
3’−T突出部を伴うアダプターの使用方法
【課題】2つ以上のサンプルにおいて2つ以上のライブラリーを産出し、検査ライブラリーを提供すること。
【解決手段】本発明の一塩基多型のハイスループット同定のための方法は、2つ以上のサンプルにおいて2つ以上のライブラリーを産出するために、複雑度の減少を行なうこと、ライブラリーの少なくとも一部をシークエンシングすること、同定された配列をアライメントすること、任意の推定上の一塩基多型を決定すること、任意の推定上の一塩基多型を確認すること、確認された一塩基多型のための検出プローブを生成することを含む。また、検査ライブラリーを提供するために、検査サンプルに同様な複雑度の減少を行なうこと、及び検出プローブを使用して一塩基多型の存在又は一塩基多型の非存在について検査ライブラリーをスクリーニングすることを含む。
【解決手段】本発明の一塩基多型のハイスループット同定のための方法は、2つ以上のサンプルにおいて2つ以上のライブラリーを産出するために、複雑度の減少を行なうこと、ライブラリーの少なくとも一部をシークエンシングすること、同定された配列をアライメントすること、任意の推定上の一塩基多型を決定すること、任意の推定上の一塩基多型を確認すること、確認された一塩基多型のための検出プローブを生成することを含む。また、検査ライブラリーを提供するために、検査サンプルに同様な複雑度の減少を行なうこと、及び検出プローブを使用して一塩基多型の存在又は一塩基多型の非存在について検査ライブラリーをスクリーニングすることを含む。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、分子生物学及び遺伝学の分野に関する。本発明は、核酸サンプルにおける複数の多型性の迅速な同定に関する。同定された多型性は、検査サンプルの多型性のためのハイスループットスクリーニング系の開発に対して使用されてもよい。
【背景技術】
【0002】
ゲノムDNAの調査は、科学関係者、特に医療関係者によって長く望まれてきた。ゲノムDNAは、癌及びアルツハイマー病のような疾患の同定、診断、及び治療の鍵を握る。ゲノムDNAの調査は、疾患の同定及び治療だけでなく、植物及び動物品種改良事業において著しい利点を提供し、食品栄養学の問題に対する答えを世界に示すかもしれない。
【0003】
多くの疾患が、特異的な遺伝子の多型性を伴う特異的な遺伝的要素に特に関連することが知られている。ゲノムのような大きなサンプルにおける多型性の同定は、現在、困難且つ多くの時間を要する課題である。しかしながら、そのような同定は、製薬産物、組織適合試験、遺伝子型決定、及び集団研究を開発する生物医学研究のような領域に対して非常に価値がある。
【発明の概要】
【発明が解決しようとする課題】
【0004】
本発明は、複雑な、例えば非常に大きな核酸サンプル(例えば、DNA又はRNA)における多型性を、ハイスループット方法の組合せを使用して、迅速及び経済的な様式で、効率的に同定し確実に検出する方法を提供する。
【0005】
ハイスループット方法のこの統合は、従来の多型性の同定及びマッピングが困難且つ多くの時間を要するような、非常に複雑な核酸サンプルにおいて、迅速及び確実な多型性の同定及び検出に対して特に適しているプラットフォームを共に提供する。
【0006】
本発明者が発見したものの1つは、多型性、好ましくは一塩基多型の同定のため、また同様に、特に大きなゲノム中の(マイクロ)サテライト及び/又は挿入・欠失(indels:インデル)の同定のための解決法である。本発明の方法は、大きなゲノム及び小さなゲノムの両方への適用の可能性という点において独特であるが、大きなゲノム、特に倍数体種における特定の利点を提供する。
【0007】
SNPを同定する(及び続いて同定されたSNPを検出する)ために、当該技術分野において利用可能ないくつかの可能性がある。第1の選択では、全ゲノムはシークエンシングすることが可能であり、いくつかの個体についてはそのようなことを行うことができる。これは煩わしく費用のかかることであるので、大半は理論的な試行であり、技術の迅速な発展にもかかわらず、単純に全ての生物、特により大きなゲノムの生物で行うのは実現可能でない。第2の選択は、ESTライブラリーのような利用可能な(断片化した)配列情報を使用することである。これは、PCRプライマーの生成、再シークエンシング、及び個体間の比較を可能にする。さらに、これは、利用可能でないか、又は限られた量でのみ利用可能な、初期の配列情報を必要とする。各々の領域については、さらに個別のPCR分析を開発しなければならず、費用及び開発時間は桁外れに増してしまう。
【0008】
第3の選択は、同定自体を各々の個体に対するゲノムの一部に限定することである。成功するSNP同定に匹敵する結果を提供するためには、提供されるゲノムの部分は、異なる個体にとっても同じでなくてはならないという問題点が存在する。本発明者等は、サンプル調製及びハイスループット同定プラットフォームで統合された、多型性の同定のためのハイスループットシークエンシングによるゲノムの一部を選択するための高度に再現可能な方法の統合によって、今やこの難問を解決している。本発明は、多型性発見の過程を加速し、次の過程で、効果的で確実なハイスループット遺伝子型決定を可能にするように、同一の要素を発見した多型性の利用のために使用する。
【0009】
本発明の方法のさらに想定される適用は、濃縮マイクロサテライトライブラリーのスクリーニング、転写プロファイリングcDNA−AFLP(デジタルノーザン)の実行、複雑なゲノムのシークエンシング、ESTライブラリーのシークエンシング(全体のcDNA又はcDNA−AFLPについて)、マイクロRNAの発見(小さなインサートライブラリーのシークエンシング)、バクテリア人工染色体(BAC)(コンティグ)シークエンシング、バルクセグレガント分析アプローチのAFLP/cDNA−AFLP、例えばマーカー利用戻し交配(MABC)のための、AFLP断片のルーチンの検出等を含む。
【0010】
定義
以下の説明及び実施例において、多くの用語が使用される。そのような用語に与えられる範囲を含む、明細書及び請求項についての明確で一貫した理解を提供するために、以下の定義が提供される。特別に本明細書において定義されないならば、使用される全ての技術的用語及び科学的用語は、本発明が属する技術分野における当業者によって一般に理解されるものと同一の意味を有する。全ての出版物、特許出願、特許及び他の参考文献の開示は、参照によりそれら全体は本明細書において援用される。
【0011】
多型性:多型性は、集団中のヌクレオチド配列の2つ以上の変異型の存在を指す。多型性は1つ又は複数の塩基変化、塩基挿入、塩基反復、又は塩基欠失を含んでもよい。多型性は、例えば、単純反復配列(SSR)及び一塩基多型(SNP)を含み、それらはアデニン(A)、チミン(T)、シトシン(C)、又はグアニン(G)の単一のヌクレオチドが変わったときに生じる変異である。集団の通常少なくとも1%で変異が生じたものが、SNPと考えられる。SNPは、例えば全てのヒト遺伝的変異の90%を占め、ヒトゲノムにわたって100〜300塩基ごとに起こるものである。3つのSNP当たり2つのSNPは、チミン(T)によってシトシン(C)が置換される。DNA塩基配列の変異は、例えば、ヒト又は植物がどのように疾患、細菌、ウイルス、化学薬品、薬剤等を扱うかに影響し得る。
【0012】
核酸:本発明に記載の核酸は、ピリミジン塩基及びプリン塩基の任意のポリマー又はオリゴマー、好ましくはシトシン、チミン及びウラシル、並びにアデニン及びグアニンをそれぞれ含んでもよい(Albert L. Lehninger著「生化学の原理(Principles of Biochemistry)」,793-800(Worth Pub. 1982)を参照、これは全ての目的のためにその全体を参照により本明細書において援用される)。本発明は、下記の塩基のメチル化された形式、ヒドロキシメチル化された形式又は糖鎖が付加した形式等のような、任意のデオキシリボヌクレオチド、リボヌクレオチド又はペプチド核酸、及びそれら任意の化学的な変異型も検討する。ポリマー又はオリゴマーは、組成物中で不均質また均質であってもよく、天然に存在するソースから単離するか又は人為的若しくは合成的に生成されてもよい。さらに核酸は、DNA又はRNA、又はそれらの混合物であってもよく、恒久的に又は一時的に、ホモ二本鎖、ヘテロ二本鎖、及びハイブリッド状態を含む、一本鎖型又は二本鎖型で存在してもよい。
【0013】
複雑度の減少:用語「複雑度の減少」は、サンプルのサブセットの生成によって、ゲノムDNAのような核酸サンプルの複雑度を減少させる方法を意味するために使用する。このサブセットはサンプル全体(すなわち複雑である)の代表になることができ、好ましくは再現可能なサブセットである。本文脈において、再現可能は、同一の方法を使用して、同一のサンプルの複雑度が減少される場合、同じ又は少なくとも同程度のサブセットが得られることを意味する。複雑度の減少のために使用される方法は、当該技術分野において既知である複雑度の減少のための任意の方法であってもよい。複雑度の減少のための方法の例は、例えば、AFLP(登録商標)(Keygene N.V.、オランダ;例えば欧州特許第0,534,858号を参照)、Dongにより記述された方法(例えば、国際公開特許第WO03/012118号、同第WO00/24939号を参照)、インデックスリンク(indexed linking)(Unrau et al.、以下参照)等を含む。本発明で使用される複雑度の減少方法は、それらが再現可能であることが共通である。同一のサンプルが同一の様式で複雑度が減少される場合に、サンプルの同一のサブセットが得られるという意味における再現性については、顕微解剖、又は選択された組織で転写されたゲノムの一部を表わし、その再現性については、組織の選択、単離時期等への依存があるmRNA(cDNA)の使用のような、より無作為な複雑度の減少に対立するものである。
【0014】
タグ付け:用語「タグ付け」は、核酸サンプルを第2の核酸サンプル又はさらなる核酸サンプルと区別することを可能にするために、核酸サンプルへタグを追加することを指す。タグ付けは、例えば、複雑度の減少の間の配列識別子の追加により、又は当該技術分野において既知である任意の他の手段により行なうことができる。そのような配列識別子は、特異的な核酸サンプルの同定のために独自に使用される、例えば一様でないが、定義された長さのユニーク塩基配列であり得る。その代表例は、例えばZIP配列である。そのようなタグを使用して、その後の加工に際して、サンプルの起源を決定することができる。異なる核酸サンプルから生じる加工生成物を組み合わせる場合には、異なる核酸サンプルは異なるタグを使用して同定されるべきである。
【0015】
タグ付けしたライブラリー:用語「タグ付けしたライブラリー」は、タグを付けた核酸のライブラリーを指す。
【0016】
シークエンシング:用語「シークエンシング」は、核酸サンプル、例えばDNA又はRNA中のヌクレオチド(塩基配列)の順番を決定することを指す。
【0017】
アライメントさせること及びアライメント:用語「アライメントさせること」及び「アライメント」により、同一又は同様のヌクレオチドの、短い又は長い一続きのものの存在に基づいた、2つ以上のヌクレオチド配列の比較が意味される。さらに以下で説明されるように、ヌクレオチド配列のアライメントのためのいくつかの方法は、当該技術分野において既知である。
【0018】
検出プローブ:用語「検出プローブ」は、特異的なヌクレオチド配列、特に1つ又は複数の多型性を含む配列の検出のために設計されたプローブを示すために使用される。
【0019】
ハイスループットスクリーニング:HTSとしばしば略されるハイスループットスクリーニングは、特に生物学分野及び化学分野に関連する、科学的な実験作業のための方法である。最新のロボット工学と他の特殊な研究室ハードウェアとの組合せによって、研究者が効果的に同時に大量のサンプルをスクリーニングすることを可能にする。
【0020】
検査サンプルの核酸:用語「検査サンプルの核酸」は、本発明の方法を使用して、多型性について調査される核酸サンプルを示すために使用される。
【0021】
制限エンドヌクレアーゼ:制限エンドヌクレアーゼ又は制限酵素は、二本鎖DNA分子中の特異的なヌクレオチド配列(標的部位)を認識し、標的部位ごとにDNA分子の両方の鎖を切断する酵素である。
【0022】
制限断片:制限エンドヌクレアーゼによる消化により生成されたDNA分子は制限断片と呼ばれる。任意の所定のゲノム(又はその起源にかかわらず核酸)は、特定の制限エンドヌクレアーゼにより、制限断片の不連続なセットへと消化されるだろう。制限エンドヌクレアーゼ切断に由来するDNA断片は、様々な技法の中でさらに使用することができ、例えばゲル電気泳動法により検出することができる。
【0023】
ゲル電気泳動法:制限断片を検出するために、サイズに基づいて二本鎖DNA分子を分画するための分析方法が必要になる。そのような分画を達成するために、最も一般に用いられている技法は、(キャピラリー)ゲル電気泳動法である。DNA断片のそのようなゲル中での移動率は、DNA断片の分子量に依存する。したがって、断片長が増加するにつれて、移動距離は減少する。ゲル電気泳動法により分画されたDNA断片は、染色手順、例えば、パターンの中に含まれた断片数が十分に少ない場合には、銀染色法又はエチジウムブロマイドを使用する染色により直接可視化することができる。或いは、DNA断片のさらなる処理では、蛍光色素分子又は放射性標識のような、断片において検出可能な標識を取り込んでもよい。
【0024】
ライゲーション:2つの二本鎖DNA分子を共有結合で共に連結させるリガーゼ酵素により触媒された酵素反応は、ライゲーションと呼ばれる。一般に、両方のDNA鎖は共有結合で共に連結されるが、鎖の末端の1つの化学的修飾又は酵素的修飾によって、2つの鎖のうちの1つの鎖のライゲーションを防ぐことも可能である。その場合には、共有結合が2つのDNA鎖のうちの1つだけにおいて起こるだろう。
【0025】
合成オリゴヌクレオチド:化学的に合成することができる、好ましくは約10〜約50塩基を有する一本鎖DNA分子は、合成オリゴヌクレオチドと呼ばれる。関連した配列を有する分子のファミリーを合成することは可能であり、それはヌクレオチド配列中の特異的な位置で異なるヌクレオチド組成を有しているが、一般に、これらの合成DNA分子は、特有なヌクレオチド配列又は望ましいヌクレオチド配列を有するように設計される。用語「合成オリゴヌクレオチド」は、設計されたヌクレオチド配列又は望ましいヌクレオチド配列を有するDNA分子を指すために使用されるだろう。
【0026】
アダプター:限られた数の塩基対、例えば約10〜約30塩基対の長さを有する短い二本鎖DNA分子は、制限断片の末端にライゲーションすることができるように設計されている。アダプターは、通常互いに部分的に相補的なヌクレオチド配列がある2つの合成オリゴヌクレオチドから成る。適切な条件下で、溶液中で2つの合成オリゴヌクレオチドを混合した場合、それらはアニーリングして、互いに二本鎖構造を形成するだろう。アニーリング後、アダプター分子の1つの末端は制限断片の末端と適合し、末端でライゲーションすることができるように設計されている。アダプターのもう1つの末端は、ライゲーションできないように設計することができるが、そうである必要はない(二重にライゲーションされたアダプター)。
【0027】
アダプターにライゲーションされた制限断片:アダプターによりキャッピングされた制限断片。
【0028】
プライマー:一般に、用語「プライマー」は、DNAの合成をプライミングすることができるDNA鎖を指す。DNAポリメラーゼは、プライマーなしではDNAをデノボ合成することができない:アセンブリングされるヌクレオチドの順序を指定するために、鋳型として相補的な鎖が用いられるような反応において、DNAポリメラーゼは既存のDNA鎖のみを伸長することができる。本発明者等は、プライマーとして、ポリメラーゼ連鎖反応(PCR)において用いられる合成オリゴヌクレオチド分子を指すだろう。
【0029】
DNAの増幅:用語「DNAの増幅」は、典型的には、PCRを用いた二本鎖DNA分子のin vitroの合成を示すために用いられるだろう。他の増幅方法が存在し、それらは主旨から外れずに、本発明において用いられてもよいことが留意される。
【図面の簡単な説明】
【0030】
【図1A】ビーズ(「454ビーズ」)上にアニーリングされた本発明に記載の断片、及び2つのコショウ系統の前増幅に用いられたプライマーの配列を示す図である。「DNA断片」は制限エンドヌクレアーゼで消化後に得られた断片を表わし、「鍵遺伝子アダプター」はライブラリーを生成するために用いられる(リン酸化された)オリゴヌクレオチドプライマーのためのアニーリング部位を提供するアダプターを表わし、「KRS」は識別子配列(タグ)を表わし、「454SEQ.アダプター」はシークエンシングアダプターを表わし、「454PCRアダプター」はDNA断片のエマルジョン増幅を可能にするアダプターを表わす。PCRアダプターはビーズへのアニーリング及び増幅を可能にし、3’−T突出部を含んでもよい。
【図1B】複雑度の減少工程において用いられる図解プライマーを示す図である。そのようなプライマーは、通常(2)として示された認識部位領域、(1)として示されたタグセクションを含む定常領域、及びその3’末端で(3)として示された選択的領域の1つ又は複数の選択的なヌクレオチドを含む。
【図2】2%のアガロースゲル電気泳動を用いた、DNA濃度の推定を示す図である。S1はPSP11を表わし、S2はPI201234を表わす。50、100、250及び500ngは、Sl及びS2のDNA量を推定するために、50ng、100ng、250ng及び500ngをそれぞれ表わす。(C)及び(D)は、ナノドロップ分光測光法を用いた、DNA濃度測定を示す図である。
【図3】実施例3の中間の品質査定の結果を示す図である。
【図4】(A)は配列データの加工パイプラインのフローチャート、すなわち、トリミング及びタグ付け(Trimming & Tagging)においてトリミングされた配列データをもたらす既知の配列情報の除去の工程を介して、シークエンシングデータの生成から、推定上のSNP、SSR及びインデルを同定する工程で、コンティグ及びシングルトン(コンティグ中にアセンブリングできない断片)を産出するためにクラスタリング及びアセンブリングを行い、その後推定上の多型性を同定及び評価することができる工程を示す図である。(B)は、さらに多型性抽出の過程を詳述する図である。
【図5A】混合したタグの問題に焦点を当て、パネル1に、サンプル1(MS1)及びサンプル2(MS2)に関連したタグを伴う、混合したタグの例を提供する図である。パネル2は、この現象の図解の説明を提供する。サンプル1(S1)及びサンプル2(S2)に由来したAFLP制限断片は、サンプル特異的なタグのS1及びS2を伴う両側で、アダプター(「鍵遺伝子アダプター」)とライゲーションされる。増幅及びシークエンシングの後で、e期待された断片はS1−S1タグを有する断片及びS2−S2タグを有する断片である。さらに、予想外に観察されるものはタグS1−S2を伴う断片又はS2−S1を伴う断片でもある。
【図5B】パネル3は、ヘテロ二本鎖産物がサンプル1及びサンプル2からの断片から形成される、混合したタグの生成の仮説的な原因について説明する。T4 DNAポリメラーゼ又はクレノウの3’−5’エキソヌクレアーゼ活性により、続いてヘテロ二本鎖では3’突出末端が無くなる。重合の間に、ギャップはヌクレオチドで満たされ、間違ったタグが導入される。これは、ほぼ同様の長さ(上部のパネル)のヘテロ二本鎖に作動するが、より長さが変化するヘテロ二本鎖に対しても作動する。
【図5C】パネル4は、混合したタグの形成をもたらす従来のプロトコルを右側に、及び修飾されたプロトコルを右側に提供する。
【図6A】コンカテマー形成の問題に焦点を当て、パネル1においてコンカテマーの代表例を挙げ、様々なアダプター及びタグ区分には、それらの起源で下線を引く(すなわち、サンプル1からのMseI制限部位アダプター、サンプル2からのMseI制限部位アダプター、サンプル1からのEcoRI制限部位アダプター、サンプル2からのEcoRI制限部位アダプターに、それぞれ対応するMS1、MS2、ES1及びES2)。パネル2は、S1−S1タグ及びS2−S2タグを伴う、期待された断片、及び観察されたが期待されないサンプル1及びサンプル2からの断片のコンカテマーである、S1−S1−S2−S2を明示する。
【図6B】混合したタグと同様に、AFLPアダプターに突出部を導入すること、修飾されたシークエンシングアダプター、及びシークエンシングアダプターをライゲーションする場合の末端を平滑にする工程の省略によって、コンカテマーの生成を回避するパネル3の解決法。ALP断片が互いにライゲーションすることができないのでコンカテマー形成が見られず、末端を平滑にする工程が省略できないので混合した断片は発生しない。
【図6C】パネル4は、混合したタグと同様に、コンカテマー形成を回避するために、修飾されたアダプターを用いた修飾されたプロトコルを提供する。
【図7】推定上の一塩基多型(SNP)を含む、コショウAFLP断片配列の多重アライメント「10037_CL989contig2」を示す図である。SNP(黒い矢印によって示された)は、上部の2つの読み取りの名称中のMS1タグの存在によって表わされた、サンプル1(PSP11)の両方の読み取りにあるA対立遺伝子、及び下部2つ読み取りの名称中のMS2タグの存在によって表わされた、サンプル2(PI201234)にあるG対立遺伝子によって定義されることに留意されたい。読み取りの名称は左側に示される。この多重アライメントのコンセンサス配列は次のとおりである(5’−3’):
【化1】

【図8A】新たな単純反復配列(SSR)の発見のためのハイスループットシークエンシングと組み合わせたSSRを標的とした濃縮戦略の略図である。
【図8B】SNPWave検出を用いるコショウ中のG/A SNPの検証を示す図である。P1=PSP11、P2=PI201234。8つのRILの子孫が番号1〜8によって示される。
【発明を実施するための形態】
【0031】
本発明は、1つ又は複数の多型性の同定のための方法を提供し、
a)対象となる第1の核酸サンプルを提供する工程と、
b)対象となる第1の核酸サンプルについて複雑度の減少を行ない、第1の核酸サンプルの第1のライブラリーを提供する、工程と、
c)対象となる第2の核酸サンプル又はさらなる核酸サンプルにより、連続的に又は同時に工程a)及び工程b)を行ない、対象となる第2の核酸サンプルの第2のライブラリー又はさらなる核酸サンプルのさらなるライブラリーを得る、工程と、
d)第1のライブラリー及び第2のライブラリー又はさらなるライブラリーの少なくとも一部をシークエンシングする工程と、
e)工程d)において得られた配列をアライメントさせる工程と、
f)工程e)のアライメントにおいて、第1の核酸サンプル及び第2の核酸サンプル又はさらなる核酸サンプルの間の1つ又は複数の多型性を決定する工程と、
g)工程f)において決定された1つ又は複数の多型性を用い、1つ又は複数の検出プローブを設計する、工程と、
h)対象となる検査サンプルの核酸を提供する工程と、
i)対象となる検査サンプルの核酸について工程b)の複雑度の減少を行ない、検査サンプルの核酸の検査ライブラリーを提供する、工程と、
j)検査ライブラリーをハイスループットスクリーニングして、工程g)において設計された1つ又は複数の検出プローブを用いて、工程f)において決定された多型性の存在、多型性の非存在、又は多型性の量を同定する、ハイスループットスクリーニングする工程と
を含む。
【0032】
工程a)では、対象となる第1の核酸サンプルが提供される。対象となる上記第1の核酸サンプルは、好ましくは、全ゲノムDNA又はcDNAライブラリーのような複雑な核酸サンプルである。複雑な核酸サンプルが全ゲノムDNAであることが好ましい。
【0033】
工程b)では、複雑度の減少は、第1の核酸サンプルの第1のライブラリーを提供するために、対象となる第1の核酸サンプルについて行なわれる。
【0034】
本発明の1つの実施形態において、核酸サンプルの複雑度の減少の工程は、制限断片の核酸サンプルを酵素で切断すること、制限断片を分離すること、及び制限断片の特定のプールを選択することを含む。その後任意で、選択された断片は、PCRプライマー鋳型/結合配列を含むアダプター配列にライゲーションされる。
【0035】
複雑度の減少の1つの実施形態において、II型エンドヌクレアーゼは核酸サンプルを消化するために用いられ、制限断片はアダプター配列に選択的にライゲーションされる。アダプター配列は、ライゲーションされる突出部に様々なヌクレオチドを含むことが可能であり、突出部でヌクレオチドの適合セットを有するアダプターのみが、断片にライゲーションされ、続いて増幅される。この技術は、当該技術分野において、「インデックスリンカー」として表現される。この原理の例は、とりわけUnrau P.及びDeugau K.V.(1994)Gene 145:163-169で見出すことができる。
【0036】
別の実施形態において、複雑度の減少の方法は、異なる標的部位及び異なる頻度を有する2つの制限エンドヌクレアーゼ、及び2つの異なるアダプター配列を利用する。
【0037】
本発明の別の実施形態において、複雑度の減少の工程は、サンプルで任意配列プライマーPCRを行なうことを含む。
【0038】
本発明のさらに別の実施形態において、複雑度の減少の工程は、DNAの変性及びDNA再アニーリングによって反復配列を除去すること、及びその後二本鎖二重鎖(double-stranded duplexes)を除去することを含む。
【0039】
本発明の別の実施形態において、複雑度の減少の工程は、望ましい配列を含むオリゴヌクレオチドプローブに結合された磁気ビーズへ核酸サンプルをハイブリダイズすることを含む。この実施形態は、ハイブリダイズされたサンプルを一本鎖DNAヌクレアーゼに暴露し、一本鎖DNAを除去する暴露すること、クラスII制限酵素を含むアダプター配列をライゲーションし、磁気ビーズを遊離するライゲーションすることをさらに含んでもよい。この実施形態は、単離されたDNA配列の増幅を含んでもよいし、含まなくてもよい。さらに、アダプター配列は、PCRオリゴヌクレオチドプライマーのための鋳型として用いられてもよいし、用いられなくてもよい。この実施形態において、アダプター配列は配列識別子又はタグを含んでもよいし、含まなくてもよい。
【0040】
別の実施形態において、複雑度の減少の方法は、ミスマッチ結合タンパク質にDNAサンプルを暴露すること、及びサンプルをエキソヌクレアーゼそしてその後一本鎖ヌクレアーゼで、3’から5’方向へ消化することを含む。この実施形態は、ミスマッチ結合タンパク質に結合された磁気ビーズの使用を含んでもよいし、含まなくてもよい。
【0041】
本発明の別の実施形態において、複雑度の減少は、本明細書の他の部分に記述されるようなCHIP法、又はSSR、NBS領域(ヌクレオチド結合領域)、プロモーター/エンハンサー配列、テロマーコンセンサス配列、MADSボックス遺伝子、ATPアーゼ遺伝子ファミリー、及び他の遺伝子ファミリーのような保存モチーフに対するPCRプライマーの設計を含む。
【0042】
工程c)において、対象となる第2の核酸サンプルの第2のライブラリー又はさらなる核酸サンプルのさらなるライブラリーを得るために、対象となる第2の核酸サンプル又はさらなる核酸サンプルにより、工程a)及び工程b)は連続的又は同時に行なわれる。対象となる当該第2の核酸サンプル又は当該さらなる核酸サンプルは、好ましくは全ゲノムDNAのような複雑な核酸サンプルでもある。複雑な核酸サンプルが全ゲノムDNAであることが好ましい。当該第2の核酸サンプル又は当該さらなる核酸サンプルが、第1の核酸サンプルに関連していることがさらに好ましい。第1の核酸サンプル及び第2の核酸又はさらなる核酸は、例えば異なるコショウ系統のような異なる植物の系統又は異なる変種であってもよい。工程a)及び工程b)は、単に対象となる第2の核酸サンプルについて行なわれてもよいが、さらに対象となる第3の核酸サンプル、第4の核酸サンプル、第5の核酸サンプル等で行なわれてもよい。
【0043】
第1の核酸サンプル及び第2の核酸サンプル又はさらなる核酸サンプルに、同様な方法を用いて、実質的に同等の条件下、好ましくは同一の条件下で、複雑度の減少が行なわれた場合、本発明に記載の方法が最も有用になることに留意されたい。そのような条件下では、(複雑な)核酸サンプルの同様の(匹敵する)画分が得られるだろう。
【0044】
工程d)において、第1のライブラリー及び第2のライブラリー又はさらなるライブラリーの少なくとも一部はシークエンシングされる。第1のライブラリー、第2のライブラリー又はさらなるライブラリーからシークエンシングされた断片のオーバーラップの量は、少なくとも50%、より好ましくは少なくとも60%、さらにより好ましくは少なくとも70%、より一層好ましくは少なくとも80%、さらにより好ましくは少なくとも90%、及び最も好ましくは少なくとも95%が好ましい。
【0045】
シークエンシングは、ダイデオキシ連鎖停止法のような、当該技術分野において既知である任意の手段によって、原則としては行われてもよい。しかしながら、シークエンシングは、国際公開特許第WO03/004690号、同第WO03/054142号、同第WO2004/069849号、同第WO2004/070005号、同第WO2004/070007号及び同第WO2005/003375号(Seo et al. (2004) Proc. Natl. Acad. Sci. USA 101:5488-93)に(全て454コーポレーションの名で)開示された方法のようなハイスループットシークエンシング法、及びヘリオス(Helios)、ソレクサ(Solexa)、USゲノミクス(US Genomics)等の技術(これらは参照により本明細書において援用される)を用いて行なわれることが好ましい。シークエンシングは、国際公開特許第WO03/004690号、同第WO03/054142号、同第WO2004/069849号、同第WO2004/070005号、同第WO2004/070007号、及び同第WO2005/003375号に(全て454コーポレーションの名で)開示された装置及び/又は方法を用いて行なわれることが最も好ましく、それらは参照により本明細書において援用される。記述された技術は、一回の実行において4000万塩基のシークエンシングを可能にし、競合技術よりも100倍速く、より安い。シークエンシング技術は、1)DNAの切断及び一本鎖DNA(ssDNA)のライブラリーに特異的なアダプターのライゲーションと、2)ビーズに対するssDNAのアニーリング、及び油中水滴型マイクロリアクター中のビーズの乳化と、3)PicoTiterPlate(登録商標)におけるDNAを伴うビーズの沈着と、4)ピロリン酸光シグナルの生成による100,000ウェルの同時シークエンシングとのおおまかには4つの工程から成る。この方法はより詳細に以下で説明されるだろう。
【0046】
工程e)において、工程d)で得た配列はアライメントを提供するためにアライメントされる。比較目的のための配列のアライメントの方法は、当該技術分野において既知である。様々なプログラム及びアライメントアルゴリズムは、Smith及びWaterman(1981)Adv. Appl. Math. 2:482; Needleman及びWunsch(1970)J. Mol. Biol. 48:443; Pearson及びLipman(1988)Proc. Natl. Acad. Sci. USA 85:2444; Higgins及びSharp(1988)Gene 73:237-244; Higgins及びsharp(1989)CABIOS 5:151-153; Corpet et al.(1988)Nucl. Acids Res. 16:10881-90; Huang et al.(1992)Computer Appl. in the Biosci. 8:155-65;及びPearson et al.(1994)Meth. Mol. Biol. 24:307-31において記述され、これらは本明細書において参照により援用される。Altschul et al.(1994)Nature Genet. 6:119-29(本明細書において参照により援用される)は、配列アラインメントの方法及び相同性の計算について詳細な考察を提供する。
【0047】
NCBIの基本的局所アライメント検索ツール(Basic Local Alignment Search Tool)(BLAST)(Altschul et al., 1990)は、配列解析プログラムのblastp、blastn、blastx、tblastn、及びtblastxに関連する使用について、国立生体情報センター(National Center for Biological Information)(NCBI、メリーランド州ベテスダ)及びインターネット上を含むいくつかのソースから利用可能である。それは<http://www.ncbi.nlm.nih.gov/BLAST/>でアクセスすることができる。このプログラムを用いて、配列同一性を決定する方法の説明は、<http://www.ncbi.nlm.nih.gov/BLAST/blast_help.html>で利用可能である。さらなる適用は、マイクロサテライトの抽出において可能である(Varshney et al. (2005) Trends in Biotechn. 23(1) :48-55を参照)。
【0048】
典型的には、アライメントは、アダプター/プライマー及び/又は識別子をトリミングした(すなわち、核酸サンプルから生じる断片からの配列データのみを用いて)配列データ上で行なわれる。典型的には、得られた配列データは、断片の起源を同定するため(すなわち、どのサンプルから)に用いられ、アダプター及び/又は識別子に由来した配列はデータから取り除かれ、アライメントはこのトリミングされたセット上で行なわれる。
【0049】
工程f)において、1つ又は複数の多型性は、アライメントにおいて、第1の核酸サンプル及び第2の核酸サンプル又はさらなる核酸サンプルの間で決定される。第1の核酸サンプル及び第2の核酸サンプル又はさらなる核酸サンプルに由来した配列を比較することができるように、当該アライメントは作られる。その後、違いは多型性を反映して同定することができる。
【0050】
工程g)において、工程g)で決定された1つ又は複数の多型性は、例えばDNAチップ又はビーズに基づいた検出プラットフォーム上のハイブリダイゼーションによる検出のための、検出プローブを設計するために用いられる。多型性が反映されるように、検出プローブは設計される。一塩基多型(SNP)の場合には、検出プローブは、典型的には、対立遺伝子識別を最大限にするような中央の位置での変異SNP対立遺伝子を含む。そのようなプローブは、或る特定の多型性がある検査サンプルをスクリーニングするのに有利に用いることができる。プローブは、当該技術分野において既知の任意の方法を用いて合成することができる。プローブは、典型的にはハイスループットスクリーニング法に適切なように設計される。
【0051】
工程h)において、対象となる検査サンプルの核酸が提供される。検査サンプルの核酸は任意のサンプルであってもよいが、好ましくは多型性についてマップされる別の系統又は変種であってもよい。一般に、研究された生物の生殖質を表わす検査サンプルのコレクションを、(SN)多型性が純種であり検出可能であることを実験的に検証するために、及び観察された対立遺伝子の対立遺伝子頻度を計算するために用いる。任意で、遺伝学的マッピング集団のサンプルも、多型性の遺伝学的地図の位置を決定するために、検証工程に含まれる。
【0052】
工程i)において、工程b)の複雑度の減少は、検査サンプルの核酸の検査ライブラリーを提供するために、対象となる検査サンプルの核酸について行なわれる。本発明に記載の方法の全体にわたって、複雑度の減少のために同様な方法が、実質的に同等な、好ましくは同一の条件を用いて、それによりサンプルの同様の画分をカバーして、用いられることは非常に好ましい。しかしながら、タグが検査ライブラリーにおいて断片上に存在してもよいが、タグを付けた検査ライブラリーを得ることは必要とされない。
【0053】
工程j)において、工程g)で設計された検出プローブを用いて、工程f)で決定された多型性の存在、多型性の非存在、又は多型性の量を同定するために、検査ライブラリーでハイスループットスクリーニングを行なう。当業者は、プローブを用いたハイスループットスクリーニングのためのいくつかの方法を知っている。工程g)で得られた情報を用いて設計された1つ又は複数のプローブが、DNAチップのようなアレイ上に固定され、続いてそのようなアレイが、ハイブリダイズする条件下で検査ライブラリーと接触されることが好ましい。アレイ上の1つ又は複数のプローブに相補的な検査ライブラリー中のDNA断片は、そのような条件下でそのようなプローブにハイブリダイズし、したがって検出することができる。工程j)で得られた検査ライブラリーを固定化させること、及びハイブリダイズする条件下で、上記の固定された検査ライブラリーを、工程h)で設計されたプローブと接触させることのような、ハイスループットスクリーニングの他の方法も、本発明の範囲内で意図される。
【0054】
別のハイスループットシークエンシングスクリーニング技法は、とりわけSNPのチップに基づいた検出を用いてAffymetrixによって提供され、ビーズ技術がIlluminaによって提供される。
【0055】
有利な実施形態において、本発明に記載の方法の工程b)は、タグを付けたライブラリーを得るためにライブラリーをタグ付けする工程をさらに含み、当該方法は、組合せライブラリーを得るための第1のタグを付けたライブラリー及び第2のタグを付けたライブラリー又はさらなるタグを付けたライブラリーを組み合わせる工程c1)をさらに含む。
【0056】
タグ付けは、第1の核酸サンプルの第1のタグを付けたライブラリーを得るのに必要な工程の量を減少させるように、複雑度の減少の工程の間に行なわれることが好ましい。そのような同時のタグ付けは、例えば、各々のサンプルに対する特有の(ヌクレオチド)識別子を含むアダプターを用いて、AFLPにより達成することができる。
【0057】
タグ付けは、2つ以上の核酸サンプルのライブラリーが、組合せライブラリーを得るために組み合わせられる場合、異なる起源の、例えば異なる植物系統から得られたサンプルを識別するように意図される。したがって好ましくは、異なるタグは、第1の核酸サンプル及び第2の核酸サンプル又はさらなる核酸サンプルのタグを付けたライブラリーの調製に用いられる。例えば、5つの核酸サンプルが用いられる場合、5つの異なるタグ(それぞれのもとのサンプルを示す5つの異なるタグ)を付けられたライブラリーを得ることが意図される。
【0058】
タグは、核酸サンプルの識別のための当該技術分野において既知の任意のタグであってもよいが、好ましくは短い識別子配列である。そのような識別子配列は、例えば、複雑度の減少によって得られたライブラリーの起源を示すために用いられる、長さが変化する非反復塩基配列であり得る。
【0059】
好ましい実施形態において、第1のライブラリー及び第2のライブラリー又はさらなるライブラリーのタグ付けは、異なるタグを用いて行なわれる。上に説明されるように、核酸サンプルのライブラリーは、各々自身のタグによって同定されることが好ましい。検査サンプルの核酸はタグ付けの必要はない。
【0060】
本発明の好ましい実施形態において、複雑度の減少は、AFLP(登録商標)(Keygene N.V.(オランダ);例えば、欧州特許第0,534,858号及びVos et al.(1995)著「AFLP:DNAフィンガープリントのための新しい技法(AFLP: a new technique for DNA fingerprinting)」Nucleic Acids Research, vol. 23, no. 21, 4407-4414を参照、これらは参照によってそれらの全体を本明細書において援用される)によって行なわれる。
【0061】
AFLPは選択的制限断片増幅のための方法である。AFLPは任意の事前配列情報は無く、任意の開始DNAで行なうことができる。一般にAFLPは、
(a)核酸、特にDNA又はcDNAを1つ又は複数の特異的な制限エンドヌクレアーゼで消化して、対応する一連の制限断片へとDNAを断片化する工程と、
(b)このように得られた制限断片を、1つの末端が1つ又は両方の制限断片の末端と適合する二本鎖合成オリゴヌクレオチドアダプターとライゲーションして、アダプターでライゲーションされた(好ましくは、タグ付けされた)開始DNAの制限断片を生成する工程と、
(c)アダプターでライゲーションされた(好ましくは、タグ付けされた)制限断片を、ハイブリダイズする条件下で、その3’−末端で少なくとも1つの選択的なヌクレオチドを含む少なくとも1つのオリゴヌクレオチドプライマーと接触させる工程と、
(d)プライマーとハイブリダイズされたアダプターでライゲーションされた(好ましくは、タグ付けされた)制限断片を、プライマーがハイブリダイズする開始DNAの制限断片に沿ってハイブリダイズされたプライマーのさらなる伸長を引き起こすように、PCR又は同様の技術によって増幅する工程と、
(e)このように得られた増幅又は伸長したDNA断片を、検出、同定、又は回収する工程
を含む。
【0062】
AFLPは、このようにアダプターにライゲーションされた断片の再現可能なサブセットを提供する。他の複雑度の減少に適切な方法は、クロマチン免疫沈降(ChiP)である。これは、転写因子のようなタンパク質がDNAに結合している間に、核DNAが単離されることを意味する。ChiPでは、最初に抗体はタンパク質に対して用いられ、Ab−タンパク質−DNA複合体をもたらす。この複合体を精製し、それを沈殿させることによって、このタンパク質が結合するDNAが選択される。続いて、DNAはライブラリー構築及びシークエンシングに用いることができる。すなわち、これは、特異的な機能的領域に向けられた、無作為でない様式において複雑度の減少を行なう方法であり、本発明の例では特異的転写因子である。
【0063】
1つのAFLP技術の有用な変形は、非選択的なヌクレオチド(すなわち+0/+0プライマー)を用い、これはしばしばリンカーPCRと呼ばれる。これは、さらに非常に適切な複雑度の減少を提供する。
【0064】
AFLP、その利点、技法と同様にその実施形態、酵素、アダプター、プライマー及びさらなる化合物、並びに本明細書で使用した道具のさらなる説明のために、米国特許第6,045,994号、並びに欧州特許第0,534,858号(B)及び同第976835号及び同第974672号、国際公開特許第WO01/88189号、及びVos et al.Nucleic Acids Research, 1995, 23, 4407-4414が言及され、これらはそれら全体が本明細書に援用される。
【0065】
したがって、本発明の方法の好ましい実施形態において、複雑度の減少は、
− 少なくとも1つの制限エンドヌクレアーゼにより核酸サンプルを消化して、制限断片へ断片化すること、
− 1つ又は両方の制限断片の末端と合うような1つの末端を有する、少なくとも1つの二本鎖合成オリゴヌクレオチドアダプターで得られた制限断片をライゲーションして、アダプターにライゲーションされた制限断片を生成すること、
− ハイブリダイズする条件下で、アダプターにライゲーションされた上記制限断片を、1つ又は複数のオリゴヌクレオチドプライマーと接触させること、及び
− 1つ又は複数のオリゴヌクレオチドプライマーの伸長によって、アダプターにライゲーションされた上記制限断片を増幅することにより行なわれ、
ここで1つ又は複数のオリゴヌクレオチドプライマーの少なくとも1つが、上記制限エンドヌクレアーゼのための標的配列の形成に関与するヌクレオチドを含み、アダプターの存在するヌクレオチドの少なくとも一部を含む、アダプターにライゲーションされた上記制限断片の末端で鎖の端末部分と同じヌクレオチド配列を有するヌクレオチド配列を含み、ここで任意で、当該プライマーの少なくとも1つは、その3’末端で、当該制限エンドヌクレアーゼのための標的配列の形成に関与するヌクレオチドにすぐに隣接して位置する少なくとも1つのヌクレオチドを含む選択された配列を含む。
【0066】
AFLPは、複雑度の減少のための高度に再現可能な方法であり、したがって本発明に記載の方法に対して特に適している。
【0067】
本発明に記載の方法の好ましい実施形態において、アダプター又はプライマーはタグを含む。個別のライブラリーに由来した配列を識別することが重要な場合、特に実際の多型性の同定についてはそうである。ライブラリーにタグ付けするために追加の工程が要求されないので、アダプター又はプライマーにオリゴヌクレオチドタグを組み入れることは非常に便利である。
【0068】
別の実施形態において、タグは識別子配列である。上で議論されるように、そのような識別子配列は、比較される核酸サンプルの量に依存して変化する長さであってもよい。区別されるサンプル間で、タグ配列が1塩基を超えて異なることが好ましいが、約4塩基長(44=256、可能な異なるタグ配列)は、限られた数のサンプル(256個まで)の起源を区別するのに十分である。必要に応じて、タグ配列の長さは結果的に調節することができる。
【0069】
一実施形態において、シークエンシングは、ビーズのような固体支持体上で行なわれる(例えば国際公開特許第WO03/004690号、同第WO03/054142号、同第WO2004/069849号、同第WO2004/070005号、同第WO2004/070007号、及び同第WO2005/003375号(全て454コーポレーションの名で)を参照、それらは参照により本明細書において援用される)。そのようなシークエンシング法は、多くのサンプルの安価で効率的な同時シークエンシングに特に適切である。
【0070】
好ましい実施形態において、シークエンシングは、
− 各々のビーズがアダプターにライゲーションされた単一の断片とアニーリングされるビーズへ、アダプターにライゲーションされた断片をアニーリングする工程と、
− 各々の油中水滴型マイクロリアクターが単一のビーズを含む、油中水滴型マイクロリアクター中のビーズの乳化する工程と、
− 各々のウェルが単一のビーズを含む、ウェル中にビーズを充填する工程と、
− ピロリン酸シグナルを生成する工程と
を含む。
【0071】
第1の工程において、シークエンシングアダプターは、組合せライブラリー中の断片へライゲーションされる。当該シークエンシングアダプターは、少なくともビーズへのアニーリングのための「キー」領域、シークエンシングプライマー領域、及びPCRプライマー領域を含む。それにより、アダプターにライゲーションされた断片が得られる。
【0072】
さらなる工程において、アダプターにライゲーションされた断片は、各々のビーズが単一アダプターにライゲーションされた断片にアニーリングする、ビーズへアニーリングされる。大多数のビーズについて、1つのビーズ当たりに、1つの単一アダプターにライゲーションされた断片のアニーリングを保証するように、アダプターにライゲーションされた断片のプールへ、ビーズが過剰に加えられる(ポアソン分布)。
【0073】
次の工程において、各々の油中水滴型マイクロリアクターが単一のビーズを含む、油中水滴型マイクロリアクターでビーズが乳化される。PCR試薬は、PCR反応がマイクロリアクター中で起こることを可能にする油中水滴型マイクロリアクターに存在する。続いて、マイクロリアクターは破壊され、DNAを含むビーズ(DNA陽性ビーズ)が濃縮される。
【0074】
以下の工程において、各々のウェルが単一のビーズを含む、ウェルにビーズが充填される。ウェルは、好ましくは、大量の断片の同時シークエンシングを可能にするPicoTiter(商標)プレートの一部である。
【0075】
酵素を伴うビーズの追加後、断片の配列はピロシークエンシングを用いて決定される。引き続いての工程において、PicoTiterプレート及びビーズは、その中の酵素ビーズと同様に、従来のシークエンシング試薬の存在下で異なるデオキシリボヌクレオチドへ曝され、デオキシリボヌクレオチドの取り込みの際、記録される光シグナルが生成される。正確なヌクレオチドの取り込みにより、検出可能なピロシークエンシングシグナルが生成されるだろう。
【0076】
ピロシークエンシング自体は、当該技術分野において既知であり、とりわけ、www.biotagebio.com;www.pyrosequencing.com / tab technologyで記述される。技術は、例えば、国際公開特許第WO03/004690号、同第WO03/054142号、同第WO2004/069849号、同第WO2004/070005号、同第WO2004/070007号、及び同第WO2005/003375号で(全て454コーポレーションの名で)、さらに適用され、それらは本明細書において参照により援用される。
【0077】
工程k)のハイスループットスクリーニングは、好ましくはアレイ上に工程h)で設計されたプローブの固定化によって行なわれ、その後ハイブリダイズする条件下で、プローブを含むアレイを、検査ライブラリーと接触させる。好ましくは、接触の工程は、ストリンジェントなハイブリダイズ条件下で行なわれる(Kennedy et al.(2003)Nat. Biotech.; published online 7 september 2003: 1-5を参照)。当業者は、アレイ上へのプローブの固定化に適切な方法、及びハイブリダイズする条件下で接触させる方法を承知している。この目的に適切な典型的な技術は、Kennedy et al.(2003)Nat. Biotech.; published online 7 september 2003: 1-5に概説される。
【0078】
1つの特に有利な適用は、倍数体作物の品種改良において見出される。高範囲での倍数体作物のシークエンシング、SNP及び様々な対立遺伝子の同定、並びに対立遺伝子特異的な増幅のためのプローブの開発によって、倍数体作物の品種改良の著しい進歩が可能となった。
【0079】
本発明の一部として、選択的増幅を複数のサンプルに対して用いて無作為に選択されたサブセットの生成と、及びハイスループットシークエンシング技術との組合せは、多型性の効率的なハイスループット同定について、本明細書において記述された方法のさらなる改良のために解決しなければならない、或る特定の複雑な問題を提示することが発見された。より詳細には、複数の(すなわち、第1の及び第2の又はさらなる)サンプルが複雑度の減少を行なった後にプール中で組み合わせられる場合、多くの断片が2つのサンプルに由来するように見える、又は言い換えれば、1つのサンプルへ独自に割り当てることができなかった多くの断片が同定され、したがって多型性を同定する過程の中で用いることができないという問題が起こることが発見された。これは、方法の信頼性の低下及び適切に同定され得る多型性(SNP、インデル、SSR)の減少をもたらす。
【0080】
割り当てることができなかった断片のヌクレオチド配列全体の注意深く詳しい分析の後、それらの断片は2つの異なるタグ含有アダプターを含んでおり、この断片は複雑度を減少させたサンプルの生成とシークエンシングアダプターのライゲーションとの間で恐らく形成されたことが発見された。この現象は「混合したタグ付け」として表現される。したがって本明細書において用いられるように、「混合したタグ付け」として表現される現象は、断片を1つのサンプルへ関連付けるタグを片側で含むが、断片の反対側では断片を他のサンプルへ関連付けるタグを含む断片を指す。したがって、1つの断片は、2つのサンプルに由来するかのように見える(両方とも(quod non))。これは多型性の誤った同定をもたらし、したがって不適当である。
【0081】
2つのサンプル間でヘテロ二本鎖断片の形成が、この異常に進行して存在することが理論付けられた。
【0082】
この問題の解決は、複雑度が減少させられるサンプルを、ハイスループットシークエンシング前に増幅することが可能であるビーズにアニーリングされた断片へ変換するための戦略の再計画において発見された。この実施形態において、各々のサンプルでは複雑度の減少及び任意の精製が行なわれる。その後、各々のサンプルをブラント(末端を平滑)にし、その後ビーズへアニーリング可能なシークエンシングアダプターへライゲーションする。その後、シークエンシングアダプターにライゲーションされた断片のサンプルは組み合わせられ、エマルジョン重合及び続くハイスループットシークエンシングのために、ビーズへライゲーションされる。
【0083】
本発明のさらなる部分として、コンカテマーの形成が多型性の適切な同定を妨げるということが分かった。コンカテマーは、複雑度を減少させた産物が、例えばT4 DNAポリメラーゼによって、「ブラントにされた」又は「平滑にされた」後に形成される断片として同定され、ビーズへのアニーリングを可能にするアダプターへライゲーションする代わりに、互いにライゲーションし、これによってコンカテマーを生成する、すなわちコンカテマーはブラントにされた断片の二量体化の結果である。
【0084】
この問題の解決は、特異的に修飾される或る特定のアダプターの使用において発見された。複雑度の減少から得られた増幅された断片は、典型的には、3’−5’エキソヌクレアーゼプルーフリーディング活性がない或る特定の好ましいポリメラーゼの特性による、3’−A突出部を含む。そのような3’−A突出部の存在もまた、アダプターライゲーション前に、断片をブラントにする理由である。アダプターが3’−T突出部を含み、ビーズへアニーリングすることが可能なアダプターの提供によって、「混合したタグ」及びコンカテマーの両方の問題が、1つの工程の中で解決できることが発見された。これらの修飾したアダプターを用いることのさらなる利点は、従来の「ブラントにする」工程及び続くリン酸化工程を省略することができるということである。
【0085】
したがって、各々のサンプルの複雑度の減少工程の後のさらなる好ましい実施形態において、工程は、複雑度の減少工程から得られたアダプターにライゲーションされた増幅された制限断片上で行なわれ、それによってこれらの断片へシークエンシングアダプターがライゲーションされ、シークエンシングアダプターは3’−T突出部を含み、ビーズへアニーリングすることができる。
【0086】
複雑度の減少工程において用いられるプライマーがリン酸化される場合、ライゲーション前の末端を平滑にする(ブラントにする)工程及び中間のリン酸化は回避できることがさらに発見された。
【0087】
したがって、本発明の非常に好ましい実施形態において、本発明は、1つ又は複数の多型性を同定する方法に関し、
a)対象となる複数の核酸サンプルを提供する工程と、
b)各々のサンプル上で複雑度の減少を行ない、核酸サンプルの複数のライブラリーを提供する、工程であって、複雑度の減少が、
− 少なくとも1つの制限エンドヌクレアーゼにより各々の核酸サンプルを消化して、制限断片へ断片化すること、
− 1つ又は両方の制限断片の末端と合うような1つの末端を有する、少なくとも1つの二本鎖の合成オリゴヌクレオチドアダプターで得られた制限断片をライゲーションして、アダプターにライゲーションされた制限断片を生成すること、
− ハイブリダイズする条件下で、前記アダプターにライゲーションされた制限断片を、1つ又は複数のリン酸化されたオリゴヌクレオチドプライマーと接触させること、及び
− 1つ又は複数のオリゴヌクレオチドプライマーの伸長によってアダプターにライゲーションされた上記制限断片を増幅することであって、ここで1つ又は複数のオリゴヌクレオチドプライマーの少なくとも1つが、上記制限エンドヌクレアーゼのための標的配列の形成に関与するヌクレオチドを含み、アダプターの存在するヌクレオチドの少なくとも一部を含む、アダプターにライゲーションされた当該制限断片の末端で鎖の端末部分と同じヌクレオチド配列を有するヌクレオチド配列を含み、ここで任意で、当該プライマーの少なくとも1つが、その3’末端で、該制限エンドヌクレアーゼのための標的配列の形成に関与するヌクレオチドにすぐに隣接して位置する少なくとも1つのヌクレオチドを含む選択された配列を含み、ここでアダプター及び/又はプライマーがタグを含むこと
によって行なわれる工程と、
c)組合せライブラリーへ上記ライブラリーを組み合わせる工程と、
d)ビーズへアニーリングすることが可能なシークエンシングアダプターを、組合せライブラリー中の増幅されたアダプターでキャッピングされた断片へライゲーションし、3’−T突出部を伴うシークエンシングアダプターを用い、ビーズにアニーリングされた断片をエマルジョン重合する工程と、
e)組合せライブラリーの少なくとも一部をシークエンシングする工程と、
f)工程e)において得られた各々のサンプルからの配列をアライメントさせる工程と、
g)工程f)のアライメントにおいて複数の核酸サンプル間で1つ又は複数の多型性を決定する工程と、
h)工程g)において決定された1つ又は複数の多型性を用いて、検出プローブを設計する工程と、
i)対象となる検査サンプルの核酸を提供する工程と、
j)対象となる検査サンプルの核酸について工程b)の複雑度の減少を行ない、検査サンプルの核酸の検査ライブラリーを提供する、工程と、
k)検査ライブラリーでハイスループットスクリーニングを行ない、工程h)において設計された検出プローブを用いて、工程g)において決定された多型性の存在、多型性の非存在、又は多型性の量を同定する、工程と
を含む。
【実施例1】
【0088】
EcoRI/MseI制限ライゲーション混合物(1)は、コショウの系統PSP−11及びPI20234のゲノムDNAから生成された。制限ライゲーション混合物を10倍に希釈し、5マイクロリットルの各々のサンプルは、EcoRI+1(A)及びMseI+1(C)プライマー(セットI)により前増幅された(2)。増幅後に、2つのコショウのサンプルの前増幅産物の品質を、1%アガロースゲル上でチェックした。前増幅産物を20倍に希釈し、その後KRSEcoRI+1(A)及びKRSMseI+2(CA)AFLP前増幅を行なった。下記のプライマー配列番号1〜4の3’−末端で、KRS(識別子)区分には下線が引かれており、選択的なヌクレオチドは太字とする。増幅後に、2つのコショウのサンプルの前増幅産物の品質を、1%アガロースゲル上で、並びにEcoRI+3(A)及びMseI+3(c) (3) AFLP フィンガープリント(4)によりチェックした。2つのコショウ系統の前増幅産物を、キアゲン(Qiagen)PCRカラムの上で別々に精製した(5)。サンプルの濃度をナノドロップ(nanodrop)で測定した。合計5006.4ngのPSP−11及び5006,4ngのPI20234を混合し、シークエンシングした。
【0089】
PSP−11の前増幅に用いられるプライマーセットI
【化2】
【0090】
PI20234の前増幅に用いられるプライマーセットII
【化3】
【0091】
(1)EcoRI/MseI制限ライゲーション混合物
制限混合物(40ul/サンプル)
DNA 6μl(±300ng)
ECoRI(5U) 0.1μl
MseI(2U) 0.05μl
5×RL 8μl
MQ 25.85μl
合計 40μl
37℃における1時間のインキュベーション
【0092】
ライゲーション混合物(10μl/サンプル)
10mM ATP 1μl
T4 DNA リガーゼ 1μl
ECoRIアダプター(5pmol/μl) 1μl
MseIアダプター(50pmol/μl) 1μl
5×RL 2μl
MQ 4μl
合計 10μl
の添加
37℃における3時間のインキュベーション
【0093】
EcoRIアダプター
【化4】
【0094】
MseIアダプター
【化5】
【0095】
(2)前増幅
前増幅(A/C):
RL混合物(10×) 5μl
EcoRIプライマー E01L(50ng/ul) 0.6μl
MseIプライマー M02K(50ng/ul) 0.6μl
dNTPs(25mM) 0.16μl
Taqポリメラーゼ(5U) 0.08μl
10×PCR 2.0μl
MQ 11.56μl
1反応につき合計20μl
【0096】
前増幅の温度プロフィール
選択的な前増幅を50μlの反応容量中で行なった。PCRをPE GeneAmp PCRシステム9700で行ない、20サイクルのプロフィールは、94℃30秒間の変性工程でスタートし、その後、56℃60秒間のアニーリング工程、及び72℃60秒間の伸張工程を行なった。
【0097】
EcoRI+1(A)1
【化6】
【0098】
MseI+1(C)1
【化7】
【0099】
事前増幅 A/CA:
PA+1/+1−混合物(20×) :5μl
EcoRIプライマー :1.5μl
MseIプライマー :1.5μl
dNTPs(25mM) :0.4μl
Taqポリメラーゼ(5U) :0.2μl
10×PCR :5μl
MQ :36.3μl
合計 :50μl
【0100】
選択的な前増幅を50μlの反応容量中で行なった。PCRをPE GeneAmp PCRシステム9700で行ない、30サイクルのプロフィールは、94℃30秒間の変性工程でスタートし、その後、56℃60秒間のアニーリング工程、及び72℃60秒間の伸張工程を行なった。
【0101】
(3)KRSEcoRI+1(A)及びKRSMseI+2(CA)2
【化8】
【0102】
太字の選択的なヌクレオチド及び下線を引いたタグ(KRS)
【化9】
【0103】
(4)AFLPのプロトコル
選択的な前増幅を20μlの反応容量中で行なった。PCRをPE GeneAmp PCRシステム9700で行なった。13サイクルのプロフィールは、94℃30秒間の変性工程でスタートし、その後、アニーリング温度が各々のサイクルにおいて0.7℃低下するタッチダウンフェーズを伴う、65℃30秒間のアニーリング工程、及び72℃60秒間の伸張工程を行なった。このプロフィールの後で、94℃30秒間の変性工程、56℃30秒間のアニーリング工程、及び72℃60秒間の伸張工程を伴う、23サイクルのプロフィールを行なった。
【0104】
【化10】
【0105】
(5)キアゲンカラム
キアゲン精製は製造者の説明書に従って行なった:QIAquick(登録商標)スピンハンドブック(http://www1.qiagen.com/literature/handbooks/PDF/DNACleanupAndConcentration/QQSpin/1021422 HBQQSpin 072002ww.pdf)
【実施例2】
【0106】
コショウ
コショウの系統PSP−11及びPI20234からのDNAを、AFLPの鍵遺伝子の認識部位に特異的なプライマーの使用により、AFLP産物を生成するために用いた。これらのAFLPプライマーは本質的に従来のAFLPプライマーと同じであり(例えば、欧州特許第0,534,858号に記述されている)、認識部位領域、定常領域、及び選択的領域において1つ又は複数の選択的なヌクレオチドを通常含むだろう。コショウの系統PSP−11又はPI20234からの150ngのDNAを、制限エンドヌクレアーゼのEcoRI(1反応につき5U)及びMseI(1反応につき2U)により、37℃で1時間消化させ、その後80℃で10分間不活性化を行なった。得られた制限断片を、1つの末端がEcoRI及び/又はMseI制限断片の1つ又は両方の末端と合う二本鎖合成オリゴヌクレオチドアダプターとライゲーションした。+1/+1 AFLPプライマーによるAFLP前増幅反応(1反応につき20μl)を、10倍に希釈した制限ライゲーション混合物で行なった。PCRプロフィール:20*(94℃で30秒+56℃で60秒+72℃で120秒)。異なる+1 EcoRI及び+2 MseI AFLP鍵遺伝子の認識部位に特異的なプライマーによる追加のAFLP反応(1反応につき50μl)を(下記の表、タグは太字とし、選択的なヌクレオチドは下線が引かれている)、20倍に希釈した+1/+1 EcoRI/MseI AFLP前増幅産物で行なった。PCRプロフィール:30*(94℃で30秒+56℃で60秒+72℃で120秒)。AFLP産物を、QIAquick(登録商標)スピンハンドブック(07/2002)の18ページに従って、QIAquick PCR精製キット(QIAGEN)を用いることによって精製し、濃度はナノドロップ(NanoDrop)(登録商標)ND−1000分光測光器により測定した。5μgの+1/+2 PSP−11 AFLP産物及び5μgの+1/+2 PI20234 AFLP産物の合計を一緒にし、23.3μlのTE中で溶解した。最終的に、430ng/μlの濃度で+1/+2 AFLP産物の混合物が得られた。
【0107】
【表1】
【実施例3】
【0108】
トウモロコシ
トウモロコシの系統B73及びM017からのDNAを、AFLPの鍵遺伝子の認識部位に特異的なプライマーの使用により、AFLP産物を生成するために用いた。これらのAFLPプライマーは本質的に従来のAFLPプライマーと同じであり(例えば、欧州特許第0,534,858号に記述されている)、認識部位領域、定常領域、及び3’末端において1つ又は複数の選択的なヌクレオチドを通常含むだろう。
【0109】
コショウ系統のB73又はM017からのDNAを、65℃1時間制限エンドヌクレアーゼTaqI(1反応につき5U)で、及び37℃で1時間MseI(1反応につき2U)で消化し、その後80℃で10分間不活性化を行なった。得られた制限断片を、1つの末端がTaqI及び/又はMseI制限断片の1つ又は両方の末端と合う二本鎖合成オリゴヌクレオチドアダプターとライゲーションした。
【0110】
+1/+1 AFLPプライマーによるAFLP前増幅反応(1反応につき20μl)を、10倍に希釈した制限ライゲーション混合物で行なった。PCRプロフィール:20*(94℃で30秒+56℃で60秒+72℃で120秒)。異なる+2 TaqI及びMseI AFLP鍵遺伝子の認識部位に特異的なプライマーによる追加のAFLP反応(1反応につき50μl)が(下記の表、タグは太字とし、選択的なヌクレオチドは下線が引かれている)、20倍に希釈した+1/+1 TaqI/MseI AFLP前増幅産物で行なわれた。PCRプロフィール:30*(94℃で30秒+56℃で60秒+72℃で120秒)。AFLP産物を、QIAquick(登録商標)スピンハンドブック(07/2002)の18ページに従って、QIAquick PCR精製キット(QIAGEN)を用いることによって精製し、濃度はナノドロップ(登録商標)ND−1000分光測光器により測定した。各々異なる1.25μgのB73 +2/+2 AFLP産物及び各々異なる1.25μgのM017 +2/+2 AFLP産物の合計を一緒にし、30μlのTE中で溶解した。最終的に、333ng/μlの濃度で+2/+2 AFLP産物の混合物が得られた。
【0111】
【表2】
【0112】
最終的に、4つのP1サンプル及び4つのP2サンプルがプール及び濃縮された。合計量25μlのDNA産物及び最終濃度400ng/ul(合計10μg)が得られた。中間の品質査定を図3に示す。
【0113】
454によるシークエンシング
本明細書において以前に記述されたように調製されたコショウ及びトウモロコシのAFLP断片サンプルは、以下に記述されるような454 Life Sciencesにより加工された(Margulies et al., 2005「微細加工高密度ピコリッターリアクター中のゲノムシークエンシング(Genome sequencing in microfabricated high-density picolitre reactors)」Nature 437 (7057) :376-80. Epub July 31, 2005)。
【0114】
データ処理
加工パイプライン:
入力データ
未加工配列データが各々の実行に対して受け取られた:
−200,000〜400,000の読み取り
−ベースコール(塩基呼び出し)品質スコア
【0115】
トリミング及びタグ付け
これらの配列データを、読み取りの始め及び末端で、鍵遺伝子認識部位(KRS)の存在について分析する。これらのKRS配列はAFLPアダプター及びサンプル標識配列の両方から成り、特定のサンプルの特定のAFLPプライマーの組合せに対して特異的である。KRS配列は、BLASTによって同定及びトリミングされ、制限部位が回復される。読み取りは、KRS起源の同定のためのタグでマークされる。トリミングされた配列は、その後の処理を行なうために、長さ(最低33ヌクレオチド)で選択される。
【0116】
クラスタリング及びアセンブリー
MegaBlast分析は、相同配列のクラスターを得るために全てのサイズ選択且つトリミングされた読み取りで行なわれる。引き続いて全てのクラスターは、アセンブリングされたコンティグをもたらすために、CAP3によりアセンブリングされる。両方の工程からの、他の読み取りと一致しないユニーク配列の読み取りが同定される。これらの読み取りはシングルトンとしてマークされる。本明細書において以前に記述された工程を行なう加工パイプラインを図4の(A)に示す。
【0117】
多型性抽出及び品質査定
アセンブリー解析からの最終的なコンティグは、多型性検出の根拠を成す。各々のクラスターのアライメントにおける各々の「ミスマッチ」は、可能性のある多型性である。選択基準を、品質スコアを得るために定義する:
− 1つのコンティグ当たりの読み取りの数
− 1つのサンプル当たりの「対立遺伝子」の頻度
− ホモポリマー配列の発生
− 近隣する多型性の発生
閾値を超えた品質スコアにより、SNP及びインデルは、推定上の多型性として同定される。SSR抽出については、MISA(MIcroSAtellite同定)ツール(http://pgrc.ipk-gatersleben.de/misa)を用いる。このツールはジヌクレオチド、トリヌクレオチド及びテトラヌクレオチド及び化合物SSRモチーフをあらかじめ定められた基準により同定し、これらのSSRの発生を要約する。
【0118】
多型性抽出過程及び品質割当過程を図4の(B)に示す。
【0119】
結果
下記の表は、組み合わせたコショウのサンプルについて2回の454シークエンスの実行、及び組み合わせたトウモロコシサンプルについて2回の実行から得られた配列を組み合わせた分析の結果を要約する。
【0120】
【表3】
【実施例4】
【0121】
コショウ中の一塩基多型(SNP)の発見
DNAの単離
ゲノムDNAは、コショウ組換え近交系(RIL)集団の親の2系統及び10のRILの子孫から単離された。親系統はPSP11及びPI201234である。ゲノムDNAを、Stuart及びViaによって記述された修飾CTAB手順を用いて、個々の苗木の葉材料から単離した(Stuart, C.N., Jr and Via,L.E. (1993)「RAPDフィンガープリンティング及び他のPCR用途のために有用な高速CTAB DNA分離方法(A rapid CTAB DNA isolation technique useful for RAPD fingeprinting and other PCR applications)」Biotechniques, 14, 748-750)。DNAサンプルを、TE(10mMトリスHCl pH 8.0、1mM EDTA)中で100ng/μlの濃度に希釈し、−20℃で保存した。
【0122】
タグ付けしたAFLPプライマーを用いたAFLP鋳型の調製
Zabeau及びVos(1993:「選択的制限断片増幅;DNAフィンガープリントのための一般法(Selective restriction fragment amplification; a general method for DNA fingerprinting)」欧州特許第0534858号(A1)及び(B1);米国特許第6045994号)、並びにVos他(Vos, P., Hogers, R., Bleeker, M., Reijans, M., van de Lee, T., Hornes, M., Frijters, A., Pot, J., Peleman, J., Kuiper, M. et al. (1995)「AFLP:DNAフィンガープリントのための新しい技術(AFLP: a new technique for DNA fingerprinting)」Nucl. Acids Res., 21, 4407-4414)によって記述されたように、制限エンドヌクレアーゼの組合せEcoRI/MseIを用いて、コショウの親系統のPSP11及びPI201234のAFLP鋳型を調製した。
【0123】
具体的には、EcoRI及びMseIによるゲノムDNAの制限は以下のように行なわれた:
DNA制限
DNA 100〜500ng
EcoRI 5単位
MseI 2単位
5×RL緩衝液 8μl
40μlまでのMilliQ水
インキュベーションは37℃で1時間行なった。酵素の制限後に、80℃で10分間インキュベーションによって、酵素を不活性化した。
【0124】
アダプターのライゲーション
10mM ATP 1μl
T4 DNAリガーゼ 1μl
EcoRIアダプター(5pmol/μl) 1μl
MseIアダプター(50pmol/μl) 1μl
5×RL緩衝液 2μl
40μlまでのMilliQ水
インキュベーションは37℃で3時間行なった。
【0125】
選択的なAFLP増幅
制限−ライゲーションに続いて、制限/ライゲーション反応物をT10E0.1で10倍に希釈し、希釈混合物5μlを、選択的増幅工程において鋳型として用いた。+1/+2選択的増幅が意図されたので、最初に+1/+1選択的前増幅工程(標準AFLPプライマーで)が行なわれたことに留意されたい。+1/+1(+A/+C)増幅の反応条件は以下のとおりであった。
【0126】
制限ライゲーション混合物(10倍希釈) 5μl
EcoRIプライマー+1(50ng/μl): 0.6μl
MseIプライマー+1(50ng/μl) 0.6μl
dNTPs(20mM) 0.2μl
Taqポリメラーゼ(5U/μl Amplitaq、PE) 0.08μl
10×PCR緩衝液 2.0μl
20μlまでのMilliQ水
プライマー配列は、
【化11】
であった。
【0127】
PCR増幅は、以下の条件を用いて、金又は銀のブロックでPE9700を用いて行なわれた:20回(94℃で30秒、56℃で60秒及び72℃で120秒)。
【0128】
生成された+1/+1前増幅産物の品質を、断片長の分布をチェックするために、100塩基対ラダー及び1Kbラダーを用いて、1%のアガロースゲルでチェックした。+1/+1選択的増幅に続いて、反応物をT10E0.1で20倍希釈し、希釈混合物5μlをタグ付けしたAFLPプライマーを用いて、+1/+2選択的増幅工程において鋳型として用いた。
【0129】
最終的に、+1/+2(A/+CA)選択的AFLP増幅は以下のように行なわれた:
+1/+1選択的な増幅産物(20倍希釈) 5.0μl
KRS EcoRIプライマー+A(50ng/μl) 1.5μl
KRS MseIプライマー+CA(50ng/μl) 1.5μl
dNTPs(20mM) 0.5μl
Taqポリメラーゼ(5U/μl Amplitaq、Perkin Elmer) 0.2μl
10×PCR緩衝液 5.0μl
50μlまでのMQ
タグ付けされたAFLPプライマー配列は、
PSP11:
【化12】
PI201234:
【化13】
であった。
【0130】
シークエンシング過程の終わりでそれぞれのコショウ系統から生じる増幅産物を区別するために、これらのプライマーの5’末端に4bpタグ(上記で下線が引かれた)が含まれることに留意されたい。
【0131】
4bpの5つのプライムタグ配列を含むAFLPプライマーによる増幅後のコショウAFLP+1/+2増幅産物の略図。
【化14】
【0132】
PCR増幅(1つのサンプル当たり24)を金又は銀のブロックでPE9700を用いて、以下の条件を用いて行なった:30回(94℃で30秒+56℃で60秒+72℃で120秒)。
【0133】
生成された増幅産物の品質を、断片長の分布をチェックするために、100塩基対ラダー及び1Kbラダーを用いて、1%のアガロースゲルでチェックした。
【0134】
AFLP反応物の精製及び定量化。
1つのコショウサンプル当たり、2つの50マイクロリットルの+1/+2選択的なAFLP反応をプールした後、最終的な12の100μl AFLP反応生成物を、QIAquick(登録商標)スピンハンドブック(18ページ)に従って、QIAquick PCR精製キット(QIAGEN)を用いて精製した。各々のカラムに最高100μlの産物を充填した。増幅された産物を、T10E0.1で溶出した。精製された産物の品質を1%アガロースゲルでチェックし、濃度をナノドロップで測定した(図2)。
【0135】
ナノドロップ濃度測定を、各々の精製されたPCR産物の最終的な濃度を、1マイクロリットル当たり300ナノグラムに合わせるために用いた。5マイクログラムのPSP11の精製増幅産物及び5マイクログラムのPI201234の精製増幅産物を混合し、454シークエンシングライブラリーの調製のための10マイクログラムの鋳型材料を生成した。
【0136】
シークエンスライブラリーの調製及びハイスループットシークエンシング
両方のコショウ系統からの混合増幅産物を、Margulies他によって記述されるような、454ライフサイエンスシークエンシング技術を用いて、ハイスループットシークエンシングした(Margulies et al., Nature 437, pp. 376-380及びオンライン上の補足)。具体的には、Margulies及び共同研究者等によって記述されるように、エマルジョンPCR増幅及び続く断片シークエンシングを促進するために、AFLP PCR産物を最初に末端を平滑にし、続いてアダプターにライゲーションした。454のアダプター配列、エマルジョンPCRプライマー、配列プライマー及びシークエンスの実行条件は、全てMargulies及び共同研究者等によって記述されるものであった。図1Aに例示されるように、454シークエンシング過程におけるセファロースビーズ上で増幅されたエマルジョン−PCR断片中の機能要素の直線的な順序は、以下のとおりだった:
454 PCRアダプター − 454シークエンスアダプター − 4bp AFLPプライマータグ1 − 選択的なヌクレオチド(複数可)を含むAFLPプライマー配列1 − AFLP断片内部配列−選択的なヌクレオチド(複数可)を含むAFLPプライマー配列2、4bp AFLPプライマータグ2 − 454配列アダプター − 454PCRアダプター − セファロースビーズ
【0137】
2つのハイスループット454シークエンスの実行は、454 Life Sciences(アメリカ合衆国コネチカット州ブランフォード)によって行なわれた。
【0138】
454シークエンス実行のデータ処理
2回の454シークエンスの実行に由来する配列データを、バイオインフォマティクスパイプライン(Keygene N.V.)を用いて加工した。具体的には、未加工の454ベースコール済みシークエンス読み取りを、FASTAフォーマットで変換し、BLASTアルゴリズムを用いて、タグ付けしたAFLPアダプター配列の存在の有無を検査した。既知のタグを付けたAFLPプライマー配列への高い信頼性の一致に際して、配列をトリミングし、制限エンドヌクレアーゼ部位を回復し、適切なタグを割り当てた(それぞれ、サンプル1 EcoRI(ES1)、サンプル1 MseI(MS1)、サンプル2 EcoRI(ES2)、又はサンプル2 MseI(MS2))。次に、33塩基よりも長いトリミングされた配列の全てを、全体の配列相同性に基づくmegaBLAST手順を用いてクラスターに分けた。次に、クラスターを、CAP3の多重アライメントアルゴリズムを用いて、1つのクラスター当たり1つ又は複数のコンティグ及び/又はシングルトンへアセンブリングした。1つより多くの配列を含むコンティグは、推定上の多型性を表わす配列ミスマッチの有無を検査された、配列ミスマッチには、以下の基準に基づく品質スコアを割り当てた:
*コンティグ中の読み取りの数
*観察された対立遺伝子の分布
上の2つの基準は、各々の推定上のSNP/インデルに対応する、いわゆるQスコアのための根拠を成す。Qスコアは0〜1にわたる;両方の対立遺伝子が少なくとも2度観察された場合にのみ、Qスコア0.3が達成される。
*特定の長さのホモポリマー中の位置(調整可能;3塩基以上のホモポリマーに位置する多型性を回避するための初期設定)
*クラスター中のコンティグの数。
*最も近い隣接する配列ミスマッチへの距離(調整可能;フランキング配列を調べる特定の型の遺伝子型決定分析にとって重要)
*サンプル1又はサンプル2で観察された対立遺伝子の関連のレベル;
推定上の多型性並びにサンプル1及び2の対立遺伝子間で一貫して完全な関連が存在する場合には、多型性(SNP)が推定上の「エリート」多型性(SNP)として示される。エリート多型性は、2つのホモ接合体系統が発見過程で用いられた場合に、ユニークゲノム配列又は低コピーのゲノム配列に位置する確率が高いと考えられる。反対に、サンプル起源との多型性の弱い関連は、コンティグ中の非対立遺伝子配列のアライメントから生じる誤った多型性を発見してしまうリスクが高い。
【0139】
SSRモチーフを含む配列は、MISA検索ツール(MIcroSAtellelite同定ツール;http://pgrc.ipk-gatersleben.de/misa/から利用可能。)を用いて同定された。
【0140】
実行の全体の統計を、以下の表で示す。
【表4】
【0141】
*SNP/インデル抽出基準は以下のとおりであった:
いずれかの側にも12塩基以内の0.1よりも大きいQスコアを有する隣接する多型性はなく、3塩基以上のホモポリマー中に存在しない。抽出基準は、サンプル1及び2で一貫した関連を考慮しなかった、すなわち、SNP及びインデルは必ずしも推定上のエリートSNP/インデルではない。
【0142】
推定上のエリート単一ヌクレオチド多型を含む多重アライメントの一例を、図7に示す。
【実施例5】
【0143】
PCR増幅及びサンガーシークエンシングによるSNP妥当性の検証
実施例1において同定された推定上のA/G SNPを検証するために、このSNPのためのタグ付き配列部位(STS)分析を、隣接するPCRプライマーを用いて設計した。PCRプライマー配列は以下のとおりであった:
【化15】
【0144】
プライマー1.2rが、5’末端でM13配列プライマー結合部位及び長さスタッファーを含むことに留意されたい。PCR増幅を、鋳型として、実施例4に記述されるように調製したPSP11及びPI210234の+A/+CA AFLP増幅産物を用いて行なった。PCR条件は以下のとおりであった:
1つのPCR反応に対して、下記成分を混合した:
5μl 1/10に希釈したAFLP混合物(app.10ng/μl)
5μl 1pmol/μlプライマー 1.2f(500μMストックから直接希釈したもの)
5μl 1pmol/μlプライマー 1.2r(500μMストックから直接希釈したもの)
5μl PCR混合物 −2μl 10×PCR緩衝液
−1μl 5mM dNTPs
−1.5μl 25mM MgCl2
−0.5μl H2O
5μl 酵素混合物 −0.5μl 10×PCR緩衝液
(Applied Biosystems)
−0.1μl 5U/μl AmpliTaq
DNAポリメラーゼ(Applied Biosystems)
−4.4μl H2O
以下のPCRプロフィール:
サイクル1 2分間;94℃
サイクル2〜サイクル34 20秒間;94℃
30秒間;56℃
2分30秒間;72℃
サイクル35 7分間;72℃
∞;4℃
を使用した。
【0145】
PCR産物をTAクローニング法を用いてベクターpCR2.1(TAクローニングキット;Invitrogen)へクローニングし、INVαF’コンピテント大腸菌細胞へ形質転換させた。形質転換体を青/白のスクリーニングにかけた。PSP11及びPI−201234について各々独立した白色の3つの形質転換体を選択し、プラスミド単離のための液体の選択培地中で、一晩、増殖させた。
【0146】
プラスミドをQIAprepスピンMiniprepキット(QIAGEN)を用いて単離した。続いて、これらのプラスミドのインサートを、以下のプロトコルに従ってシークエンシングし、MegaBACE 1000(Amersham)で溶解した。得られた配列をSNP対立遺伝子の有無について検査した。PI−201234インサートを含む独立した2つのプラスミド、及びPSP11インサートを含む1つのプラスミドは、SNPに隣接する期待されたコンセンサス配列を含んでいた。PSP11断片に由来する配列は期待されたA対立遺伝子(下線が引かれた)を含み、PI−201234断片に由来する配列は期待されたG対立遺伝子(二重下線が引かれた)を含んでいた:
PSP11(配列1):(5’−3’)
【化16】
PI−201234(配列1):(5’−3’)
【化17】
PI−201234(配列2):(5’−3’)
【化18】
【0147】
この結果は、推定上のコショウA/G SNPが、設計されたSTS分析を用いて検出可能な真の遺伝的多型を表わすことを示す。
【実施例6】
【0148】
SNPWave検出によるSNP妥当性の検証
実施例1において同定された推定上のA/G SNPを検証するために、コンセンサス配列を用いて、SNPWaveライゲーションプローブセットは、このSNPの両方の対立遺伝子について定義された。ライゲーションプローブの配列は以下のとおりであった:
SNPWaveプローブ配列(5’−3’)
【化19】
【0149】
共通の遺伝子座特異的プローブ06A164へのライゲーションに際して、94(42+54)塩基及び96(44+52)塩基のライゲーション産物サイズをもたらすように、A及びGの対立遺伝子について、それぞれの対立遺伝子特異的プローブの06A162及び06A163が、2塩基のサイズで異なることに留意されたい。
【0150】
van Eijk及び共同研究者等によって記述されるように、出発物質として100ngのコショウ系統PSP11及びPI201234のゲノムDNA及び8つのRIL子孫を用いて、SNPWaveライゲーション及びPCR反応が実行された(M. J. T. van Eijk, J. L.N. Broekhof, H. J.A. van der Poel, R. C. J. Hogers, H. schneiders, J. Kamerbeek, E. Verstege, J.W. van Aart, H. Geerlings, J. B. Buntjer, A. J. van Oeveren, and P. Vos. (2004)「SNPWave(商標):柔軟な多重化SNP遺伝子型決定技術(SNPWaveTM: a flexible multiplexed SNP genotyping technology)」Nucleic Acids Research 32: e47)。PCRプライマーの配列は次のとおりであった:
【化20】
【0151】
PCR増幅に続いて、PCR産物の精製及びMegaBACE1000での検出は、van Eijk及び共同研究者等(上記参照)によって記述された通りであった。PSP11、PI201234、及び8つのRIL子孫から得られた増幅産物の擬似ゲル画像を、図8Bに示す。
【0152】
SNPWave結果は、P1(PSP11)及びRIL子孫(1、2、3、4、6、及び7)に対して92bp産物(=AAのホモ接合体遺伝子型)、及びP2(PI201233)及びRIL子孫5及び8に対して94bp産物(=GGのホモ接合体遺伝子型)をもたらし、A/G SNPが、SNPWave分析によって検出されることを明確に実証する。
【実施例7】
【0153】
低コピー配列のAFLP断片ライブラリーを濃縮するための戦略
この実施例は、実施例4に記述されていたようなエリート多型性の収率を増加させるために、ユニークゲノム配列の低コピーを標的とする、いくつかの濃縮法を記述する。この方法は4つのカテゴリーに分類することができる:
【0154】
1)葉緑体配列を除いて高品質ゲノムDNAを調製することを目標とする方法
ここで、大量の葉緑体DNAの共単離を除外するために、実施例4に記述されているような全ゲノムDNAの代わりに、核DNAを調製することを提案する。この調製により、断片ライブラリー調製方法で用いられる制限エンドヌクレアーゼ及び選択的なAFLPプライマーに依存して、植物ゲノムDNA配列数の減少がもたらされ得る。高度に純粋なトマト核DNAの単離のプロトコルは、Peterson, DG., Boehm, K.S. & Stack S.M. (1997)「トマト(Lycopersicon esculentum)からのミリグラム量の核DNAの単離、高レベルのポリフェノール化合物を含む植物(Isolation of Milligram Quantities of Nuclear DNA From Tomato (Lycopersicon esculentum), A Plant Containing High Levels of Polyphenolic Compounds)」Plant Molecular Biology Reporter 15 (2), pages 148-153により記述されている。
【0155】
2)低コピー配列のレベルの増加をもたらすと期待される、AFLP鋳型の調製過程で制限エンドヌクレアーゼを用いることを目標とする方法
ここで、AFLP鋳型調製方法において特定の制限エンドヌクレアーゼを用いることを提案する。この使用は、低コピーのゲノム配列又はユニークゲノム配列を標的とすると予想され、遺伝子型決定分析への転換能力の増加により、多型性について濃縮された断片ライブラリーをもたらす。植物ゲノムにおける低コピー配列を標的とする制限エンドヌクレアーゼの一例は、PstIである。他のメチル化感受性の制限エンドヌクレアーゼも、低コピーのゲノム配列又はユニークゲノム配列を優先的に標的とし得る。
【0156】
3)反復配列対低コピー配列の再アニーリング速度論に基づく、高度に重複した配列を選択的に除去することを目標とした方法
ここで、選択的増幅の前に、全ゲノムDNAサンプル又は(cDNA−)AFLP鋳型材料のいずれかから、高度に重複した(反復)配列を選択的に除去することを提案する。
【0157】
3a)高C0t DNA調製は、複雑な植物ゲノムDNA混合物から低コピー配列を濃縮して徐々にアニーリングする一般に用いられる技術である(Yuan et al. 2003;「トウモロコシゲノムの高Cotの配列分析(High-Cot sequence analysis of the maize genome)」Plant J. 34: 249-255)。低コピー配列中に位置する多型性のために、濃縮する出発物質として、全ゲノムDNAの代わりに高C0t DNAを採用することが示唆される。
【0158】
3b)面倒な高C0t調製の代替案は、Zhulidov及び共同研究者等(2004;「カムチャツカガニの二重鎖特異的ヌクレアーゼを用いる単純なcDNA正規化(simple cDNA normalization using Kamchatka crab duplex-specific nuclease)」Nucleic Acids Research 32, e37)、並びにShagin及び共同研究者等(2006;「カニ肝膵臓からの新しい二重鎖特異的ヌクレアーゼを用いるSNP検出のための新規方法(a novel method for SNP detection using a new duplex-specific nuclease from crab hepatopancreas)」Genome Research 12: 1935-1942)によって記述されるように、不完全に一致したDNA二本鎖よりも高い率で、短い完全に一致したDNA二本鎖を切断する、カムチャツカガニからの新規ヌクレアーゼで、変性した再アニーリングdsDNAをインキュベートすることである。具体的には、それは高度に重複した配列の混合物を枯渇させるために、このエンドヌクレアーゼでAFLP制限/ライゲーション混合物をインキュベートし、その後残存する低コピーのゲノム配列又はユニークゲノム配列の選択的なAFLP増幅を行なうことが提案される。
【0159】
3c)メチル濾過は、Cがメチル化される場合に、配列[A/G]Cでメチル化されたDNAを切断する制限エンドヌクレアーゼMcrBCを用いて、低メチル化ゲノムDNA断片について濃縮する方法である(Pablo D. Rabinowicz , Robert Citek, Muhammad A. Budiman, Andrew Nunberg, Joseph A. Bedell Nathan Lakey, Andrew L. O' Sshaughnessy, Lidia U. Nascimento, W. Richard McCombie and Robert A. Martienssen、「陸上植物における遺伝子の差異的なメチル化及び反復(Differential methylation of genes and repeats in land plants)」Genome Research 15:1431-1440, 2005を参照)。McrBCは、多型性発見のための出発物質としてのゲノムの低コピー配列画分を濃縮するために用いられてもよい。
【0160】
4)遺伝子配列を標的とするための、ゲノムDNAとは対照的なcDNAの使用
最終的に、ここで、任意で、正規化のために上の3b中に記述した、二重鎖特異的なカニのヌクレアーゼの使用と組み合わせて、多型性の発見のための出発物質としてのゲノムDNAとは対照的なオリゴdTでプライミングしたcDNAを用いることが提案される。オリゴdTでプライミングしたcDNAの使用により、葉緑体配列も除外されることに留意されたい。或いは、オリゴdTでプライミングしたcDNAの代わりに、cDNA−AFLP鋳型を、AFLPと同様に、残存する低コピー配列の増幅を促進するために用いる(上の3bも参照)。
【実施例8】
【0161】
単純反復配列濃縮のための戦略
この実施例は、実施例4において記述されたSNP発見と同様に、単純反復配列の発見のために提案された戦略を記述する。
【0162】
具体的には、2つ以上のサンプルのゲノムDNAの制限ライゲーションは、例えば、制限エンドヌクレアーゼPstI/MseIを用いて行なわれる。実施例4において記述されているように、選択的なAFLP増幅が行なわれる。次に、選択されたSSRモチーフを含む断片は、2つの方法のうちの1つによって濃縮される。
【0163】
1)Armour及び共同研究者等によって記述されたものと同様の方法での、意図したSSRモチーフと一致するオリゴヌクレオチドを含むフィルター上へのサザンブロットハイブリダイゼーション(例えば、CA/GT反復の濃縮の場合には、(CA)15)と、その後の結合断片の増幅(Armour, J., Sismani, C., Patsalis, P., and Cross, G. (2000)「増幅可能なプローブとのハイブリダイゼーションによる遺伝子座コピー数の測定(Measurement of locus copy number by hybridization with amplifiable probes)」Nueleic Acids Research vol 28, no. 2, pp. 605-609)又は
2)Kijas及び共同研究者等によって記述された解決法での、(AFLP)断片を取り込むためにビオチン化された捕獲オリゴヌクレオチドハイブリダイゼーションプローブを用いる濃縮(Kijas, J.M,. Fowler, J.C., Garbett C.A., and Thomas, M.R., (1994)「ストレプトアビジンがコートされた磁気微粒子に結合したビオチン化オリゴヌクレオチド配列を用いた、柑橘類のゲノムからのマイクロサテライトの濃縮(Enrichment of microsatellites from the citrus genome using biotinylated oligonucleotide sequences bound to streptavidin-coated magnetic particles)」Biotechniques, vol. 16, pp. 656-662)。
【0164】
次に、SSRモチーフが濃縮されたAFLP断片は、前増幅工程で用いられるのと同様のAFLPプライマーを用いて、シークエンスライブラリーを生成するために増幅される。増幅された断片の一部分をT/Aクローニングし、96のクローンを陽性のクローン画分(意図したSSRモチーフ、例えば5反復単位よりも長いCA/GTモチーフを含むクローン)を推定するためのシークエンスとする。SSRを含む断片が濃縮されるかを視覚的に検査するために、任意で、読取り可能なフィンガープリントを得るさらなる選択的増幅の後に、濃縮されたAFLP断片混合物の他の部分を、ポリアクリルアミドゲル電気泳動法(PAGE)によって検出する。これらの制御工程の首尾良く完了させた後、シークエンスライブラリーで、ハイスループット454シークエンシングを行なう。
【0165】
新たなSSR発見のための上の戦略は、図8Aにおいて概略的に示され、捕獲オリゴヌクレオチド配列を置換することによって、他の配列モチーフに対して適応させることができる。
【実施例9】
【0166】
混合したタグの回避ための戦略
混合したタグは、1つのサンプル当たりに、タグ付けされたAFLPプライマーの期待される組合せに加えて、サンプル1のタグを1つの末端に及びサンプル2のタグを他方の末端に含む配列の画分が少量観察されるという観察を示す(実施例4中の表1も参照)。図式的に、混合したタグを含んでいる配列の配置は本明細書において以下で表現される。
【0167】
期待されるサンプルタグの組合せの配置図。
【化21】
【0168】
混合タグの配置図。
【化22】
【0169】
混合したタグの観察によって、配列が、PSP11又はPI−201234のいずれかへ正確に割り当てられることは除外される。
【0170】
実施例4において記述されるコショウのシークエンス実行において観察された混合したタグの配列の一例を、図5Aに示す。期待されるタグ及び混合したタグを含む、観察された断片の配置の概観を、図5Aのパネル2において示す。
【0171】
混合したタグに対して提案された分子的な説明は、シークエンスライブラリーの調製工程の間、3’突出末端を除去するT4 DNAポリメラーゼ又はクレノウ酵素の使用によって、アダプターライゲーション前に、DNA断片がブラントにされるということである(Margulies et al., 2005)。単一のDNAサンプルが加工される場合にはこれはうまくいくのだろうが、異なってタグ付けされたDNAサンプルの2つ以上のサンプルの混合物を使用する場合には、ポリメラーゼによって埋められると、異なるサンプルに由来する相補的な鎖の間にヘテロ二本鎖が形成される際に、間違ったタグ配列の取り込みをもたらす(図5Bパネル3混合したタグ)。その解決法は、図5Cのパネル4において示されるような454シークエンスライブラリーの構築工程において、アダプターライゲーションに続く精製工程の後にサンプルをプールすることであることが見い出された。
【実施例10】
【0172】
454シークエンスライブラリー調製のための改善された設計を使用する、混合したタグ及びコンカテマーの回避ための戦略
実施例9において記述されるような混合したタグを含む低頻度のシークエンス読み取りについての観察の他に、コンカテマーになったAFLP断片から観察された低頻度のシークエンス読み取りが観察された。
【0173】
コンカテマーに由来するシークエンス読み取りの一例を図6Aパネル1において示す。期待されるタグ及びコンカテマーを含む配列の配置を、図式的に図6Aパネル2において示す。
【0174】
コンカテマーになったAFLP断片の発生に対して提案された分子的な説明は、454シークエンスライブラリー調製工程の間に、DNA断片は、3’突出末端を除去するT4 DNAポリメラーゼ又はクレノウ酵素を使用して、アダプターライゲーション前にブラントにされるということである(Margulies et al., 2005)。その結果、ブラントな末端のサンプルDNA断片はライゲーション工程の間にアダプターを競合し、アダプターにライゲーションされる前に互いにライゲーションされるであろう。この現象は、実際、ライブラリーの調製工程において、単一のDNAサンプルが含まれるか、又は複数の(タグ付けされた)サンプルの混合物が含まれているか否かに依存せず、したがって、Margulies及び共同研究者等によって記述されるような従来のシークエンシングの間にも起こってもよい。実施例4において記述されているような複数のタグを付けられたサンプルの使用の場合には、コンカテマーは、タグ情報に基づきサンプルに対する配列読み取りの正確な割り当てを複雑にし、したがって、回避されるべきである。
【0175】
コンカテマー(及び混合したタグ)の形成に対する提案された解決法は、図6Bパネル3において示されるように、ブラント末端アダプターライゲーションを、PCR産物のT/Aクローニングと同様に、3’T突出部を含むアダプターのライゲーションと置換することである。便利なように、これらの修飾された3’T突出部含むアダプターは、アダプター配列のブラント末端コンカテマー形成を防ぐために、反対側の3’末端(それはサンプルDNA断片にライゲーションされないであろう)でC突出部を含むように提案される(図6Bパネル3を参照)。修飾されたアダプターのアプローチを使用する場合の、シークエンスライブラリー構築過程の最終的な適応ワークフローを、図6Cのパネル4において図式的に示す。
【技術分野】
【0001】
本発明は、分子生物学及び遺伝学の分野に関する。本発明は、核酸サンプルにおける複数の多型性の迅速な同定に関する。同定された多型性は、検査サンプルの多型性のためのハイスループットスクリーニング系の開発に対して使用されてもよい。
【背景技術】
【0002】
ゲノムDNAの調査は、科学関係者、特に医療関係者によって長く望まれてきた。ゲノムDNAは、癌及びアルツハイマー病のような疾患の同定、診断、及び治療の鍵を握る。ゲノムDNAの調査は、疾患の同定及び治療だけでなく、植物及び動物品種改良事業において著しい利点を提供し、食品栄養学の問題に対する答えを世界に示すかもしれない。
【0003】
多くの疾患が、特異的な遺伝子の多型性を伴う特異的な遺伝的要素に特に関連することが知られている。ゲノムのような大きなサンプルにおける多型性の同定は、現在、困難且つ多くの時間を要する課題である。しかしながら、そのような同定は、製薬産物、組織適合試験、遺伝子型決定、及び集団研究を開発する生物医学研究のような領域に対して非常に価値がある。
【発明の概要】
【発明が解決しようとする課題】
【0004】
本発明は、複雑な、例えば非常に大きな核酸サンプル(例えば、DNA又はRNA)における多型性を、ハイスループット方法の組合せを使用して、迅速及び経済的な様式で、効率的に同定し確実に検出する方法を提供する。
【0005】
ハイスループット方法のこの統合は、従来の多型性の同定及びマッピングが困難且つ多くの時間を要するような、非常に複雑な核酸サンプルにおいて、迅速及び確実な多型性の同定及び検出に対して特に適しているプラットフォームを共に提供する。
【0006】
本発明者が発見したものの1つは、多型性、好ましくは一塩基多型の同定のため、また同様に、特に大きなゲノム中の(マイクロ)サテライト及び/又は挿入・欠失(indels:インデル)の同定のための解決法である。本発明の方法は、大きなゲノム及び小さなゲノムの両方への適用の可能性という点において独特であるが、大きなゲノム、特に倍数体種における特定の利点を提供する。
【0007】
SNPを同定する(及び続いて同定されたSNPを検出する)ために、当該技術分野において利用可能ないくつかの可能性がある。第1の選択では、全ゲノムはシークエンシングすることが可能であり、いくつかの個体についてはそのようなことを行うことができる。これは煩わしく費用のかかることであるので、大半は理論的な試行であり、技術の迅速な発展にもかかわらず、単純に全ての生物、特により大きなゲノムの生物で行うのは実現可能でない。第2の選択は、ESTライブラリーのような利用可能な(断片化した)配列情報を使用することである。これは、PCRプライマーの生成、再シークエンシング、及び個体間の比較を可能にする。さらに、これは、利用可能でないか、又は限られた量でのみ利用可能な、初期の配列情報を必要とする。各々の領域については、さらに個別のPCR分析を開発しなければならず、費用及び開発時間は桁外れに増してしまう。
【0008】
第3の選択は、同定自体を各々の個体に対するゲノムの一部に限定することである。成功するSNP同定に匹敵する結果を提供するためには、提供されるゲノムの部分は、異なる個体にとっても同じでなくてはならないという問題点が存在する。本発明者等は、サンプル調製及びハイスループット同定プラットフォームで統合された、多型性の同定のためのハイスループットシークエンシングによるゲノムの一部を選択するための高度に再現可能な方法の統合によって、今やこの難問を解決している。本発明は、多型性発見の過程を加速し、次の過程で、効果的で確実なハイスループット遺伝子型決定を可能にするように、同一の要素を発見した多型性の利用のために使用する。
【0009】
本発明の方法のさらに想定される適用は、濃縮マイクロサテライトライブラリーのスクリーニング、転写プロファイリングcDNA−AFLP(デジタルノーザン)の実行、複雑なゲノムのシークエンシング、ESTライブラリーのシークエンシング(全体のcDNA又はcDNA−AFLPについて)、マイクロRNAの発見(小さなインサートライブラリーのシークエンシング)、バクテリア人工染色体(BAC)(コンティグ)シークエンシング、バルクセグレガント分析アプローチのAFLP/cDNA−AFLP、例えばマーカー利用戻し交配(MABC)のための、AFLP断片のルーチンの検出等を含む。
【0010】
定義
以下の説明及び実施例において、多くの用語が使用される。そのような用語に与えられる範囲を含む、明細書及び請求項についての明確で一貫した理解を提供するために、以下の定義が提供される。特別に本明細書において定義されないならば、使用される全ての技術的用語及び科学的用語は、本発明が属する技術分野における当業者によって一般に理解されるものと同一の意味を有する。全ての出版物、特許出願、特許及び他の参考文献の開示は、参照によりそれら全体は本明細書において援用される。
【0011】
多型性:多型性は、集団中のヌクレオチド配列の2つ以上の変異型の存在を指す。多型性は1つ又は複数の塩基変化、塩基挿入、塩基反復、又は塩基欠失を含んでもよい。多型性は、例えば、単純反復配列(SSR)及び一塩基多型(SNP)を含み、それらはアデニン(A)、チミン(T)、シトシン(C)、又はグアニン(G)の単一のヌクレオチドが変わったときに生じる変異である。集団の通常少なくとも1%で変異が生じたものが、SNPと考えられる。SNPは、例えば全てのヒト遺伝的変異の90%を占め、ヒトゲノムにわたって100〜300塩基ごとに起こるものである。3つのSNP当たり2つのSNPは、チミン(T)によってシトシン(C)が置換される。DNA塩基配列の変異は、例えば、ヒト又は植物がどのように疾患、細菌、ウイルス、化学薬品、薬剤等を扱うかに影響し得る。
【0012】
核酸:本発明に記載の核酸は、ピリミジン塩基及びプリン塩基の任意のポリマー又はオリゴマー、好ましくはシトシン、チミン及びウラシル、並びにアデニン及びグアニンをそれぞれ含んでもよい(Albert L. Lehninger著「生化学の原理(Principles of Biochemistry)」,793-800(Worth Pub. 1982)を参照、これは全ての目的のためにその全体を参照により本明細書において援用される)。本発明は、下記の塩基のメチル化された形式、ヒドロキシメチル化された形式又は糖鎖が付加した形式等のような、任意のデオキシリボヌクレオチド、リボヌクレオチド又はペプチド核酸、及びそれら任意の化学的な変異型も検討する。ポリマー又はオリゴマーは、組成物中で不均質また均質であってもよく、天然に存在するソースから単離するか又は人為的若しくは合成的に生成されてもよい。さらに核酸は、DNA又はRNA、又はそれらの混合物であってもよく、恒久的に又は一時的に、ホモ二本鎖、ヘテロ二本鎖、及びハイブリッド状態を含む、一本鎖型又は二本鎖型で存在してもよい。
【0013】
複雑度の減少:用語「複雑度の減少」は、サンプルのサブセットの生成によって、ゲノムDNAのような核酸サンプルの複雑度を減少させる方法を意味するために使用する。このサブセットはサンプル全体(すなわち複雑である)の代表になることができ、好ましくは再現可能なサブセットである。本文脈において、再現可能は、同一の方法を使用して、同一のサンプルの複雑度が減少される場合、同じ又は少なくとも同程度のサブセットが得られることを意味する。複雑度の減少のために使用される方法は、当該技術分野において既知である複雑度の減少のための任意の方法であってもよい。複雑度の減少のための方法の例は、例えば、AFLP(登録商標)(Keygene N.V.、オランダ;例えば欧州特許第0,534,858号を参照)、Dongにより記述された方法(例えば、国際公開特許第WO03/012118号、同第WO00/24939号を参照)、インデックスリンク(indexed linking)(Unrau et al.、以下参照)等を含む。本発明で使用される複雑度の減少方法は、それらが再現可能であることが共通である。同一のサンプルが同一の様式で複雑度が減少される場合に、サンプルの同一のサブセットが得られるという意味における再現性については、顕微解剖、又は選択された組織で転写されたゲノムの一部を表わし、その再現性については、組織の選択、単離時期等への依存があるmRNA(cDNA)の使用のような、より無作為な複雑度の減少に対立するものである。
【0014】
タグ付け:用語「タグ付け」は、核酸サンプルを第2の核酸サンプル又はさらなる核酸サンプルと区別することを可能にするために、核酸サンプルへタグを追加することを指す。タグ付けは、例えば、複雑度の減少の間の配列識別子の追加により、又は当該技術分野において既知である任意の他の手段により行なうことができる。そのような配列識別子は、特異的な核酸サンプルの同定のために独自に使用される、例えば一様でないが、定義された長さのユニーク塩基配列であり得る。その代表例は、例えばZIP配列である。そのようなタグを使用して、その後の加工に際して、サンプルの起源を決定することができる。異なる核酸サンプルから生じる加工生成物を組み合わせる場合には、異なる核酸サンプルは異なるタグを使用して同定されるべきである。
【0015】
タグ付けしたライブラリー:用語「タグ付けしたライブラリー」は、タグを付けた核酸のライブラリーを指す。
【0016】
シークエンシング:用語「シークエンシング」は、核酸サンプル、例えばDNA又はRNA中のヌクレオチド(塩基配列)の順番を決定することを指す。
【0017】
アライメントさせること及びアライメント:用語「アライメントさせること」及び「アライメント」により、同一又は同様のヌクレオチドの、短い又は長い一続きのものの存在に基づいた、2つ以上のヌクレオチド配列の比較が意味される。さらに以下で説明されるように、ヌクレオチド配列のアライメントのためのいくつかの方法は、当該技術分野において既知である。
【0018】
検出プローブ:用語「検出プローブ」は、特異的なヌクレオチド配列、特に1つ又は複数の多型性を含む配列の検出のために設計されたプローブを示すために使用される。
【0019】
ハイスループットスクリーニング:HTSとしばしば略されるハイスループットスクリーニングは、特に生物学分野及び化学分野に関連する、科学的な実験作業のための方法である。最新のロボット工学と他の特殊な研究室ハードウェアとの組合せによって、研究者が効果的に同時に大量のサンプルをスクリーニングすることを可能にする。
【0020】
検査サンプルの核酸:用語「検査サンプルの核酸」は、本発明の方法を使用して、多型性について調査される核酸サンプルを示すために使用される。
【0021】
制限エンドヌクレアーゼ:制限エンドヌクレアーゼ又は制限酵素は、二本鎖DNA分子中の特異的なヌクレオチド配列(標的部位)を認識し、標的部位ごとにDNA分子の両方の鎖を切断する酵素である。
【0022】
制限断片:制限エンドヌクレアーゼによる消化により生成されたDNA分子は制限断片と呼ばれる。任意の所定のゲノム(又はその起源にかかわらず核酸)は、特定の制限エンドヌクレアーゼにより、制限断片の不連続なセットへと消化されるだろう。制限エンドヌクレアーゼ切断に由来するDNA断片は、様々な技法の中でさらに使用することができ、例えばゲル電気泳動法により検出することができる。
【0023】
ゲル電気泳動法:制限断片を検出するために、サイズに基づいて二本鎖DNA分子を分画するための分析方法が必要になる。そのような分画を達成するために、最も一般に用いられている技法は、(キャピラリー)ゲル電気泳動法である。DNA断片のそのようなゲル中での移動率は、DNA断片の分子量に依存する。したがって、断片長が増加するにつれて、移動距離は減少する。ゲル電気泳動法により分画されたDNA断片は、染色手順、例えば、パターンの中に含まれた断片数が十分に少ない場合には、銀染色法又はエチジウムブロマイドを使用する染色により直接可視化することができる。或いは、DNA断片のさらなる処理では、蛍光色素分子又は放射性標識のような、断片において検出可能な標識を取り込んでもよい。
【0024】
ライゲーション:2つの二本鎖DNA分子を共有結合で共に連結させるリガーゼ酵素により触媒された酵素反応は、ライゲーションと呼ばれる。一般に、両方のDNA鎖は共有結合で共に連結されるが、鎖の末端の1つの化学的修飾又は酵素的修飾によって、2つの鎖のうちの1つの鎖のライゲーションを防ぐことも可能である。その場合には、共有結合が2つのDNA鎖のうちの1つだけにおいて起こるだろう。
【0025】
合成オリゴヌクレオチド:化学的に合成することができる、好ましくは約10〜約50塩基を有する一本鎖DNA分子は、合成オリゴヌクレオチドと呼ばれる。関連した配列を有する分子のファミリーを合成することは可能であり、それはヌクレオチド配列中の特異的な位置で異なるヌクレオチド組成を有しているが、一般に、これらの合成DNA分子は、特有なヌクレオチド配列又は望ましいヌクレオチド配列を有するように設計される。用語「合成オリゴヌクレオチド」は、設計されたヌクレオチド配列又は望ましいヌクレオチド配列を有するDNA分子を指すために使用されるだろう。
【0026】
アダプター:限られた数の塩基対、例えば約10〜約30塩基対の長さを有する短い二本鎖DNA分子は、制限断片の末端にライゲーションすることができるように設計されている。アダプターは、通常互いに部分的に相補的なヌクレオチド配列がある2つの合成オリゴヌクレオチドから成る。適切な条件下で、溶液中で2つの合成オリゴヌクレオチドを混合した場合、それらはアニーリングして、互いに二本鎖構造を形成するだろう。アニーリング後、アダプター分子の1つの末端は制限断片の末端と適合し、末端でライゲーションすることができるように設計されている。アダプターのもう1つの末端は、ライゲーションできないように設計することができるが、そうである必要はない(二重にライゲーションされたアダプター)。
【0027】
アダプターにライゲーションされた制限断片:アダプターによりキャッピングされた制限断片。
【0028】
プライマー:一般に、用語「プライマー」は、DNAの合成をプライミングすることができるDNA鎖を指す。DNAポリメラーゼは、プライマーなしではDNAをデノボ合成することができない:アセンブリングされるヌクレオチドの順序を指定するために、鋳型として相補的な鎖が用いられるような反応において、DNAポリメラーゼは既存のDNA鎖のみを伸長することができる。本発明者等は、プライマーとして、ポリメラーゼ連鎖反応(PCR)において用いられる合成オリゴヌクレオチド分子を指すだろう。
【0029】
DNAの増幅:用語「DNAの増幅」は、典型的には、PCRを用いた二本鎖DNA分子のin vitroの合成を示すために用いられるだろう。他の増幅方法が存在し、それらは主旨から外れずに、本発明において用いられてもよいことが留意される。
【図面の簡単な説明】
【0030】
【図1A】ビーズ(「454ビーズ」)上にアニーリングされた本発明に記載の断片、及び2つのコショウ系統の前増幅に用いられたプライマーの配列を示す図である。「DNA断片」は制限エンドヌクレアーゼで消化後に得られた断片を表わし、「鍵遺伝子アダプター」はライブラリーを生成するために用いられる(リン酸化された)オリゴヌクレオチドプライマーのためのアニーリング部位を提供するアダプターを表わし、「KRS」は識別子配列(タグ)を表わし、「454SEQ.アダプター」はシークエンシングアダプターを表わし、「454PCRアダプター」はDNA断片のエマルジョン増幅を可能にするアダプターを表わす。PCRアダプターはビーズへのアニーリング及び増幅を可能にし、3’−T突出部を含んでもよい。
【図1B】複雑度の減少工程において用いられる図解プライマーを示す図である。そのようなプライマーは、通常(2)として示された認識部位領域、(1)として示されたタグセクションを含む定常領域、及びその3’末端で(3)として示された選択的領域の1つ又は複数の選択的なヌクレオチドを含む。
【図2】2%のアガロースゲル電気泳動を用いた、DNA濃度の推定を示す図である。S1はPSP11を表わし、S2はPI201234を表わす。50、100、250及び500ngは、Sl及びS2のDNA量を推定するために、50ng、100ng、250ng及び500ngをそれぞれ表わす。(C)及び(D)は、ナノドロップ分光測光法を用いた、DNA濃度測定を示す図である。
【図3】実施例3の中間の品質査定の結果を示す図である。
【図4】(A)は配列データの加工パイプラインのフローチャート、すなわち、トリミング及びタグ付け(Trimming & Tagging)においてトリミングされた配列データをもたらす既知の配列情報の除去の工程を介して、シークエンシングデータの生成から、推定上のSNP、SSR及びインデルを同定する工程で、コンティグ及びシングルトン(コンティグ中にアセンブリングできない断片)を産出するためにクラスタリング及びアセンブリングを行い、その後推定上の多型性を同定及び評価することができる工程を示す図である。(B)は、さらに多型性抽出の過程を詳述する図である。
【図5A】混合したタグの問題に焦点を当て、パネル1に、サンプル1(MS1)及びサンプル2(MS2)に関連したタグを伴う、混合したタグの例を提供する図である。パネル2は、この現象の図解の説明を提供する。サンプル1(S1)及びサンプル2(S2)に由来したAFLP制限断片は、サンプル特異的なタグのS1及びS2を伴う両側で、アダプター(「鍵遺伝子アダプター」)とライゲーションされる。増幅及びシークエンシングの後で、e期待された断片はS1−S1タグを有する断片及びS2−S2タグを有する断片である。さらに、予想外に観察されるものはタグS1−S2を伴う断片又はS2−S1を伴う断片でもある。
【図5B】パネル3は、ヘテロ二本鎖産物がサンプル1及びサンプル2からの断片から形成される、混合したタグの生成の仮説的な原因について説明する。T4 DNAポリメラーゼ又はクレノウの3’−5’エキソヌクレアーゼ活性により、続いてヘテロ二本鎖では3’突出末端が無くなる。重合の間に、ギャップはヌクレオチドで満たされ、間違ったタグが導入される。これは、ほぼ同様の長さ(上部のパネル)のヘテロ二本鎖に作動するが、より長さが変化するヘテロ二本鎖に対しても作動する。
【図5C】パネル4は、混合したタグの形成をもたらす従来のプロトコルを右側に、及び修飾されたプロトコルを右側に提供する。
【図6A】コンカテマー形成の問題に焦点を当て、パネル1においてコンカテマーの代表例を挙げ、様々なアダプター及びタグ区分には、それらの起源で下線を引く(すなわち、サンプル1からのMseI制限部位アダプター、サンプル2からのMseI制限部位アダプター、サンプル1からのEcoRI制限部位アダプター、サンプル2からのEcoRI制限部位アダプターに、それぞれ対応するMS1、MS2、ES1及びES2)。パネル2は、S1−S1タグ及びS2−S2タグを伴う、期待された断片、及び観察されたが期待されないサンプル1及びサンプル2からの断片のコンカテマーである、S1−S1−S2−S2を明示する。
【図6B】混合したタグと同様に、AFLPアダプターに突出部を導入すること、修飾されたシークエンシングアダプター、及びシークエンシングアダプターをライゲーションする場合の末端を平滑にする工程の省略によって、コンカテマーの生成を回避するパネル3の解決法。ALP断片が互いにライゲーションすることができないのでコンカテマー形成が見られず、末端を平滑にする工程が省略できないので混合した断片は発生しない。
【図6C】パネル4は、混合したタグと同様に、コンカテマー形成を回避するために、修飾されたアダプターを用いた修飾されたプロトコルを提供する。
【図7】推定上の一塩基多型(SNP)を含む、コショウAFLP断片配列の多重アライメント「10037_CL989contig2」を示す図である。SNP(黒い矢印によって示された)は、上部の2つの読み取りの名称中のMS1タグの存在によって表わされた、サンプル1(PSP11)の両方の読み取りにあるA対立遺伝子、及び下部2つ読み取りの名称中のMS2タグの存在によって表わされた、サンプル2(PI201234)にあるG対立遺伝子によって定義されることに留意されたい。読み取りの名称は左側に示される。この多重アライメントのコンセンサス配列は次のとおりである(5’−3’):
【化1】
【図8A】新たな単純反復配列(SSR)の発見のためのハイスループットシークエンシングと組み合わせたSSRを標的とした濃縮戦略の略図である。
【図8B】SNPWave検出を用いるコショウ中のG/A SNPの検証を示す図である。P1=PSP11、P2=PI201234。8つのRILの子孫が番号1〜8によって示される。
【発明を実施するための形態】
【0031】
本発明は、1つ又は複数の多型性の同定のための方法を提供し、
a)対象となる第1の核酸サンプルを提供する工程と、
b)対象となる第1の核酸サンプルについて複雑度の減少を行ない、第1の核酸サンプルの第1のライブラリーを提供する、工程と、
c)対象となる第2の核酸サンプル又はさらなる核酸サンプルにより、連続的に又は同時に工程a)及び工程b)を行ない、対象となる第2の核酸サンプルの第2のライブラリー又はさらなる核酸サンプルのさらなるライブラリーを得る、工程と、
d)第1のライブラリー及び第2のライブラリー又はさらなるライブラリーの少なくとも一部をシークエンシングする工程と、
e)工程d)において得られた配列をアライメントさせる工程と、
f)工程e)のアライメントにおいて、第1の核酸サンプル及び第2の核酸サンプル又はさらなる核酸サンプルの間の1つ又は複数の多型性を決定する工程と、
g)工程f)において決定された1つ又は複数の多型性を用い、1つ又は複数の検出プローブを設計する、工程と、
h)対象となる検査サンプルの核酸を提供する工程と、
i)対象となる検査サンプルの核酸について工程b)の複雑度の減少を行ない、検査サンプルの核酸の検査ライブラリーを提供する、工程と、
j)検査ライブラリーをハイスループットスクリーニングして、工程g)において設計された1つ又は複数の検出プローブを用いて、工程f)において決定された多型性の存在、多型性の非存在、又は多型性の量を同定する、ハイスループットスクリーニングする工程と
を含む。
【0032】
工程a)では、対象となる第1の核酸サンプルが提供される。対象となる上記第1の核酸サンプルは、好ましくは、全ゲノムDNA又はcDNAライブラリーのような複雑な核酸サンプルである。複雑な核酸サンプルが全ゲノムDNAであることが好ましい。
【0033】
工程b)では、複雑度の減少は、第1の核酸サンプルの第1のライブラリーを提供するために、対象となる第1の核酸サンプルについて行なわれる。
【0034】
本発明の1つの実施形態において、核酸サンプルの複雑度の減少の工程は、制限断片の核酸サンプルを酵素で切断すること、制限断片を分離すること、及び制限断片の特定のプールを選択することを含む。その後任意で、選択された断片は、PCRプライマー鋳型/結合配列を含むアダプター配列にライゲーションされる。
【0035】
複雑度の減少の1つの実施形態において、II型エンドヌクレアーゼは核酸サンプルを消化するために用いられ、制限断片はアダプター配列に選択的にライゲーションされる。アダプター配列は、ライゲーションされる突出部に様々なヌクレオチドを含むことが可能であり、突出部でヌクレオチドの適合セットを有するアダプターのみが、断片にライゲーションされ、続いて増幅される。この技術は、当該技術分野において、「インデックスリンカー」として表現される。この原理の例は、とりわけUnrau P.及びDeugau K.V.(1994)Gene 145:163-169で見出すことができる。
【0036】
別の実施形態において、複雑度の減少の方法は、異なる標的部位及び異なる頻度を有する2つの制限エンドヌクレアーゼ、及び2つの異なるアダプター配列を利用する。
【0037】
本発明の別の実施形態において、複雑度の減少の工程は、サンプルで任意配列プライマーPCRを行なうことを含む。
【0038】
本発明のさらに別の実施形態において、複雑度の減少の工程は、DNAの変性及びDNA再アニーリングによって反復配列を除去すること、及びその後二本鎖二重鎖(double-stranded duplexes)を除去することを含む。
【0039】
本発明の別の実施形態において、複雑度の減少の工程は、望ましい配列を含むオリゴヌクレオチドプローブに結合された磁気ビーズへ核酸サンプルをハイブリダイズすることを含む。この実施形態は、ハイブリダイズされたサンプルを一本鎖DNAヌクレアーゼに暴露し、一本鎖DNAを除去する暴露すること、クラスII制限酵素を含むアダプター配列をライゲーションし、磁気ビーズを遊離するライゲーションすることをさらに含んでもよい。この実施形態は、単離されたDNA配列の増幅を含んでもよいし、含まなくてもよい。さらに、アダプター配列は、PCRオリゴヌクレオチドプライマーのための鋳型として用いられてもよいし、用いられなくてもよい。この実施形態において、アダプター配列は配列識別子又はタグを含んでもよいし、含まなくてもよい。
【0040】
別の実施形態において、複雑度の減少の方法は、ミスマッチ結合タンパク質にDNAサンプルを暴露すること、及びサンプルをエキソヌクレアーゼそしてその後一本鎖ヌクレアーゼで、3’から5’方向へ消化することを含む。この実施形態は、ミスマッチ結合タンパク質に結合された磁気ビーズの使用を含んでもよいし、含まなくてもよい。
【0041】
本発明の別の実施形態において、複雑度の減少は、本明細書の他の部分に記述されるようなCHIP法、又はSSR、NBS領域(ヌクレオチド結合領域)、プロモーター/エンハンサー配列、テロマーコンセンサス配列、MADSボックス遺伝子、ATPアーゼ遺伝子ファミリー、及び他の遺伝子ファミリーのような保存モチーフに対するPCRプライマーの設計を含む。
【0042】
工程c)において、対象となる第2の核酸サンプルの第2のライブラリー又はさらなる核酸サンプルのさらなるライブラリーを得るために、対象となる第2の核酸サンプル又はさらなる核酸サンプルにより、工程a)及び工程b)は連続的又は同時に行なわれる。対象となる当該第2の核酸サンプル又は当該さらなる核酸サンプルは、好ましくは全ゲノムDNAのような複雑な核酸サンプルでもある。複雑な核酸サンプルが全ゲノムDNAであることが好ましい。当該第2の核酸サンプル又は当該さらなる核酸サンプルが、第1の核酸サンプルに関連していることがさらに好ましい。第1の核酸サンプル及び第2の核酸又はさらなる核酸は、例えば異なるコショウ系統のような異なる植物の系統又は異なる変種であってもよい。工程a)及び工程b)は、単に対象となる第2の核酸サンプルについて行なわれてもよいが、さらに対象となる第3の核酸サンプル、第4の核酸サンプル、第5の核酸サンプル等で行なわれてもよい。
【0043】
第1の核酸サンプル及び第2の核酸サンプル又はさらなる核酸サンプルに、同様な方法を用いて、実質的に同等の条件下、好ましくは同一の条件下で、複雑度の減少が行なわれた場合、本発明に記載の方法が最も有用になることに留意されたい。そのような条件下では、(複雑な)核酸サンプルの同様の(匹敵する)画分が得られるだろう。
【0044】
工程d)において、第1のライブラリー及び第2のライブラリー又はさらなるライブラリーの少なくとも一部はシークエンシングされる。第1のライブラリー、第2のライブラリー又はさらなるライブラリーからシークエンシングされた断片のオーバーラップの量は、少なくとも50%、より好ましくは少なくとも60%、さらにより好ましくは少なくとも70%、より一層好ましくは少なくとも80%、さらにより好ましくは少なくとも90%、及び最も好ましくは少なくとも95%が好ましい。
【0045】
シークエンシングは、ダイデオキシ連鎖停止法のような、当該技術分野において既知である任意の手段によって、原則としては行われてもよい。しかしながら、シークエンシングは、国際公開特許第WO03/004690号、同第WO03/054142号、同第WO2004/069849号、同第WO2004/070005号、同第WO2004/070007号及び同第WO2005/003375号(Seo et al. (2004) Proc. Natl. Acad. Sci. USA 101:5488-93)に(全て454コーポレーションの名で)開示された方法のようなハイスループットシークエンシング法、及びヘリオス(Helios)、ソレクサ(Solexa)、USゲノミクス(US Genomics)等の技術(これらは参照により本明細書において援用される)を用いて行なわれることが好ましい。シークエンシングは、国際公開特許第WO03/004690号、同第WO03/054142号、同第WO2004/069849号、同第WO2004/070005号、同第WO2004/070007号、及び同第WO2005/003375号に(全て454コーポレーションの名で)開示された装置及び/又は方法を用いて行なわれることが最も好ましく、それらは参照により本明細書において援用される。記述された技術は、一回の実行において4000万塩基のシークエンシングを可能にし、競合技術よりも100倍速く、より安い。シークエンシング技術は、1)DNAの切断及び一本鎖DNA(ssDNA)のライブラリーに特異的なアダプターのライゲーションと、2)ビーズに対するssDNAのアニーリング、及び油中水滴型マイクロリアクター中のビーズの乳化と、3)PicoTiterPlate(登録商標)におけるDNAを伴うビーズの沈着と、4)ピロリン酸光シグナルの生成による100,000ウェルの同時シークエンシングとのおおまかには4つの工程から成る。この方法はより詳細に以下で説明されるだろう。
【0046】
工程e)において、工程d)で得た配列はアライメントを提供するためにアライメントされる。比較目的のための配列のアライメントの方法は、当該技術分野において既知である。様々なプログラム及びアライメントアルゴリズムは、Smith及びWaterman(1981)Adv. Appl. Math. 2:482; Needleman及びWunsch(1970)J. Mol. Biol. 48:443; Pearson及びLipman(1988)Proc. Natl. Acad. Sci. USA 85:2444; Higgins及びSharp(1988)Gene 73:237-244; Higgins及びsharp(1989)CABIOS 5:151-153; Corpet et al.(1988)Nucl. Acids Res. 16:10881-90; Huang et al.(1992)Computer Appl. in the Biosci. 8:155-65;及びPearson et al.(1994)Meth. Mol. Biol. 24:307-31において記述され、これらは本明細書において参照により援用される。Altschul et al.(1994)Nature Genet. 6:119-29(本明細書において参照により援用される)は、配列アラインメントの方法及び相同性の計算について詳細な考察を提供する。
【0047】
NCBIの基本的局所アライメント検索ツール(Basic Local Alignment Search Tool)(BLAST)(Altschul et al., 1990)は、配列解析プログラムのblastp、blastn、blastx、tblastn、及びtblastxに関連する使用について、国立生体情報センター(National Center for Biological Information)(NCBI、メリーランド州ベテスダ)及びインターネット上を含むいくつかのソースから利用可能である。それは<http://www.ncbi.nlm.nih.gov/BLAST/>でアクセスすることができる。このプログラムを用いて、配列同一性を決定する方法の説明は、<http://www.ncbi.nlm.nih.gov/BLAST/blast_help.html>で利用可能である。さらなる適用は、マイクロサテライトの抽出において可能である(Varshney et al. (2005) Trends in Biotechn. 23(1) :48-55を参照)。
【0048】
典型的には、アライメントは、アダプター/プライマー及び/又は識別子をトリミングした(すなわち、核酸サンプルから生じる断片からの配列データのみを用いて)配列データ上で行なわれる。典型的には、得られた配列データは、断片の起源を同定するため(すなわち、どのサンプルから)に用いられ、アダプター及び/又は識別子に由来した配列はデータから取り除かれ、アライメントはこのトリミングされたセット上で行なわれる。
【0049】
工程f)において、1つ又は複数の多型性は、アライメントにおいて、第1の核酸サンプル及び第2の核酸サンプル又はさらなる核酸サンプルの間で決定される。第1の核酸サンプル及び第2の核酸サンプル又はさらなる核酸サンプルに由来した配列を比較することができるように、当該アライメントは作られる。その後、違いは多型性を反映して同定することができる。
【0050】
工程g)において、工程g)で決定された1つ又は複数の多型性は、例えばDNAチップ又はビーズに基づいた検出プラットフォーム上のハイブリダイゼーションによる検出のための、検出プローブを設計するために用いられる。多型性が反映されるように、検出プローブは設計される。一塩基多型(SNP)の場合には、検出プローブは、典型的には、対立遺伝子識別を最大限にするような中央の位置での変異SNP対立遺伝子を含む。そのようなプローブは、或る特定の多型性がある検査サンプルをスクリーニングするのに有利に用いることができる。プローブは、当該技術分野において既知の任意の方法を用いて合成することができる。プローブは、典型的にはハイスループットスクリーニング法に適切なように設計される。
【0051】
工程h)において、対象となる検査サンプルの核酸が提供される。検査サンプルの核酸は任意のサンプルであってもよいが、好ましくは多型性についてマップされる別の系統又は変種であってもよい。一般に、研究された生物の生殖質を表わす検査サンプルのコレクションを、(SN)多型性が純種であり検出可能であることを実験的に検証するために、及び観察された対立遺伝子の対立遺伝子頻度を計算するために用いる。任意で、遺伝学的マッピング集団のサンプルも、多型性の遺伝学的地図の位置を決定するために、検証工程に含まれる。
【0052】
工程i)において、工程b)の複雑度の減少は、検査サンプルの核酸の検査ライブラリーを提供するために、対象となる検査サンプルの核酸について行なわれる。本発明に記載の方法の全体にわたって、複雑度の減少のために同様な方法が、実質的に同等な、好ましくは同一の条件を用いて、それによりサンプルの同様の画分をカバーして、用いられることは非常に好ましい。しかしながら、タグが検査ライブラリーにおいて断片上に存在してもよいが、タグを付けた検査ライブラリーを得ることは必要とされない。
【0053】
工程j)において、工程g)で設計された検出プローブを用いて、工程f)で決定された多型性の存在、多型性の非存在、又は多型性の量を同定するために、検査ライブラリーでハイスループットスクリーニングを行なう。当業者は、プローブを用いたハイスループットスクリーニングのためのいくつかの方法を知っている。工程g)で得られた情報を用いて設計された1つ又は複数のプローブが、DNAチップのようなアレイ上に固定され、続いてそのようなアレイが、ハイブリダイズする条件下で検査ライブラリーと接触されることが好ましい。アレイ上の1つ又は複数のプローブに相補的な検査ライブラリー中のDNA断片は、そのような条件下でそのようなプローブにハイブリダイズし、したがって検出することができる。工程j)で得られた検査ライブラリーを固定化させること、及びハイブリダイズする条件下で、上記の固定された検査ライブラリーを、工程h)で設計されたプローブと接触させることのような、ハイスループットスクリーニングの他の方法も、本発明の範囲内で意図される。
【0054】
別のハイスループットシークエンシングスクリーニング技法は、とりわけSNPのチップに基づいた検出を用いてAffymetrixによって提供され、ビーズ技術がIlluminaによって提供される。
【0055】
有利な実施形態において、本発明に記載の方法の工程b)は、タグを付けたライブラリーを得るためにライブラリーをタグ付けする工程をさらに含み、当該方法は、組合せライブラリーを得るための第1のタグを付けたライブラリー及び第2のタグを付けたライブラリー又はさらなるタグを付けたライブラリーを組み合わせる工程c1)をさらに含む。
【0056】
タグ付けは、第1の核酸サンプルの第1のタグを付けたライブラリーを得るのに必要な工程の量を減少させるように、複雑度の減少の工程の間に行なわれることが好ましい。そのような同時のタグ付けは、例えば、各々のサンプルに対する特有の(ヌクレオチド)識別子を含むアダプターを用いて、AFLPにより達成することができる。
【0057】
タグ付けは、2つ以上の核酸サンプルのライブラリーが、組合せライブラリーを得るために組み合わせられる場合、異なる起源の、例えば異なる植物系統から得られたサンプルを識別するように意図される。したがって好ましくは、異なるタグは、第1の核酸サンプル及び第2の核酸サンプル又はさらなる核酸サンプルのタグを付けたライブラリーの調製に用いられる。例えば、5つの核酸サンプルが用いられる場合、5つの異なるタグ(それぞれのもとのサンプルを示す5つの異なるタグ)を付けられたライブラリーを得ることが意図される。
【0058】
タグは、核酸サンプルの識別のための当該技術分野において既知の任意のタグであってもよいが、好ましくは短い識別子配列である。そのような識別子配列は、例えば、複雑度の減少によって得られたライブラリーの起源を示すために用いられる、長さが変化する非反復塩基配列であり得る。
【0059】
好ましい実施形態において、第1のライブラリー及び第2のライブラリー又はさらなるライブラリーのタグ付けは、異なるタグを用いて行なわれる。上に説明されるように、核酸サンプルのライブラリーは、各々自身のタグによって同定されることが好ましい。検査サンプルの核酸はタグ付けの必要はない。
【0060】
本発明の好ましい実施形態において、複雑度の減少は、AFLP(登録商標)(Keygene N.V.(オランダ);例えば、欧州特許第0,534,858号及びVos et al.(1995)著「AFLP:DNAフィンガープリントのための新しい技法(AFLP: a new technique for DNA fingerprinting)」Nucleic Acids Research, vol. 23, no. 21, 4407-4414を参照、これらは参照によってそれらの全体を本明細書において援用される)によって行なわれる。
【0061】
AFLPは選択的制限断片増幅のための方法である。AFLPは任意の事前配列情報は無く、任意の開始DNAで行なうことができる。一般にAFLPは、
(a)核酸、特にDNA又はcDNAを1つ又は複数の特異的な制限エンドヌクレアーゼで消化して、対応する一連の制限断片へとDNAを断片化する工程と、
(b)このように得られた制限断片を、1つの末端が1つ又は両方の制限断片の末端と適合する二本鎖合成オリゴヌクレオチドアダプターとライゲーションして、アダプターでライゲーションされた(好ましくは、タグ付けされた)開始DNAの制限断片を生成する工程と、
(c)アダプターでライゲーションされた(好ましくは、タグ付けされた)制限断片を、ハイブリダイズする条件下で、その3’−末端で少なくとも1つの選択的なヌクレオチドを含む少なくとも1つのオリゴヌクレオチドプライマーと接触させる工程と、
(d)プライマーとハイブリダイズされたアダプターでライゲーションされた(好ましくは、タグ付けされた)制限断片を、プライマーがハイブリダイズする開始DNAの制限断片に沿ってハイブリダイズされたプライマーのさらなる伸長を引き起こすように、PCR又は同様の技術によって増幅する工程と、
(e)このように得られた増幅又は伸長したDNA断片を、検出、同定、又は回収する工程
を含む。
【0062】
AFLPは、このようにアダプターにライゲーションされた断片の再現可能なサブセットを提供する。他の複雑度の減少に適切な方法は、クロマチン免疫沈降(ChiP)である。これは、転写因子のようなタンパク質がDNAに結合している間に、核DNAが単離されることを意味する。ChiPでは、最初に抗体はタンパク質に対して用いられ、Ab−タンパク質−DNA複合体をもたらす。この複合体を精製し、それを沈殿させることによって、このタンパク質が結合するDNAが選択される。続いて、DNAはライブラリー構築及びシークエンシングに用いることができる。すなわち、これは、特異的な機能的領域に向けられた、無作為でない様式において複雑度の減少を行なう方法であり、本発明の例では特異的転写因子である。
【0063】
1つのAFLP技術の有用な変形は、非選択的なヌクレオチド(すなわち+0/+0プライマー)を用い、これはしばしばリンカーPCRと呼ばれる。これは、さらに非常に適切な複雑度の減少を提供する。
【0064】
AFLP、その利点、技法と同様にその実施形態、酵素、アダプター、プライマー及びさらなる化合物、並びに本明細書で使用した道具のさらなる説明のために、米国特許第6,045,994号、並びに欧州特許第0,534,858号(B)及び同第976835号及び同第974672号、国際公開特許第WO01/88189号、及びVos et al.Nucleic Acids Research, 1995, 23, 4407-4414が言及され、これらはそれら全体が本明細書に援用される。
【0065】
したがって、本発明の方法の好ましい実施形態において、複雑度の減少は、
− 少なくとも1つの制限エンドヌクレアーゼにより核酸サンプルを消化して、制限断片へ断片化すること、
− 1つ又は両方の制限断片の末端と合うような1つの末端を有する、少なくとも1つの二本鎖合成オリゴヌクレオチドアダプターで得られた制限断片をライゲーションして、アダプターにライゲーションされた制限断片を生成すること、
− ハイブリダイズする条件下で、アダプターにライゲーションされた上記制限断片を、1つ又は複数のオリゴヌクレオチドプライマーと接触させること、及び
− 1つ又は複数のオリゴヌクレオチドプライマーの伸長によって、アダプターにライゲーションされた上記制限断片を増幅することにより行なわれ、
ここで1つ又は複数のオリゴヌクレオチドプライマーの少なくとも1つが、上記制限エンドヌクレアーゼのための標的配列の形成に関与するヌクレオチドを含み、アダプターの存在するヌクレオチドの少なくとも一部を含む、アダプターにライゲーションされた上記制限断片の末端で鎖の端末部分と同じヌクレオチド配列を有するヌクレオチド配列を含み、ここで任意で、当該プライマーの少なくとも1つは、その3’末端で、当該制限エンドヌクレアーゼのための標的配列の形成に関与するヌクレオチドにすぐに隣接して位置する少なくとも1つのヌクレオチドを含む選択された配列を含む。
【0066】
AFLPは、複雑度の減少のための高度に再現可能な方法であり、したがって本発明に記載の方法に対して特に適している。
【0067】
本発明に記載の方法の好ましい実施形態において、アダプター又はプライマーはタグを含む。個別のライブラリーに由来した配列を識別することが重要な場合、特に実際の多型性の同定についてはそうである。ライブラリーにタグ付けするために追加の工程が要求されないので、アダプター又はプライマーにオリゴヌクレオチドタグを組み入れることは非常に便利である。
【0068】
別の実施形態において、タグは識別子配列である。上で議論されるように、そのような識別子配列は、比較される核酸サンプルの量に依存して変化する長さであってもよい。区別されるサンプル間で、タグ配列が1塩基を超えて異なることが好ましいが、約4塩基長(44=256、可能な異なるタグ配列)は、限られた数のサンプル(256個まで)の起源を区別するのに十分である。必要に応じて、タグ配列の長さは結果的に調節することができる。
【0069】
一実施形態において、シークエンシングは、ビーズのような固体支持体上で行なわれる(例えば国際公開特許第WO03/004690号、同第WO03/054142号、同第WO2004/069849号、同第WO2004/070005号、同第WO2004/070007号、及び同第WO2005/003375号(全て454コーポレーションの名で)を参照、それらは参照により本明細書において援用される)。そのようなシークエンシング法は、多くのサンプルの安価で効率的な同時シークエンシングに特に適切である。
【0070】
好ましい実施形態において、シークエンシングは、
− 各々のビーズがアダプターにライゲーションされた単一の断片とアニーリングされるビーズへ、アダプターにライゲーションされた断片をアニーリングする工程と、
− 各々の油中水滴型マイクロリアクターが単一のビーズを含む、油中水滴型マイクロリアクター中のビーズの乳化する工程と、
− 各々のウェルが単一のビーズを含む、ウェル中にビーズを充填する工程と、
− ピロリン酸シグナルを生成する工程と
を含む。
【0071】
第1の工程において、シークエンシングアダプターは、組合せライブラリー中の断片へライゲーションされる。当該シークエンシングアダプターは、少なくともビーズへのアニーリングのための「キー」領域、シークエンシングプライマー領域、及びPCRプライマー領域を含む。それにより、アダプターにライゲーションされた断片が得られる。
【0072】
さらなる工程において、アダプターにライゲーションされた断片は、各々のビーズが単一アダプターにライゲーションされた断片にアニーリングする、ビーズへアニーリングされる。大多数のビーズについて、1つのビーズ当たりに、1つの単一アダプターにライゲーションされた断片のアニーリングを保証するように、アダプターにライゲーションされた断片のプールへ、ビーズが過剰に加えられる(ポアソン分布)。
【0073】
次の工程において、各々の油中水滴型マイクロリアクターが単一のビーズを含む、油中水滴型マイクロリアクターでビーズが乳化される。PCR試薬は、PCR反応がマイクロリアクター中で起こることを可能にする油中水滴型マイクロリアクターに存在する。続いて、マイクロリアクターは破壊され、DNAを含むビーズ(DNA陽性ビーズ)が濃縮される。
【0074】
以下の工程において、各々のウェルが単一のビーズを含む、ウェルにビーズが充填される。ウェルは、好ましくは、大量の断片の同時シークエンシングを可能にするPicoTiter(商標)プレートの一部である。
【0075】
酵素を伴うビーズの追加後、断片の配列はピロシークエンシングを用いて決定される。引き続いての工程において、PicoTiterプレート及びビーズは、その中の酵素ビーズと同様に、従来のシークエンシング試薬の存在下で異なるデオキシリボヌクレオチドへ曝され、デオキシリボヌクレオチドの取り込みの際、記録される光シグナルが生成される。正確なヌクレオチドの取り込みにより、検出可能なピロシークエンシングシグナルが生成されるだろう。
【0076】
ピロシークエンシング自体は、当該技術分野において既知であり、とりわけ、www.biotagebio.com;www.pyrosequencing.com / tab technologyで記述される。技術は、例えば、国際公開特許第WO03/004690号、同第WO03/054142号、同第WO2004/069849号、同第WO2004/070005号、同第WO2004/070007号、及び同第WO2005/003375号で(全て454コーポレーションの名で)、さらに適用され、それらは本明細書において参照により援用される。
【0077】
工程k)のハイスループットスクリーニングは、好ましくはアレイ上に工程h)で設計されたプローブの固定化によって行なわれ、その後ハイブリダイズする条件下で、プローブを含むアレイを、検査ライブラリーと接触させる。好ましくは、接触の工程は、ストリンジェントなハイブリダイズ条件下で行なわれる(Kennedy et al.(2003)Nat. Biotech.; published online 7 september 2003: 1-5を参照)。当業者は、アレイ上へのプローブの固定化に適切な方法、及びハイブリダイズする条件下で接触させる方法を承知している。この目的に適切な典型的な技術は、Kennedy et al.(2003)Nat. Biotech.; published online 7 september 2003: 1-5に概説される。
【0078】
1つの特に有利な適用は、倍数体作物の品種改良において見出される。高範囲での倍数体作物のシークエンシング、SNP及び様々な対立遺伝子の同定、並びに対立遺伝子特異的な増幅のためのプローブの開発によって、倍数体作物の品種改良の著しい進歩が可能となった。
【0079】
本発明の一部として、選択的増幅を複数のサンプルに対して用いて無作為に選択されたサブセットの生成と、及びハイスループットシークエンシング技術との組合せは、多型性の効率的なハイスループット同定について、本明細書において記述された方法のさらなる改良のために解決しなければならない、或る特定の複雑な問題を提示することが発見された。より詳細には、複数の(すなわち、第1の及び第2の又はさらなる)サンプルが複雑度の減少を行なった後にプール中で組み合わせられる場合、多くの断片が2つのサンプルに由来するように見える、又は言い換えれば、1つのサンプルへ独自に割り当てることができなかった多くの断片が同定され、したがって多型性を同定する過程の中で用いることができないという問題が起こることが発見された。これは、方法の信頼性の低下及び適切に同定され得る多型性(SNP、インデル、SSR)の減少をもたらす。
【0080】
割り当てることができなかった断片のヌクレオチド配列全体の注意深く詳しい分析の後、それらの断片は2つの異なるタグ含有アダプターを含んでおり、この断片は複雑度を減少させたサンプルの生成とシークエンシングアダプターのライゲーションとの間で恐らく形成されたことが発見された。この現象は「混合したタグ付け」として表現される。したがって本明細書において用いられるように、「混合したタグ付け」として表現される現象は、断片を1つのサンプルへ関連付けるタグを片側で含むが、断片の反対側では断片を他のサンプルへ関連付けるタグを含む断片を指す。したがって、1つの断片は、2つのサンプルに由来するかのように見える(両方とも(quod non))。これは多型性の誤った同定をもたらし、したがって不適当である。
【0081】
2つのサンプル間でヘテロ二本鎖断片の形成が、この異常に進行して存在することが理論付けられた。
【0082】
この問題の解決は、複雑度が減少させられるサンプルを、ハイスループットシークエンシング前に増幅することが可能であるビーズにアニーリングされた断片へ変換するための戦略の再計画において発見された。この実施形態において、各々のサンプルでは複雑度の減少及び任意の精製が行なわれる。その後、各々のサンプルをブラント(末端を平滑)にし、その後ビーズへアニーリング可能なシークエンシングアダプターへライゲーションする。その後、シークエンシングアダプターにライゲーションされた断片のサンプルは組み合わせられ、エマルジョン重合及び続くハイスループットシークエンシングのために、ビーズへライゲーションされる。
【0083】
本発明のさらなる部分として、コンカテマーの形成が多型性の適切な同定を妨げるということが分かった。コンカテマーは、複雑度を減少させた産物が、例えばT4 DNAポリメラーゼによって、「ブラントにされた」又は「平滑にされた」後に形成される断片として同定され、ビーズへのアニーリングを可能にするアダプターへライゲーションする代わりに、互いにライゲーションし、これによってコンカテマーを生成する、すなわちコンカテマーはブラントにされた断片の二量体化の結果である。
【0084】
この問題の解決は、特異的に修飾される或る特定のアダプターの使用において発見された。複雑度の減少から得られた増幅された断片は、典型的には、3’−5’エキソヌクレアーゼプルーフリーディング活性がない或る特定の好ましいポリメラーゼの特性による、3’−A突出部を含む。そのような3’−A突出部の存在もまた、アダプターライゲーション前に、断片をブラントにする理由である。アダプターが3’−T突出部を含み、ビーズへアニーリングすることが可能なアダプターの提供によって、「混合したタグ」及びコンカテマーの両方の問題が、1つの工程の中で解決できることが発見された。これらの修飾したアダプターを用いることのさらなる利点は、従来の「ブラントにする」工程及び続くリン酸化工程を省略することができるということである。
【0085】
したがって、各々のサンプルの複雑度の減少工程の後のさらなる好ましい実施形態において、工程は、複雑度の減少工程から得られたアダプターにライゲーションされた増幅された制限断片上で行なわれ、それによってこれらの断片へシークエンシングアダプターがライゲーションされ、シークエンシングアダプターは3’−T突出部を含み、ビーズへアニーリングすることができる。
【0086】
複雑度の減少工程において用いられるプライマーがリン酸化される場合、ライゲーション前の末端を平滑にする(ブラントにする)工程及び中間のリン酸化は回避できることがさらに発見された。
【0087】
したがって、本発明の非常に好ましい実施形態において、本発明は、1つ又は複数の多型性を同定する方法に関し、
a)対象となる複数の核酸サンプルを提供する工程と、
b)各々のサンプル上で複雑度の減少を行ない、核酸サンプルの複数のライブラリーを提供する、工程であって、複雑度の減少が、
− 少なくとも1つの制限エンドヌクレアーゼにより各々の核酸サンプルを消化して、制限断片へ断片化すること、
− 1つ又は両方の制限断片の末端と合うような1つの末端を有する、少なくとも1つの二本鎖の合成オリゴヌクレオチドアダプターで得られた制限断片をライゲーションして、アダプターにライゲーションされた制限断片を生成すること、
− ハイブリダイズする条件下で、前記アダプターにライゲーションされた制限断片を、1つ又は複数のリン酸化されたオリゴヌクレオチドプライマーと接触させること、及び
− 1つ又は複数のオリゴヌクレオチドプライマーの伸長によってアダプターにライゲーションされた上記制限断片を増幅することであって、ここで1つ又は複数のオリゴヌクレオチドプライマーの少なくとも1つが、上記制限エンドヌクレアーゼのための標的配列の形成に関与するヌクレオチドを含み、アダプターの存在するヌクレオチドの少なくとも一部を含む、アダプターにライゲーションされた当該制限断片の末端で鎖の端末部分と同じヌクレオチド配列を有するヌクレオチド配列を含み、ここで任意で、当該プライマーの少なくとも1つが、その3’末端で、該制限エンドヌクレアーゼのための標的配列の形成に関与するヌクレオチドにすぐに隣接して位置する少なくとも1つのヌクレオチドを含む選択された配列を含み、ここでアダプター及び/又はプライマーがタグを含むこと
によって行なわれる工程と、
c)組合せライブラリーへ上記ライブラリーを組み合わせる工程と、
d)ビーズへアニーリングすることが可能なシークエンシングアダプターを、組合せライブラリー中の増幅されたアダプターでキャッピングされた断片へライゲーションし、3’−T突出部を伴うシークエンシングアダプターを用い、ビーズにアニーリングされた断片をエマルジョン重合する工程と、
e)組合せライブラリーの少なくとも一部をシークエンシングする工程と、
f)工程e)において得られた各々のサンプルからの配列をアライメントさせる工程と、
g)工程f)のアライメントにおいて複数の核酸サンプル間で1つ又は複数の多型性を決定する工程と、
h)工程g)において決定された1つ又は複数の多型性を用いて、検出プローブを設計する工程と、
i)対象となる検査サンプルの核酸を提供する工程と、
j)対象となる検査サンプルの核酸について工程b)の複雑度の減少を行ない、検査サンプルの核酸の検査ライブラリーを提供する、工程と、
k)検査ライブラリーでハイスループットスクリーニングを行ない、工程h)において設計された検出プローブを用いて、工程g)において決定された多型性の存在、多型性の非存在、又は多型性の量を同定する、工程と
を含む。
【実施例1】
【0088】
EcoRI/MseI制限ライゲーション混合物(1)は、コショウの系統PSP−11及びPI20234のゲノムDNAから生成された。制限ライゲーション混合物を10倍に希釈し、5マイクロリットルの各々のサンプルは、EcoRI+1(A)及びMseI+1(C)プライマー(セットI)により前増幅された(2)。増幅後に、2つのコショウのサンプルの前増幅産物の品質を、1%アガロースゲル上でチェックした。前増幅産物を20倍に希釈し、その後KRSEcoRI+1(A)及びKRSMseI+2(CA)AFLP前増幅を行なった。下記のプライマー配列番号1〜4の3’−末端で、KRS(識別子)区分には下線が引かれており、選択的なヌクレオチドは太字とする。増幅後に、2つのコショウのサンプルの前増幅産物の品質を、1%アガロースゲル上で、並びにEcoRI+3(A)及びMseI+3(c) (3) AFLP フィンガープリント(4)によりチェックした。2つのコショウ系統の前増幅産物を、キアゲン(Qiagen)PCRカラムの上で別々に精製した(5)。サンプルの濃度をナノドロップ(nanodrop)で測定した。合計5006.4ngのPSP−11及び5006,4ngのPI20234を混合し、シークエンシングした。
【0089】
PSP−11の前増幅に用いられるプライマーセットI
【化2】
【0090】
PI20234の前増幅に用いられるプライマーセットII
【化3】
【0091】
(1)EcoRI/MseI制限ライゲーション混合物
制限混合物(40ul/サンプル)
DNA 6μl(±300ng)
ECoRI(5U) 0.1μl
MseI(2U) 0.05μl
5×RL 8μl
MQ 25.85μl
合計 40μl
37℃における1時間のインキュベーション
【0092】
ライゲーション混合物(10μl/サンプル)
10mM ATP 1μl
T4 DNA リガーゼ 1μl
ECoRIアダプター(5pmol/μl) 1μl
MseIアダプター(50pmol/μl) 1μl
5×RL 2μl
MQ 4μl
合計 10μl
の添加
37℃における3時間のインキュベーション
【0093】
EcoRIアダプター
【化4】
【0094】
MseIアダプター
【化5】
【0095】
(2)前増幅
前増幅(A/C):
RL混合物(10×) 5μl
EcoRIプライマー E01L(50ng/ul) 0.6μl
MseIプライマー M02K(50ng/ul) 0.6μl
dNTPs(25mM) 0.16μl
Taqポリメラーゼ(5U) 0.08μl
10×PCR 2.0μl
MQ 11.56μl
1反応につき合計20μl
【0096】
前増幅の温度プロフィール
選択的な前増幅を50μlの反応容量中で行なった。PCRをPE GeneAmp PCRシステム9700で行ない、20サイクルのプロフィールは、94℃30秒間の変性工程でスタートし、その後、56℃60秒間のアニーリング工程、及び72℃60秒間の伸張工程を行なった。
【0097】
EcoRI+1(A)1
【化6】
【0098】
MseI+1(C)1
【化7】
【0099】
事前増幅 A/CA:
PA+1/+1−混合物(20×) :5μl
EcoRIプライマー :1.5μl
MseIプライマー :1.5μl
dNTPs(25mM) :0.4μl
Taqポリメラーゼ(5U) :0.2μl
10×PCR :5μl
MQ :36.3μl
合計 :50μl
【0100】
選択的な前増幅を50μlの反応容量中で行なった。PCRをPE GeneAmp PCRシステム9700で行ない、30サイクルのプロフィールは、94℃30秒間の変性工程でスタートし、その後、56℃60秒間のアニーリング工程、及び72℃60秒間の伸張工程を行なった。
【0101】
(3)KRSEcoRI+1(A)及びKRSMseI+2(CA)2
【化8】
【0102】
太字の選択的なヌクレオチド及び下線を引いたタグ(KRS)
【化9】
【0103】
(4)AFLPのプロトコル
選択的な前増幅を20μlの反応容量中で行なった。PCRをPE GeneAmp PCRシステム9700で行なった。13サイクルのプロフィールは、94℃30秒間の変性工程でスタートし、その後、アニーリング温度が各々のサイクルにおいて0.7℃低下するタッチダウンフェーズを伴う、65℃30秒間のアニーリング工程、及び72℃60秒間の伸張工程を行なった。このプロフィールの後で、94℃30秒間の変性工程、56℃30秒間のアニーリング工程、及び72℃60秒間の伸張工程を伴う、23サイクルのプロフィールを行なった。
【0104】
【化10】
【0105】
(5)キアゲンカラム
キアゲン精製は製造者の説明書に従って行なった:QIAquick(登録商標)スピンハンドブック(http://www1.qiagen.com/literature/handbooks/PDF/DNACleanupAndConcentration/QQSpin/1021422 HBQQSpin 072002ww.pdf)
【実施例2】
【0106】
コショウ
コショウの系統PSP−11及びPI20234からのDNAを、AFLPの鍵遺伝子の認識部位に特異的なプライマーの使用により、AFLP産物を生成するために用いた。これらのAFLPプライマーは本質的に従来のAFLPプライマーと同じであり(例えば、欧州特許第0,534,858号に記述されている)、認識部位領域、定常領域、及び選択的領域において1つ又は複数の選択的なヌクレオチドを通常含むだろう。コショウの系統PSP−11又はPI20234からの150ngのDNAを、制限エンドヌクレアーゼのEcoRI(1反応につき5U)及びMseI(1反応につき2U)により、37℃で1時間消化させ、その後80℃で10分間不活性化を行なった。得られた制限断片を、1つの末端がEcoRI及び/又はMseI制限断片の1つ又は両方の末端と合う二本鎖合成オリゴヌクレオチドアダプターとライゲーションした。+1/+1 AFLPプライマーによるAFLP前増幅反応(1反応につき20μl)を、10倍に希釈した制限ライゲーション混合物で行なった。PCRプロフィール:20*(94℃で30秒+56℃で60秒+72℃で120秒)。異なる+1 EcoRI及び+2 MseI AFLP鍵遺伝子の認識部位に特異的なプライマーによる追加のAFLP反応(1反応につき50μl)を(下記の表、タグは太字とし、選択的なヌクレオチドは下線が引かれている)、20倍に希釈した+1/+1 EcoRI/MseI AFLP前増幅産物で行なった。PCRプロフィール:30*(94℃で30秒+56℃で60秒+72℃で120秒)。AFLP産物を、QIAquick(登録商標)スピンハンドブック(07/2002)の18ページに従って、QIAquick PCR精製キット(QIAGEN)を用いることによって精製し、濃度はナノドロップ(NanoDrop)(登録商標)ND−1000分光測光器により測定した。5μgの+1/+2 PSP−11 AFLP産物及び5μgの+1/+2 PI20234 AFLP産物の合計を一緒にし、23.3μlのTE中で溶解した。最終的に、430ng/μlの濃度で+1/+2 AFLP産物の混合物が得られた。
【0107】
【表1】
【実施例3】
【0108】
トウモロコシ
トウモロコシの系統B73及びM017からのDNAを、AFLPの鍵遺伝子の認識部位に特異的なプライマーの使用により、AFLP産物を生成するために用いた。これらのAFLPプライマーは本質的に従来のAFLPプライマーと同じであり(例えば、欧州特許第0,534,858号に記述されている)、認識部位領域、定常領域、及び3’末端において1つ又は複数の選択的なヌクレオチドを通常含むだろう。
【0109】
コショウ系統のB73又はM017からのDNAを、65℃1時間制限エンドヌクレアーゼTaqI(1反応につき5U)で、及び37℃で1時間MseI(1反応につき2U)で消化し、その後80℃で10分間不活性化を行なった。得られた制限断片を、1つの末端がTaqI及び/又はMseI制限断片の1つ又は両方の末端と合う二本鎖合成オリゴヌクレオチドアダプターとライゲーションした。
【0110】
+1/+1 AFLPプライマーによるAFLP前増幅反応(1反応につき20μl)を、10倍に希釈した制限ライゲーション混合物で行なった。PCRプロフィール:20*(94℃で30秒+56℃で60秒+72℃で120秒)。異なる+2 TaqI及びMseI AFLP鍵遺伝子の認識部位に特異的なプライマーによる追加のAFLP反応(1反応につき50μl)が(下記の表、タグは太字とし、選択的なヌクレオチドは下線が引かれている)、20倍に希釈した+1/+1 TaqI/MseI AFLP前増幅産物で行なわれた。PCRプロフィール:30*(94℃で30秒+56℃で60秒+72℃で120秒)。AFLP産物を、QIAquick(登録商標)スピンハンドブック(07/2002)の18ページに従って、QIAquick PCR精製キット(QIAGEN)を用いることによって精製し、濃度はナノドロップ(登録商標)ND−1000分光測光器により測定した。各々異なる1.25μgのB73 +2/+2 AFLP産物及び各々異なる1.25μgのM017 +2/+2 AFLP産物の合計を一緒にし、30μlのTE中で溶解した。最終的に、333ng/μlの濃度で+2/+2 AFLP産物の混合物が得られた。
【0111】
【表2】
【0112】
最終的に、4つのP1サンプル及び4つのP2サンプルがプール及び濃縮された。合計量25μlのDNA産物及び最終濃度400ng/ul(合計10μg)が得られた。中間の品質査定を図3に示す。
【0113】
454によるシークエンシング
本明細書において以前に記述されたように調製されたコショウ及びトウモロコシのAFLP断片サンプルは、以下に記述されるような454 Life Sciencesにより加工された(Margulies et al., 2005「微細加工高密度ピコリッターリアクター中のゲノムシークエンシング(Genome sequencing in microfabricated high-density picolitre reactors)」Nature 437 (7057) :376-80. Epub July 31, 2005)。
【0114】
データ処理
加工パイプライン:
入力データ
未加工配列データが各々の実行に対して受け取られた:
−200,000〜400,000の読み取り
−ベースコール(塩基呼び出し)品質スコア
【0115】
トリミング及びタグ付け
これらの配列データを、読み取りの始め及び末端で、鍵遺伝子認識部位(KRS)の存在について分析する。これらのKRS配列はAFLPアダプター及びサンプル標識配列の両方から成り、特定のサンプルの特定のAFLPプライマーの組合せに対して特異的である。KRS配列は、BLASTによって同定及びトリミングされ、制限部位が回復される。読み取りは、KRS起源の同定のためのタグでマークされる。トリミングされた配列は、その後の処理を行なうために、長さ(最低33ヌクレオチド)で選択される。
【0116】
クラスタリング及びアセンブリー
MegaBlast分析は、相同配列のクラスターを得るために全てのサイズ選択且つトリミングされた読み取りで行なわれる。引き続いて全てのクラスターは、アセンブリングされたコンティグをもたらすために、CAP3によりアセンブリングされる。両方の工程からの、他の読み取りと一致しないユニーク配列の読み取りが同定される。これらの読み取りはシングルトンとしてマークされる。本明細書において以前に記述された工程を行なう加工パイプラインを図4の(A)に示す。
【0117】
多型性抽出及び品質査定
アセンブリー解析からの最終的なコンティグは、多型性検出の根拠を成す。各々のクラスターのアライメントにおける各々の「ミスマッチ」は、可能性のある多型性である。選択基準を、品質スコアを得るために定義する:
− 1つのコンティグ当たりの読み取りの数
− 1つのサンプル当たりの「対立遺伝子」の頻度
− ホモポリマー配列の発生
− 近隣する多型性の発生
閾値を超えた品質スコアにより、SNP及びインデルは、推定上の多型性として同定される。SSR抽出については、MISA(MIcroSAtellite同定)ツール(http://pgrc.ipk-gatersleben.de/misa)を用いる。このツールはジヌクレオチド、トリヌクレオチド及びテトラヌクレオチド及び化合物SSRモチーフをあらかじめ定められた基準により同定し、これらのSSRの発生を要約する。
【0118】
多型性抽出過程及び品質割当過程を図4の(B)に示す。
【0119】
結果
下記の表は、組み合わせたコショウのサンプルについて2回の454シークエンスの実行、及び組み合わせたトウモロコシサンプルについて2回の実行から得られた配列を組み合わせた分析の結果を要約する。
【0120】
【表3】
【実施例4】
【0121】
コショウ中の一塩基多型(SNP)の発見
DNAの単離
ゲノムDNAは、コショウ組換え近交系(RIL)集団の親の2系統及び10のRILの子孫から単離された。親系統はPSP11及びPI201234である。ゲノムDNAを、Stuart及びViaによって記述された修飾CTAB手順を用いて、個々の苗木の葉材料から単離した(Stuart, C.N., Jr and Via,L.E. (1993)「RAPDフィンガープリンティング及び他のPCR用途のために有用な高速CTAB DNA分離方法(A rapid CTAB DNA isolation technique useful for RAPD fingeprinting and other PCR applications)」Biotechniques, 14, 748-750)。DNAサンプルを、TE(10mMトリスHCl pH 8.0、1mM EDTA)中で100ng/μlの濃度に希釈し、−20℃で保存した。
【0122】
タグ付けしたAFLPプライマーを用いたAFLP鋳型の調製
Zabeau及びVos(1993:「選択的制限断片増幅;DNAフィンガープリントのための一般法(Selective restriction fragment amplification; a general method for DNA fingerprinting)」欧州特許第0534858号(A1)及び(B1);米国特許第6045994号)、並びにVos他(Vos, P., Hogers, R., Bleeker, M., Reijans, M., van de Lee, T., Hornes, M., Frijters, A., Pot, J., Peleman, J., Kuiper, M. et al. (1995)「AFLP:DNAフィンガープリントのための新しい技術(AFLP: a new technique for DNA fingerprinting)」Nucl. Acids Res., 21, 4407-4414)によって記述されたように、制限エンドヌクレアーゼの組合せEcoRI/MseIを用いて、コショウの親系統のPSP11及びPI201234のAFLP鋳型を調製した。
【0123】
具体的には、EcoRI及びMseIによるゲノムDNAの制限は以下のように行なわれた:
DNA制限
DNA 100〜500ng
EcoRI 5単位
MseI 2単位
5×RL緩衝液 8μl
40μlまでのMilliQ水
インキュベーションは37℃で1時間行なった。酵素の制限後に、80℃で10分間インキュベーションによって、酵素を不活性化した。
【0124】
アダプターのライゲーション
10mM ATP 1μl
T4 DNAリガーゼ 1μl
EcoRIアダプター(5pmol/μl) 1μl
MseIアダプター(50pmol/μl) 1μl
5×RL緩衝液 2μl
40μlまでのMilliQ水
インキュベーションは37℃で3時間行なった。
【0125】
選択的なAFLP増幅
制限−ライゲーションに続いて、制限/ライゲーション反応物をT10E0.1で10倍に希釈し、希釈混合物5μlを、選択的増幅工程において鋳型として用いた。+1/+2選択的増幅が意図されたので、最初に+1/+1選択的前増幅工程(標準AFLPプライマーで)が行なわれたことに留意されたい。+1/+1(+A/+C)増幅の反応条件は以下のとおりであった。
【0126】
制限ライゲーション混合物(10倍希釈) 5μl
EcoRIプライマー+1(50ng/μl): 0.6μl
MseIプライマー+1(50ng/μl) 0.6μl
dNTPs(20mM) 0.2μl
Taqポリメラーゼ(5U/μl Amplitaq、PE) 0.08μl
10×PCR緩衝液 2.0μl
20μlまでのMilliQ水
プライマー配列は、
【化11】
であった。
【0127】
PCR増幅は、以下の条件を用いて、金又は銀のブロックでPE9700を用いて行なわれた:20回(94℃で30秒、56℃で60秒及び72℃で120秒)。
【0128】
生成された+1/+1前増幅産物の品質を、断片長の分布をチェックするために、100塩基対ラダー及び1Kbラダーを用いて、1%のアガロースゲルでチェックした。+1/+1選択的増幅に続いて、反応物をT10E0.1で20倍希釈し、希釈混合物5μlをタグ付けしたAFLPプライマーを用いて、+1/+2選択的増幅工程において鋳型として用いた。
【0129】
最終的に、+1/+2(A/+CA)選択的AFLP増幅は以下のように行なわれた:
+1/+1選択的な増幅産物(20倍希釈) 5.0μl
KRS EcoRIプライマー+A(50ng/μl) 1.5μl
KRS MseIプライマー+CA(50ng/μl) 1.5μl
dNTPs(20mM) 0.5μl
Taqポリメラーゼ(5U/μl Amplitaq、Perkin Elmer) 0.2μl
10×PCR緩衝液 5.0μl
50μlまでのMQ
タグ付けされたAFLPプライマー配列は、
PSP11:
【化12】
PI201234:
【化13】
であった。
【0130】
シークエンシング過程の終わりでそれぞれのコショウ系統から生じる増幅産物を区別するために、これらのプライマーの5’末端に4bpタグ(上記で下線が引かれた)が含まれることに留意されたい。
【0131】
4bpの5つのプライムタグ配列を含むAFLPプライマーによる増幅後のコショウAFLP+1/+2増幅産物の略図。
【化14】
【0132】
PCR増幅(1つのサンプル当たり24)を金又は銀のブロックでPE9700を用いて、以下の条件を用いて行なった:30回(94℃で30秒+56℃で60秒+72℃で120秒)。
【0133】
生成された増幅産物の品質を、断片長の分布をチェックするために、100塩基対ラダー及び1Kbラダーを用いて、1%のアガロースゲルでチェックした。
【0134】
AFLP反応物の精製及び定量化。
1つのコショウサンプル当たり、2つの50マイクロリットルの+1/+2選択的なAFLP反応をプールした後、最終的な12の100μl AFLP反応生成物を、QIAquick(登録商標)スピンハンドブック(18ページ)に従って、QIAquick PCR精製キット(QIAGEN)を用いて精製した。各々のカラムに最高100μlの産物を充填した。増幅された産物を、T10E0.1で溶出した。精製された産物の品質を1%アガロースゲルでチェックし、濃度をナノドロップで測定した(図2)。
【0135】
ナノドロップ濃度測定を、各々の精製されたPCR産物の最終的な濃度を、1マイクロリットル当たり300ナノグラムに合わせるために用いた。5マイクログラムのPSP11の精製増幅産物及び5マイクログラムのPI201234の精製増幅産物を混合し、454シークエンシングライブラリーの調製のための10マイクログラムの鋳型材料を生成した。
【0136】
シークエンスライブラリーの調製及びハイスループットシークエンシング
両方のコショウ系統からの混合増幅産物を、Margulies他によって記述されるような、454ライフサイエンスシークエンシング技術を用いて、ハイスループットシークエンシングした(Margulies et al., Nature 437, pp. 376-380及びオンライン上の補足)。具体的には、Margulies及び共同研究者等によって記述されるように、エマルジョンPCR増幅及び続く断片シークエンシングを促進するために、AFLP PCR産物を最初に末端を平滑にし、続いてアダプターにライゲーションした。454のアダプター配列、エマルジョンPCRプライマー、配列プライマー及びシークエンスの実行条件は、全てMargulies及び共同研究者等によって記述されるものであった。図1Aに例示されるように、454シークエンシング過程におけるセファロースビーズ上で増幅されたエマルジョン−PCR断片中の機能要素の直線的な順序は、以下のとおりだった:
454 PCRアダプター − 454シークエンスアダプター − 4bp AFLPプライマータグ1 − 選択的なヌクレオチド(複数可)を含むAFLPプライマー配列1 − AFLP断片内部配列−選択的なヌクレオチド(複数可)を含むAFLPプライマー配列2、4bp AFLPプライマータグ2 − 454配列アダプター − 454PCRアダプター − セファロースビーズ
【0137】
2つのハイスループット454シークエンスの実行は、454 Life Sciences(アメリカ合衆国コネチカット州ブランフォード)によって行なわれた。
【0138】
454シークエンス実行のデータ処理
2回の454シークエンスの実行に由来する配列データを、バイオインフォマティクスパイプライン(Keygene N.V.)を用いて加工した。具体的には、未加工の454ベースコール済みシークエンス読み取りを、FASTAフォーマットで変換し、BLASTアルゴリズムを用いて、タグ付けしたAFLPアダプター配列の存在の有無を検査した。既知のタグを付けたAFLPプライマー配列への高い信頼性の一致に際して、配列をトリミングし、制限エンドヌクレアーゼ部位を回復し、適切なタグを割り当てた(それぞれ、サンプル1 EcoRI(ES1)、サンプル1 MseI(MS1)、サンプル2 EcoRI(ES2)、又はサンプル2 MseI(MS2))。次に、33塩基よりも長いトリミングされた配列の全てを、全体の配列相同性に基づくmegaBLAST手順を用いてクラスターに分けた。次に、クラスターを、CAP3の多重アライメントアルゴリズムを用いて、1つのクラスター当たり1つ又は複数のコンティグ及び/又はシングルトンへアセンブリングした。1つより多くの配列を含むコンティグは、推定上の多型性を表わす配列ミスマッチの有無を検査された、配列ミスマッチには、以下の基準に基づく品質スコアを割り当てた:
*コンティグ中の読み取りの数
*観察された対立遺伝子の分布
上の2つの基準は、各々の推定上のSNP/インデルに対応する、いわゆるQスコアのための根拠を成す。Qスコアは0〜1にわたる;両方の対立遺伝子が少なくとも2度観察された場合にのみ、Qスコア0.3が達成される。
*特定の長さのホモポリマー中の位置(調整可能;3塩基以上のホモポリマーに位置する多型性を回避するための初期設定)
*クラスター中のコンティグの数。
*最も近い隣接する配列ミスマッチへの距離(調整可能;フランキング配列を調べる特定の型の遺伝子型決定分析にとって重要)
*サンプル1又はサンプル2で観察された対立遺伝子の関連のレベル;
推定上の多型性並びにサンプル1及び2の対立遺伝子間で一貫して完全な関連が存在する場合には、多型性(SNP)が推定上の「エリート」多型性(SNP)として示される。エリート多型性は、2つのホモ接合体系統が発見過程で用いられた場合に、ユニークゲノム配列又は低コピーのゲノム配列に位置する確率が高いと考えられる。反対に、サンプル起源との多型性の弱い関連は、コンティグ中の非対立遺伝子配列のアライメントから生じる誤った多型性を発見してしまうリスクが高い。
【0139】
SSRモチーフを含む配列は、MISA検索ツール(MIcroSAtellelite同定ツール;http://pgrc.ipk-gatersleben.de/misa/から利用可能。)を用いて同定された。
【0140】
実行の全体の統計を、以下の表で示す。
【表4】
【0141】
*SNP/インデル抽出基準は以下のとおりであった:
いずれかの側にも12塩基以内の0.1よりも大きいQスコアを有する隣接する多型性はなく、3塩基以上のホモポリマー中に存在しない。抽出基準は、サンプル1及び2で一貫した関連を考慮しなかった、すなわち、SNP及びインデルは必ずしも推定上のエリートSNP/インデルではない。
【0142】
推定上のエリート単一ヌクレオチド多型を含む多重アライメントの一例を、図7に示す。
【実施例5】
【0143】
PCR増幅及びサンガーシークエンシングによるSNP妥当性の検証
実施例1において同定された推定上のA/G SNPを検証するために、このSNPのためのタグ付き配列部位(STS)分析を、隣接するPCRプライマーを用いて設計した。PCRプライマー配列は以下のとおりであった:
【化15】
【0144】
プライマー1.2rが、5’末端でM13配列プライマー結合部位及び長さスタッファーを含むことに留意されたい。PCR増幅を、鋳型として、実施例4に記述されるように調製したPSP11及びPI210234の+A/+CA AFLP増幅産物を用いて行なった。PCR条件は以下のとおりであった:
1つのPCR反応に対して、下記成分を混合した:
5μl 1/10に希釈したAFLP混合物(app.10ng/μl)
5μl 1pmol/μlプライマー 1.2f(500μMストックから直接希釈したもの)
5μl 1pmol/μlプライマー 1.2r(500μMストックから直接希釈したもの)
5μl PCR混合物 −2μl 10×PCR緩衝液
−1μl 5mM dNTPs
−1.5μl 25mM MgCl2
−0.5μl H2O
5μl 酵素混合物 −0.5μl 10×PCR緩衝液
(Applied Biosystems)
−0.1μl 5U/μl AmpliTaq
DNAポリメラーゼ(Applied Biosystems)
−4.4μl H2O
以下のPCRプロフィール:
サイクル1 2分間;94℃
サイクル2〜サイクル34 20秒間;94℃
30秒間;56℃
2分30秒間;72℃
サイクル35 7分間;72℃
∞;4℃
を使用した。
【0145】
PCR産物をTAクローニング法を用いてベクターpCR2.1(TAクローニングキット;Invitrogen)へクローニングし、INVαF’コンピテント大腸菌細胞へ形質転換させた。形質転換体を青/白のスクリーニングにかけた。PSP11及びPI−201234について各々独立した白色の3つの形質転換体を選択し、プラスミド単離のための液体の選択培地中で、一晩、増殖させた。
【0146】
プラスミドをQIAprepスピンMiniprepキット(QIAGEN)を用いて単離した。続いて、これらのプラスミドのインサートを、以下のプロトコルに従ってシークエンシングし、MegaBACE 1000(Amersham)で溶解した。得られた配列をSNP対立遺伝子の有無について検査した。PI−201234インサートを含む独立した2つのプラスミド、及びPSP11インサートを含む1つのプラスミドは、SNPに隣接する期待されたコンセンサス配列を含んでいた。PSP11断片に由来する配列は期待されたA対立遺伝子(下線が引かれた)を含み、PI−201234断片に由来する配列は期待されたG対立遺伝子(二重下線が引かれた)を含んでいた:
PSP11(配列1):(5’−3’)
【化16】
PI−201234(配列1):(5’−3’)
【化17】
PI−201234(配列2):(5’−3’)
【化18】
【0147】
この結果は、推定上のコショウA/G SNPが、設計されたSTS分析を用いて検出可能な真の遺伝的多型を表わすことを示す。
【実施例6】
【0148】
SNPWave検出によるSNP妥当性の検証
実施例1において同定された推定上のA/G SNPを検証するために、コンセンサス配列を用いて、SNPWaveライゲーションプローブセットは、このSNPの両方の対立遺伝子について定義された。ライゲーションプローブの配列は以下のとおりであった:
SNPWaveプローブ配列(5’−3’)
【化19】
【0149】
共通の遺伝子座特異的プローブ06A164へのライゲーションに際して、94(42+54)塩基及び96(44+52)塩基のライゲーション産物サイズをもたらすように、A及びGの対立遺伝子について、それぞれの対立遺伝子特異的プローブの06A162及び06A163が、2塩基のサイズで異なることに留意されたい。
【0150】
van Eijk及び共同研究者等によって記述されるように、出発物質として100ngのコショウ系統PSP11及びPI201234のゲノムDNA及び8つのRIL子孫を用いて、SNPWaveライゲーション及びPCR反応が実行された(M. J. T. van Eijk, J. L.N. Broekhof, H. J.A. van der Poel, R. C. J. Hogers, H. schneiders, J. Kamerbeek, E. Verstege, J.W. van Aart, H. Geerlings, J. B. Buntjer, A. J. van Oeveren, and P. Vos. (2004)「SNPWave(商標):柔軟な多重化SNP遺伝子型決定技術(SNPWaveTM: a flexible multiplexed SNP genotyping technology)」Nucleic Acids Research 32: e47)。PCRプライマーの配列は次のとおりであった:
【化20】
【0151】
PCR増幅に続いて、PCR産物の精製及びMegaBACE1000での検出は、van Eijk及び共同研究者等(上記参照)によって記述された通りであった。PSP11、PI201234、及び8つのRIL子孫から得られた増幅産物の擬似ゲル画像を、図8Bに示す。
【0152】
SNPWave結果は、P1(PSP11)及びRIL子孫(1、2、3、4、6、及び7)に対して92bp産物(=AAのホモ接合体遺伝子型)、及びP2(PI201233)及びRIL子孫5及び8に対して94bp産物(=GGのホモ接合体遺伝子型)をもたらし、A/G SNPが、SNPWave分析によって検出されることを明確に実証する。
【実施例7】
【0153】
低コピー配列のAFLP断片ライブラリーを濃縮するための戦略
この実施例は、実施例4に記述されていたようなエリート多型性の収率を増加させるために、ユニークゲノム配列の低コピーを標的とする、いくつかの濃縮法を記述する。この方法は4つのカテゴリーに分類することができる:
【0154】
1)葉緑体配列を除いて高品質ゲノムDNAを調製することを目標とする方法
ここで、大量の葉緑体DNAの共単離を除外するために、実施例4に記述されているような全ゲノムDNAの代わりに、核DNAを調製することを提案する。この調製により、断片ライブラリー調製方法で用いられる制限エンドヌクレアーゼ及び選択的なAFLPプライマーに依存して、植物ゲノムDNA配列数の減少がもたらされ得る。高度に純粋なトマト核DNAの単離のプロトコルは、Peterson, DG., Boehm, K.S. & Stack S.M. (1997)「トマト(Lycopersicon esculentum)からのミリグラム量の核DNAの単離、高レベルのポリフェノール化合物を含む植物(Isolation of Milligram Quantities of Nuclear DNA From Tomato (Lycopersicon esculentum), A Plant Containing High Levels of Polyphenolic Compounds)」Plant Molecular Biology Reporter 15 (2), pages 148-153により記述されている。
【0155】
2)低コピー配列のレベルの増加をもたらすと期待される、AFLP鋳型の調製過程で制限エンドヌクレアーゼを用いることを目標とする方法
ここで、AFLP鋳型調製方法において特定の制限エンドヌクレアーゼを用いることを提案する。この使用は、低コピーのゲノム配列又はユニークゲノム配列を標的とすると予想され、遺伝子型決定分析への転換能力の増加により、多型性について濃縮された断片ライブラリーをもたらす。植物ゲノムにおける低コピー配列を標的とする制限エンドヌクレアーゼの一例は、PstIである。他のメチル化感受性の制限エンドヌクレアーゼも、低コピーのゲノム配列又はユニークゲノム配列を優先的に標的とし得る。
【0156】
3)反復配列対低コピー配列の再アニーリング速度論に基づく、高度に重複した配列を選択的に除去することを目標とした方法
ここで、選択的増幅の前に、全ゲノムDNAサンプル又は(cDNA−)AFLP鋳型材料のいずれかから、高度に重複した(反復)配列を選択的に除去することを提案する。
【0157】
3a)高C0t DNA調製は、複雑な植物ゲノムDNA混合物から低コピー配列を濃縮して徐々にアニーリングする一般に用いられる技術である(Yuan et al. 2003;「トウモロコシゲノムの高Cotの配列分析(High-Cot sequence analysis of the maize genome)」Plant J. 34: 249-255)。低コピー配列中に位置する多型性のために、濃縮する出発物質として、全ゲノムDNAの代わりに高C0t DNAを採用することが示唆される。
【0158】
3b)面倒な高C0t調製の代替案は、Zhulidov及び共同研究者等(2004;「カムチャツカガニの二重鎖特異的ヌクレアーゼを用いる単純なcDNA正規化(simple cDNA normalization using Kamchatka crab duplex-specific nuclease)」Nucleic Acids Research 32, e37)、並びにShagin及び共同研究者等(2006;「カニ肝膵臓からの新しい二重鎖特異的ヌクレアーゼを用いるSNP検出のための新規方法(a novel method for SNP detection using a new duplex-specific nuclease from crab hepatopancreas)」Genome Research 12: 1935-1942)によって記述されるように、不完全に一致したDNA二本鎖よりも高い率で、短い完全に一致したDNA二本鎖を切断する、カムチャツカガニからの新規ヌクレアーゼで、変性した再アニーリングdsDNAをインキュベートすることである。具体的には、それは高度に重複した配列の混合物を枯渇させるために、このエンドヌクレアーゼでAFLP制限/ライゲーション混合物をインキュベートし、その後残存する低コピーのゲノム配列又はユニークゲノム配列の選択的なAFLP増幅を行なうことが提案される。
【0159】
3c)メチル濾過は、Cがメチル化される場合に、配列[A/G]Cでメチル化されたDNAを切断する制限エンドヌクレアーゼMcrBCを用いて、低メチル化ゲノムDNA断片について濃縮する方法である(Pablo D. Rabinowicz , Robert Citek, Muhammad A. Budiman, Andrew Nunberg, Joseph A. Bedell Nathan Lakey, Andrew L. O' Sshaughnessy, Lidia U. Nascimento, W. Richard McCombie and Robert A. Martienssen、「陸上植物における遺伝子の差異的なメチル化及び反復(Differential methylation of genes and repeats in land plants)」Genome Research 15:1431-1440, 2005を参照)。McrBCは、多型性発見のための出発物質としてのゲノムの低コピー配列画分を濃縮するために用いられてもよい。
【0160】
4)遺伝子配列を標的とするための、ゲノムDNAとは対照的なcDNAの使用
最終的に、ここで、任意で、正規化のために上の3b中に記述した、二重鎖特異的なカニのヌクレアーゼの使用と組み合わせて、多型性の発見のための出発物質としてのゲノムDNAとは対照的なオリゴdTでプライミングしたcDNAを用いることが提案される。オリゴdTでプライミングしたcDNAの使用により、葉緑体配列も除外されることに留意されたい。或いは、オリゴdTでプライミングしたcDNAの代わりに、cDNA−AFLP鋳型を、AFLPと同様に、残存する低コピー配列の増幅を促進するために用いる(上の3bも参照)。
【実施例8】
【0161】
単純反復配列濃縮のための戦略
この実施例は、実施例4において記述されたSNP発見と同様に、単純反復配列の発見のために提案された戦略を記述する。
【0162】
具体的には、2つ以上のサンプルのゲノムDNAの制限ライゲーションは、例えば、制限エンドヌクレアーゼPstI/MseIを用いて行なわれる。実施例4において記述されているように、選択的なAFLP増幅が行なわれる。次に、選択されたSSRモチーフを含む断片は、2つの方法のうちの1つによって濃縮される。
【0163】
1)Armour及び共同研究者等によって記述されたものと同様の方法での、意図したSSRモチーフと一致するオリゴヌクレオチドを含むフィルター上へのサザンブロットハイブリダイゼーション(例えば、CA/GT反復の濃縮の場合には、(CA)15)と、その後の結合断片の増幅(Armour, J., Sismani, C., Patsalis, P., and Cross, G. (2000)「増幅可能なプローブとのハイブリダイゼーションによる遺伝子座コピー数の測定(Measurement of locus copy number by hybridization with amplifiable probes)」Nueleic Acids Research vol 28, no. 2, pp. 605-609)又は
2)Kijas及び共同研究者等によって記述された解決法での、(AFLP)断片を取り込むためにビオチン化された捕獲オリゴヌクレオチドハイブリダイゼーションプローブを用いる濃縮(Kijas, J.M,. Fowler, J.C., Garbett C.A., and Thomas, M.R., (1994)「ストレプトアビジンがコートされた磁気微粒子に結合したビオチン化オリゴヌクレオチド配列を用いた、柑橘類のゲノムからのマイクロサテライトの濃縮(Enrichment of microsatellites from the citrus genome using biotinylated oligonucleotide sequences bound to streptavidin-coated magnetic particles)」Biotechniques, vol. 16, pp. 656-662)。
【0164】
次に、SSRモチーフが濃縮されたAFLP断片は、前増幅工程で用いられるのと同様のAFLPプライマーを用いて、シークエンスライブラリーを生成するために増幅される。増幅された断片の一部分をT/Aクローニングし、96のクローンを陽性のクローン画分(意図したSSRモチーフ、例えば5反復単位よりも長いCA/GTモチーフを含むクローン)を推定するためのシークエンスとする。SSRを含む断片が濃縮されるかを視覚的に検査するために、任意で、読取り可能なフィンガープリントを得るさらなる選択的増幅の後に、濃縮されたAFLP断片混合物の他の部分を、ポリアクリルアミドゲル電気泳動法(PAGE)によって検出する。これらの制御工程の首尾良く完了させた後、シークエンスライブラリーで、ハイスループット454シークエンシングを行なう。
【0165】
新たなSSR発見のための上の戦略は、図8Aにおいて概略的に示され、捕獲オリゴヌクレオチド配列を置換することによって、他の配列モチーフに対して適応させることができる。
【実施例9】
【0166】
混合したタグの回避ための戦略
混合したタグは、1つのサンプル当たりに、タグ付けされたAFLPプライマーの期待される組合せに加えて、サンプル1のタグを1つの末端に及びサンプル2のタグを他方の末端に含む配列の画分が少量観察されるという観察を示す(実施例4中の表1も参照)。図式的に、混合したタグを含んでいる配列の配置は本明細書において以下で表現される。
【0167】
期待されるサンプルタグの組合せの配置図。
【化21】
【0168】
混合タグの配置図。
【化22】
【0169】
混合したタグの観察によって、配列が、PSP11又はPI−201234のいずれかへ正確に割り当てられることは除外される。
【0170】
実施例4において記述されるコショウのシークエンス実行において観察された混合したタグの配列の一例を、図5Aに示す。期待されるタグ及び混合したタグを含む、観察された断片の配置の概観を、図5Aのパネル2において示す。
【0171】
混合したタグに対して提案された分子的な説明は、シークエンスライブラリーの調製工程の間、3’突出末端を除去するT4 DNAポリメラーゼ又はクレノウ酵素の使用によって、アダプターライゲーション前に、DNA断片がブラントにされるということである(Margulies et al., 2005)。単一のDNAサンプルが加工される場合にはこれはうまくいくのだろうが、異なってタグ付けされたDNAサンプルの2つ以上のサンプルの混合物を使用する場合には、ポリメラーゼによって埋められると、異なるサンプルに由来する相補的な鎖の間にヘテロ二本鎖が形成される際に、間違ったタグ配列の取り込みをもたらす(図5Bパネル3混合したタグ)。その解決法は、図5Cのパネル4において示されるような454シークエンスライブラリーの構築工程において、アダプターライゲーションに続く精製工程の後にサンプルをプールすることであることが見い出された。
【実施例10】
【0172】
454シークエンスライブラリー調製のための改善された設計を使用する、混合したタグ及びコンカテマーの回避ための戦略
実施例9において記述されるような混合したタグを含む低頻度のシークエンス読み取りについての観察の他に、コンカテマーになったAFLP断片から観察された低頻度のシークエンス読み取りが観察された。
【0173】
コンカテマーに由来するシークエンス読み取りの一例を図6Aパネル1において示す。期待されるタグ及びコンカテマーを含む配列の配置を、図式的に図6Aパネル2において示す。
【0174】
コンカテマーになったAFLP断片の発生に対して提案された分子的な説明は、454シークエンスライブラリー調製工程の間に、DNA断片は、3’突出末端を除去するT4 DNAポリメラーゼ又はクレノウ酵素を使用して、アダプターライゲーション前にブラントにされるということである(Margulies et al., 2005)。その結果、ブラントな末端のサンプルDNA断片はライゲーション工程の間にアダプターを競合し、アダプターにライゲーションされる前に互いにライゲーションされるであろう。この現象は、実際、ライブラリーの調製工程において、単一のDNAサンプルが含まれるか、又は複数の(タグ付けされた)サンプルの混合物が含まれているか否かに依存せず、したがって、Margulies及び共同研究者等によって記述されるような従来のシークエンシングの間にも起こってもよい。実施例4において記述されているような複数のタグを付けられたサンプルの使用の場合には、コンカテマーは、タグ情報に基づきサンプルに対する配列読み取りの正確な割り当てを複雑にし、したがって、回避されるべきである。
【0175】
コンカテマー(及び混合したタグ)の形成に対する提案された解決法は、図6Bパネル3において示されるように、ブラント末端アダプターライゲーションを、PCR産物のT/Aクローニングと同様に、3’T突出部を含むアダプターのライゲーションと置換することである。便利なように、これらの修飾された3’T突出部含むアダプターは、アダプター配列のブラント末端コンカテマー形成を防ぐために、反対側の3’末端(それはサンプルDNA断片にライゲーションされないであろう)でC突出部を含むように提案される(図6Bパネル3を参照)。修飾されたアダプターのアプローチを使用する場合の、シークエンスライブラリー構築過程の最終的な適応ワークフローを、図6Cのパネル4において図式的に示す。
【特許請求の範囲】
【請求項1】
増幅されたDNAサンプルのタグ付け減少、DNAサンプルのDNAコンカテマー生成の減少もしくは抑制、及び/または、核酸試料における多型性の同定のための方法に使用することを特徴とする3’−T突出部を伴うアダプターの使用方法。
【請求項2】
請求項1に記載の使用方法において、前記増幅されたDNA試料の混合したタグ付け減少方法は、
DNA試料を提供する工程と、
タグ付けされ増幅されたプライマーを有するDNA試料を増幅してタグ付けされた増幅産物を生成する工程と、
任意的に3’−A突出部を前記タグ付けされた増幅産物の末端に設ける工程と、
前記3’−T突出部を伴うアダプターをライゲーションさせてタグ付けされた増幅産物にする工程と、
を有することを特徴とする使用方法。
【請求項3】
請求項1に記載の使用方法において、前記DNAサンプルからDNA断片のコンカテマー生成の減少または抑制のための方法は、
DNAサンプルからDNA断片を準備する工程と、
任意的に、前記DNA断片を研磨してブラントな末端を有するDNA断片を設ける工程と、
任意的に、ブラントな末端を有するDNA断片の前記末端に、3’−A突出部を設ける工程と、
前記断片にライゲーションされた前記末端において、3’−T突出部を含む前記アダプターを前記DNA断片にライゲーションさせる工程と、
を有することを特徴とする使用方法。
【請求項4】
請求項2又は3に記載の使用方法において、前記DNAサンプルは、複雑度が減少したDNAサンプル及び/又は、前記DNA断片は、複雑度が減少したDNA断片であることを特徴とする使用方法。
【請求項5】
請求項3又は4に記載の使用方法において、前記断片は、増幅産物を生成する(タグ付き)増幅されたプライマーによって増幅されていることを特徴とする使用方法。
【請求項6】
請求項2〜5のいずれか一項に記載の使用方法において、前記アダプターがライゲーションされた断片もしくは増幅産物は、固体支持体上でシークエンシングされることを特徴とする使用方法。
【請求項7】
請求項1に記載の使用方法において、前記核酸試料における多型性の同定のための方法は、
a)対象となる複数の核酸サンプルを提供する工程と、
b)対象となる前記複数の核酸サンプルについて複雑度の減少を行ない、前記複数の核酸サンプルの複数のライブラリーを提供する工程と、
c)3’−T突出部を伴うアダプターを用いて複雑度が減少した前記核酸サンプルにアダプターをライゲーションする工程と、
d)前記ライブラリーの少なくとも一部をシークエンシングする工程と、
e)工程d)において得られた配列をアライメントさせる工程と、
f)工程e)のアライメントにおいて、前記複数の核酸サンプルの間の1つ又は複数の多型性を決定する工程と、
g)任意に、検出プローブを用いて、対象となる検査核酸サンプルをスクリーニングして、工程f)において決定された1つ又は複数の多型性の有無又は量を同定する工程と、
を有することを特徴とする使用方法。
【請求項8】
請求項7に記載の使用方法において、前記検査核酸サンプルが、工程b)に用いられる複雑度の減少を用いて得られた複雑度を減少した核酸サンプルであることを特徴とする使用方法。
【請求項9】
請求項7又は8に記載の使用方法において、前記工程b)が、タグを付けたライブラリーを得るための前記ライブラリーにタグを付ける工程をさらに含むことを特徴とする使用方法。
【請求項10】
請求項9に記載の使用方法において、前記タグは、前記アダプター又は前記プライマーに設けられていることを特徴とする使用方法。
【請求項11】
請求項10に記載の使用方法において、前記タグが、識別子配列であることを特徴とする使用方法。
【請求項12】
請求項10に記載の使用方法において、前記プライマーの少なくとも1つがリン酸化されることを特徴とする使用方法。
【請求項13】
請求項10に記載の使用方法において、前記シークエンシングが、固体支持体上で行なわれることを含むことを特徴とする使用方法。
【請求項14】
請求項7〜13のいずれか一項に記載の使用方法において、スクリーニングがアレイ上に請求項7に記載の工程g)で設計されたプローブの固定化によって行なわれ、その後ハイブリダイズする条件下で、プローブを含む前記アレイを検査ライブラリーと接触させることを特徴とする使用方法。
【請求項15】
請求項14に記載の使用方法を、濃縮されたマイクロサテライトライブラリーのスクリーニング、転写プロファイリングcDNA−AFLP(デジタルノーザン)の実行、複雑なゲノムのシークエンシング、発現配列タグライブラリーのシークエンシング(全体のcDNA又はcDNA−AFLPについて)、マイクロRNAの検出方法(小さなインサートライブラリーのシークエンシング)、バクテリア人工染色体(コンティグ)シークエンシング、AFLP/cDNA−AFLPと組み合わせたバルクセグレガント分析(Bulked Segregant analysis:バルク分離体分析)アプローチ方法、AFLP断片のルーチン検出方法(マーカー利用戻し交配)のために使用することを特徴とする使用方法。
【請求項1】
増幅されたDNAサンプルのタグ付け減少、DNAサンプルのDNAコンカテマー生成の減少もしくは抑制、及び/または、核酸試料における多型性の同定のための方法に使用することを特徴とする3’−T突出部を伴うアダプターの使用方法。
【請求項2】
請求項1に記載の使用方法において、前記増幅されたDNA試料の混合したタグ付け減少方法は、
DNA試料を提供する工程と、
タグ付けされ増幅されたプライマーを有するDNA試料を増幅してタグ付けされた増幅産物を生成する工程と、
任意的に3’−A突出部を前記タグ付けされた増幅産物の末端に設ける工程と、
前記3’−T突出部を伴うアダプターをライゲーションさせてタグ付けされた増幅産物にする工程と、
を有することを特徴とする使用方法。
【請求項3】
請求項1に記載の使用方法において、前記DNAサンプルからDNA断片のコンカテマー生成の減少または抑制のための方法は、
DNAサンプルからDNA断片を準備する工程と、
任意的に、前記DNA断片を研磨してブラントな末端を有するDNA断片を設ける工程と、
任意的に、ブラントな末端を有するDNA断片の前記末端に、3’−A突出部を設ける工程と、
前記断片にライゲーションされた前記末端において、3’−T突出部を含む前記アダプターを前記DNA断片にライゲーションさせる工程と、
を有することを特徴とする使用方法。
【請求項4】
請求項2又は3に記載の使用方法において、前記DNAサンプルは、複雑度が減少したDNAサンプル及び/又は、前記DNA断片は、複雑度が減少したDNA断片であることを特徴とする使用方法。
【請求項5】
請求項3又は4に記載の使用方法において、前記断片は、増幅産物を生成する(タグ付き)増幅されたプライマーによって増幅されていることを特徴とする使用方法。
【請求項6】
請求項2〜5のいずれか一項に記載の使用方法において、前記アダプターがライゲーションされた断片もしくは増幅産物は、固体支持体上でシークエンシングされることを特徴とする使用方法。
【請求項7】
請求項1に記載の使用方法において、前記核酸試料における多型性の同定のための方法は、
a)対象となる複数の核酸サンプルを提供する工程と、
b)対象となる前記複数の核酸サンプルについて複雑度の減少を行ない、前記複数の核酸サンプルの複数のライブラリーを提供する工程と、
c)3’−T突出部を伴うアダプターを用いて複雑度が減少した前記核酸サンプルにアダプターをライゲーションする工程と、
d)前記ライブラリーの少なくとも一部をシークエンシングする工程と、
e)工程d)において得られた配列をアライメントさせる工程と、
f)工程e)のアライメントにおいて、前記複数の核酸サンプルの間の1つ又は複数の多型性を決定する工程と、
g)任意に、検出プローブを用いて、対象となる検査核酸サンプルをスクリーニングして、工程f)において決定された1つ又は複数の多型性の有無又は量を同定する工程と、
を有することを特徴とする使用方法。
【請求項8】
請求項7に記載の使用方法において、前記検査核酸サンプルが、工程b)に用いられる複雑度の減少を用いて得られた複雑度を減少した核酸サンプルであることを特徴とする使用方法。
【請求項9】
請求項7又は8に記載の使用方法において、前記工程b)が、タグを付けたライブラリーを得るための前記ライブラリーにタグを付ける工程をさらに含むことを特徴とする使用方法。
【請求項10】
請求項9に記載の使用方法において、前記タグは、前記アダプター又は前記プライマーに設けられていることを特徴とする使用方法。
【請求項11】
請求項10に記載の使用方法において、前記タグが、識別子配列であることを特徴とする使用方法。
【請求項12】
請求項10に記載の使用方法において、前記プライマーの少なくとも1つがリン酸化されることを特徴とする使用方法。
【請求項13】
請求項10に記載の使用方法において、前記シークエンシングが、固体支持体上で行なわれることを含むことを特徴とする使用方法。
【請求項14】
請求項7〜13のいずれか一項に記載の使用方法において、スクリーニングがアレイ上に請求項7に記載の工程g)で設計されたプローブの固定化によって行なわれ、その後ハイブリダイズする条件下で、プローブを含む前記アレイを検査ライブラリーと接触させることを特徴とする使用方法。
【請求項15】
請求項14に記載の使用方法を、濃縮されたマイクロサテライトライブラリーのスクリーニング、転写プロファイリングcDNA−AFLP(デジタルノーザン)の実行、複雑なゲノムのシークエンシング、発現配列タグライブラリーのシークエンシング(全体のcDNA又はcDNA−AFLPについて)、マイクロRNAの検出方法(小さなインサートライブラリーのシークエンシング)、バクテリア人工染色体(コンティグ)シークエンシング、AFLP/cDNA−AFLPと組み合わせたバルクセグレガント分析(Bulked Segregant analysis:バルク分離体分析)アプローチ方法、AFLP断片のルーチン検出方法(マーカー利用戻し交配)のために使用することを特徴とする使用方法。
【図1A】

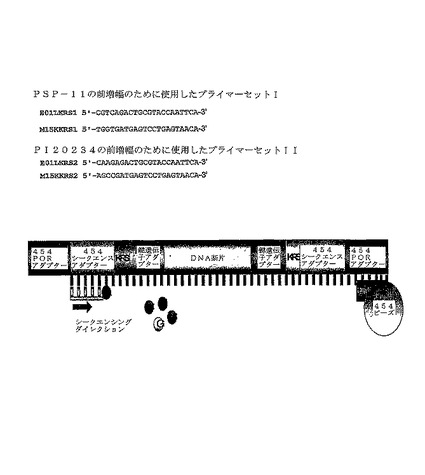
【図1B】
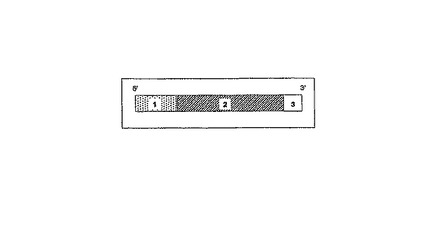
【図2】

【図3】

【図4】
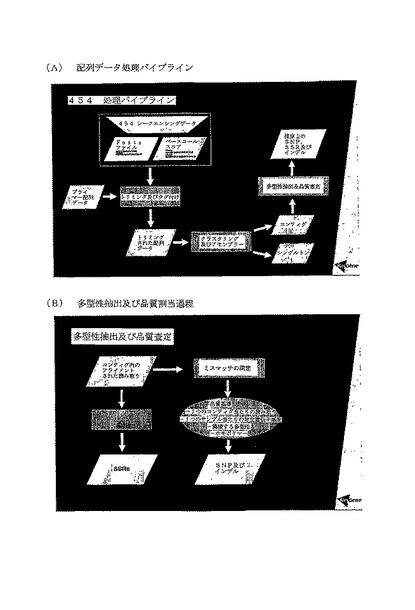
【図5A】

【図5B】
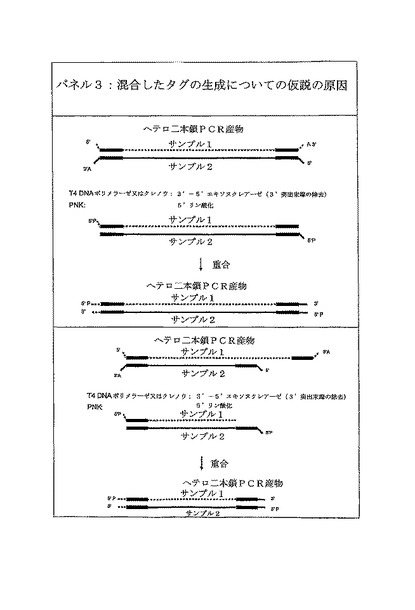
【図5C】

【図6A】

【図6B】

【図6C】
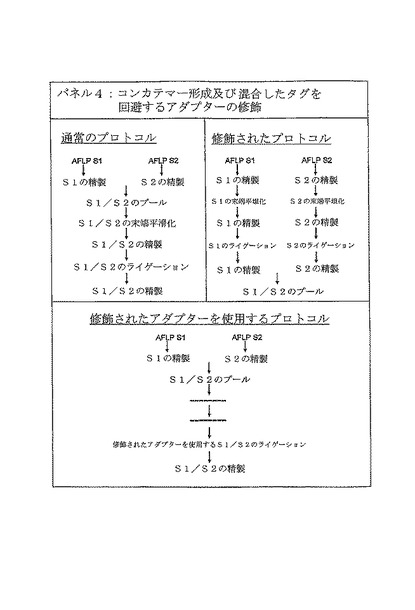
【図7】
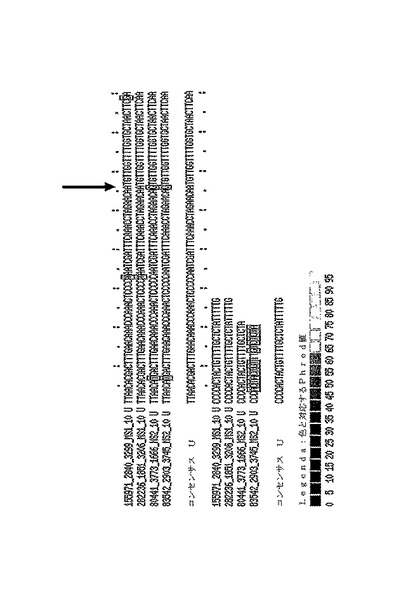
【図8A】
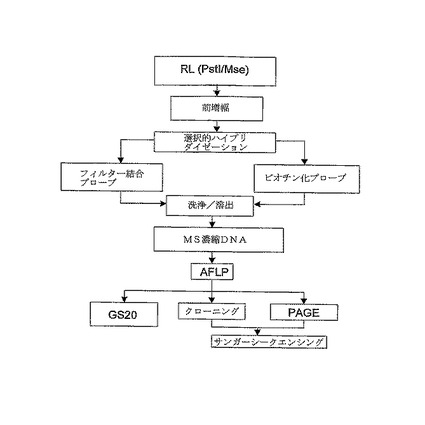
【図8B】
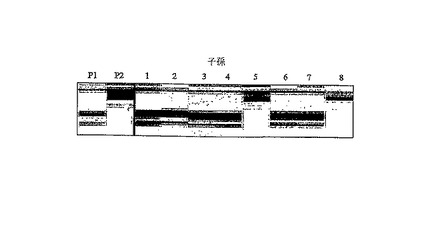
【図1B】
【図2】
【図3】
【図4】
【図5A】
【図5B】
【図5C】
【図6A】
【図6B】
【図6C】
【図7】
【図8A】
【図8B】
【公開番号】特開2013−63095(P2013−63095A)
【公開日】平成25年4月11日(2013.4.11)
【国際特許分類】
【出願番号】特願2013−6095(P2013−6095)
【出願日】平成25年1月17日(2013.1.17)
【分割の表示】特願2008−518056(P2008−518056)の分割
【原出願日】平成18年6月23日(2006.6.23)
【出願人】(505464888)キージーン ナムローゼ フェンノートシャップ (11)
【Fターム(参考)】
【公開日】平成25年4月11日(2013.4.11)
【国際特許分類】
【出願日】平成25年1月17日(2013.1.17)
【分割の表示】特願2008−518056(P2008−518056)の分割
【原出願日】平成18年6月23日(2006.6.23)
【出願人】(505464888)キージーン ナムローゼ フェンノートシャップ (11)
【Fターム(参考)】
[ Back to top ]