の場合には、オリジナルの幅優先ルールに縮退する。また、一般に、完全にランダムに並び替えた特徴列・仮説列を用いることで、RANSACのパフォーマンスが確率的に最大化することができることが知られている。しかし、逐次的な問題設定では特徴列・仮説列は、出現順序の影響を受けるため、この完全ランダムな並び替えは不可能となる。また、並び替え済みの列Uが与えられているとき、新しい要素UnewをUに加えたいのであれば、その処理は、列Uのランダムに選択した箇所にUnewの各要素を挿入する処理となり、O(|Unew|)の計算量で実行できる。
【0043】
(システムの有効性)
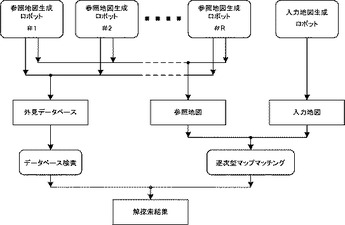
本実施形態のシステム(マップマッチングシステム)の有効性を検証するため、自己位置推定の実験を行ったので、以下、本実施形態のシステム構成および実験結果について説明する。まず、本実施形態のシステムについて図2に基づいて説明する。本実施形態のシステムでは、環境内に複数台の参照地図生成ロボット#1,・・・,#Rおよび入力地図生成ロボットが在る。参照地図生成ロボットが取得した点を参照地図に挿入する。また、参照地図生成ロボットが取得した外見特徴を外見データベースに登録する。また、入力地図生成ロボットが観測した点を入力地図に挿入する。また、外見データベースの検索結果、および、入力地図と参照地図との逐次型マップマッチング結果をもとに、有望な位置合せの候補を探索する。
【0044】
次に、実験結果について説明する。本実験では、radishデータセットを用いる(図3参照)。本データセットは、運動および知覚のセンサデータ列からなる。各運動データは、ある視点から次の視点までのロボットの運動を観測したものである。参考までに、本システムでは、運動データのフォーマットとして、前進・横進・回転(FSR)フォーマットを採用した。各認識データは、前部レーザースキャナによる1回の走査であり、観測ごとに、ロボット中心座標系の180個のデータ点を取得する。また、外見特徴として、レーザデータ点に一般的な、形状特徴を用いる。特に、上記非特許文献2および3において安定性が示されたgeneralized shape context(GSC)を用いる。また、SLAM手法として、単純なスキャンマッチングアルゴリズムを用いる。各観測ごとの新規特徴および新規仮説の数はそれぞれ|Unew|=10および|Vnew|=1,000に設定する。pRANSACスキームに使用するブロックサイズは、B=|Unew|に設定する。LSHのパラメータは、経験的にK=30、L=20に設定する。
【0045】
本実施形態では、典型的なシナリオとして、R台の参照地図生成ロボット(マッパーロボット)がR個の異なる建物を探索している状況を考える。ロボットには、自分がどの建物にいるか、また、建物中でどこにいるのか、について事前知識は与えられない。サブマップGr(1≦r≦R)は、それぞれ、地図構築タスクの開始時に、空の地図へと初期化される。地図は、タスク中に地図生成ロボットにより逐次的に構築される。新規スキャンが到着するたびに、外見特徴群をスキャン点群から抽出する。そして、抽出した特徴を外見データベースに追加し参照地図を更新する。図4(a)に、3つの異なる環境「albert」、「fr079」と「fr101」を用いて、異なるサイズのグローバルマップそれぞれについて、特徴1つ当たりの更新プロセスによって消費された時間を示す。時間コストは地図サイズに依存せず、一定以下となっていることが分かる。参照地図(大域地図)を構成する一つ一つのサブマップを直接に実装すると、3次元xyθ姿勢空間でおよそ2.1×107のセルを消費した。これに対し、上述のハッシュ表による近似表現を用いると全体でおよそ3.4×108のセルとなり大幅に空間コストを削減できた。本実施形態のシステムでは、グリッド地図からサイズ1×107ビンのUH(普遍ハッシュ関数)テーブルに変換する。UHテーブルのサイズは、元のグリッド地図の3%未満となる。LSHデータベースによって消費されたLSHテーブルはこの実験で高々7.2×106ビンとなる。以上のことから、我々のデータ構造が完全に逐次的であり、大規模地図に有効であることが分かる。
【0046】
図5および図6は自己位置推定の結果を表す。自己位置推定タスクの開始時に、局所地図を空地図へと初期化する。新規スキャンが到着するたびに、外見特徴群をスキャン点群から抽出し入力地図(局所地図)を更新する。その後、一セットの外見特徴をスキャン点群から抽出する。その後、各特徴を検索質問として外見データベースを検索する。その検索結果に基づいて、新規仮説を生成する。図4(b)は、時間コストを示している。上述したように、検索処理の時間コストは実際に一定値以下となっている。図6(a)〜(d)にマップマッチングの流れの例を示す。図6(a)〜(c)は、未だマッチングに成功していない状況を表している。この内、図6(a),(b)は、入力地図(局所地図)が未だ十分な情報量を持たないか、あるいは、疎な状況であり、その結果として、全てのマッチング仮説が信頼できない状況にあった。これに対し、図6(c)では、入力地図の大部分が、参照地図(大域地図)に記されていない未知領域にあり、その結果として、誤った仮説が不当に高い一致度を得ていた。これは、例えば、入力地図を誤った建物とマッチングするなどの誤りである。図6(d)は、最終的にマッチングに成功した状況を表している。ここでは、入力地図が十分な情報量を持っており、かつ、入力地図の大きな部分が参照地図中で既知の領域を含んでいる。図4(c)は、マップマッチング処理による時間コストも一定以下に抑えられている様子を表している。重要な点として、時間コストは地図データベースのサイズに依存していない。
【0047】
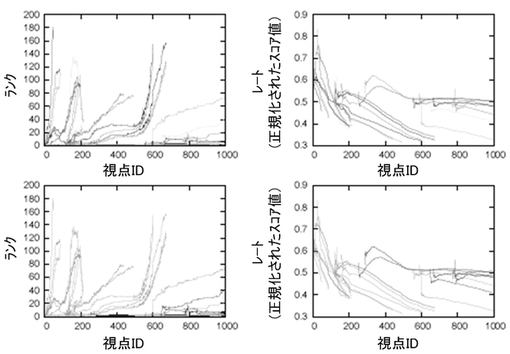
図7に評価の様子を説明する。説明のために、「ランク」という概念を導入する。これは、仮説群をスコア値が高いものから順に並べたときの各仮説の順位のことであり、仮説間の相対的な重要度を表している。ただし、全ての仮説についてランクをプロットすると煩雑となるため、少なくとも一回はトップランク(つまり、ランク1が割り当てられた)された仮説のみをプロットした。ここでは、多数のデータ点群と整合性ある良質な仮説は、優先的に評価対象として選ばれる傾向がある。一方、ノイズにより汚染された良質でない仮説群は、すぐに除去される傾向がある。良い仮説が一度高いランクとなれば、長い期間、高位グループにとどまる傾向がある。また、典型的なrRANSACスキームとの重要な差異として、本スキームでは、仮説の割合およびランキングは、ロボットがナビゲーションするとともに減少する傾向がある。その理由は、オドメトリ誤差の蓄積により、局所地図と新規データ点との整合性が悪くなっていく傾向があるためである。結果として、新旧の仮説は、プリエンプション(preemption)スキームの枠組みにおいて、相互に比較され、若いデータ点でサポートされるトップランクの仮説は、各視点の最良の仮説として出力される傾向がある。
【0048】
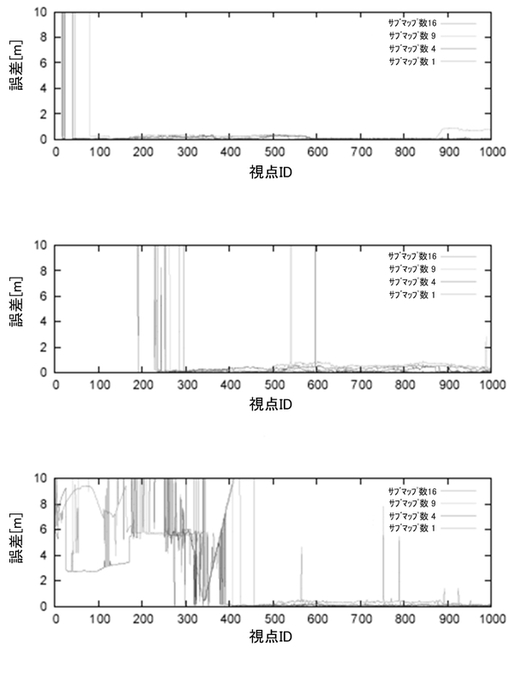
図8は、いくつかの実験を通して自己位置推定の性能を示す。ここでは、3つの異なる入力地図、および、それぞれ1,4,9,16のサブマップから構成される4つの異なるサイズの大域地図からなる、全12通りの実験を行った。図3(a)〜(c)に各実験結果を要約する。ここでは、対象ロボットは、地図生成ロボットの16個の建物のうちのどれか一つを移動しているものと仮定する。この仮定の下では、一つのセンサデータ列から対象ロボットと地図生成ロボットのためのセンサデータ列を取り出すことが必要になる。その際は、2つのロボットが使用するセンサデータ部分列が互いに重なり合わないように注意した。図8に実験結果を示す。まず、図8(b)および(c)では、自己位置推定タスクの初期に推定がうまくいっていないことが分かる。これは、対象ロボットのスタート地点が参照地図に記されていない未知領域中にあったことに起因している。しかし、全ての実験において、最終的に自己位置推定の誤差は、1mよりも小さくなっていることが分かる。特に、大域地図のサブマップ数が16の場合は、3.5×105を上回る外見特徴を含んでいる。図8では、自己位置推定タスクが16サブマップの環境でさえ成功していることが分かる。これは、完全に逐次的なシステムとしては、従来のもの(非特許文献1〜4を含む)と比べて、非常に大きなサイズの地図といえる。本実施形態の逐次的なスキームがそのような参照地図(大域地図)でさえうまくいっているのは、特筆すべき点といえる。
【0049】
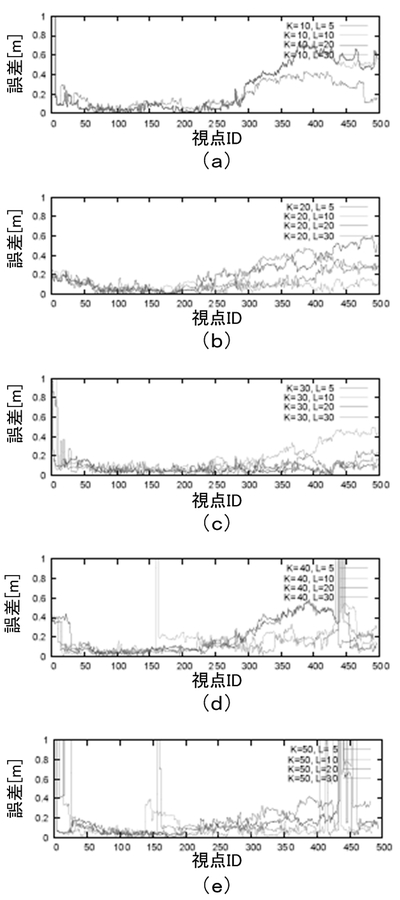
また、パラメータ感度とスケーラビリティを調査するために追加実験を行った。図9は、LSHパラメータに対する感度を要約したものである。本実施形態のシステムが広範囲のパラメータにおいて安定していることが分かる。発明者らは、また、合成したデータセットを使用することではるかに大きなグローバルマップを用いた実験を行い、発明者らの計画が40サブマップ(1.2×106の特徴)環境で成功することを確認している。上記の結果から、本実施形態のスキームは、完全に逐次的であり、大規模問題に有効であると結論することができる。
【0050】
(システムの機能ブロック)
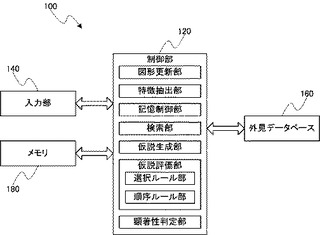
本実施形態のシステム(マップマッチングシステム)100について、図10に基づいて説明する。なお、図10に示すシステム100は、図2に示したマップマッチングシステムの処理部分を具体化して詳細に説明したものである。システム100は、制御部120と、入力部140と、外見データベース160と、メモリ180とを備える。制御部120は、上述した各種処理(後述するフローチャート参照)を実行する。具体的に、制御部120は、図形更新部と、特徴抽出部と、記憶制御部と、検索部と、仮説生成部と、仮説評価部として機能する。ここで、仮説評価部は、さらに、順序ルール部と、選択ルール部を含み、制御部120は、これら各部としても機能する。また、検索部は、ハッシュ表の各ビンに格納したハッシュ値のヒストグラムを管理する顕著性判定部を含み、制御部120は、顕著性判定部としても機能する。
【0051】
入力部140は、例えば視覚センサによって構成され、入力図形の入力を受け、これを制御部120に提供する。外見データベース160は、上述したとおりであり、その詳細は省略する。メモリ180は、例えばRAMによって構成され、制御部120による処理の実行に際し、各種データ等が記憶される領域である。
【0052】
なお、制御部120は、図10には図示されていない領域に記憶されたプログラムによって、各種処理を実行する。例えば、図11に示すフローチャートによる各種処理(制御部120によって実現される図10に示す各部による各種工程)を実行する。また、履歴Hが悪い仮説を、仮説集合から除外し、仮説集合が所定のサイズに納まるようにするための処理を実行する((上記「(幅優先ルール)」の項に記載の幅優先ルールのステップ(2)参照)。さらに、特徴抽出部によって抽出された入力地図内の局所特徴の一つをクエリとし、このクエリに関する局所特徴の顕著性を判定する。
【0053】
(システムで実行される処理)
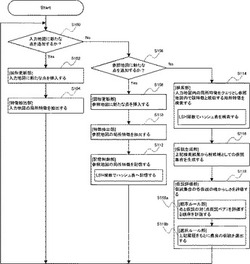
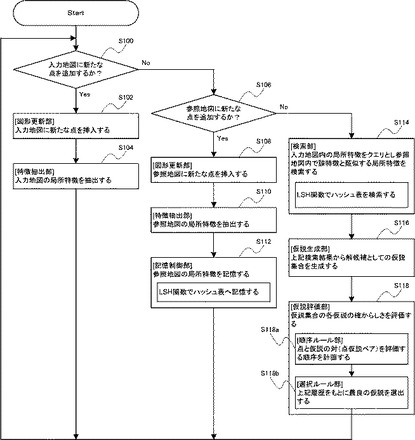
本実施形態のシステム100で実行される処理について、図11に示すフローチャートに基づき参照して説明する。この処理を開始した制御部120は、まず、入力地図に新たな点を追加するか否かを判断する(S100)。判断の結果、入力地図に新たな点を追加する場合(S100:Yes)、制御部120は、入力地図に新たな点を挿入し(S102)、入力地図の局所特徴を抽出する(S104)。そして、制御部120は、処理をS100に戻す。
【0054】
S100の判断の結果、入力地図に新たな点を追加しない場合(S100:No)、制御部120は、参照地図に新たな点を追加するか否かを判断する(S106)。判断の結果、参照地図に新たな点を追加する場合(S106:Yes)、制御部120は、参照地図に新たな点を挿入し(S108)、参照地図の局所特徴を抽出する(S110)。続けて、制御部120は、参照地図の局所特徴を、外見データベース160に記憶する。この際、制御部120は、S108で抽出された局所特徴をLSH関数によりハッシュし、対応するビンにアクセスし、この局所特徴をハッシュ表に記憶する(S112)。詳細には、S108で抽出された局所特徴をLSH関数でハッシュ値に変換し、このハッシュ値に対応するビンにアクセスし、このハッシュ値に対応するハッシュ表のビンに、この局所特徴を関連づけて記憶する。そして、制御部120は、処理をS100に戻す。
【0055】
S106の判断の結果、参照地図に新たな点を追加しない場合(S106:No)、制御部120は、入力地図内の局所特徴をクエリとし、参照地図内でクエリに関する局所特徴と類似する局所特徴(局所特徴群)を検索する(S114)。この際、制御部120は、S112と同様に、LSH関数で、外見データベースのハッシュ表を検索する。具体的に、クエリに関する局所特徴をLSH関数でハッシュ値に変換し、このハッシュ値に対応するビンにアクセスし、それらに記憶(格納)されている全ての局所特徴(局所特徴群)を出力(検索)する。
【0056】
S114を実行した後、制御部120は、S114の検索による検索結果から、解候補としての仮説を含む仮説集合を生成する(S116)。続けて、制御部120は、仮説集合に含まれる各仮説の確からしさを評価する(S118)。具体的に、制御部120は、S118でインライア判定を実行する。また、制御部120は、S118で、点と仮説との対である点仮説ペア(特徴仮説ペア)を評価する順序を計画し、計画された順序に基づき、点仮説ペアを選択し、選択された点仮説ペアの仮説のスコア値を計算するとともに、得点結果(計算されたスコア値)に基づき、当該仮説のスコア値の履歴Hを更新する(S118a)。その上で、制御部120は、得点結果に基づき更新された履歴Hをもとに、最良の仮説を選出する(S118b)。そして、制御部120は、処理をS100に戻す。なお、制御部120は、所定の指示を検出したとき、この処理を終了する。
【0057】
(本実施形態による有利な効果)
本実施形態のシステムによれば、逐次的かつ大規模環境な自己位置推定システムを実現することができる。LSH外見データベースとRANSACマップマッチングスキームを使用することにより、実際に大規模環境におけるリアルタイムの自己位置推定を実現した。実験結果から、本システムが自己位置推定タスクの間に逐次的に到着するローカル及びグローバルな特徴の多くに効率的に対処できることが示された。外見ベースと位置ベースの方法を結合した本システムは、動的な環境など、アウトライア(はずれ値)観測が多い環境においても有効であることが期待される。
【符号の説明】
【0058】
100 システム(マップマッチングシステム)
120 制御部
140 入力部
160 外見データベース
180 メモリ
【技術分野】
【0001】
本発明は、点列で構成された2次元図形の位置合せをする2次元図形マッチングに関するものである。
【背景技術】
【0002】
点列で構成された2次元図形の位置合せをするマッチングに関し、各種技術(研究成果)が開示されている。例えば、入力図形及び参照図形のそれぞれに対して、図形上の線分あるいは点列から、接線方向あるいは法線方向を付加した点を所定の間隔で選択し、該選択点の位置と方向から定義される基底を用いて、該選択点の周囲に存在する他の選択点の位置と方向を座標変換し、該座標変換後の他の選択点の集合を該選択点のインデックスとして用いて幾何学的ハッシュ法を行い、入力図形と参照図形がマッチする相対位置姿勢の候補を求める線図形マッチング方法が提案されている(例えば、特許文献1参照)。
【0003】
また、逐次型マップマッチングと呼ばれる技術も提案されている(例えば、特許文献2参照)。さらに、2次元図形として地図を対象とした移動ロボット用地図作成システムも提案されている(例えば、特許文献3参照)。
【0004】
この他、大規模地図でのマップマッチングに関し、RANSAC(RANdom SAmple Consensus)に基づくマップマッチングの有効性が確認されている(例えば、非特許文献1参照)。なお、本出願の発明者においても、2次元図形に関するマッチングについて、幾つかの研究成果を報告している(例えば、非特許文献2〜4参照)。
【先行技術文献】
【特許文献】
【0005】
【特許文献1】特開2005−174062号公報
【特許文献2】特開2008−39698号公報
【特許文献3】特開2004−276168号公報
【非特許文献】
【0006】
【非特許文献1】Neira J., Tardos J.D., and Castellanos J.A. Linear time vehicle relocation in slam. IEEE International Conference on Robotics and Automation, 1:427-433, 2003.
【非特許文献2】Tanaka K. and Eiji K. A scalable algorithm for monte carlo localization using an incremental e2lsh-database of high dimensional features. IEEE Int. Conf. Robotics and Automation, pages 2784-2791, 2008.
【非特許文献3】Tanaka K and Kondo E. Incremental ransac for online vehicle relocation in large dynamic environments. Proc. IEEE Int. Conf. Robotics and Automation (ICRA), pages 1025-1030, 2006.
【非特許文献4】Takeshi Ueda and Kanji Tanaka. On the scalability of robot localization using high-dimensional features. IAPR International conference on pattern recognition, pages 1-4, 2008.
【発明の概要】
【発明が解決しようとする課題】
【0007】
近年、SLAM(Simultaneous Localization And Mapping)技術の進展により、移動ロボットのセンサデータ群を集約し大規模環境のランドマーク地図をリアルタイムに生成することが可能になってきた。それにともない、大規模地図を複数ロボット間で共有するセンサネットワークやロボットGISなどの試みがなされている。これらの枠組みに共通して、ロボットが地図上での自己位置を推定することは、最も基本的なタスクとなる。
【0008】
本発明は、以上を踏まえ、自己位置推定問題を対象とする。これまで様々な自己位置推定問題の研究がなされてきたが(例えば、上記非特許文献1参照)、それらの多くは、地図を所与とし、オフラインで地図データを構造化していた。これに対し、上記のように、最新の環境情報を反映してリアルタイムに構築・改変することのできる地図(以下、逐次型地図/2次元図形の一例)の需要が高まっている。
【0009】
本発明は、逐次性を有する高速な2次元図形マッチング方法を提供することを目的とする。
【課題を解決するための手段】
【0010】
上記課題に鑑みなされた本発明は、入力2次元図形に新たな点を挿入し、入力2次元図形の局所特徴を抽出し、参照2次元図形に新たな点を挿入し、参照2次元図形の局所特徴を抽出し、抽出された参照2次元図形の局所特徴を記憶し、抽出された入力2次元図形内の局所特徴の一つをクエリとし、記憶された参照2次元図形内で、クエリに関する局所特徴と類似する参照2次元図形内の局所特徴群を検索し、検索結果から解候補としての仮説を含む仮説集合を生成し、仮説集合に含まれる各仮説の確からしさを評価することとしたものである。
【0011】
この際、抽出された参照2次元図形の局所特徴を、LSH関数でハッシュ値に変換し、当該ハッシュ値に対応するハッシュ表の全てのビンに参照2次元図形の局所特徴を関連付けて記憶し、抽出された入力2次元図形内の局所特徴を、LSH関数でハッシュ値に変換し、当該ハッシュ値に対応するハッシュ表のビンにアクセスし、ハッシュ表中で入力2次元図形内の局所特徴に対応する局所特徴群を検索する。また、点と仮説との対である点仮説ペアの当該仮説のスコア値を計算し、計算されたスコア値に基づき、点仮説ペアを評価する順序を計画し、最良の仮説を選出する。
【0012】
本発明を反映した第1の課題解決手段は、点列で構成された2次元図形の位置合せをする2次元図形マッチング方法であって、入力2次元図形および参照2次元図形に新たな点を挿入する図形更新工程と、前記入力2次元図形および前記参照2次元図形各々の局所特徴を抽出する特徴抽出工程と、前記特徴抽出工程によって抽出された前記参照2次元図形の前記局所特徴を記憶する記憶工程と、前記特徴抽出工程によって抽出された前記入力2次元図形内の前記局所特徴の一つをクエリとし、前記記憶工程で記憶された前記参照2次元図形内で、前記クエリに関する前記局所特徴と類似する前記参照2次元図形内の局所特徴群を検索する検索工程と、前記検索工程での検索結果から解候補としての仮説を含む仮説集合を生成する仮説生成工程と、前記仮説集合に含まれる各仮説の確からしさを評価する仮説評価工程とを有し、前記記憶工程は、前記特徴抽出工程によって抽出された前記参照2次元図形の前記局所特徴を、LSH関数でハッシュ値に変換し、当該ハッシュ値に対応するハッシュ表の全てのビンに前記参照2次元図形の前記局所特徴を関連付けて記憶し、前記検索工程は、前記特徴抽出工程によって抽出された前記入力2次元図形内の前記局所特徴を、LSH関数でハッシュ値に変換し、当該ハッシュ値に対応する前記ハッシュ表の前記ビンにアクセスし、前記ハッシュ表中で前記入力2次元図形内の前記局所特徴に対応する前記局所特徴群を検索し、前記仮説評価工程は、点と仮説との対である点仮説ペアの当該仮説のスコア値を計算し、計算された前記スコア値に基づき、前記点仮説ペアを評価する順序を計画する順序ルール工程と、前記順序ルール工程で計算された前記スコア値に基づき更新された、前記仮説の前記スコア値の履歴をもとに、最良の仮説を選出する選択ルール工程とを有することを特徴とする2次元図形マッチング方法である。これによれば、逐次的に高速な2次元図形のマッチングを実行することができる。
【0013】
第2の課題解決手段は、第1の課題解決手段の2次元図形マッチング方法であって、前記仮説評価工程は、前記履歴が悪い仮説を、前記仮説集合から除外し、前記仮説集合が所定のサイズに納まるようにすることを特徴とする。これによれば、仮説集合のサイズを所定のサイズに納めることができる。
【発明の効果】
【0014】
本発明によれば、逐次性を有する高速な2次元図形マッチング方法を得ることができる。
【図面の簡単な説明】
【0015】
【図1】RANSACマップマッチングを説明する図である。
【図2】マップマッチングシステムを説明する図である。
【図3】ロボットの作業環境の例を示す図である。
【図4】時間コストを示す図である。
【図5】最良仮説を生成するのに用いた基底(局所特徴)を時間の流れに沿って示した図である。
【図6】自己位置推定の様子を表す図である。
【図7】各時刻の最良仮説についてスコアと順位(ランク)が変化していく様子を追跡した図である。
【図8】自己位置推定の性能を示す図である。
【図9】LSHパラメータに対する感度を要約した図である。
【図10】マップマッチングシステムの機能ブロックを示す図である。
【図11】マップマッチングシステムで実行される処理のフローチャートを示す図である。
【発明を実施するための形態】
【0016】
本発明を反映した上記課題解決手段を実施するための実施形態について、図面を用いて以下に詳細に説明する。上記課題解決手段は、以下に記載の構成に限定されるものではなく、同一の技術的思想において種々の構成を採用することができる。例えば、以下に説明する各構成において、所定の構成を省略することもできる。
【0017】
(本実施形態の位置付け)
本実施形態の説明に先立ち、まず、本実施形態の位置付けについて説明する。なお、以下では、2次元図形として、地図を例に説明する。
【0018】
一般に、自己位置推定のアプローチには、外見ベースの方法と位置ベースの方法がある。この内、外見ベースの方法は、ランドマークの外見を色・模様などの高次元特徴(例:SIFT, shape context)により表現する。そして、地図生成時に、各ランドマークの外見を位置と関連付けて地図データベースに登録しておく。その上で、自己位置推定時に、ロボット周辺で観測されたランドマークと類似するものを地図中から検索し、自己位置を絞り込む。これは、大規模地図を高速に検索し、自己位置を大きく絞り込むのに有効な方法といえる。一方、位置ベースの方法は、自己位置推定時、ロボット周辺で観測された局所的なランドマーク配置を直接、地図と照合し、自己位置を絞り込む。これは、多数のランドマークを利用して詳細に自己位置を絞り込むのに有効な方法といえる。以上のように、2つの方法にはそれぞれ異なる長所があり、両者を融合する方法が注目されている。本発明は、この融合方法に分類される。
【0019】
本出願の発明者らは、上記非特許文献2において、逐次型地図に有効な外見ベース手法を開発した。従来、多くのシステムでは、全ての特徴を一括して構造化・インデクス付けするバッチ型の地図データベース(例:kd-tree法)が用いられた。これに対し、発明者らは、ハッシュ技術に基づく地図データベースを構成した。ハッシュ表は、木構造など他の多くのデータベース構造と異なり、データの挿入・削除を逐次的・高速に行うことができる。この点を利用し、非特許文献2では、逐次型地図に有効なLSH(Locality Sensitive Hashing)に基づく地図データベースを提案した。
【0020】
一方、発明者らは非特許文献3において、逐次型地図に有効な位置ベース手法を開発した。一般に、大規模地図に有効な位置ベース法として、ロボット周辺地図(局所地図)と参照地図との位置合せを行うマップマッチング法が知られている。上述したとおり、特に、RANSAC(RANdomSAmple Consensus)に基づくマップマッチングは大規模地図での有効性が確認されている。しかし、これらは、所与の地図を前提とし、逐次型地図を扱うことができなかった。これを踏まえ、非特許文献3では、逐次型地図に有効なiRANSAC(incremental RANSAC)と呼ぶ逐次型のRANSAC手法を提案した。
【0021】
従来の方法は、位置ベース法および外見ベース法としては素朴な方法を用いていた。本実施形態では、両者を融合し、LSH-RANSACと呼ぶ、外見ベース法および位置ベース法の両面に優れる方法を提案する。なお、本実施形態と同様、LSHとRANSACを融合するアプローチとして、エピポーラ幾何、形状マッチング、画像検索など、近年、重要な研究事例がある。しかし、従来、LSHを逐次型データベースとして利用する事例は少なかった。また、逐次型のLSH-RANSACや自己位置推定への応用事例はなかった。
【0022】
また、コンピュータビジョン分野の場所認識(location recognition)問題においても、最近、階層型k-meansなど、大規模地図に有効な方法が開発されている。しかし、それらの殆どは、地図データベースをオフラインで構築しており、逐次型地図を扱うことができない。また、SLAM分野の閉ループ(loop closure)問題においては、逐次型地図を用いた場所認識が研究される。しかし、この問題では、自己位置の追跡結果を事前知識として利用しており、本問題のような、自己位置が完全に未知の状況を扱ってはいない。
【0023】
また、外見ベース法に関連して、PCAや視覚語彙(visual vocabulary)など翻訳関数を用いて、高次元の外見特徴を視覚単語(visual word)などコンパクトな低次元データに予め翻訳しておく方法が知られている。しかし、これらの方法は、人為的な訓練環境、あるいは、ロボットが過去に訪れた別の環境において、翻訳関数を機械学習しておくことを前提にしている。従って、教示の必要性や訓練環境への過学習など、未知環境への適応性の面で課題が残る。
【0024】
一方、本実施形態の提案方法は、翻訳関数などの事前学習を前提としない点で、従来のハッシュ技術に基づく物体分類手法に似ている。従来では、高次元の特徴空間を規則的な格子で分割し、各格子点に固有の物体クラスを考える。その結果、クラス数が膨大となるが、それらをハッシュ表を用いて管理し、最先端の検索速度と精度を実現している。ただし、基本的に単一視点での物体分類問題を対象としており、本実施形態の自己位置推定問題のような、多視点での問題は検討がなされていなかった。
【0025】
また、位置ベース法に関連して、ロバスト推定RANSACは、コンピュータビジョン分野の標準方法として広く用いられている。特に、近年、randomized RANSACと呼ばれる様々な亜種が提案されている。これらの多くは、主に、与えられた目標精度を、できるだけ短い計算時間で達成することを目的とする。これに対し、preemptive RANSAC(pRANSAC)は、与えられた計算時間で、できるだけ高い推定精度を達成することを目的とする。これは、SLAMなどリアルタイム応用に適した考え方といえる。本実施形態のiRANSACは、このpRANSACを逐次型へと拡張したものである。
【0026】
(マップマッチング)
次に、基本的なRANSACマップマッチングについて、図1に基づき説明する。ここでは、簡単のため、ロボット周辺地図Lおよび参照地図Gが時間とともに変動しないものと仮定する。いま、R台の地図生成ロボットID=1,・・・,Rがいるものとし、各々のロボットが生成する地図をG={G1,・・・,GR}とする。このとき、本問題の目的は、地図Lを並進回転ψさせたときに最も大きく重なり合うような地図Grを見つけ、その最大重なりを与える座標変換ψを求めることにある。その解法として、我々は、標準的なRANSACマップマッチングを基礎とし、pRANSACスキームを用いた高速化を行う。これらのRANSACマップマッチングおよびpRANSACについて以下に説明する。
【0027】
(RANSACマップマッチング)
一般的なRANSACアルゴリズムを以下に示す。いま、N個のデータ点があるものとし、これらを集合U={xi}により表す。また、集合Uの部分集合Sをもとに、後述の方法により、モデルパラメータpを算出する関数(モデル関数)をfm:S→pとする。また、モデルパラメータpの一つのデータ点で1つのデータポイントxに対しコスト関数ρ(p,x)を定義する。このコスト関数は、xがモデルに対して整合する(インライア)ならば1を取り、それ以外では0を返す。このとき、RANSACによるパラメータ推定の目的は、コスト関数を最大限にするモデルパラメータp*およびそれを与えるコストC*を探索することにある。具体的には、RANSACアルゴリズムは、信頼できる仮説が見つかるまで、次のステップ(1)〜(3)を繰返す。
(1)部分集合Sk⊂Uをランダムに選択し、モデルパラメータ仮説pk=fm(Sk)を算出する。
(2)コストCkを求める。コストCkは、以下の式(1)によって算出される。
【数1】
(3)もしCk>C*ならばC*←Ck,p*←pkとする。
【0028】
このRANSACアルゴリズムは、直接にバッチ型マップマッチング問題に適用することができる。この問題設定においては、地図Lの特徴数をNと解釈する。また、地図L上の特徴をx、地図Lから地図Grへの変換をpと解釈する。変換pの下で、もし地図Lの特徴点xが地図G上の特徴点にマッチするならば、コスト関数ρ(p,x)は1を取り、そうでなければ、0を取る。またモデル関数fmは、L(Shape Contextのような)のローカル特徴からGのグローバル特徴への変換を表す。
【0029】
(pRANSACスキーム)
RANSACのさらなる高速化のために、rRANSACと呼ばれるRANSACの亜種が提案されており、それらの亜種の中でも、本実施形態では、リアルタイム性に優れるpRANSACを用いる。pRANSACの概要を以下に示す。pRANSACは、ある時点までに評価された全ての特徴仮説ペア(pj,xj)、および対応する得点結果
Cj=ρ(pj,xj)・・・(2)
の過程
H={(pj,xj,Cj)}・・・(3)
を保持し、これをもとに、各時点の処理を行う。また、2種類のユーザ定義関数、順序ルール
(p,x)=fo(H)・・・(4)
および選択ルール
p*=fp(H)・・・(5)
を用いる。順序ルールは、履歴Hが与えられたときに、次にどの特徴仮説ペアを評価すべきかを決定する。選択ルールは、履歴Hをもとに、最もよい仮説を選び出す。いま、ある特徴集合
U={xi}・・・(6)
および、仮説集合
V={pj}・・・(7)
が与えられたものとすると、pRANSACは、計算時間の許す限り次のステップ(1)および(2)を繰り返す。なお、ステップ(1)(以下、「pRANSACのステップ(1)」ともいう。)は、図11のフローチャートのS118aに相当する処理である。また、ステップ(2)(以下、「pRANSACのステップ(2)」ともいう。)は、同処理フローのS118bに相当する処理である。
(1)特徴仮説ペア(pk,xk)=fo(H)を選択し、スコアρ(pk,xk)を計算する。
(2)得点結果に基づき、特徴仮説ペアの当該仮説のスコア値の履歴Hを更新する。必要に応じて、最良の仮説p*=fp(H)を出力する。
【0030】
(幅優先ルール)
pRANSACの性能は、主に順序ルールfo(H)に依存する。ここで、プリエンプティブ(preemptive)幅優先ルールと呼ばれる順序ルールは、いくつかの魅力的な特性がある。第1に、その計算時間は、仮説集合サイズに比例した定数により制限される。第2に、評価は、ある絶対的な品質尺度ではなく仮説間の競合によって行われる。第3に、インライア・アウトライア・モデルという簡略化されたモデル下であるが、安定した性能が解析的に示されている。以下に、幅優先スキームに基づくpRANSACの概要を手短に示す。
【0031】
計算時間を節約するために、単調減少のプリエンプティブ関数fb(i)(p関数)を用いて、評価対象となる(アクティブな)仮説の数を制限する。このp関数は、まず、仮説ID1,・・・,Nおよび、特徴ID1,・・・,Mをランダムに並び替える。また、各々の仮説について、j(1≦j≦M)スコア値をCj=0に初期化する。そして、計算時間がなくなるまで、以下、ステップ(1)および(2)を繰返す。なお、ステップ(1)(以下、「幅優先ルールのステップ(1)」ともいう。)は、図11のフローチャートのS118に相当する処理である。また、ステップ(1)および(2)は、(以下、ステップ(2)について「幅優先ルールのステップ(2)」ともいう。)は、履歴Hが悪い仮説を、仮説集合から除外し、仮説集合が所定のサイズに納まるようにするための処理である。ステップ(2)は、各時刻(所定のタイミング)において、実行される。
(1)仮説j(1≦j≦fb(i))ごとにスコア値Cj←Cj+ρ(pj,xi)を算出する。
(2)仮説ID1,・・・,Nを整理し、スコア値Gjがトップfb(i)の中に納まるようにする。p関数fb(i)を式(8)に示す。
【数2】
Bは予め設定された定数である。
【0032】
このBは、「ブロックサイズ」と呼ばれる。以上の処理で、B回繰返すたびに仮説集合のサイズが半分になる。結果として、全体の時間コストは、O(BM)となる。
【0033】
(逐次型LSH-RANSACスキーム)
これまで、発明者らは、特徴と仮説の集合が固定されたバッチ問題を考えてきた。しかし、実際には、ロボットの自己位置推定タスクでは、特徴集合と仮説集合が逐次的に変化していく。このことを理解するために、我々は、典型的な自己位置推定タスクを以下に素描する。自己位置推定タスク中、自己位置推定プロセス(つまりマップマッチングプロセス)は最新のセンサデータを取り入れながら常に最良の解を探し続ける。自己位置推定プロセスは、自己位置推定タスクの始めにスタート視点で一度だけ初期化されて、空集合から始まる。その後、これらの集合および地図は、以下の2種類のイベントにより修正されていく。なお、第1イベントでの(a)は、図11のフローチャートのS100に相当し、(b)は、S102に相当し、(c)は、S114に相当し、(d)および(e)は、S116に相当する処理である。また、第2イベントでの(f)は、S108に相当し、(g)は、S110に相当し、(h)は、S112に相当する処理である。
(第1イベント)
(a)入力地図(局所地図)更新
(b)入力地図に新規特徴が追加される
(c)新規特徴を用いて外見データベースに検索質問(クエリ)を行う
(d)検索結果をもとに新規仮説を生成する
(e)仮説集合に新規仮説を追加する
(第2イベント)
(f)参照地図(大域地図)更新
(g)参照地図に新規特徴が追加される
(h)新規特徴を外見データベースに追加する
【0034】
以上のことから、リアルタイム自己位置推定問題を実現するためには、以下の2点が重要となる。第一に、仮説の数Mが無制限に成長するとともに、問題サイズはO(BM)の複雑さで増加し、効率的なpRANSACを用いても手に負えなくなる。これに対処するために、本実施形態では、外見特徴を手掛かりとし少数(例えば1,000個)の確からしい仮説のみを生成する。特に、本実施形態では、地図生成タスクにおいて、逐次的に構築・改変することのできる逐次型の外見データベースを提案する。
【0035】
第二に、マップマッチングに用いる入力地図(局所地図)および参照地図(大域地図)を逐次的に更新することが求められる。これに対処するために、本実施形態では、マップマッチングタスク中に新規の特徴を追加することのできる逐次型RANSAC(iRANSAC)スキームを応用する。特に、多くの生き残っている仮説(アクティブな仮説)を扱いやすいサイズに抑えるために、本実施形態では、プリエンプティブ幅優先ルールを逐次型へと拡張する。以下では、さらに詳細に上述の考えを実行する方法を説明する。
【0036】
(外見データベース)
外見データベースは、Locality Sensitve Hashing(LSH)に基づき構築する。LSHは、高次元空間中の或る質問点に対し、データベース中から近傍にある点を探索する。特に、E2LSH(Exact Euclidean Locality Sensitive Hashing)は、(R, cR)-Near Neighbor問題を扱う。これは、データベース点がqから距離Rの範囲内であるならば、ゴールは質問qから距離cRの中の点を返す、という性質を持つANN技術である。E2LSHはある近似ファクタρ(c)<1に対しO(nρ(c)log n)時間コストであり、他のANNアルゴリズムと比べても高速であることが示されている。本実施形態が、LSHを利用するもう一つの理由は、LSHがハッシュ表に基づく点にある。ツリーのような他のデータ構造とは異なり、ハッシュテーブルに基づく構造では、データベース要素の挿入/削除が頻繁かつ逐次的に行えるという利点がある。まず、LSHは、前処理において、K次元を備えたLハッシュ関数はp-stable分布(例えば正規分布)を用いて、確率的に生成する。そして、新しい特徴が参照地図(大域地図)に追加されるとき、以下のステップ(1)〜(3)によりデータベースを更新する。なお、新しい特徴が参照地図(大域地図)に追加されるとき(図11のフローチャートのS106:Yes参照)に実行される、ステップ(1)〜(3)は、図11のフローチャートのS112に相当する処理である。
(1)特徴の実世界位置を記憶する
(2)E2LSH関数により特徴をハッシュし、対応するビンにアクセスする、
(3)特徴の実世界位置とビンを関連付ける
【0037】
ただし、高次元特徴の本体を記憶すると、特徴次元に比例した膨大な空間コストがかかるので、特徴本体は忘却するものとし、ハッシュ値のみを記憶する。これは、単純な工夫だが、データベースの空間・時間コストを大幅に削減することが知られている。発明者らは、上記非特許文献2において、この手法をモンテカルロ自己位置推定に適用し、その性能を検証している。以上からも分かるように、データベースの更新手続きは、完全に逐次的に行うことができる。
【0038】
特徴の実世界位置はグリッドマップ上に記憶する。ただし、これを直接に行うと、大規模環境では、グリッドマップのセル数が膨大となり、記憶容量が不足するという問題がある。そこで、我々は、一次元ハッシュ表に、実世界位置を写像する普遍ハッシュ関数(UH)を利用する。一般に、適切なハッシュ表のサイズは、環境サイズ・特徴数に依存するが、衝突確率が十分に低くなるように設定するものとする。これは、衝突が生じるたびに、一つの特徴が誤った実世界位置にあると信じることになり、多数の衝突が生じると誤認識の危険性が高まるからである。現在の実装では、グリッドマップの空間コストに対し、近似されたハッシュ表のサイズの比率は、0.03である。なお、衝突確率は、この比率以下となることが保証される。
【0039】
(マップマッチング)
iRANSACアルゴリズムを以下に要約する。タスクの始めに、特徴集合および仮説集合を空集合U←φ,V←φへと初期化する。そして、タスク中、次のステップ(1)〜(3)を繰り返す。なお、ステップ(1)は、図11のフローチャートのS102に相当し、ステップ(2)は、S116に相当し、ステップ(3)は、S118に相当する処理である。
(1)新規特徴Unewが到着したとき、特徴集合をU←Unew∪Uのように修正する
(2)新規仮説Vnewが到着したとき、仮説集合をV←Vnew∪Vのように修正する
(3)pRANSACのステップ(1)および(2)(上記「(pRANSACスキーム)」の項参照)を実行する。
【0040】
幅優先ルールを逐次型へと修正し用いる。これは、繰り返しiごとに次のステップ(1)および(2)を実行する処理となる。なお、ステップ(2)は、履歴Hが悪い仮説を、仮説集合から除外し、仮説集合が所定のサイズに納まるようにするための処理である。
(1)iRANSACアルゴリズムのステップ(1)および(2)(この「マップマッチング」の項に記載の上記ステップ(1)および(2)参照)を実行する
(2)オリジナルの幅優先ルールのステップ(1)および(2)(上記「(幅優先ルール)」の項参照)を実行する。その際、式(9)の形式のプリエンプティブ(Preemption)関数fb(i)を用いる。
【数3】
ただし、m(i)は、i番目の繰り返しが終了した時点での仮設数を表す。
【0041】
選択ルールにも、少しだけ修正を加える。逐次的な問題設定では、仮説の評価数が仮説間で大きく異なりうる。若い仮説は、古いものより短い時間で不当に高い評価を得る可能性がある。そこで、公正な比較のために、単純にスコア値Cjを評価するのではなく、正規化されたスコア値Cj/Njを評価する。さらに、最良の仮説を選ぶ際、スコア値が閾値Coより小さい若い仮説は候補とみなさない。
【0042】
以上のように修正を加えた幅優先ルールは、仮説集合が固定の場合には、オリジナルの幅優先ルールに縮退する。また、一般に、完全にランダムに並び替えた特徴列・仮説列を用いることで、RANSACのパフォーマンスが確率的に最大化することができることが知られている。しかし、逐次的な問題設定では特徴列・仮説列は、出現順序の影響を受けるため、この完全ランダムな並び替えは不可能となる。また、並び替え済みの列Uが与えられているとき、新しい要素UnewをUに加えたいのであれば、その処理は、列Uのランダムに選択した箇所にUnewの各要素を挿入する処理となり、O(|Unew|)の計算量で実行できる。
【0043】
(システムの有効性)
本実施形態のシステム(マップマッチングシステム)の有効性を検証するため、自己位置推定の実験を行ったので、以下、本実施形態のシステム構成および実験結果について説明する。まず、本実施形態のシステムについて図2に基づいて説明する。本実施形態のシステムでは、環境内に複数台の参照地図生成ロボット#1,・・・,#Rおよび入力地図生成ロボットが在る。参照地図生成ロボットが取得した点を参照地図に挿入する。また、参照地図生成ロボットが取得した外見特徴を外見データベースに登録する。また、入力地図生成ロボットが観測した点を入力地図に挿入する。また、外見データベースの検索結果、および、入力地図と参照地図との逐次型マップマッチング結果をもとに、有望な位置合せの候補を探索する。
【0044】
次に、実験結果について説明する。本実験では、radishデータセットを用いる(図3参照)。本データセットは、運動および知覚のセンサデータ列からなる。各運動データは、ある視点から次の視点までのロボットの運動を観測したものである。参考までに、本システムでは、運動データのフォーマットとして、前進・横進・回転(FSR)フォーマットを採用した。各認識データは、前部レーザースキャナによる1回の走査であり、観測ごとに、ロボット中心座標系の180個のデータ点を取得する。また、外見特徴として、レーザデータ点に一般的な、形状特徴を用いる。特に、上記非特許文献2および3において安定性が示されたgeneralized shape context(GSC)を用いる。また、SLAM手法として、単純なスキャンマッチングアルゴリズムを用いる。各観測ごとの新規特徴および新規仮説の数はそれぞれ|Unew|=10および|Vnew|=1,000に設定する。pRANSACスキームに使用するブロックサイズは、B=|Unew|に設定する。LSHのパラメータは、経験的にK=30、L=20に設定する。
【0045】
本実施形態では、典型的なシナリオとして、R台の参照地図生成ロボット(マッパーロボット)がR個の異なる建物を探索している状況を考える。ロボットには、自分がどの建物にいるか、また、建物中でどこにいるのか、について事前知識は与えられない。サブマップGr(1≦r≦R)は、それぞれ、地図構築タスクの開始時に、空の地図へと初期化される。地図は、タスク中に地図生成ロボットにより逐次的に構築される。新規スキャンが到着するたびに、外見特徴群をスキャン点群から抽出する。そして、抽出した特徴を外見データベースに追加し参照地図を更新する。図4(a)に、3つの異なる環境「albert」、「fr079」と「fr101」を用いて、異なるサイズのグローバルマップそれぞれについて、特徴1つ当たりの更新プロセスによって消費された時間を示す。時間コストは地図サイズに依存せず、一定以下となっていることが分かる。参照地図(大域地図)を構成する一つ一つのサブマップを直接に実装すると、3次元xyθ姿勢空間でおよそ2.1×107のセルを消費した。これに対し、上述のハッシュ表による近似表現を用いると全体でおよそ3.4×108のセルとなり大幅に空間コストを削減できた。本実施形態のシステムでは、グリッド地図からサイズ1×107ビンのUH(普遍ハッシュ関数)テーブルに変換する。UHテーブルのサイズは、元のグリッド地図の3%未満となる。LSHデータベースによって消費されたLSHテーブルはこの実験で高々7.2×106ビンとなる。以上のことから、我々のデータ構造が完全に逐次的であり、大規模地図に有効であることが分かる。
【0046】
図5および図6は自己位置推定の結果を表す。自己位置推定タスクの開始時に、局所地図を空地図へと初期化する。新規スキャンが到着するたびに、外見特徴群をスキャン点群から抽出し入力地図(局所地図)を更新する。その後、一セットの外見特徴をスキャン点群から抽出する。その後、各特徴を検索質問として外見データベースを検索する。その検索結果に基づいて、新規仮説を生成する。図4(b)は、時間コストを示している。上述したように、検索処理の時間コストは実際に一定値以下となっている。図6(a)〜(d)にマップマッチングの流れの例を示す。図6(a)〜(c)は、未だマッチングに成功していない状況を表している。この内、図6(a),(b)は、入力地図(局所地図)が未だ十分な情報量を持たないか、あるいは、疎な状況であり、その結果として、全てのマッチング仮説が信頼できない状況にあった。これに対し、図6(c)では、入力地図の大部分が、参照地図(大域地図)に記されていない未知領域にあり、その結果として、誤った仮説が不当に高い一致度を得ていた。これは、例えば、入力地図を誤った建物とマッチングするなどの誤りである。図6(d)は、最終的にマッチングに成功した状況を表している。ここでは、入力地図が十分な情報量を持っており、かつ、入力地図の大きな部分が参照地図中で既知の領域を含んでいる。図4(c)は、マップマッチング処理による時間コストも一定以下に抑えられている様子を表している。重要な点として、時間コストは地図データベースのサイズに依存していない。
【0047】
図7に評価の様子を説明する。説明のために、「ランク」という概念を導入する。これは、仮説群をスコア値が高いものから順に並べたときの各仮説の順位のことであり、仮説間の相対的な重要度を表している。ただし、全ての仮説についてランクをプロットすると煩雑となるため、少なくとも一回はトップランク(つまり、ランク1が割り当てられた)された仮説のみをプロットした。ここでは、多数のデータ点群と整合性ある良質な仮説は、優先的に評価対象として選ばれる傾向がある。一方、ノイズにより汚染された良質でない仮説群は、すぐに除去される傾向がある。良い仮説が一度高いランクとなれば、長い期間、高位グループにとどまる傾向がある。また、典型的なrRANSACスキームとの重要な差異として、本スキームでは、仮説の割合およびランキングは、ロボットがナビゲーションするとともに減少する傾向がある。その理由は、オドメトリ誤差の蓄積により、局所地図と新規データ点との整合性が悪くなっていく傾向があるためである。結果として、新旧の仮説は、プリエンプション(preemption)スキームの枠組みにおいて、相互に比較され、若いデータ点でサポートされるトップランクの仮説は、各視点の最良の仮説として出力される傾向がある。
【0048】
図8は、いくつかの実験を通して自己位置推定の性能を示す。ここでは、3つの異なる入力地図、および、それぞれ1,4,9,16のサブマップから構成される4つの異なるサイズの大域地図からなる、全12通りの実験を行った。図3(a)〜(c)に各実験結果を要約する。ここでは、対象ロボットは、地図生成ロボットの16個の建物のうちのどれか一つを移動しているものと仮定する。この仮定の下では、一つのセンサデータ列から対象ロボットと地図生成ロボットのためのセンサデータ列を取り出すことが必要になる。その際は、2つのロボットが使用するセンサデータ部分列が互いに重なり合わないように注意した。図8に実験結果を示す。まず、図8(b)および(c)では、自己位置推定タスクの初期に推定がうまくいっていないことが分かる。これは、対象ロボットのスタート地点が参照地図に記されていない未知領域中にあったことに起因している。しかし、全ての実験において、最終的に自己位置推定の誤差は、1mよりも小さくなっていることが分かる。特に、大域地図のサブマップ数が16の場合は、3.5×105を上回る外見特徴を含んでいる。図8では、自己位置推定タスクが16サブマップの環境でさえ成功していることが分かる。これは、完全に逐次的なシステムとしては、従来のもの(非特許文献1〜4を含む)と比べて、非常に大きなサイズの地図といえる。本実施形態の逐次的なスキームがそのような参照地図(大域地図)でさえうまくいっているのは、特筆すべき点といえる。
【0049】
また、パラメータ感度とスケーラビリティを調査するために追加実験を行った。図9は、LSHパラメータに対する感度を要約したものである。本実施形態のシステムが広範囲のパラメータにおいて安定していることが分かる。発明者らは、また、合成したデータセットを使用することではるかに大きなグローバルマップを用いた実験を行い、発明者らの計画が40サブマップ(1.2×106の特徴)環境で成功することを確認している。上記の結果から、本実施形態のスキームは、完全に逐次的であり、大規模問題に有効であると結論することができる。
【0050】
(システムの機能ブロック)
本実施形態のシステム(マップマッチングシステム)100について、図10に基づいて説明する。なお、図10に示すシステム100は、図2に示したマップマッチングシステムの処理部分を具体化して詳細に説明したものである。システム100は、制御部120と、入力部140と、外見データベース160と、メモリ180とを備える。制御部120は、上述した各種処理(後述するフローチャート参照)を実行する。具体的に、制御部120は、図形更新部と、特徴抽出部と、記憶制御部と、検索部と、仮説生成部と、仮説評価部として機能する。ここで、仮説評価部は、さらに、順序ルール部と、選択ルール部を含み、制御部120は、これら各部としても機能する。また、検索部は、ハッシュ表の各ビンに格納したハッシュ値のヒストグラムを管理する顕著性判定部を含み、制御部120は、顕著性判定部としても機能する。
【0051】
入力部140は、例えば視覚センサによって構成され、入力図形の入力を受け、これを制御部120に提供する。外見データベース160は、上述したとおりであり、その詳細は省略する。メモリ180は、例えばRAMによって構成され、制御部120による処理の実行に際し、各種データ等が記憶される領域である。
【0052】
なお、制御部120は、図10には図示されていない領域に記憶されたプログラムによって、各種処理を実行する。例えば、図11に示すフローチャートによる各種処理(制御部120によって実現される図10に示す各部による各種工程)を実行する。また、履歴Hが悪い仮説を、仮説集合から除外し、仮説集合が所定のサイズに納まるようにするための処理を実行する((上記「(幅優先ルール)」の項に記載の幅優先ルールのステップ(2)参照)。さらに、特徴抽出部によって抽出された入力地図内の局所特徴の一つをクエリとし、このクエリに関する局所特徴の顕著性を判定する。
【0053】
(システムで実行される処理)
本実施形態のシステム100で実行される処理について、図11に示すフローチャートに基づき参照して説明する。この処理を開始した制御部120は、まず、入力地図に新たな点を追加するか否かを判断する(S100)。判断の結果、入力地図に新たな点を追加する場合(S100:Yes)、制御部120は、入力地図に新たな点を挿入し(S102)、入力地図の局所特徴を抽出する(S104)。そして、制御部120は、処理をS100に戻す。
【0054】
S100の判断の結果、入力地図に新たな点を追加しない場合(S100:No)、制御部120は、参照地図に新たな点を追加するか否かを判断する(S106)。判断の結果、参照地図に新たな点を追加する場合(S106:Yes)、制御部120は、参照地図に新たな点を挿入し(S108)、参照地図の局所特徴を抽出する(S110)。続けて、制御部120は、参照地図の局所特徴を、外見データベース160に記憶する。この際、制御部120は、S108で抽出された局所特徴をLSH関数によりハッシュし、対応するビンにアクセスし、この局所特徴をハッシュ表に記憶する(S112)。詳細には、S108で抽出された局所特徴をLSH関数でハッシュ値に変換し、このハッシュ値に対応するビンにアクセスし、このハッシュ値に対応するハッシュ表のビンに、この局所特徴を関連づけて記憶する。そして、制御部120は、処理をS100に戻す。
【0055】
S106の判断の結果、参照地図に新たな点を追加しない場合(S106:No)、制御部120は、入力地図内の局所特徴をクエリとし、参照地図内でクエリに関する局所特徴と類似する局所特徴(局所特徴群)を検索する(S114)。この際、制御部120は、S112と同様に、LSH関数で、外見データベースのハッシュ表を検索する。具体的に、クエリに関する局所特徴をLSH関数でハッシュ値に変換し、このハッシュ値に対応するビンにアクセスし、それらに記憶(格納)されている全ての局所特徴(局所特徴群)を出力(検索)する。
【0056】
S114を実行した後、制御部120は、S114の検索による検索結果から、解候補としての仮説を含む仮説集合を生成する(S116)。続けて、制御部120は、仮説集合に含まれる各仮説の確からしさを評価する(S118)。具体的に、制御部120は、S118でインライア判定を実行する。また、制御部120は、S118で、点と仮説との対である点仮説ペア(特徴仮説ペア)を評価する順序を計画し、計画された順序に基づき、点仮説ペアを選択し、選択された点仮説ペアの仮説のスコア値を計算するとともに、得点結果(計算されたスコア値)に基づき、当該仮説のスコア値の履歴Hを更新する(S118a)。その上で、制御部120は、得点結果に基づき更新された履歴Hをもとに、最良の仮説を選出する(S118b)。そして、制御部120は、処理をS100に戻す。なお、制御部120は、所定の指示を検出したとき、この処理を終了する。
【0057】
(本実施形態による有利な効果)
本実施形態のシステムによれば、逐次的かつ大規模環境な自己位置推定システムを実現することができる。LSH外見データベースとRANSACマップマッチングスキームを使用することにより、実際に大規模環境におけるリアルタイムの自己位置推定を実現した。実験結果から、本システムが自己位置推定タスクの間に逐次的に到着するローカル及びグローバルな特徴の多くに効率的に対処できることが示された。外見ベースと位置ベースの方法を結合した本システムは、動的な環境など、アウトライア(はずれ値)観測が多い環境においても有効であることが期待される。
【符号の説明】
【0058】
100 システム(マップマッチングシステム)
120 制御部
140 入力部
160 外見データベース
180 メモリ
【特許請求の範囲】
【請求項1】
点列で構成された2次元図形の位置合せをする2次元図形マッチング方法であって、
入力2次元図形および参照2次元図形に新たな点を挿入する図形更新工程と、
前記入力2次元図形および前記参照2次元図形各々の局所特徴を抽出する特徴抽出工程と、
前記特徴抽出工程によって抽出された前記参照2次元図形の前記局所特徴を記憶する記憶工程と、
前記特徴抽出工程によって抽出された前記入力2次元図形内の前記局所特徴の一つをクエリとし、前記記憶工程で記憶された前記参照2次元図形内で、前記クエリに関する前記局所特徴と類似する前記参照2次元図形内の局所特徴群を検索する検索工程と、
前記検索工程での検索結果から解候補としての仮説を含む仮説集合を生成する仮説生成工程と、
前記仮説集合に含まれる各仮説の確からしさを評価する仮説評価工程とを有し、
前記記憶工程は、前記特徴抽出工程によって抽出された前記参照2次元図形の前記局所特徴を、LSH関数でハッシュ値に変換し、当該ハッシュ値に対応するハッシュ表の全てのビンに前記参照2次元図形の前記局所特徴を関連付けて記憶し、
前記検索工程は、前記特徴抽出工程によって抽出された前記入力2次元図形内の前記局所特徴を、LSH関数でハッシュ値に変換し、当該ハッシュ値に対応する前記ハッシュ表の前記ビンにアクセスし、前記ハッシュ表中で前記入力2次元図形内の前記局所特徴に対応する前記局所特徴群を検索し、
前記仮説評価工程は、点と仮説との対である点仮説ペアの当該仮説のスコア値を計算し、計算された前記スコア値に基づき、前記点仮説ペアを評価する順序を計画する順序ルール工程と、前記順序ルール工程で計算された前記スコア値に基づき更新された、前記仮説の前記スコア値の履歴をもとに、最良の仮説を選出する選択ルール工程とを有することを特徴とする2次元図形マッチング方法。
【請求項2】
前記仮説評価工程は、前記履歴が悪い仮説を、前記仮説集合から除外し、前記仮説集合が所定のサイズに納まるようにすることを特徴とする請求項1に記載の2次元図形マッチング方法。
【請求項1】
点列で構成された2次元図形の位置合せをする2次元図形マッチング方法であって、
入力2次元図形および参照2次元図形に新たな点を挿入する図形更新工程と、
前記入力2次元図形および前記参照2次元図形各々の局所特徴を抽出する特徴抽出工程と、
前記特徴抽出工程によって抽出された前記参照2次元図形の前記局所特徴を記憶する記憶工程と、
前記特徴抽出工程によって抽出された前記入力2次元図形内の前記局所特徴の一つをクエリとし、前記記憶工程で記憶された前記参照2次元図形内で、前記クエリに関する前記局所特徴と類似する前記参照2次元図形内の局所特徴群を検索する検索工程と、
前記検索工程での検索結果から解候補としての仮説を含む仮説集合を生成する仮説生成工程と、
前記仮説集合に含まれる各仮説の確からしさを評価する仮説評価工程とを有し、
前記記憶工程は、前記特徴抽出工程によって抽出された前記参照2次元図形の前記局所特徴を、LSH関数でハッシュ値に変換し、当該ハッシュ値に対応するハッシュ表の全てのビンに前記参照2次元図形の前記局所特徴を関連付けて記憶し、
前記検索工程は、前記特徴抽出工程によって抽出された前記入力2次元図形内の前記局所特徴を、LSH関数でハッシュ値に変換し、当該ハッシュ値に対応する前記ハッシュ表の前記ビンにアクセスし、前記ハッシュ表中で前記入力2次元図形内の前記局所特徴に対応する前記局所特徴群を検索し、
前記仮説評価工程は、点と仮説との対である点仮説ペアの当該仮説のスコア値を計算し、計算された前記スコア値に基づき、前記点仮説ペアを評価する順序を計画する順序ルール工程と、前記順序ルール工程で計算された前記スコア値に基づき更新された、前記仮説の前記スコア値の履歴をもとに、最良の仮説を選出する選択ルール工程とを有することを特徴とする2次元図形マッチング方法。
【請求項2】
前記仮説評価工程は、前記履歴が悪い仮説を、前記仮説集合から除外し、前記仮説集合が所定のサイズに納まるようにすることを特徴とする請求項1に記載の2次元図形マッチング方法。
【図2】

【図10】
【図11】
【図1】
【図3】
【図4】
【図5】

【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図1】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【公開番号】特開2010−262546(P2010−262546A)
【公開日】平成22年11月18日(2010.11.18)
【国際特許分類】
【出願番号】特願2009−114066(P2009−114066)
【出願日】平成21年5月9日(2009.5.9)
【出願人】(504145320)国立大学法人福井大学 (287)
【Fターム(参考)】
【公開日】平成22年11月18日(2010.11.18)
【国際特許分類】
【出願日】平成21年5月9日(2009.5.9)
【出願人】(504145320)国立大学法人福井大学 (287)
【Fターム(参考)】
[ Back to top ]