
Nグラム検索のための転置インデックスの生成方法および生成装置、当該転置インデックスを用いた検索方法および検索装置、ならびに、コンピュータプログラム
【課題】データサイズを抑えつつ高速な検索処理を実現するのに好適な転置インデックスの生成方法等を提供する。
【解決手段】生成装置1において、抽出部101は、文書データ300のうちから「3文字の文字列であるトライグラム」を、当該文書データ300中での出現位置と対応付けて、抽出する。分類部102は、抽出されたトライグラムのうち中央の文字が共通なトライグラムを、先頭および末尾の文字に基づいて、トライグラム群に分類する。生成部103は、分類されたトライグラム群のそれぞれに、当該トライグラム群に分類されたトライグラムに対応付けられた出現位置を対応付けて、転置インデックス900を生成する。
【解決手段】生成装置1において、抽出部101は、文書データ300のうちから「3文字の文字列であるトライグラム」を、当該文書データ300中での出現位置と対応付けて、抽出する。分類部102は、抽出されたトライグラムのうち中央の文字が共通なトライグラムを、先頭および末尾の文字に基づいて、トライグラム群に分類する。生成部103は、分類されたトライグラム群のそれぞれに、当該トライグラム群に分類されたトライグラムに対応付けられた出現位置を対応付けて、転置インデックス900を生成する。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、Nグラム検索に関し、とくにデータサイズを抑えつつ高速な検索処理を実現するのに好適な転置インデックスの生成方法および生成装置、当該転置インデックスを用いた検索方法および検索装置、ならびにコンピュータプログラムに関する。
【背景技術】
【0002】
文書の電子化の増大に伴い、これまでに蓄積されてきた大量の文書群から所望の文書を見つけ出す検索技術の重要性が高まっている。
【0003】
大量の文書群を対象とした検索では、検索処理の高速化のため、検索対象となる文書群に含まれる単語等を索引単位として、索引ファイルを作成することが一般的である。あらかじめ作成された索引ファイル(以下、転置インデックスと呼称する)を検索時に用いることで、検索のたびに大量の文書群にアクセスする必要がなくなり、高速な検索処理が実現されるからである。
【0004】
英語などの多くの言語においては、単語を索引単位として転置インデックスを作成することが一般的である。しかし、日本語の場合、スペース等によって単語の切れ目が明示的に示されないため、しばしば、Nグラムを索引単位とする方法が用いられる。Nグラムとは、連続するN文字からなる部分文字列のことである。Nグラムによる転置インデックスの作成は、単語を認識する必要がなく、文字列にのみ基づくため、日本語の文書を検索対象とした検索に適している。
【0005】
このようなNグラムを用いた検索では、検索処理の速度や転置インデックスのデータサイズは、索引単位として採用するNグラムのNの値によって変化する。例えば、非特許文献1には、異なるNの値における検索処理の高速化の比較が記載されている。
【先行技術文献】
【非特許文献】
【0006】
【非特許文献1】小川泰嗣,松田透,”n−gram索引を用いた効率的な文書検索法”,電子情報通信学会論文誌(D-I),Vol.J82-D-I,No.1,pp.121-129,1999年1月
【発明の概要】
【発明が解決しようとする課題】
【0007】
Nグラムを用いた検索では、転置インデックスの単位として採用するNの値を大きくすると、原則として検索処理の速度は上がる。一方で、Nの値を大きくすると、文書から抽出されるNグラムの種類が多くなるため、転置インデックスのデータサイズは増大する。そのため、検索処理の高速化と転置インデックスのデータサイズの抑制とは両立しにくかった。しかし、転置インデックスのデータサイズをなるべく抑えつつ、検索処理の高速化も実現したい、との要望がある。
【0008】
本発明は、以上のような課題を解決するためのものであり、データサイズを抑えつつ高速な検索処理を実現するのに好適な転置インデックスの生成方法および生成装置、当該転置インデックスを用いた検索方法および検索装置、ならびに、コンピュータプログラムを提供することを目的とする。
【課題を解決するための手段】
【0009】
上記目的を達成するため、本発明にかかる転置インデックスの生成方法は、
文書データのうちから「3文字の文字列であるトライグラム」を、当該文書データ中での出現位置と対応付けて、抽出する抽出ステップと、
前記抽出されたトライグラムのうち中央の文字が共通なトライグラムを、先頭および末尾の文字に基づいて、トライグラム群に分類する分類ステップと、
前記分類されたトライグラム群のそれぞれに、当該トライグラム群に分類されたトライグラムに対応付けられた出現位置を対応付けて、転置インデックスを生成する生成ステップと、
を備えることを特徴とする。
【発明の効果】
【0010】
本発明によれば、データサイズを抑えつつ高速な検索処理を実現するのに好適な転置インデックスの生成方法および生成装置、当該転置インデックスを用いた検索方法および検索装置、ならびに、コンピュータプログラムを提供することができる。
【図面の簡単な説明】
【0011】
【図1】本発明の実施形態に係る転置インデックスの生成装置の概要構成を示す図である。
【図2】本発明の実施形態に係る転置インデックスの生成装置の物理構成を示す図である。
【図3】本発明の実施形態に係る文書データ構成を示す図である。
【図4】本発明の実施形態に係る生成装置の処理の流れを示すフローチャートである。
【図5】本発明の実施形態において、文書データから抽出されたトライグラムとその出現位置の例を示す図である。
【図6】本発明の実施形態において、トライグラムが統合トライグラム群に分類された様子を示す図である。
【図7】本発明の実施形態において、統合トライグラム群のトライグラムが中間トライグラム群に分類される様子を示す図である。
【図8】本発明の実施形態において、中間トライグラム群のトライグラムがトライグラム群に分類される様子を示す図である。
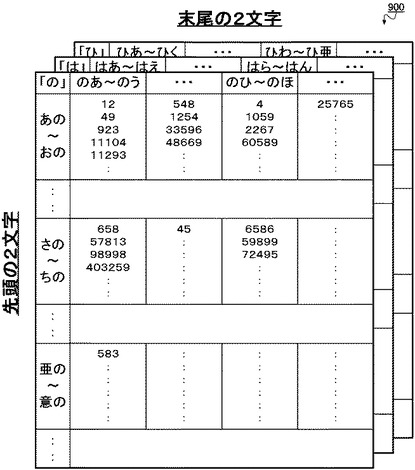
【図9】本発明の実施形態において、転置インデックスの構成をトライグラムの中央の文字ごとに2次元状に表した図である。
【図10】本発明の実施形態に係る検索装置の概要構成を示す図である。
【図11】本発明の実施形態に係る検索装置の物理構成を示す図である。
【図12A】本発明の実施形態に係る検索装置の処理の流れを示す第1のフローチャートである。
【図12B】本発明の実施形態に係る検索装置の処理の流れを示す第2のフローチャートである。
【図12C】本発明の実施形態に係る検索装置の処理の流れを示す第3のフローチャートである。
【図13A】本発明の実施形態に係る検索処理において、転置インデックスから出現位置が取得される様子を示す第1の図である。
【図13B】本発明の実施形態に係る検索処理において、転置インデックスから出現位置が取得される様子を示す第2の図である。
【図13C】本発明の実施形態に係る検索処理において、転置インデックスから出現位置が取得される様子を示す第3の図である。
【図13D】本発明の実施形態に係る検索処理において、転置インデックスから出現位置が取得される様子を示す第4の図である。
【図14】本発明に係る検索装置の構成概要について、別の例を示す図である。
【図15】本発明に係る転置インデックスの構成について、別の例を示す図である。
【発明を実施するための形態】
【0012】
以下、本発明の実施形態について、図面を参照して説明する。なお、以下に説明する実施形態は説明のためのものであり、本発明の範囲を制限するものではない。したがって、当業者であれば下記の各構成要素を均等なものに置換した実施形態を採用することが可能であるが、これらの実施形態も本発明の範囲に含まれる。また、以下の説明では、本発明の理解を容易にするため、重要でない公知の技術的事項の説明を適宜省略する。
【0013】
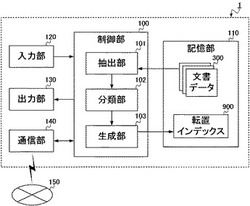
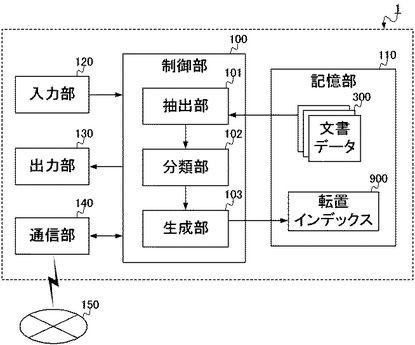
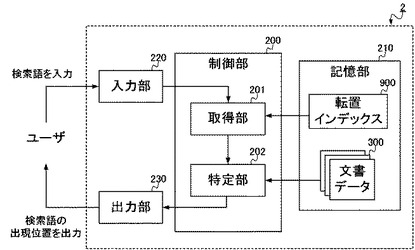
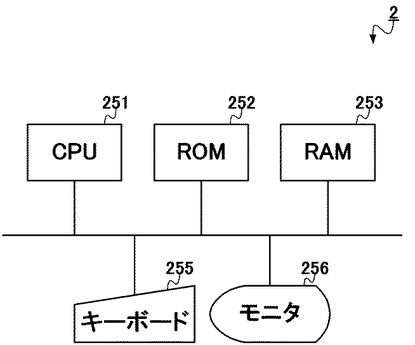
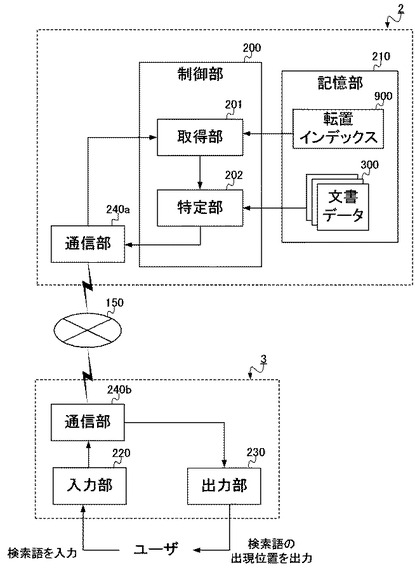
まず、本実施形態に係る転置インデックスの生成装置1が実現される情報処理装置は、図1に示されるような構成をとる。すなわち、生成装置1は、制御部100と、記憶部110と、入力部120と、出力部130と、通信部140と、を備える。一方、当該生成装置1は、物理的には図2に示されるように構成され、CPU(Central Processing Unit)151と、ROM(Read Only Memory)152と、RAM(Random Access Memory)153と、ハードディスク154と、キーボード155と、モニタ156と、DVD−ROMドライブ157と、通信装置158と、を備える。以下、図1および図2を参照して、生成装置1の構成要素の説明をする。
【0014】
制御部100は、生成装置1全体の動作を制御し、各構成要素と接続され、制御信号やデータをやりとりする。すなわち、制御部100は、記憶部110、入力部120、出力部130、通信部140と接続され、これら各部の機能を活用しながら、転置インデックスの生成処理を実行する。
【0015】
ここで制御部100は、抽出部101と、分類部102と、生成部103と、を備える。これらの各部は、詳細には後述するように、記憶部110に記憶されている文書データ300をもとにして、転置インデックス900を生成する処理を実行する。
【0016】
このような制御部100(抽出部101、分類部102、生成部103)は、例えばCPU151によって構成される。ここでCPU151は、命令やデータを転送するための伝送経路であるシステムバスにより各構成要素と相互に接続され、ROM152に記録されている生成装置1全体の動作制御に必要なコンピュータプログラムや各種データに従って動作する。そしてCPU151は、ROM152から読み出したコンピュータプログラムやデータ、その他処理の進行に必要なデータを、RAM153に一時的に記憶しながら、各種動作を制御する。このようにCPU151がROM152やRAM153と協働することで、制御部100は、生成装置1全体の動作を制御する。
【0017】
記憶部110は、例えばハードディスク154のような大容量外部記憶装置によって構成され、制御部100が転置インデックス900を生成する処理のために必要な各種データ、具体的には後述する検索装置によって検索対象とされる文書データ300等が、記憶される。また、記憶部110は、生成装置1の処理によって生成された転置インデックス900も記憶する。
【0018】
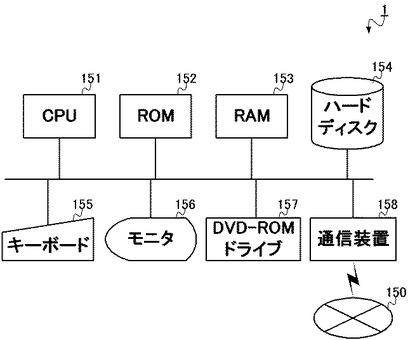
ここで、記憶部110にあらかじめ記憶される文書データ300は、図3に示されるように、個々の文書データ300a〜300c等から構成され、さらに文書データ300a〜300c等はそれぞれ、「見出し語」と「説明文」とから構成される。すなわち、文書データ300a〜300c等は、辞書を構成する構成単位であり、「見出し語」とは、当該辞書の見出しとなる1つの語句であり、1つの文書データ300に対して1つの見出し語が対応付けられる。そして、「見出し語」には当該見出し語を説明する「説明文」が対応付けられ、これらを合わせて1つの文書データ300を構成する。
【0019】
図1および図2に戻って、記憶部110が記憶するこれらのデータは、例えば生成装置1のDVD−ROMドライブ157を介して、あるいは通信部140によって接続されるネットワーク150を介して、外部とやり取りされる。
【0020】
入力部120は、例えばキーボード155のような入力装置によって構成され、ユーザからの入力を受け付ける。受け付けられた入力情報は、制御部100へと供給される。本実施形態では、転置インデックス900を生成するためのユーザからの命令を受け付ける。
【0021】
出力部130は、例えばモニタ156のような表示装置によって構成され、制御部100が処理を行った結果をユーザへ出力する。本実施形態では、抽出部101、分類部102、生成部103のそれぞれが行う転置インデックス900の生成処理の経過や結果がモニタ156に表示される。これにより、ユーザは当該生成処理の経過や結果についての情報を得ることができる。
【0022】
通信部140は、生成装置1をインターネット等のネットワーク150に接続し、制御部100の制御のもと、ネットワーク150を介してデータをやり取りする。このような通信部140は、例えばモデム等の適宜の通信装置158によって構成される。
【0023】
以上のように構成される生成装置1は、制御部100の制御のもと、転置インデックス900の生成処理を行う。具体的には、図4のフローチャートに示される手順で処理を実行する。
【0024】
本処理は、ユーザからの転置インデックス900を生成する旨の指示を、生成装置1の入力部120が受け付けることを契機として、開始される。すなわち、キーボード155を用いて、ユーザが転置インデックス900を生成する旨を指示することで、本処理が開始する。
【0025】
処理が開始されると、まず抽出部101が、記憶部110に記憶された文書データ300からトライグラム(N=3のNグラム)を、その出現位置を対応付けて抽出する(ステップS401)。ここでNグラムとは、N文字の文字列(Nは自然数)を意味し、N=3のNグラム(トライグラム)とは、3文字の文字列をいう。すなわち、抽出部101は、文書データ300に含まれる見出し語や説明文を構成する文字列から、3文字の文字列(トライグラム)を抽出可能な数だけ抽出する。
【0026】
一般的に、文字数がX文字の文字列からは、X−N+1個のNグラムが抽出されるため、N=3の場合は、X−2個(X−3+1個)のバイグラムが抽出される。例えば、「携帯電話」という4文字の文字列からは、「携帯電」「帯電話」という2個(4−2個)のトライグラムが抽出され、「ボールペン」という5文字の文字列からは、「ボール」「ールペ」「ルペン」という3個(5−2個)のトライグラムが抽出される。
【0027】
このとき抽出部101は、それぞれに文書データ300中での出現位置を対応付けつつ、トライグラムを抽出する。すなわち、抽出されたトライグラムが、抽出元の文書データ300中の先頭文字から数えて何文字目に位置していたかの情報を、当該トライグラムに対応付けながら抽出する。
【0028】
例えば、文書データ300を構成する文字列が、「ボールペン」という5文字の文字列から始まっていたとした場合は、抽出されたトライグラムのうち、トライグラム「ボール」には1(文字目)、トライグラム「ールペ」には2(文字目)、トライグラム「ルペン」には3(文字目)、という出現位置を表す値が対応付けられる。ここで、文書データ300中に同一のトライグラムが複数出現する場合には、当該トライグラムに複数の出現位置が対応付けられることになる。
【0029】
出現位置の対応付け処理が行われると、具体的には図5に示されるように、文書データ300から抽出された各トライグラムとその出現位置との対応関係が形成される。本図の対応関係からは、例えば「ボール」というトライグラムは、文書データ300の先頭から1文字目、22文字目、33文字目、87文字目、120文字目に出現し、また「リンゴ」というトライグラムは199文字目と219文字目に出現するということが分かる。
【0030】
これらの抽出されたトライグラムやそれらの出現位置は、RAM153等に一時的に保持される。
【0031】
トライグラムが抽出されると、次に分類部102が、抽出されたトライグラムのうち、中央の文字が共通なトライグラムを統合トライグラム群としてまとめる(ステップS402)。すなわち、分類部102は、トライグラムの3文字の文字列のうち、中央の(2番目の)文字に着目し、同じ文字を中央の文字として有するトライグラムを1つの統合トライグラム群としてまとめる。
【0032】
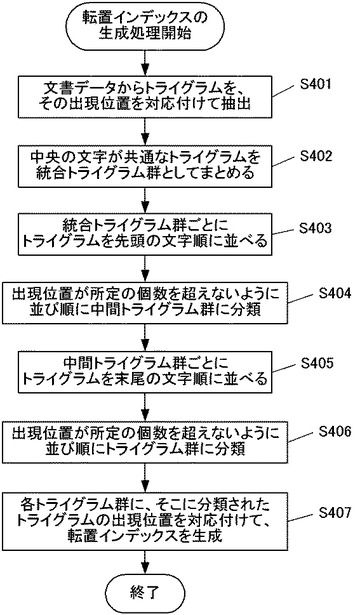
まとめられた統合トライグラム群は、例えば図6に示されるようになる。すなわち、「あ」を中央の文字として有するトライグラムが分類された統合トライグラム群、「の」を中央の文字として有するトライグラムが分類された統合トライグラム群、「ン」を中央の文字として有するトライグラムが分類された統合トライグラム群、「山」を中央の文字として有するトライグラムが分類された統合トライグラム群・・・というように、文書データ300から抽出されたトライグラムの中央の文字の種類の数だけ、統合トライグラム群を作成する。
【0033】
統合トライグラム群にトライグラムがまとめられると、次に分類部102は、統合トライグラム群ごとにトライグラムを先頭の文字順に並べる(ステップS403)。ここで文字順とは、いわゆる辞書順であり、五十音順やアルファベット順等のような文字列の並び順をいう。日本語のように複数の文字種がある場合にはひらがな、カタカナ、漢字、アルファベット・・・といったように文字種に順序を定めてもよい。すなわち、中央の文字が共通なトライグラムについて、先頭の文字に着目し、このような辞書順に並べる。
【0034】
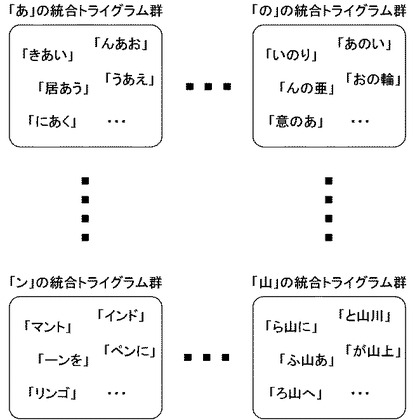
具体的には図7に示すように、分類部102は、例えば文字「の」を共通な中央の文字とする統合トライグラム群にまとめられたトライグラムについて、それぞれの先頭の文字に着目し、先頭の文字が「あ」「い」・・・「お」・・・「ん」・・・「意」・・・といった順になるように並べる。このようなトライグラムを先頭の文字について辞書順に並べる処理を、すべての統合トライグラム群に対して実行する。
【0035】
図4のフローチャートに戻って、次に分類部102は、並べられたトライグラムを、出現位置が所定の個数を超えないように、並び順に中間トライグラム群に分類する(ステップS404)。すなわち分類部102は、先頭の文字順に並べられたトライグラムについて、最初のトライグラムから並び順に1つ以上のトライグラムをひとまとめにし、中間トライグラム群としてまとめていく。
【0036】
具体的に、図7のように「の」を共通な中央の文字とする統合トライグラム群の例では、先頭の文字順に並べられたトライグラムについて、最初に並べられたトライグラム「あのあ」から順に、「あのい」、「あのう」・・・「おの輪」までを1つの中間トライグラム群Aとしてまとめる。そして、次のトライグラム「かのあ」から、並べられた順に「けの和」まで、中間トライグラム群Bとしてまとめる。このような処理を繰り返して、中間トライグラム群X、中間トライグラム群Y・・・というように、並べられた最後のトライグラムまで、中間トライグラム群としてまとめていく。
【0037】
なおこのとき、分類が複雑になることを防ぐため、分類部102は、先頭の文字が同一のトライグラムは同一の中間トライグラム群にまとめられるようにする。例えば、「かのあ」と「かのわ」という2つのトライグラムは、同一の先頭の文字「か」を有するため、異なる中間トライグラム群に分けて分類されるのではなく、トライグラム「かのあ」が分類された中間トライグラム群には必ずトライグラム「かのわ」も分類されるようにする。
【0038】
さらにこのとき、1つの中間トライグラム群にまとめられるトライグラムの個数が、まとめられたトライグラムに対応付けられた出現位置の個数の和が所定の個数を超えないように、分類部102はトライグラムを分類する。具体的に説明すると、分類部102は、各トライグラムに対応付けられた出現位置の個数に着目し、最初のトライグラムから順に中間トライグラム群に分類していく際、分類対象となっているトライグラムの出現位置の個数と、分類候補となっている中間トライグラム群にすでに分類されたトライグラムの出現位置の個数との和を算出し、あらかじめ用意された所定の個数と比較する。所定の個数を超えていなければ、当該分類候補となっている中間トライグラム群に分類対象のトライグラムを分類する。一方で、所定の個数を超えていれば、異なる中間トライグラム群に分類対象のトライグラムを分類する。
【0039】
このように、分類部102が各中間トライグラム群に分類されるトライグラムの出現位置の個数の和が所定の個数を超えないように分類することで、各中間トライグラム群の出現位置の個数をなるべく均一にすることができる。その結果、出現位置が効率的に格納された転置インデックス900を生成することへとつながる。
【0040】
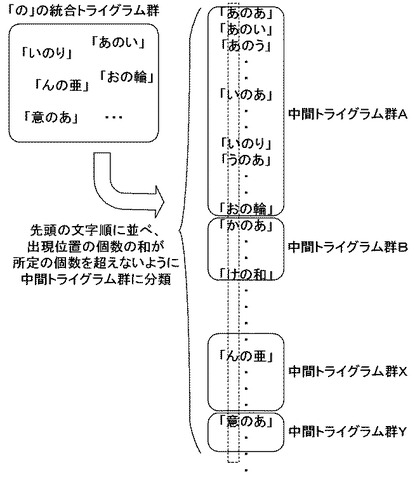
再び図4のフローチャートに戻って、さらに分類部102は、作成された中間トライグラム群ごとに、トライグラムを末尾の文字順に並べる(ステップS405)。すなわち分類部102は、トライグラムの先頭の文字に基づいて分類された中間トライグラム群のそれぞれにおいて、今度はトライグラムの末尾の文字に着目し、末尾の文字の辞書順に並べる。
【0041】
具体的には図8に示すように、分類部102は、例えば文字「の」を共通な中央の文字とし、先頭の文字が「あ」〜「お」のトライグラムが分類された中間トライグラム群Aにおいて、トライグラムの末尾の文字に着目し、末尾の文字が「あ」「い」「う」・・・「り」・・・「輪」・・・といった順になるように並べる。このようなトライグラムを末尾の文字について辞書順に並べる処理を、すべての中間トライグラム群に対して実行する。
【0042】
図4のフローチャートに戻って、次に分類部102は、末尾の文字順に並べられたトライグラムを、出現位置が所定の個数を超えないように、並び順にトライグラム群に分類する(ステップS406)。すなわち分類部102は、末尾の文字順に並べられたトライグラムについて、最初のトライグラムから並び順に1つ以上のトライグラムをひとまとめにし、トライグラム群としてまとめていく。
【0043】
具体的に、図8のような中間トライグラム群Aの例では、末尾の文字順に並べられたトライグラムについて、最初に並べられたトライグラム「あのあ」から順に、「いのあ」・・・「おのあ」「あのい」・・・「おのう」までを1つのトライグラム群AAとしてまとめる。そして、次のトライグラム「あのえ」から、並べられた順に「おのく」まで、トライグラム群ABとしてまとめる。このような処理を繰り返して、トライグラム群AP、トライグラム群AQ・・・というように、並べられた最後のトライグラムまで、トライグラム群としてまとめていく。
【0044】
なおこのとき、上記中間トライグラム群への分類と同様に、分類が複雑になることを防ぐため、分類部102は、末尾の文字が同一のトライグラムは同一のトライグラム群にまとめられるようにする。例えば、「かのさ」と「このさ」という2つのトライグラムは、同一の末尾の文字「さ」を有するため、異なるトライグラム群に分けて分類されるのではなく、トライグラム「かのさ」が分類されたトライグラム群には必ずトライグラム「このさ」も分類されるようにする。
【0045】
さらにこのとき、上記中間トライグラム群への分類と同様に、トライグラム群の出現位置の個数をなるべく均一にするため、1つのトライグラム群にまとめられるトライグラムの個数が、まとめられたトライグラムに対応付けられた出現位置の個数の和が所定の個数を超えないように、分類部102はトライグラムを分類する。具体的に説明すると、分類部102は、各トライグラムに対応付けられた出現位置の個数に着目し、各中間トライグラム群において最初のトライグラムから順にトライグラム群に分類していく際、分類対象となっているトライグラムの出現位置の個数と、分類候補となっているトライグラム群にすでに分類されたトライグラムの出現位置の個数との和を算出し、あらかじめ用意された所定の個数と比較する。所定の個数を超えていなければ、当該分類候補となっているトライグラム群に分類対象のトライグラムを分類する。一方で、所定の個数を超えていれば、異なるトライグラム群に分類対象のトライグラムを分類する。
【0046】
図4のフローチャートに戻って、最後に生成装置1の生成部103が、各トライグラム群に、そこに分類されたトライグラムの出現位置を対応付けて、転置インデックス900を生成する(ステップS407)。すなわち、生成部103は、トライグラム群と、そこに分類された全てのトライグラムに上記ステップS401にて対応付けられた文書データ300中での出現位置と、を構成要素として、転置インデックス900を生成する。その後、生成された転置インデックス900は、ハードディスク154のような記憶部110に記憶され、本フローチャートの処理は終了する。
【0047】
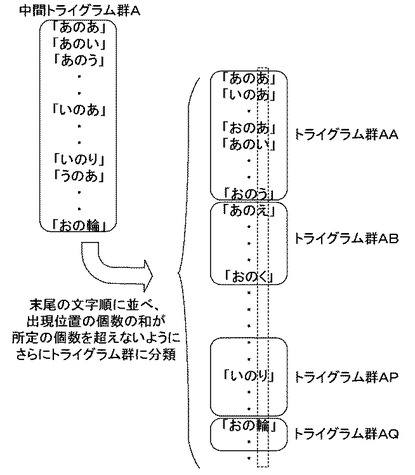
ここで生成される転置インデックス900は、図9に示されるような2次元の表状に表すことができる。すなわち、生成される転置インデックス900の構成は、トライグラムの中央の文字ごとに、先頭の2文字を縦軸に、末尾の2文字を横軸にとり、出現位置を要素とする2次元状の表として表される。1つの表全体は、中央の文字を共通とするトライグラム全体、すなわち統合トライグラム群1つに相当するものである。
【0048】
ここで本図における縦軸の構成単位は、中央の文字が共通のトライグラムを先頭の文字に基づいて中間トライグラム群に分類した際の分類の単位であり、横軸の構成単位は、中間トライグラム群に分類されたトライグラムを末尾の文字に基づいてトライグラム群に分類した際の分類の単位である。そのため、1つのセルは1つのトライグラム群に相当し、1つのセルには、対応するトライグラム群に分類されたトライグラムに対応付けられた全ての出現位置が格納される。
【0049】
具体的に説明すると、表上で最も左上に配置されたセルは、先頭の2文字が「あの」〜「おの」であり、末尾の2文字が「のあ」〜「のう」であるトライグラムが分類されたトライグラム群に相当する。例えば「いのう」や「おのあ」というトライグラムがここに分類される。そして、当該トライグラム群に分類されたいずれかのトライグラムは、本図の当該セルに示されるように、文書データ300中の先頭から12文字目、49文字目、923文字目、11104文字目、11293文字目・・・という位置に出現する。一方で別の例を挙げると、例えば「しのひ」や「たのへ」といったトライグラムは、先頭の2文字が「さの」〜「ちの」で末尾の2文字が「のひ」〜「のほ」に相当するトライグラムである。本図によれば、これらのうちいずれかのトライグラムが、文書データ300中の先頭から6586文字目、59899文字目、72495文字目・・・の位置に出現する。
【0050】
生成装置1が生成する転置インデックス900は、このようなトライグラム群とその出現位置との2次元状の対応関係を、トライグラムの中央の文字のそれぞれについて備え、後述する検索処理において用いられる。
【0051】
以上のような構成により、本実施形態の生成装置1は、文書データ300から抽出されたトライグラムについて、中央の文字が共通なトライグラムをまとめ、まとめられたトライグラムをさらに先頭および末尾の文字に基づいてトライグラム群に分類する。そして、トライグラム群とそれぞれに分類されたトライグラムの出現位置とを対応付けて、転置インデックス900を生成する。その結果、トライグラムを単独で単位としたものに比べてデータサイズが抑えられ、かつ後述する検索装置2において高速な検索処理を実現することができる転置インデックス900を生成することができる。
【0052】
その際、生成装置1は、トライグラム群に分類されるトライグラムの出現位置の個数の和が所定の上限値を超えないようにトライグラムを分類していく。これにより、各トライグラム群に対応付けられる出現位置の個数がなるべく同じ個数に均一化することができ、出現位置が効率的に格納された転置インデックス900を生成することができる。
【0053】
本発明では、上記のような転置インデックス900の生成装置1、およびそれを用いた転置インデックス900の生成方法に加え、当該生成された転置インデックス900を用いて、文書データ300を検索対象とした検索を行う検索装置2、およびそれを用いた検索方法を提供する。
【0054】
ここで検索装置は、通常は上記転置インデックスの生成装置1とは異なる情報処理装置によって実現される。具体的に本実施形態では、検索装置として、電子辞書等の機能を備える小型の情報処理装置を想定して説明する。すなわち、検索対象である文書データ300についての転置インデックス900の生成については、あらかじめ上記図1および図2に示されたような一般的な情報処理装置において行われ、一方で当該生成された転置インデックス900を用いた文書データ300の検索については、生成装置1とは異なる情報処理装置、すなわち電子辞書等の小型の情報処理装置において実現される。
【0055】
このような検索装置2として、その構成は図10に示されるようなものになる。すなわち検索装置2は、制御部200と、記憶部210と、入力部220と、出力部230と、を備える。一方、当該検索装置2は、物理的には図11に示されるように構成され、CPU251と、ROM252と、RAM253と、キーボード255と、モニタ256と、を備える。以下、図10および図11を参照して、検索装置2の構成要素の説明をする。
【0056】
制御部200は、検索装置2全体の動作を制御し、各構成要素と接続され、制御信号やデータをやりとりする。すなわち、制御部200は、記憶部210、入力部220、出力部230と接続され、これら各部の機能を活用しながら、検索処理を実行する。
【0057】
ここで制御部200は、取得部201と、特定部202と、を備える。これらの各部は、詳細には後述するように、記憶部210に記憶されている転置インデックス900を用いて、文書データ300のうちから検索文字列が出現する位置を特定する処理を実行する。
【0058】
このような制御部200(取得部201、特定部202)は、例えばCPU251によって構成される。ここでCPU251は、基本的には生成装置1におけるCPU151と同様、命令やデータを転送するための伝送経路であるシステムバスにより各構成要素と相互に接続され、ROM252に記録されている検索装置2全体の動作制御に必要なコンピュータプログラムや各種データに従って動作し、さらにROM252から読み出したコンピュータプログラムやデータ、その他処理の進行に必要なデータを、RAM253に一時的に記憶しながら、各種動作を制御する。このようにCPU251がROM252やRAM253と協働することで、制御部200は、検索装置2全体の動作を制御する。
【0059】
記憶部210は、例えば検索装置2内に備えられたROM252のような読出し専用の記憶媒体によって構成され、制御部200が検索処理に必要な各種データを記憶する。具体的にここでは、検索対象とされる文書データ300、および転置インデックス900が記憶される。
【0060】
これら文書データ300は、上記生成装置1の記憶部110に記憶された文書データ300と同一のものであり、また転置インデックス900は、上記生成装置1が、これら文書データ300をもとにして生成した転置インデックス900と同一のものである。
【0061】
入力部220は、例えばキーボード255のような入力装置によって構成され、ユーザからの入力を受け付ける。具体的にここでは、ユーザからの検索語を受け付ける。受け付けられた検索語は、制御部200の取得部201へと供給され、当該検索語の文字列の文書データ300における出現位置を検索する処理に用いられる。
【0062】
出力部230は、例えばモニタ256のような表示装置によって構成され、制御部200が処理を行った結果をユーザへ出力する。具体的にここでは、ユーザが入力した検索語の文書データ300における出現位置を、検索結果としてモニタ256に表示することで、当該ユーザへと出力する。これにより、ユーザは、自身が入力した検索語の出現位置を出力結果として取得し、種々に利用することができるようになる。
【0063】
なお、入力部220と出力部230は、タッチパネル等のような入力装置と出力装置が組み合わされた装置によって構成されてもよい。この場合には、タッチパネルに内蔵されたタッチセンサ等からなる位置入力装置が入力部220を、液晶ディスプレイ等からなる表示装置が出力部230を、それぞれ構成する。
【0064】
以上のように構成される検索装置2は、制御部200の制御のもと、検索処理を行う。具体的には、図12A〜図12Cのフローチャートに示される手順で処理を実行する。
【0065】
本処理は、ユーザから入力された検索語を、検索装置2の入力部220が受け付けることを契機として、開始される。すなわち、キーボード255を用いて、ユーザが所望の検索語を入力し、検索する旨を指示することで、本処理が開始する。
【0066】
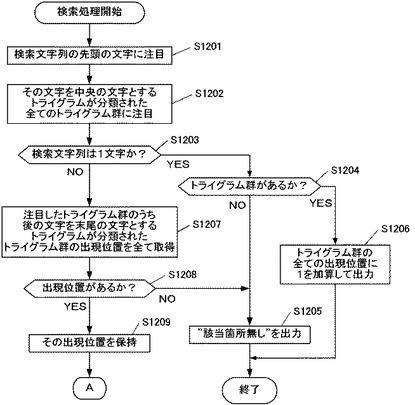
まず図12Aのフローチャートにおいて、検索処理が開始されると、まず取得部201が、入力された検索語の文字列(検索文字列)の先頭の文字に注目する(ステップS1201)。例えば、ユーザが「しすてむ」という検索語を入力した場合、取得部201は、先頭の文字「し」に注目する。あるいは、ユーザが「山」という1文字の検索語を入力した場合には、取得部201は、当該1文字「山」を先頭の文字として注目する。
【0067】
先頭の文字が注目されると、次に取得部201は、その文字を中央の文字とするトライグラムが分類された全てのトライグラム群に注目する(ステップS1202)。すなわち取得部201は、記憶部210に記憶されている転置インデックス900にアクセスし、その中に格納されているトライグラム群のうち、注目した文字を中央の文字とするトライグラムが分類された全てのトライグラム群(上記図9における1つの表全体に対応する全てのトライグラム群に相当)に注目する。上記の例では、注目した先頭の文字「し」や「山」を中央の文字とするトライグラムが分類された全てのトライグラム群に注目する。
【0068】
ここで取得部201は、検索文字列が1文字か否かを判定する(ステップS1203)。例えばユーザが「山」という検索語を入力したとき等のように、検索文字列が1文字の場合は(ステップS1203;YES)、検索語が2文字以上の場合とは異なるフローへ移行し、まず検索装置2の特定部202が、注目したトライグラム群があるか否かを判定する(ステップS1204)。すなわち、上記ステップS1202にて注目した、1文字の検索語(例えば「山」)を中央の文字とするトライグラムが分類されたトライグラム群が1つでも存在するか否かを判定する。
【0069】
1文字の検索語を中央の文字とするトライグラム群がない場合(ステップS1204;NO)、特定部202は、「該当箇所無し」を出力し(ステップS1205)、検索処理を終了する。文書データ300のいずれかの位置に当該1文字の検索語があるならば、その1文字を中央の文字とするトライグラムが分類されたトライグラム群があるはずであり、トライグラム群がないということは、文書データ300中に入力された1文字の検索語がないということになるからである。そのため、特定部202は、出力部230を介してモニタ256に「該当箇所無し」という文字を表示する等により、ユーザへその旨を出力する。
【0070】
一方、1文字の検索語を中央の文字とするトライグラム群がある場合(ステップS1204;YES)、特定部202は、該当するトライグラム群の全ての出現位置に1を加算して出力し(ステップS1206)、検索処理を終了する。後述する2文字以上の検索語の場合と異なり、検索語が1文字の場合には、注目したトライグラム群のトライグラムは当該1文字の検索語をその中央の文字として必ず含んでいるため、トライグラム群の出現位置に1を加算した位置(すなわち対応するトライグラムの2文字目)には必ず当該1文字の検索語が出現するからである。そのため、特定部202は、出力部230を介してモニタ256に表示する等により、該当するトライグラム群の全ての出現位置に1を加算した位置を、ユーザへ出力する。
【0071】
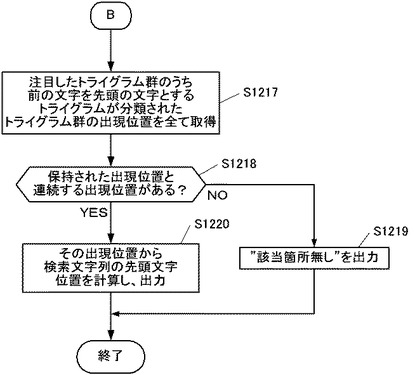
また一方で、入力された検索語の文字列が1文字でない場合(ステップS1203;NO)は、検索装置2の処理はステップS1207へと移行し、取得部201が、注目したトライグラム群のうち後の文字を末尾の文字とするトライグラムが分類されたトライグラム群の出現位置を全て取得する(ステップS1207)。すなわちここでは、取得部201は、上記ステップS1202にて注目した検索文字列の先頭の文字を中心の文字とするトライグラムが分類された全てのトライグラム群について、さらに検索文字列の後の文字(先頭から2文字目)を末尾の文字とするトライグラムが分類されたトライグラム群にまで絞り込みを行う。そして、取得部201は、絞り込んだトライグラム群について、転置インデックス900に格納されている全ての出現位置を取得する。
【0072】
具体的な例として、ユーザが「しすてむ」という検索語を入力した場合について説明する。この場合、上記ステップS1202にて注目したトライグラム群は、当該4文字の検索語の先頭の文字「し」を中心の文字とするトライグラムが分類された全てのトライグラム群であって、図13Aに表された文字「し」についての2次元状の表に配置されたトライグラム群全体に相当する。ここで本図における2次元状の表は、上記図9と同様に、転置インデックス900の構成をトライグラムの中央の文字ごとに2次元状に表したものである。
【0073】
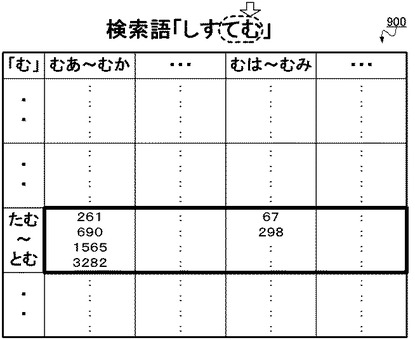
そして、上記ステップS1207にて絞り込んだトライグラム群は、当該検索語「しすてむ」の2番目の文字「す」を末尾の文字とするトライグラムが分類されたトライグラム群であって、図13Aにおける太線で囲われた部分のトライグラム群に相当する。すなわち、絞り込むべきトライグラム群は、「しす」という2文字を末尾の2文字とするトライグラム「*しす」(*はどの文字種でもよい)が分類されたトライグラム群であるので、図13Aにおける「しさ」〜「しせ」の欄の縦一列の全てのセルのトライグラム群に相当することになる。ステップS1207では、取得部201が、これら縦一列の全てのセル内の出現位置(191文字目、449文字目、6545文字目、11095文字目・・・、321文字目、1088文字目・・・等)を取得する。
【0074】
図12Aのフローチャートに戻って、取得部201が転置インデックス900から出現位置を取得すると、次に取得部201が、出現位置があるか否かを判定する(ステップS1208)。すなわち、取得した出現位置がそもそも1つでも存在するか否かを判定する。出現位置がない場合は(ステップS1208;NO)、検索対象の文書データ300中に入力された検索文字列が存在しないということを意味するため、特定部202が、「該当箇所無し」を出力し(ステップS1205)、検索処理を終了する。すなわち特定部202は、出力部230を介してモニタ256に「該当箇所無し」という文字を表示する等により、ユーザへその旨を出力する。
【0075】
一方、出現位置が1つでも存在する場合は(ステップS1208;YES)、特定部202が、その出現位置を保持する(ステップS1209)。すなわち、転置インデックス900から取得した全ての出現位置を、RAM253等に一時的に保持する。その後、検索処理は図12Bのフローチャートへ移行する。
【0076】
検索処理が図12Bのフローチャートへ移行すると、次に取得部201は、検索文字列の次の文字に注目し(ステップS1210)、その文字を中央の文字とするトライグラムが分類された全てのトライグラム群に注目する(ステップS1211)。具体的にユーザが「しすてむ」という4文字の検索語を入力した場合では、取得部201は、先頭の文字の次の文字、すなわち2文字目の文字「す」に注目する。そして、転置インデックス900内に格納された当該文字「す」を中心の文字とするトライグラムが分類された全てのトライグラム群に注目する。ここで注目するトライグラム群は、図13Bに表された文字「す」についての2次元状の表に配置されたトライグラム群全体に相当する。
【0077】
図12Bのフローチャートにおいて、さらに取得部201は、検索文字列の注目した文字に対して、後の文字があるか否かを判定する(ステップS1212)。上記検索語「しすてむ」での例では、注目した文字「す」の後にさらに「て」と「む」の文字が存在しているため、取得部201は後の文字があると判定する。
【0078】
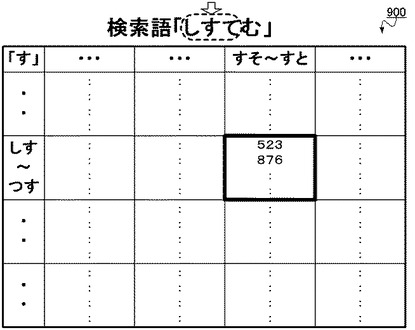
後の文字があると判定すると(ステップS1212;YES)、取得部201は、注目したトライグラム群のうち、前の文字を先頭の文字とし、後の文字を末尾の文字とするトライグラムが分類されたトライグラム群の出現位置を全て取得する(ステップS1213)。すなわち、上記検索語「しすてむ」での例では、注目した2文字目の文字「す」を中央の文字、前の文字「し」を先頭の文字、後の文字「て」を末尾の文字とするトライグラム「しすて」が分類されたトライグラム群の出現位置を全て、取得部201が取得する。
【0079】
図13Bに表された文字「す」についての2次元状の表では、当該「しすて」というトライグラムは、先頭の2文字(縦軸)が「しす」〜「つす」、末尾の2文字(横軸)が「すそ」〜「すと」の範囲に該当するものであるため、当該トライグラムが分類されたトライグラム群は、太線で囲われた1つのセルに相当するものとなる。従って、取得部201は、当該セル内の出現位置(523文字目、876文字目・・・等)を全て取得する。
【0080】
図12Bのフローチャートに戻って、出現位置を取得すると、次に特定部202が、保持された出現位置と連続する出現位置があるか否かを判定する(ステップS1214)。すなわち特定部202は、上記ステップS1209にて保持した検索語の先頭の文字についてのトライグラム群の出現位置と、取得した検索語の2番目の文字についてのトライグラム群の出現位置とを比較して、保持した出現位置の値に1だけ加算した値の出現位置があるか否かを判定する。保持した出現位置と取得した出現位置の中に、検索語の文字列を構成するトライグラムの出現位置が含まれているならば、それらは検索語の文字列を構成するように連続しているはずだからである。
【0081】
そのため、連続する出現位置がなければ(ステップS1214;NO)、検索対象の文書データ300には検索語が含まれていないということになり、特定部202は、「該当箇所無し」を出力し(ステップS1215)、検索処理を終了する。すなわち特定部202は、出力部230を介してモニタ256に「該当箇所無し」という文字を表示する等により、ユーザへその旨を出力する。
【0082】
一方、連続する出現位置があれば(ステップS1214;YES)、特定部202は、保持する出現位置を連続する出現位置と入れ替える(ステップS1216)。すなわち、特定部202は、検索文字列の2番目の文字についてのトライグラム群の出現位置のうち、連続すると判定した出現位置を、それまで保持していた先頭の文字についてのトライグラム群の出現位置と入れ替えて、RAM253等に保持する。
【0083】
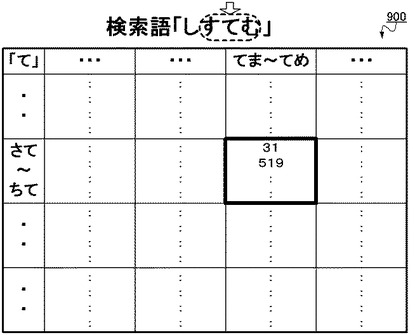
その後、検索処理は再びステップS1210へと戻る。すなわち、検索装置2は、検索文字列の次の文字に注目し、当該注目した文字について、ステップS1211以降の処理を繰り返す。上記検索語「しすてむ」での例では、取得部201は、3文字目の文字「て」に注目し、その前後の文字とともに構成するトライグラム「すてむ」が分類されたトライグラム群の出現位置を、転置インデックス900から取得する。
【0084】
具体的に図13Cに表された文字「て」についての2次元状の表では、当該「すてむ」というトライグラムは、先頭の2文字(縦軸)が「さて」〜「ちて」、末尾の2文字(横軸)が「てま」〜「てめ」の範囲に該当するものであるため、当該トライグラムが分類されたトライグラム群は、太線で囲われたセルに相当するものとなる。従って、取得部201は、当該セル内の出現位置(31文字目、519文字目・・・等)を全て取得する。
【0085】
その後同様に、特定部202が出現位置の連続性を判定し(ステップS1214)、連続する出現位置を保持して(ステップS1216)、再び検索処理はステップS1210へと戻る。そして、検索文字列の次の文字、すなわち検索語「しすてむ」の最後の文字「む」に注目し(ステップS1210)、当該文字「む」についてのトライグラム群に注目する(ステップS1211)。注目した文字が検索語の最後の文字の場合には、その後の文字はないため(ステップS1212;NO)、検索処理は図12Cのフローチャートへと移行する。
【0086】
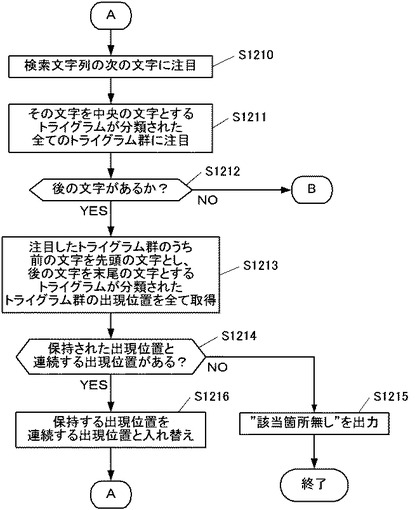
検索処理が図12Cのフローチャートへ移行すると、次に取得部201は、注目したトライグラム群のうち、前の文字を先頭の文字とするトライグラムが分類されたトライグラム群の出現位置を全て取得する(ステップS1217)。すなわち、上記検索語「しすてむ」での例では、注目した最後の文字「む」を中央の文字、前の文字「て」を先頭の文字とするトライグラム「てむ*」(*はどの文字種でもよい)が分類されたトライグラム群の出現位置を全て、取得部201が取得する。
【0087】
図13Dに表された文字「む」についての2次元状の表では、当該「てむ*」というトライグラムは、先頭の2文字(縦軸)が「たむ」〜「とむ」の範囲に該当するものであるため、当該トライグラムが分類されたトライグラム群は、太線で囲われた横一列のセルに相当するものとなる。従って、取得部201は、当該セル内の出現位置(261文字目、690文字目、1565文字目、3282文字目・・・、67文字目、298文字目・・・等)を全て取得する。
【0088】
図12Cのフローチャートに戻って、最後の文字についての出現位置を取得すると、上記ステップS1214と同様に、特定部202が、保持された出現位置と連続する出現位置があるか否かを判定する(ステップS1218)。取得された出現位置が入力された検索語の文字列を構成するものであるか否かを判定するためである。
【0089】
連続する出現位置がなければ(ステップS1218;NO)、検索対象の文書データ300には検索語が含まれていないということになるため、特定部202は、「該当箇所無し」を出力し(ステップS1219)、検索処理を終了する。すなわち特定部202は、出力部230を介してモニタ256に「該当箇所無し」という文字を表示する等により、ユーザへその旨を出力する。
【0090】
一方、連続する出現位置があれば(ステップS1218;YES)、入力された検索語が文書データ300中に含まれているということになる。そのため、特定部202は、その出現位置から検索文字列の先頭文字位置を計算し、出力する(ステップS1220)。すなわち特定部202は、連続すると判定した出現位置に対応する検索文字列の先頭文字位置を計算し、それを検索結果としてユーザへ出力する。連続する出現位置が複数存在した場合は、特定部202は、原則的には全てについて検索文字列の先頭文字位置を計算し、出力する。その後、本フローチャートにて示した検索装置2の処理は終了する。
【0091】
このとき出力結果は、出力部230を介しモニタ256に表示される等によって、ユーザへと出力される。ユーザは、当該出力結果により、記憶部210に記憶された文書データ300中において、自身が入力した検索語が出現する位置を取得することができ、種々に利用することができるようになる。
【0092】
以上のような構成により、本実施形態の検索装置2は、所望の検索文字列に対して、それを構成する文字ごとに前後の文字とあわせて転置インデックス900から出現位置を取得し、出現位置の連続性を判定することで、当該検索文字列が文書データ300中のどこに出現するのかを特定する。ここで用いられる転置インデックス900は、トライグラムがその文字列に基づいて分類されたトライグラム群を単位として構成されている。そのため、検索装置2は、トライグラムを単独で単位としたものに比べ、搭載される転置インデックス900のデータサイズを抑え、検索処理の速度をなるべく低下することなく検索を実行できる。
【0093】
これは、例えば電子辞書や携帯電話等のような小型の電子機器のような使用できるデータ容量が限られた環境においてはとくに、転置インデックス900のデータサイズを抑制しつつ高速な検索処理を実現する上で効果的である。
【0094】
なお、上記実施形態は一例であり、本発明の適用範囲はこれに限られない。すなわち、種々の応用が可能であり、あらゆる実施の形態が本発明の範囲に含まれる。
【0095】
例えば、上記実施形態では、検索装置2は、ROM252のような記憶部210内に文書データ300等を記憶した。しかしこれに限られず、検索装置2は、ハードディスク等の大容量記憶装置やDVD−ROMドライブを備え、文書データ300等がハードディスクやDVD−ROM等に記憶されるようにしてもよい。あるいは、検索装置2は、ネットワークに接続され、文書データ300等がネットワーク上に存在するようにしてもよい。
【0096】
また、上記実施形態では、検索装置2は、ユーザが検索語を入力する入力部220や検索結果を出力する出力部230は、制御部200や記憶部210と同一の装置内に存在した。しかしこれに限られず、入力部220と出力部230は、検索装置2の外部にあってもよい。すなわち、例えば図14に示すように、検索装置2は入力部220と出力部230を備えず、これらを備える端末装置3とネットワーク150を介して接続されるようにし、オンライン型の電子辞書のような情報機器として構成するようにしてもよい。
【0097】
このとき、検索装置2と端末装置3は、それぞれが備える通信部240a,240bにより、ネットワーク150を介して互いにデータを通信しあう。すなわち、端末装置3のユーザが入力した検索語は、検索装置2へと送信され、制御部200により検索処理が実行される。その後、検索結果の情報が再び端末装置3へと送信され、端末装置3のユーザへと出力される。このような構成をとることで、検索装置2内の文書データ300等を一括して管理して複数のユーザに利用できるようになり、またユーザ側の端末装置3は、文書データ300等を保持する必要がないため、データサイズを抑えることができるといった利点がある。
【0098】
また、上記実施形態では、検索装置2として電子辞書のような小型の情報処理装置を想定して説明した。しかしこれに限られず、検索装置2は、ビジネス用・家庭用の一般的なコンピュータ装置や、携帯電話等の他の情報機器であってもよい。また、電子辞書における検索に限られず、種々の電子データを検索するものであってもよい。例えば、一般的なコンピュータ装置において、ハードディスク等の大容量記憶装置やDVD−ROM等に記憶された電子ファイルのうちから、所望の検索語を含む電子ファイルを検索するものであってもよい。あるいは、ネットワークと接続され、ネットワーク上に存在するウェブページを検索するものであってもよい。
【0099】
また、生成装置1について、上記実施形態での生成装置1は、ハードディスク154のような記憶部110に記憶されている文書データ300をもとにして転置インデックス900を生成し、当該生成された転置インデックス900を記憶部110に記憶した。しかし、これら文書データ300は、生成装置1内に備えられた記憶部110に記憶されることに限られず、通信部140を介して接続されるネットワーク150上に存在していてもよいし、あるいはDVD−ROMドライブ157に搭載されるDVD−ROM内に記憶されていてもよい。
【0100】
また、上記実施形態では、文書データ300は、「見出し語」と「説明文」とから構成された。しかしこれらに限られず、様々な要素から構成されてもよい。例えば、「見出し語」を説明するための図や表を有するものであってもよい。あるいは、辞書における検索以外の一般的な電子ファイル等の検索では、このような「見出し語」と「説明文」といった構成要素に限らず、文書データ300は様々な形式で文字列データを有していてもよい。
【0101】
また、上記実施形態では、分類部102がトライグラムを中間トライグラム群およびトライグラム群に分類する際、1つの中間トライグラム群およびトライグラム群に分類されるトライグラムに対応付けられた出現位置の個数の和が所定の個数を超えないように分類した。しかし出現位置の個数ではなく、文字種の個数に着目して分類してもよい。すなわち、分類部102は、
(a)共通な中央の文字を有するトライグラムがまとめられた統合トライグラム群ごとに、トライグラムを先頭の文字順に並べ、1つの中間トライグラム群に分類されるトライグラムの先頭の文字種の個数が所定の個数を超えないように、トライグラムを並び順に中間トライグラム群に分類し、
(b)さらに中間トライグラム群ごとに、トライグラムを末尾の文字順に並べ、1つのトライグラム群に分類されるトライグラムの末尾の文字種の個数が所定の個数を超えないように、トライグラムを並び順にトライグラム群に分類してもよい。
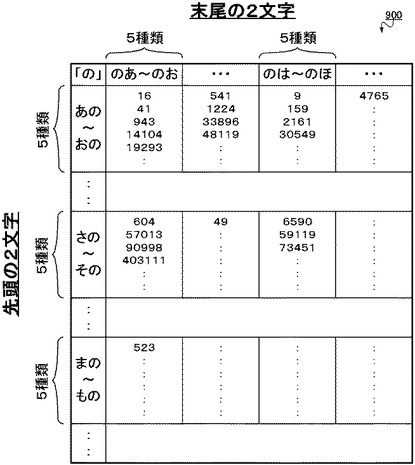
【0102】
具体的に、1つの中間トライグラム群およびトライグラム群に分類されるトライグラムの先頭および末尾の文字種の個数を5種類とした場合について説明する。このとき、例えば文字「の」を中央の文字とするトライグラムについて、分類部102は、5種類の先頭の文字「あ」〜「お」を有するトライグラムを最初の中間トライグラム群としてまとめ、その後「か」〜「こ」、「さ」〜「そ」・・・というように、先頭の文字について5種類ずつ中間トライグラム群にまとめていく。さらに分類部102は、中間トライグラム群ごとに、5種類の末尾の文字「あ」〜「お」を有するトライグラムを最初のトライグラム群としてまとめ、その後「か」〜「こ」、「さ」〜「そ」・・・というように、末尾の文字について5種類ずつトライグラム群にまとめていく。
【0103】
その結果、生成される転置インデックス900について、例えば文字「の」についてのトライグラム群と出現位置との対応関係を2次元状に表すと、図15のようになる。すなわち、当該2次元状の表の縦軸と横軸の構成単位は、「あの」〜「おの」・・・「さの」〜「その」・・・等のように、先頭および末尾についての5個の文字種ごとに区切られたものとなる。
【0104】
このように、先頭および末尾の文字種の個数に基づいてトライグラム群を作成していくことで、各トライグラム群に分類されるトライグラムの種類の個数をなるべく同じ個数にすることができる。これにより、トライグラム群の出現位置の個数がなるべく同じ個数になるように分類された場合に比べ、出現位置の個数にはばらつきがでるが、各トライグラム群のトライグラムの個数が均一化されるため、一般的に扱いやすい転置インデックス900を生成することができる。
【0105】
なお、本発明に係る機能を実現するための構成を予め備えた転置インデックスの生成装置および当該転置インデックスを用いた検索装置として提供できることはもとより、プログラムの適用により、既存のパーソナルコンピュータや情報端末機器等を、本発明に係る生成装置および検索装置として機能させることもできる。すなわち、上記実施形態で例示した生成装置1および検索装置2による各機能構成を実現させるための生成プログラムまたは検索プログラムを、既存のパーソナルコンピュータや情報端末機器等を制御するCPU等が実行できるように適用することで、それぞれ本発明に係る生成装置1および検索装置2として機能させることができる。また、本発明に係る転置インデックスの生成方法および当該転置インデックスを用いた検索方法は、それぞれ生成装置1および検索装置2を用いて実施できる。
【0106】
また、このようなプログラムの適用方法は任意であり、例えば、CD−ROMやDVD−ROM、メモリカードなどのコンピュータ読み取り可能な記憶媒体に格納して適用できる他、例えば、インターネットなどの通信媒体を介して適用することもできる。
【0107】
以上、本発明の好ましい実施形態について説明したが、本発明は係る特定の実施形態に限定されるものではなく、本発明には、特許請求の範囲に記載された発明とその均等の範囲が含まれる。以下に、本願出願の当初の特許請求の範囲に記載された発明を付記する。
【0108】
(付記1)
文書データのうちから「3文字の文字列であるトライグラム」を、当該文書データ中での出現位置と対応付けて、抽出する抽出ステップと、
前記抽出されたトライグラムのうち中央の文字が共通なトライグラムを、先頭および末尾の文字に基づいて、トライグラム群に分類する分類ステップと、
前記分類されたトライグラム群のそれぞれに、当該トライグラム群に分類されたトライグラムに対応付けられた出現位置を対応付けて、転置インデックスを生成する生成ステップと、
を備えることを特徴とする転置インデックスの生成方法。
【0109】
(付記2)
前記分類ステップでは、
(a)前記抽出されたトライグラムのうち中央の文字が共通なトライグラムを、先頭の文字に基づいて、中間トライグラム群に分類し、
(b)前記中間トライグラム群に分類されたトライグラムを、末尾の文字に基づいて、トライグラム群に分類する、
ことを特徴とする付記1に記載の転置インデックスの生成方法。
【0110】
(付記3)
前記分類ステップでは、
(a)前記抽出されたトライグラムのうち中央の文字が共通なトライグラムを、前記中間トライグラム群に分類されるトライグラムに対応付けられた出現位置の個数の和が所定の第1の個数を超えないように分類し、
(b)前記中間トライグラム群に分類されたトライグラムを、前記トライグラム群に分類されるトライグラムに対応付けられた出現位置の個数が所定の第2の個数の和を超えないように分類する、
ことを特徴とする付記2に記載の転置インデックスの生成方法。
【0111】
(付記4)
前記分類ステップでは、
(a)前記抽出されたトライグラムのうち中央の文字が共通なトライグラムを、前記中間トライグラム群に分類されるトライグラムの先頭の文字種の個数が所定の第3の個数を超えないように分類し、
(b)前記中間トライグラム群に分類されたトライグラムを、前記トライグラム群に分類されるトライグラムの末尾の文字種の個数が所定の第4の個数を超えないように分類する、
ことを特徴とする付記2に記載の転置インデックスの生成方法。
【0112】
(付記5)
付記1から4のいずれか1つに記載の生成方法によって生成された転置インデックスを用いる検索方法であって、
所望の検索文字列を構成するトライグラムのそれぞれについて、前記転置インデックスから、当該トライグラムが分類されたトライグラム群に対応付けられた出現位置を取得する取得ステップと、
前記取得された出現位置に基づいて、前記検索文字列の前記文書データにおける出現位置を特定する特定ステップと、
を備えることを特徴とする検索方法。
【0113】
(付記6)
前記取得ステップでは、
(p)前記検索文字列の先頭の文字を中央の文字とし、先頭から2番目の文字を末尾の文字とするトライグラムが分類されたトライグラム群に対応付けられた出現位置を取得し、
(q)前記検索文字列の末尾の文字を中央の文字とし、末尾から2番目の文字を先頭の文字とするトライグラムが分類されたトライグラム群に対応付けられた出現位置を取得する、
ことを特徴とする付記5に記載の検索方法。
【0114】
(付記7)
文書データのうちから「3文字の文字列であるトライグラム」を、当該文書データ中での出現位置と対応付けて、抽出する抽出手段と、
前記抽出されたトライグラムのうち中央の文字が共通なトライグラムを、先頭および末尾の文字に基づいて、トライグラム群に分類する分類手段と、
前記分類されたトライグラム群のそれぞれに、当該トライグラム群に分類されたトライグラムに対応付けられた出現位置を対応付けて、転置インデックスを生成する生成手段と、
を備えることを特徴とする生成装置。
【0115】
(付記8)
付記1から4のいずれか1つに記載の生成方法によって生成された転置インデックスを用いる検索装置であって、
所望の検索文字列を構成するトライグラムのそれぞれについて、前記転置インデックスから、当該トライグラムが分類されたトライグラム群に対応付けられた出現位置を取得する取得手段と、
前記取得された出現位置に基づいて、前記検索文字列の前記文書データにおける出現位置を特定する特定手段と、
を備えることを特徴とする検索装置。
【0116】
(付記9)
コンピュータを、
文書データのうちから「3文字の文字列であるトライグラム」を、当該文書データ中での出現位置と対応付けて、抽出する抽出手段、
前記抽出されたトライグラムのうち中央の文字が共通なトライグラムを、先頭および末尾の文字に基づいて、トライグラム群に分類する分類手段、
前記分類されたトライグラム群のそれぞれに、当該トライグラム群に分類されたトライグラムに対応付けられた出現位置を対応付けて、転置インデックスを生成する生成手段、
として機能させることを特徴とするコンピュータプログラム。
【0117】
(付記10)
コンピュータを、
付記1から4のいずれか1つに記載の生成方法によって生成された転置インデックスを用いる検索装置として機能させるコンピュータプログラムであって、
前記コンピュータを、
所望の検索文字列を構成するトライグラムのそれぞれについて、前記転置インデックスから、当該トライグラムが分類されたトライグラム群に対応付けられた出現位置を取得する取得手段、
前記取得された出現位置に基づいて、前記検索文字列の前記文書データにおける出現位置を特定する特定手段、
として機能させることを特徴とするコンピュータプログラム。
【符号の説明】
【0118】
1…生成装置、2…検索装置、3…端末装置、100…制御部、101…抽出部、102…分類部、103…生成部、110…記憶部、120…入力部、130…出力部、140…通信部、150…ネットワーク、151…CPU、152…ROM、153…RAM、154…ハードディスク、155…キーボード、156…モニタ、157…DVD−ROMドライブ、158…通信装置、200…制御部、201…取得部、202…特定部、210…記憶部、220…入力部、230…出力部、240a,240b…通信部、251…CPU、252…ROM、253…RAM、255…キーボード、256…モニタ、300…文書データ、900…転置インデックス
【技術分野】
【0001】
本発明は、Nグラム検索に関し、とくにデータサイズを抑えつつ高速な検索処理を実現するのに好適な転置インデックスの生成方法および生成装置、当該転置インデックスを用いた検索方法および検索装置、ならびにコンピュータプログラムに関する。
【背景技術】
【0002】
文書の電子化の増大に伴い、これまでに蓄積されてきた大量の文書群から所望の文書を見つけ出す検索技術の重要性が高まっている。
【0003】
大量の文書群を対象とした検索では、検索処理の高速化のため、検索対象となる文書群に含まれる単語等を索引単位として、索引ファイルを作成することが一般的である。あらかじめ作成された索引ファイル(以下、転置インデックスと呼称する)を検索時に用いることで、検索のたびに大量の文書群にアクセスする必要がなくなり、高速な検索処理が実現されるからである。
【0004】
英語などの多くの言語においては、単語を索引単位として転置インデックスを作成することが一般的である。しかし、日本語の場合、スペース等によって単語の切れ目が明示的に示されないため、しばしば、Nグラムを索引単位とする方法が用いられる。Nグラムとは、連続するN文字からなる部分文字列のことである。Nグラムによる転置インデックスの作成は、単語を認識する必要がなく、文字列にのみ基づくため、日本語の文書を検索対象とした検索に適している。
【0005】
このようなNグラムを用いた検索では、検索処理の速度や転置インデックスのデータサイズは、索引単位として採用するNグラムのNの値によって変化する。例えば、非特許文献1には、異なるNの値における検索処理の高速化の比較が記載されている。
【先行技術文献】
【非特許文献】
【0006】
【非特許文献1】小川泰嗣,松田透,”n−gram索引を用いた効率的な文書検索法”,電子情報通信学会論文誌(D-I),Vol.J82-D-I,No.1,pp.121-129,1999年1月
【発明の概要】
【発明が解決しようとする課題】
【0007】
Nグラムを用いた検索では、転置インデックスの単位として採用するNの値を大きくすると、原則として検索処理の速度は上がる。一方で、Nの値を大きくすると、文書から抽出されるNグラムの種類が多くなるため、転置インデックスのデータサイズは増大する。そのため、検索処理の高速化と転置インデックスのデータサイズの抑制とは両立しにくかった。しかし、転置インデックスのデータサイズをなるべく抑えつつ、検索処理の高速化も実現したい、との要望がある。
【0008】
本発明は、以上のような課題を解決するためのものであり、データサイズを抑えつつ高速な検索処理を実現するのに好適な転置インデックスの生成方法および生成装置、当該転置インデックスを用いた検索方法および検索装置、ならびに、コンピュータプログラムを提供することを目的とする。
【課題を解決するための手段】
【0009】
上記目的を達成するため、本発明にかかる転置インデックスの生成方法は、
文書データのうちから「3文字の文字列であるトライグラム」を、当該文書データ中での出現位置と対応付けて、抽出する抽出ステップと、
前記抽出されたトライグラムのうち中央の文字が共通なトライグラムを、先頭および末尾の文字に基づいて、トライグラム群に分類する分類ステップと、
前記分類されたトライグラム群のそれぞれに、当該トライグラム群に分類されたトライグラムに対応付けられた出現位置を対応付けて、転置インデックスを生成する生成ステップと、
を備えることを特徴とする。
【発明の効果】
【0010】
本発明によれば、データサイズを抑えつつ高速な検索処理を実現するのに好適な転置インデックスの生成方法および生成装置、当該転置インデックスを用いた検索方法および検索装置、ならびに、コンピュータプログラムを提供することができる。
【図面の簡単な説明】
【0011】
【図1】本発明の実施形態に係る転置インデックスの生成装置の概要構成を示す図である。
【図2】本発明の実施形態に係る転置インデックスの生成装置の物理構成を示す図である。
【図3】本発明の実施形態に係る文書データ構成を示す図である。
【図4】本発明の実施形態に係る生成装置の処理の流れを示すフローチャートである。
【図5】本発明の実施形態において、文書データから抽出されたトライグラムとその出現位置の例を示す図である。
【図6】本発明の実施形態において、トライグラムが統合トライグラム群に分類された様子を示す図である。
【図7】本発明の実施形態において、統合トライグラム群のトライグラムが中間トライグラム群に分類される様子を示す図である。
【図8】本発明の実施形態において、中間トライグラム群のトライグラムがトライグラム群に分類される様子を示す図である。
【図9】本発明の実施形態において、転置インデックスの構成をトライグラムの中央の文字ごとに2次元状に表した図である。
【図10】本発明の実施形態に係る検索装置の概要構成を示す図である。
【図11】本発明の実施形態に係る検索装置の物理構成を示す図である。
【図12A】本発明の実施形態に係る検索装置の処理の流れを示す第1のフローチャートである。
【図12B】本発明の実施形態に係る検索装置の処理の流れを示す第2のフローチャートである。
【図12C】本発明の実施形態に係る検索装置の処理の流れを示す第3のフローチャートである。
【図13A】本発明の実施形態に係る検索処理において、転置インデックスから出現位置が取得される様子を示す第1の図である。
【図13B】本発明の実施形態に係る検索処理において、転置インデックスから出現位置が取得される様子を示す第2の図である。
【図13C】本発明の実施形態に係る検索処理において、転置インデックスから出現位置が取得される様子を示す第3の図である。
【図13D】本発明の実施形態に係る検索処理において、転置インデックスから出現位置が取得される様子を示す第4の図である。
【図14】本発明に係る検索装置の構成概要について、別の例を示す図である。
【図15】本発明に係る転置インデックスの構成について、別の例を示す図である。
【発明を実施するための形態】
【0012】
以下、本発明の実施形態について、図面を参照して説明する。なお、以下に説明する実施形態は説明のためのものであり、本発明の範囲を制限するものではない。したがって、当業者であれば下記の各構成要素を均等なものに置換した実施形態を採用することが可能であるが、これらの実施形態も本発明の範囲に含まれる。また、以下の説明では、本発明の理解を容易にするため、重要でない公知の技術的事項の説明を適宜省略する。
【0013】
まず、本実施形態に係る転置インデックスの生成装置1が実現される情報処理装置は、図1に示されるような構成をとる。すなわち、生成装置1は、制御部100と、記憶部110と、入力部120と、出力部130と、通信部140と、を備える。一方、当該生成装置1は、物理的には図2に示されるように構成され、CPU(Central Processing Unit)151と、ROM(Read Only Memory)152と、RAM(Random Access Memory)153と、ハードディスク154と、キーボード155と、モニタ156と、DVD−ROMドライブ157と、通信装置158と、を備える。以下、図1および図2を参照して、生成装置1の構成要素の説明をする。
【0014】
制御部100は、生成装置1全体の動作を制御し、各構成要素と接続され、制御信号やデータをやりとりする。すなわち、制御部100は、記憶部110、入力部120、出力部130、通信部140と接続され、これら各部の機能を活用しながら、転置インデックスの生成処理を実行する。
【0015】
ここで制御部100は、抽出部101と、分類部102と、生成部103と、を備える。これらの各部は、詳細には後述するように、記憶部110に記憶されている文書データ300をもとにして、転置インデックス900を生成する処理を実行する。
【0016】
このような制御部100(抽出部101、分類部102、生成部103)は、例えばCPU151によって構成される。ここでCPU151は、命令やデータを転送するための伝送経路であるシステムバスにより各構成要素と相互に接続され、ROM152に記録されている生成装置1全体の動作制御に必要なコンピュータプログラムや各種データに従って動作する。そしてCPU151は、ROM152から読み出したコンピュータプログラムやデータ、その他処理の進行に必要なデータを、RAM153に一時的に記憶しながら、各種動作を制御する。このようにCPU151がROM152やRAM153と協働することで、制御部100は、生成装置1全体の動作を制御する。
【0017】
記憶部110は、例えばハードディスク154のような大容量外部記憶装置によって構成され、制御部100が転置インデックス900を生成する処理のために必要な各種データ、具体的には後述する検索装置によって検索対象とされる文書データ300等が、記憶される。また、記憶部110は、生成装置1の処理によって生成された転置インデックス900も記憶する。
【0018】
ここで、記憶部110にあらかじめ記憶される文書データ300は、図3に示されるように、個々の文書データ300a〜300c等から構成され、さらに文書データ300a〜300c等はそれぞれ、「見出し語」と「説明文」とから構成される。すなわち、文書データ300a〜300c等は、辞書を構成する構成単位であり、「見出し語」とは、当該辞書の見出しとなる1つの語句であり、1つの文書データ300に対して1つの見出し語が対応付けられる。そして、「見出し語」には当該見出し語を説明する「説明文」が対応付けられ、これらを合わせて1つの文書データ300を構成する。
【0019】
図1および図2に戻って、記憶部110が記憶するこれらのデータは、例えば生成装置1のDVD−ROMドライブ157を介して、あるいは通信部140によって接続されるネットワーク150を介して、外部とやり取りされる。
【0020】
入力部120は、例えばキーボード155のような入力装置によって構成され、ユーザからの入力を受け付ける。受け付けられた入力情報は、制御部100へと供給される。本実施形態では、転置インデックス900を生成するためのユーザからの命令を受け付ける。
【0021】
出力部130は、例えばモニタ156のような表示装置によって構成され、制御部100が処理を行った結果をユーザへ出力する。本実施形態では、抽出部101、分類部102、生成部103のそれぞれが行う転置インデックス900の生成処理の経過や結果がモニタ156に表示される。これにより、ユーザは当該生成処理の経過や結果についての情報を得ることができる。
【0022】
通信部140は、生成装置1をインターネット等のネットワーク150に接続し、制御部100の制御のもと、ネットワーク150を介してデータをやり取りする。このような通信部140は、例えばモデム等の適宜の通信装置158によって構成される。
【0023】
以上のように構成される生成装置1は、制御部100の制御のもと、転置インデックス900の生成処理を行う。具体的には、図4のフローチャートに示される手順で処理を実行する。
【0024】
本処理は、ユーザからの転置インデックス900を生成する旨の指示を、生成装置1の入力部120が受け付けることを契機として、開始される。すなわち、キーボード155を用いて、ユーザが転置インデックス900を生成する旨を指示することで、本処理が開始する。
【0025】
処理が開始されると、まず抽出部101が、記憶部110に記憶された文書データ300からトライグラム(N=3のNグラム)を、その出現位置を対応付けて抽出する(ステップS401)。ここでNグラムとは、N文字の文字列(Nは自然数)を意味し、N=3のNグラム(トライグラム)とは、3文字の文字列をいう。すなわち、抽出部101は、文書データ300に含まれる見出し語や説明文を構成する文字列から、3文字の文字列(トライグラム)を抽出可能な数だけ抽出する。
【0026】
一般的に、文字数がX文字の文字列からは、X−N+1個のNグラムが抽出されるため、N=3の場合は、X−2個(X−3+1個)のバイグラムが抽出される。例えば、「携帯電話」という4文字の文字列からは、「携帯電」「帯電話」という2個(4−2個)のトライグラムが抽出され、「ボールペン」という5文字の文字列からは、「ボール」「ールペ」「ルペン」という3個(5−2個)のトライグラムが抽出される。
【0027】
このとき抽出部101は、それぞれに文書データ300中での出現位置を対応付けつつ、トライグラムを抽出する。すなわち、抽出されたトライグラムが、抽出元の文書データ300中の先頭文字から数えて何文字目に位置していたかの情報を、当該トライグラムに対応付けながら抽出する。
【0028】
例えば、文書データ300を構成する文字列が、「ボールペン」という5文字の文字列から始まっていたとした場合は、抽出されたトライグラムのうち、トライグラム「ボール」には1(文字目)、トライグラム「ールペ」には2(文字目)、トライグラム「ルペン」には3(文字目)、という出現位置を表す値が対応付けられる。ここで、文書データ300中に同一のトライグラムが複数出現する場合には、当該トライグラムに複数の出現位置が対応付けられることになる。
【0029】
出現位置の対応付け処理が行われると、具体的には図5に示されるように、文書データ300から抽出された各トライグラムとその出現位置との対応関係が形成される。本図の対応関係からは、例えば「ボール」というトライグラムは、文書データ300の先頭から1文字目、22文字目、33文字目、87文字目、120文字目に出現し、また「リンゴ」というトライグラムは199文字目と219文字目に出現するということが分かる。
【0030】
これらの抽出されたトライグラムやそれらの出現位置は、RAM153等に一時的に保持される。
【0031】
トライグラムが抽出されると、次に分類部102が、抽出されたトライグラムのうち、中央の文字が共通なトライグラムを統合トライグラム群としてまとめる(ステップS402)。すなわち、分類部102は、トライグラムの3文字の文字列のうち、中央の(2番目の)文字に着目し、同じ文字を中央の文字として有するトライグラムを1つの統合トライグラム群としてまとめる。
【0032】
まとめられた統合トライグラム群は、例えば図6に示されるようになる。すなわち、「あ」を中央の文字として有するトライグラムが分類された統合トライグラム群、「の」を中央の文字として有するトライグラムが分類された統合トライグラム群、「ン」を中央の文字として有するトライグラムが分類された統合トライグラム群、「山」を中央の文字として有するトライグラムが分類された統合トライグラム群・・・というように、文書データ300から抽出されたトライグラムの中央の文字の種類の数だけ、統合トライグラム群を作成する。
【0033】
統合トライグラム群にトライグラムがまとめられると、次に分類部102は、統合トライグラム群ごとにトライグラムを先頭の文字順に並べる(ステップS403)。ここで文字順とは、いわゆる辞書順であり、五十音順やアルファベット順等のような文字列の並び順をいう。日本語のように複数の文字種がある場合にはひらがな、カタカナ、漢字、アルファベット・・・といったように文字種に順序を定めてもよい。すなわち、中央の文字が共通なトライグラムについて、先頭の文字に着目し、このような辞書順に並べる。
【0034】
具体的には図7に示すように、分類部102は、例えば文字「の」を共通な中央の文字とする統合トライグラム群にまとめられたトライグラムについて、それぞれの先頭の文字に着目し、先頭の文字が「あ」「い」・・・「お」・・・「ん」・・・「意」・・・といった順になるように並べる。このようなトライグラムを先頭の文字について辞書順に並べる処理を、すべての統合トライグラム群に対して実行する。
【0035】
図4のフローチャートに戻って、次に分類部102は、並べられたトライグラムを、出現位置が所定の個数を超えないように、並び順に中間トライグラム群に分類する(ステップS404)。すなわち分類部102は、先頭の文字順に並べられたトライグラムについて、最初のトライグラムから並び順に1つ以上のトライグラムをひとまとめにし、中間トライグラム群としてまとめていく。
【0036】
具体的に、図7のように「の」を共通な中央の文字とする統合トライグラム群の例では、先頭の文字順に並べられたトライグラムについて、最初に並べられたトライグラム「あのあ」から順に、「あのい」、「あのう」・・・「おの輪」までを1つの中間トライグラム群Aとしてまとめる。そして、次のトライグラム「かのあ」から、並べられた順に「けの和」まで、中間トライグラム群Bとしてまとめる。このような処理を繰り返して、中間トライグラム群X、中間トライグラム群Y・・・というように、並べられた最後のトライグラムまで、中間トライグラム群としてまとめていく。
【0037】
なおこのとき、分類が複雑になることを防ぐため、分類部102は、先頭の文字が同一のトライグラムは同一の中間トライグラム群にまとめられるようにする。例えば、「かのあ」と「かのわ」という2つのトライグラムは、同一の先頭の文字「か」を有するため、異なる中間トライグラム群に分けて分類されるのではなく、トライグラム「かのあ」が分類された中間トライグラム群には必ずトライグラム「かのわ」も分類されるようにする。
【0038】
さらにこのとき、1つの中間トライグラム群にまとめられるトライグラムの個数が、まとめられたトライグラムに対応付けられた出現位置の個数の和が所定の個数を超えないように、分類部102はトライグラムを分類する。具体的に説明すると、分類部102は、各トライグラムに対応付けられた出現位置の個数に着目し、最初のトライグラムから順に中間トライグラム群に分類していく際、分類対象となっているトライグラムの出現位置の個数と、分類候補となっている中間トライグラム群にすでに分類されたトライグラムの出現位置の個数との和を算出し、あらかじめ用意された所定の個数と比較する。所定の個数を超えていなければ、当該分類候補となっている中間トライグラム群に分類対象のトライグラムを分類する。一方で、所定の個数を超えていれば、異なる中間トライグラム群に分類対象のトライグラムを分類する。
【0039】
このように、分類部102が各中間トライグラム群に分類されるトライグラムの出現位置の個数の和が所定の個数を超えないように分類することで、各中間トライグラム群の出現位置の個数をなるべく均一にすることができる。その結果、出現位置が効率的に格納された転置インデックス900を生成することへとつながる。
【0040】
再び図4のフローチャートに戻って、さらに分類部102は、作成された中間トライグラム群ごとに、トライグラムを末尾の文字順に並べる(ステップS405)。すなわち分類部102は、トライグラムの先頭の文字に基づいて分類された中間トライグラム群のそれぞれにおいて、今度はトライグラムの末尾の文字に着目し、末尾の文字の辞書順に並べる。
【0041】
具体的には図8に示すように、分類部102は、例えば文字「の」を共通な中央の文字とし、先頭の文字が「あ」〜「お」のトライグラムが分類された中間トライグラム群Aにおいて、トライグラムの末尾の文字に着目し、末尾の文字が「あ」「い」「う」・・・「り」・・・「輪」・・・といった順になるように並べる。このようなトライグラムを末尾の文字について辞書順に並べる処理を、すべての中間トライグラム群に対して実行する。
【0042】
図4のフローチャートに戻って、次に分類部102は、末尾の文字順に並べられたトライグラムを、出現位置が所定の個数を超えないように、並び順にトライグラム群に分類する(ステップS406)。すなわち分類部102は、末尾の文字順に並べられたトライグラムについて、最初のトライグラムから並び順に1つ以上のトライグラムをひとまとめにし、トライグラム群としてまとめていく。
【0043】
具体的に、図8のような中間トライグラム群Aの例では、末尾の文字順に並べられたトライグラムについて、最初に並べられたトライグラム「あのあ」から順に、「いのあ」・・・「おのあ」「あのい」・・・「おのう」までを1つのトライグラム群AAとしてまとめる。そして、次のトライグラム「あのえ」から、並べられた順に「おのく」まで、トライグラム群ABとしてまとめる。このような処理を繰り返して、トライグラム群AP、トライグラム群AQ・・・というように、並べられた最後のトライグラムまで、トライグラム群としてまとめていく。
【0044】
なおこのとき、上記中間トライグラム群への分類と同様に、分類が複雑になることを防ぐため、分類部102は、末尾の文字が同一のトライグラムは同一のトライグラム群にまとめられるようにする。例えば、「かのさ」と「このさ」という2つのトライグラムは、同一の末尾の文字「さ」を有するため、異なるトライグラム群に分けて分類されるのではなく、トライグラム「かのさ」が分類されたトライグラム群には必ずトライグラム「このさ」も分類されるようにする。
【0045】
さらにこのとき、上記中間トライグラム群への分類と同様に、トライグラム群の出現位置の個数をなるべく均一にするため、1つのトライグラム群にまとめられるトライグラムの個数が、まとめられたトライグラムに対応付けられた出現位置の個数の和が所定の個数を超えないように、分類部102はトライグラムを分類する。具体的に説明すると、分類部102は、各トライグラムに対応付けられた出現位置の個数に着目し、各中間トライグラム群において最初のトライグラムから順にトライグラム群に分類していく際、分類対象となっているトライグラムの出現位置の個数と、分類候補となっているトライグラム群にすでに分類されたトライグラムの出現位置の個数との和を算出し、あらかじめ用意された所定の個数と比較する。所定の個数を超えていなければ、当該分類候補となっているトライグラム群に分類対象のトライグラムを分類する。一方で、所定の個数を超えていれば、異なるトライグラム群に分類対象のトライグラムを分類する。
【0046】
図4のフローチャートに戻って、最後に生成装置1の生成部103が、各トライグラム群に、そこに分類されたトライグラムの出現位置を対応付けて、転置インデックス900を生成する(ステップS407)。すなわち、生成部103は、トライグラム群と、そこに分類された全てのトライグラムに上記ステップS401にて対応付けられた文書データ300中での出現位置と、を構成要素として、転置インデックス900を生成する。その後、生成された転置インデックス900は、ハードディスク154のような記憶部110に記憶され、本フローチャートの処理は終了する。
【0047】
ここで生成される転置インデックス900は、図9に示されるような2次元の表状に表すことができる。すなわち、生成される転置インデックス900の構成は、トライグラムの中央の文字ごとに、先頭の2文字を縦軸に、末尾の2文字を横軸にとり、出現位置を要素とする2次元状の表として表される。1つの表全体は、中央の文字を共通とするトライグラム全体、すなわち統合トライグラム群1つに相当するものである。
【0048】
ここで本図における縦軸の構成単位は、中央の文字が共通のトライグラムを先頭の文字に基づいて中間トライグラム群に分類した際の分類の単位であり、横軸の構成単位は、中間トライグラム群に分類されたトライグラムを末尾の文字に基づいてトライグラム群に分類した際の分類の単位である。そのため、1つのセルは1つのトライグラム群に相当し、1つのセルには、対応するトライグラム群に分類されたトライグラムに対応付けられた全ての出現位置が格納される。
【0049】
具体的に説明すると、表上で最も左上に配置されたセルは、先頭の2文字が「あの」〜「おの」であり、末尾の2文字が「のあ」〜「のう」であるトライグラムが分類されたトライグラム群に相当する。例えば「いのう」や「おのあ」というトライグラムがここに分類される。そして、当該トライグラム群に分類されたいずれかのトライグラムは、本図の当該セルに示されるように、文書データ300中の先頭から12文字目、49文字目、923文字目、11104文字目、11293文字目・・・という位置に出現する。一方で別の例を挙げると、例えば「しのひ」や「たのへ」といったトライグラムは、先頭の2文字が「さの」〜「ちの」で末尾の2文字が「のひ」〜「のほ」に相当するトライグラムである。本図によれば、これらのうちいずれかのトライグラムが、文書データ300中の先頭から6586文字目、59899文字目、72495文字目・・・の位置に出現する。
【0050】
生成装置1が生成する転置インデックス900は、このようなトライグラム群とその出現位置との2次元状の対応関係を、トライグラムの中央の文字のそれぞれについて備え、後述する検索処理において用いられる。
【0051】
以上のような構成により、本実施形態の生成装置1は、文書データ300から抽出されたトライグラムについて、中央の文字が共通なトライグラムをまとめ、まとめられたトライグラムをさらに先頭および末尾の文字に基づいてトライグラム群に分類する。そして、トライグラム群とそれぞれに分類されたトライグラムの出現位置とを対応付けて、転置インデックス900を生成する。その結果、トライグラムを単独で単位としたものに比べてデータサイズが抑えられ、かつ後述する検索装置2において高速な検索処理を実現することができる転置インデックス900を生成することができる。
【0052】
その際、生成装置1は、トライグラム群に分類されるトライグラムの出現位置の個数の和が所定の上限値を超えないようにトライグラムを分類していく。これにより、各トライグラム群に対応付けられる出現位置の個数がなるべく同じ個数に均一化することができ、出現位置が効率的に格納された転置インデックス900を生成することができる。
【0053】
本発明では、上記のような転置インデックス900の生成装置1、およびそれを用いた転置インデックス900の生成方法に加え、当該生成された転置インデックス900を用いて、文書データ300を検索対象とした検索を行う検索装置2、およびそれを用いた検索方法を提供する。
【0054】
ここで検索装置は、通常は上記転置インデックスの生成装置1とは異なる情報処理装置によって実現される。具体的に本実施形態では、検索装置として、電子辞書等の機能を備える小型の情報処理装置を想定して説明する。すなわち、検索対象である文書データ300についての転置インデックス900の生成については、あらかじめ上記図1および図2に示されたような一般的な情報処理装置において行われ、一方で当該生成された転置インデックス900を用いた文書データ300の検索については、生成装置1とは異なる情報処理装置、すなわち電子辞書等の小型の情報処理装置において実現される。
【0055】
このような検索装置2として、その構成は図10に示されるようなものになる。すなわち検索装置2は、制御部200と、記憶部210と、入力部220と、出力部230と、を備える。一方、当該検索装置2は、物理的には図11に示されるように構成され、CPU251と、ROM252と、RAM253と、キーボード255と、モニタ256と、を備える。以下、図10および図11を参照して、検索装置2の構成要素の説明をする。
【0056】
制御部200は、検索装置2全体の動作を制御し、各構成要素と接続され、制御信号やデータをやりとりする。すなわち、制御部200は、記憶部210、入力部220、出力部230と接続され、これら各部の機能を活用しながら、検索処理を実行する。
【0057】
ここで制御部200は、取得部201と、特定部202と、を備える。これらの各部は、詳細には後述するように、記憶部210に記憶されている転置インデックス900を用いて、文書データ300のうちから検索文字列が出現する位置を特定する処理を実行する。
【0058】
このような制御部200(取得部201、特定部202)は、例えばCPU251によって構成される。ここでCPU251は、基本的には生成装置1におけるCPU151と同様、命令やデータを転送するための伝送経路であるシステムバスにより各構成要素と相互に接続され、ROM252に記録されている検索装置2全体の動作制御に必要なコンピュータプログラムや各種データに従って動作し、さらにROM252から読み出したコンピュータプログラムやデータ、その他処理の進行に必要なデータを、RAM253に一時的に記憶しながら、各種動作を制御する。このようにCPU251がROM252やRAM253と協働することで、制御部200は、検索装置2全体の動作を制御する。
【0059】
記憶部210は、例えば検索装置2内に備えられたROM252のような読出し専用の記憶媒体によって構成され、制御部200が検索処理に必要な各種データを記憶する。具体的にここでは、検索対象とされる文書データ300、および転置インデックス900が記憶される。
【0060】
これら文書データ300は、上記生成装置1の記憶部110に記憶された文書データ300と同一のものであり、また転置インデックス900は、上記生成装置1が、これら文書データ300をもとにして生成した転置インデックス900と同一のものである。
【0061】
入力部220は、例えばキーボード255のような入力装置によって構成され、ユーザからの入力を受け付ける。具体的にここでは、ユーザからの検索語を受け付ける。受け付けられた検索語は、制御部200の取得部201へと供給され、当該検索語の文字列の文書データ300における出現位置を検索する処理に用いられる。
【0062】
出力部230は、例えばモニタ256のような表示装置によって構成され、制御部200が処理を行った結果をユーザへ出力する。具体的にここでは、ユーザが入力した検索語の文書データ300における出現位置を、検索結果としてモニタ256に表示することで、当該ユーザへと出力する。これにより、ユーザは、自身が入力した検索語の出現位置を出力結果として取得し、種々に利用することができるようになる。
【0063】
なお、入力部220と出力部230は、タッチパネル等のような入力装置と出力装置が組み合わされた装置によって構成されてもよい。この場合には、タッチパネルに内蔵されたタッチセンサ等からなる位置入力装置が入力部220を、液晶ディスプレイ等からなる表示装置が出力部230を、それぞれ構成する。
【0064】
以上のように構成される検索装置2は、制御部200の制御のもと、検索処理を行う。具体的には、図12A〜図12Cのフローチャートに示される手順で処理を実行する。
【0065】
本処理は、ユーザから入力された検索語を、検索装置2の入力部220が受け付けることを契機として、開始される。すなわち、キーボード255を用いて、ユーザが所望の検索語を入力し、検索する旨を指示することで、本処理が開始する。
【0066】
まず図12Aのフローチャートにおいて、検索処理が開始されると、まず取得部201が、入力された検索語の文字列(検索文字列)の先頭の文字に注目する(ステップS1201)。例えば、ユーザが「しすてむ」という検索語を入力した場合、取得部201は、先頭の文字「し」に注目する。あるいは、ユーザが「山」という1文字の検索語を入力した場合には、取得部201は、当該1文字「山」を先頭の文字として注目する。
【0067】
先頭の文字が注目されると、次に取得部201は、その文字を中央の文字とするトライグラムが分類された全てのトライグラム群に注目する(ステップS1202)。すなわち取得部201は、記憶部210に記憶されている転置インデックス900にアクセスし、その中に格納されているトライグラム群のうち、注目した文字を中央の文字とするトライグラムが分類された全てのトライグラム群(上記図9における1つの表全体に対応する全てのトライグラム群に相当)に注目する。上記の例では、注目した先頭の文字「し」や「山」を中央の文字とするトライグラムが分類された全てのトライグラム群に注目する。
【0068】
ここで取得部201は、検索文字列が1文字か否かを判定する(ステップS1203)。例えばユーザが「山」という検索語を入力したとき等のように、検索文字列が1文字の場合は(ステップS1203;YES)、検索語が2文字以上の場合とは異なるフローへ移行し、まず検索装置2の特定部202が、注目したトライグラム群があるか否かを判定する(ステップS1204)。すなわち、上記ステップS1202にて注目した、1文字の検索語(例えば「山」)を中央の文字とするトライグラムが分類されたトライグラム群が1つでも存在するか否かを判定する。
【0069】
1文字の検索語を中央の文字とするトライグラム群がない場合(ステップS1204;NO)、特定部202は、「該当箇所無し」を出力し(ステップS1205)、検索処理を終了する。文書データ300のいずれかの位置に当該1文字の検索語があるならば、その1文字を中央の文字とするトライグラムが分類されたトライグラム群があるはずであり、トライグラム群がないということは、文書データ300中に入力された1文字の検索語がないということになるからである。そのため、特定部202は、出力部230を介してモニタ256に「該当箇所無し」という文字を表示する等により、ユーザへその旨を出力する。
【0070】
一方、1文字の検索語を中央の文字とするトライグラム群がある場合(ステップS1204;YES)、特定部202は、該当するトライグラム群の全ての出現位置に1を加算して出力し(ステップS1206)、検索処理を終了する。後述する2文字以上の検索語の場合と異なり、検索語が1文字の場合には、注目したトライグラム群のトライグラムは当該1文字の検索語をその中央の文字として必ず含んでいるため、トライグラム群の出現位置に1を加算した位置(すなわち対応するトライグラムの2文字目)には必ず当該1文字の検索語が出現するからである。そのため、特定部202は、出力部230を介してモニタ256に表示する等により、該当するトライグラム群の全ての出現位置に1を加算した位置を、ユーザへ出力する。
【0071】
また一方で、入力された検索語の文字列が1文字でない場合(ステップS1203;NO)は、検索装置2の処理はステップS1207へと移行し、取得部201が、注目したトライグラム群のうち後の文字を末尾の文字とするトライグラムが分類されたトライグラム群の出現位置を全て取得する(ステップS1207)。すなわちここでは、取得部201は、上記ステップS1202にて注目した検索文字列の先頭の文字を中心の文字とするトライグラムが分類された全てのトライグラム群について、さらに検索文字列の後の文字(先頭から2文字目)を末尾の文字とするトライグラムが分類されたトライグラム群にまで絞り込みを行う。そして、取得部201は、絞り込んだトライグラム群について、転置インデックス900に格納されている全ての出現位置を取得する。
【0072】
具体的な例として、ユーザが「しすてむ」という検索語を入力した場合について説明する。この場合、上記ステップS1202にて注目したトライグラム群は、当該4文字の検索語の先頭の文字「し」を中心の文字とするトライグラムが分類された全てのトライグラム群であって、図13Aに表された文字「し」についての2次元状の表に配置されたトライグラム群全体に相当する。ここで本図における2次元状の表は、上記図9と同様に、転置インデックス900の構成をトライグラムの中央の文字ごとに2次元状に表したものである。
【0073】
そして、上記ステップS1207にて絞り込んだトライグラム群は、当該検索語「しすてむ」の2番目の文字「す」を末尾の文字とするトライグラムが分類されたトライグラム群であって、図13Aにおける太線で囲われた部分のトライグラム群に相当する。すなわち、絞り込むべきトライグラム群は、「しす」という2文字を末尾の2文字とするトライグラム「*しす」(*はどの文字種でもよい)が分類されたトライグラム群であるので、図13Aにおける「しさ」〜「しせ」の欄の縦一列の全てのセルのトライグラム群に相当することになる。ステップS1207では、取得部201が、これら縦一列の全てのセル内の出現位置(191文字目、449文字目、6545文字目、11095文字目・・・、321文字目、1088文字目・・・等)を取得する。
【0074】
図12Aのフローチャートに戻って、取得部201が転置インデックス900から出現位置を取得すると、次に取得部201が、出現位置があるか否かを判定する(ステップS1208)。すなわち、取得した出現位置がそもそも1つでも存在するか否かを判定する。出現位置がない場合は(ステップS1208;NO)、検索対象の文書データ300中に入力された検索文字列が存在しないということを意味するため、特定部202が、「該当箇所無し」を出力し(ステップS1205)、検索処理を終了する。すなわち特定部202は、出力部230を介してモニタ256に「該当箇所無し」という文字を表示する等により、ユーザへその旨を出力する。
【0075】
一方、出現位置が1つでも存在する場合は(ステップS1208;YES)、特定部202が、その出現位置を保持する(ステップS1209)。すなわち、転置インデックス900から取得した全ての出現位置を、RAM253等に一時的に保持する。その後、検索処理は図12Bのフローチャートへ移行する。
【0076】
検索処理が図12Bのフローチャートへ移行すると、次に取得部201は、検索文字列の次の文字に注目し(ステップS1210)、その文字を中央の文字とするトライグラムが分類された全てのトライグラム群に注目する(ステップS1211)。具体的にユーザが「しすてむ」という4文字の検索語を入力した場合では、取得部201は、先頭の文字の次の文字、すなわち2文字目の文字「す」に注目する。そして、転置インデックス900内に格納された当該文字「す」を中心の文字とするトライグラムが分類された全てのトライグラム群に注目する。ここで注目するトライグラム群は、図13Bに表された文字「す」についての2次元状の表に配置されたトライグラム群全体に相当する。
【0077】
図12Bのフローチャートにおいて、さらに取得部201は、検索文字列の注目した文字に対して、後の文字があるか否かを判定する(ステップS1212)。上記検索語「しすてむ」での例では、注目した文字「す」の後にさらに「て」と「む」の文字が存在しているため、取得部201は後の文字があると判定する。
【0078】
後の文字があると判定すると(ステップS1212;YES)、取得部201は、注目したトライグラム群のうち、前の文字を先頭の文字とし、後の文字を末尾の文字とするトライグラムが分類されたトライグラム群の出現位置を全て取得する(ステップS1213)。すなわち、上記検索語「しすてむ」での例では、注目した2文字目の文字「す」を中央の文字、前の文字「し」を先頭の文字、後の文字「て」を末尾の文字とするトライグラム「しすて」が分類されたトライグラム群の出現位置を全て、取得部201が取得する。
【0079】
図13Bに表された文字「す」についての2次元状の表では、当該「しすて」というトライグラムは、先頭の2文字(縦軸)が「しす」〜「つす」、末尾の2文字(横軸)が「すそ」〜「すと」の範囲に該当するものであるため、当該トライグラムが分類されたトライグラム群は、太線で囲われた1つのセルに相当するものとなる。従って、取得部201は、当該セル内の出現位置(523文字目、876文字目・・・等)を全て取得する。
【0080】
図12Bのフローチャートに戻って、出現位置を取得すると、次に特定部202が、保持された出現位置と連続する出現位置があるか否かを判定する(ステップS1214)。すなわち特定部202は、上記ステップS1209にて保持した検索語の先頭の文字についてのトライグラム群の出現位置と、取得した検索語の2番目の文字についてのトライグラム群の出現位置とを比較して、保持した出現位置の値に1だけ加算した値の出現位置があるか否かを判定する。保持した出現位置と取得した出現位置の中に、検索語の文字列を構成するトライグラムの出現位置が含まれているならば、それらは検索語の文字列を構成するように連続しているはずだからである。
【0081】
そのため、連続する出現位置がなければ(ステップS1214;NO)、検索対象の文書データ300には検索語が含まれていないということになり、特定部202は、「該当箇所無し」を出力し(ステップS1215)、検索処理を終了する。すなわち特定部202は、出力部230を介してモニタ256に「該当箇所無し」という文字を表示する等により、ユーザへその旨を出力する。
【0082】
一方、連続する出現位置があれば(ステップS1214;YES)、特定部202は、保持する出現位置を連続する出現位置と入れ替える(ステップS1216)。すなわち、特定部202は、検索文字列の2番目の文字についてのトライグラム群の出現位置のうち、連続すると判定した出現位置を、それまで保持していた先頭の文字についてのトライグラム群の出現位置と入れ替えて、RAM253等に保持する。
【0083】
その後、検索処理は再びステップS1210へと戻る。すなわち、検索装置2は、検索文字列の次の文字に注目し、当該注目した文字について、ステップS1211以降の処理を繰り返す。上記検索語「しすてむ」での例では、取得部201は、3文字目の文字「て」に注目し、その前後の文字とともに構成するトライグラム「すてむ」が分類されたトライグラム群の出現位置を、転置インデックス900から取得する。
【0084】
具体的に図13Cに表された文字「て」についての2次元状の表では、当該「すてむ」というトライグラムは、先頭の2文字(縦軸)が「さて」〜「ちて」、末尾の2文字(横軸)が「てま」〜「てめ」の範囲に該当するものであるため、当該トライグラムが分類されたトライグラム群は、太線で囲われたセルに相当するものとなる。従って、取得部201は、当該セル内の出現位置(31文字目、519文字目・・・等)を全て取得する。
【0085】
その後同様に、特定部202が出現位置の連続性を判定し(ステップS1214)、連続する出現位置を保持して(ステップS1216)、再び検索処理はステップS1210へと戻る。そして、検索文字列の次の文字、すなわち検索語「しすてむ」の最後の文字「む」に注目し(ステップS1210)、当該文字「む」についてのトライグラム群に注目する(ステップS1211)。注目した文字が検索語の最後の文字の場合には、その後の文字はないため(ステップS1212;NO)、検索処理は図12Cのフローチャートへと移行する。
【0086】
検索処理が図12Cのフローチャートへ移行すると、次に取得部201は、注目したトライグラム群のうち、前の文字を先頭の文字とするトライグラムが分類されたトライグラム群の出現位置を全て取得する(ステップS1217)。すなわち、上記検索語「しすてむ」での例では、注目した最後の文字「む」を中央の文字、前の文字「て」を先頭の文字とするトライグラム「てむ*」(*はどの文字種でもよい)が分類されたトライグラム群の出現位置を全て、取得部201が取得する。
【0087】
図13Dに表された文字「む」についての2次元状の表では、当該「てむ*」というトライグラムは、先頭の2文字(縦軸)が「たむ」〜「とむ」の範囲に該当するものであるため、当該トライグラムが分類されたトライグラム群は、太線で囲われた横一列のセルに相当するものとなる。従って、取得部201は、当該セル内の出現位置(261文字目、690文字目、1565文字目、3282文字目・・・、67文字目、298文字目・・・等)を全て取得する。
【0088】
図12Cのフローチャートに戻って、最後の文字についての出現位置を取得すると、上記ステップS1214と同様に、特定部202が、保持された出現位置と連続する出現位置があるか否かを判定する(ステップS1218)。取得された出現位置が入力された検索語の文字列を構成するものであるか否かを判定するためである。
【0089】
連続する出現位置がなければ(ステップS1218;NO)、検索対象の文書データ300には検索語が含まれていないということになるため、特定部202は、「該当箇所無し」を出力し(ステップS1219)、検索処理を終了する。すなわち特定部202は、出力部230を介してモニタ256に「該当箇所無し」という文字を表示する等により、ユーザへその旨を出力する。
【0090】
一方、連続する出現位置があれば(ステップS1218;YES)、入力された検索語が文書データ300中に含まれているということになる。そのため、特定部202は、その出現位置から検索文字列の先頭文字位置を計算し、出力する(ステップS1220)。すなわち特定部202は、連続すると判定した出現位置に対応する検索文字列の先頭文字位置を計算し、それを検索結果としてユーザへ出力する。連続する出現位置が複数存在した場合は、特定部202は、原則的には全てについて検索文字列の先頭文字位置を計算し、出力する。その後、本フローチャートにて示した検索装置2の処理は終了する。
【0091】
このとき出力結果は、出力部230を介しモニタ256に表示される等によって、ユーザへと出力される。ユーザは、当該出力結果により、記憶部210に記憶された文書データ300中において、自身が入力した検索語が出現する位置を取得することができ、種々に利用することができるようになる。
【0092】
以上のような構成により、本実施形態の検索装置2は、所望の検索文字列に対して、それを構成する文字ごとに前後の文字とあわせて転置インデックス900から出現位置を取得し、出現位置の連続性を判定することで、当該検索文字列が文書データ300中のどこに出現するのかを特定する。ここで用いられる転置インデックス900は、トライグラムがその文字列に基づいて分類されたトライグラム群を単位として構成されている。そのため、検索装置2は、トライグラムを単独で単位としたものに比べ、搭載される転置インデックス900のデータサイズを抑え、検索処理の速度をなるべく低下することなく検索を実行できる。
【0093】
これは、例えば電子辞書や携帯電話等のような小型の電子機器のような使用できるデータ容量が限られた環境においてはとくに、転置インデックス900のデータサイズを抑制しつつ高速な検索処理を実現する上で効果的である。
【0094】
なお、上記実施形態は一例であり、本発明の適用範囲はこれに限られない。すなわち、種々の応用が可能であり、あらゆる実施の形態が本発明の範囲に含まれる。
【0095】
例えば、上記実施形態では、検索装置2は、ROM252のような記憶部210内に文書データ300等を記憶した。しかしこれに限られず、検索装置2は、ハードディスク等の大容量記憶装置やDVD−ROMドライブを備え、文書データ300等がハードディスクやDVD−ROM等に記憶されるようにしてもよい。あるいは、検索装置2は、ネットワークに接続され、文書データ300等がネットワーク上に存在するようにしてもよい。
【0096】
また、上記実施形態では、検索装置2は、ユーザが検索語を入力する入力部220や検索結果を出力する出力部230は、制御部200や記憶部210と同一の装置内に存在した。しかしこれに限られず、入力部220と出力部230は、検索装置2の外部にあってもよい。すなわち、例えば図14に示すように、検索装置2は入力部220と出力部230を備えず、これらを備える端末装置3とネットワーク150を介して接続されるようにし、オンライン型の電子辞書のような情報機器として構成するようにしてもよい。
【0097】
このとき、検索装置2と端末装置3は、それぞれが備える通信部240a,240bにより、ネットワーク150を介して互いにデータを通信しあう。すなわち、端末装置3のユーザが入力した検索語は、検索装置2へと送信され、制御部200により検索処理が実行される。その後、検索結果の情報が再び端末装置3へと送信され、端末装置3のユーザへと出力される。このような構成をとることで、検索装置2内の文書データ300等を一括して管理して複数のユーザに利用できるようになり、またユーザ側の端末装置3は、文書データ300等を保持する必要がないため、データサイズを抑えることができるといった利点がある。
【0098】
また、上記実施形態では、検索装置2として電子辞書のような小型の情報処理装置を想定して説明した。しかしこれに限られず、検索装置2は、ビジネス用・家庭用の一般的なコンピュータ装置や、携帯電話等の他の情報機器であってもよい。また、電子辞書における検索に限られず、種々の電子データを検索するものであってもよい。例えば、一般的なコンピュータ装置において、ハードディスク等の大容量記憶装置やDVD−ROM等に記憶された電子ファイルのうちから、所望の検索語を含む電子ファイルを検索するものであってもよい。あるいは、ネットワークと接続され、ネットワーク上に存在するウェブページを検索するものであってもよい。
【0099】
また、生成装置1について、上記実施形態での生成装置1は、ハードディスク154のような記憶部110に記憶されている文書データ300をもとにして転置インデックス900を生成し、当該生成された転置インデックス900を記憶部110に記憶した。しかし、これら文書データ300は、生成装置1内に備えられた記憶部110に記憶されることに限られず、通信部140を介して接続されるネットワーク150上に存在していてもよいし、あるいはDVD−ROMドライブ157に搭載されるDVD−ROM内に記憶されていてもよい。
【0100】
また、上記実施形態では、文書データ300は、「見出し語」と「説明文」とから構成された。しかしこれらに限られず、様々な要素から構成されてもよい。例えば、「見出し語」を説明するための図や表を有するものであってもよい。あるいは、辞書における検索以外の一般的な電子ファイル等の検索では、このような「見出し語」と「説明文」といった構成要素に限らず、文書データ300は様々な形式で文字列データを有していてもよい。
【0101】
また、上記実施形態では、分類部102がトライグラムを中間トライグラム群およびトライグラム群に分類する際、1つの中間トライグラム群およびトライグラム群に分類されるトライグラムに対応付けられた出現位置の個数の和が所定の個数を超えないように分類した。しかし出現位置の個数ではなく、文字種の個数に着目して分類してもよい。すなわち、分類部102は、
(a)共通な中央の文字を有するトライグラムがまとめられた統合トライグラム群ごとに、トライグラムを先頭の文字順に並べ、1つの中間トライグラム群に分類されるトライグラムの先頭の文字種の個数が所定の個数を超えないように、トライグラムを並び順に中間トライグラム群に分類し、
(b)さらに中間トライグラム群ごとに、トライグラムを末尾の文字順に並べ、1つのトライグラム群に分類されるトライグラムの末尾の文字種の個数が所定の個数を超えないように、トライグラムを並び順にトライグラム群に分類してもよい。
【0102】
具体的に、1つの中間トライグラム群およびトライグラム群に分類されるトライグラムの先頭および末尾の文字種の個数を5種類とした場合について説明する。このとき、例えば文字「の」を中央の文字とするトライグラムについて、分類部102は、5種類の先頭の文字「あ」〜「お」を有するトライグラムを最初の中間トライグラム群としてまとめ、その後「か」〜「こ」、「さ」〜「そ」・・・というように、先頭の文字について5種類ずつ中間トライグラム群にまとめていく。さらに分類部102は、中間トライグラム群ごとに、5種類の末尾の文字「あ」〜「お」を有するトライグラムを最初のトライグラム群としてまとめ、その後「か」〜「こ」、「さ」〜「そ」・・・というように、末尾の文字について5種類ずつトライグラム群にまとめていく。
【0103】
その結果、生成される転置インデックス900について、例えば文字「の」についてのトライグラム群と出現位置との対応関係を2次元状に表すと、図15のようになる。すなわち、当該2次元状の表の縦軸と横軸の構成単位は、「あの」〜「おの」・・・「さの」〜「その」・・・等のように、先頭および末尾についての5個の文字種ごとに区切られたものとなる。
【0104】
このように、先頭および末尾の文字種の個数に基づいてトライグラム群を作成していくことで、各トライグラム群に分類されるトライグラムの種類の個数をなるべく同じ個数にすることができる。これにより、トライグラム群の出現位置の個数がなるべく同じ個数になるように分類された場合に比べ、出現位置の個数にはばらつきがでるが、各トライグラム群のトライグラムの個数が均一化されるため、一般的に扱いやすい転置インデックス900を生成することができる。
【0105】
なお、本発明に係る機能を実現するための構成を予め備えた転置インデックスの生成装置および当該転置インデックスを用いた検索装置として提供できることはもとより、プログラムの適用により、既存のパーソナルコンピュータや情報端末機器等を、本発明に係る生成装置および検索装置として機能させることもできる。すなわち、上記実施形態で例示した生成装置1および検索装置2による各機能構成を実現させるための生成プログラムまたは検索プログラムを、既存のパーソナルコンピュータや情報端末機器等を制御するCPU等が実行できるように適用することで、それぞれ本発明に係る生成装置1および検索装置2として機能させることができる。また、本発明に係る転置インデックスの生成方法および当該転置インデックスを用いた検索方法は、それぞれ生成装置1および検索装置2を用いて実施できる。
【0106】
また、このようなプログラムの適用方法は任意であり、例えば、CD−ROMやDVD−ROM、メモリカードなどのコンピュータ読み取り可能な記憶媒体に格納して適用できる他、例えば、インターネットなどの通信媒体を介して適用することもできる。
【0107】
以上、本発明の好ましい実施形態について説明したが、本発明は係る特定の実施形態に限定されるものではなく、本発明には、特許請求の範囲に記載された発明とその均等の範囲が含まれる。以下に、本願出願の当初の特許請求の範囲に記載された発明を付記する。
【0108】
(付記1)
文書データのうちから「3文字の文字列であるトライグラム」を、当該文書データ中での出現位置と対応付けて、抽出する抽出ステップと、
前記抽出されたトライグラムのうち中央の文字が共通なトライグラムを、先頭および末尾の文字に基づいて、トライグラム群に分類する分類ステップと、
前記分類されたトライグラム群のそれぞれに、当該トライグラム群に分類されたトライグラムに対応付けられた出現位置を対応付けて、転置インデックスを生成する生成ステップと、
を備えることを特徴とする転置インデックスの生成方法。
【0109】
(付記2)
前記分類ステップでは、
(a)前記抽出されたトライグラムのうち中央の文字が共通なトライグラムを、先頭の文字に基づいて、中間トライグラム群に分類し、
(b)前記中間トライグラム群に分類されたトライグラムを、末尾の文字に基づいて、トライグラム群に分類する、
ことを特徴とする付記1に記載の転置インデックスの生成方法。
【0110】
(付記3)
前記分類ステップでは、
(a)前記抽出されたトライグラムのうち中央の文字が共通なトライグラムを、前記中間トライグラム群に分類されるトライグラムに対応付けられた出現位置の個数の和が所定の第1の個数を超えないように分類し、
(b)前記中間トライグラム群に分類されたトライグラムを、前記トライグラム群に分類されるトライグラムに対応付けられた出現位置の個数が所定の第2の個数の和を超えないように分類する、
ことを特徴とする付記2に記載の転置インデックスの生成方法。
【0111】
(付記4)
前記分類ステップでは、
(a)前記抽出されたトライグラムのうち中央の文字が共通なトライグラムを、前記中間トライグラム群に分類されるトライグラムの先頭の文字種の個数が所定の第3の個数を超えないように分類し、
(b)前記中間トライグラム群に分類されたトライグラムを、前記トライグラム群に分類されるトライグラムの末尾の文字種の個数が所定の第4の個数を超えないように分類する、
ことを特徴とする付記2に記載の転置インデックスの生成方法。
【0112】
(付記5)
付記1から4のいずれか1つに記載の生成方法によって生成された転置インデックスを用いる検索方法であって、
所望の検索文字列を構成するトライグラムのそれぞれについて、前記転置インデックスから、当該トライグラムが分類されたトライグラム群に対応付けられた出現位置を取得する取得ステップと、
前記取得された出現位置に基づいて、前記検索文字列の前記文書データにおける出現位置を特定する特定ステップと、
を備えることを特徴とする検索方法。
【0113】
(付記6)
前記取得ステップでは、
(p)前記検索文字列の先頭の文字を中央の文字とし、先頭から2番目の文字を末尾の文字とするトライグラムが分類されたトライグラム群に対応付けられた出現位置を取得し、
(q)前記検索文字列の末尾の文字を中央の文字とし、末尾から2番目の文字を先頭の文字とするトライグラムが分類されたトライグラム群に対応付けられた出現位置を取得する、
ことを特徴とする付記5に記載の検索方法。
【0114】
(付記7)
文書データのうちから「3文字の文字列であるトライグラム」を、当該文書データ中での出現位置と対応付けて、抽出する抽出手段と、
前記抽出されたトライグラムのうち中央の文字が共通なトライグラムを、先頭および末尾の文字に基づいて、トライグラム群に分類する分類手段と、
前記分類されたトライグラム群のそれぞれに、当該トライグラム群に分類されたトライグラムに対応付けられた出現位置を対応付けて、転置インデックスを生成する生成手段と、
を備えることを特徴とする生成装置。
【0115】
(付記8)
付記1から4のいずれか1つに記載の生成方法によって生成された転置インデックスを用いる検索装置であって、
所望の検索文字列を構成するトライグラムのそれぞれについて、前記転置インデックスから、当該トライグラムが分類されたトライグラム群に対応付けられた出現位置を取得する取得手段と、
前記取得された出現位置に基づいて、前記検索文字列の前記文書データにおける出現位置を特定する特定手段と、
を備えることを特徴とする検索装置。
【0116】
(付記9)
コンピュータを、
文書データのうちから「3文字の文字列であるトライグラム」を、当該文書データ中での出現位置と対応付けて、抽出する抽出手段、
前記抽出されたトライグラムのうち中央の文字が共通なトライグラムを、先頭および末尾の文字に基づいて、トライグラム群に分類する分類手段、
前記分類されたトライグラム群のそれぞれに、当該トライグラム群に分類されたトライグラムに対応付けられた出現位置を対応付けて、転置インデックスを生成する生成手段、
として機能させることを特徴とするコンピュータプログラム。
【0117】
(付記10)
コンピュータを、
付記1から4のいずれか1つに記載の生成方法によって生成された転置インデックスを用いる検索装置として機能させるコンピュータプログラムであって、
前記コンピュータを、
所望の検索文字列を構成するトライグラムのそれぞれについて、前記転置インデックスから、当該トライグラムが分類されたトライグラム群に対応付けられた出現位置を取得する取得手段、
前記取得された出現位置に基づいて、前記検索文字列の前記文書データにおける出現位置を特定する特定手段、
として機能させることを特徴とするコンピュータプログラム。
【符号の説明】
【0118】
1…生成装置、2…検索装置、3…端末装置、100…制御部、101…抽出部、102…分類部、103…生成部、110…記憶部、120…入力部、130…出力部、140…通信部、150…ネットワーク、151…CPU、152…ROM、153…RAM、154…ハードディスク、155…キーボード、156…モニタ、157…DVD−ROMドライブ、158…通信装置、200…制御部、201…取得部、202…特定部、210…記憶部、220…入力部、230…出力部、240a,240b…通信部、251…CPU、252…ROM、253…RAM、255…キーボード、256…モニタ、300…文書データ、900…転置インデックス
【特許請求の範囲】
【請求項1】
文書データのうちから「3文字の文字列であるトライグラム」を、当該文書データ中での出現位置と対応付けて、抽出する抽出ステップと、
前記抽出されたトライグラムのうち中央の文字が共通なトライグラムを、先頭および末尾の文字に基づいて、トライグラム群に分類する分類ステップと、
前記分類されたトライグラム群のそれぞれに、当該トライグラム群に分類されたトライグラムに対応付けられた出現位置を対応付けて、転置インデックスを生成する生成ステップと、
を備えることを特徴とする転置インデックスの生成方法。
【請求項2】
前記分類ステップでは、
(a)前記抽出されたトライグラムのうち中央の文字が共通なトライグラムを、先頭の文字に基づいて、中間トライグラム群に分類し、
(b)前記中間トライグラム群に分類されたトライグラムを、末尾の文字に基づいて、トライグラム群に分類する、
ことを特徴とする請求項1に記載の転置インデックスの生成方法。
【請求項3】
前記分類ステップでは、
(a)前記抽出されたトライグラムのうち中央の文字が共通なトライグラムを、前記中間トライグラム群に分類されるトライグラムに対応付けられた出現位置の個数の和が所定の第1の個数を超えないように分類し、
(b)前記中間トライグラム群に分類されたトライグラムを、前記トライグラム群に分類されるトライグラムに対応付けられた出現位置の個数が所定の第2の個数の和を超えないように分類する、
ことを特徴とする請求項2に記載の転置インデックスの生成方法。
【請求項4】
前記分類ステップでは、
(a)前記抽出されたトライグラムのうち中央の文字が共通なトライグラムを、前記中間トライグラム群に分類されるトライグラムの先頭の文字種の個数が所定の第3の個数を超えないように分類し、
(b)前記中間トライグラム群に分類されたトライグラムを、前記トライグラム群に分類されるトライグラムの末尾の文字種の個数が所定の第4の個数を超えないように分類する、
ことを特徴とする請求項2に記載の転置インデックスの生成方法。
【請求項5】
請求項1から4のいずれか1項に記載の生成方法によって生成された転置インデックスを用いる検索方法であって、
所望の検索文字列を構成するトライグラムのそれぞれについて、前記転置インデックスから、当該トライグラムが分類されたトライグラム群に対応付けられた出現位置を取得する取得ステップと、
前記取得された出現位置に基づいて、前記検索文字列の前記文書データにおける出現位置を特定する特定ステップと、
を備えることを特徴とする検索方法。
【請求項6】
前記取得ステップでは、
(p)前記検索文字列の先頭の文字を中央の文字とし、先頭から2番目の文字を末尾の文字とするトライグラムが分類されたトライグラム群に対応付けられた出現位置を取得し、
(q)前記検索文字列の末尾の文字を中央の文字とし、末尾から2番目の文字を先頭の文字とするトライグラムが分類されたトライグラム群に対応付けられた出現位置を取得する、
ことを特徴とする請求項5に記載の検索方法。
【請求項7】
文書データのうちから「3文字の文字列であるトライグラム」を、当該文書データ中での出現位置と対応付けて、抽出する抽出手段と、
前記抽出されたトライグラムのうち中央の文字が共通なトライグラムを、先頭および末尾の文字に基づいて、トライグラム群に分類する分類手段と、
前記分類されたトライグラム群のそれぞれに、当該トライグラム群に分類されたトライグラムに対応付けられた出現位置を対応付けて、転置インデックスを生成する生成手段と、
を備えることを特徴とする生成装置。
【請求項8】
請求項1から4のいずれか1項に記載の生成方法によって生成された転置インデックスを用いる検索装置であって、
所望の検索文字列を構成するトライグラムのそれぞれについて、前記転置インデックスから、当該トライグラムが分類されたトライグラム群に対応付けられた出現位置を取得する取得手段と、
前記取得された出現位置に基づいて、前記検索文字列の前記文書データにおける出現位置を特定する特定手段と、
を備えることを特徴とする検索装置。
【請求項9】
コンピュータを、
文書データのうちから「3文字の文字列であるトライグラム」を、当該文書データ中での出現位置と対応付けて、抽出する抽出手段、
前記抽出されたトライグラムのうち中央の文字が共通なトライグラムを、先頭および末尾の文字に基づいて、トライグラム群に分類する分類手段、
前記分類されたトライグラム群のそれぞれに、当該トライグラム群に分類されたトライグラムに対応付けられた出現位置を対応付けて、転置インデックスを生成する生成手段、
として機能させることを特徴とするコンピュータプログラム。
【請求項10】
コンピュータを、
請求項1から4のいずれか1項に記載の生成方法によって生成された転置インデックスを用いる検索装置として機能させるコンピュータプログラムであって、
前記コンピュータを、
所望の検索文字列を構成するトライグラムのそれぞれについて、前記転置インデックスから、当該トライグラムが分類されたトライグラム群に対応付けられた出現位置を取得する取得手段、
前記取得された出現位置に基づいて、前記検索文字列の前記文書データにおける出現位置を特定する特定手段、
として機能させることを特徴とするコンピュータプログラム。
【請求項1】
文書データのうちから「3文字の文字列であるトライグラム」を、当該文書データ中での出現位置と対応付けて、抽出する抽出ステップと、
前記抽出されたトライグラムのうち中央の文字が共通なトライグラムを、先頭および末尾の文字に基づいて、トライグラム群に分類する分類ステップと、
前記分類されたトライグラム群のそれぞれに、当該トライグラム群に分類されたトライグラムに対応付けられた出現位置を対応付けて、転置インデックスを生成する生成ステップと、
を備えることを特徴とする転置インデックスの生成方法。
【請求項2】
前記分類ステップでは、
(a)前記抽出されたトライグラムのうち中央の文字が共通なトライグラムを、先頭の文字に基づいて、中間トライグラム群に分類し、
(b)前記中間トライグラム群に分類されたトライグラムを、末尾の文字に基づいて、トライグラム群に分類する、
ことを特徴とする請求項1に記載の転置インデックスの生成方法。
【請求項3】
前記分類ステップでは、
(a)前記抽出されたトライグラムのうち中央の文字が共通なトライグラムを、前記中間トライグラム群に分類されるトライグラムに対応付けられた出現位置の個数の和が所定の第1の個数を超えないように分類し、
(b)前記中間トライグラム群に分類されたトライグラムを、前記トライグラム群に分類されるトライグラムに対応付けられた出現位置の個数が所定の第2の個数の和を超えないように分類する、
ことを特徴とする請求項2に記載の転置インデックスの生成方法。
【請求項4】
前記分類ステップでは、
(a)前記抽出されたトライグラムのうち中央の文字が共通なトライグラムを、前記中間トライグラム群に分類されるトライグラムの先頭の文字種の個数が所定の第3の個数を超えないように分類し、
(b)前記中間トライグラム群に分類されたトライグラムを、前記トライグラム群に分類されるトライグラムの末尾の文字種の個数が所定の第4の個数を超えないように分類する、
ことを特徴とする請求項2に記載の転置インデックスの生成方法。
【請求項5】
請求項1から4のいずれか1項に記載の生成方法によって生成された転置インデックスを用いる検索方法であって、
所望の検索文字列を構成するトライグラムのそれぞれについて、前記転置インデックスから、当該トライグラムが分類されたトライグラム群に対応付けられた出現位置を取得する取得ステップと、
前記取得された出現位置に基づいて、前記検索文字列の前記文書データにおける出現位置を特定する特定ステップと、
を備えることを特徴とする検索方法。
【請求項6】
前記取得ステップでは、
(p)前記検索文字列の先頭の文字を中央の文字とし、先頭から2番目の文字を末尾の文字とするトライグラムが分類されたトライグラム群に対応付けられた出現位置を取得し、
(q)前記検索文字列の末尾の文字を中央の文字とし、末尾から2番目の文字を先頭の文字とするトライグラムが分類されたトライグラム群に対応付けられた出現位置を取得する、
ことを特徴とする請求項5に記載の検索方法。
【請求項7】
文書データのうちから「3文字の文字列であるトライグラム」を、当該文書データ中での出現位置と対応付けて、抽出する抽出手段と、
前記抽出されたトライグラムのうち中央の文字が共通なトライグラムを、先頭および末尾の文字に基づいて、トライグラム群に分類する分類手段と、
前記分類されたトライグラム群のそれぞれに、当該トライグラム群に分類されたトライグラムに対応付けられた出現位置を対応付けて、転置インデックスを生成する生成手段と、
を備えることを特徴とする生成装置。
【請求項8】
請求項1から4のいずれか1項に記載の生成方法によって生成された転置インデックスを用いる検索装置であって、
所望の検索文字列を構成するトライグラムのそれぞれについて、前記転置インデックスから、当該トライグラムが分類されたトライグラム群に対応付けられた出現位置を取得する取得手段と、
前記取得された出現位置に基づいて、前記検索文字列の前記文書データにおける出現位置を特定する特定手段と、
を備えることを特徴とする検索装置。
【請求項9】
コンピュータを、
文書データのうちから「3文字の文字列であるトライグラム」を、当該文書データ中での出現位置と対応付けて、抽出する抽出手段、
前記抽出されたトライグラムのうち中央の文字が共通なトライグラムを、先頭および末尾の文字に基づいて、トライグラム群に分類する分類手段、
前記分類されたトライグラム群のそれぞれに、当該トライグラム群に分類されたトライグラムに対応付けられた出現位置を対応付けて、転置インデックスを生成する生成手段、
として機能させることを特徴とするコンピュータプログラム。
【請求項10】
コンピュータを、
請求項1から4のいずれか1項に記載の生成方法によって生成された転置インデックスを用いる検索装置として機能させるコンピュータプログラムであって、
前記コンピュータを、
所望の検索文字列を構成するトライグラムのそれぞれについて、前記転置インデックスから、当該トライグラムが分類されたトライグラム群に対応付けられた出現位置を取得する取得手段、
前記取得された出現位置に基づいて、前記検索文字列の前記文書データにおける出現位置を特定する特定手段、
として機能させることを特徴とするコンピュータプログラム。
【図1】


【図2】
【図3】
【図4】
【図5】

【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12A】
【図12B】
【図12C】
【図13A】

【図13B】
【図13C】
【図13D】
【図14】
【図15】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12A】
【図12B】
【図12C】
【図13A】
【図13B】
【図13C】
【図13D】
【図14】
【図15】
【公開番号】特開2012−203579(P2012−203579A)
【公開日】平成24年10月22日(2012.10.22)
【国際特許分類】
【出願番号】特願2011−66611(P2011−66611)
【出願日】平成23年3月24日(2011.3.24)
【出願人】(000001443)カシオ計算機株式会社 (8,748)
【Fターム(参考)】
【公開日】平成24年10月22日(2012.10.22)
【国際特許分類】
【出願日】平成23年3月24日(2011.3.24)
【出願人】(000001443)カシオ計算機株式会社 (8,748)
【Fターム(参考)】
[ Back to top ]