
Nグラム検索のための転置インデックスの生成方法および生成装置、当該転置インデックスを用いた検索方法および検索装置、ならびに、コンピュータプログラム
【課題】検索漏れを抑えるのに好適な転置インデックスの生成方法等を提供する。
【解決手段】生成装置1は、複数の文書データ(文書データ群500)のそれぞれを、所定の変換規則に基づいて、変換文書データに変換する文書文字列変換部101と、変換された複数の文書データに含まれる文字列から、「N文字の文字列であるNグラム(Nは自然数)」を抽出する文書Nグラム抽出部102と、抽出されたNグラムと、変換文書データ中における当該Nグラムの出現位置と、を構成要素とする転置インデックス600を生成するインデックス生成部103と、を備えることを特徴とする。
【解決手段】生成装置1は、複数の文書データ(文書データ群500)のそれぞれを、所定の変換規則に基づいて、変換文書データに変換する文書文字列変換部101と、変換された複数の文書データに含まれる文字列から、「N文字の文字列であるNグラム(Nは自然数)」を抽出する文書Nグラム抽出部102と、抽出されたNグラムと、変換文書データ中における当該Nグラムの出現位置と、を構成要素とする転置インデックス600を生成するインデックス生成部103と、を備えることを特徴とする。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、Nグラム検索に関し、とくに検索漏れを抑えるのに好適な転置インデックスの生成方法および生成装置、当該転置インデックスを用いた検索方法および検索装置、ならびにコンピュータプログラムに関する。
【背景技術】
【0002】
文書の電子化の増大に伴い、これまでに蓄積されてきた大量の文書群から所望の文書を見つけ出す検索技術の重要性が高まっている。
【0003】
大量の文書群を対象とした検索では、検索処理の高速化のため、検索対象となる文書群に含まれる単語等を索引単位として、索引ファイル(以下、「転置インデックス」と呼称する。)を作成することが一般的である。あらかじめ作成された転置インデックスを検索時に用いることで、検索のたびに大量の文書群にアクセスする必要がなくなり、高速な検索処理が実現されるからである。
【0004】
ところで、日本語の文書は、極めて柔軟な表記が可能であり、同じ意味を有する単語を表記する場合でも複数の表記が存在する。例えば、「ユーザ」と「ユーザー」、「インターフェース」と「インターフェイス」といったカタカナ表記、あるいは「表わす」と「表す」、「行なう」と「行う」といった送り仮名表記等である。そのため、大量の文書群から所望の文書を検索する場合に、ユーザが検索時に入力した検索語をそのまま使用すると、その検索語と同一の表記で記述されている文書は検索することができるが、異なる表記で記述されている文書は検索することができず、検索漏れが発生してしまうという問題点がある。
【0005】
このような問題点に対し、検索漏れを防ぐための種々の技術が開発されている。例えば特許文献1および特許文献2には、検索対象の文書群についての転置インデックスを単語単位で作成する際に、表記ゆれを伴う単語を一定の規則に従って統一した表記に変換してから転置インデックスを作成する技術が開示されている。この場合、検索時には、入力された検索語を同様の規則に従って変換してから当該転置インデックスに基づいて検索を行うことで、表記ゆれによる検索漏れを抑えつつ検索することができる。
【先行技術文献】
【特許文献】
【0006】
【特許文献1】特開平7−319891号公報
【特許文献2】特開2002−73656号公報
【発明の概要】
【発明が解決しようとする課題】
【0007】
日本語の文書は、英語などの他の多くの言語と異なり、スペース等によって単語の切れ目が明示的に示されないため、転置インデックスを作成する際に、単語に分解する必要がある。そのため、表記ゆれに起因する検索漏れとともに、日本語の単語分解の精度によっては、さらなる検索漏れも生じうる。
【0008】
本発明は、以上のような課題を解決するためのものであり、検索漏れを抑えるのに好適な転置インデックスの生成方法および生成装置、当該転置インデックスを用いた検索方法および検索装置、ならびに、コンピュータプログラムを提供することを目的とする。
【課題を解決するための手段】
【0009】
上記目的を達成するため、本発明にかかる転置インデックスの生成方法は、
複数の文書データのそれぞれを、所定の変換規則に基づいて、変換文書データに変換する文書文字列変換ステップと、
前記変換された複数の文書データに含まれる文字列から、「N文字の文字列であるNグラム(Nは自然数)」を抽出する文書Nグラム抽出ステップと、
前記抽出されたNグラムと、前記変換文書データ中における当該Nグラムの出現位置と、を構成要素とする転置インデックスを生成するインデックス生成ステップと、
を備えることを特徴とする。
【発明の効果】
【0010】
本発明によれば、検索漏れを抑えるのに好適な転置インデックスの生成方法および生成装置、当該転置インデックスを用いた検索方法および検索装置、ならびに、コンピュータプログラムを提供することができる。
【図面の簡単な説明】
【0011】
【図1】本発明の実施形態に係る転置インデックスの生成装置の概要構成を示す図である。
【図2】本発明の実施形態に係る転置インデックスの生成装置の物理構成を示す図である。
【図3】本発明の実施形態に係る生成装置の処理の流れを示すフローチャートである。
【図4】本発明の実施形態に係る変換テーブルの構成を示す図である。
【図5】本発明の実施形態において、文書データが変換される様子を示す図である。
【図6】本発明の実施形態に係る転置インデックスの構成を示す図である。
【図7】本発明の実施形態に係る検索装置の概要構成を示す図である。
【図8】本発明の実施形態に係る検索装置の物理構成を示す図である。
【図9A】本発明の実施形態に係る検索装置の処理の流れを示す第1のフローチャートである。
【図9B】本発明の実施形態に係る検索装置の処理の流れを示す第2のフローチャートである。
【図9C】本発明の実施形態に係る検索装置の処理の流れを示す第3のフローチャートである。
【図10】本発明の実施形態において、検索文字列が変換され、そこからバイグラムが抽出される様子を示す図である。
【図11】本発明に係る検索装置の構成概要について、別の例を示す図である。
【発明を実施するための形態】
【0012】
以下、本発明の実施形態について、図面を参照して説明する。なお、以下に説明する実施形態は説明のためのものであり、本発明の範囲を制限するものではない。したがって、当業者であれば下記の各構成要素を均等なものに置換した実施形態を採用することが可能であるが、これらの実施形態も本発明の範囲に含まれる。また、以下の説明では、本発明の理解を容易にするため、重要でない公知の技術的事項の説明を適宜省略する。
【0013】
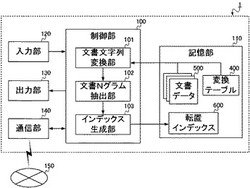
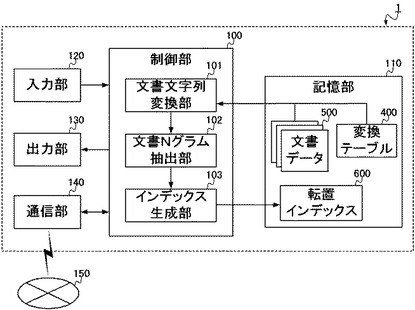
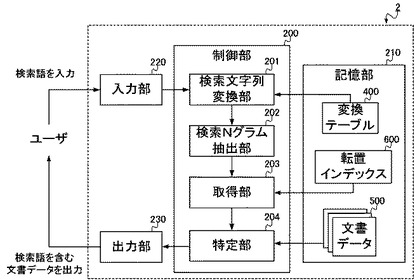
まず、本実施形態に係る転置インデックスの生成装置1が実現される情報処理装置は、図1に示されるような構成をとる。すなわち、生成装置1は、制御部100と、記憶部110と、入力部120と、出力部130と、通信部140と、を備える。一方、当該生成装置1は、物理的には図2に示されるように構成され、CPU(Central Processing Unit)151と、ROM(Read Only Memory)152と、RAM(Random Access Memory)153と、ハードディスク154と、キーボード155と、モニタ156と、DVD−ROMドライブ157と、通信装置158と、を備える。以下、図1および図2を参照して、生成装置1の構成要素の説明をする。
【0014】
制御部100は、生成装置1全体の動作を制御し、各構成要素と接続され、制御信号やデータをやりとりする。すなわち、制御部100は、記憶部110、入力部120、出力部130、通信部140と接続され、これら各部の機能を活用しながら、転置インデックスの生成処理を実行する。
【0015】
ここで制御部100は、文書文字列変換部101と、文書Nグラム抽出部102と、インデックス生成部103と、を備える。これらの各部は、詳細には後述するように、記憶部110に記憶されている複数の文書データ(文書データ群500)と変換テーブル400とを用いて、転置インデックス600を生成する処理を実行する。
【0016】
このような制御部100(文書文字列変換部101、文書Nグラム抽出部102、インデックス生成部103)は、例えばCPU151によって構成される。ここでCPU151は、命令やデータを転送するための伝送経路であるシステムバスにより各構成要素と相互に接続され、ROM152に記録されている生成装置1全体の動作制御に必要なコンピュータプログラムや各種データに従って動作する。そしてCPU151は、ROM152から読み出したコンピュータプログラムやデータ、その他処理の進行に必要なデータを、RAM153に一時的に記憶しながら、各種動作を制御する。このようにCPU151がROM152やRAM153と協働することで、制御部100は、生成装置1全体の動作を制御する。
【0017】
記憶部110は、例えばハードディスク154のような大容量外部記憶装置によって構成され、制御部100が転置インデックス600を生成する処理のために必要な各種データを記憶する。具体的にここでは、後述する検索装置によって検索対象とされる複数の文書データ(文書データ群500)、および、変換テーブル400が記憶される。また、記憶部110は、生成装置1の処理によって生成された転置インデックス600も記憶する。
【0018】
記憶部110が記憶するこれらのデータは、例えば生成装置1のDVD−ROMドライブ157を介して、あるいは通信部140によって接続されるネットワーク150を介して、外部とやり取りされる。
【0019】
入力部120は、例えばキーボード155のような入力装置によって構成され、ユーザからの入力を受け付ける。受け付けられた入力情報は、制御部100へと供給される。本実施形態では、転置インデックス600を生成するためのユーザからの命令を受け付ける。
【0020】
出力部130は、例えばモニタ156のような表示装置によって構成され、制御部100が処理を行った結果をユーザへ出力する。本実施形態では、文書文字列変換部101、文書Nグラム抽出部102、インデックス生成部103のそれぞれが行う転置インデックス600の生成処理の経過や結果がモニタ156に表示される。これにより、ユーザは当該生成処理の経過や結果についての情報を得ることができる。
【0021】
通信部140は、生成装置1をインターネット等のネットワーク150に接続し、制御部100の制御のもと、ネットワーク150を介してデータをやり取りする。このような通信部140は、例えばモデム等の適宜の通信装置158によって構成される。
【0022】
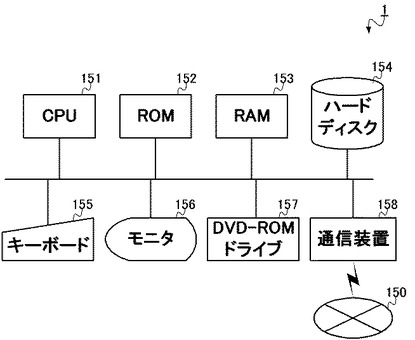
以上のように構成される生成装置1は、制御部100の制御のもと、転置インデックス600の生成処理を行う。具体的には、図3のフローチャートに示される手順で処理を実行する。
【0023】
本処理は、ユーザからの転置インデックス600を生成する旨の指示を、生成装置1の入力部120が受け付けることを契機として、開始される。すなわち、キーボード155を用いて、ユーザが転置インデックス600を生成する旨を指示することで、本処理が開始する。
【0024】
処理が開始されると、まず文書文字列変換部101が、記憶部110に記憶されている複数の文書データ(文書データ群500)のそれぞれを、同じく記憶部110に記憶されている変換テーブル400に基づいて変換する(ステップS301)。
【0025】
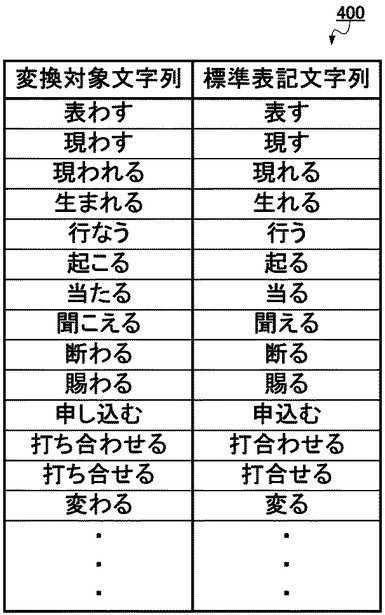
ここで変換テーブル400とは、図4に示すような構成をとるもので、文書データ群500のそれぞれの文書データに含まれる変換対象文字列と標準表記文字列との対応を付けたものである。具体的には、「表わす」と「表す」、「生まれる」と「生れる」、「打ち合せる」と「打合せる」等のように、異なる送り仮名表記が可能な語句を変換対象文字列とし、それぞれについて1つの統一した標準表記文字列と対応付けたものであり、文書データ群500内のそれぞれの文書データを構成する文字列を1つの統一した表記に変換するためのものである。すなわち、当該変換テーブル400は、検索対象である文書データ群500内に含まれるこのような変換対象文字列を抽出し、それぞれについて1つの統一した標準表記文字列を対応付けることで作成されたものである。
【0026】
このとき、標準表記文字列には、複数の可能な送り仮名表記のうち、最も文字数が小さいものにとる。この理由は、変換後の文書データ群500に含まれる文字列の文字数を、なるべく少なく抑えるためである。例えば、「表わす」と「表す」という送り仮名表記が可能な語句については、文字数の小さい「表す」を標準表記文字列とし、変換対象文字列「表わす」が当該標準表記文字列「表す」へと変換されるようにする。
【0027】
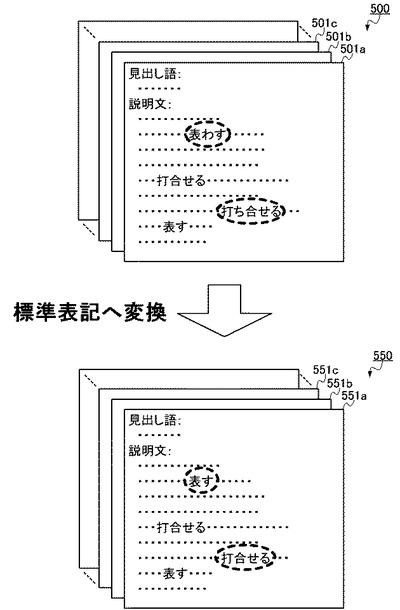
具体的に、変換テーブル400によって、文書データ群500のそれぞれの文書データに含まれる文字列は図5に示されるように変換される。ここで、文書データ群500を構成する複数の文書データ501a〜501c等は、「見出し語」と「説明文」とから構成される。すなわち、文書データ501a〜501c等は、辞書を構成する構成単位であり、当該辞書の見出しとなる1つの語句に対して1つの文書データ501が対応付けられる。そして、「見出し語」には当該見出し語を説明する「説明文」が対応付けられ、これらを合わせて1つの文書データ501を構成する。さらに、このような文書データ501が「見出し語」の数だけ存在し、全体で文書データ群500を構成する。
【0028】
文書文字列変換部101は、複数の文書データ501a〜501c等のそれぞれについて、このような「見出し語」および「説明文」を構成する文字列を、変換テーブル400に基づいて変換し、変換文書データ551a〜551c等を作成する。具体的には図5のように、「説明文」中に含まれる「表わす」や「打ち合せる」といった変換対象文字列を、それぞれ「表す」や「打合せる」といった標準表記文字列へと変換する。これにより、文書データ501aでは「表わす」と「表す」、「打ち合せる」と「打合せる」といったように表記ゆれをしていた文字列が、変換文書データ551aでは「表す」、「打合せる」といった1つの表記に統一される。
【0029】
このとき、異なる表記のうち最も文字数の小さい表記に統一されているので、変換文書データ551aは、変換前の文書データ501aよりも文字数が小さくなり、データサイズも抑制される。
【0030】
このように作成された複数の変換文書データ551a〜551c等(変換文書データ群550)は、RAM153等に一時的に保持される。
【0031】
図3のフローチャートに戻って、次に生成装置1の処理はステップS302に移行する。具体的にここでは、文書Nグラム抽出部102が、変換文書データ群550に含まれる文字列から、バイグラム(N=2のNグラム)を抽出する(ステップS302)。ここでNグラムとは、N文字の文字列(Nは自然数)を意味し、N=2のNグラム(バイグラム)とは、2文字の文字列をいう。すなわち、文書Nグラム抽出部102は、変換文書データ群550に含まれる見出し語や説明文を構成する文字列から、2文字の文字列(バイグラム)を抽出可能な数だけ抽出する。
【0032】
一般的に、文字数がX文字の文字列からは、X−N+1個のNグラムが抽出されるため、N=2の場合は、X−1個(X−2+1個)のバイグラムが抽出される。例えば、「電話機」という3文字の文字列からは、「電話」「話機」という2個(3−1個)のバイグラムが抽出され、「ボールペン」という5文字の文字列からは、「ボー」「ール」「ルペ」「ペン」という4個(5−1個)のバイグラムが抽出される。
【0033】
次に、文書Nグラム抽出部102が、抽出されたバイグラムと、変換文書データ群550中での出現位置と、を対応付ける処理を行う(ステップS303)。すなわち、抽出されたバイグラムが、抽出元の変換文書データ群550中の先頭文字から数えて何文字目に位置していたかの情報を、当該バイグラムに対応付ける。
【0034】
例えば、変換文書データ群550を構成する文字列が、「ボールペン」という5文字の文字列から始まっていたとした場合は、抽出されたバイグラムのうち、バイグラム「ボー」には1(文字目)、バイグラム「ール」には2(文字目)、バイグラム「ルペ」には3(文字目)、バイグラム「ペン」には4(文字目)、という出現位置を表す値が対応付けられる。
【0035】
これらの抽出されたバイグラムやそれらの出現位置は、RAM153等に一時的に保持される。
【0036】
次に、インデックス生成部103が、抽出されたバイグラムと、その出現位置と、を構成要素とする転置インデックス600を生成する(ステップS304)。すなわち、インデックス生成部103は、抽出されたバイグラムと、当該バイグラムのそれぞれについて上記ステップS303にて対応付けられた変換文書データ群550中で出現位置と、を構成要素として、転置インデックス600を生成する。その後、生成された転置インデックス600は、ハードディスク154のような記憶部110に記憶され、本フローチャートの処理は終了する。
【0037】
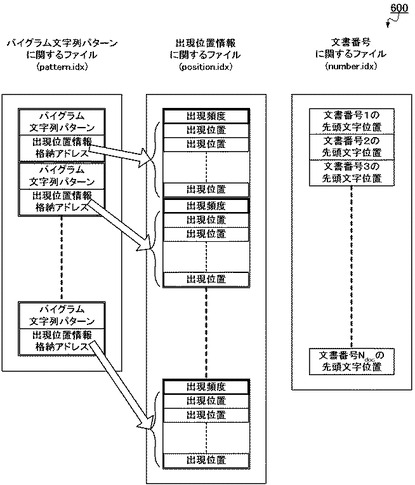
ここで生成される転置インデックス600は、具体的には図6に示されるような構成をとる。すなわち、本図のように、変換文書データ群550から抽出されたバイグラムは、バイグラム文字列パターンに関するファイル(pattern.idx)に格納される。ここで格納されたバイグラムのそれぞれには、その出現位置の情報が格納されているアドレス情報が付加される。この出現位置情報格納アドレスが示す先は、出現位置情報に関するファイル(position.idx)に格納されている出現位置の情報へとつながっており、それぞれのバイグラムが変換文書データ群550中のどの位置で出現したかが対応付けられている。
【0038】
なお、各バイグラムは、変換文書データ群550中に複数回出現することが通常想定されるため、本図のように、1個のバイグラムに対して複数の出現位置が対応付けられて格納される。
【0039】
また、インデックス生成部103は、本図での出現位置情報に関するファイル(position.idx)のように、出現頻度の情報もさらに構成要素として、転置インデックス600を生成する。ここで出現頻度とは、各バイグラムが変換文書データ群550中に何度出現したかの度合を表すものであり、後述する当該転置インデックス600を用いた検索処理において、処理を高速化するために使用されるものである。具体的に当該出現頻度として、各バイグラムに対応付けられた出現位置の個数が表される。すなわち、変換文書データ群550中でより何度も出現したバイグラムほど、付与される出現頻度の値はより大きな値になる。
【0040】
ここでさらに、インデックス生成部103は、文書番号と当該文書番号についての先頭文字位置とを対応付けた文書番号に関するファイル(number.idx)もあわせて構成要素として、転置インデックス600を生成する。格納されたバイグラムの出現位置が、変換テーブル400によって変換される前の複数の文書データ501a〜501c等のうち、どの文書データ501中であるのかを対応付けるためである。
【0041】
ここで格納される文書番号とは、いずれかの文書データ501とそれが変換された変換文書データ551に対応するものである。具体的には、文書番号1は文書データ501aおよびそれが変換された変換文書データ551aに対応し、文書番号2は文書データ501bおよびそれが変換された変換文書データ551bに対応し、文書番号3は文書データ501cおよびそれが変換された変換文書データ551cに対応する。
【0042】
また、先頭文字位置とは、変換文書データ群550の先頭文字から数えた変換文書データ551の先頭文字の位置である。例えば、文書データ1〜3に相当する変換文書データ551a,551b,551cに含まれる文字列が、それぞれA文字、B文字、C文字の文字数であるとすると、文書番号1の先頭文字位置は1(文字目)となり、文書番号2の先頭文字位置はA+1(文字目)となり、文書番号3の先頭文字位置はA+B+1(文字目)となる。このように、文書データ501あるいは変換文書データ551の個数(Ndoc個)まで文書番号が付けられ、それぞれの文書番号には変換文書データ群550の先頭文字から数えた位置の値が対応付けられる。
【0043】
このような対応関係により、バイグラムの出現位置のそれぞれが、複数の文書データ501a〜501c等のうちのどの文書データ501内に相当するのかを取得可能となる。
【0044】
以上のような構成により、本実施形態の生成装置1は、文書データ群500に含まれる複数の送り仮名表記を伴う語句を1つの統一した標準表記文字列へと変換した変換文書データ群550を作成し、その上で変換文書データ群550に含まれるバイグラムを単位とした転置インデックス600を生成する。当該転置インデックス600を用いることにより、検索漏れを抑制することができる検索方法および検索装置を提供することができる。これは、同一の語句に複数の表記が可能なことが多く、さらに単語間が明示的に区切られない日本語の検索処理に対して、特に効果的である。
【0045】
さらにその際、複数の送り仮名表記のうち文字数が最小となる表記へと変換することで、生成される転置インデックス600のデータサイズを抑制することができる。これは、後述するように、電子辞書のような使用可能なデータ容量が限られた環境にある小型の情報機器において、効率的な検索処理を実現するのに効果的である。
【0046】
本発明では、上記のような転置インデックス600の生成装置1、およびそれを用いた転置インデックス600の生成方法に加え、当該生成された転置インデックス600を用いて、文書データ群500を検索対象とした検索を行う検索装置、およびそれを用いた検索方法を提供する。
【0047】
ここで検索装置は、通常は上記転置インデックスの生成装置1とは異なる情報処理装置によって実現される。具体的に本実施形態では、検索装置として、電子辞書等の機能を備える小型の情報処理装置を想定して説明する。すなわち、検索対象である文書データ群500(複数の文書データ501a〜501c等)についての転置インデックス600の生成については、あらかじめ上記図1および図2に示されたような一般的な情報処理装置において行われ、一方で当該生成された転置インデックス600を用いた文書データ群500の検索については、生成装置1とは異なる情報処理装置、すなわち電子辞書等の小型の情報処理装置において実現される。
【0048】
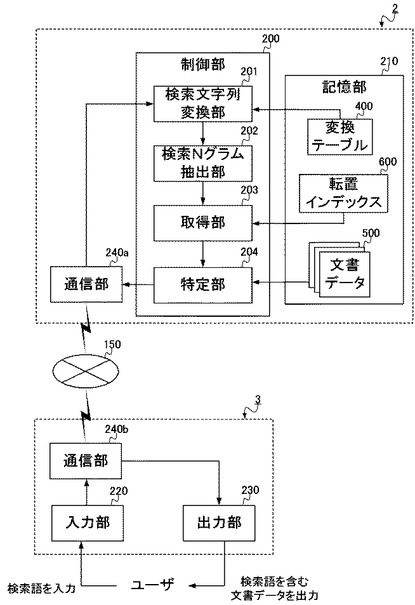
このような検索装置2として、その構成は図7に示されるようなものになる。すなわち検索装置2は、制御部200と、記憶部210と、入力部220と、出力部230と、を備える。一方、当該検索装置2は、物理的には図8に示されるように構成され、CPU251と、ROM252と、RAM253と、キーボード255と、モニタ256と、を備える。以下、図7および図8を参照して、検索装置2の構成要素の説明をする。
【0049】
制御部200は、検索装置2全体の動作を制御し、各構成要素と接続され、制御信号やデータをやりとりする。すなわち、制御部200は、記憶部210、入力部220、出力部230と接続され、これら各部の機能を活用しながら、検索処理を実行する。
【0050】
ここで制御部200は、検索文字列変換部201と、検索Nグラム抽出部202と、取得部203と、特定部204と、を備える。これらの各部は、詳細には後述するように、記憶部210に記憶されている変換テーブル400と転置インデックス600を用いて、文書データ群500(複数の文書データ501a〜501c等)のうちから検索語を含む文書データを特定する処理を実行する。
【0051】
このような制御部200(検索文字列変換部201、検索Nグラム抽出部202、取得部203、特定部204)は、例えばCPU251によって構成される。ここでCPU251は、基本的には生成装置1におけるCPU151と同様、命令やデータを転送するための伝送経路であるシステムバスにより各構成要素と相互に接続され、ROM252に記録されている検索装置2全体の動作制御に必要なコンピュータプログラムや各種データに従って動作し、さらにROM252から読み出したコンピュータプログラムやデータ、その他処理の進行に必要なデータを、RAM253に一時的に記憶しながら、各種動作を制御する。このようにCPU251がROM252やRAM253と協働することで、制御部200は、検索装置2全体の動作を制御する。
【0052】
記憶部210は、例えば検索装置2内に備えられたROM252のような読出し専用の記憶媒体によって構成され、制御部200が検索処理に必要な各種データを記憶する。具体的にここでは、検索対象とされる文書データ群500、変換テーブル400、および転置インデックス600が記憶される。
【0053】
これら文書データ群500および変換テーブル400は、上記生成装置1の記憶部110に記憶された文書データ群500および変換テーブル400と同一のものであり、また転置インデックス600は、上記生成装置1が、これら文書データ群500および変換テーブル400から生成した転置インデックス600と同一のものである。
【0054】
入力部220は、例えばキーボード255のような入力装置によって構成され、ユーザからの入力を受け付ける。具体的にここでは、ユーザからの検索語を受け付ける。受け付けられた検索語は、制御部200の検索文字列変換部201へと供給され、当該検索語の文字列を含む文書データ501を検索する処理に用いられる。
【0055】
出力部230は、例えばモニタ256のような表示装置によって構成され、制御部200が処理を行った結果をユーザへ出力する。具体的にここでは、ユーザが入力した検索語を含む文書データ501を、検索結果としてモニタ256に表示することで、当該ユーザへと出力する。これにより、ユーザは、自身が入力した検索語を含む文書データ501を出力結果として取得し、種々に利用することができるようになる。
【0056】
なお、入力部220と出力部230は、タッチパネル等のような入力装置と出力装置が組み合わされた装置によって構成されてもよい。この場合には、タッチパネルに内蔵されたタッチセンサ等からなる位置入力装置が入力部220を、液晶ディスプレイ等からなる表示装置が出力部230を、それぞれ構成する。
【0057】
以上のように構成される検索装置2は、制御部200の制御のもと、検索処理を行う。具体的には、図9A〜図9Cのフローチャートに示される手順で処理を実行する。
【0058】
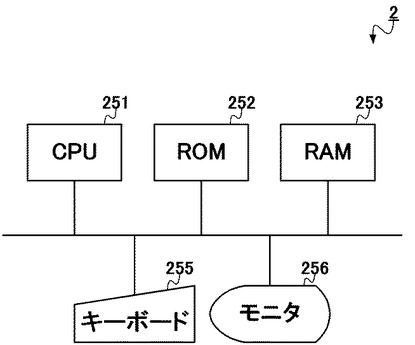
本処理は、ユーザから入力された検索語を、検索装置2の入力部220が受け付けることを契機として、開始される。すなわち、キーボード255を用いて、ユーザが所望の検索語を入力し、検索する旨を指示することで、本処理が開始する。
【0059】
なお、検索装置2は、一般的な情報機器において実現されている検索と同様に、ユーザから複数の検索語を受け付け、それらの論理積や論理和等の各種演算処理を施したものについての検索を行うことができる。以下、本フローチャートでは、複数の検索語が受け付けられ、それらの論理積をとった検索処理が行われることを想定して説明する。
【0060】
処理が開始されると、まず検索文字列変換部201が、ユーザから入力された検索語を、変換テーブル400に基づいて変換する(ステップS901)。ここで用いられる変換テーブル400は、上記生成装置1が転置インデックス600を生成する際に用いられたものと同一なものであり、ここでは当該変換テーブル400は、検索装置2内の記憶部210に記憶される。そのため検索文字列変換部201は、当該記憶部210内の変換テーブル400にアクセスして、検索語の変換処理を行う。
【0061】
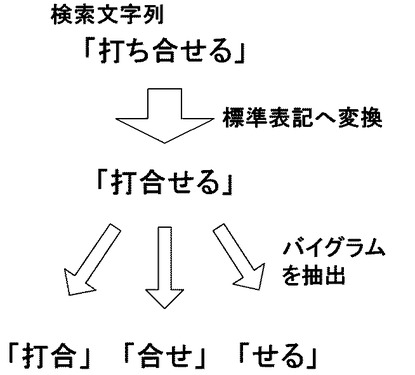
具体的に、変換テーブル400は、上記図4に示されるように、複数の送り仮名表記が可能な語句のそれぞれを、1つの統一した標準表記に変換するためのものである。すなわち、検索語を構成する文字列(検索文字列)に、「表わす」と「表す」、「生まれる」と「生れる」、「打ち合せる」と「打合せる」等のような複数の送り仮名表記が可能な語句が含まれていた場合、これらを1つの統一した標準表記へと変換する。例えば、検索語が、図10に示されるように「打ち合せる」という文字列であった場合、変換テーブル400に基づいて、「打合せる」という標準表記文字列へと変換される。
【0062】
図9Aのフローチャートに戻って、次に、検索Nグラム抽出部202が、変換された検索語からバイグラムを抽出する(ステップS902)。すなわち、変換された検索語を構成する文字列(変換検索文字列)から、2文字の文字列であるバイグラムを抽出する。具体的に、図10のように変換された検索語が「打合せる」という文字列であった場合は、「打合」「合せ」「せる」という3個のバイグラムが抽出される。
【0063】
図9Aのフローチャートに戻って、次に制御部200が、入力部220がユーザから受け付けた全ての検索語が処理されたか否かが判定する(ステップS903)。すなわち、ユーザが検索語を複数入力した場合、入力された全ての検索語に対してステップS901〜S902の処理を行うため、ここで全ての検索語が処理されたか否かが判定される。入力された検索語が1語であれば、ここでの判定は常にYESとなる。
【0064】
全ての検索語が処理されていなければ(ステップS903;NO)、処理はステップS901へと戻り、未処理の検索語に対し、ステップS901〜S902の処理を再度行う。すなわち、未処理の検索語を変換テーブル400に基づいて変換し、当該変換された検索語からバイグラムを抽出する。
【0065】
このようにして全ての検索語が処理されると(ステップS903;YES)、処理はステップS904へと移行する。そしてここでは、取得部203が、転置インデックス600から、抽出された各バイグラムの出現頻度を取得する(ステップS904)。ここで転置インデックス600は、上記生成装置1によって生成されたものであり、上記図6のような構成をとる。ここでは転置インデックス600は、検索装置2の記憶部210に記憶されており、取得部203が、当該記憶部210内の転置インデックス600にアクセスして、処理を行う。
【0066】
具体的にここで取得部203は、転置インデックス600のバイグラム文字列パターンに関するファイル(pattern.idx)において抽出された各バイグラムに相当するものに着目し、それらが指し示す出現位置情報に関するファイル(position.idx)内の格納アドレスにある出現頻度の情報を取得する。
【0067】
出現頻度が取得されると、次に制御部200は、各検索語について、最少出現頻度を導出する(ステップS905)。例えば、上記の例のように「打合」「合せ」「せる」という3個のバイグラムが抽出されている場合には、これら3個のバイグラムの出現頻度を比較して、最少のものが導出されることになる。検索語が複数ある場合には、この導出が検索語ごとに行われ、検索語の数だけ最少出現頻度が導出される。
【0068】
さらに制御部200は、導出された最少出現頻度が最も小さい検索語を基準検索語とし、それ以外を検証検索語とする(ステップS906)。すなわち、検索語が複数存在する場合に、各検索語について導出された最少出現頻度を比較し、最も小さい最少出現頻度を有する検索語(標準表記に変換された検索語)を基準検索語とし、それ以外の検索語(標準表記に変換された検索語)を検証検索語とする。なお、検索語が1語の場合は、当該検索語(標準表記に変換された検索語)が基準検索語とされ、検証検索語は存在しないことになる。
【0069】
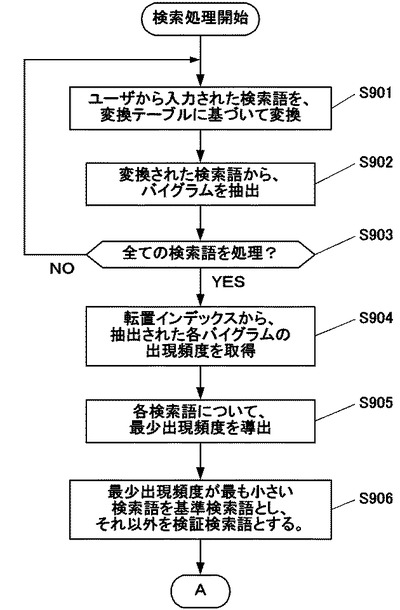
ここから検索装置2の処理は、図9Bのフローチャートへと移る。ここではまず、取得部203が、転置インデックス600から、基準検索語から抽出された各バイグラムの出現位置を取得する(ステップS907)。すなわち取得部203は、記憶部210に記憶されている転置インデックス600にアクセスし、出現位置情報に関するファイル(position.idx)内に格納されている各バイグラムの出現位置を取得する。例えば、基準検索語から抽出されたバイグラムが、上記の例のように「打合」「合せ」「せる」という3個のバイグラムである場合には、これらのバイグラムが変換文書データ群550(複数の変換文書データ551a〜551c等)内において出現する位置が取得される。
【0070】
そして、検索装置2の特定部204が、取得された出現位置に連続性があるか否かを判定する(ステップS908)。すなわちここで特定部204は、各バイグラムについて取得された出現位置が、これらが抽出された元である基準検索語を構成するように連続しているか否か、を評価する。例えば、基準検索語「打合せる」から「打合」「合せ」「せる」という3個のバイグラムが抽出された場合には、これら3個のバイグラムに対応付けられた出現位置のうち、それぞれが基準検索語を構成するように1文字ずつずれた値をもつ出現位置があるか否かが評価される。
【0071】
連続性がないと判定された場合(ステップS908;NO)、処理はステップS907へと戻る。すなわち、基準検索語を構成するような連続性がない出現位置にあるバイグラムは、変換文書データ551内において基準検索語を構成するものではなく、それ以外の語句を構成するものであるため、ここでは他の出現位置を取得するためステップS907の処理を再度行う。
【0072】
なお、転置インデックス600から取得されたバイグラムの出現位置のすべてについて、このような連続性を有するものがないと評価された場合は、複数の変換文書データ551a〜551c等のいずれにも基準検索語が含まれない、すなわち入力された検索語が複数の文書データ501a〜501c等のいずれにも含まれないと判断することができる。そのためこの場合は、検索装置2の処理は当該フローチャートを抜け、出力部230がユーザに所望の検索語を含む文書データ501が見つからなかった旨を表示する等した上で、終了する。
【0073】
一方、連続性があると判定された場合(ステップS908;YES)、処理はステップS909へと移行し、特定部204が、連続性があると判定された出現位置から出現候補文書番号を導出する(ステップS909)。すなわちここでの処理は、連続性により基準検索語が存在すると判断された出現位置が、複数の変換文書データ551a〜551c等のうちどれに含まれるのかを特定する処理に相当する。
【0074】
そのため特定部204が、記憶部210に記憶されている転置インデックス600にアクセスし、文書番号に関するファイル(number.idx)に格納された文書番号とその先頭文字位置との対応関係に着目する。そして、当該連続性があると判定された出現位置に対応する文書番号、すなわち、先頭文字位置が当該出現位置以下であり、かつ次の文書番号の先頭文字位置が当該出現位置より大きいような文書番号を取得し、出現候補文書番号とする。
【0075】
出現候補文書番号が導出されると、次に制御部200は、入力された検索語が2個以上か否かを判定する(ステップS910)。入力された検索語が2個以上の場合(ステップS910;YES)、処理は図9Cのフローチャートへと移り、検証検索語についての処理を行う。
【0076】
一方で、入力された検索語が1個の場合は(ステップS910;NO)、検証検索語が存在せず、ステップS909で導出された基準検索語を含む出現候補文書番号がそのまま所望の文書データ501に対応するものであるため、出力部230が、当該出現候補文書番号に対応する文書データ501を検索結果として出力する(ステップS911)。すなわちここでは、ユーザに入力された1語の検索語を含む文書データ501が1個見つかったことになり、検索装置2のモニタ256に表示される等により、当該文書データ501がユーザへと出力される。その後、処理は後述するステップS918へと移行し、検索語を含む文書データ501が文書データ群500中にさらにあるか否かを調べる処理を行う。
【0077】
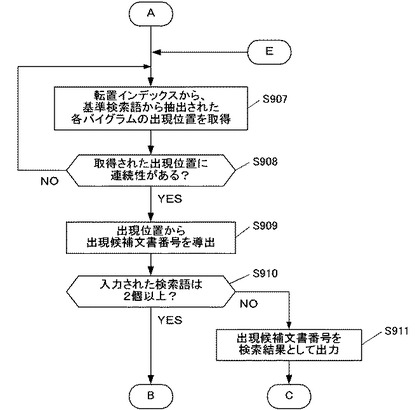
ここから検索装置2の処理は、図9Cのフローチャートへと移る。本図では主に、入力された検索語が2個以上の場合(ステップS910;YES)における検証検索語についての処理が行われる。すなわち、上記ステップS909において基準検索語を含む変換文書データ551を示す出現候補文書番号が導出されているため、当該変換文書データ551がさらに検証検索語も含んでいるか否かが調べられる。
【0078】
ここではまず、取得部203が、検証検索語のバイグラムのうち、最少出現頻度を有するバイグラムの出現位置を、転置インデックス600から取得する(ステップS912)。すなわちここで取得部203は、検証検索語が出現候補文書番号に対応する変換文書データ551に含まれるか否かを判定するため、当該検証検索語から抽出されたバイグラムの出現位置を、記憶部210内の転置インデックス600から取得する。
【0079】
そしてこのとき、検証検索語から抽出されたバイグラムのうち、最少出現頻度を有するバイグラムが、まず着目される。なぜなら、出現頻度が少ない、すなわち転置インデックス600に格納されている出現位置の個数が少ないバイグラムに着目した方が、この後の出現位置についての文書データの特定および連続性評価の処理を行う回数を減らすことができ、検索処理の高速化につながるからである。すなわちここでは、複数のバイグラムが検証検索語から抽出された場合に、上記ステップS905において導出された最少出現頻度を有するバイグラムについて、出現位置が取得される。このとき、当該最少出現頻度を有するバイグラムについて複数の出現位置がある場合には、出現位置の値が最小のものがまず取得される。
【0080】
そしてこの後、特定部204が、当該取得された出現位置が出現候補文書番号の先頭文字位置以上か否かを判定する(ステップS913)。先頭文字位置以上でなければ(ステップS913;NO)、取得されたバイグラムの出現位置が、出現候補文書番号に対応する変換文書データ551内に含まれていないと判断できるため、処理はステップS912へと戻り、最少出現頻度を有するバイグラムについての出現位置が改めて取得される。すなわち、当該最少出現頻度を有するバイグラムについて、次に出現位置の値が小さなものが取得され、再び当該取得された出現位置が、出現候補文書番号の先頭文字位置以上か否かが判定される。
【0081】
一方、先頭文字位置以上であれば(ステップS913;YES)、引き続いて特定部204が、当該取得された出現位置が出現候補文書番号の最終文字位置以下か否かを判定する(ステップS914)。最終文字位置以下でなければ(ステップS914;NO)、当該出現候補文書番号に対応する変換文書データ551内には検証検索語から抽出されたバイグラムが含まれておらず、従って当該検証検索語自体も含まれていないと判断できるため、処理は検証検索語についての処理を抜け、後述するステップS918へと移行する。
【0082】
一方で、最終文字位置以下であった場合は(ステップS914;YES)、着目された最少出現頻度を有するバイグラムは、当該出現候補文書番号に対応する変換文書データ551内に含まれていることになる。そのためこのとき、当該バイグラムだけでなく、検証検索語自体も当該変換文書データ551内に含まれているか否かを判定するため、特定部204はさらに、出現位置が連続しているか否かを判定する(ステップS915)。すなわち、最少出現頻度を有するバイグラムだけでなく、検証検索語から抽出されたその他のバイグラムにも着目し、取得部203が転置インデックス600からこれらの出現位置を取得した上で、特定部204が、各バイグラムについて取得された出現位置が検証検索語を構成するように連続しているか否かを判定する。
【0083】
出現位置が連続していない場合には(ステップS915;NO)、変換文書データ551内には当該検証検索語が含まれていないと判断され、後述するステップS918へと移行する。一方、出現位置が連続している場合には(ステップS915;YES)、変換文書データ551内には当該検証検索語が含まれていると判断できる。この時点では、基準検索語と当該検証検索語の2語を含む変換文書データ551が特定されたことになる。
【0084】
さらに本フローチャートでは、制御部200が、全ての検証検索語を処理したか否かを判定する(ステップS916)。すなわち、ユーザが3語以上の検索語を入力していた場合は、ここでは全ての検証検索語が処理されていないため(ステップS916;NO)、処理はステップS912へと戻り、未処理の検証検索語について当該出現候補文書番号に対応する変換文書データ551に含まれるか否かの処理が行われる。
【0085】
一方、ユーザが2語しか検索語を入力していない場合、あるいは3語以上入力していた場合でも、全ての検証検索語について処理がされ(ステップS916;YES)、当該出現候補文書番号に対応する変換文書データ551に含まれると判断されると、出力部230が、対応する文書データ501を検索結果として出力する(ステップS917)。すなわちここでは、ユーザに入力された複数の検索語を含む文書データ501が1個見つかったことになり、検索装置2のモニタ256に表示される等により、当該文書データ501がユーザへと出力される。
【0086】
その後、検索装置2の処理はステップS918へと移行し、制御部200が、基準検索語について、未処理の出現位置があるか否かを判定する(ステップS918)。未処理の出現位置がある場合(ステップS918;YES)、処理はステップS907へと戻る。すなわち、基準検索語から抽出された各バイグラムの出現位置のうち、未処理のものを転置インデックス600から取得し、当該取得された出現位置について、上述したステップS908〜S917までの処理を繰り返す。これにより、基準検索語および検証検索語が含まれる変換文書データ551が、他に存在するかが調べられ、存在した場合には、対応する文書データ501が出力部230によってユーザへと出力される。
【0087】
一方、最終的に、基準検索語について未処理の出現位置がなくなった場合(ステップS918;NO)、検索処理は終了する。
【0088】
以上のような構成により、本実施形態の検索装置2は、検索文字列に含まれる複数の送り仮名表記を伴う文字列を1つの統一した標準表記文字列へと変換した上で、同じく標準表記へと変換された変換文書データ群550のうち、当該変換された検索文字列がどの変換文書データ551に含まれるかを特定する。これにより、同一の語句について複数の表記で記載されている文書について、検索漏れを抑制して検索することができる。
【0089】
さらにその際、検索に使用される転置インデックス600は、複数の送り仮名表記のうち文字数が最小となる表記へと変換されたものについて生成されたものであるため、データサイズが抑制されている。そのため、特に電子辞書のような使用可能なデータ容量が限られた環境にある小型の情報機器において、効率的な検索処理を実現できる。
【0090】
なお、上記実施形態は一例であり、本発明の適用範囲はこれに限られない。すなわち、種々の応用が可能であり、あらゆる実施の形態が本発明の範囲に含まれる。
【0091】
例えば、上記実施形態では、検索装置2は、ROM252のような記憶部210内に文書データ群500等を記憶した。しかしこれに限られず、検索装置2は、ハードディスク等の大容量記憶装置やDVD−ROMドライブを備え、文書データ群500等がハードディスクやDVD−ROM等に記憶されるようにしてもよい。あるいは、検索装置2は、ネットワークに接続され、文書データ群500等がネットワーク上に存在するようにしてもよい。
【0092】
また、上記実施形態では、検索装置2は、ユーザが検索語を入力する入力部220や検索結果を出力する出力部230は、制御部200や記憶部210と同一の装置内に存在した。しかしこれに限られず、入力部220と出力部230は、検索装置2の外部にあってもよい。すなわち、例えば図11に示すように、検索装置2は入力部220と出力部230を備えず、これらを備える端末装置3とネットワーク150を介して接続されるようにし、オンライン型の電子辞書のような情報機器として構成するようにしてもよい。
【0093】
このとき、検索装置2と端末装置3は、それぞれが備える通信部240a,240bにより、ネットワーク150を介して互いにデータを通信しあう。すなわち、端末装置3のユーザが入力した検索語は、検索装置2へと送信され、制御部200により検索処理が実行される。その後、検索結果として特定された文書データ501の情報が再び端末装置3へと送信され、端末装置3のユーザへと出力される。このような構成をとることで、検索装置2内の文書データ群500等を一括して管理して複数のユーザに利用できるようになり、またユーザ側の端末装置3は、文書データ群500等を保持する必要がないため、データサイズを抑えることができるといった利点がある。
【0094】
また、上記実施形態では、検索装置2として電子辞書のような小型の情報処理装置を想定して説明した。しかしこれに限られず、検索装置2は、ビジネス用・家庭用の一般的なコンピュータ装置や、携帯電話等の他の情報機器であってもよい。また、電子辞書における検索に限られず、種々の電子データを検索するものであってもよい。例えば、一般的なコンピュータ装置において、ハードディスク等の大容量記憶装置やDVD−ROM等に記憶された電子ファイルのうちから、所望の検索語を含む電子ファイルを検索するものであってもよい。あるいは、ネットワークと接続され、ネットワーク上に存在するウェブページを検索するものであってもよい。
【0095】
また、生成装置1について、上記実施形態での生成装置1は、ハードディスク154のような記憶部110に記憶されている文書データ群500および変換テーブル400から転置インデックス600を生成し、当該生成された転置インデックス600を記憶部110に記憶した。しかし、これら文書データ群500等は、生成装置1内に備えられた記憶部110に記憶されることに限られず、通信部140を介して接続されるネットワーク150上に存在していてもよいし、あるいはDVD−ROMドライブ157に搭載されるDVD−ROM内に記憶されていてもよい。
【0096】
また、上記実施形態では、異なる送り仮名表記が可能な語句について、1つの統一した表記に変換した。しかし送り仮名表記に限られず、異なる表記が可能なために表記ゆれを起こしやすい語句について、1つの統一した表記に変換するものであってもよい。例えば、「ユーザ」と「ユーザー」、「インターフェース」と「インターフェイス」等のように、異なるカタカナ表記が可能な語句を統一するものであってもよい。
【0097】
また、上記実施形態では、文書データ群500を構成する複数の文書データ501は、「見出し語」と「説明文」とから構成された。しかしこれらに限られず、様々な要素から構成されてもよい。例えば、「見出し語」を説明するための図や表を有するものであってもよい。あるいは、辞書における検索以外の一般的な電子ファイル等の検索では、このような「見出し語」と「説明文」といった構成要素に限らず、文書データ501は様々な形式で文字列データを有していてもよい。
【0098】
また、上記実施形態では、転置インデックス600の構成単位として、N=2のNグラム(バイグラム)を採用した。しかしこれに限られず、Nが他の値のNグラムを、転置インデックス600の構成単位としてもよい。例えば、モノグラム(N=1のNグラム)であってもよいし、トリグラム(N=3のNグラム)、あるいはそれ以外のNの値を有するNグラムであってもよい。
【0099】
なお、本発明に係る機能を実現するための構成を予め備えた転置インデックスの生成装置および当該転置インデックスを用いた検索装置として提供できることはもとより、プログラムの適用により、既存のパーソナルコンピュータや情報端末機器等を、本発明に係る生成装置および検索装置として機能させることもできる。すなわち、上記実施形態で例示した生成装置1および検索装置2による各機能構成を実現させるための生成プログラムまたは検索プログラムを、既存のパーソナルコンピュータや情報端末機器等を制御するCPU等が実行できるように適用することで、それぞれ本発明に係る生成装置1および検索装置2として機能させることができる。また、本発明に係る転置インデックスの生成方法および当該転置インデックスを用いた検索方法は、それぞれ生成装置1および検索装置2を用いて実施できる。
【0100】
また、このようなプログラムの適用方法は任意であり、例えば、CD−ROMやDVD−ROM、メモリカードなどのコンピュータ読み取り可能な記憶媒体に格納して適用できる他、例えば、インターネットなどの通信媒体を介して適用することもできる。
【0101】
以上、本発明の好ましい実施形態について説明したが、本発明は係る特定の実施形態に限定されるものではなく、本発明には、特許請求の範囲に記載された発明とその均等の範囲が含まれる。以下に、本願出願の当初の特許請求の範囲に記載された発明を付記する。
【0102】
(付記1)
複数の文書データのそれぞれを、所定の変換規則に基づいて、変換文書データに変換する文書文字列変換ステップと、
前記変換された複数の文書データに含まれる文字列から、「N文字の文字列であるNグラム(Nは自然数)」を抽出する文書Nグラム抽出ステップと、
前記抽出されたNグラムと、前記変換文書データ中における当該Nグラムの出現位置と、を構成要素とする転置インデックスを生成するインデックス生成ステップと、
を備えることを特徴とする転置インデックスの生成方法。
【0103】
(付記2)
前記インデックス生成ステップでは、前記出現位置と前記複数の文書データのうち当該出現位置を含む文書データとの対応関係をさらに構成要素として、転置インデックスを生成する、
ことを特徴とする付記1に記載の転置インデックスの生成方法。
【0104】
(付記3)
前記所定の変換規則とは、複数の表記を伴う語句のそれぞれを、当該複数の表記のうちのいずれかの表記に変換する規則である、
ことを特徴とする付記1または2に記載の転置インデックスの生成方法。
【0105】
(付記4)
前記所定の変換規則とは、複数の表記を伴う語句のそれぞれを、当該複数の表記のうち最小文字数の表記に変換する規則である、
ことを特徴とする付記3に記載の転置インデックスの生成方法。
【0106】
(付記5)
前記複数の表記を伴う語句とは、複数の送り仮名表記を伴う語句である、
ことを特徴とする付記3または4に記載の転置インデックスの生成方法。
【0107】
(付記6)
付記1から5のいずれか1つに記載の生成方法によって生成された転置インデックスを用いる検索方法であって、
検索文字列を、前記所定の変換規則に基づいて、変換検索文字列に変換する検索文字列変換ステップと、
前記変換検索文字列から、Nグラムを抽出する検索Nグラム抽出ステップと、
前記変換検索文字列から抽出されたNグラムに対応付けられた出現位置を、前記転置インデックスから取得する取得ステップと、
前記取得された出現位置に基づいて、前記複数の文書データのうちから、前記検索文字列を含む文書データを特定する特定ステップと、
を備えることを特徴とする検索方法。
【0108】
(付記7)
複数の文書データのそれぞれを、所定の変換規則に基づいて、変換文書データに変換する文書文字列変換手段と、
前記変換された複数の文書データに含まれる文字列から、「N文字の文字列であるNグラム(Nは自然数)」を抽出する文書Nグラム抽出手段と、
前記抽出されたNグラムと、前記変換文書データ中における当該Nグラムの出現位置と、を構成要素とする転置インデックスを生成するインデックス生成手段と、
を備えることを特徴とする転置インデックスの生成装置。
【0109】
(付記8)
付記1から5のいずれか1つに記載の生成方法によって生成された転置インデックスを用いる検索装置であって、
検索文字列を、前記所定の変換規則に基づいて、変換検索文字列に変換する検索文字列変換手段と、
前記変換検索文字列から、Nグラムを抽出する検索Nグラム抽出手段と、
前記変換検索文字列から抽出されたNグラムに対応付けられた出現位置を、前記転置インデックスから取得する取得手段と、
前記取得された出現位置に基づいて、前記複数の文書データのうちから、前記検索文字列を含む文書データを特定する特定手段と、
を備えることを特徴とする検索装置。
【0110】
(付記9)
コンピュータを、
複数の文書データのそれぞれを、所定の変換規則に基づいて、変換文書データに変換する文書文字列変換手段、
前記変換された複数の文書データに含まれる文字列から、「N文字の文字列であるNグラム(Nは自然数)」を抽出する文書Nグラム抽出手段、
前記抽出されたNグラムと、前記変換文書データ中における当該Nグラムの出現位置と、を構成要素とする転置インデックスを生成するインデックス生成手段、
として機能させることを特徴とするコンピュータプログラム。
【0111】
(付記10)
コンピュータを、
付記1から5のいずれか1つに記載の生成方法によって生成された転置インデックスを用いる検索装置として機能させるコンピュータプログラムであって、
前記コンピュータを、
検索文字列を、前記所定の変換規則に基づいて、変換検索文字列に変換する検索文字列変換手段、
前記変換検索文字列から、Nグラムを抽出する検索Nグラム抽出手段、
前記変換検索文字列から抽出されたNグラムに対応付けられた出現位置を、前記転置インデックスから取得する取得手段、
前記取得された出現位置に基づいて、前記複数の文書データのうちから、前記検索文字列を含む文書データを特定する特定手段、
として機能させることを特徴とするコンピュータプログラム。
【符号の説明】
【0112】
1…生成装置、2…検索装置、3…端末装置、100…制御部、101…文書文字列変換部、102…文書Nグラム抽出部、103…インデックス生成部、110…記憶部、120…入力部、130…出力部、140…通信部、150…ネットワーク、151…CPU、152…ROM、153…RAM、154…ハードディスク、155…キーボード、156…モニタ、157…DVD−ROMドライブ、158…通信装置、200…制御部、201…検索文字列変換部、202…検索Nグラム抽出部、203…取得部、204…特定部、210…記憶部、220…入力部、230…出力部、240a,240b…通信部、251…CPU、252…ROM、253…RAM、255…キーボード、256…モニタ、400…変換テーブル、500…文書データ群、501a,501b,501c…文書データ、550…変換文書データ群、551a,551b,551c…変換文書データ、600…転置インデックス
【技術分野】
【0001】
本発明は、Nグラム検索に関し、とくに検索漏れを抑えるのに好適な転置インデックスの生成方法および生成装置、当該転置インデックスを用いた検索方法および検索装置、ならびにコンピュータプログラムに関する。
【背景技術】
【0002】
文書の電子化の増大に伴い、これまでに蓄積されてきた大量の文書群から所望の文書を見つけ出す検索技術の重要性が高まっている。
【0003】
大量の文書群を対象とした検索では、検索処理の高速化のため、検索対象となる文書群に含まれる単語等を索引単位として、索引ファイル(以下、「転置インデックス」と呼称する。)を作成することが一般的である。あらかじめ作成された転置インデックスを検索時に用いることで、検索のたびに大量の文書群にアクセスする必要がなくなり、高速な検索処理が実現されるからである。
【0004】
ところで、日本語の文書は、極めて柔軟な表記が可能であり、同じ意味を有する単語を表記する場合でも複数の表記が存在する。例えば、「ユーザ」と「ユーザー」、「インターフェース」と「インターフェイス」といったカタカナ表記、あるいは「表わす」と「表す」、「行なう」と「行う」といった送り仮名表記等である。そのため、大量の文書群から所望の文書を検索する場合に、ユーザが検索時に入力した検索語をそのまま使用すると、その検索語と同一の表記で記述されている文書は検索することができるが、異なる表記で記述されている文書は検索することができず、検索漏れが発生してしまうという問題点がある。
【0005】
このような問題点に対し、検索漏れを防ぐための種々の技術が開発されている。例えば特許文献1および特許文献2には、検索対象の文書群についての転置インデックスを単語単位で作成する際に、表記ゆれを伴う単語を一定の規則に従って統一した表記に変換してから転置インデックスを作成する技術が開示されている。この場合、検索時には、入力された検索語を同様の規則に従って変換してから当該転置インデックスに基づいて検索を行うことで、表記ゆれによる検索漏れを抑えつつ検索することができる。
【先行技術文献】
【特許文献】
【0006】
【特許文献1】特開平7−319891号公報
【特許文献2】特開2002−73656号公報
【発明の概要】
【発明が解決しようとする課題】
【0007】
日本語の文書は、英語などの他の多くの言語と異なり、スペース等によって単語の切れ目が明示的に示されないため、転置インデックスを作成する際に、単語に分解する必要がある。そのため、表記ゆれに起因する検索漏れとともに、日本語の単語分解の精度によっては、さらなる検索漏れも生じうる。
【0008】
本発明は、以上のような課題を解決するためのものであり、検索漏れを抑えるのに好適な転置インデックスの生成方法および生成装置、当該転置インデックスを用いた検索方法および検索装置、ならびに、コンピュータプログラムを提供することを目的とする。
【課題を解決するための手段】
【0009】
上記目的を達成するため、本発明にかかる転置インデックスの生成方法は、
複数の文書データのそれぞれを、所定の変換規則に基づいて、変換文書データに変換する文書文字列変換ステップと、
前記変換された複数の文書データに含まれる文字列から、「N文字の文字列であるNグラム(Nは自然数)」を抽出する文書Nグラム抽出ステップと、
前記抽出されたNグラムと、前記変換文書データ中における当該Nグラムの出現位置と、を構成要素とする転置インデックスを生成するインデックス生成ステップと、
を備えることを特徴とする。
【発明の効果】
【0010】
本発明によれば、検索漏れを抑えるのに好適な転置インデックスの生成方法および生成装置、当該転置インデックスを用いた検索方法および検索装置、ならびに、コンピュータプログラムを提供することができる。
【図面の簡単な説明】
【0011】
【図1】本発明の実施形態に係る転置インデックスの生成装置の概要構成を示す図である。
【図2】本発明の実施形態に係る転置インデックスの生成装置の物理構成を示す図である。
【図3】本発明の実施形態に係る生成装置の処理の流れを示すフローチャートである。
【図4】本発明の実施形態に係る変換テーブルの構成を示す図である。
【図5】本発明の実施形態において、文書データが変換される様子を示す図である。
【図6】本発明の実施形態に係る転置インデックスの構成を示す図である。
【図7】本発明の実施形態に係る検索装置の概要構成を示す図である。
【図8】本発明の実施形態に係る検索装置の物理構成を示す図である。
【図9A】本発明の実施形態に係る検索装置の処理の流れを示す第1のフローチャートである。
【図9B】本発明の実施形態に係る検索装置の処理の流れを示す第2のフローチャートである。
【図9C】本発明の実施形態に係る検索装置の処理の流れを示す第3のフローチャートである。
【図10】本発明の実施形態において、検索文字列が変換され、そこからバイグラムが抽出される様子を示す図である。
【図11】本発明に係る検索装置の構成概要について、別の例を示す図である。
【発明を実施するための形態】
【0012】
以下、本発明の実施形態について、図面を参照して説明する。なお、以下に説明する実施形態は説明のためのものであり、本発明の範囲を制限するものではない。したがって、当業者であれば下記の各構成要素を均等なものに置換した実施形態を採用することが可能であるが、これらの実施形態も本発明の範囲に含まれる。また、以下の説明では、本発明の理解を容易にするため、重要でない公知の技術的事項の説明を適宜省略する。
【0013】
まず、本実施形態に係る転置インデックスの生成装置1が実現される情報処理装置は、図1に示されるような構成をとる。すなわち、生成装置1は、制御部100と、記憶部110と、入力部120と、出力部130と、通信部140と、を備える。一方、当該生成装置1は、物理的には図2に示されるように構成され、CPU(Central Processing Unit)151と、ROM(Read Only Memory)152と、RAM(Random Access Memory)153と、ハードディスク154と、キーボード155と、モニタ156と、DVD−ROMドライブ157と、通信装置158と、を備える。以下、図1および図2を参照して、生成装置1の構成要素の説明をする。
【0014】
制御部100は、生成装置1全体の動作を制御し、各構成要素と接続され、制御信号やデータをやりとりする。すなわち、制御部100は、記憶部110、入力部120、出力部130、通信部140と接続され、これら各部の機能を活用しながら、転置インデックスの生成処理を実行する。
【0015】
ここで制御部100は、文書文字列変換部101と、文書Nグラム抽出部102と、インデックス生成部103と、を備える。これらの各部は、詳細には後述するように、記憶部110に記憶されている複数の文書データ(文書データ群500)と変換テーブル400とを用いて、転置インデックス600を生成する処理を実行する。
【0016】
このような制御部100(文書文字列変換部101、文書Nグラム抽出部102、インデックス生成部103)は、例えばCPU151によって構成される。ここでCPU151は、命令やデータを転送するための伝送経路であるシステムバスにより各構成要素と相互に接続され、ROM152に記録されている生成装置1全体の動作制御に必要なコンピュータプログラムや各種データに従って動作する。そしてCPU151は、ROM152から読み出したコンピュータプログラムやデータ、その他処理の進行に必要なデータを、RAM153に一時的に記憶しながら、各種動作を制御する。このようにCPU151がROM152やRAM153と協働することで、制御部100は、生成装置1全体の動作を制御する。
【0017】
記憶部110は、例えばハードディスク154のような大容量外部記憶装置によって構成され、制御部100が転置インデックス600を生成する処理のために必要な各種データを記憶する。具体的にここでは、後述する検索装置によって検索対象とされる複数の文書データ(文書データ群500)、および、変換テーブル400が記憶される。また、記憶部110は、生成装置1の処理によって生成された転置インデックス600も記憶する。
【0018】
記憶部110が記憶するこれらのデータは、例えば生成装置1のDVD−ROMドライブ157を介して、あるいは通信部140によって接続されるネットワーク150を介して、外部とやり取りされる。
【0019】
入力部120は、例えばキーボード155のような入力装置によって構成され、ユーザからの入力を受け付ける。受け付けられた入力情報は、制御部100へと供給される。本実施形態では、転置インデックス600を生成するためのユーザからの命令を受け付ける。
【0020】
出力部130は、例えばモニタ156のような表示装置によって構成され、制御部100が処理を行った結果をユーザへ出力する。本実施形態では、文書文字列変換部101、文書Nグラム抽出部102、インデックス生成部103のそれぞれが行う転置インデックス600の生成処理の経過や結果がモニタ156に表示される。これにより、ユーザは当該生成処理の経過や結果についての情報を得ることができる。
【0021】
通信部140は、生成装置1をインターネット等のネットワーク150に接続し、制御部100の制御のもと、ネットワーク150を介してデータをやり取りする。このような通信部140は、例えばモデム等の適宜の通信装置158によって構成される。
【0022】
以上のように構成される生成装置1は、制御部100の制御のもと、転置インデックス600の生成処理を行う。具体的には、図3のフローチャートに示される手順で処理を実行する。
【0023】
本処理は、ユーザからの転置インデックス600を生成する旨の指示を、生成装置1の入力部120が受け付けることを契機として、開始される。すなわち、キーボード155を用いて、ユーザが転置インデックス600を生成する旨を指示することで、本処理が開始する。
【0024】
処理が開始されると、まず文書文字列変換部101が、記憶部110に記憶されている複数の文書データ(文書データ群500)のそれぞれを、同じく記憶部110に記憶されている変換テーブル400に基づいて変換する(ステップS301)。
【0025】
ここで変換テーブル400とは、図4に示すような構成をとるもので、文書データ群500のそれぞれの文書データに含まれる変換対象文字列と標準表記文字列との対応を付けたものである。具体的には、「表わす」と「表す」、「生まれる」と「生れる」、「打ち合せる」と「打合せる」等のように、異なる送り仮名表記が可能な語句を変換対象文字列とし、それぞれについて1つの統一した標準表記文字列と対応付けたものであり、文書データ群500内のそれぞれの文書データを構成する文字列を1つの統一した表記に変換するためのものである。すなわち、当該変換テーブル400は、検索対象である文書データ群500内に含まれるこのような変換対象文字列を抽出し、それぞれについて1つの統一した標準表記文字列を対応付けることで作成されたものである。
【0026】
このとき、標準表記文字列には、複数の可能な送り仮名表記のうち、最も文字数が小さいものにとる。この理由は、変換後の文書データ群500に含まれる文字列の文字数を、なるべく少なく抑えるためである。例えば、「表わす」と「表す」という送り仮名表記が可能な語句については、文字数の小さい「表す」を標準表記文字列とし、変換対象文字列「表わす」が当該標準表記文字列「表す」へと変換されるようにする。
【0027】
具体的に、変換テーブル400によって、文書データ群500のそれぞれの文書データに含まれる文字列は図5に示されるように変換される。ここで、文書データ群500を構成する複数の文書データ501a〜501c等は、「見出し語」と「説明文」とから構成される。すなわち、文書データ501a〜501c等は、辞書を構成する構成単位であり、当該辞書の見出しとなる1つの語句に対して1つの文書データ501が対応付けられる。そして、「見出し語」には当該見出し語を説明する「説明文」が対応付けられ、これらを合わせて1つの文書データ501を構成する。さらに、このような文書データ501が「見出し語」の数だけ存在し、全体で文書データ群500を構成する。
【0028】
文書文字列変換部101は、複数の文書データ501a〜501c等のそれぞれについて、このような「見出し語」および「説明文」を構成する文字列を、変換テーブル400に基づいて変換し、変換文書データ551a〜551c等を作成する。具体的には図5のように、「説明文」中に含まれる「表わす」や「打ち合せる」といった変換対象文字列を、それぞれ「表す」や「打合せる」といった標準表記文字列へと変換する。これにより、文書データ501aでは「表わす」と「表す」、「打ち合せる」と「打合せる」といったように表記ゆれをしていた文字列が、変換文書データ551aでは「表す」、「打合せる」といった1つの表記に統一される。
【0029】
このとき、異なる表記のうち最も文字数の小さい表記に統一されているので、変換文書データ551aは、変換前の文書データ501aよりも文字数が小さくなり、データサイズも抑制される。
【0030】
このように作成された複数の変換文書データ551a〜551c等(変換文書データ群550)は、RAM153等に一時的に保持される。
【0031】
図3のフローチャートに戻って、次に生成装置1の処理はステップS302に移行する。具体的にここでは、文書Nグラム抽出部102が、変換文書データ群550に含まれる文字列から、バイグラム(N=2のNグラム)を抽出する(ステップS302)。ここでNグラムとは、N文字の文字列(Nは自然数)を意味し、N=2のNグラム(バイグラム)とは、2文字の文字列をいう。すなわち、文書Nグラム抽出部102は、変換文書データ群550に含まれる見出し語や説明文を構成する文字列から、2文字の文字列(バイグラム)を抽出可能な数だけ抽出する。
【0032】
一般的に、文字数がX文字の文字列からは、X−N+1個のNグラムが抽出されるため、N=2の場合は、X−1個(X−2+1個)のバイグラムが抽出される。例えば、「電話機」という3文字の文字列からは、「電話」「話機」という2個(3−1個)のバイグラムが抽出され、「ボールペン」という5文字の文字列からは、「ボー」「ール」「ルペ」「ペン」という4個(5−1個)のバイグラムが抽出される。
【0033】
次に、文書Nグラム抽出部102が、抽出されたバイグラムと、変換文書データ群550中での出現位置と、を対応付ける処理を行う(ステップS303)。すなわち、抽出されたバイグラムが、抽出元の変換文書データ群550中の先頭文字から数えて何文字目に位置していたかの情報を、当該バイグラムに対応付ける。
【0034】
例えば、変換文書データ群550を構成する文字列が、「ボールペン」という5文字の文字列から始まっていたとした場合は、抽出されたバイグラムのうち、バイグラム「ボー」には1(文字目)、バイグラム「ール」には2(文字目)、バイグラム「ルペ」には3(文字目)、バイグラム「ペン」には4(文字目)、という出現位置を表す値が対応付けられる。
【0035】
これらの抽出されたバイグラムやそれらの出現位置は、RAM153等に一時的に保持される。
【0036】
次に、インデックス生成部103が、抽出されたバイグラムと、その出現位置と、を構成要素とする転置インデックス600を生成する(ステップS304)。すなわち、インデックス生成部103は、抽出されたバイグラムと、当該バイグラムのそれぞれについて上記ステップS303にて対応付けられた変換文書データ群550中で出現位置と、を構成要素として、転置インデックス600を生成する。その後、生成された転置インデックス600は、ハードディスク154のような記憶部110に記憶され、本フローチャートの処理は終了する。
【0037】
ここで生成される転置インデックス600は、具体的には図6に示されるような構成をとる。すなわち、本図のように、変換文書データ群550から抽出されたバイグラムは、バイグラム文字列パターンに関するファイル(pattern.idx)に格納される。ここで格納されたバイグラムのそれぞれには、その出現位置の情報が格納されているアドレス情報が付加される。この出現位置情報格納アドレスが示す先は、出現位置情報に関するファイル(position.idx)に格納されている出現位置の情報へとつながっており、それぞれのバイグラムが変換文書データ群550中のどの位置で出現したかが対応付けられている。
【0038】
なお、各バイグラムは、変換文書データ群550中に複数回出現することが通常想定されるため、本図のように、1個のバイグラムに対して複数の出現位置が対応付けられて格納される。
【0039】
また、インデックス生成部103は、本図での出現位置情報に関するファイル(position.idx)のように、出現頻度の情報もさらに構成要素として、転置インデックス600を生成する。ここで出現頻度とは、各バイグラムが変換文書データ群550中に何度出現したかの度合を表すものであり、後述する当該転置インデックス600を用いた検索処理において、処理を高速化するために使用されるものである。具体的に当該出現頻度として、各バイグラムに対応付けられた出現位置の個数が表される。すなわち、変換文書データ群550中でより何度も出現したバイグラムほど、付与される出現頻度の値はより大きな値になる。
【0040】
ここでさらに、インデックス生成部103は、文書番号と当該文書番号についての先頭文字位置とを対応付けた文書番号に関するファイル(number.idx)もあわせて構成要素として、転置インデックス600を生成する。格納されたバイグラムの出現位置が、変換テーブル400によって変換される前の複数の文書データ501a〜501c等のうち、どの文書データ501中であるのかを対応付けるためである。
【0041】
ここで格納される文書番号とは、いずれかの文書データ501とそれが変換された変換文書データ551に対応するものである。具体的には、文書番号1は文書データ501aおよびそれが変換された変換文書データ551aに対応し、文書番号2は文書データ501bおよびそれが変換された変換文書データ551bに対応し、文書番号3は文書データ501cおよびそれが変換された変換文書データ551cに対応する。
【0042】
また、先頭文字位置とは、変換文書データ群550の先頭文字から数えた変換文書データ551の先頭文字の位置である。例えば、文書データ1〜3に相当する変換文書データ551a,551b,551cに含まれる文字列が、それぞれA文字、B文字、C文字の文字数であるとすると、文書番号1の先頭文字位置は1(文字目)となり、文書番号2の先頭文字位置はA+1(文字目)となり、文書番号3の先頭文字位置はA+B+1(文字目)となる。このように、文書データ501あるいは変換文書データ551の個数(Ndoc個)まで文書番号が付けられ、それぞれの文書番号には変換文書データ群550の先頭文字から数えた位置の値が対応付けられる。
【0043】
このような対応関係により、バイグラムの出現位置のそれぞれが、複数の文書データ501a〜501c等のうちのどの文書データ501内に相当するのかを取得可能となる。
【0044】
以上のような構成により、本実施形態の生成装置1は、文書データ群500に含まれる複数の送り仮名表記を伴う語句を1つの統一した標準表記文字列へと変換した変換文書データ群550を作成し、その上で変換文書データ群550に含まれるバイグラムを単位とした転置インデックス600を生成する。当該転置インデックス600を用いることにより、検索漏れを抑制することができる検索方法および検索装置を提供することができる。これは、同一の語句に複数の表記が可能なことが多く、さらに単語間が明示的に区切られない日本語の検索処理に対して、特に効果的である。
【0045】
さらにその際、複数の送り仮名表記のうち文字数が最小となる表記へと変換することで、生成される転置インデックス600のデータサイズを抑制することができる。これは、後述するように、電子辞書のような使用可能なデータ容量が限られた環境にある小型の情報機器において、効率的な検索処理を実現するのに効果的である。
【0046】
本発明では、上記のような転置インデックス600の生成装置1、およびそれを用いた転置インデックス600の生成方法に加え、当該生成された転置インデックス600を用いて、文書データ群500を検索対象とした検索を行う検索装置、およびそれを用いた検索方法を提供する。
【0047】
ここで検索装置は、通常は上記転置インデックスの生成装置1とは異なる情報処理装置によって実現される。具体的に本実施形態では、検索装置として、電子辞書等の機能を備える小型の情報処理装置を想定して説明する。すなわち、検索対象である文書データ群500(複数の文書データ501a〜501c等)についての転置インデックス600の生成については、あらかじめ上記図1および図2に示されたような一般的な情報処理装置において行われ、一方で当該生成された転置インデックス600を用いた文書データ群500の検索については、生成装置1とは異なる情報処理装置、すなわち電子辞書等の小型の情報処理装置において実現される。
【0048】
このような検索装置2として、その構成は図7に示されるようなものになる。すなわち検索装置2は、制御部200と、記憶部210と、入力部220と、出力部230と、を備える。一方、当該検索装置2は、物理的には図8に示されるように構成され、CPU251と、ROM252と、RAM253と、キーボード255と、モニタ256と、を備える。以下、図7および図8を参照して、検索装置2の構成要素の説明をする。
【0049】
制御部200は、検索装置2全体の動作を制御し、各構成要素と接続され、制御信号やデータをやりとりする。すなわち、制御部200は、記憶部210、入力部220、出力部230と接続され、これら各部の機能を活用しながら、検索処理を実行する。
【0050】
ここで制御部200は、検索文字列変換部201と、検索Nグラム抽出部202と、取得部203と、特定部204と、を備える。これらの各部は、詳細には後述するように、記憶部210に記憶されている変換テーブル400と転置インデックス600を用いて、文書データ群500(複数の文書データ501a〜501c等)のうちから検索語を含む文書データを特定する処理を実行する。
【0051】
このような制御部200(検索文字列変換部201、検索Nグラム抽出部202、取得部203、特定部204)は、例えばCPU251によって構成される。ここでCPU251は、基本的には生成装置1におけるCPU151と同様、命令やデータを転送するための伝送経路であるシステムバスにより各構成要素と相互に接続され、ROM252に記録されている検索装置2全体の動作制御に必要なコンピュータプログラムや各種データに従って動作し、さらにROM252から読み出したコンピュータプログラムやデータ、その他処理の進行に必要なデータを、RAM253に一時的に記憶しながら、各種動作を制御する。このようにCPU251がROM252やRAM253と協働することで、制御部200は、検索装置2全体の動作を制御する。
【0052】
記憶部210は、例えば検索装置2内に備えられたROM252のような読出し専用の記憶媒体によって構成され、制御部200が検索処理に必要な各種データを記憶する。具体的にここでは、検索対象とされる文書データ群500、変換テーブル400、および転置インデックス600が記憶される。
【0053】
これら文書データ群500および変換テーブル400は、上記生成装置1の記憶部110に記憶された文書データ群500および変換テーブル400と同一のものであり、また転置インデックス600は、上記生成装置1が、これら文書データ群500および変換テーブル400から生成した転置インデックス600と同一のものである。
【0054】
入力部220は、例えばキーボード255のような入力装置によって構成され、ユーザからの入力を受け付ける。具体的にここでは、ユーザからの検索語を受け付ける。受け付けられた検索語は、制御部200の検索文字列変換部201へと供給され、当該検索語の文字列を含む文書データ501を検索する処理に用いられる。
【0055】
出力部230は、例えばモニタ256のような表示装置によって構成され、制御部200が処理を行った結果をユーザへ出力する。具体的にここでは、ユーザが入力した検索語を含む文書データ501を、検索結果としてモニタ256に表示することで、当該ユーザへと出力する。これにより、ユーザは、自身が入力した検索語を含む文書データ501を出力結果として取得し、種々に利用することができるようになる。
【0056】
なお、入力部220と出力部230は、タッチパネル等のような入力装置と出力装置が組み合わされた装置によって構成されてもよい。この場合には、タッチパネルに内蔵されたタッチセンサ等からなる位置入力装置が入力部220を、液晶ディスプレイ等からなる表示装置が出力部230を、それぞれ構成する。
【0057】
以上のように構成される検索装置2は、制御部200の制御のもと、検索処理を行う。具体的には、図9A〜図9Cのフローチャートに示される手順で処理を実行する。
【0058】
本処理は、ユーザから入力された検索語を、検索装置2の入力部220が受け付けることを契機として、開始される。すなわち、キーボード255を用いて、ユーザが所望の検索語を入力し、検索する旨を指示することで、本処理が開始する。
【0059】
なお、検索装置2は、一般的な情報機器において実現されている検索と同様に、ユーザから複数の検索語を受け付け、それらの論理積や論理和等の各種演算処理を施したものについての検索を行うことができる。以下、本フローチャートでは、複数の検索語が受け付けられ、それらの論理積をとった検索処理が行われることを想定して説明する。
【0060】
処理が開始されると、まず検索文字列変換部201が、ユーザから入力された検索語を、変換テーブル400に基づいて変換する(ステップS901)。ここで用いられる変換テーブル400は、上記生成装置1が転置インデックス600を生成する際に用いられたものと同一なものであり、ここでは当該変換テーブル400は、検索装置2内の記憶部210に記憶される。そのため検索文字列変換部201は、当該記憶部210内の変換テーブル400にアクセスして、検索語の変換処理を行う。
【0061】
具体的に、変換テーブル400は、上記図4に示されるように、複数の送り仮名表記が可能な語句のそれぞれを、1つの統一した標準表記に変換するためのものである。すなわち、検索語を構成する文字列(検索文字列)に、「表わす」と「表す」、「生まれる」と「生れる」、「打ち合せる」と「打合せる」等のような複数の送り仮名表記が可能な語句が含まれていた場合、これらを1つの統一した標準表記へと変換する。例えば、検索語が、図10に示されるように「打ち合せる」という文字列であった場合、変換テーブル400に基づいて、「打合せる」という標準表記文字列へと変換される。
【0062】
図9Aのフローチャートに戻って、次に、検索Nグラム抽出部202が、変換された検索語からバイグラムを抽出する(ステップS902)。すなわち、変換された検索語を構成する文字列(変換検索文字列)から、2文字の文字列であるバイグラムを抽出する。具体的に、図10のように変換された検索語が「打合せる」という文字列であった場合は、「打合」「合せ」「せる」という3個のバイグラムが抽出される。
【0063】
図9Aのフローチャートに戻って、次に制御部200が、入力部220がユーザから受け付けた全ての検索語が処理されたか否かが判定する(ステップS903)。すなわち、ユーザが検索語を複数入力した場合、入力された全ての検索語に対してステップS901〜S902の処理を行うため、ここで全ての検索語が処理されたか否かが判定される。入力された検索語が1語であれば、ここでの判定は常にYESとなる。
【0064】
全ての検索語が処理されていなければ(ステップS903;NO)、処理はステップS901へと戻り、未処理の検索語に対し、ステップS901〜S902の処理を再度行う。すなわち、未処理の検索語を変換テーブル400に基づいて変換し、当該変換された検索語からバイグラムを抽出する。
【0065】
このようにして全ての検索語が処理されると(ステップS903;YES)、処理はステップS904へと移行する。そしてここでは、取得部203が、転置インデックス600から、抽出された各バイグラムの出現頻度を取得する(ステップS904)。ここで転置インデックス600は、上記生成装置1によって生成されたものであり、上記図6のような構成をとる。ここでは転置インデックス600は、検索装置2の記憶部210に記憶されており、取得部203が、当該記憶部210内の転置インデックス600にアクセスして、処理を行う。
【0066】
具体的にここで取得部203は、転置インデックス600のバイグラム文字列パターンに関するファイル(pattern.idx)において抽出された各バイグラムに相当するものに着目し、それらが指し示す出現位置情報に関するファイル(position.idx)内の格納アドレスにある出現頻度の情報を取得する。
【0067】
出現頻度が取得されると、次に制御部200は、各検索語について、最少出現頻度を導出する(ステップS905)。例えば、上記の例のように「打合」「合せ」「せる」という3個のバイグラムが抽出されている場合には、これら3個のバイグラムの出現頻度を比較して、最少のものが導出されることになる。検索語が複数ある場合には、この導出が検索語ごとに行われ、検索語の数だけ最少出現頻度が導出される。
【0068】
さらに制御部200は、導出された最少出現頻度が最も小さい検索語を基準検索語とし、それ以外を検証検索語とする(ステップS906)。すなわち、検索語が複数存在する場合に、各検索語について導出された最少出現頻度を比較し、最も小さい最少出現頻度を有する検索語(標準表記に変換された検索語)を基準検索語とし、それ以外の検索語(標準表記に変換された検索語)を検証検索語とする。なお、検索語が1語の場合は、当該検索語(標準表記に変換された検索語)が基準検索語とされ、検証検索語は存在しないことになる。
【0069】
ここから検索装置2の処理は、図9Bのフローチャートへと移る。ここではまず、取得部203が、転置インデックス600から、基準検索語から抽出された各バイグラムの出現位置を取得する(ステップS907)。すなわち取得部203は、記憶部210に記憶されている転置インデックス600にアクセスし、出現位置情報に関するファイル(position.idx)内に格納されている各バイグラムの出現位置を取得する。例えば、基準検索語から抽出されたバイグラムが、上記の例のように「打合」「合せ」「せる」という3個のバイグラムである場合には、これらのバイグラムが変換文書データ群550(複数の変換文書データ551a〜551c等)内において出現する位置が取得される。
【0070】
そして、検索装置2の特定部204が、取得された出現位置に連続性があるか否かを判定する(ステップS908)。すなわちここで特定部204は、各バイグラムについて取得された出現位置が、これらが抽出された元である基準検索語を構成するように連続しているか否か、を評価する。例えば、基準検索語「打合せる」から「打合」「合せ」「せる」という3個のバイグラムが抽出された場合には、これら3個のバイグラムに対応付けられた出現位置のうち、それぞれが基準検索語を構成するように1文字ずつずれた値をもつ出現位置があるか否かが評価される。
【0071】
連続性がないと判定された場合(ステップS908;NO)、処理はステップS907へと戻る。すなわち、基準検索語を構成するような連続性がない出現位置にあるバイグラムは、変換文書データ551内において基準検索語を構成するものではなく、それ以外の語句を構成するものであるため、ここでは他の出現位置を取得するためステップS907の処理を再度行う。
【0072】
なお、転置インデックス600から取得されたバイグラムの出現位置のすべてについて、このような連続性を有するものがないと評価された場合は、複数の変換文書データ551a〜551c等のいずれにも基準検索語が含まれない、すなわち入力された検索語が複数の文書データ501a〜501c等のいずれにも含まれないと判断することができる。そのためこの場合は、検索装置2の処理は当該フローチャートを抜け、出力部230がユーザに所望の検索語を含む文書データ501が見つからなかった旨を表示する等した上で、終了する。
【0073】
一方、連続性があると判定された場合(ステップS908;YES)、処理はステップS909へと移行し、特定部204が、連続性があると判定された出現位置から出現候補文書番号を導出する(ステップS909)。すなわちここでの処理は、連続性により基準検索語が存在すると判断された出現位置が、複数の変換文書データ551a〜551c等のうちどれに含まれるのかを特定する処理に相当する。
【0074】
そのため特定部204が、記憶部210に記憶されている転置インデックス600にアクセスし、文書番号に関するファイル(number.idx)に格納された文書番号とその先頭文字位置との対応関係に着目する。そして、当該連続性があると判定された出現位置に対応する文書番号、すなわち、先頭文字位置が当該出現位置以下であり、かつ次の文書番号の先頭文字位置が当該出現位置より大きいような文書番号を取得し、出現候補文書番号とする。
【0075】
出現候補文書番号が導出されると、次に制御部200は、入力された検索語が2個以上か否かを判定する(ステップS910)。入力された検索語が2個以上の場合(ステップS910;YES)、処理は図9Cのフローチャートへと移り、検証検索語についての処理を行う。
【0076】
一方で、入力された検索語が1個の場合は(ステップS910;NO)、検証検索語が存在せず、ステップS909で導出された基準検索語を含む出現候補文書番号がそのまま所望の文書データ501に対応するものであるため、出力部230が、当該出現候補文書番号に対応する文書データ501を検索結果として出力する(ステップS911)。すなわちここでは、ユーザに入力された1語の検索語を含む文書データ501が1個見つかったことになり、検索装置2のモニタ256に表示される等により、当該文書データ501がユーザへと出力される。その後、処理は後述するステップS918へと移行し、検索語を含む文書データ501が文書データ群500中にさらにあるか否かを調べる処理を行う。
【0077】
ここから検索装置2の処理は、図9Cのフローチャートへと移る。本図では主に、入力された検索語が2個以上の場合(ステップS910;YES)における検証検索語についての処理が行われる。すなわち、上記ステップS909において基準検索語を含む変換文書データ551を示す出現候補文書番号が導出されているため、当該変換文書データ551がさらに検証検索語も含んでいるか否かが調べられる。
【0078】
ここではまず、取得部203が、検証検索語のバイグラムのうち、最少出現頻度を有するバイグラムの出現位置を、転置インデックス600から取得する(ステップS912)。すなわちここで取得部203は、検証検索語が出現候補文書番号に対応する変換文書データ551に含まれるか否かを判定するため、当該検証検索語から抽出されたバイグラムの出現位置を、記憶部210内の転置インデックス600から取得する。
【0079】
そしてこのとき、検証検索語から抽出されたバイグラムのうち、最少出現頻度を有するバイグラムが、まず着目される。なぜなら、出現頻度が少ない、すなわち転置インデックス600に格納されている出現位置の個数が少ないバイグラムに着目した方が、この後の出現位置についての文書データの特定および連続性評価の処理を行う回数を減らすことができ、検索処理の高速化につながるからである。すなわちここでは、複数のバイグラムが検証検索語から抽出された場合に、上記ステップS905において導出された最少出現頻度を有するバイグラムについて、出現位置が取得される。このとき、当該最少出現頻度を有するバイグラムについて複数の出現位置がある場合には、出現位置の値が最小のものがまず取得される。
【0080】
そしてこの後、特定部204が、当該取得された出現位置が出現候補文書番号の先頭文字位置以上か否かを判定する(ステップS913)。先頭文字位置以上でなければ(ステップS913;NO)、取得されたバイグラムの出現位置が、出現候補文書番号に対応する変換文書データ551内に含まれていないと判断できるため、処理はステップS912へと戻り、最少出現頻度を有するバイグラムについての出現位置が改めて取得される。すなわち、当該最少出現頻度を有するバイグラムについて、次に出現位置の値が小さなものが取得され、再び当該取得された出現位置が、出現候補文書番号の先頭文字位置以上か否かが判定される。
【0081】
一方、先頭文字位置以上であれば(ステップS913;YES)、引き続いて特定部204が、当該取得された出現位置が出現候補文書番号の最終文字位置以下か否かを判定する(ステップS914)。最終文字位置以下でなければ(ステップS914;NO)、当該出現候補文書番号に対応する変換文書データ551内には検証検索語から抽出されたバイグラムが含まれておらず、従って当該検証検索語自体も含まれていないと判断できるため、処理は検証検索語についての処理を抜け、後述するステップS918へと移行する。
【0082】
一方で、最終文字位置以下であった場合は(ステップS914;YES)、着目された最少出現頻度を有するバイグラムは、当該出現候補文書番号に対応する変換文書データ551内に含まれていることになる。そのためこのとき、当該バイグラムだけでなく、検証検索語自体も当該変換文書データ551内に含まれているか否かを判定するため、特定部204はさらに、出現位置が連続しているか否かを判定する(ステップS915)。すなわち、最少出現頻度を有するバイグラムだけでなく、検証検索語から抽出されたその他のバイグラムにも着目し、取得部203が転置インデックス600からこれらの出現位置を取得した上で、特定部204が、各バイグラムについて取得された出現位置が検証検索語を構成するように連続しているか否かを判定する。
【0083】
出現位置が連続していない場合には(ステップS915;NO)、変換文書データ551内には当該検証検索語が含まれていないと判断され、後述するステップS918へと移行する。一方、出現位置が連続している場合には(ステップS915;YES)、変換文書データ551内には当該検証検索語が含まれていると判断できる。この時点では、基準検索語と当該検証検索語の2語を含む変換文書データ551が特定されたことになる。
【0084】
さらに本フローチャートでは、制御部200が、全ての検証検索語を処理したか否かを判定する(ステップS916)。すなわち、ユーザが3語以上の検索語を入力していた場合は、ここでは全ての検証検索語が処理されていないため(ステップS916;NO)、処理はステップS912へと戻り、未処理の検証検索語について当該出現候補文書番号に対応する変換文書データ551に含まれるか否かの処理が行われる。
【0085】
一方、ユーザが2語しか検索語を入力していない場合、あるいは3語以上入力していた場合でも、全ての検証検索語について処理がされ(ステップS916;YES)、当該出現候補文書番号に対応する変換文書データ551に含まれると判断されると、出力部230が、対応する文書データ501を検索結果として出力する(ステップS917)。すなわちここでは、ユーザに入力された複数の検索語を含む文書データ501が1個見つかったことになり、検索装置2のモニタ256に表示される等により、当該文書データ501がユーザへと出力される。
【0086】
その後、検索装置2の処理はステップS918へと移行し、制御部200が、基準検索語について、未処理の出現位置があるか否かを判定する(ステップS918)。未処理の出現位置がある場合(ステップS918;YES)、処理はステップS907へと戻る。すなわち、基準検索語から抽出された各バイグラムの出現位置のうち、未処理のものを転置インデックス600から取得し、当該取得された出現位置について、上述したステップS908〜S917までの処理を繰り返す。これにより、基準検索語および検証検索語が含まれる変換文書データ551が、他に存在するかが調べられ、存在した場合には、対応する文書データ501が出力部230によってユーザへと出力される。
【0087】
一方、最終的に、基準検索語について未処理の出現位置がなくなった場合(ステップS918;NO)、検索処理は終了する。
【0088】
以上のような構成により、本実施形態の検索装置2は、検索文字列に含まれる複数の送り仮名表記を伴う文字列を1つの統一した標準表記文字列へと変換した上で、同じく標準表記へと変換された変換文書データ群550のうち、当該変換された検索文字列がどの変換文書データ551に含まれるかを特定する。これにより、同一の語句について複数の表記で記載されている文書について、検索漏れを抑制して検索することができる。
【0089】
さらにその際、検索に使用される転置インデックス600は、複数の送り仮名表記のうち文字数が最小となる表記へと変換されたものについて生成されたものであるため、データサイズが抑制されている。そのため、特に電子辞書のような使用可能なデータ容量が限られた環境にある小型の情報機器において、効率的な検索処理を実現できる。
【0090】
なお、上記実施形態は一例であり、本発明の適用範囲はこれに限られない。すなわち、種々の応用が可能であり、あらゆる実施の形態が本発明の範囲に含まれる。
【0091】
例えば、上記実施形態では、検索装置2は、ROM252のような記憶部210内に文書データ群500等を記憶した。しかしこれに限られず、検索装置2は、ハードディスク等の大容量記憶装置やDVD−ROMドライブを備え、文書データ群500等がハードディスクやDVD−ROM等に記憶されるようにしてもよい。あるいは、検索装置2は、ネットワークに接続され、文書データ群500等がネットワーク上に存在するようにしてもよい。
【0092】
また、上記実施形態では、検索装置2は、ユーザが検索語を入力する入力部220や検索結果を出力する出力部230は、制御部200や記憶部210と同一の装置内に存在した。しかしこれに限られず、入力部220と出力部230は、検索装置2の外部にあってもよい。すなわち、例えば図11に示すように、検索装置2は入力部220と出力部230を備えず、これらを備える端末装置3とネットワーク150を介して接続されるようにし、オンライン型の電子辞書のような情報機器として構成するようにしてもよい。
【0093】
このとき、検索装置2と端末装置3は、それぞれが備える通信部240a,240bにより、ネットワーク150を介して互いにデータを通信しあう。すなわち、端末装置3のユーザが入力した検索語は、検索装置2へと送信され、制御部200により検索処理が実行される。その後、検索結果として特定された文書データ501の情報が再び端末装置3へと送信され、端末装置3のユーザへと出力される。このような構成をとることで、検索装置2内の文書データ群500等を一括して管理して複数のユーザに利用できるようになり、またユーザ側の端末装置3は、文書データ群500等を保持する必要がないため、データサイズを抑えることができるといった利点がある。
【0094】
また、上記実施形態では、検索装置2として電子辞書のような小型の情報処理装置を想定して説明した。しかしこれに限られず、検索装置2は、ビジネス用・家庭用の一般的なコンピュータ装置や、携帯電話等の他の情報機器であってもよい。また、電子辞書における検索に限られず、種々の電子データを検索するものであってもよい。例えば、一般的なコンピュータ装置において、ハードディスク等の大容量記憶装置やDVD−ROM等に記憶された電子ファイルのうちから、所望の検索語を含む電子ファイルを検索するものであってもよい。あるいは、ネットワークと接続され、ネットワーク上に存在するウェブページを検索するものであってもよい。
【0095】
また、生成装置1について、上記実施形態での生成装置1は、ハードディスク154のような記憶部110に記憶されている文書データ群500および変換テーブル400から転置インデックス600を生成し、当該生成された転置インデックス600を記憶部110に記憶した。しかし、これら文書データ群500等は、生成装置1内に備えられた記憶部110に記憶されることに限られず、通信部140を介して接続されるネットワーク150上に存在していてもよいし、あるいはDVD−ROMドライブ157に搭載されるDVD−ROM内に記憶されていてもよい。
【0096】
また、上記実施形態では、異なる送り仮名表記が可能な語句について、1つの統一した表記に変換した。しかし送り仮名表記に限られず、異なる表記が可能なために表記ゆれを起こしやすい語句について、1つの統一した表記に変換するものであってもよい。例えば、「ユーザ」と「ユーザー」、「インターフェース」と「インターフェイス」等のように、異なるカタカナ表記が可能な語句を統一するものであってもよい。
【0097】
また、上記実施形態では、文書データ群500を構成する複数の文書データ501は、「見出し語」と「説明文」とから構成された。しかしこれらに限られず、様々な要素から構成されてもよい。例えば、「見出し語」を説明するための図や表を有するものであってもよい。あるいは、辞書における検索以外の一般的な電子ファイル等の検索では、このような「見出し語」と「説明文」といった構成要素に限らず、文書データ501は様々な形式で文字列データを有していてもよい。
【0098】
また、上記実施形態では、転置インデックス600の構成単位として、N=2のNグラム(バイグラム)を採用した。しかしこれに限られず、Nが他の値のNグラムを、転置インデックス600の構成単位としてもよい。例えば、モノグラム(N=1のNグラム)であってもよいし、トリグラム(N=3のNグラム)、あるいはそれ以外のNの値を有するNグラムであってもよい。
【0099】
なお、本発明に係る機能を実現するための構成を予め備えた転置インデックスの生成装置および当該転置インデックスを用いた検索装置として提供できることはもとより、プログラムの適用により、既存のパーソナルコンピュータや情報端末機器等を、本発明に係る生成装置および検索装置として機能させることもできる。すなわち、上記実施形態で例示した生成装置1および検索装置2による各機能構成を実現させるための生成プログラムまたは検索プログラムを、既存のパーソナルコンピュータや情報端末機器等を制御するCPU等が実行できるように適用することで、それぞれ本発明に係る生成装置1および検索装置2として機能させることができる。また、本発明に係る転置インデックスの生成方法および当該転置インデックスを用いた検索方法は、それぞれ生成装置1および検索装置2を用いて実施できる。
【0100】
また、このようなプログラムの適用方法は任意であり、例えば、CD−ROMやDVD−ROM、メモリカードなどのコンピュータ読み取り可能な記憶媒体に格納して適用できる他、例えば、インターネットなどの通信媒体を介して適用することもできる。
【0101】
以上、本発明の好ましい実施形態について説明したが、本発明は係る特定の実施形態に限定されるものではなく、本発明には、特許請求の範囲に記載された発明とその均等の範囲が含まれる。以下に、本願出願の当初の特許請求の範囲に記載された発明を付記する。
【0102】
(付記1)
複数の文書データのそれぞれを、所定の変換規則に基づいて、変換文書データに変換する文書文字列変換ステップと、
前記変換された複数の文書データに含まれる文字列から、「N文字の文字列であるNグラム(Nは自然数)」を抽出する文書Nグラム抽出ステップと、
前記抽出されたNグラムと、前記変換文書データ中における当該Nグラムの出現位置と、を構成要素とする転置インデックスを生成するインデックス生成ステップと、
を備えることを特徴とする転置インデックスの生成方法。
【0103】
(付記2)
前記インデックス生成ステップでは、前記出現位置と前記複数の文書データのうち当該出現位置を含む文書データとの対応関係をさらに構成要素として、転置インデックスを生成する、
ことを特徴とする付記1に記載の転置インデックスの生成方法。
【0104】
(付記3)
前記所定の変換規則とは、複数の表記を伴う語句のそれぞれを、当該複数の表記のうちのいずれかの表記に変換する規則である、
ことを特徴とする付記1または2に記載の転置インデックスの生成方法。
【0105】
(付記4)
前記所定の変換規則とは、複数の表記を伴う語句のそれぞれを、当該複数の表記のうち最小文字数の表記に変換する規則である、
ことを特徴とする付記3に記載の転置インデックスの生成方法。
【0106】
(付記5)
前記複数の表記を伴う語句とは、複数の送り仮名表記を伴う語句である、
ことを特徴とする付記3または4に記載の転置インデックスの生成方法。
【0107】
(付記6)
付記1から5のいずれか1つに記載の生成方法によって生成された転置インデックスを用いる検索方法であって、
検索文字列を、前記所定の変換規則に基づいて、変換検索文字列に変換する検索文字列変換ステップと、
前記変換検索文字列から、Nグラムを抽出する検索Nグラム抽出ステップと、
前記変換検索文字列から抽出されたNグラムに対応付けられた出現位置を、前記転置インデックスから取得する取得ステップと、
前記取得された出現位置に基づいて、前記複数の文書データのうちから、前記検索文字列を含む文書データを特定する特定ステップと、
を備えることを特徴とする検索方法。
【0108】
(付記7)
複数の文書データのそれぞれを、所定の変換規則に基づいて、変換文書データに変換する文書文字列変換手段と、
前記変換された複数の文書データに含まれる文字列から、「N文字の文字列であるNグラム(Nは自然数)」を抽出する文書Nグラム抽出手段と、
前記抽出されたNグラムと、前記変換文書データ中における当該Nグラムの出現位置と、を構成要素とする転置インデックスを生成するインデックス生成手段と、
を備えることを特徴とする転置インデックスの生成装置。
【0109】
(付記8)
付記1から5のいずれか1つに記載の生成方法によって生成された転置インデックスを用いる検索装置であって、
検索文字列を、前記所定の変換規則に基づいて、変換検索文字列に変換する検索文字列変換手段と、
前記変換検索文字列から、Nグラムを抽出する検索Nグラム抽出手段と、
前記変換検索文字列から抽出されたNグラムに対応付けられた出現位置を、前記転置インデックスから取得する取得手段と、
前記取得された出現位置に基づいて、前記複数の文書データのうちから、前記検索文字列を含む文書データを特定する特定手段と、
を備えることを特徴とする検索装置。
【0110】
(付記9)
コンピュータを、
複数の文書データのそれぞれを、所定の変換規則に基づいて、変換文書データに変換する文書文字列変換手段、
前記変換された複数の文書データに含まれる文字列から、「N文字の文字列であるNグラム(Nは自然数)」を抽出する文書Nグラム抽出手段、
前記抽出されたNグラムと、前記変換文書データ中における当該Nグラムの出現位置と、を構成要素とする転置インデックスを生成するインデックス生成手段、
として機能させることを特徴とするコンピュータプログラム。
【0111】
(付記10)
コンピュータを、
付記1から5のいずれか1つに記載の生成方法によって生成された転置インデックスを用いる検索装置として機能させるコンピュータプログラムであって、
前記コンピュータを、
検索文字列を、前記所定の変換規則に基づいて、変換検索文字列に変換する検索文字列変換手段、
前記変換検索文字列から、Nグラムを抽出する検索Nグラム抽出手段、
前記変換検索文字列から抽出されたNグラムに対応付けられた出現位置を、前記転置インデックスから取得する取得手段、
前記取得された出現位置に基づいて、前記複数の文書データのうちから、前記検索文字列を含む文書データを特定する特定手段、
として機能させることを特徴とするコンピュータプログラム。
【符号の説明】
【0112】
1…生成装置、2…検索装置、3…端末装置、100…制御部、101…文書文字列変換部、102…文書Nグラム抽出部、103…インデックス生成部、110…記憶部、120…入力部、130…出力部、140…通信部、150…ネットワーク、151…CPU、152…ROM、153…RAM、154…ハードディスク、155…キーボード、156…モニタ、157…DVD−ROMドライブ、158…通信装置、200…制御部、201…検索文字列変換部、202…検索Nグラム抽出部、203…取得部、204…特定部、210…記憶部、220…入力部、230…出力部、240a,240b…通信部、251…CPU、252…ROM、253…RAM、255…キーボード、256…モニタ、400…変換テーブル、500…文書データ群、501a,501b,501c…文書データ、550…変換文書データ群、551a,551b,551c…変換文書データ、600…転置インデックス
【特許請求の範囲】
【請求項1】
複数の文書データのそれぞれを、所定の変換規則に基づいて、変換文書データに変換する文書文字列変換ステップと、
前記変換された複数の文書データに含まれる文字列から、「N文字の文字列であるNグラム(Nは自然数)」を抽出する文書Nグラム抽出ステップと、
前記抽出されたNグラムと、前記変換文書データ中における当該Nグラムの出現位置と、を構成要素とする転置インデックスを生成するインデックス生成ステップと、
を備えることを特徴とする転置インデックスの生成方法。
【請求項2】
前記インデックス生成ステップでは、前記出現位置と前記複数の文書データのうち当該出現位置を含む文書データとの対応関係をさらに構成要素として、転置インデックスを生成する、
ことを特徴とする請求項1に記載の転置インデックスの生成方法。
【請求項3】
前記所定の変換規則とは、複数の表記を伴う語句のそれぞれを、当該複数の表記のうちのいずれかの表記に変換する規則である、
ことを特徴とする請求項1または2に記載の転置インデックスの生成方法。
【請求項4】
前記所定の変換規則とは、複数の表記を伴う語句のそれぞれを、当該複数の表記のうち最小文字数の表記に変換する規則である、
ことを特徴とする請求項3に記載の転置インデックスの生成方法。
【請求項5】
前記複数の表記を伴う語句とは、複数の送り仮名表記を伴う語句である、
ことを特徴とする請求項3または4に記載の転置インデックスの生成方法。
【請求項6】
請求項1から5のいずれか1項に記載の生成方法によって生成された転置インデックスを用いる検索方法であって、
検索文字列を、前記所定の変換規則に基づいて、変換検索文字列に変換する検索文字列変換ステップと、
前記変換検索文字列から、Nグラムを抽出する検索Nグラム抽出ステップと、
前記変換検索文字列から抽出されたNグラムに対応付けられた出現位置を、前記転置インデックスから取得する取得ステップと、
前記取得された出現位置に基づいて、前記複数の文書データのうちから、前記検索文字列を含む文書データを特定する特定ステップと、
を備えることを特徴とする検索方法。
【請求項7】
複数の文書データのそれぞれを、所定の変換規則に基づいて、変換文書データに変換する文書文字列変換手段と、
前記変換された複数の文書データに含まれる文字列から、「N文字の文字列であるNグラム(Nは自然数)」を抽出する文書Nグラム抽出手段と、
前記抽出されたNグラムと、前記変換文書データ中における当該Nグラムの出現位置と、を構成要素とする転置インデックスを生成するインデックス生成手段と、
を備えることを特徴とする転置インデックスの生成装置。
【請求項8】
請求項1から5のいずれか1項に記載の生成方法によって生成された転置インデックスを用いる検索装置であって、
検索文字列を、前記所定の変換規則に基づいて、変換検索文字列に変換する検索文字列変換手段と、
前記変換検索文字列から、Nグラムを抽出する検索Nグラム抽出手段と、
前記変換検索文字列から抽出されたNグラムに対応付けられた出現位置を、前記転置インデックスから取得する取得手段と、
前記取得された出現位置に基づいて、前記複数の文書データのうちから、前記検索文字列を含む文書データを特定する特定手段と、
を備えることを特徴とする検索装置。
【請求項9】
コンピュータを、
複数の文書データのそれぞれを、所定の変換規則に基づいて、変換文書データに変換する文書文字列変換手段、
前記変換された複数の文書データに含まれる文字列から、「N文字の文字列であるNグラム(Nは自然数)」を抽出する文書Nグラム抽出手段、
前記抽出されたNグラムと、前記変換文書データ中における当該Nグラムの出現位置と、を構成要素とする転置インデックスを生成するインデックス生成手段、
として機能させることを特徴とするコンピュータプログラム。
【請求項10】
コンピュータを、
請求項1から5のいずれか1項に記載の生成方法によって生成された転置インデックスを用いる検索装置として機能させるコンピュータプログラムであって、
前記コンピュータを、
検索文字列を、前記所定の変換規則に基づいて、変換検索文字列に変換する検索文字列変換手段、
前記変換検索文字列から、Nグラムを抽出する検索Nグラム抽出手段、
前記変換検索文字列から抽出されたNグラムに対応付けられた出現位置を、前記転置インデックスから取得する取得手段、
前記取得された出現位置に基づいて、前記複数の文書データのうちから、前記検索文字列を含む文書データを特定する特定手段、
として機能させることを特徴とするコンピュータプログラム。
【請求項1】
複数の文書データのそれぞれを、所定の変換規則に基づいて、変換文書データに変換する文書文字列変換ステップと、
前記変換された複数の文書データに含まれる文字列から、「N文字の文字列であるNグラム(Nは自然数)」を抽出する文書Nグラム抽出ステップと、
前記抽出されたNグラムと、前記変換文書データ中における当該Nグラムの出現位置と、を構成要素とする転置インデックスを生成するインデックス生成ステップと、
を備えることを特徴とする転置インデックスの生成方法。
【請求項2】
前記インデックス生成ステップでは、前記出現位置と前記複数の文書データのうち当該出現位置を含む文書データとの対応関係をさらに構成要素として、転置インデックスを生成する、
ことを特徴とする請求項1に記載の転置インデックスの生成方法。
【請求項3】
前記所定の変換規則とは、複数の表記を伴う語句のそれぞれを、当該複数の表記のうちのいずれかの表記に変換する規則である、
ことを特徴とする請求項1または2に記載の転置インデックスの生成方法。
【請求項4】
前記所定の変換規則とは、複数の表記を伴う語句のそれぞれを、当該複数の表記のうち最小文字数の表記に変換する規則である、
ことを特徴とする請求項3に記載の転置インデックスの生成方法。
【請求項5】
前記複数の表記を伴う語句とは、複数の送り仮名表記を伴う語句である、
ことを特徴とする請求項3または4に記載の転置インデックスの生成方法。
【請求項6】
請求項1から5のいずれか1項に記載の生成方法によって生成された転置インデックスを用いる検索方法であって、
検索文字列を、前記所定の変換規則に基づいて、変換検索文字列に変換する検索文字列変換ステップと、
前記変換検索文字列から、Nグラムを抽出する検索Nグラム抽出ステップと、
前記変換検索文字列から抽出されたNグラムに対応付けられた出現位置を、前記転置インデックスから取得する取得ステップと、
前記取得された出現位置に基づいて、前記複数の文書データのうちから、前記検索文字列を含む文書データを特定する特定ステップと、
を備えることを特徴とする検索方法。
【請求項7】
複数の文書データのそれぞれを、所定の変換規則に基づいて、変換文書データに変換する文書文字列変換手段と、
前記変換された複数の文書データに含まれる文字列から、「N文字の文字列であるNグラム(Nは自然数)」を抽出する文書Nグラム抽出手段と、
前記抽出されたNグラムと、前記変換文書データ中における当該Nグラムの出現位置と、を構成要素とする転置インデックスを生成するインデックス生成手段と、
を備えることを特徴とする転置インデックスの生成装置。
【請求項8】
請求項1から5のいずれか1項に記載の生成方法によって生成された転置インデックスを用いる検索装置であって、
検索文字列を、前記所定の変換規則に基づいて、変換検索文字列に変換する検索文字列変換手段と、
前記変換検索文字列から、Nグラムを抽出する検索Nグラム抽出手段と、
前記変換検索文字列から抽出されたNグラムに対応付けられた出現位置を、前記転置インデックスから取得する取得手段と、
前記取得された出現位置に基づいて、前記複数の文書データのうちから、前記検索文字列を含む文書データを特定する特定手段と、
を備えることを特徴とする検索装置。
【請求項9】
コンピュータを、
複数の文書データのそれぞれを、所定の変換規則に基づいて、変換文書データに変換する文書文字列変換手段、
前記変換された複数の文書データに含まれる文字列から、「N文字の文字列であるNグラム(Nは自然数)」を抽出する文書Nグラム抽出手段、
前記抽出されたNグラムと、前記変換文書データ中における当該Nグラムの出現位置と、を構成要素とする転置インデックスを生成するインデックス生成手段、
として機能させることを特徴とするコンピュータプログラム。
【請求項10】
コンピュータを、
請求項1から5のいずれか1項に記載の生成方法によって生成された転置インデックスを用いる検索装置として機能させるコンピュータプログラムであって、
前記コンピュータを、
検索文字列を、前記所定の変換規則に基づいて、変換検索文字列に変換する検索文字列変換手段、
前記変換検索文字列から、Nグラムを抽出する検索Nグラム抽出手段、
前記変換検索文字列から抽出されたNグラムに対応付けられた出現位置を、前記転置インデックスから取得する取得手段、
前記取得された出現位置に基づいて、前記複数の文書データのうちから、前記検索文字列を含む文書データを特定する特定手段、
として機能させることを特徴とするコンピュータプログラム。
【図1】


【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9A】
【図9B】
【図9C】
【図10】
【図11】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9A】
【図9B】
【図9C】
【図10】
【図11】
【公開番号】特開2012−198794(P2012−198794A)
【公開日】平成24年10月18日(2012.10.18)
【国際特許分類】
【出願番号】特願2011−62996(P2011−62996)
【出願日】平成23年3月22日(2011.3.22)
【出願人】(000001443)カシオ計算機株式会社 (8,748)
【Fターム(参考)】
【公開日】平成24年10月18日(2012.10.18)
【国際特許分類】
【出願日】平成23年3月22日(2011.3.22)
【出願人】(000001443)カシオ計算機株式会社 (8,748)
【Fターム(参考)】
[ Back to top ]