
Gタンパク共役型受容体判別装置、判別方法、判別プログラム及びそのプログラムを記録した記録媒体
【課題】 タンパク質がGタンパク共役型受容体であるか否かを精度よく判別可能な装置を提供すること。
【解決手段】 タンパク質のアミノ酸配列データを、アミノ酸のクラス毎の識別子で表した識別子配列データに変換する配列変換手段(6)、識別子配列データを分割し、生成されたフラグメントの総数に対する各々のフラグメントの数の割合としてフラグメント頻度を求める頻度算出手段(7)、タンパク質の残基数、疎水性指標及び頻度から特徴ベクトルを生成する特徴ベクトル生成手段(8)、複数のタンパク質の特徴ベクトル及びGタンパク共役型受容体であるか否かを表すGタンパク共役型受容体変数を用い、サポートベクターマシンによりGタンパク共役型受容体判別モデルを生成する判別モデル生成手段(9)、及び判別対象の特徴ベクトル及び前記Gタンパク共役型受容体判別モデルを用いて判別対象がGタンパク共役型受容体か否かを判別する判別手段(10)を備える。
【解決手段】 タンパク質のアミノ酸配列データを、アミノ酸のクラス毎の識別子で表した識別子配列データに変換する配列変換手段(6)、識別子配列データを分割し、生成されたフラグメントの総数に対する各々のフラグメントの数の割合としてフラグメント頻度を求める頻度算出手段(7)、タンパク質の残基数、疎水性指標及び頻度から特徴ベクトルを生成する特徴ベクトル生成手段(8)、複数のタンパク質の特徴ベクトル及びGタンパク共役型受容体であるか否かを表すGタンパク共役型受容体変数を用い、サポートベクターマシンによりGタンパク共役型受容体判別モデルを生成する判別モデル生成手段(9)、及び判別対象の特徴ベクトル及び前記Gタンパク共役型受容体判別モデルを用いて判別対象がGタンパク共役型受容体か否かを判別する判別手段(10)を備える。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、対象のタンパク質がGタンパク共役型受容体であるか否かを判別する判別装置、判別方法、判別プログラム及びそのプログラムを記録した記録媒体に関する。
【背景技術】
【0002】
受容体は、細胞に存在し、細胞外の結合物質を認識し、その結合物質の情報に基づいて細胞に応答を誘起する構造体からなるタンパク質である。各受容体は、それぞれ特定の結合物質を認識する。
【0003】
生体内の細胞膜上に存在する受容体は、イオンチャンネル型受容体、酵素活性内蔵型受容体、及びGタンパク共役型受容体の3種類に大別される。これらの中でGタンパク共役型受容体には、構造的に関連したタンパク質が種々存在し、それらがスーパーファミリーを構成している。Gタンパク共役型受容体は、細胞膜貫通部位が7ヵ所存在し、αβγサブユニットからなるGタンパク質を介してその情報を細胞内に伝達する。
【0004】
このGタンパク共役型受容体の刺激により活性化されたGタンパク質は、細胞膜の内側で酵素やイオンチャンネルと結合してそれらの活性を制御する。その結果、細胞内ではシグナル分子が生成又は消失し、細胞外あるいは細胞内小器官からイオンが流入する。細胞内で調節されたシグナル分子は、最終的に何らかのプロテインキナーゼ(タンパク質リン酸化酵素)の活性化などを介して複雑で多様な生物学的機能を発現する。
【0005】
Gタンパク共役型受容体には、アドレナリン、セロトニン、ヒスタミン、プロスタグランジン、アセチルコリンなどの低分子を結合物質とする受容体ファミリーと、アンジオテンシンII、ガストリン等のペプチドのような高分子を結合物質とする受容体ファミリーがある。
【0006】
現在販売されている臨床薬の30〜50%は、このGタンパク共役型受容体を標的とするリガンド(結合物質)であると考えられている。従って、新規Gタンパク共役型受容体の探索は、アゴニストやアンタゴニストなどのGタンパク共役型受容体に特異的なリガンドの探索に有用であることが知られている。Gタンパク共役型受容体は現在でも新薬発見の宝庫であると期待され、本受容体のアゴニストやアンタゴニストを得るために分子生物学の技術を用いて多くのGタンパク共役型受容体が同定されているが、その結合物質が未だ同定されていないオーファン受容体(Orphan GPCR)も多く存在している。Gタンパク共役型受容体が従来から医薬品開発の標的分子として多く取り上げられてきた理由には、このGタンパク共役型受容体は細胞内の情報伝達に重要な役割を担っている事、Gタンパク共役型受容体に作用する薬剤の基本的な構造要素に関する知見が多い事、Gタンパク共役型受容体は種類が多く多様性に富んでおり未知のものも数多く存在していると考えられる事、等がある。従って、新規Gタンパク共役型受容体タンパク質の解析を通して、新しい生体内情報伝達機構の発見や、新規薬物標的タンパク質の同定も期待できる。
【0007】
近年、ゲノミクス、プロテオミクスの発展により多くの新規なGタンパク共役型受容体が発見されているが、実験による解析は、非常に時間と費用が掛かることから、新規Gタンパク共役型受容体の探索の効率的な方法とは言えなくなってきている。最近では、新規Gタンパク共役型受容体の探索にバイオインフォマティクスの技術を用いて、実験的手法によらない、あるいは実験の負荷を軽減する目的で、ゲノム配列若しくは、アミノ酸配列よりGタンパク共役型受容体を予測する手法が開発されている。
【0008】
下記特許文献1及び非特許文献8には、新規Gタンパク共役型受容体の遺伝子やタンパク質を検索する方法が開示されている。即ち、アミノ酸配列の長さが200〜1500であり、6〜8の細胞膜貫通領域を含むオープンリーディングフレーム(ORF)をゲノム配列上から検索し、得られたORFと既知のGタンパク共役型受容体とのホモロジーを評価して新規Gタンパク共役型受容体遺伝子を検索する方法が開示されている。
【0009】
下記特許文献2には、新規Gタンパク共役型受容体配列を効率的に抽出する方法を開示している。即ち、ゲノム配列から遺伝子の探索、既知のGタンパク共役型受容体とのホモロジー検索、モチーフ及びドメインの帰属、膜貫通領域の予測を行い、それぞれの和集合により、候補配列の抽出する方法が開示されている。また、特許文献2では、抽出した配列に関し、重複配列の除去、及び誤予測により分離された断片配列の融合により遺伝子候補の質を向上させている。
【0010】
下記非特許文献1には、未知のタンパク質をサポートベクターマシン(Support Vector Machine:以下、SVMと記す)を用いて、既知のクラスに分類する方法が開示されている。非特許文献1では、アミノ酸の出現頻度(文字単位)、疎水性指標、Van der Waals Volume、極性、分極率、電化、表面張力、二次構造、solvent accessibilityを用いて、タンパク質を特徴化している。
【0011】
また、下記非特許文献2〜6には、Gタンパク共役型受容体タンパク質を判別する上で使用できる種々の疎水性指標が開示されており、下記非特許文献7には、SVMの内容が開示されている。
【0012】
このようにGタンパク共役型受容体タンパク質をゲノム配列、或いは機能既知タンパク質から検索する方法が知られているが、新規な生体内情報伝達機構の発見や新規薬物標的タンパク質の同定を可能とすることができる新規Gタンパク共役型受容体タンパク質をアミノ酸配列データベース上で網羅的に検索することにより予測精度の高い新しいGタンパク共役型受容体の判別方法が要望されている。
【特許文献1】特開2002−112793号公報
【特許文献2】特開2003−284573号公報
【非特許文献1】Cai CZ, et al., Nucleic Acids Research, Vol.31, No.13, 3692-3697(2003)
【非特許文献2】Kyte J and Doolittle RF, J. Mol. Biol., Vol.157, 105-132(1982)
【非特許文献3】Goldsack DE, et al., J. Theor. Biol., Vol.39, 645-651(1973)
【非特許文献4】SweeT RM, et al., J. Mol. Biol., Vol.171, 479-488(1983)
【非特許文献5】Zimmerman JM, et al., J. Theor. Biol., Vol.21, 170-201(1968)
【非特許文献6】Ponnuswamy PK. Prog. Biophys. Mol. Biol., Vol.59, 57-103(1993)
【非特許文献7】Vapnik VN, The Nature of Statistical Learning Theory, Springer(1995)
【非特許文献8】Takeda T, et al., FEBS Letters, Vol.520, 97-101(2002)
【発明の開示】
【発明が解決しようとする課題】
【0013】
しかしながら、上述した従来のGタンパク共役型受容体タンパク質の予測方法は、配列類似性を主に指標として用いている。その予測成績は、配列相同性が低い場合において、十分ではない。例えば、非特許文献8に開示されている既知Gタンパク共役型受容体を用いた予測成績は高々57%である。
【0014】
本発明の目的は、新しい手法を用いてアミノ酸配列データベースを網羅的に検索することにより、判別精度の高いGタンパク共役型受容体判別装置、判別方法、判別プログラム及びそのプログラムを記録した記録媒体を提供することにある。
【課題を解決するための手段】
【0015】
本発明者らは、既知のタンパク質のアミノ酸配列データを用いて、アミノ酸残基数、疎水性指標、アミノ酸構成頻度を基にGタンパク共役型受容体タンパク質が有する配列上の特徴についてモデル化を行った。そして、構築したモデルに機能未知のタンパク質の配列データを提供し、Gタンパク共役型受容体タンパク質である可能性について評価することによって、機能未知のタンパク質が、Gタンパク共役型受容体タンパク質である可能性を予測可能であることを見出した。特に、既知Gタンパク共役型受容体タンパク質を対象としてGタンパク共役型受容体タンパク質が有するアミノ酸配列上の特徴を抽出し、SVMにてGタンパク共役型受容体タンパク質のアミノ酸配列間に内在する規則を学習させた後、未知のタンパク質のアミノ酸配列をこの学習機械に入力し、SVMにて、学習された規則に基づいて新規なGタンパク共役型受容体タンパク質の可能性を判定する装置及びその方法を利用することにより公知の配列データベース上で網羅的に検索することにより新規Gタンパク共役型受容体タンパク質を得ることが可能であることを見出した。
【0016】
上記目的を達成するために、本発明に係るGタンパク共役型受容体判別装置(1)は、タンパク質のアミノ酸配列データを、アミノ酸の属するクラス毎に付与された識別子で表した配列である識別子配列データに変換する配列変換手段と、前記識別子配列データを分割し、所定の識別子数の長さの複数のフラグメントを生成し、生成された前記フラグメントの総数に対する各々の前記フラグメントの数の割合として各々の前記フラグメントの頻度を求める頻度算出手段と、前記タンパク質の残基数、疎水性指標及び複数の前記頻度から特徴ベクトルを生成する特徴ベクトル生成手段と、複数のタンパク質の各々に関する前記特徴ベクトル及びGタンパク共役型受容体であるか否かを表すGタンパク共役型受容体変数を用いて、サポートベクターマシンによってGタンパク共役型受容体判別モデルを生成する判別モデル生成手段と、判別対象のタンパク質に関する特徴ベクトル及び前記Gタンパク共役型受容体判別モデルを用いて判別対象のタンパク質がGタンパク共役型受容体であるか否かを判別する判別手段とを備えることを特徴としている。
【0017】
また、本発明に係るGタンパク共役型受容体判別装置(2)は、上記のGタンパク共役型受容体判別装置(1)において、複数の既知のGタンパク共役型受容体タンパク質及びGタンパク共役型受容体でない複数の膜タンパク質を用いて前記Gタンパク共役型受容体判別モデルを生成することを特徴としている。
【0018】
また、本発明に係るGタンパク共役型受容体判別装置(3)は、上記のGタンパク共役型受容体判別装置(2)において、Gタンパク共役型受容体でない複数の可溶性タンパク質をさらに用いて前記Gタンパク共役型受容体判別モデルを生成することを特徴としている。
【0019】
また、本発明に係るGタンパク共役型受容体判別装置(4)は、上記のGタンパク共役型受容体判別装置(1)〜(3)の何れかにおいて、前記フラグメントの長さが1以上6以下の範囲の整数値であることを特徴としている。
【0020】
また、本発明に係るGタンパク共役型受容体判別装置(5)は、上記のGタンパク共役型受容体判別装置(1)〜(4)の何れかにおいて、前記疎水性指標が、疎水親水指数(Hydropathy index)、疎水性因子(Hydrophobicity factor)、最適化マッチング疎水性(Optimal matching hydrophobicity)、疎水性(Hydrophobicity)、及び疎水性スケール(Hydrophobicity scales)の中の何れかから選択される1つであることを特徴としている。
【0021】
また、本発明に係るGタンパク共役型受容体判別装置(6)は、上記のGタンパク共役型受容体判別装置(1)〜(5)の何れかにおいて、前記識別子が、塩基性アミノ酸、酸性アミノ酸、芳香族アミノ酸、イミノ酸、及び脂肪族アミノ酸のクラス毎に付与されていることを特徴としている。
【0022】
また、本発明に係るGタンパク共役型受容体判別装置(7)は、上記のGタンパク共役型受容体判別装置(6)において、前記識別子が1以上5以下の範囲の整数値であることを特徴としている。
【0023】
また、本発明に係るGタンパク共役型受容体判別方法(1)は、タンパク質のアミノ酸配列データを、アミノ酸の属するクラス毎に付与された識別子で表した配列である識別子配列データに変換する第1ステップと、前記識別子配列データを分割し、所定の識別子数の長さの複数のフラグメントを生成し、生成された前記フラグメントの総数に対する各々の前記フラグメントの数の割合として各々の前記フラグメントの頻度を求める第2ステップと、前記タンパク質の残基数、疎水性指標及び複数の前記頻度から特徴ベクトルを生成する第3ステップと、複数のタンパク質の各々に関する前記特徴ベクトル及びGタンパク共役型受容体であるか否かを表すGタンパク共役型受容体変数を用いて、サポートベクターマシンによってGタンパク共役型受容体判別モデルを生成する第4ステップと、判別対象のタンパク質に関する前記特徴ベクトル及び前記Gタンパク共役型受容体判別モデルを用いて判別対象のタンパク質がGタンパク共役型受容体であるか否かを判別する第5ステップとを含むことを特徴としている。
【0024】
また、本発明に係るGタンパク共役型受容体判別方法(2)は、上記のGタンパク共役型受容体判別方法(1)において、複数の既知のGタンパク共役型受容体タンパク質及びGタンパク共役型受容体でない複数の膜タンパク質を用いて前記Gタンパク共役型受容体判別モデルを生成することを特徴としている。
【0025】
また、本発明に係るGタンパク共役型受容体判別方法(3)は、上記のGタンパク共役型受容体判別方法(2)において、Gタンパク共役型受容体でない複数の可溶性タンパク質をさらに用いて前記Gタンパク共役型受容体判別モデルを生成することを特徴としている。
【0026】
また、本発明に係るGタンパク共役型受容体判別方法(4)は、上記のGタンパク共役型受容体判別方法(1)〜(3)の何れかにおいて、前記フラグメントの長さが1、3、5、又は6の何れかであることを特徴としている。
【0027】
また、本発明に係るGタンパク共役型受容体判別方法(5)は、上記のGタンパク共役型受容体判別方法(1)〜(4)の何れかにおいて、前記疎水性指標が、疎水親水指数(Hydropathy index)、疎水性因子(Hydrophobicity factor)、最適化マッチング疎水性(Optimal matching hydrophobicity)、疎水性(Hydrophobicity)、及び疎水性スケール(Hydrophobicity scales)の中の何れかから選択される1つであることを特徴としている。
【0028】
また、本発明に係るGタンパク共役型受容体判別方法(6)は、上記のGタンパク共役型受容体判別方法(1)〜(5)の何れかにおいて、前記識別子が、塩基性アミノ酸、酸性アミノ酸、芳香族アミノ酸、イミノ酸、及び脂肪族アミノ酸のクラス毎に付与されていることを特徴としている。
【0029】
また、本発明に係るGタンパク共役型受容体判別方法(7)は、上記のGタンパク共役型受容体判別方法(6)において、前記識別子が1以上5以下の範囲の整数値であることを特徴としている。
【0030】
また、本発明に係るGタンパク共役型受容体判別プログラム(1)は、コンピュータに、タンパク質のアミノ酸配列データを、アミノ酸の属するクラス毎に付与された識別子で表した配列である識別子配列データに変換する機能と、前記識別子配列データを分割し、所定の識別子数の長さの複数のフラグメントを生成し、生成された前記フラグメントの総数に対する各々の前記フラグメントの数の割合として各々の前記フラグメントの頻度を求める頻度算出機能と、前記タンパク質の残基数、疎水性指標及び複数の前記頻度から特徴ベクトルを生成する機能と、複数のタンパク質の各々に関する前記特徴ベクトル及びGタンパク共役型受容体であるか否かを表すGタンパク共役型受容体変数を用いて、サポートベクターマシンによってGタンパク共役型受容体判別モデルを生成する機能と、判別対象のタンパク質に関する前記特徴ベクトル及び前記Gタンパク共役型受容体判別モデルを用いて判別対象のタンパク質がGタンパク共役型受容体であるか否かを判別する機能とを実現させることを特徴とする。
【0031】
また、本発明に係るGタンパク共役型受容体判別プログラム(2)は、上記のGタンパク共役型受容体判別プログラム(1)において、複数の既知のGタンパク共役型受容体タンパク質、及びGタンパク共役型受容体でない複数の膜タンパク質を用いて前記Gタンパク共役型受容体判別モデルを生成することを特徴としている。
【0032】
また、本発明に係るGタンパク共役型受容体判別プログラム(3)は、上記のGタンパク共役型受容体判別プログラム(2)において、Gタンパク共役型受容体でない複数の可溶性タンパク質をさらに用いて前記Gタンパク共役型受容体判別モデルを生成することを特徴としている。
【0033】
また、本発明に係るGタンパク共役型受容体判別プログラム(4)は、上記のGタンパク共役型受容体判別プログラム(1)〜(3)の何れかにおいて、前記フラグメントの長さが1、3、5、又は6の何れかであることを特徴としている。
【0034】
また、本発明に係るGタンパク共役型受容体判別プログラム(5)は、上記のGタンパク共役型受容体判別プログラム(1)〜(4)の何れかにおいて、前記疎水性指標が、疎水親水指数(Hydropathy index)、疎水性因子(Hydrophobicity factor)、最適化マッチング疎水性(Optimal matching hydrophobicity)、疎水性(Hydrophobicity)、及び疎水性スケール(Hydrophobicity scales)の中の何れかから選択される1つであることを特徴としている。
【0035】
また、本発明に係るGタンパク共役型受容体判別プログラム(6)は、上記のGタンパク共役型受容体判別プログラム(1)〜(5)の何れかにおいて、前記識別子が、塩基性アミノ酸、酸性アミノ酸、芳香族アミノ酸、イミノ酸、及び脂肪族アミノ酸のクラス毎に付与されていることを特徴としている。
【0036】
また、本発明に係るGタンパク共役型受容体判別プログラム(7)は、上記のGタンパク共役型受容体判別プログラム(6)において、前記識別子が1以上5以下の範囲の整数値であることを特徴としている。
【0037】
また、本発明に係るGタンパク共役型受容体判別プログラムを記録したコンピュータ読み取り可能な記録媒体は、上記のGタンパク共役型受容体判別プログラム(1)〜(7)の何れかを記録していることを特徴としている。
【発明の効果】
【0038】
本発明によれば、タンパク質がGタンパク共役型受容体であるか否かを高い精度で判別することができるので、実験を行う前に新規Gタンパク共役型受容体タンパク質候補を予め絞り込むことができ、総当り的な膨大な実験を行うことなくGタンパク共役型受容体タンパク質を効率良く発見することが可能となる。
【0039】
また、従来の予測法のようにアミノ酸配列の相同性に頼ることなく、アミノ酸配列から直接に特徴量を抽出し、これに基づいて判別を行うため、相同性タンパク質に関する情報を持たない機能未知のタンパク質配列をも判別することが可能である。
【0040】
従って、本発明は、新規Gタンパク共役型受容体タンパク質の作用を利用するバイオテクノロジーを用いる創薬の分野、さらにはこれらの基礎研究としてのバイオインフォマティクス、プロテオミクス、生命科学分野全般にわたって適用可能である。
【発明を実施するための最良の形態】
【0041】
以下、本発明に係るGタンパク共役型受容体判別装置及びその判別方法に関して、添付図を参照しながら説明する。
【0042】
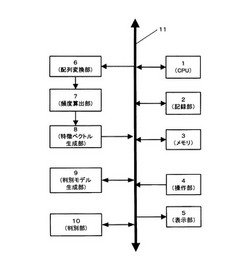
図1は、本発明の実施の形態に係る新規Gタンパク共役型受容体タンパク質判別装置の概略構成を示すブロック図である。図1に示したように、本判別装置は、各部を制御するCPU1、記録部2と、メモリ3、操作部4、表示部5、配列変換部6、頻度算出部7、特徴ベクトル生成部8、判別モデル生成部9、判別部10、及びデータバス11を備えている。本判別装置は、機能未知のタンパク質がGタンパク共役型受容体であるか否かを判別するための基準となるGタンパク共役型受容体判別モデルを生成する機能、及びGタンパク共役型受容体判別モデルを用いて実際に判別を行う機能(Gタンパク共役型受容体判別機能)の2つの機能を持っている。
【0043】
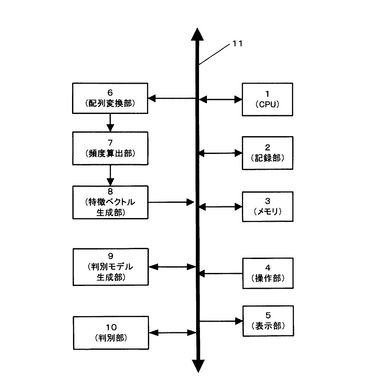
図2、3は、本判別装置の動作を説明するフローチャートである。以下、これらのフローチャートに従って、本判別装置の動作を説明する。ここで、記録部2には、予め既知のGタンパク共役型受容体タンパク質のアミノ酸配列、Gタンパク共役型受容体以外の膜タンパク質のアミノ酸配列、可溶性タンパク質のアミノ酸配列が所定の形式で記録されているとする。また、特に断らない限りCPU1が行う処理として記載し、種々のデータ処理はメモリ3上のワーク領域で実行される。メモリ3は処理途中及び処理結果データの一時記憶にも使用され、処理結果データは記録部2にも適宜記録される。また、処理途中のデータ又は処理結果データは、表示部5内部のビデオメモリ(図示せず)に伝送され、所定の形式で、例えばCRT表示装置、液晶表示装置(いずれも図示せず)などに表示される。また、操作部4は例えば、コンピュータ用のキーボード、マウスなどであり、使用者により操作されて指示が入力される。まず図2のフローチャートに従って、Gタンパク共役型受容体判別モデルの生成機能に関して説明する。
【0044】
ステップS1において、操作部4を介して、所定の自然数Δ及び、判別モデルの生成に使用するタンパク質のアミノ酸配列データの総数Nの入力を受け付け、繰り返し処理のカウンタiに初期値として1をセットする。
【0045】
ステップS2において、記録部2に記録されている複数のタンパク質(既知のGタンパク共役型受容体タンパク質、Gタンパク共役型受容体以外の膜タンパク質、可溶性タンパク質)のアミノ酸配列データの中から、1つのアミノ酸配列データAiを読み出す。
【0046】
ここで、アミノ酸配列データAiは、例えばインターネットのウェブに公開されている公共或いは私的なデータベースから取得したデータである。データベースの例としては、SWISS−PROTタンパク質データベース(http://www.psc.edu/general/software/packages/swiss/swiss.html)がある。また、アミノ酸配列としては、Gタンパク共役型受容体としてデータベースに登録されている配列を用いるのが特に好ましい。これらの配列は、例えば、"An Internet review: the complete neuroscientist scours the World Wide Web." Bloom FE, Science 1996; 274(5290):1104-9に詳細が記載されているGCRDb(The G-protein-coupled Receptor Database)(http://www.gcrdb.uthscsa.edu/)、GPCRDB(http://www.gpcr.org/7tm/)、ExPASy(http://www.expasy.ch/cgi-bin/sm-gpcr.pl)、ORDB(http://senselab.med.yale.edu/senselab/ORDB/default.asp)等から入手できる。
【0047】
さらに、Gタンパク共役型受容体としてデータベースに登録されている配列のみならず、GeneBank(ftp://ncbi.nlm.nih.gov/genbank/genomes/)、ENSEMBL(http://www.ensembl.org)、PIR(http://www-nbrf.georgetown.edu/pir/、(National Biomedical Research Foundation(NBRF))、Swiss Plot(http://www.expasy.ch/sprot/sprot-top.html、Swiss Institute of Bioinformatics(SIB)、European Bioinfomatics Institute(EBI))、TrEMBL(URL及び管理者ともにSwiss Plotと同じ)、TrEMBLNEW(URL及び管理者ともにSwiss Plotと同じ)等のデータベースに登録されているヒト(H.sapiens)、マウス(M.musculus)、ラット(R.norvegicus)、ゼブラフィッシュ(D. rerio)、ショウジョ ウバエ(D. melanogaster)、線虫(C. elagans)、酵母(S.cerevisiae)、シロイヌナズナ(A. thaliana)などの如何なるアミノ酸配列を用いることもできる。
【0048】
これらのデータベースは単なる例示であり、タンパク質のアミノ酸配列が登録されているものであれば如何なるデータベースを用いることもできる。
【0049】
ステップS3において、ステップS2で読み出したアミノ酸配列データAiから、配列の長さLi、疎水性指標Hi、及びGタンパク共役型受容体変数yiを決定する。ここで、配列の長さLiは、そのタンパク質のアミノ酸残基の総数であり、読み出したアミノ酸配列Aiデータから算出する。一方、Gタンパク共役型受容体変数yiは、そのタンパク質がGタンパク共役型受容体であるか否かを示す変数であり、Gタンパク共役型受容体であれば“1”であり、Gタンパク共役型受容体で無ければ“−1”を設定する。Gタンパク共役型受容体変数yiは、タンパク質のアミノ酸配列に対応させて予め記録部2に記録されていてもよく、その場合には、Gタンパク共役型受容体変数yiを記録部から読み出せばよい。
【0050】
また、疎水性指標Hiの計算には、Kyte-Doolittle法における疎水親水指数(Hydropathy index、上記非特許文献2)、Goldsack-Chalifoux法における疎水性因子(Hydrophobicity factor、上記非特許文献3)、Sweet-Eisenberg法における最適化マッチング疎水性(Optimal matching hydrophobicity、上記非特許文献4)、Zimmerman法における疎水性(Hydrophobicity、上記非特許文献5)、及びPonnuswamy法における疎水性スケール(Hydrophobicity scales、上記非特許文献6)のいずれかを使用すればよい。詳細は後述するが、これらの疎水性指標のうち、疎水親水指数(Hydropathy index)が最も好ましい。
【0051】
ステップS4において、CPU1が、ステップS2で取得したアミノ酸配列データAiを配列変換部6に伝送し、配列変換部6が、伝送されたアミノ酸配列データAiを所定の識別子の配列データに変換する。即ち、予めタンパク質を構成するアミノ酸が属するクラス毎に識別子が付与されており、それらが対応付けられて、例えば記録部2に対応テーブルとして記録されており、配列変換部6が、その対応テーブルを参照しながら、伝送されたアミノ酸配列データAiを識別子で表わされた配列データ(以下、識別子配列データと記す)に変換する。識別子には、数字、アルファベット、記号など任意の文字を使用すれば良い。ここでは一例として、表1に示した識別子を使用することとする。即ち、ヒスチジン(His)、アルギニン(Arg)、リジン(Lys)などの塩基性アミノ酸の識別子を“1”とし、アスパラギン酸(Asp)、グルタミン酸(Glu)などの酸性アミノ酸の識別子を“2”とし、フェニルアラニン(Phe)、チロシン(Tyr)、トリプトファン(Trp)などの芳香族アミノ酸の識別子を“3”とし、プロリン(Pro)などのイミノ酸の識別子を“4”とし、その他の脂肪族アミノ酸(Other)の識別子を“5”とする。
【0052】
【表1】

【0053】
ステップS5において、配列変換部6が、ステップS4で変換した識別子配列データ(アミノ酸配列データAiに対応)を頻度算出部7に出力し、頻度算出部7が、ステップS1で指定された値Δを単位長さ(アミノ酸残基の個数)として、入力された識別子配列データを先頭から分割する。分割された単位長さの識別子配列データを、アミノ酸フラグメントと呼ぶ。Δとしては、任意の自然数を使用することができるが、後述するように1〜6の値が望ましく、その中でも5が最も望ましい。
【0054】
ステップS6において、頻度算出部7は、ステップS5で生成されたアミノ酸フラグメントの頻度を求める。即ち、頻度算出部7は、ステップS5で生成されたアミノ酸フラグメントの総数に対する各アミノ酸フラグメントaijの個数の割合を、頻度Fijとして求める。一例として、Δ=5とした場合を表2に示す。表2では、アミノ酸フラグメントaijは、表1の識別子1〜5を用いて標記した順列として、昇順に表記されている。この場合、アミノ酸フラグメントの総数は、55=3125である。
【0055】
【表2】
【0056】
ステップS7において、頻度算出部7が、頻度Fijを特徴ベクトル生成部8に出力し、特徴ベクトル生成部8は、入力された頻度FijとステップS3で取得した配列長Li及び疎水性指標Hiとを対応つけて、ベクトルデータxiを生成する。具体的には、ベクトルデータxiは、例えばxi=(Li,Hi,Fi1,…,FiM)である。Mは可能なアミノ酸フラグメントの総数であり、Δ=5の場合、M=3125である。また、Fi1,…,FiMの順序は、所定の順序であればよく、例えば表2に示した番号jの順である。
【0057】
ステップS8において、特徴ベクトル生成部8は、ベクトルデータxiをGタンパク共役型受容体変数yiと対応させて記録部2に記録する。
【0058】
ステップS9において、カウンタiがNよりも小さいか否かを判断し、小さいと判断すれば、ステップS10に移行して、カウンタiを1増加させて、ステップS2に戻る。このように、CPUは、配列変換部6、頻度算出部7、特徴ベクトル生成部8を制御ながら、カウンタiがN以上になるまで、ステップS2〜S8を繰り返し、記録部2から順にタンパク質配列データAiを読み出し、対応するベクトルデータxiを生成し、Gタンパク共役型受容体変数yiと対応させて記録部2に記録する。
【0059】
ステップS9において、i<Nでないと判断すればステップS11に移行し、判別モデル生成部9が、Gタンパク共役型受容体判別モデルを生成する。即ち、Gタンパク共役型受容体判別モデルの生成は、ステップS8で記録されたベクトルデータxi(i=1〜N)をパターン認識のための特徴ベクトルとし、Gタンパク共役型受容体変数yi(i=1〜N)と共に一連のトレーニングデータとして、サポートベクターマシンSVMに入力することによって行なわれる。SVMは公知の技術であるので、ここでは簡単に説明する。
【0060】
SVMは、認識対象のサンプル集合を2つのクラスに分類する方法であって、1960年代にVapnik等が提案したOptimal Separating Hyperplaneを起源とする。即ち、多次元ベクトル空間上に位置する各サンプルを分離することができる2つの超平面を決定する方法である。通常、サンプル集合を明確に分離できる、即ち線形分離可能な場合は少ないので、ソフトマージンを導入する方法がある。さらに、1990年代になってカーネル学習法と組み合わされた非線形の識別方法へと拡張された。カーネルトリックにより非線形の識別関数が構成できるように拡張されたSVMは、現在知られている手法の中でも最もパターン認識性能の高い学習モデルの一つである(上記非特許文献7参照)。認識対象に応じて種々のSVMを使用することができるが、ここでは、一例としてソフトマージンを導入したSVMを使用する場合を説明する。
【0061】
パターン認識には、認識対象から何らかの特徴量を計測(抽出)することが必要である。一般に、1種類の特徴量だけではなく複数の特徴量を計測し、それらを同時に使用して認識を行う。
【0062】
SVMでは正しい例である正例と誤った例である負例の2つのクラスのいずれかに属するr個のトレーニング用データの集合(x1,y1),…(xr,yr)を準備する。ここで、xiは、データiの特徴ベクトル(n次元ベクトル)である。また、yiは、データiが正例の場合“+1”の値をとり、負例の場合には、“−1”の値をとるスカラーの変数である。ここでは、Gタンパク共役型受容体であるタンパク質の特徴ベクトルとして、上記ステップS8で記録部に記録したベクトルデータxi及びGタンパク共役型受容体変数yiを用いる。即ち、配列の長さL、疎水性指標H、アミノ酸フラグメントの頻度(F1,…,FM)を用いて、Gタンパク共役型受容体であるタンパク質の特徴ベクトルは、xi=(Li,Hi,Fi1,…,FiM)、yi=1で表され、Gタンパク共役型受容体でないタンパク質の特徴ベクトルは、xj=(Lj,Hj,Fj1,…,FjM)、yj=0で表される。ここで、i=1〜Nである。
【0063】
これら複数の特徴ベクトル(以下、トレーニングセットと記す)(x1,y1),…(xN,yN)を(M+2)次元Euclid空間上の(w・x)+b=0なる超平面で分離する。ここで、wもベクトルであり、w・xは2つのベクトルの内積(スカラー)を表し、bは(≦0)スカラーである。この際、近接する正例と負例のデータ間の距離が大きい方が、精度良くデータを分類できる。ここで、(w・x)+b=1で表される正例側の分離超平面H1と、(w・x)+b=−1で表される負例側の分離超平面H2とを考える。
【0064】
2つの分離超平面H1、H2間の距離は、2/‖w‖である。この距離を最大にするには、‖w‖を最小にすればよい。ある関数のとる値が最小値となる時、‖w‖が最適値をとるような関数を目的関数と呼ぶ。この場合、下記の目的関数Φを使用すればよい。
【0065】
【数1】
【0066】
ここで、ξiは、トレーニングデータxi(i=1〜N)が分離超平面によって分離できない場合、即ち訓練データxiの正例/負例を誤認識してしまう場合の訓練データxiの分離超平面からの距離を表す非負の変数である。式1の右辺第一項は、2つの分離超平面H1とH2との間の距離の逆数の2乗に比例しているので、この項の値が小さいほど2つの分離超平面間の距離が大きい。右辺第二項のCを除いた部分は、分離できなかった各訓練データと、分離超平面H1あるいはH2との距離(例えば、トレーニングデータxiが正例の場合、超平面H1からの距離、トレーニングデータxiが負例の場合、超平面H2からの距離)の和であり、誤差項と呼ぶ。Cは、第一項と第二項を重視する度合いを決めるための正値(0以上)のパラメータである。Cの値が大きいときは、訓練データxiの分離超平面H1、H2からの誤差が大きく評価され、Cの値が小さいときは、相対的に分離超平面間の距離の大きさが重視される。後述する実施例ではC=1を用いた。
【0067】
トレーニングセットにより、目的関数Φを最小にする最適な判別ベクトルw及び判別スカラーbを決定し、記録部に記録する。最適な判別ベクトルw及び判別スカラーbの計算には、例えばLagrange法を用いることができる。以上で、Gタンパク共役型受容体判別部9によるGタンパク共役型受容体判別モデルの生成が終了する。
【0068】
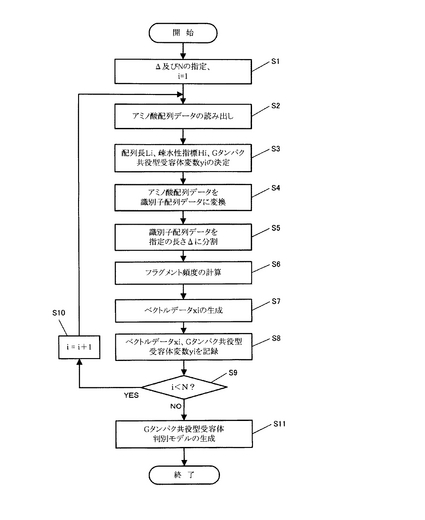
次に、上記で決定されたGタンパク共役型受容体判別モデルを使用したGタンパク共役型受容体判別機能に関して説明する。図3は、Gタンパク共役型受容体判別処理を説明するフローチャートである。ここで、図2と同様に、特に断らない限りCPUが行う処理として記載し、メモリ、記録部を使用して適宜処理途中のデータを記録しながら処理が行われる。
【0069】
ステップS21において、判別対象のタンパク質のアミノ酸配列データを入力する。例えば、操作部4を介して、予め記録部2に記録されているアミノ酸配列データが指定され、それが読み出される。
【0070】
ステップS22において、ステップS21で読み出されたアミノ酸配列データから、上記したステップS3と同様に、配列長L0、疎水性指標H0を決定する。
【0071】
ステップS23〜S26において、上記ステップS4〜S7と同様に、配列変換部6が、ステップS21で入力されたアミノ酸配列データを識別子配列データに変換し、頻度算出部7が、識別子配列データを指定の長さΔ(Gタンパク共役型受容体判別モデルの生成に使用したのと同じ値)のフラグメントに分割し、各フラグメントの頻度を求め、特徴ベクトル生成部8が、特徴ベクトルデータx0を生成する。
【0072】
ステップS27において、判別部10が、Gタンパク共役型受容体判別モデルを用いて、ステップS26で生成され特徴ベクトルデータx0がGタンパク共役型受容体であるか否かを判別する。即ち、Gタンパク共役型受容体判別モデルを用いて計算した識別関数が“1”であれば所定のフラグfに“1”をセット(Gタンパク共役型受容体であることを示す)し、“−1”であれば、所定のフラグfに“−1”をセット(Gタンパク共役型受容体でないことを示す)する。SVMによる判別方法の詳細は非特許文献7に開示されているので省略する。
【0073】
ステップS8において、フラグfの値に応じて判別結果を出力する。即ち、f=1であれば表示部にGタンパク共役型受容体であることを表示し、f=−1であれば表示部にGタンパク共役型受容体でないことを表示する。
【0074】
以上によって、機能未知のタンパク質のアミノ酸配列が分かれば、予め決定されたGタンパク共役型受容体判別モデルを用いてGタンパク共役型受容体であるか否かの判別を行うことができる。
【0075】
本発明の有効性を確認するために、後述する実施例で示されるように、既知Gタンパク共役型受容体タンパク質の配列(2955配列)、Gタンパク共役型受容体以外の膜タンパク質の配列(1152配列)、可溶性タンパク質の配列(3202配列)をトレーニングセットとして用いて、クロスバリデーション試験を行った。その結果、上記した何れの疎水性指標を使用した場合にも90%近い精度で正しく判別することができた。その中でも、Kyte-dolittleらによる疎水親水指標を使用してGタンパク共役型受容体判定に使用するモデルを生成した場合、最も高い判別精度93.8%を実現することができた。
【0076】
また、Gタンパク共役型受容体判別モデルを生成する方法は、SVMに限定されず、既知のタンパク質の配列長、疎水性指標、及びフラグメントの頻度を要素とする特徴ベクトルを用いさえすれば、ベイズ推定、決定木、kNN、ニューラルネットワークやその他の認識方法を用いてもよい。
【0077】
また、本発明に係るGタンパク共役型受容体判別装置の構成は、図1に示した構成に限定さない。即ち、単体の装置であっても、複数の装置からなるシステムであってもよく、さらにLAN、WAN等のネットワークを介してデータの記録、交換などを行いながら処理が行なわれるシステムであってもよい。
【0078】
また、内部バスに接続されたCPU、ROMやRAMなどのメモリ、入力装置、出力装置、外部記録装置、媒体駆動装置、可搬記録媒体、ネットワーク接続装置で構成されるシステム、例えば一般的なコンピュータであってもよい。即ち、上記した機能をコンピュータに実現させるコンピュータプログラムがコンピュータ読み取り可能な記録媒体に記録されており、そのプログラムを記録媒体から読み出し、メモリ上に展開し、CPUがそのプログラムを実行することによっても実現することができる。
【0079】
コンピュータプログラムを供給するための可搬記録媒体としては、例えば、フレキシブルディスク、ハードディスク、光ディスク、光磁気ディスク、CD−ROM、CD−R、DVD−ROM、DVD−RAM、磁気テープ、不揮発性メモリーカード等の種々の記録媒体を用いることができる。
【0080】
また、コンピュータがメモリ上に読み出したプログラムコードを実行することによって、上記した実施の形態の機能が実現される場合に限らず、そのプログラムコードの指示に基づき、コンピュータ上で複数のコンピュータアプリケーションソフトが実際の処理の一部又は全部を行ない、その処理によって上記した実施の形態の機能が実現されるようにしてもよい。
【0081】
さらに、可搬型記録媒体から読み出されたコンピュータプログラムコードやコンピュータプログラム(データ)提供者から提供されたコンピュータプログラム(データ)が、コンピュータに挿入された機能拡張ボードやコンピュータに接続された機能拡張ユニットに備わるメモリに書き込まれた後、そのプログラムコードの指示に基づき、その機能拡張ボードや機能拡張ユニットに備わるCPUなどが実際の処理の一部又は全部を行ない、その処理によって上記した実施の形態の機能が実現されるようにしてもよい。
【実施例】
【0082】
以下に実施例を示し、本発明の特徴とするところをより一層明確にする。
(1)Gタンパク共役型受容体の判別
コンピュータを使用して図2に示したフローチャートに従って生成したGタンパク共役型受容体判別モデルを用いて、トレーニングセットに含まれないGタンパク共役型受容体であるか否かが既知の複数のタンパク質を対象として、図3に示したフローチャートに従ってGタンパク共役型受容体判別を行なった。
【0083】
その結果、例えば、トレーニングセットに含まれなかったGR3(NM_004293)がGタンパク共役型受容体として抽出された。このGR3(NM_004293)は、Gタンパク共役型受容体であることが知られており、本方法によるGタンパク共役型受容体判別が有効であることが分かる。
(2)Gタンパク共役型受容体判別精度のフラグメント長への依存性
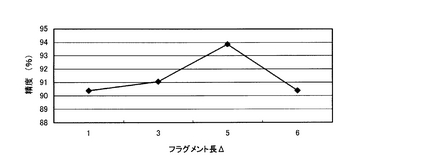
Gタンパク共役型受容体判別精度が、どの程度フラグメントの長さに依存するかを評価した。
【0084】
図2に示したフローチャートにおいて、Δ=1、3、5、又は6(それぞれ、アミノ酸1残基、3残基、5残基、6残基に対応)とし、上記したように、既知Gタンパク共役型受容体タンパク質の配列(2955配列)、Gタンパク共役型受容体以外の膜タンパク質の配列(1152配列)、可溶性タンパク質の配列(3202配列)をトレーニングセットとして用いて、Gタンパク共役型受容体判別モデルを生成し、その後クロスバリデーション試験を行なった。
【0085】
その結果を図4に示す。図4は、横軸はΔ(フラグメント長)であり、縦軸はGタンパク共役型受容体の判別精度であり、総判別回数に対する正しい結果が得られた回数の割合である。図3から分かるように、何れの場合にも判別精度が90%より高く、本発明が有効であることが分かる。さらに、Δ=5(5残基フラグメント)の場合、判別精度が93.8%と最も高くなっており、Δ=5が最も望ましい。
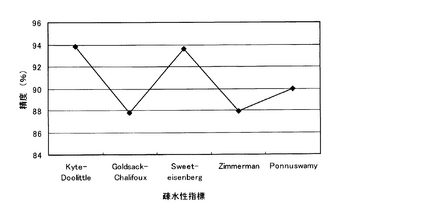
(3)Gタンパク共役型受容体判別精度の疎水性指標への依存性
Gタンパク共役型受容体判別精度が、どの程度疎水性指標に依存するかを評価した。即ち、図2に示したフローチャートにおいて、Δ=5とし、疎水性指標Hとして、疎水親水指数(Hydropathy index)、疎水性因子(Hydrophobicity factor)、最適化マッチング疎水性(Optimal matching hydrophobicity)、疎水性(Hydrophobicity)、及び疎水性スケール(Hydrophobicity scales)を用いて、上記と同様に、既知Gタンパク共役型受容体タンパク質の配列(2955配列)、Gタンパク共役型受容体以外の膜タンパク質の配列(1152配列)、可溶性タンパク質の配列(3202配列)をトレーニングセットとして用いて、Gタンパク共役型受容体判別モデルを生成し、その後クロスバリデーション試験を行った。
【0086】
その結果を図5に示す。図5は、横軸は疎水性指標の種類であり、縦軸は図4と同様にGタンパク共役型受容体の判別精度である。何れの疎水性指標を使用した場合にも判別精度が約88%以上と高く、本発明が有効であることが分かる。さらに、疎水性指標として疎水親水指数(Hydropathy index)を使用した場合、判別精度が93.8%と最も高くなっており、疎水性指標として疎水親水指数(Hydropathy index)が最も望ましい。
【図面の簡単な説明】
【0087】
【図1】本発明の実施の形態に係るGタンパク共役型受容体判別装置の概略構成を示すブロック図である。
【図2】図1の判別装置によるGタンパク共役型受容体判別モデルを生成する機能を説明するフローチャートである。
【図3】図1の判別装置によるGタンパク共役型受容体判別機能を説明するフローチャートである。
【図4】本発明の実施の形態に係るGタンパク共役型受容体判別方法の判別精度のフラグメントの長さへの依存性を示す図である。
【図5】本発明の実施の形態に係るGタンパク共役型受容体判別方法の判別精度の疎水性指標への依存性を示す図である。
【符号の説明】
【0088】
1 CPU
2 記録部
3 メモリ
4 操作部
5 表示部
6 配列変換部
7 頻度算出部
8 特徴ベクトル生成部
9 判別モデル生成部
10 判別部
11 データバス
【技術分野】
【0001】
本発明は、対象のタンパク質がGタンパク共役型受容体であるか否かを判別する判別装置、判別方法、判別プログラム及びそのプログラムを記録した記録媒体に関する。
【背景技術】
【0002】
受容体は、細胞に存在し、細胞外の結合物質を認識し、その結合物質の情報に基づいて細胞に応答を誘起する構造体からなるタンパク質である。各受容体は、それぞれ特定の結合物質を認識する。
【0003】
生体内の細胞膜上に存在する受容体は、イオンチャンネル型受容体、酵素活性内蔵型受容体、及びGタンパク共役型受容体の3種類に大別される。これらの中でGタンパク共役型受容体には、構造的に関連したタンパク質が種々存在し、それらがスーパーファミリーを構成している。Gタンパク共役型受容体は、細胞膜貫通部位が7ヵ所存在し、αβγサブユニットからなるGタンパク質を介してその情報を細胞内に伝達する。
【0004】
このGタンパク共役型受容体の刺激により活性化されたGタンパク質は、細胞膜の内側で酵素やイオンチャンネルと結合してそれらの活性を制御する。その結果、細胞内ではシグナル分子が生成又は消失し、細胞外あるいは細胞内小器官からイオンが流入する。細胞内で調節されたシグナル分子は、最終的に何らかのプロテインキナーゼ(タンパク質リン酸化酵素)の活性化などを介して複雑で多様な生物学的機能を発現する。
【0005】
Gタンパク共役型受容体には、アドレナリン、セロトニン、ヒスタミン、プロスタグランジン、アセチルコリンなどの低分子を結合物質とする受容体ファミリーと、アンジオテンシンII、ガストリン等のペプチドのような高分子を結合物質とする受容体ファミリーがある。
【0006】
現在販売されている臨床薬の30〜50%は、このGタンパク共役型受容体を標的とするリガンド(結合物質)であると考えられている。従って、新規Gタンパク共役型受容体の探索は、アゴニストやアンタゴニストなどのGタンパク共役型受容体に特異的なリガンドの探索に有用であることが知られている。Gタンパク共役型受容体は現在でも新薬発見の宝庫であると期待され、本受容体のアゴニストやアンタゴニストを得るために分子生物学の技術を用いて多くのGタンパク共役型受容体が同定されているが、その結合物質が未だ同定されていないオーファン受容体(Orphan GPCR)も多く存在している。Gタンパク共役型受容体が従来から医薬品開発の標的分子として多く取り上げられてきた理由には、このGタンパク共役型受容体は細胞内の情報伝達に重要な役割を担っている事、Gタンパク共役型受容体に作用する薬剤の基本的な構造要素に関する知見が多い事、Gタンパク共役型受容体は種類が多く多様性に富んでおり未知のものも数多く存在していると考えられる事、等がある。従って、新規Gタンパク共役型受容体タンパク質の解析を通して、新しい生体内情報伝達機構の発見や、新規薬物標的タンパク質の同定も期待できる。
【0007】
近年、ゲノミクス、プロテオミクスの発展により多くの新規なGタンパク共役型受容体が発見されているが、実験による解析は、非常に時間と費用が掛かることから、新規Gタンパク共役型受容体の探索の効率的な方法とは言えなくなってきている。最近では、新規Gタンパク共役型受容体の探索にバイオインフォマティクスの技術を用いて、実験的手法によらない、あるいは実験の負荷を軽減する目的で、ゲノム配列若しくは、アミノ酸配列よりGタンパク共役型受容体を予測する手法が開発されている。
【0008】
下記特許文献1及び非特許文献8には、新規Gタンパク共役型受容体の遺伝子やタンパク質を検索する方法が開示されている。即ち、アミノ酸配列の長さが200〜1500であり、6〜8の細胞膜貫通領域を含むオープンリーディングフレーム(ORF)をゲノム配列上から検索し、得られたORFと既知のGタンパク共役型受容体とのホモロジーを評価して新規Gタンパク共役型受容体遺伝子を検索する方法が開示されている。
【0009】
下記特許文献2には、新規Gタンパク共役型受容体配列を効率的に抽出する方法を開示している。即ち、ゲノム配列から遺伝子の探索、既知のGタンパク共役型受容体とのホモロジー検索、モチーフ及びドメインの帰属、膜貫通領域の予測を行い、それぞれの和集合により、候補配列の抽出する方法が開示されている。また、特許文献2では、抽出した配列に関し、重複配列の除去、及び誤予測により分離された断片配列の融合により遺伝子候補の質を向上させている。
【0010】
下記非特許文献1には、未知のタンパク質をサポートベクターマシン(Support Vector Machine:以下、SVMと記す)を用いて、既知のクラスに分類する方法が開示されている。非特許文献1では、アミノ酸の出現頻度(文字単位)、疎水性指標、Van der Waals Volume、極性、分極率、電化、表面張力、二次構造、solvent accessibilityを用いて、タンパク質を特徴化している。
【0011】
また、下記非特許文献2〜6には、Gタンパク共役型受容体タンパク質を判別する上で使用できる種々の疎水性指標が開示されており、下記非特許文献7には、SVMの内容が開示されている。
【0012】
このようにGタンパク共役型受容体タンパク質をゲノム配列、或いは機能既知タンパク質から検索する方法が知られているが、新規な生体内情報伝達機構の発見や新規薬物標的タンパク質の同定を可能とすることができる新規Gタンパク共役型受容体タンパク質をアミノ酸配列データベース上で網羅的に検索することにより予測精度の高い新しいGタンパク共役型受容体の判別方法が要望されている。
【特許文献1】特開2002−112793号公報
【特許文献2】特開2003−284573号公報
【非特許文献1】Cai CZ, et al., Nucleic Acids Research, Vol.31, No.13, 3692-3697(2003)
【非特許文献2】Kyte J and Doolittle RF, J. Mol. Biol., Vol.157, 105-132(1982)
【非特許文献3】Goldsack DE, et al., J. Theor. Biol., Vol.39, 645-651(1973)
【非特許文献4】SweeT RM, et al., J. Mol. Biol., Vol.171, 479-488(1983)
【非特許文献5】Zimmerman JM, et al., J. Theor. Biol., Vol.21, 170-201(1968)
【非特許文献6】Ponnuswamy PK. Prog. Biophys. Mol. Biol., Vol.59, 57-103(1993)
【非特許文献7】Vapnik VN, The Nature of Statistical Learning Theory, Springer(1995)
【非特許文献8】Takeda T, et al., FEBS Letters, Vol.520, 97-101(2002)
【発明の開示】
【発明が解決しようとする課題】
【0013】
しかしながら、上述した従来のGタンパク共役型受容体タンパク質の予測方法は、配列類似性を主に指標として用いている。その予測成績は、配列相同性が低い場合において、十分ではない。例えば、非特許文献8に開示されている既知Gタンパク共役型受容体を用いた予測成績は高々57%である。
【0014】
本発明の目的は、新しい手法を用いてアミノ酸配列データベースを網羅的に検索することにより、判別精度の高いGタンパク共役型受容体判別装置、判別方法、判別プログラム及びそのプログラムを記録した記録媒体を提供することにある。
【課題を解決するための手段】
【0015】
本発明者らは、既知のタンパク質のアミノ酸配列データを用いて、アミノ酸残基数、疎水性指標、アミノ酸構成頻度を基にGタンパク共役型受容体タンパク質が有する配列上の特徴についてモデル化を行った。そして、構築したモデルに機能未知のタンパク質の配列データを提供し、Gタンパク共役型受容体タンパク質である可能性について評価することによって、機能未知のタンパク質が、Gタンパク共役型受容体タンパク質である可能性を予測可能であることを見出した。特に、既知Gタンパク共役型受容体タンパク質を対象としてGタンパク共役型受容体タンパク質が有するアミノ酸配列上の特徴を抽出し、SVMにてGタンパク共役型受容体タンパク質のアミノ酸配列間に内在する規則を学習させた後、未知のタンパク質のアミノ酸配列をこの学習機械に入力し、SVMにて、学習された規則に基づいて新規なGタンパク共役型受容体タンパク質の可能性を判定する装置及びその方法を利用することにより公知の配列データベース上で網羅的に検索することにより新規Gタンパク共役型受容体タンパク質を得ることが可能であることを見出した。
【0016】
上記目的を達成するために、本発明に係るGタンパク共役型受容体判別装置(1)は、タンパク質のアミノ酸配列データを、アミノ酸の属するクラス毎に付与された識別子で表した配列である識別子配列データに変換する配列変換手段と、前記識別子配列データを分割し、所定の識別子数の長さの複数のフラグメントを生成し、生成された前記フラグメントの総数に対する各々の前記フラグメントの数の割合として各々の前記フラグメントの頻度を求める頻度算出手段と、前記タンパク質の残基数、疎水性指標及び複数の前記頻度から特徴ベクトルを生成する特徴ベクトル生成手段と、複数のタンパク質の各々に関する前記特徴ベクトル及びGタンパク共役型受容体であるか否かを表すGタンパク共役型受容体変数を用いて、サポートベクターマシンによってGタンパク共役型受容体判別モデルを生成する判別モデル生成手段と、判別対象のタンパク質に関する特徴ベクトル及び前記Gタンパク共役型受容体判別モデルを用いて判別対象のタンパク質がGタンパク共役型受容体であるか否かを判別する判別手段とを備えることを特徴としている。
【0017】
また、本発明に係るGタンパク共役型受容体判別装置(2)は、上記のGタンパク共役型受容体判別装置(1)において、複数の既知のGタンパク共役型受容体タンパク質及びGタンパク共役型受容体でない複数の膜タンパク質を用いて前記Gタンパク共役型受容体判別モデルを生成することを特徴としている。
【0018】
また、本発明に係るGタンパク共役型受容体判別装置(3)は、上記のGタンパク共役型受容体判別装置(2)において、Gタンパク共役型受容体でない複数の可溶性タンパク質をさらに用いて前記Gタンパク共役型受容体判別モデルを生成することを特徴としている。
【0019】
また、本発明に係るGタンパク共役型受容体判別装置(4)は、上記のGタンパク共役型受容体判別装置(1)〜(3)の何れかにおいて、前記フラグメントの長さが1以上6以下の範囲の整数値であることを特徴としている。
【0020】
また、本発明に係るGタンパク共役型受容体判別装置(5)は、上記のGタンパク共役型受容体判別装置(1)〜(4)の何れかにおいて、前記疎水性指標が、疎水親水指数(Hydropathy index)、疎水性因子(Hydrophobicity factor)、最適化マッチング疎水性(Optimal matching hydrophobicity)、疎水性(Hydrophobicity)、及び疎水性スケール(Hydrophobicity scales)の中の何れかから選択される1つであることを特徴としている。
【0021】
また、本発明に係るGタンパク共役型受容体判別装置(6)は、上記のGタンパク共役型受容体判別装置(1)〜(5)の何れかにおいて、前記識別子が、塩基性アミノ酸、酸性アミノ酸、芳香族アミノ酸、イミノ酸、及び脂肪族アミノ酸のクラス毎に付与されていることを特徴としている。
【0022】
また、本発明に係るGタンパク共役型受容体判別装置(7)は、上記のGタンパク共役型受容体判別装置(6)において、前記識別子が1以上5以下の範囲の整数値であることを特徴としている。
【0023】
また、本発明に係るGタンパク共役型受容体判別方法(1)は、タンパク質のアミノ酸配列データを、アミノ酸の属するクラス毎に付与された識別子で表した配列である識別子配列データに変換する第1ステップと、前記識別子配列データを分割し、所定の識別子数の長さの複数のフラグメントを生成し、生成された前記フラグメントの総数に対する各々の前記フラグメントの数の割合として各々の前記フラグメントの頻度を求める第2ステップと、前記タンパク質の残基数、疎水性指標及び複数の前記頻度から特徴ベクトルを生成する第3ステップと、複数のタンパク質の各々に関する前記特徴ベクトル及びGタンパク共役型受容体であるか否かを表すGタンパク共役型受容体変数を用いて、サポートベクターマシンによってGタンパク共役型受容体判別モデルを生成する第4ステップと、判別対象のタンパク質に関する前記特徴ベクトル及び前記Gタンパク共役型受容体判別モデルを用いて判別対象のタンパク質がGタンパク共役型受容体であるか否かを判別する第5ステップとを含むことを特徴としている。
【0024】
また、本発明に係るGタンパク共役型受容体判別方法(2)は、上記のGタンパク共役型受容体判別方法(1)において、複数の既知のGタンパク共役型受容体タンパク質及びGタンパク共役型受容体でない複数の膜タンパク質を用いて前記Gタンパク共役型受容体判別モデルを生成することを特徴としている。
【0025】
また、本発明に係るGタンパク共役型受容体判別方法(3)は、上記のGタンパク共役型受容体判別方法(2)において、Gタンパク共役型受容体でない複数の可溶性タンパク質をさらに用いて前記Gタンパク共役型受容体判別モデルを生成することを特徴としている。
【0026】
また、本発明に係るGタンパク共役型受容体判別方法(4)は、上記のGタンパク共役型受容体判別方法(1)〜(3)の何れかにおいて、前記フラグメントの長さが1、3、5、又は6の何れかであることを特徴としている。
【0027】
また、本発明に係るGタンパク共役型受容体判別方法(5)は、上記のGタンパク共役型受容体判別方法(1)〜(4)の何れかにおいて、前記疎水性指標が、疎水親水指数(Hydropathy index)、疎水性因子(Hydrophobicity factor)、最適化マッチング疎水性(Optimal matching hydrophobicity)、疎水性(Hydrophobicity)、及び疎水性スケール(Hydrophobicity scales)の中の何れかから選択される1つであることを特徴としている。
【0028】
また、本発明に係るGタンパク共役型受容体判別方法(6)は、上記のGタンパク共役型受容体判別方法(1)〜(5)の何れかにおいて、前記識別子が、塩基性アミノ酸、酸性アミノ酸、芳香族アミノ酸、イミノ酸、及び脂肪族アミノ酸のクラス毎に付与されていることを特徴としている。
【0029】
また、本発明に係るGタンパク共役型受容体判別方法(7)は、上記のGタンパク共役型受容体判別方法(6)において、前記識別子が1以上5以下の範囲の整数値であることを特徴としている。
【0030】
また、本発明に係るGタンパク共役型受容体判別プログラム(1)は、コンピュータに、タンパク質のアミノ酸配列データを、アミノ酸の属するクラス毎に付与された識別子で表した配列である識別子配列データに変換する機能と、前記識別子配列データを分割し、所定の識別子数の長さの複数のフラグメントを生成し、生成された前記フラグメントの総数に対する各々の前記フラグメントの数の割合として各々の前記フラグメントの頻度を求める頻度算出機能と、前記タンパク質の残基数、疎水性指標及び複数の前記頻度から特徴ベクトルを生成する機能と、複数のタンパク質の各々に関する前記特徴ベクトル及びGタンパク共役型受容体であるか否かを表すGタンパク共役型受容体変数を用いて、サポートベクターマシンによってGタンパク共役型受容体判別モデルを生成する機能と、判別対象のタンパク質に関する前記特徴ベクトル及び前記Gタンパク共役型受容体判別モデルを用いて判別対象のタンパク質がGタンパク共役型受容体であるか否かを判別する機能とを実現させることを特徴とする。
【0031】
また、本発明に係るGタンパク共役型受容体判別プログラム(2)は、上記のGタンパク共役型受容体判別プログラム(1)において、複数の既知のGタンパク共役型受容体タンパク質、及びGタンパク共役型受容体でない複数の膜タンパク質を用いて前記Gタンパク共役型受容体判別モデルを生成することを特徴としている。
【0032】
また、本発明に係るGタンパク共役型受容体判別プログラム(3)は、上記のGタンパク共役型受容体判別プログラム(2)において、Gタンパク共役型受容体でない複数の可溶性タンパク質をさらに用いて前記Gタンパク共役型受容体判別モデルを生成することを特徴としている。
【0033】
また、本発明に係るGタンパク共役型受容体判別プログラム(4)は、上記のGタンパク共役型受容体判別プログラム(1)〜(3)の何れかにおいて、前記フラグメントの長さが1、3、5、又は6の何れかであることを特徴としている。
【0034】
また、本発明に係るGタンパク共役型受容体判別プログラム(5)は、上記のGタンパク共役型受容体判別プログラム(1)〜(4)の何れかにおいて、前記疎水性指標が、疎水親水指数(Hydropathy index)、疎水性因子(Hydrophobicity factor)、最適化マッチング疎水性(Optimal matching hydrophobicity)、疎水性(Hydrophobicity)、及び疎水性スケール(Hydrophobicity scales)の中の何れかから選択される1つであることを特徴としている。
【0035】
また、本発明に係るGタンパク共役型受容体判別プログラム(6)は、上記のGタンパク共役型受容体判別プログラム(1)〜(5)の何れかにおいて、前記識別子が、塩基性アミノ酸、酸性アミノ酸、芳香族アミノ酸、イミノ酸、及び脂肪族アミノ酸のクラス毎に付与されていることを特徴としている。
【0036】
また、本発明に係るGタンパク共役型受容体判別プログラム(7)は、上記のGタンパク共役型受容体判別プログラム(6)において、前記識別子が1以上5以下の範囲の整数値であることを特徴としている。
【0037】
また、本発明に係るGタンパク共役型受容体判別プログラムを記録したコンピュータ読み取り可能な記録媒体は、上記のGタンパク共役型受容体判別プログラム(1)〜(7)の何れかを記録していることを特徴としている。
【発明の効果】
【0038】
本発明によれば、タンパク質がGタンパク共役型受容体であるか否かを高い精度で判別することができるので、実験を行う前に新規Gタンパク共役型受容体タンパク質候補を予め絞り込むことができ、総当り的な膨大な実験を行うことなくGタンパク共役型受容体タンパク質を効率良く発見することが可能となる。
【0039】
また、従来の予測法のようにアミノ酸配列の相同性に頼ることなく、アミノ酸配列から直接に特徴量を抽出し、これに基づいて判別を行うため、相同性タンパク質に関する情報を持たない機能未知のタンパク質配列をも判別することが可能である。
【0040】
従って、本発明は、新規Gタンパク共役型受容体タンパク質の作用を利用するバイオテクノロジーを用いる創薬の分野、さらにはこれらの基礎研究としてのバイオインフォマティクス、プロテオミクス、生命科学分野全般にわたって適用可能である。
【発明を実施するための最良の形態】
【0041】
以下、本発明に係るGタンパク共役型受容体判別装置及びその判別方法に関して、添付図を参照しながら説明する。
【0042】
図1は、本発明の実施の形態に係る新規Gタンパク共役型受容体タンパク質判別装置の概略構成を示すブロック図である。図1に示したように、本判別装置は、各部を制御するCPU1、記録部2と、メモリ3、操作部4、表示部5、配列変換部6、頻度算出部7、特徴ベクトル生成部8、判別モデル生成部9、判別部10、及びデータバス11を備えている。本判別装置は、機能未知のタンパク質がGタンパク共役型受容体であるか否かを判別するための基準となるGタンパク共役型受容体判別モデルを生成する機能、及びGタンパク共役型受容体判別モデルを用いて実際に判別を行う機能(Gタンパク共役型受容体判別機能)の2つの機能を持っている。
【0043】
図2、3は、本判別装置の動作を説明するフローチャートである。以下、これらのフローチャートに従って、本判別装置の動作を説明する。ここで、記録部2には、予め既知のGタンパク共役型受容体タンパク質のアミノ酸配列、Gタンパク共役型受容体以外の膜タンパク質のアミノ酸配列、可溶性タンパク質のアミノ酸配列が所定の形式で記録されているとする。また、特に断らない限りCPU1が行う処理として記載し、種々のデータ処理はメモリ3上のワーク領域で実行される。メモリ3は処理途中及び処理結果データの一時記憶にも使用され、処理結果データは記録部2にも適宜記録される。また、処理途中のデータ又は処理結果データは、表示部5内部のビデオメモリ(図示せず)に伝送され、所定の形式で、例えばCRT表示装置、液晶表示装置(いずれも図示せず)などに表示される。また、操作部4は例えば、コンピュータ用のキーボード、マウスなどであり、使用者により操作されて指示が入力される。まず図2のフローチャートに従って、Gタンパク共役型受容体判別モデルの生成機能に関して説明する。
【0044】
ステップS1において、操作部4を介して、所定の自然数Δ及び、判別モデルの生成に使用するタンパク質のアミノ酸配列データの総数Nの入力を受け付け、繰り返し処理のカウンタiに初期値として1をセットする。
【0045】
ステップS2において、記録部2に記録されている複数のタンパク質(既知のGタンパク共役型受容体タンパク質、Gタンパク共役型受容体以外の膜タンパク質、可溶性タンパク質)のアミノ酸配列データの中から、1つのアミノ酸配列データAiを読み出す。
【0046】
ここで、アミノ酸配列データAiは、例えばインターネットのウェブに公開されている公共或いは私的なデータベースから取得したデータである。データベースの例としては、SWISS−PROTタンパク質データベース(http://www.psc.edu/general/software/packages/swiss/swiss.html)がある。また、アミノ酸配列としては、Gタンパク共役型受容体としてデータベースに登録されている配列を用いるのが特に好ましい。これらの配列は、例えば、"An Internet review: the complete neuroscientist scours the World Wide Web." Bloom FE, Science 1996; 274(5290):1104-9に詳細が記載されているGCRDb(The G-protein-coupled Receptor Database)(http://www.gcrdb.uthscsa.edu/)、GPCRDB(http://www.gpcr.org/7tm/)、ExPASy(http://www.expasy.ch/cgi-bin/sm-gpcr.pl)、ORDB(http://senselab.med.yale.edu/senselab/ORDB/default.asp)等から入手できる。
【0047】
さらに、Gタンパク共役型受容体としてデータベースに登録されている配列のみならず、GeneBank(ftp://ncbi.nlm.nih.gov/genbank/genomes/)、ENSEMBL(http://www.ensembl.org)、PIR(http://www-nbrf.georgetown.edu/pir/、(National Biomedical Research Foundation(NBRF))、Swiss Plot(http://www.expasy.ch/sprot/sprot-top.html、Swiss Institute of Bioinformatics(SIB)、European Bioinfomatics Institute(EBI))、TrEMBL(URL及び管理者ともにSwiss Plotと同じ)、TrEMBLNEW(URL及び管理者ともにSwiss Plotと同じ)等のデータベースに登録されているヒト(H.sapiens)、マウス(M.musculus)、ラット(R.norvegicus)、ゼブラフィッシュ(D. rerio)、ショウジョ ウバエ(D. melanogaster)、線虫(C. elagans)、酵母(S.cerevisiae)、シロイヌナズナ(A. thaliana)などの如何なるアミノ酸配列を用いることもできる。
【0048】
これらのデータベースは単なる例示であり、タンパク質のアミノ酸配列が登録されているものであれば如何なるデータベースを用いることもできる。
【0049】
ステップS3において、ステップS2で読み出したアミノ酸配列データAiから、配列の長さLi、疎水性指標Hi、及びGタンパク共役型受容体変数yiを決定する。ここで、配列の長さLiは、そのタンパク質のアミノ酸残基の総数であり、読み出したアミノ酸配列Aiデータから算出する。一方、Gタンパク共役型受容体変数yiは、そのタンパク質がGタンパク共役型受容体であるか否かを示す変数であり、Gタンパク共役型受容体であれば“1”であり、Gタンパク共役型受容体で無ければ“−1”を設定する。Gタンパク共役型受容体変数yiは、タンパク質のアミノ酸配列に対応させて予め記録部2に記録されていてもよく、その場合には、Gタンパク共役型受容体変数yiを記録部から読み出せばよい。
【0050】
また、疎水性指標Hiの計算には、Kyte-Doolittle法における疎水親水指数(Hydropathy index、上記非特許文献2)、Goldsack-Chalifoux法における疎水性因子(Hydrophobicity factor、上記非特許文献3)、Sweet-Eisenberg法における最適化マッチング疎水性(Optimal matching hydrophobicity、上記非特許文献4)、Zimmerman法における疎水性(Hydrophobicity、上記非特許文献5)、及びPonnuswamy法における疎水性スケール(Hydrophobicity scales、上記非特許文献6)のいずれかを使用すればよい。詳細は後述するが、これらの疎水性指標のうち、疎水親水指数(Hydropathy index)が最も好ましい。
【0051】
ステップS4において、CPU1が、ステップS2で取得したアミノ酸配列データAiを配列変換部6に伝送し、配列変換部6が、伝送されたアミノ酸配列データAiを所定の識別子の配列データに変換する。即ち、予めタンパク質を構成するアミノ酸が属するクラス毎に識別子が付与されており、それらが対応付けられて、例えば記録部2に対応テーブルとして記録されており、配列変換部6が、その対応テーブルを参照しながら、伝送されたアミノ酸配列データAiを識別子で表わされた配列データ(以下、識別子配列データと記す)に変換する。識別子には、数字、アルファベット、記号など任意の文字を使用すれば良い。ここでは一例として、表1に示した識別子を使用することとする。即ち、ヒスチジン(His)、アルギニン(Arg)、リジン(Lys)などの塩基性アミノ酸の識別子を“1”とし、アスパラギン酸(Asp)、グルタミン酸(Glu)などの酸性アミノ酸の識別子を“2”とし、フェニルアラニン(Phe)、チロシン(Tyr)、トリプトファン(Trp)などの芳香族アミノ酸の識別子を“3”とし、プロリン(Pro)などのイミノ酸の識別子を“4”とし、その他の脂肪族アミノ酸(Other)の識別子を“5”とする。
【0052】
【表1】
【0053】
ステップS5において、配列変換部6が、ステップS4で変換した識別子配列データ(アミノ酸配列データAiに対応)を頻度算出部7に出力し、頻度算出部7が、ステップS1で指定された値Δを単位長さ(アミノ酸残基の個数)として、入力された識別子配列データを先頭から分割する。分割された単位長さの識別子配列データを、アミノ酸フラグメントと呼ぶ。Δとしては、任意の自然数を使用することができるが、後述するように1〜6の値が望ましく、その中でも5が最も望ましい。
【0054】
ステップS6において、頻度算出部7は、ステップS5で生成されたアミノ酸フラグメントの頻度を求める。即ち、頻度算出部7は、ステップS5で生成されたアミノ酸フラグメントの総数に対する各アミノ酸フラグメントaijの個数の割合を、頻度Fijとして求める。一例として、Δ=5とした場合を表2に示す。表2では、アミノ酸フラグメントaijは、表1の識別子1〜5を用いて標記した順列として、昇順に表記されている。この場合、アミノ酸フラグメントの総数は、55=3125である。
【0055】
【表2】
【0056】
ステップS7において、頻度算出部7が、頻度Fijを特徴ベクトル生成部8に出力し、特徴ベクトル生成部8は、入力された頻度FijとステップS3で取得した配列長Li及び疎水性指標Hiとを対応つけて、ベクトルデータxiを生成する。具体的には、ベクトルデータxiは、例えばxi=(Li,Hi,Fi1,…,FiM)である。Mは可能なアミノ酸フラグメントの総数であり、Δ=5の場合、M=3125である。また、Fi1,…,FiMの順序は、所定の順序であればよく、例えば表2に示した番号jの順である。
【0057】
ステップS8において、特徴ベクトル生成部8は、ベクトルデータxiをGタンパク共役型受容体変数yiと対応させて記録部2に記録する。
【0058】
ステップS9において、カウンタiがNよりも小さいか否かを判断し、小さいと判断すれば、ステップS10に移行して、カウンタiを1増加させて、ステップS2に戻る。このように、CPUは、配列変換部6、頻度算出部7、特徴ベクトル生成部8を制御ながら、カウンタiがN以上になるまで、ステップS2〜S8を繰り返し、記録部2から順にタンパク質配列データAiを読み出し、対応するベクトルデータxiを生成し、Gタンパク共役型受容体変数yiと対応させて記録部2に記録する。
【0059】
ステップS9において、i<Nでないと判断すればステップS11に移行し、判別モデル生成部9が、Gタンパク共役型受容体判別モデルを生成する。即ち、Gタンパク共役型受容体判別モデルの生成は、ステップS8で記録されたベクトルデータxi(i=1〜N)をパターン認識のための特徴ベクトルとし、Gタンパク共役型受容体変数yi(i=1〜N)と共に一連のトレーニングデータとして、サポートベクターマシンSVMに入力することによって行なわれる。SVMは公知の技術であるので、ここでは簡単に説明する。
【0060】
SVMは、認識対象のサンプル集合を2つのクラスに分類する方法であって、1960年代にVapnik等が提案したOptimal Separating Hyperplaneを起源とする。即ち、多次元ベクトル空間上に位置する各サンプルを分離することができる2つの超平面を決定する方法である。通常、サンプル集合を明確に分離できる、即ち線形分離可能な場合は少ないので、ソフトマージンを導入する方法がある。さらに、1990年代になってカーネル学習法と組み合わされた非線形の識別方法へと拡張された。カーネルトリックにより非線形の識別関数が構成できるように拡張されたSVMは、現在知られている手法の中でも最もパターン認識性能の高い学習モデルの一つである(上記非特許文献7参照)。認識対象に応じて種々のSVMを使用することができるが、ここでは、一例としてソフトマージンを導入したSVMを使用する場合を説明する。
【0061】
パターン認識には、認識対象から何らかの特徴量を計測(抽出)することが必要である。一般に、1種類の特徴量だけではなく複数の特徴量を計測し、それらを同時に使用して認識を行う。
【0062】
SVMでは正しい例である正例と誤った例である負例の2つのクラスのいずれかに属するr個のトレーニング用データの集合(x1,y1),…(xr,yr)を準備する。ここで、xiは、データiの特徴ベクトル(n次元ベクトル)である。また、yiは、データiが正例の場合“+1”の値をとり、負例の場合には、“−1”の値をとるスカラーの変数である。ここでは、Gタンパク共役型受容体であるタンパク質の特徴ベクトルとして、上記ステップS8で記録部に記録したベクトルデータxi及びGタンパク共役型受容体変数yiを用いる。即ち、配列の長さL、疎水性指標H、アミノ酸フラグメントの頻度(F1,…,FM)を用いて、Gタンパク共役型受容体であるタンパク質の特徴ベクトルは、xi=(Li,Hi,Fi1,…,FiM)、yi=1で表され、Gタンパク共役型受容体でないタンパク質の特徴ベクトルは、xj=(Lj,Hj,Fj1,…,FjM)、yj=0で表される。ここで、i=1〜Nである。
【0063】
これら複数の特徴ベクトル(以下、トレーニングセットと記す)(x1,y1),…(xN,yN)を(M+2)次元Euclid空間上の(w・x)+b=0なる超平面で分離する。ここで、wもベクトルであり、w・xは2つのベクトルの内積(スカラー)を表し、bは(≦0)スカラーである。この際、近接する正例と負例のデータ間の距離が大きい方が、精度良くデータを分類できる。ここで、(w・x)+b=1で表される正例側の分離超平面H1と、(w・x)+b=−1で表される負例側の分離超平面H2とを考える。
【0064】
2つの分離超平面H1、H2間の距離は、2/‖w‖である。この距離を最大にするには、‖w‖を最小にすればよい。ある関数のとる値が最小値となる時、‖w‖が最適値をとるような関数を目的関数と呼ぶ。この場合、下記の目的関数Φを使用すればよい。
【0065】
【数1】
【0066】
ここで、ξiは、トレーニングデータxi(i=1〜N)が分離超平面によって分離できない場合、即ち訓練データxiの正例/負例を誤認識してしまう場合の訓練データxiの分離超平面からの距離を表す非負の変数である。式1の右辺第一項は、2つの分離超平面H1とH2との間の距離の逆数の2乗に比例しているので、この項の値が小さいほど2つの分離超平面間の距離が大きい。右辺第二項のCを除いた部分は、分離できなかった各訓練データと、分離超平面H1あるいはH2との距離(例えば、トレーニングデータxiが正例の場合、超平面H1からの距離、トレーニングデータxiが負例の場合、超平面H2からの距離)の和であり、誤差項と呼ぶ。Cは、第一項と第二項を重視する度合いを決めるための正値(0以上)のパラメータである。Cの値が大きいときは、訓練データxiの分離超平面H1、H2からの誤差が大きく評価され、Cの値が小さいときは、相対的に分離超平面間の距離の大きさが重視される。後述する実施例ではC=1を用いた。
【0067】
トレーニングセットにより、目的関数Φを最小にする最適な判別ベクトルw及び判別スカラーbを決定し、記録部に記録する。最適な判別ベクトルw及び判別スカラーbの計算には、例えばLagrange法を用いることができる。以上で、Gタンパク共役型受容体判別部9によるGタンパク共役型受容体判別モデルの生成が終了する。
【0068】
次に、上記で決定されたGタンパク共役型受容体判別モデルを使用したGタンパク共役型受容体判別機能に関して説明する。図3は、Gタンパク共役型受容体判別処理を説明するフローチャートである。ここで、図2と同様に、特に断らない限りCPUが行う処理として記載し、メモリ、記録部を使用して適宜処理途中のデータを記録しながら処理が行われる。
【0069】
ステップS21において、判別対象のタンパク質のアミノ酸配列データを入力する。例えば、操作部4を介して、予め記録部2に記録されているアミノ酸配列データが指定され、それが読み出される。
【0070】
ステップS22において、ステップS21で読み出されたアミノ酸配列データから、上記したステップS3と同様に、配列長L0、疎水性指標H0を決定する。
【0071】
ステップS23〜S26において、上記ステップS4〜S7と同様に、配列変換部6が、ステップS21で入力されたアミノ酸配列データを識別子配列データに変換し、頻度算出部7が、識別子配列データを指定の長さΔ(Gタンパク共役型受容体判別モデルの生成に使用したのと同じ値)のフラグメントに分割し、各フラグメントの頻度を求め、特徴ベクトル生成部8が、特徴ベクトルデータx0を生成する。
【0072】
ステップS27において、判別部10が、Gタンパク共役型受容体判別モデルを用いて、ステップS26で生成され特徴ベクトルデータx0がGタンパク共役型受容体であるか否かを判別する。即ち、Gタンパク共役型受容体判別モデルを用いて計算した識別関数が“1”であれば所定のフラグfに“1”をセット(Gタンパク共役型受容体であることを示す)し、“−1”であれば、所定のフラグfに“−1”をセット(Gタンパク共役型受容体でないことを示す)する。SVMによる判別方法の詳細は非特許文献7に開示されているので省略する。
【0073】
ステップS8において、フラグfの値に応じて判別結果を出力する。即ち、f=1であれば表示部にGタンパク共役型受容体であることを表示し、f=−1であれば表示部にGタンパク共役型受容体でないことを表示する。
【0074】
以上によって、機能未知のタンパク質のアミノ酸配列が分かれば、予め決定されたGタンパク共役型受容体判別モデルを用いてGタンパク共役型受容体であるか否かの判別を行うことができる。
【0075】
本発明の有効性を確認するために、後述する実施例で示されるように、既知Gタンパク共役型受容体タンパク質の配列(2955配列)、Gタンパク共役型受容体以外の膜タンパク質の配列(1152配列)、可溶性タンパク質の配列(3202配列)をトレーニングセットとして用いて、クロスバリデーション試験を行った。その結果、上記した何れの疎水性指標を使用した場合にも90%近い精度で正しく判別することができた。その中でも、Kyte-dolittleらによる疎水親水指標を使用してGタンパク共役型受容体判定に使用するモデルを生成した場合、最も高い判別精度93.8%を実現することができた。
【0076】
また、Gタンパク共役型受容体判別モデルを生成する方法は、SVMに限定されず、既知のタンパク質の配列長、疎水性指標、及びフラグメントの頻度を要素とする特徴ベクトルを用いさえすれば、ベイズ推定、決定木、kNN、ニューラルネットワークやその他の認識方法を用いてもよい。
【0077】
また、本発明に係るGタンパク共役型受容体判別装置の構成は、図1に示した構成に限定さない。即ち、単体の装置であっても、複数の装置からなるシステムであってもよく、さらにLAN、WAN等のネットワークを介してデータの記録、交換などを行いながら処理が行なわれるシステムであってもよい。
【0078】
また、内部バスに接続されたCPU、ROMやRAMなどのメモリ、入力装置、出力装置、外部記録装置、媒体駆動装置、可搬記録媒体、ネットワーク接続装置で構成されるシステム、例えば一般的なコンピュータであってもよい。即ち、上記した機能をコンピュータに実現させるコンピュータプログラムがコンピュータ読み取り可能な記録媒体に記録されており、そのプログラムを記録媒体から読み出し、メモリ上に展開し、CPUがそのプログラムを実行することによっても実現することができる。
【0079】
コンピュータプログラムを供給するための可搬記録媒体としては、例えば、フレキシブルディスク、ハードディスク、光ディスク、光磁気ディスク、CD−ROM、CD−R、DVD−ROM、DVD−RAM、磁気テープ、不揮発性メモリーカード等の種々の記録媒体を用いることができる。
【0080】
また、コンピュータがメモリ上に読み出したプログラムコードを実行することによって、上記した実施の形態の機能が実現される場合に限らず、そのプログラムコードの指示に基づき、コンピュータ上で複数のコンピュータアプリケーションソフトが実際の処理の一部又は全部を行ない、その処理によって上記した実施の形態の機能が実現されるようにしてもよい。
【0081】
さらに、可搬型記録媒体から読み出されたコンピュータプログラムコードやコンピュータプログラム(データ)提供者から提供されたコンピュータプログラム(データ)が、コンピュータに挿入された機能拡張ボードやコンピュータに接続された機能拡張ユニットに備わるメモリに書き込まれた後、そのプログラムコードの指示に基づき、その機能拡張ボードや機能拡張ユニットに備わるCPUなどが実際の処理の一部又は全部を行ない、その処理によって上記した実施の形態の機能が実現されるようにしてもよい。
【実施例】
【0082】
以下に実施例を示し、本発明の特徴とするところをより一層明確にする。
(1)Gタンパク共役型受容体の判別
コンピュータを使用して図2に示したフローチャートに従って生成したGタンパク共役型受容体判別モデルを用いて、トレーニングセットに含まれないGタンパク共役型受容体であるか否かが既知の複数のタンパク質を対象として、図3に示したフローチャートに従ってGタンパク共役型受容体判別を行なった。
【0083】
その結果、例えば、トレーニングセットに含まれなかったGR3(NM_004293)がGタンパク共役型受容体として抽出された。このGR3(NM_004293)は、Gタンパク共役型受容体であることが知られており、本方法によるGタンパク共役型受容体判別が有効であることが分かる。
(2)Gタンパク共役型受容体判別精度のフラグメント長への依存性
Gタンパク共役型受容体判別精度が、どの程度フラグメントの長さに依存するかを評価した。
【0084】
図2に示したフローチャートにおいて、Δ=1、3、5、又は6(それぞれ、アミノ酸1残基、3残基、5残基、6残基に対応)とし、上記したように、既知Gタンパク共役型受容体タンパク質の配列(2955配列)、Gタンパク共役型受容体以外の膜タンパク質の配列(1152配列)、可溶性タンパク質の配列(3202配列)をトレーニングセットとして用いて、Gタンパク共役型受容体判別モデルを生成し、その後クロスバリデーション試験を行なった。
【0085】
その結果を図4に示す。図4は、横軸はΔ(フラグメント長)であり、縦軸はGタンパク共役型受容体の判別精度であり、総判別回数に対する正しい結果が得られた回数の割合である。図3から分かるように、何れの場合にも判別精度が90%より高く、本発明が有効であることが分かる。さらに、Δ=5(5残基フラグメント)の場合、判別精度が93.8%と最も高くなっており、Δ=5が最も望ましい。
(3)Gタンパク共役型受容体判別精度の疎水性指標への依存性
Gタンパク共役型受容体判別精度が、どの程度疎水性指標に依存するかを評価した。即ち、図2に示したフローチャートにおいて、Δ=5とし、疎水性指標Hとして、疎水親水指数(Hydropathy index)、疎水性因子(Hydrophobicity factor)、最適化マッチング疎水性(Optimal matching hydrophobicity)、疎水性(Hydrophobicity)、及び疎水性スケール(Hydrophobicity scales)を用いて、上記と同様に、既知Gタンパク共役型受容体タンパク質の配列(2955配列)、Gタンパク共役型受容体以外の膜タンパク質の配列(1152配列)、可溶性タンパク質の配列(3202配列)をトレーニングセットとして用いて、Gタンパク共役型受容体判別モデルを生成し、その後クロスバリデーション試験を行った。
【0086】
その結果を図5に示す。図5は、横軸は疎水性指標の種類であり、縦軸は図4と同様にGタンパク共役型受容体の判別精度である。何れの疎水性指標を使用した場合にも判別精度が約88%以上と高く、本発明が有効であることが分かる。さらに、疎水性指標として疎水親水指数(Hydropathy index)を使用した場合、判別精度が93.8%と最も高くなっており、疎水性指標として疎水親水指数(Hydropathy index)が最も望ましい。
【図面の簡単な説明】
【0087】
【図1】本発明の実施の形態に係るGタンパク共役型受容体判別装置の概略構成を示すブロック図である。
【図2】図1の判別装置によるGタンパク共役型受容体判別モデルを生成する機能を説明するフローチャートである。
【図3】図1の判別装置によるGタンパク共役型受容体判別機能を説明するフローチャートである。
【図4】本発明の実施の形態に係るGタンパク共役型受容体判別方法の判別精度のフラグメントの長さへの依存性を示す図である。
【図5】本発明の実施の形態に係るGタンパク共役型受容体判別方法の判別精度の疎水性指標への依存性を示す図である。
【符号の説明】
【0088】
1 CPU
2 記録部
3 メモリ
4 操作部
5 表示部
6 配列変換部
7 頻度算出部
8 特徴ベクトル生成部
9 判別モデル生成部
10 判別部
11 データバス
【特許請求の範囲】
【請求項1】
タンパク質のアミノ酸配列データを、アミノ酸の属するクラス毎に付与された識別子で表した配列である識別子配列データに変換する配列変換手段と、
前記識別子配列データを分割し、所定の識別子数の長さの複数のフラグメントを生成し、生成された前記フラグメントの総数に対する各々の前記フラグメントの数の割合として各々の前記フラグメントの頻度を求める頻度算出手段と、
前記タンパク質の残基数、疎水性指標及び複数の前記頻度から特徴ベクトルを生成する特徴ベクトル生成手段と、
複数のタンパク質の各々に関する前記特徴ベクトル及びGタンパク共役型受容体であるか否かを表すGタンパク共役型受容体変数を用いて、サポートベクターマシンによってGタンパク共役型受容体判別モデルを生成する判別モデル生成手段と、
判別対象のタンパク質に関する特徴ベクトル及び前記Gタンパク共役型受容体判別モデルを用いて判別対象のタンパク質がGタンパク共役型受容体であるか否かを判別する判別手段とを備えることを特徴とするGタンパク共役型受容体判別装置。
【請求項2】
複数の既知のGタンパク共役型受容体タンパク質及びGタンパク共役型受容体でない複数の膜タンパク質を用いて前記Gタンパク共役型受容体判別モデルを生成することを特徴とする請求項1に記載のGタンパク共役型受容体判別装置。
【請求項3】
Gタンパク共役型受容体でない複数の可溶性タンパク質をさらに用いて前記Gタンパク共役型受容体判別モデルを生成することを特徴とする請求項2に記載のGタンパク共役型受容体判別装置。
【請求項4】
前記フラグメントの長さが1以上6以下の範囲の整数値であることを特徴とする請求項1〜3の何れかの項に記載のGタンパク共役型受容体判別装置。
【請求項5】
前記疎水性指標が、疎水親水指数(Hydropathy index)、疎水性因子(Hydrophobicity factor)、最適化マッチング疎水性(Optimal matching hydrophobicity)、疎水性(Hydrophobicity)、及び疎水性スケール(Hydrophobicity scales)の中の何れかから選択される1つであることを特徴とする請求項1〜4の何れかの項に記載のGタンパク共役型受容体判別装置。
【請求項6】
前記識別子が、塩基性アミノ酸、酸性アミノ酸、芳香族アミノ酸、イミノ酸、及び脂肪族アミノ酸のクラス毎に付与されていることを特徴とする請求項1〜5の何れかの項に記載のGタンパク共役型受容体判別装置。
【請求項7】
前記識別子が1以上5以下の範囲の整数値であることを特徴とする請求項6に記載のGタンパク共役型受容体判別装置。
【請求項8】
タンパク質のアミノ酸配列データを、アミノ酸の属するクラス毎に付与された識別子で表した配列である識別子配列データに変換する第1ステップと、
前記識別子配列データを分割し、所定の識別子数の長さの複数のフラグメントを生成し、生成された前記フラグメントの総数に対する各々の前記フラグメントの数の割合として各々の前記フラグメントの頻度を求める第2ステップと、
前記タンパク質の残基数、疎水性指標及び複数の前記頻度から特徴ベクトルを生成する第3ステップと、
複数のタンパク質の各々に関する前記特徴ベクトル及びGタンパク共役型受容体であるか否かを表すGタンパク共役型受容体変数を用いて、サポートベクターマシンによってGタンパク共役型受容体判別モデルを生成する第4ステップと、
判別対象のタンパク質に関する前記特徴ベクトル及び前記Gタンパク共役型受容体判別モデルを用いて判別対象のタンパク質がGタンパク共役型受容体であるか否かを判別する第5ステップとを含むGタンパク共役型受容体判別方法。
【請求項9】
複数の既知のGタンパク共役型受容体タンパク質及びGタンパク共役型受容体でない複数の膜タンパク質を用いて前記Gタンパク共役型受容体判別モデルを生成することを特徴とする請求項8に記載のGタンパク共役型受容体判別方法。
【請求項10】
Gタンパク共役型受容体でない複数の可溶性タンパク質をさらに用いて前記Gタンパク共役型受容体判別モデルを生成することを特徴とする請求項9に記載のGタンパク共役型受容体判別方法。
【請求項11】
前記フラグメントの長さが1、3、5、又は6の何れかであることを特徴とする請求項8〜10の何れかの項に記載のGタンパク共役型受容体判別方法。
【請求項12】
前記疎水性指標が、疎水親水指数(Hydropathy index)、疎水性因子(Hydrophobicity factor)、最適化マッチング疎水性(Optimal matching hydrophobicity)、疎水性(Hydrophobicity)、及び疎水性スケール(Hydrophobicity scales)の中の何れかから選択される1つであることを特徴とする請求項8〜11の何れかの項に記載のGタンパク共役型受容体判別方法。
【請求項13】
前記識別子が、塩基性アミノ酸、酸性アミノ酸、芳香族アミノ酸、イミノ酸、及び脂肪族アミノ酸のクラス毎に付与されていることを特徴とする請求項8〜12の何れかの項に記載のGタンパク共役型受容体判別方法。
【請求項14】
前記識別子が1以上5以下の範囲の整数値であることを特徴とする請求項13に記載のGタンパク共役型受容体判別方法。
【請求項15】
コンピュータに、
タンパク質のアミノ酸配列データを、アミノ酸の属するクラス毎に付与された識別子で表した配列である識別子配列データに変換する機能と、
前記識別子配列データを分割し、所定の識別子数の長さの複数のフラグメントを生成し、生成された前記フラグメントの総数に対する各々の前記フラグメントの数の割合として各々の前記フラグメントの頻度を求める頻度算出機能と、
前記タンパク質の残基数、疎水性指標及び複数の前記頻度から特徴ベクトルを生成する機能と、
複数のタンパク質の各々に関する前記特徴ベクトル及びGタンパク共役型受容体であるか否かを表すGタンパク共役型受容体変数を用いて、サポートベクターマシンによってGタンパク共役型受容体判別モデルを生成する機能と、
判別対象のタンパク質に関する前記特徴ベクトル及び前記Gタンパク共役型受容体判別モデルを用いて判別対象のタンパク質がGタンパク共役型受容体であるか否かを判別する機能とを実現させるためのGタンパク共役型受容体判別プログラム。
【請求項16】
複数の既知のGタンパク共役型受容体タンパク質、及びGタンパク共役型受容体でない複数の膜タンパク質を用いて前記Gタンパク共役型受容体判別モデルを生成することを特徴とする請求項15に記載のGタンパク共役型受容体判別プログラム。
【請求項17】
Gタンパク共役型受容体でない複数の可溶性タンパク質をさらに用いて前記Gタンパク共役型受容体判別モデルを生成することを特徴とする請求項16に記載のGタンパク共役型受容体判別プログラム。
【請求項18】
前記フラグメントの長さが1、3、5、又は6の何れかであることを特徴とする請求項15〜17の何れかの項に記載のGタンパク共役型受容体判別プログラム。
【請求項19】
前記疎水性指標が、疎水親水指数(Hydropathy index)、疎水性因子(Hydrophobicity factor)、最適化マッチング疎水性(Optimal matching hydrophobicity)、疎水性(Hydrophobicity)、及び疎水性スケール(Hydrophobicity scales)の中の何れかから選択される1つであることを特徴とする請求項15〜18の何れかの項に記載のGタンパク共役型受容体判別プログラム。
【請求項20】
前記識別子が、塩基性アミノ酸、酸性アミノ酸、芳香族アミノ酸、イミノ酸、及び脂肪族アミノ酸のクラス毎に付与されていることを特徴とする請求項15〜19の何れかの項に記載のGタンパク共役型受容体判別プログラム。
【請求項21】
前記識別子が1以上5以下の範囲の整数値であることを特徴とする請求項20に記載のGタンパク共役型受容体判別プログラム。
【請求項22】
請求項15〜21の何れかの項に記載のGタンパク共役型受容体判別プログラムを記録したコンピュータ読み取り可能な記録媒体。
【請求項1】
タンパク質のアミノ酸配列データを、アミノ酸の属するクラス毎に付与された識別子で表した配列である識別子配列データに変換する配列変換手段と、
前記識別子配列データを分割し、所定の識別子数の長さの複数のフラグメントを生成し、生成された前記フラグメントの総数に対する各々の前記フラグメントの数の割合として各々の前記フラグメントの頻度を求める頻度算出手段と、
前記タンパク質の残基数、疎水性指標及び複数の前記頻度から特徴ベクトルを生成する特徴ベクトル生成手段と、
複数のタンパク質の各々に関する前記特徴ベクトル及びGタンパク共役型受容体であるか否かを表すGタンパク共役型受容体変数を用いて、サポートベクターマシンによってGタンパク共役型受容体判別モデルを生成する判別モデル生成手段と、
判別対象のタンパク質に関する特徴ベクトル及び前記Gタンパク共役型受容体判別モデルを用いて判別対象のタンパク質がGタンパク共役型受容体であるか否かを判別する判別手段とを備えることを特徴とするGタンパク共役型受容体判別装置。
【請求項2】
複数の既知のGタンパク共役型受容体タンパク質及びGタンパク共役型受容体でない複数の膜タンパク質を用いて前記Gタンパク共役型受容体判別モデルを生成することを特徴とする請求項1に記載のGタンパク共役型受容体判別装置。
【請求項3】
Gタンパク共役型受容体でない複数の可溶性タンパク質をさらに用いて前記Gタンパク共役型受容体判別モデルを生成することを特徴とする請求項2に記載のGタンパク共役型受容体判別装置。
【請求項4】
前記フラグメントの長さが1以上6以下の範囲の整数値であることを特徴とする請求項1〜3の何れかの項に記載のGタンパク共役型受容体判別装置。
【請求項5】
前記疎水性指標が、疎水親水指数(Hydropathy index)、疎水性因子(Hydrophobicity factor)、最適化マッチング疎水性(Optimal matching hydrophobicity)、疎水性(Hydrophobicity)、及び疎水性スケール(Hydrophobicity scales)の中の何れかから選択される1つであることを特徴とする請求項1〜4の何れかの項に記載のGタンパク共役型受容体判別装置。
【請求項6】
前記識別子が、塩基性アミノ酸、酸性アミノ酸、芳香族アミノ酸、イミノ酸、及び脂肪族アミノ酸のクラス毎に付与されていることを特徴とする請求項1〜5の何れかの項に記載のGタンパク共役型受容体判別装置。
【請求項7】
前記識別子が1以上5以下の範囲の整数値であることを特徴とする請求項6に記載のGタンパク共役型受容体判別装置。
【請求項8】
タンパク質のアミノ酸配列データを、アミノ酸の属するクラス毎に付与された識別子で表した配列である識別子配列データに変換する第1ステップと、
前記識別子配列データを分割し、所定の識別子数の長さの複数のフラグメントを生成し、生成された前記フラグメントの総数に対する各々の前記フラグメントの数の割合として各々の前記フラグメントの頻度を求める第2ステップと、
前記タンパク質の残基数、疎水性指標及び複数の前記頻度から特徴ベクトルを生成する第3ステップと、
複数のタンパク質の各々に関する前記特徴ベクトル及びGタンパク共役型受容体であるか否かを表すGタンパク共役型受容体変数を用いて、サポートベクターマシンによってGタンパク共役型受容体判別モデルを生成する第4ステップと、
判別対象のタンパク質に関する前記特徴ベクトル及び前記Gタンパク共役型受容体判別モデルを用いて判別対象のタンパク質がGタンパク共役型受容体であるか否かを判別する第5ステップとを含むGタンパク共役型受容体判別方法。
【請求項9】
複数の既知のGタンパク共役型受容体タンパク質及びGタンパク共役型受容体でない複数の膜タンパク質を用いて前記Gタンパク共役型受容体判別モデルを生成することを特徴とする請求項8に記載のGタンパク共役型受容体判別方法。
【請求項10】
Gタンパク共役型受容体でない複数の可溶性タンパク質をさらに用いて前記Gタンパク共役型受容体判別モデルを生成することを特徴とする請求項9に記載のGタンパク共役型受容体判別方法。
【請求項11】
前記フラグメントの長さが1、3、5、又は6の何れかであることを特徴とする請求項8〜10の何れかの項に記載のGタンパク共役型受容体判別方法。
【請求項12】
前記疎水性指標が、疎水親水指数(Hydropathy index)、疎水性因子(Hydrophobicity factor)、最適化マッチング疎水性(Optimal matching hydrophobicity)、疎水性(Hydrophobicity)、及び疎水性スケール(Hydrophobicity scales)の中の何れかから選択される1つであることを特徴とする請求項8〜11の何れかの項に記載のGタンパク共役型受容体判別方法。
【請求項13】
前記識別子が、塩基性アミノ酸、酸性アミノ酸、芳香族アミノ酸、イミノ酸、及び脂肪族アミノ酸のクラス毎に付与されていることを特徴とする請求項8〜12の何れかの項に記載のGタンパク共役型受容体判別方法。
【請求項14】
前記識別子が1以上5以下の範囲の整数値であることを特徴とする請求項13に記載のGタンパク共役型受容体判別方法。
【請求項15】
コンピュータに、
タンパク質のアミノ酸配列データを、アミノ酸の属するクラス毎に付与された識別子で表した配列である識別子配列データに変換する機能と、
前記識別子配列データを分割し、所定の識別子数の長さの複数のフラグメントを生成し、生成された前記フラグメントの総数に対する各々の前記フラグメントの数の割合として各々の前記フラグメントの頻度を求める頻度算出機能と、
前記タンパク質の残基数、疎水性指標及び複数の前記頻度から特徴ベクトルを生成する機能と、
複数のタンパク質の各々に関する前記特徴ベクトル及びGタンパク共役型受容体であるか否かを表すGタンパク共役型受容体変数を用いて、サポートベクターマシンによってGタンパク共役型受容体判別モデルを生成する機能と、
判別対象のタンパク質に関する前記特徴ベクトル及び前記Gタンパク共役型受容体判別モデルを用いて判別対象のタンパク質がGタンパク共役型受容体であるか否かを判別する機能とを実現させるためのGタンパク共役型受容体判別プログラム。
【請求項16】
複数の既知のGタンパク共役型受容体タンパク質、及びGタンパク共役型受容体でない複数の膜タンパク質を用いて前記Gタンパク共役型受容体判別モデルを生成することを特徴とする請求項15に記載のGタンパク共役型受容体判別プログラム。
【請求項17】
Gタンパク共役型受容体でない複数の可溶性タンパク質をさらに用いて前記Gタンパク共役型受容体判別モデルを生成することを特徴とする請求項16に記載のGタンパク共役型受容体判別プログラム。
【請求項18】
前記フラグメントの長さが1、3、5、又は6の何れかであることを特徴とする請求項15〜17の何れかの項に記載のGタンパク共役型受容体判別プログラム。
【請求項19】
前記疎水性指標が、疎水親水指数(Hydropathy index)、疎水性因子(Hydrophobicity factor)、最適化マッチング疎水性(Optimal matching hydrophobicity)、疎水性(Hydrophobicity)、及び疎水性スケール(Hydrophobicity scales)の中の何れかから選択される1つであることを特徴とする請求項15〜18の何れかの項に記載のGタンパク共役型受容体判別プログラム。
【請求項20】
前記識別子が、塩基性アミノ酸、酸性アミノ酸、芳香族アミノ酸、イミノ酸、及び脂肪族アミノ酸のクラス毎に付与されていることを特徴とする請求項15〜19の何れかの項に記載のGタンパク共役型受容体判別プログラム。
【請求項21】
前記識別子が1以上5以下の範囲の整数値であることを特徴とする請求項20に記載のGタンパク共役型受容体判別プログラム。
【請求項22】
請求項15〜21の何れかの項に記載のGタンパク共役型受容体判別プログラムを記録したコンピュータ読み取り可能な記録媒体。
【図1】

【図2】
【図3】
【図4】
【図5】
【図2】
【図3】
【図4】
【図5】
【公開番号】特開2006−3970(P2006−3970A)
【公開日】平成18年1月5日(2006.1.5)
【国際特許分類】
【出願番号】特願2004−176965(P2004−176965)
【出願日】平成16年6月15日(2004.6.15)
【出願人】(000206956)大塚製薬株式会社 (230)
【Fターム(参考)】
【公開日】平成18年1月5日(2006.1.5)
【国際特許分類】
【出願日】平成16年6月15日(2004.6.15)
【出願人】(000206956)大塚製薬株式会社 (230)
【Fターム(参考)】
[ Back to top ]