
NMRデータの処理装置及び方法
【課題】 メタボノミクスのためのNMRスペクトルの解析処理の精度と効率を高める。
【解決手段】 NMR装置102からの多数サンプルのFIDデータがNMRスペクトルに変換され、各NMRスペクトルの実部の周波数微分の二乗と、虚部の周波数微分の二乗との和の平方根である絶対値微分が計算される(ステップ110)。多数サンプルの絶対値微分(AD)スペクトルに基づいて、それらのADスペクトル上の重要ピークも分割しないように最適化バケットセットが計算され、最適化バケットセットを用いた最適化バケット積分がADスペクトルに実行される(ステップ112)。多数サンプルの最適化バケット積分の結果を用いて、PCA解析とSIMCA解析が実行される(ステップ116)。解析結果とNMRスペクトルとが連携して画面に表示される。SIMCA解析の結果がPCA解析にフィードバックされ、バイオマーカの決定を容易化する。
【解決手段】 NMR装置102からの多数サンプルのFIDデータがNMRスペクトルに変換され、各NMRスペクトルの実部の周波数微分の二乗と、虚部の周波数微分の二乗との和の平方根である絶対値微分が計算される(ステップ110)。多数サンプルの絶対値微分(AD)スペクトルに基づいて、それらのADスペクトル上の重要ピークも分割しないように最適化バケットセットが計算され、最適化バケットセットを用いた最適化バケット積分がADスペクトルに実行される(ステップ112)。多数サンプルの最適化バケット積分の結果を用いて、PCA解析とSIMCA解析が実行される(ステップ116)。解析結果とNMRスペクトルとが連携して画面に表示される。SIMCA解析の結果がPCA解析にフィードバックされ、バイオマーカの決定を容易化する。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、NMR(核磁気共鳴)データを処理するための装置及び方法に関わり、特に、例えばメタボローム解析(メタボノミクスまたはメタボロミクス)のように多数のNMRスペクトルの多変量解析を行なう用途に好適なものである。
【背景技術】
【0002】
近年、ゲノムやプロテオーム科学の進展に伴って、代謝物全体(メタボローム又はメタボノーム)を網羅的に解析するメタボノミクス(メタボロミクスともいう)が注目を集めている。特に、NMR装置により測定される多数の生体サンプルのプロトンスペクトル(NMRスペクトル)を用い、多変量解析によってサンプル間のパターン分類を行うことで、例えば病態や未病に対する知見を得ようとする解析方法が、メタボノミクスにおいて採用される。
【0003】
すなわち、生体サンプルのプロトンスペクトルは、多種の低分子代謝物や生体高分子化合物を含むので多くのピークが重なり複雑なパターンを示す。また、微弱なピークも多くて、それをノイズと区別することが難しい。そのため、プロトンスペクトルに含まれる個々のピークを同定し構造解析することが困難である。そこで、メタボノミクスにおいては、多数の生体サンプルのプロトンスペクトルを測定し、測定された多数のプロトンスペクトルのデータを用いて多変量解析のような統計的解析を行ない、生体サンプル間の構成成分種や比率の相違をパターン(特徴量)として抽出するという解析方法が採用される。この方法により、代謝物の質的相違を捉えたり、経時変化を検出したりすることが可能になる。
【0004】
ところで、メタボノミクスを使用した薬物発見、疾患の処置及び診断のための方法が特許文献1に開示されている。ただし、特許文献1には、NMRスペクトルに関する開示はない。また、特許文献2及び3には、メタボノミクスのためのNMRスペクトルの処理に関する技術が開示されている。また、化学データの多変量解析の種々の手法が、非特許文献1に開示されている。
【0005】
【特許文献1】特表2003−530130号公報
【特許文献2】特表2004−526130号公報
【特許文献3】特表2004−538559号公報
【非特許文献1】「コンピュータ・ケミストリーシリーズ3 ケモメトリックス 化学パターン認識と多変量解析」宮下芳・佐々木慎一著、共立出版
【発明の開示】
【発明が解決しようとする課題】
【0006】
一般的なメタボノミクスのプロセスは、NMR装置から出力される多数のサンプルのFID(Free Induction Decay:自由誘導減衰)データを得ること、多数のサンプルのFID信号をそれぞれNMRスペクトルに変換すること、及び、多数のサンプルのNMRスペクトルに関して多変量解析に代表される統計処理を行なうことが含まれる。メタボノミクスのプロセスに含まれる複雑なNMRスペクトルデータの処理は、通常、コンピュータにより実行されるが、信頼できる処理結果を得るためには、FID信号から得られるNMRスペクトルの精度を向上し、かつ、多数のNMRスペクトルを統計処理プログラムで効率よく分析できるようにするためのデータ加工技術が必要である。
【0007】
NMRスペクトルの精度を向上させるための従来の処理技術として、位相補正とベースライン補正がある。位相補正とベースライン補正は、いずれも、コンピュータにより自動的に行い得るが、しかし最終的には、人が手動で、コンピュータの表示スクリーンに表示されたNMRスペクトルのグラフを見ながら、補正パラメータを最も適当と思われる値に調整するための操作をコンピュータに加えるという方法で行われる。しかし、この従来の補正方法は、長い作業時間を要して非効率的であるとともに、補正結果の適正レベルが人に依存するので常に最適なNMRスペクトルを得ることが難しい。
【0008】
また、NMRスペクトルを統計処理プログラムで効率よく分析できるようにするために、従来、NMRスペクトルを統計処理プログラムにインプットする前に、NMRスペクトルにバケット積分を適用して、これをデータ量のより小さいヒストグラムに縮約するという処理が行われている。すなわち、NMRスペクトルのケミカルシフト軸(周波数軸)に沿った観測範囲が、一定幅(典型的には0.04ppm)の刻みで多数のバケット(ケミカルシフトの小区間)に分割され、バケット毎にNMRスペクトルの強度の積分(バケット積分)が行われ、その結果として、多数のバケットの積分値のセットからなるヒストグラムが、NMRスペクトルの縮約として得られる。各サンプルのNMRスペクトルがヒストグラムに変換されるので、全体でサンプル数×バケット数に相当する数の積分値が得られ、それらの積分値が統計処理プログラムにインプットされる。
【0009】
しかしながら、従来のバケット積分の処理方法で得られるヒストグラムは、必ずしも、NMRスペクトルの特徴を十分に良く反映したものではない。すなわち、NMRスペクトル上の重要な幾つかの強度ピークが、ヒストグラム上では矮小化又は稀釈化されてしまう場合がある。この現象は、バケット積分のプロセスにおいて、一つの強度ピークが分布するケミカルシフト領域が複数のバケットに分割され、その結果、その強度ピークが複数の小さい積分値に分散されるときに生じる。
【0010】
上述した位相補正とベースライン補正に関わる問題、及びバケット積分に関わる問題に対しては、特許文献1−3はいずれも、格別有用な技術を提供していない。これらの問題は、メタボノミクスのためのNMRスペクトル処理だけに限らず、他の用途のためのNMRスペクトル処理においても同様に存在する。
【0011】
また、統計処理プログラムにより行なわれる多変量解析の処理については、上述した特許文献には格別の提案はない。
【0012】
ここで、非特許文献1に開示されているように、多変量解析と呼ばれる分析手法には多くの種類がある。代表的な分析手法の一つはPCA(Principal component Analysis:主成分分析)である。PCAでは、サンプルの成分である多数の変数の座標軸からなる多次元空間中で、サンプル間の相違(分散)が最も顕著に現れる少数本(例えば3本程度)の新しい座標軸が定義され、そして、新しい座標軸上での各サンプルの座標値が計算される。ここで、その新しい座標軸は「主成分軸」と呼ばれ、各主成分軸に沿った変数は「主成分」と呼ばれ、そして、各サンプルの各主成分軸上の座標値は「スコア」と呼ばれる。各主成分は、多数の変数の線形一次式で定義され、その線形一次式内の各変数項の係数は「ローディング」と呼ばれる。ある主成分についての各変数のローディングは、その主成分に対する各変量の寄与度合いつまり重みを表す。
【0013】
このようなPCAの結果に基づいて、主成分空間上に多数のサンプルをプロットすることにより、それらサンプルの性格を視覚的に把握することが容易になる。また、主成分空間上でのサンプルの配置や相互間の距離などを利用して、多数のサンプルのクラス分けを行なうことができる。
【0014】
また、PCAを応用したSIMCA(Soft Independent Modeling of Class Analogy:部分空間法)も、メタボノミクスにおいて有用であると考えられる。SIMCAでは、異なるクラスのサンプルに対してクラス毎にPCAを行ない、クラス毎に主成分を決定し、そして、或る主成分がそれらのクラスを分類するためにどの程度有効であるかを評価することができる。
【0015】
このようなPCA及びSIMCAの解析結果を巧く利用することにより、サンプルから得られる知見を有効に生かして、例えばマーカ変数の検出やその他の目的をより容易且つ精度良く達成できるようになることが期待される。
【0016】
しかしながら、上記の期待を満足させるために、特に、メタボノミクスのような応用分野で高い有用性を発揮するために、PCA及びSIMCAを具体的にどのように実行し、どのように関連させ、そして、その解析結果をどのようなにユーザに対して表示するかというような活用技術については、まだ満足できるものが従来提供されていない。そのため、多変量解析は、統計数学の専門家以外の人々にとってはまだ敷居が高く、メタボノミクスなどの応用分野で、期待されながらも、その真価を発揮するほどには十分に活用されていないというのが現状である。
【0017】
従って、本発明の目的は、NMRスペクトルの解析処理の精度を高めることにある。
【0018】
別の目的は、NMRスペクトルの解析処理の効率を高めることにある。
【0019】
別の目的は、NMRスペクトルをバケット積分によりヒストグラムに縮約するとき、NMRスペクトルのピークの特徴がヒストグラムに良く反映されるようにすることにある。
【0020】
さらに別の目的は、多数サンプルのNMRスペクトルの解析において、多変量解析を有効に活かすための処理技術を提供することにある。
【0021】
さらにまた別の目的は、メタボノミクスなどの応用分野において、多変量解析処理を活用して、より精度の高い結果又は結論を導くことを容易にすることにある。
【課題を解決するための手段】
【0022】
本発明の一つの側面に従えば、NMRデータの処理装置は、サンプルのNMR特性を示す対象スペクトルデータを生成するスペクトル生成手段と、前記対象スペクトルデータに対し、不均等な幅をもつ多数のバケットからなるバケットセットを用いたバケット積分を実行することにより、前記対象スペクトルデータをヒストグラムデータに縮約するデータ縮約手段と、前記ヒストグラムデータを記憶又は出力する手段とを備える。
【0023】
対象スペクトルデータのバケット積分を実行する際、適切に設定された不均等な幅をもつバケットセットを用いることにより、対象スペクトルデータがもつ重要なピークの情報を良好に維持したまま、対象スペクトルデータをバケット積分データのセットであるヒストグラムに縮約できる。そのため、そのヒストグラムを用いて行われるスペクトル解析の精度が向上する。
【0024】
好適な実施形態では、対象スペクトルデータがもつ重要なピークの情報を良好に維持するために、指定された1以上のピーク領域のいずれもが複数バケットに分割されないように、不均等幅のバケットセットが設定されている。さらに、対象スペクトルデータから検出された1以上のピーク領域のいずれもが複数バケットに分割されないように、不均等幅のバケットセットが設定されている。
【0025】
好適な実施形態では、上記のような不均等幅のバケットセットを自ら設定するバケット設定手段が、NMRデータの処理装置に備えられる。このバケット設定手段は、複数の対象スペクトルデータを入力し、それらの複数の対象スペクトルデータが投影された投影スペクトルデータを生成し、投影スペクトルデータからピーク領域を検出し、そして、検出された1以上のピーク領域のいずれもが複数バケットに分割されないようにして各バケットを設定する。さらに、このバケット設定手段は、1以上のピーク領域を指定し、指定された1以上のピーク領域のいずれもが複数バケットに分割されないようにして各バケットを設定する。さらに、このバケット設定手段は、オペレータから入力された要求に応答して、各バケットを修正することもできる。
【0026】
好適な実施形態では、上記対象スペクトルとして、サンプルのFIDデータから得られたNMRスペクトルデータに絶対値微分を施した結果である絶対値微分スペクトルデータが用いられる。ここで、NMRスペクトルデータの絶対値微分とは、NMRスペクトルの実部の周波数(ケミカルシフト)微分の二乗と、虚部の周波数(ケミカルシフト)微分の二乗との和の平方根である。このような絶対値微分スペクトルデータを用いてスペクトル解析を行うことで、面倒な位相補正やベースライン補正を行うことなしに、効率的に精度の良い解析結果を得ることが可能になる。
【0027】
本発明の別の側面に従うNMRデータの処理装置は、サンプルのFIDデータを取得する手段と、前記FIDデータからNMRスペクトルデータを生成する手段と、前記NMRスペクトルデータに絶対値微分を施して絶対値微分スペクトルデータを生成する手段と、前記絶対値微分スペクトルデータを記憶又は出力する手段とを備える。
【0028】
本発明のまた別の側面に従うNMRスペクトルの統計処理装置は、複数のサンプルのNMRヒストグラムデータからなる多変量データ行列を入力する多変量データ行列入力手段と、入力された前記多変量データ行列についてPCA解析計算を行なうPCA解析手段と、前記PCA解析計算の結果を受けて、複数種のPCA解析結果チャートをユーザインタフェース画面に表示するPCA解析結果表示手段と、前記ユーザインタフェース画面を用いてユーザ要求を入力するユーザ要求入力手段と、入力された前記ユーザ要求が1以上のサンプルを選択するものである場合、前記選択されたサンプルのNMRスペクトルのデータを入力して、入力された前記NMRスペクトルをケミカルシフト軸上に表したNMRスペクトルチャートを前記ユーザインタフェース画面に表示するNMRスペクトル連携手段とを備える。
【0029】
前記PCA解析結果チャートには少なくとも、複数の主成分に対する前記サンプルのスコアを表したスコアプロットと、変数たる所定の複数のケミカルシフト値の前記複数の主成分に対するローディングを表したローディングプロットと、前記所定の複数のケミカルシフト値の寄与率又はローディングをケミカルシフト軸上に表した寄与率/ローディングチャートとが含まれる。前記寄与率/ローディングチャートと前記NMRスペクトルチャートとは、それぞれの前記ケミカルシフト軸のスケールが一致するようにして、前記ケミカルシフト軸に直交する方向に並べられて表示されるようになっている。
【0030】
好適な実施形態では、入力された前記ユーザ要求が前記寄与率/ローディングチャートを拡大するものである場合、前記PCA解析結果表示手段と前記NMRスペクトル連携手段が、前記寄与率/ローディングチャートと前記NMRスペクトルチャートとの間の前記ケミカルシフト軸のスケールの一致が保持されるようにして、前記寄与率/ローディングチャートと前記NMRスペクトルチャートとを拡大して表示する。
【0031】
また、好適な実施形態では、入力された前記ユーザ要求が選択された1以上のサンプルを削除するものである場合、前記PCA解析手段が、前記削除されたサンプル以外のサンプルのNMRヒストグラムデータからなる多変量データ行列についてPCA解析計算を再度実行し、前記PCA解析結果表示手段が、再度実行された前記PCA解析計算の結果を受けて、前記PCA解析結果チャートを改めて表示する。
【0032】
また、好適な実施形態では、入力された前記ユーザ要求が選択された1以上の変数たるケミカルシフト値を削除するものである場合、前記PCA解析手段が、前記削除されたケミカルシフト値以外のケミカルシフト値を用いてPCA解析計算を再度実行し、前記PCA解析結果表示手段が、再度実行された前記PCA解析計算の結果を受けて、前記PCA解析結果チャートを改めて表示する。
【0033】
本発明のさらにまた別の側面に従うNMRスペクトルの統計処理装置は、数のクラスに割り当てられた複数のサンプルのNMRヒストグラムデータからなる複数クラスの多変量データ行列を入力する多変量データ行列入力手段と、入力された前記複数クラスの多変量データ行列についてSIMCA解析計算を行なうSIMCA解析手段と、前記SIMCA解析計算の結果を受けて、複数種のSIMCA解析結果チャートをユーザインタフェース画面に表示するSIMCA解析結果表示手段と、前記ユーザインタフェース画面を用いてユーザ要求を入力するユーザ要求入力手段と、入力された前記ユーザ要求が1以上のサンプルを選択するものである場合、前記選択されたサンプルのNMRスペクトルのデータを入力して、入力された前記NMRスペクトルをケミカルシフト軸上に表したNMRスペクトルチャートを前記ユーザインタフェース画面に表示するNMRスペクトル連携手段とを備える。
【0034】
前記SIMCA解析結果チャートには少なくとも、前記複数のクラスに対する前記サンプルの距離を表したクーマンプロットと、変数たる所定の複数のケミカルシフト値のモデリング力又は識別力をケミカルシフト軸上に表したモデリング力/識別力チャートとが含まれる。前記モデリング力/識別力チャートと前記NMRスペクトルチャートとは、それぞれの前記ケミカルシフト軸のスケールが一致するようにして、前記ケミカルシフト軸に直交する方向に並べられて表示されるようになっている。
【0035】
好適な実施形態では、入力された前記ユーザ要求が前記モデリング力/識別力チャートを拡大するものである場合、前記SIMCA解析結果表示手段と前記NMRスペクトル連携手段が、前記モデリング力/識別力チャートと前記NMRスペクトルチャートとの間の前記ケミカルシフト軸のスケールの一致が保持されるようにして、前記モデリング力/識別力チャートと前記NMRスペクトルチャートとを拡大して表示する。
【0036】
また、好適な実施形態では、入力された前記ユーザ要求が選択された1以上のサンプルを削除するものである場合、前記SIMCA解析手段が、前記削除されたサンプル以外のサンプルのNMRヒストグラムデータからなる複数クラスの多変量データ行列についてSIMCA解析計算を再度実行し、前記SIMCA解析結果表示手段が、再度実行された前記SIMCA解析計算の結果を受けて、前記SIMCA解析結果チャートを改めて表示する。
【0037】
また、好適な実施形態では、入力された前記ユーザ要求が、所定の閾値より前記識別力又はモデリング力が高い変数たるケミカルシフト値を選択するとともに再計算を要求するものである場合、前記SIMCA解析手段が、前記選択されたケミカルシフト値だけを用いてSIMCA解析計算を再度実行し、前記SIMCA解析結果表示手段が、再度実行された前記SIMCA解析計算の結果を受けて、前記SIMCA解析結果チャートを改めて表示する。
【0038】
本発明のまた更に別の側面に従うNMRスペクトルの統計処理装置は、複数のサンプルのNMRヒストグラムデータからなる多変量データ行列についてPCA解析計算を行なうPCA解析手段と、前記PCA解析計算の結果を受けて、複数種のPCA解析結果チャートをユーザインタフェース画面に表示するPCA解析結果表示手段と、複数のクラスに割り当てられた複数のサンプルのNMRヒストグラムデータからなる複数クラスの多変量データ行列を入力する多変量データ行列入力手段と、入力された前記複数クラスの多変量データ行列についてSIMCA解析計算を行なうSIMCA解析手段と、前記SIMCA解析計算の結果を受けて、複数種のSIMCA解析結果チャートをユーザインタフェース画面に表示するSIMCA解析結果表示手段と、前記ユーザインタフェース画面を用いてユーザ要求を入力するユーザ要求入力手段とを備える。
【0039】
前記PCA解析結果チャートには少なくとも、複数の主成分に対する前記サンプルのスコアを表したスコアプロットと、変数たる所定の複数のケミカルシフト値の前記複数の主成分に対するローディングを表したローディングプロットと、前記所定の複数のケミカルシフト値の寄与率又はローディングをケミカルシフト軸上に表した寄与率/ローディングチャートとが含まれる。前記SIMCA解析結果チャートには少なくとも、前記複数のクラスに対する前記サンプルの距離を表したクーマンプロットと、変数たる所定の複数のケミカルシフト値のモデリング力又は識別力をケミカルシフト軸上に表したモデリング力/識別力チャートとが含まれる。
【0040】
前記ユーザ要求入力手段により入力された前記ユーザ要求が、前記モデリング力/識別力チャートに表示された前記識別力又はモデリング力が所定閾値より高い変数たるケミカルシフト値を選択するとともにPCA解析計算の再実行を要求するものである場合、前記PCA解析手段が、前記選択されたケミカルシフト値だけを用いてPCA解析計算を再度実行し、前記PCA解析結果表示手段が、再度実行された前記PCA解析計算の結果を受けて、前記PCA解析結果チャートを改めて表示する。
【0041】
好適な実施形態では、前記ユーザ要求入力手段により入力された前記ユーザ要求が、前記モデリング力/識別力チャートに表示された前記識別力又はモデリング力が所定閾値より高い変数たるケミカルシフト値を選択するとともに変数を追加したPCA解析計算の再実行を要求するものである場合、前記PCA解析手段が、前記選択されたケミカルシフト値を現在の変数たるケミカルシフト値に追加してなる変数を用いてPCA解析計算を再度実行し、前記PCA解析結果表示手段が、再度実行された前記PCA解析計算の結果を受けて、前記PCA解析結果チャートを改めて表示する。
【0042】
また、好適な実施形態では、前記ユーザ要求入力手段により入力された前記ユーザ要求が、前記モデリング力/識別力チャートに表示された前記識別力又はモデリング力が所定閾値より高い変数たるケミカルシフト値を選択するとともにSIMCA解析計算の再実行を要求するものである場合、前記SIMCA解析手段が、前記選択されたケミカルシフト値だけを用いてPCA解析計算を再度実行し、前記SIMCA解析結果表示手段が、再度実行された前記SIMCA解析計算の結果を受けて、前記SIMCA解析結果チャートを改めて表示する。
【0043】
本発明は更に、上述した原理に基づくNMRデータの処理方法、NMRデータ処理のためのコンピュータプログラム、及びNMRスペクトルの統計処理のためのコンピュータプログラムも提供する。
【発明の効果】
【0044】
本発明のNMRデータの処理装置及び方法によれば、多数サンプルのNMRスペクトルの解析において、多変量解析を有効に活かすことができ、そのため、メタボノミクスなどの応用分野において、より精度の高い結果又は結論を導くことが容易になる。
【0045】
本発明のNMRデータの処理装置及び方法によれば、NMRスペクトルに絶対値微分を適用することで、NMRスペクトルの解析処理の効率が向上する。
【0046】
本発明のNMRスペクトルの統計処理装置によれば、多数サンプルのNMRスペクトルの解析において、多変量解析を有効に活かすことができる。
【0047】
本発明のNMRスペクトルの統計処理装置によれば、これをメタボノミクスなどの応用分野で利用することにより、多変量解析処理を活用して、より精度の高い結果又は結論を導くことが容易になる。
【発明を実施するための最良の形態】
【0048】
以下、図面を参照して本発明の実施形態を説明する。
【0049】
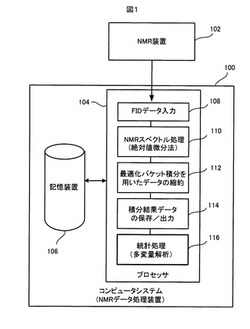
図1は、本発明に従うNMRデータ処理装置の一実施形態の全体的な構成と機能を示す。
【0050】
図1に示すように、本発明に従うNMRデータ処理装置としてのコンピュータシステム100が、NMR装置102と関連して用いられる。コンピュータシステム100は、プログラムされた1台コンピュータマシン(例えば、汎用のパーソナルコンピュータ、ワークステーション或いはメインフレームコンピュータマシンなど)であってもよいし、或は複数台のコンピュータマシンから構成されてもよい。なお、コンピュータシステムに代えて、1以上の専用ハードウェア回路、又は専用ハードウェア回路とコンピュータシステムとの組み合わせなどが、NMRデータ処理装置として用いられてもよい。
【0051】
コンピュータシステム100は、プロセッサ104と、プロセッサ104のためのコンピュータプログラム及びプロセッサ104により処理されるデータを格納するための記憶装置106とを有する。プロセッサ104は、記憶装置306に記憶されている所定のコンピュータプログラムを実行することによりNMRデータの処理を行う。NMRデータを処理する目的が異なれば、その処理の方法も当然に異なるが、ここでは、NMRデータの処理の一例として、メタボノミクスによりマーカ成分を確定することを目的として、多数のサンプルのNMRスペクトルを収集し、それらのスペクトルを統計的に解析する場合を取り上げて説明する。
【0052】
プロセッサ104が行うNMRデータの処理は、大きくFIDデータ入力処理108、NMRスペクトル処理110、データ縮約処理112、積分結果データ保存/出力処理114、及び統計処理116に分けられる。FIDデータ入力処理108では、NMR装置102から出力される各サンプルのFID(Free Induction Decay:自由誘導減衰)データが入力され、それにより、多数のサンプルのFIDデータが収集されて記憶装置106に記憶される。NMRスペクトル処理110では、各サンプルのFIDデータがフーリエ変換によりNMRスペクトルデータに変換され、更にそのNMRスペクトルデータが本発明の原理に従った「絶対値微分法(Absolute
Differential Calculation Method)」により「絶対値微分NMRスペクトル(Absolute Differential NMR Spectrum」データに変換され、それにより、多数のサンプルの「絶対値微分NMRスペクトル」データが記憶装置106に記憶される。ここで、「絶対値微分法」及び「絶対値微分NMRスペクトル」という用語は、この明細書で説明の便宜上用いられる特殊な用語であり、その詳細は後に説明する。「絶対値微分NMRスペクトル」は、以下、「ADスペクトル」と略称する。
【0053】
次のデータ縮約処理112では、本発明の原理に従った方法で「最適化バケットセット」が算出され、そして、その「最適化バケットセット」を用いて多数のサンプルのADスペクトルに「最適化バケット積分」が実行され、それにより、多数のサンプルのADスペクトルの縮約データであるヒストグラム(バケット積分データのセット)が生成される。ここで、「最適化バケットセット」及び「最適化バケット積分」という用語も、この明細書で説明の便宜上用いられる特殊な用語であり、その詳細は後に説明する。積分結果データ保存/出力処理114では、上記のデータ縮約処理112により生成された多数のサンプルのヒストグラムデータ(バケット積分データのセット)が、記憶装置106に記憶され、また必要に応じて外部へ出力される。統計処理116では、多数のサンプルのヒストグラムデータを用いて、処理目的に応じた統計処理、例えばマーカ成分を確定するための検出多変量解析、が行われる。そして、その統計処理の結果を表すデータが記憶装置106に記憶され、また必要に応じて外部へ出力される。
【0054】
ここで、FIDデータ入力処理108、積分結果データ保存/出力処理114及び統計処理116には、それぞれ、公知の各種の処理方法が採用可能であるため、これらについての詳細な説明は省略する。以下では、絶対値微分法を用いたNMRスペクトル処理110と、最適化バケット積分によるデータ縮約114について、詳細且つ具体的に説明する。
【0055】
図2は、NMRスペクトル処理110の流れを示す。
【0056】
図2に示すように、ステップ120で、NMR装置102から取得されて記憶装置106に保存されている各サンプルのFIDデータが、記憶装置106から読み込まれる。ステップ122で、そのFIDデータに対してウィンドウ処理が行われ、そのFIDデータのSN比が改善され、またリップルが除去される。ステップ124で、ウィンドウ処理122を経たFIDデータに対してフーリエ変換処理が行われて、そのFIDデータがNMRスペクトルデータに変換される。ステップ126で、そのNMRスペクトルデータに対して絶対値微分演算が行われて、そのNMRスペクトルデータがADスペクトルデータ(絶対値微分NMRスペクトルデータ)に変換される。ステップ128で、そのNMRスペクトルデータとADスペクトルデータとが記憶装置106に保存され、また、必要に応じて外部へ出力される。多数のサンプルの各々について、上記のステップ120〜128の処理が行われ、それにより、多数のサンプルのNMRスペクトルデータとADスペクトルデータが記憶装置106に蓄積される。
【0057】
ステップ126の絶対値微分演算について、以下、具体的に説明する。
【0058】
絶対値微分の対象であるNMRスペクトルは、δをケミカルシフト、jを虚数記号としたとき、次式
NMRスペクトル=R(δ)+j・I(δ) …(1)
で表現することができる。ここで、R(δ)はNMRスペクトルの実部であり、I(δ)は虚部である。そして、NMRスペクトルを絶対値微分した結果であるADスペクトルは、次式
【0059】
【数1】

で表現することができ(又は、ケミカルシフトδに代えて周波数ωで微分してもよい)。すなわち、これは、NMRスペクトルの実部R(δ)と虚部I(δ)それぞれの微分値の2乗和の平方根である。
【0060】
図3Aは、NMRスペクトルの一例の実部の波形を示し、図3BはこのNMRスペクトルの絶対値微分であるADスペクトルの波形を示す。
【0061】
図3Aに示されたNMRスペクトルの実部140から分かるように、このNMRスペクトルには位相ずれ(例えば、溶媒信号の部分142に位相ずれが顕著に表れている)が含まれ、かつ、そのベースライン成分は平坦ではなく歪んでいる。FIDデータから得られたNMRスペクトルは、殆ど例外なく、位相ずれと歪んだベースライン成分を含んでいる。従来技術によれば、NMRスペクトルに位相補正とベースライン補正が施される必要がある。
【0062】
位相補正は位相ずれを除去するための操作である。位相ずれが含まれたNMRスペクトルでは、実部R(δ)と虚部I(δ)におけるピーク波形はそれぞれ図4Aに例示するような波形になる。位相補正では、位相ずれを低減して、図4Bに例示するような波形に整形する。また、ベースライン補正は、NMRスペクトルからベースライン成分を差し引くための補正である。図5Bに例示するように歪んだベースラインBLを、図5Bに例示するようなゼロで一定のベースラインBLに修正するのである。しかし、位相補正とベースライン補正は、オペレータにより手動で調整される必要があり、時間がかかり、かつ、オペレータの主観や技量のバイアスが入ってしまう。さらに、苦労して調整しても、十分満足できる結果に到達することが難しい。
【0063】
これに対し、図3Bに例示されるように、NMRスペクトルの絶対値微分結果であるADスペクトル144においては、位相ずれが解消され、さらに、ベースラインもゼロ近傍でほぼ一定である。このことは、ADスペクトル144を用いれば、位相補正とベースライン補正が実質的に不要になることを意味する。その理由について具体的に説明する。
【0064】
NMRスペクトルの実部R(δ)と虚部I(δ)は、次式
R(δ)=A(δ)・cos(θ(δ)) …(3)
I(δ)=A(δ)・sin(θ(δ)) …(4)
で表現することができる。ここで、A(δ)は振幅であり、θ(δ)は位相である。位相θ(δ)は、大雑把にはケミカルシフトδの一次関数、
θ(δ)=K・δ+L …(5)
で表すことができ、ここで、KとLは一定の係数である。これらの式を用いて絶対値微分を計算すると、ADスペクトルは次式、
【0065】
【数2】
に変換される。
【0066】
上記(6)式から分かるように、ADスペクトルには位相θ(δ)の成分が含まれていない。また、(6)式において支配的な部分は第1項であるが、そこでは振幅A(δ)がケミカルシフトδで微分されており、この微分によりベースライン成分(これは、図5Aの例から分かるようにケミカルシフトδに対して緩やかな傾きで歪んでいる)は実質的にゼロになる。そのため、ADスペクトルでは、ベースライン成分はかなり小さく低減される。このように、絶対値微分という簡易な演算により、位相補正およびベースライン補正をすることなく高品位なスペクトルを得ることができる。
【0067】
また、NMRスペクトルには、図3Aに参照番号142で示すような溶媒(例えば軽水)信号の巨大なピークが存在する。その巨大な溶媒ピークの裾野部分は幅広く広がっており、これも、スペクトルの精度低下の主原因の一つである。しかし、ADスペクトルにおいては、ベースラインと同様に上記理由によって溶媒ピークの裾野部分も良好に低減されるので、溶媒ピークの影響を極めて小さくすることができる。
【0068】
なお、ADスペクトルの一つの欠点は、NMRスペクトルの絶対的な定量性が失われること、特に、ブロードなピークの信号強度が微分により減衰してしまうことである。しかしながら、複数のNMRスペクトル相互間の相対的な関係(例えば、どのケミカルシフトδの位置にピークが現れるかという点での相対的関係)は、ADスペクトルにおいても保たれるため、メタボノミクスのように多数のNMRスペクトルを解析する目的においては、ADスペクトルは非常に有用な情報である。
【0069】
再び図2を参照して、ステップ126で上述したADスペクトルが生成された後、ステップ128でそのADスペクトルが記憶装置106に保存される。統計処理に必要な多数のサンプルのNMRスペクトルのそれぞれについて、図2に示す処理が繰り返され、その結果、多数のサンプルのADスペクトルが記憶装置106に蓄積される。その後、図1に示すように、最適化バケット積分を用いたデータ縮約処理112が実行される。
【0070】
図6は、最適化バケット積分を用いたデータ縮約処理112の流れを示す。
【0071】
図6に示すように、ステップ170で、記憶装置106に蓄積された多数のADスペクトルのそれぞれについて、そのケミカルシフト(δ)軸スケールの基準点(δ基準点)(原点)が自動的に設定される。δ基準点の設定は公知の方法で行うことができ、それにより、いずれのADスペクトルについても、同じ特定物質のピークが現れるケミカルシフト軸上のポイントが基準点として設定される。
【0072】
その後、ステップ171で、多数のADスペクトルを共通のスペクトル上に投影する処理が行われる。このスペクトル投影処理171は、それらのADスペクトルのケミカルシフト軸のスケールを合わせた上で、ケミカルシフトδのポイント毎に全てのADスペクトルの最大値又は総和を計算するという処理である。その結果、多数のADスペクトルの最大値又は総和として1つの投影ADスペクトルが生成され、その投影ADスペクトルには、全てのADスペクトルに含まれる全てのピークが現れることになる。
【0073】
図7A,Bは、このスペクトル投影処理171の原理を説明する図であり、図8は、このスペクトル投影処理171の流れを示す。
【0074】
スペクトル投影処理171では、図8に示すように、ステップ190で、多数のADスペクトルの中から一つのADスペクトルSaが選択される。例えば図7Aに示すようなスペクトルSaが選択される。このADスペクトルSaが、投影ADスペクトルSpに初期設定される。ステップ192で、別の一つのADスペクトルSbが選択される。例えば、図7Bに示すようなADスペクトルSbが選択される。
【0075】
ステップ194で、両スペクトルSbとSpのケミカルシフト軸スケールを一致させた上で(例えば、両スペクトルの基準点rbとraの差分(rb-ra)だけ、スペクトルSbのδスケール(ケミカルシフト軸スケール)をシフトさせて、基準点rbとraを一致させた上で)、両スペクトルSbとSpの強度の最大値又は和がδポイント毎に計算される。具体的には、
最大値: if(Sp > Sb(rb-ra)) Sp=Sa else Sp =Sb(rb-ra)
和: Sp = Sp+Sb (rb-ra)
という計算がδポイント毎に行われる。それにより、図7Cに示すように、投影ADスペクトルSpには、処理された複数のスペクトルSaとSbに含まれている全てのピークが投影されることになる。なお、最大値と和のうち、いずれか一方のみが計算されてもよいし、或いは、最大値と和の両方が別個の投影ADスペクトルとして計算されてもよい。
【0076】
ステップ196により、処理対象である全てのADスペクトルについて、上述したステップ192と194が繰り返される。全てのADスペクトルについての繰り返し処理が終わると、その全てのADスペクトルに含まれる全てのピークが投影された投影ADスペクトルSpが完成する。ステップ198で、その投影ADスペクトルSpが記憶装置106に保存され、また、必要に応じて外部へ出力される。
【0077】
再び図6を参照する。上述したスペクトル投影処理171が終わると、ステップ172で、投影ADスペクトルのバケット積分が計算される。
【0078】
図9は、この投影ADスペクトルのバケット積分処理172の原理を説明する図であり、図10は、このバケット積分処理172の流れを示す。
【0079】
図9において、参照番号200は、バケット積分が実行される1単位の積分範囲を示し、「バケット」と呼ばれる。バケット200は、このバケット積分処理172においては、規定された一定の幅W(例えば0.04ppm)をもつが、後の処理において、この幅Wが修正され最適化されることになる。参照番号202は、バケット積分を実行すべきケミカルシフトδの全範囲を示し、例えば0ppm〜約16ppmの範囲である。全範囲202は、例えば約200個のバケット200に分割される。このように全範囲202内に設定された多数のバケット200の集合を、以下、「バケットセット」という。また、参照番号204は、バケット積分を実行しない範囲を示し、「ダークリジョン」と呼ばれる。
【0080】
図10に示すように、バケット積分処理172では、ステップ210で、図9に示された全範囲202が多数の一定幅Wのバケット200に均等に分割され、そして、バケット200毎に投影ADスペクトルSpの積分値(すなわち、各バケットにおける投影ADスペクトルSpとケミカルシフト軸とにより挟まれた領域の面積)が計算される。それにより、バケット200の個数に相当する個数のバケット積分データの集合が得られる。この多数のバケット積分データの集合を、以下「積分データセット」という。この積分データセットは、投影ADスペクトルSpのバケット毎のピーク面積を示す一種のヒストグラムである。
【0081】
その後、ステップ212で、ダークリジョン204に該当するバケットと、そのバケットセットのバケット積分データが、ステップ210で得られたバケットセットと積分データセットの中から削除される。ステップ214では、その積分データセットの総和が所定値になるように、その積分データセットがノーマライズされる。そして、ノーマライズされた積分データセット(ヒストグラムデータ)と、バケットセットに含まれる全てのバケットの位置(始点と終点)を表したバケットセット情報とが、記憶装置106に保存され、また、必要に応じて外部出力される。
【0082】
再び図6を参照する。上述したバケット積分処理172が終わると、ステップ174で、自動積分ブロック設定に基づくバケットの自動修正処理が行われる。ここでは、公知技術である自動積分ブロック設定処理により、投影ADスペクトルSp上の種々のピークが自動的に検出され、検出された各ピークが複数のバケットにより分割されないようにバケットの位置と幅Wが修正される。以下では、「ピーク」という用語は、単一の孤立したピークだけでなく、一つのピークと看做せるような一塊の複数のピークを指す意味でも用いる。
【0083】
図11は、この自動積分ブロック設定に基づくバケットの自動修正処理174の原理を説明する図であり、図12は、このバケット自動修正処理174の流れを示す。
【0084】
このバケット自動修正処理174では、図12に示すように、ステップ230で、公知技術である自動積分ブロック設定処理が投影ADスペクトルSpに対して施される。それにより、投影ADスペクトルSp上の種々のピークが自動的に検出され、そして、検出されたピークが存在するケミカルシフトδ領域(以下、「ピーク領域」という)にそれぞれ1対1の関係で積分ブロック(積分区間)が自動的に設定される。例えば、図11Aに示されるように、ADスペクトルSp上に2つのピーク(例えば、左側のものは3つのピークの塊であり、右側は単一のピークである)が存在する場合、その2つのピークが自動的に検出され、そして、図11Bに例示するように、左側のピーク領域には一つの積分ブロック220xが設定され、また、右側のピーク領域には別の一つの積分ブロック220yが設定される。いずれの積分ブロック220x、220yも、対応するピーク領域をカバーしており、一つのピーク領域が複数の積分ブロックにより分割されることはない。
【0085】
これに対し、図11Cに例示するように、現在のバケット200a、200b、200c、…は、図9を参照して既に説明したように、全範囲202を単純に一定幅W(例えばm0.04ppm)で均等分割したものであるから、一つのピーク領域を複数のバケットが分割しているおそれがある。図11A,Cに示す例では、左側のピーク領域が2つのバケット200bと200cにより分割されている。記憶装置106に現在保存されている積分データセット(ヒストグラム)は、このようなバケットセットを用いて計算されたものであるため、分割されたピークの情報が異なる積分データに分散され稀釈化されてしまっていおり、精度が良くない。そこで、この問題を解消するために、以下に述べる後続のステップが行われて、ピークを分割しないようにバケットセットが修正される。
【0086】
すなわち、図12に示すように、ステップ232で、それぞれの積分ブロックの始点に最も近いバケットの終点が記憶装置106内のバケットセット情報からサーチされ、見つかったバケットの終点が、それぞれ対応する積分ブロックの始点と同一値に修正される。さらに、ステップ234で、それぞれの積分ブロックの終点に最も近いバケットの始点が記憶装置106内のバケットセット情報からサーチされ、見つかったバケットの始点が、それぞれ対応する積分ブロックの終点と同一値に修正される。例えば、図11B,C,Dに示された例では、左側の積分ブロック200xの始点s(x)に最も近いバケット200aの終点e(a)がその始点s(x)と同一値に修正され、また、右側の積分ブロック200yの始点s(y)に最も近いバケット200dの終点e(d)がその始点s(y)と同一値に修正される。また、左側の積分ブロック200xの終点e(x)に最も近いバケット200dの始点s(d)がその終点e(x)と同一値に修正され、右側の積分ブロック200yの終点e(y)に最も近いバケット200fの始点s(f)がその終点e(y)と同一値に修正される。
【0087】
上記始点/終点の修正の後、ステップ236で、一つの積分ブロックを分割する複数のバケットがサーチされ、その複数のバケットが一つのバケットに統合される。例えば、図11B,C,Dに示された例では、上記始点/終点の修正の後は、左側の積分ブロック200xだけが2つのバケット200bと200cにより分割されるので、その2つのバケット200bと200cが一つのバケット200bcに統合される。
【0088】
そして、ステップ238で、上述したステップ232〜236で修正された全てのバケットについてバケット積分が再計算される。そして、記憶装置106に現在記憶されている積分データセットのうち、該当するバケットの積分データが、再計算された積分データに置き換えられる。例えば図11Dに示された例の場合、バケット200a、200bc、200d、200e及び200fの全てに修正がなされたので、それらバケット200a、200bc、200d、200e及び200fのそれぞれについてバケット積分が再計算されて、再計算された積分データが、前の積分データに置き換えられる。
【0089】
ステップ239では、以上のようにして修正された積分データセットと修正されたバケットセット情報とが記憶装置106に保存され、また、必要に応じて外部へ出力される。上記修正されたバケットセット情報によれば、自動積分ブロック設定処理によって投影ADスペクトルSpから自動的に検出された全てのピーク領域のいずれもが複数バケットにより分割されないように(つまり、一つのピーク領域は必ず一つのバケットによりカバーされる)ように、バケットセットが定義される。上記修正された積分データセットは、上記修正されたバケットセットに基づいているので、検出された全てのピークの情報は稀釈されておらず、よって、以前の積分データセットより精度が良い。
【0090】
しかしながら、公知の自動積分ブロック設定処理により自動検出されたピークに基づいて設定されたケミカルシフトδ区間(積分区間)が必ずしも適切であるとはいえない。そこで、更にバケットデータセットと成分データセットを最適化するための処理が後続して行われる。すなわち、図6に示すように、上述した自動積分ブロック設定に基づくバケット自動修正処理174の後、更にバケットデータセットと成分データセットを最適化するために、指定ピーク情報に基づくバケット自動修正処理176と、バケットの手動修正処理178とが実行される。
【0091】
まず、指定ピーク情報に基づくバケット自動修正処理176について説明する。
【0092】
この処理176では、既に同定されているNMRスペクトル(ADスペクトルではない)上の特定のピークが指定され、その指定されたピークのピーク領域をカバーするように積分ブロックが決定され、その積分ブロックに基づいて、指定ピークのピーク領域が複数バケットにより分割されないように、現在記憶されているバケットセットが修正される。指定されるピークは、典型的には、このスペクトル解析の用途においてマーカになり得るようなピークである。スペクトル解析の用途が異なればマーカも異なることになるから、用途に応じて、指定されるピークが異なってくる。
【0093】
ピークを指定するためのソースデータとしては、学会誌などで規定するNMRデータの一般的な発表フォーマット(Bull. Chem. Soc. Japan等)に従ったピーク定義データ用いることができる。そのようなフォーマットによるピーク定義データの一例を挙げると、
1H-NMR (CDCl3) δ: 8.06 (2H, t, J = 8.1 Hz, CH2), 7.24 (1H, s, CH3),…
というようなものである。このデータ例において、最初の「1H-NMR」は測定核名を示し、次の「(CDCl3)」は溶媒名を示し、次の「δ: 8.06」は1つ目のピークの中心のケミカルシフトを示し、次の「2H」は1つ目のピークのプロトン数を示し、次の「t」は1つ目のピークの分裂パターンを示し、次の「J = 8.1 Hz」は1つ目のピークのスピン結合定数を示し、次の「CH2」は1つ目のピークに関するコメントである。1つ目のピークの定義の後に、2つ目のピークの定義、3つ目のピークの定義、…が順次続く。ここで、ピークの分裂パターンには種々のものがあるが、代表的な分裂パターンは例えば以下の5種のパターン、
「s」:単一(singlet)
「d」:2分裂(doublet)
「t」:3分裂(triplet)
「q」:4分裂(qualtet)
「m」:多分裂(multiplet)
の組合せとなる。
【0094】
図13Aは3分裂ピークの例を示しており、図13Bは4分裂ピークの例を示している。
【0095】
図13Aに示すように、3分裂ピークの場合、上述したようなフォーマットのピーク定義データにより、その中心のケミカルシフトδ(単位:ppm)と1つのスピン結合定数J(単位:Hz)が定義される。図示は省略するが、2分裂ピークの場合も、同様に、中心のケミカルシフトδと1つのスピン結合定数Jが定義される。単一ピークの場合は、中心のケミカルシフトδが定義されるが、スピン結合定数Jは当然に定義されない。また、図13Bに例示するように、4分裂ピークの場合、中心のケミカルシフトδと、広狭2つのスピン結合定数Ja、Jb(単位:Hz)が定義される。図示は省略するが、多分裂(5以上の分裂)ピークの場合、中心のケミカルシフトδと、分列数に応じた数の異なるスピン結合定数が定義される。なお、中心のケミカルシフトδが決め難い複数分裂ピークの場合、「δa−δb」というようにケミカルシフトδの範囲でピークが定義される場合もあり得る。
【0096】
図13A、Bに例示するように、各ピークのピーク領域(そのピークが位置するケミカルシフトδ区間)は、上述したピーク定義データに含まれる数値、特に中心のケミカルシフトδとスピン結合定数Jとに基づいて決定することができる。例えば図13Aに示す3分裂ピークの場合には、そのピーク領域240xの始点s(x)と終点e(x)は、
s(x)=δ−(J+PW/2)
e(x)=δ+(J+PW/2)
により、また、図13Bに示す4分裂ピークの場合には、そのピーク領域240yの始点s(y)と終点e(y)は、
s(y)=δ−(Jb+PW/2)
e(y)=δ+(Jb+PW/2)
により計算することができる。ここで、「PW」はピーク幅(単位:Hz)を指し、これはNMR装置の分解能やサンプルの状態などの幾つかの条件によって異なってくるので、その条件セットに応じた適当な値を予め設定しておけばよい。図示以外の分裂パターンの場合についても、中心ケミカルシフトδとスピン結合定数J(ここで、単一ピークの場合はJ=0とすればよい)を用いてピークが定義されていれば、上記と同様のやり方でピーク領域が決定できる。また、「δa−δb」というようにケミカルシフトδの範囲でピークが定義されている場合には、そのピーク領域の始点sと終点eは、
s=δa−PW/2
e=δb+PW/2
により計算することができる。
【0097】
さて、本実施形態にかかるNMRデータ処理装置100は、指定ピークについて上述したようなフォーマットのピーク定義データを入力し、そのピーク定義データに基づいて、指定ピークのピーク領域を決定するために必要な情報(以下、「指定ピーク情報」という)を自動的に生成する。生成された指定ピーク情報は、後に何時でも利用できるように、記憶装置106に登録されることができる。
【0098】
図14A,Bは、記憶装置106に登録される指定ピーク情報のデータ構造例を示す。
【0099】
図14Aに示すように、NMRスペクトル解析の異なる用途にそれぞれ対応した異なる指定ピーク情報セット250A、250B、250Cが、記憶装置106に登録されている。例えば、特定の疾病に罹患した者の血液に共通するマーカを確定しようとする用途と、特定種類の食品に共通するマーカを確定しようとする用途とでは、マーカとなり得るピークは異なるから、用途毎に異なるピークが指定されることになる。そのため、用途毎に別の指定ピーク情報セット250A、250B、250Cが登録される。指定ピーク情報セット250A、250B、250Cの各々には、指定された1以上のピークの各々のピーク指定情報が記録されている。各ピークのピーク指定情報には、そのピークを識別するためのピークIDと、そのピークのピーク領域を計算するためのケミカルシフト、分裂パターン及びスピン結合定数などの数値データが含まれている。これらの数値データは、NMRデータ処理装置100に入力された上述したようなフォーマットのピーク定義データの中から、NMRデータ処理装置100により自動抽出されたものである。
【0100】
また、図14Bに例示するように、予め設定されたピーク幅PWを示すピーク幅セット252も、記憶装置106に登録されている。前述したように分解能やその他の条件が異なるとピーク幅PWが異なってくるため、ピーク幅セット252には、異なる条件セットに対応して異なるピーク幅PWが設定されている。
【0101】
ところで、変形例として、図14Aに例示された指定ピーク情報セット250A、250B、250Cには、ケミカルシフト、分裂パターン及びスピン結合定数などの数値データと共に、又はそれに代えて、それらの数値データに基づき上記計算方法により計算されたピーク領域を示すデータ(例えば、始点と終点の数値データ)が登録されてもよい。
【0102】
さて、以上のような指定ピーク情報を用いて、図6に示されたステップ176の、指定ピーク情報に基づくバケットの自動修正処理が、次の手順で行われる。
【0103】
図15は、このバケット自動修正処理176の流れを示す。
【0104】
図15に示すように、ステップ260で、任意に指定された1以上のピークのそれぞれについてピーク定義情報が入力され、そのピーク定義情報に基づいて各指定ピークのピーク定義情報が生成される。或いは、予め記憶装置106に登録されている図14Aに例示されたような指定ピーク情報セット250A、250B、250Cの中から、今回の用途に対応した指定ピーク情報セットが選択され、その選択された指定ピーク情報セットからピーク毎の指定ピーク情報が読み込まれる。さらに、予め設定されている図14Bに例示されたような条件毎のピーク幅データの中から、今回の解析に最適なピーク幅データが読込まれる。
【0105】
そして、ステップ262で、各指定ピークの指定ピーク情報とピーク幅データに基づいて、上述したような計算方法により、各指定ピークのピーク領域が決定され、そのピーク領域がそのまま積分ブロックとして設定される。例えば、図13A,Bに例示された2種類のピークの場合、それらのピークのピーク領域240x及び240yがそれぞれ積分ブロックとして設定される。
【0106】
その後、ステップ264で、図12に示した自動積分ブロック設定に基づくバケット修正処理174のステップ232〜238と同様の手順で、記憶装置106に記憶されている1度修正されたバケットセットが、指定ピークに対応する積分ブロックに応じて更に修正される。この2回目のバケット修正により、いずれの指定ピークのピーク領域も複数のバケットにより分割されないようになる(つまり、いずれの指定ピークのピーク領域の必ずいずれか一つのバケット内に入るようになる)。また、ここで修正がなされたバケットについては、投影ADスペクトルSpのバケット積分が再計算され、再計算されたバケットの積分データにより、記憶装置106に記憶されている対応するバケットの積分データが置き換えられる。
【0107】
そして、ステップ239で、このように2度修正されたバケットセットと積分データセットが、記憶装置106に保存され、また、必要に応じて外部に出力される。
【0108】
次に、図6に示されたステップ178の、バケットの手動修正処理について説明する。この処理178は、上述した2回の自動的なバケット修正だけでは満足できない場合、オペレータが手動でバケットを更に修正できるようにするためのものである。
【0109】
図16A,Bはバケットの手動修正処理178の原理を示し、図17はバケットの手動修正処理178の流れを示す。
【0110】
この処理178において、記憶装置106に保存されている投影ADスペクトルSpと前述した2度の自動修正を終えたバケットセットが、NMRスペクトル処理装置100のディスプレイスクリーンに表示される。オペレータはその表示を見ながら、任意のバケットの始点又は終点に対する修正要求をNMRスペクトル処理装置100に入力する。例えば、図16Aに例示するように、或るバケット200jを修正したい場合、オペレータは、そのバケット200jを指定した上で、その始点を終点の修正要求として、新たな始点s(j)と新たな終点e(j)を入力する。すると、図17に示すように、ステップ270で、指定されたバケット200jの始点と終点が、オペレータから入力された始点s(j)と終点e(j)と同一値に修正される。また、ステップ272で、指定されたバケットの始点s(j)側の隣バケットの終点e(i)が指定バケットの始点s(j)と同一値に修正され、ステップ274で、指定バケットの終点e(j)側の隣バケットの始点s(k)が指定バケットの終点e(j)と同一値に修正される。その後、ステップ276で、修正されたバケット毎にバケット積分が再計算され、再計算された積分データにより、記憶装置106に記憶されている対応するバケットの積分データが置き換えられる。そして、ステップ278で、手動修正の終わったバケットセットと、そのバケットセットに基づいて上記のように修正された積分データセットとが、記憶装置106に保存され、また必要に応じて外部へ出力される。
【0111】
以上のように、図6のステップ172で、全バケットが一定幅(例えば0.04ppm)をもつ均等幅のバケットセットが初期的に設定され、その後、ステップ174と176と178の3段階のバケット修正が行われて、バケットにより幅の異なる不均等幅のバケットセットが完成する。なお、ステップ174と176と178の3つの修正段階は、必ずしもその全てが実行されなければならないわけではなく、いずれかの修正段階(例えば手動修正)が省略されても良い。いずれにしても、最終的に完成された不均等幅のバケットセットは「最適化バケットセット」と呼ばれる。
【0112】
図18は、記憶装置106に保存された最適化バケットセットのデータ構造例を示す。
【0113】
図18に示すように、スペクトル解析の異なる用途にそれぞれ対応して異なる最適化バケットセット280A、280B、280Cが、記憶装置106に記憶されている。用途が異なれば、既に説明したように指定ピークが異なり、また、処理対象のNMRスペクトル自体も異なるので、当然、出来上がる最適化バケットセットが異なるからである。最適化バケットセット280A、280B、280Cの各々には、用途を示す用途ID、ピーク幅PWを示す数値データ、ケミカルシフト軸スケールの基準点(原点)を示す数値データ、並びに、このバケットセットを構成する多数のバケットのバケット番号、始点及び終点のデータなどが登録されている。さらに、いずれかの指定ピークに対応するバケットには、その対応する指定ピークを指すピークIDも登録されている。
【0114】
上述した3段階のバケット修正処理の説明から分かるように、最適化バケットセットにおいては、全てのバケットが均等な幅(例えば0.04ppm)をもってはおらず、それぞれに特有の不均等な幅をもっている。そして、投影ADスペクトルSpから自動的に検出された全てのピークについても、加えて、指定ピーク情報により指定された全てのピークについても、各ピークのピーク領域は必ずいずれか一つのバケットの中に入っており、いずれのピーク領域も複数バケットにより分割されてはいない。さらに、この最適化バケットセットの作成の基礎となった投影ADスペクトルSpには、解析対象である多数のADスペクトル上のほぼ全てのピークが投影されており、それらのピークのピーク領域が最適化バケットセット反映されている。さらに、解析用途のために重要であると考えられる既知の指定ピークのピーク領域も、最適化バケットセットに反映されている。従って、この最適化バケットセットを用いて、解析対象である多数のADスペクトルのそれぞれのバケット積分を行なうことにより、いずれのADスペクトルも、そこに含まれるほぼ全てのピークの情報が良好に維持された状態で、積分データセット(ヒストグラム)に変換されることになる。
【0115】
再び図6を参照する。最適化バケットセットが完成すると、ステップ180の、多数ADスペクトルの最適化バケット積分処理が行われる。
【0116】
図19は、多数ADスペクトルの最適化バケット積分処理180の流れを示す。
【0117】
図19に示すように、ステップ290で、最適化バケットセットが記憶装置106から読込まれる。ステップ292で、解析対象である多数のADスペクトルの各々が記憶装置106から読込まれる。ステップ292で、読込まれたADスペクトルのケミカルシフト軸スケール(δスケール)が、最適化バケットセットのケミカルシフト軸スケール(δスケール)に合わされる(例えば、ADスペクトルの基準点が最適化バケットセットの基準点に一致するように、ADスペクトルのケミカルシフト軸スケールがシフトされる。)。そして、ステップ296で、そのADスペクトルのバケット積分が、最適化バケットセットを用いて実行され、ステップ298で、そのバケット積分で求まった積分データセット(ヒストグラムデータ)が記憶装置106に保存され、必要に応じて外部へ出力される。
【0118】
ステップ299により、解析対象の全てのADスペクトルについて、上述したステップ292〜298の処理が繰り返される。その結果、解析対象の全てのADスペクトルが、それぞれ積分データセット(ヒストグラムデータ)に縮約されて、記憶装置106に保存される。
【0119】
再び図6を参照する。その後、ステップ182で、解析対象の全てのADスペクトルの最適化バケット積分データセット(ヒストグラムデータ)が、次の統計処理に渡すのに適したデータ形式に整えられた上で、記憶装置106に保存され、必要に応じて外部へ出力される。
【0120】
以上図6に示された流れに沿って説明した処理が実行されることにより、図1に示された最適化バケット積分を用いたデータの縮約処理112と、積分結果データの保存/出力処理114が完了する。その後に、図1に示される統計処理116が実行される。この統計処理116では、解析対象の全てのADスペクトルの積分データセット(ヒストグラムデータ)が記憶装置106から読込まれ、それらの積分データセット(ヒストグラムデータ)を用いて、所定の統計処理(例えば多変量解析法の一つである主成分分析)が実行され、そして、マーカとなるピークの確定などの解析結果が生成され出力される。統計処理の具体的な手法としては、公知の種々の方法を用いることができる。例えば、後に詳述するように、本発明の原理に従う統計処理では、いずれも多変量解析法の一つである主成分分析(Principal component Analysis:PCA)と部分空間法(Soft Independent Modeling of Class Analogy:SIMCA)とが組み合わせて用いられる。既に説明するようなしたように、統計処理の材料であるADスペクトルの積分データセット(ヒストグラムデータ)には、ADスペクトル上の重要なピークの情報が良好に含まれているので、統計処理の結果は精度の高いものとなる。
【0121】
図20は、本発明に従うNMRデータ処理装置の別の実施形態の全体的な構成と機能を示す。
【0122】
このNMRデータ処理装置300は、前述のNMRデータ処理装置100とは別の用途に使用される。すなわち、前述のNMRデータ処理装置100の用途は、多数のサンプルのNMRスペクトルを解析し統計的なデータを得ることであるのに対し、このNMRデータ処理装置300の用途は、基本的に一つのサンプルのNMRスペクトルを分析してそのサンプルの性質又は成分などを検査すること(例えば、或る人の血液のNMRスペクトルを分析して、その人が特定の疾病に罹患してないかどうか検査すること、あるいは、或る食品のNMRスペクトルを分析して、そこに如何なる物質が含有されているか検査すること、など)にある。このNMRデータ処理装置300も、前述のNMRデータ処理装置100と同様に、プログラムされたコンピュータシステムを用いて実現することができる。
【0123】
図20に示すように、NMRデータ処理装置300のプロセッサ304は、記憶装置306に記憶されている所定のコンピュータプログラムを実行することにより、FIDデータ入力処理308、NMRスペクトル処理310、最適化バケット積分を用いたデータ縮約処理312、ヒストグラム分析処理314、分析結果データ保存/出力処理316を行う。記憶装置306には、上記コンピュータプログラムの他に、予め、図18に例示したような用途別の最適化バケットセット280A、280B、280Cが記憶されている。さらに記憶装置306には、検査目的に対応した参照モデルデータが記憶されている。検査目的に対応した参照モデルデータとは、検査の判断を行う際に検査対象のNMRデータと対比される基準のデータである。例えば、人の血液からその人が特定の疾病に罹患してないかどうか検査するという用途の場合であれば、その特定の疾病に罹患している多数の人々の血液サンプルのNMRデータを前述のNMRデータ処理装置200で解析することによって確定されたマーカの情報が、参照モデルデータの一つとして採用することができる。
【0124】
FIDデータ入力処理312では、NMR装置102から出力される検査対象の一サンプルのFIDデータが入力され、記憶装置306に記憶される。NMRスペクトル処理310では、入力されたFIDデータに対して、図2に示されたと同様の流れの処理が行われて、そのFIDデータの絶対値微分であるADスペクトルが生成され、記憶装置306に記憶される。
【0125】
データ縮約処理312では、記憶装置306に予め記憶されている用途に応じた最適化バケットセットを用いた最適化バケット積分が、検査対象のADスペクトルに対して実行され、それにより、検査対象のADスペクトルが最適化された積分データセット(ヒストグラム)に縮約される。ヒストグラム分析処理314では、検査対象の積分データセット(ヒストグラム)が、記憶装置306に予め記憶されている用途に応じた参照モデルデータと対比され、対比結果に基づく判断がなされて検査結果が生成される。分析結果の保存/出力処理316では、生成された検査結果が記憶装置306に保存され、また外部へ出力される。
【0126】
図21は、図20に示された最適化バケット積分を用いたデータ縮約処理312の流れを示す。
【0127】
ステップ320で、検査対象のADスペクトルが記憶装置306から読込まれ、ステップ322で、用途に対応した最適化バケットセットが記憶装置306から読込まれる。ステップ324で、検査対象のADスペクトルのケミカルシフト軸スケール(δスケール)が最適化バケットセットのそれに一致させられる。その後、ステップ326で、最適化バケットセットを用いた最適化バケット積分が、検査対象のADスペクトルに対して実行され、検査対象の積分データセット(ヒストグラム)が求まる。ステップ328で、検査対象の積分データセット(ヒストグラム)が記憶装置306に保存され、必要に応じて外部へ出力される。
【0128】
図22は、図20に示されたヒストグラムの分析処理314の流れを示す。
【0129】
ステップ330で、検査対象の積分データセット(ヒストグラム)が記憶装置306から読込まれる。ステップ332で、検査目的に対応した参照モデルデータが記憶装置306から読込まれる。ステップ334で、検査対象の積分データセット(ヒストグラム)と、検査目的に対応した参照モデルデータとが対比され、検査結果が判断される。ステップ336で、検査結果が記憶装置306に保存され、また外部へ出力される。
【0130】
以上のようなサンプルの検査を用途とするNMRデータ処理においても、用途に応じて予め用意された最適化バケットセットを用いた最適化バケット積分がスペクトルに対して行われるので、スペクトルがもつピーク情報が良好に維持され、精度の高い検査結果を得ることができる。また、分析には、NMRスペクトルの絶対値微分であるADスペクトルが用いられるため、面倒な位相補正やベースライン補正が不要になり、処理効率が向上する。
【0131】
次に、本発明の一実施形態にかかるNMRスペクトルの統計処理装置について説明する。
【0132】
本発明の一実施形態にかかる統計処理装置は、図1に示したNMRデータ処理装置100内に統計処理部116として組み込まれており、そして、典型的には、既に説明した前処理部分(図1内の処理部108,110,112,114)と一緒にコンピュータプログラムとして具現化されている。しかし、これは説明のための一つの例示にすぎず、本発明に従うNMRスペクトルの統計処理装置は、既に説明した前処理部分からは分離された単独装置として構成されることもできる。
【0133】
図22は、本発明の一実施形態にかかるNMRスペクトルの統計処理装置、すなわち、図1に示した統計処理部116、の機能的な構成を示す。
【0134】
図22に示すように、統計処理部116は、多変量解析部340と、ユーザ要求入力部342と、表示制御部344とを有する。
【0135】
多変量解析部340は、PCA解析部346とSIMCA解析部348とを有する。PCA解析部346は、記憶装置106に保存されている多数のサンプルのNMRスペクトルの積分データセット(以下、「NMRヒストグラム」という)を入力して、主成分分析(Principal component Analysis: PCA)による多変量解析を行なう。また、SIMCA解析部348は、記憶装置106に保存されている多数のサンプルのNMRヒストグラムを入力して、部分空間法(Soft Independent Modeling of Class Analogy:SIMCA)(以下、SIMCAという)による多変量解析を行なう。PCA解析部346とSIMCA解析部348の入力となる解析対象としての多数のサンプルのヒストグラムのデータは、記憶装置106内のPCAテーブル350に記録されている。PCAテーブル350の構成については、後に説明する。
【0136】
記憶装置106内には、図1に示した積分結果データの保存/出力処理114により書き込まれた大量のサンプルのNMRヒストグラムデータ356がある。PCA解析部346とSIMCA解析部348は、それぞれ、その大量のサンプルのNMRヒストグラムデータ356の中から、任意の多数のサンプルのNMRヒストグラムのデータを解析対象として抽出してPCAテーブル350に登録することができる。多変量解析部340は、ユーザからの要求に応じてPCAテーブル350の更新も行なう。また、PCA解析部346とSIMCA解析部348は、それぞれ、PCA解析結果(例えば、サンプルのスコア及び変数のローディングなど)とSIMCA解析結果(サンプルの各クラスまでの距離、変数のモデリング力及び識別力など)を、解析結果データ352として、記憶装置106内に保存することができる。
【0137】
SIMCA解析部348とPCA解析部346は、後に詳述するように、前者による解析結果が後者の解析にフィードバックされるように連携して動作することができる。それにより、このような多変量解析を行なう目的、例えばメタボノミクスにおいてバイオマーカを探し当てる目的が、より容易に達成されるようになる。
【0138】
表示制御部344は、PCA解析部346からPCA解析結果(スコア及びローディングなど)を受け、また、SIMCA解析部348からとSIMCA解析結果(各クラスまでの距離、モデリング力及び識別力など)を受けて、そして、そのPCA解析結果とSIMCA解析結果を表示したグラフィカルユーザインタフェース(以下、「UI」という)346を作成し、そのUI346をコンピュータシステム100(図1)のディスプレイ装置(図示省略)に表示する。表示制御部344は、記憶装置106に記憶されている多数のサンプルのNMRスペクトルデータ350の中から、ユーザにより選択された1以上のサンプルのNMRスペクトルデータを読み込み、そのUI346上に、PCA解析結果とSIMCA解析結果と一緒に、ユーザにより選択されたサンプルのNMRスペクトルを表示する。なお、この実施形態では、表示されるNMRスペクトルデータは、元のNMRスペクトルデータではなく、それを絶対値微分して得られたADスペクトルデータであるが、これを以下では単に「NMRスペクトルデータ」と呼ぶ。
【0139】
表示制御部344は、UI346上のPCA解析結果とSIMCA解析結果の表示とNMRスペクトルの表示とが連携するように、UI346上での両者の表示を制御する。それにより、オペレータは多変量解析結果とNMRスペクトルとの関連性が視覚的に容易に理解できるようになり、このような多変量解析を行なう目的、例えばメタボノミクスにおいてバイオマーカを探し当てる目的が、より容易に達成されるようになる。さらに、そのUI346上には、ユーザが各種の要求を入力するための各種の入力ボタンも表示される。そのUI346の詳細については、後に説明する。
【0140】
ユーザ要求入力部342は、ユーザによりマウスまたはキーボードなどから上記UIに入力された各種の要求を受け、その入力要求を上述した多変量解析部340および表示制御部344に渡す。多変量解析部340および表示制御部344は、ユーザから入力された要求に応答して、後述するような各種の動作を行う。
【0141】
図24は、図23に示したPCAテーブル350の構成例を示す。
【0142】
既に述べたように、PCAテーブル350には、解析の対象となる多数のサンプルのNMRヒストグラムのデータが記録されている。すなわち、図24に示すように、PCAテーブル350には、ヒストグラムを作成するときに行なわれたバケット積分に関するバケット積分条件400が記録されており、これには、バケット積分が行なわれたケミカルシフトδの全範囲(図9に示した全範囲202に相当)、バケットの基本的な幅(図9に示した幅Wに相当)、自動積分ブロック設定でバケット幅の調整を行ったか否か、全範囲の合計積分値、及びダークリジョン((図9に示したダークリジョン204に相当)(図示の例では、5.3ppmから4.3ppmという1つのダークリジョンだけが登録されているが、複数のダークリジョンが登録され得る)が含まれる。
【0143】
また、PCAテーブル350には、解析対象のサンプルの数402、各サンプルを構成する多数の変数の数(つまり、バケットの数)404、及び、各サンプルのNMRスペクトルデータが格納されているフォルダ名406とファイル名408のセット(つまり、各サンプルのNMRスペクトルデータファイルのパス名)が記録されている。ここで、前述した図23では、図示の都合から、多数のサンプルのNMRスペクトルデータは纏めて1つのブロック354で示されているが、このブロック354は実際には、サンプル毎のNMRスペクトルデータを格納した多数のスペクトルデータファイルの集まりであり、それら多数のスペクトルデータファイルのパス名(フォルダ名406とファイル名408)がPCAテーブル350に記録されている。図24では、図示の都合から、3つのサンプルのスペクトルデータファイルのパス名しか示されていないが、実際には、サンプル数402に示された数のサンプルの全てのスペクトルデータファイルのパス名がPCAテーブル350に記録されている。
【0144】
さらに、PCAテーブル350には、UI346の画面上にプロットされるサンプル毎のマークの形状とカラーをそれぞれ指定したプロットタイプ410とプロットカラー412が定義されている。プロットタイプ410は、例えば、値「0」が×形マーク、値「1」が塗りつぶしの無い円形マーク、値「−1」が黒く塗りつぶされた円形マーク、…などを指定する。また、プロットカラー412は、3原色である赤(R)、緑(G)及び青(B)の明度(濃度)値のセットで定義される。後述するように、UI346上にはPCA解析結果の一つであるスコアプロットや、SIMCA解析結果の一つであるクーマンプロットが表示されるが、そのスコアプロットやクーマンプロット上では、各サンプルは、PCAテーブル350で指定された形状とカラーを持ったマークで表示されることになる。
【0145】
さらに、PCAテーブル350には、サンプル毎のサンプルステータス414が登録されている。各サンプルのサンプルステータス414は、該当のサンプルが解析対象に含まれるか否かを示すものであり、例えば、値「0」が該当のサンプルが解析対象に含まれることを意味し、値「1」が該当のサンプルがユーザからの要求により解析対象から除外されたことを意味する。後に説明するように、PCAテーブル350に登録されているサンプルの全ては初期的には解析対象に含まれるのである(つまり、サンプルステータスが「0」である)が、ユーザは、UI346のスコアプロット上でクーマンプロット上で任意のサンプルを選択して、選択したサンプルを解析対象から除外することができ、そのようにして除外されたサンプルのサンプルステータスは「1」に変わる。サンプルステータスが「1」であるサンプルは、PCA解析やSIMCA解析において計算に入れられない。
【0146】
さらに、PCAテーブル350には、実質的な解析対象である多変量データ行列418が登録されている。この多変量データ行列418には、上記積分全範囲に含まれる全バケットのそれぞれの中点のケミカルシフト値(これは、多変量解析における変数つまり記述子に相当する)418と、サンプル毎のNMRヒストグラムのデータ(すなわち、サンプル毎の最適化バケット積分で得られた積分データのセットであり、解析対象である多変量データ行列の正味の部分である)420、それぞれのバケットの始点のケミカルシフト値422と終点のケミカルシフト値424、及び、それぞれのバケットのステータス426が登録されている。各バケットのステータス426は、そのバケット(つまり、その変数)を解析に使用するか否かを示すものであり、例えば、値「0」はそのバケットを解析に使用することを意味し、値「1」は解析に使用しないことを意味する。後述するように、UI346上に表示されるSIMCA解析結果の一つである識別力に基づいて、ユーザは任意のレベル以上に高い識別力をもつ変数(バケット)だけを選択し、選択されたバケットだけを用いて再度PCA解析やSIMCA解析を行なうことを要求することができる。全てのバケットは、初期的にはステータスが「0」であって、解析に使用されるようになっているが、上記のようにして特定のバケットだけが後の解析のために選択された場合、選択されなかったバケットのステータスは「1」に変わり、ステータスが「1」であるバケットは後の解析では使用されないことになる。
【0147】
以上のような構成を持つPCAテーブル350を使用して、PCA解析とSIMCA解析が実行されることになる。
【0148】
図25は、図23に示した多変量解析部340のPCA解析部346とSIMCA解析部348並びに表示制御部344の機能をより詳細に示している。
【0149】
図25に示すように、PCA解析部346は、PCAモデル読込・追加・保存部360と、PCA計算部362とを有する。PCAモデル読込・追加・保存部360は、記憶装置106上の大量サンプルのNMRヒストグラムデータ356の中から、解析対象となる多数のサンプルのNMRヒストグラムデータを選んで、その選ばれた多数のサンプルのNMRヒストグラムデータに基づいてPCAテーブルの情報を新規に作成する機能や、記憶装置106上の大量サンプルのNMRヒストグラムデータ356の中から追加のサンプルのNMRヒストグラムデータを選んで、それをPCAテーブルの多変量データ行列に追加する機能をもつ。さらに、PCAモデル読込・追加・保存部360は、作成されたり追加されたり或は変更されたりしたPCAテーブルの情報を、記憶装置106にPCAテーブル350として保存する機能をもつ。PCA計算部362は、PCAモデル読込・追加・保存部360により用意されたPCAテーブルの情報を用いてPCA解析の計算を行ってPCAモデルを作成し、そのPCAモデルに基づいたPCA解析結果(例えば、各サンプルのスコアや、各変数(各バケット)のローディングなど)を出力する。なお、PCA解析の計算方法それ自体は周知であるから(例えば、非特許文献1を参照)、これについての詳細な説明はこの明細書では省略する。
【0150】
SIMCA解析部370は、PCAモデル読込・追加・保存部370と、SIMCA計算部370を有する。PCAモデル読込・追加・保存部370は、記憶装置106上の大量サンプルのNMRヒストグラムデータ356の中からユーザが第1と第2のクラスにそれぞれ割り当てたサンプルのNMRヒストグラムデータを読込んで、第1と第2の2つのクラスのPCAテーブルの情報を用意する機能や、記憶装置106上の大量サンプルのNMRヒストグラムデータ356の中からユーザがテストクラスに割り当てたサンプルのNMRヒストグラムデータを読込んで、テストクラスのPCAテーブルの情報を用意する機能をもつ。さらに、PCAモデル読込・追加・保存部370は、各クラスのPCAテーブルの情報を、記憶装置106に各クラスのPCAテーブル350として保存する機能をもつ。SIMCA計算部372は、PCAモデル読込・追加・保存部370により用意された複数のクラスのPCAテーブルの情報を用いてSIMCA解析の計算を行って各クラスのPCAモデルを作成し、それらのPCAモデルに基づいたSIMCA解析結果(例えば、各サンプルの各クラスからの距離や、各変数(各バケット)のモデリング力や識別力など)を出力する。SIMCA解析の計算には、クラス毎のPCA計算が含まれており、このクラス毎のPCA計算を行うために、SIMCA計算部372は、PCA解析部346のPCA計算部362を使用する。なお、SIMCA解析の計算方法それ自体は周知であるから(例えば、非特許文献1を参照)、これについての詳細な説明はこの明細書では省略する。
【0151】
PCA解析部346とSIMCA解析部348は、解析データ記憶部364と解析データ保存部366とを有する。解析データ記憶部364は、PCA解析部346から出力されたPCA解析結果と、SIMCA解析部348から出力されたSIMCA解析結果を記憶する。解析データ保存部366は、解析データ記憶部364に記憶されたPCA解析結果とSIMCA解析結果を、記憶装置106上に解析結果データ352として保存する。
【0152】
後に詳述するように、解析データ記憶部364に記憶されるSIMCA解析結果の中には、或るレベル以上に高い識別力をもつ変数(バケット又はそれに対応するケミカルシフト値)を選択する情報が含まれている。この変数選択情報は、解析データ記憶部364を通じて、PCA計算部362及びSIMCA計算部372にフィードバックされることができる。そして、PCA計算部362とSIMCA計算部372はそれぞれ、フィードバックされた変数選択情報に従って、選択された変数(つまり、或るレベル以上に高い識別力をもつバケット又はそれに対応するケミカルシフト値)だけを用いて、再度、PCA解析とSIMCA解析を行なって、修正されたPCA解析結果とSIMCA解析結果を再度出力することができるようになっている。これにより、より望ましいPCA解析結果とSIMCA解析結果を得ることができるようになる。
【0153】
表示制御部344は、PCA解析画面制御部374と、SIMCA解析画面制御部376と、NMRスペクトル連携部378とを有する。PCA解析画面制御部374は、PCA計算部362から解析データ記憶部364に出力されたPCA解析結果を受けて、後に具体的に説明するように、UI346上にPCA解析結果を示した複数種のチャート(例えば、スコアプロット、ローディングプロット、寄与率チャート及びローディングチャート)(以下、「PCA解析結果チャート」と総称する)を表示し、また、UI346に入力されたユーザからの選択、拡大、削除及び初期化などの要求に応答して、UI346上のそれらのチャートを変化させる。SIMCA解析画面制御部376は、SIMCA計算部372から解析データ記憶部364に出力されたSIMCA解析結果を受けて、後に具体的に説明するように、SIMCA解析結果を示す複数種のチャート(例えば、クーマンプロット、モデリング力チャート及び識別力チャート)(以下、「SIMCA解析結果チャート」と総称する)をUI346上に表示し、また、UI346に入力されたユーザからの選択、拡大、削除及び初期化などの要求に応答して、UI346上のそれらのチャートを変化させる。
【0154】
NMRスペクトル連携部378は、記憶装置106上の大量のサンプルのNMRスペクトルデータ354の中から、UI346上でユーザにより選択された1又は複数のサンプルのNMRスペクトルデータを読込んで、その選択されたサンプルのNMRスペクトルを示すチャートを、UI346上に上述したPCA解析結果チャートまたはSIMCA解析結果チャートと並べて表示する。
【0155】
以下では、図25に示した各部の機能を、UI346の画面例を参照しつつ説明する。
【0156】
図26は、PCA解析結果を表示した場合におけるUI346の画面例を示す。図27は、SIMCA解析結果を表示した場合におけるUI346の画面例を示す。
【0157】
図26と図27に示すように、この実施形態におけるUI346の画面430(以下、「UI画面」という)は、PCA解析結果とSIMCA解析結果とが交互に切り替え可能な別の画面に表示されるようになっているが、これは表示方法の一例にすぎない。十分に大型のディスプレイ装置を使用する場合のために、同一画面にPCA解析結果とSIMCA解析結果とを表示できるようになっていてもよい。
【0158】
図26と図27に示すように、PCA解析結果とSIMCA解析結果のいずれを表示する場合にも、UI画面430には、コントロールパネル432があり、そこには、図1に示したステップ108〜114の前処理を制御するための各種要求をユーザが入力するための前処理コントロールパネル434と、PCA解析を制御するための各種要求をユーザが入力するためのPCAコントロールパネル436と、SIMCA解析を制御するための各種要求をユーザが入力するためのSIMCAコントロールパネル438とが図示のように配置される。
【0159】
このUI画面430上のPCAコントロールパネル436の一番上の「PCA」選択ラジオボタンがユーザにより操作された(例えばクリックされた)場合には、それに応答して、図25に示したPCA解析画面制御部374が動作する。PCA解析画面制御部374は、解析データ記憶部364からPCA解析結果を受けて、UI画面430上に図26に示すように、複数のPCA解析結果チャート、すなわち、スコアプロット440、ローディングプロット442、寄与率プロット444及びローディングプロットを表示する。他方、SIMCAコントロールパネル438の一番上の「SIMCA」選択ラジオボタンが操作された場合には、それに応答して図25に示したSIMCA解析画面制御部376が動作する。SIMCA解析画面制御部376は、解析データ記憶部364からSIMCA解析結果を受けて、UI画面430上に図27に示すように、複数のSIMCA解析チャート、すなわち、クーマンプロット462、第1のクラスに対するモデリング力チャート464、第2のクラスに対するモデリング力チャート466及び識別力チャート468を表示する。
【0160】
さらに、図26と図27に示すように、PCA解析結果とSIMCA解析結果のいずれを表示する場合にも、図25に示したNMRスペクトル連携部378が動作して、UI画面430上に、NMRスペクトルチャート450を表示する。NMRスペクトルチャート450には、ユーザに選択された1以上のサンプルのNMRスペクトルのグラフが表示される。ここで、注目すべき点は、PCA解析結果を表示した場合、図26に示すように、NMRスペクトルチャート450と寄与率チャート444とローディングチャート446とが、それぞれの横軸であるケミカルシフト軸のスケールが互に一致するようにして、ケミカルシフト軸に直交する縦軸方向に配列される点である。また、同様に、SIMCA解析結果を表示した場合、図27に示すように、NMRスペクトルチャート450と識別力チャート468とが、それぞれの横軸であるケミカルシフト軸のスケールが互に一致するようにして、ケミカルシフト軸に直交する縦軸方向に配列される。これにより、ユーザは、寄与率、ローディング又は識別力の大きい変数(バケット又はそれに対応するケミカルシフト値)とNMRスペクトルのピークとの相関関係が視覚的に容易に把握でき、例えばメタボノミクスにおいてバイオマーカを決定することがより容易になる。
【0161】
以下では、PCA解析を行なう場合と、SMCA解析を行なう場合とに分けて、それぞれの場合における動作をより具体的に説明する。まず、PCA解析を行なう場合について説明する。
【0162】
まず、図26に示したUI画面430上のPCAコントロールパネル436内の「PCA」選択ラジオボタンが操作された上で「Open_Model」ボタンが操作されると、図25に示したPCAモデル読込・追加・保存部360が動作して、記憶装置106内の大量のサンプルのNMRヒストグラムデータ356の中から、ユーザに指定された複数のサンプルのNMRヒストグラムデータを選択して読み込み、図24に示したような、多変量データ行列やその他の情報をからなるPCAテーブルの情報を作成する。ユーザ指定されたサンプルの数がN個で、各サンプルのNMRスペクトルを構成する変数(バケット)の数がM個であるならば、PCAテーブルの情報に含まれる多変量データ行列はN×Mのデータ行列となる。
【0163】
PCAモデル読込・追加・保存部360は、作成したPCAテーブルの 情報をPCA計算部362に引渡す。PCA計算部362は、そのPCAテーブルの情報を用いてPCA解析の計算を行なって、そのPCAテーブルの情報に含まれている多変量データ行列についてのPCAモデルを算出する。ここで、PCA解析計算において計算される主成分の数は、UI画面430上のPCAコントロールパネル436の一番上の「PCA」選択ラジオボタンの右脇に置かれた入力ボックスにユーザが入力した数で決まる(図示の例では主成分数として「6」が設定されている)。PCA計算部362は、算出されたPCAモデルに基づくPCA解析結果として、各主成分に対する各サンプルのスコア、そのスコアの分散、各主成分に対する各変数のローディング及び各変数の寄与率(全主成分に対するローディングの絶対値の和)などを算出する。算出されたPCA解析結果は、解析データ記憶部364に記憶される。
【0164】
PCA解析画面制御部374が、解析データ記憶部364から上記PCA解析結果を受け取る。PCA解析画面制御部374は、図26に示すように、各主成分に対する各サンプルのスコアに基づいて、スコアプロット440を作成してUI画面430上に表示し、各主成分に対する各変数のローディングに基づいて、ローディングプロット442とローディングチャート446を作成してUI画面430上に表示し、さらに、各変数の寄与率に基づいて、寄与率チャート444を作成してUI画面430上に表示する。
【0165】
図26に示すように、スコアプロット440では、ユーザにより選択された2つの主成分に対するそれぞれのスコアをそれぞれX軸とY軸にとり、各サンプルのその2つの主成分に対するスコアがプロットされる。X軸とY軸に相当する主成分は、PCAコントロールパネル436内の「X」軸プルダウンメニュー及び「Y」軸プリダウンメニューからユーザにより選ばれた番号の主成分である(図示の例では、X軸が第「1」主成分(PCA1)、Y軸が第「2」主成分(PCA2)。)。プロットされるサンプルのマークの形状と色は、上記PCAテーブル情報の中のサンプル毎のプロットタイプとプロットカラー(図24の参照番号410、412に対応する情報)に従う。さらに、X軸とY軸には、対応する主成分番号とその分散も表示される(例:PC1(39.8%))。さらに、計算に使用されたサンプル数も表示される。
【0166】
スコアプロット440上で、複数のサンプルマーク間の位置が近いほど、それらのサンプルは特徴的に互いにより似ており、他方、位置が遠いほどより違っていることを意味する。従って、スコアプロット440上に、例えば互いに分離された幾つかのサンプルマークの塊が存在するならば、分析対象のサンプルが、それぞれの塊に対応する特徴的に異なる幾つかのクラスに分けられたと判断することができる。
【0167】
また、各主成分におけるスコアの分散は、その値が大きいほど、その主成分がサンプルのクラス分けに寄与する度合いが高いことを意味する。例えば、X軸とY軸の主成分の分散の和が、或る値(例えば、60%程度)より大きければ、それらの主成分を用いたPCAモデルにおいてサンプルがかなり明確にクラス分けされ得ると判断することができる。
【0168】
PCAコントロールパネル436内の「Name」チェックボックスにユーザがチェックを入れると、PCA解析画面制御部374は、図28(スコアプロット440内の部分領域の拡大図)に示すように、スコアプロット440上の全てのサンプルマークの近傍に、対応するサンプルのNMRスペクトルのファイル名を表示する。マウスポインターが各サンプルの上に置かれた場合にも、スコアプロット440の右上に自動的に対応するファイル名が表示される。これにより、ユーザは、スコアプロット440上の各サンプルマークが、具体的にどのサンプルに該当するのかを容易に把握できる。
【0169】
図26に示すように、ローディングプロット442では、PCAコントロールパネル436内の「X」軸プルダウンメニュー及び「Y」軸プリダウンメニューで選択された2つの主成分におけるローディングをそれぞれX軸とY軸にとり、その2つの主成分に対する各変数(バケット又はそれに対応するケミカルシフト値)のローディングが、所定の形状とカラーをもつ変数マークでプロットされる。また、X軸とY軸には、対応する主成分願号とその分散が表示される(例:PC1(39.8%))。また、計算に使用された変数(バケット)の数も表示される。
【0170】
ローディングプロット442上で、X軸とY軸の原点から遠くに存在する変数ほど、X軸とY軸にそれぞれ対応する主成分に対する寄与度が高い、つまり、サンプルのクラス分けに寄与する度合いが高いことを意味する。
【0171】
PCAコントロールパネル436内の「Name」チェックボックスにユーザがチェックを入れると、PCA解析画面制御部374は、図29(ローディングプロット442内の部分領域の拡大図)に示すように、ローディングプロット442上の全ての変数マークの近傍に、対応する変数(バケット)のケミカルシフト値(ppm)を表示する。また、マウスポインターが各変数マークの上に置かれた場合にも、ローディングプロット442の右上に自動的に対応するケミカルシフト値が表示される。これにより、ユーザは、ローディングプロット442上の各変数マークが、具体的にどの変数(ケミカルシフト値)に該当するのかを容易に把握できる。
【0172】
図26に示すように、寄与率チャート444では、ケミカルシフトを横軸にとり、各変数(ケミカルシフト値)の第1、2、3主成分に対するローディングの絶対値と残差(residual)成分の和が、棒グラフの形で表示される。第1、2、3主成分のスコアの分散と残差成分の分散も表示される。寄与率チャート444において、寄与率(棒グラフの高さ)が高い変数ほど、サンプルのクラス分けに寄与する度合いが高いと判断することができる。
【0173】
図26に示すように、ローディングチャート446では、ケミカルシフトを横軸にとり、PCAコントロールパネル436内の「X」軸プルダウンメニューで選択された1つの主成分に対する各変数のローディングが、棒グラフの形で表示される。また、そのX軸に選択された主成分のスコアの分散も表示される。ローディングチャート446において、ローディングの絶対値(棒グラフの高さ)が高い変数ほど、その主成分に寄与する度合いが高いと判断することができる。
【0174】
図26に示されたスコアプロット440、ローディングプロット442、寄与率プロット444及びローディングチャート446のそれぞれにおいて、選択、拡大/縮小、削除、初期化等の各種操作を行うことが可能である。
【0175】
まず、スコアプロット440の各種操作について説明する。
【0176】
図30に示すように、スコアプロット440上の任意の1以上のサンプルマークをマウスのドラッグにより選択すると、PCA解析画面制御部374(図25)が、その選択範囲470をスコアプロット440上に表示する。これと連携して、NMRスペクトル連携部378(図25)が動作して、選択されたサンプルマークに対応するサンプルのNMRスペクトルデータを、PCMテーブルに登録されているそのサンプルのパス名とファイル名とを用いて、記憶装置106内のNMRスペクトルデータ354から読み込み、そして、選択されたサンプルのNMRスペクトルをNMRスペクトルチャート450上に表示する。NMRスペクトルチャート450には、表示されたNMRスペクトルのファイル名も表示される。
【0177】
NMRスペクトルチャート450上で、複数のNMRスペクトルは、ケミカルシフト軸スケールを互いに一致させるようにして、ケミカルシフト軸に直交する縦軸方向に並んで表示され、且つ、規定の異なる色で区別して表示されるので、相互間の識別および相関が一目で分かる。加えて、図26に示されているように、NMRスペクトルチャート450上の各NMRスペクトルと、寄与率チャート444とローディングチャート446とが、ケミカルシフト軸スケールを互いに一致させて、縦軸方向に並んで表示されるので、それらの間の相関も一目で分かる。
【0178】
ユーザがキーボードの「CTRL」キーを押しながら、スコアプロット440上の任意のサンプルマークをマウスにてドラッグして選択すると、PCA解析画面制御部374は、そのサンプルマークを選択範囲に追加し、又は、そのサンプルマークが既に選択されている場合には、そのサンプルマークを選択範囲から外す。これと連携して、NMRスペクトル連携部378が、選択範囲に追加されたサンプルマークに対応するサンプルのNMRスペクトルをNMRスペクトルチャート450上に追加表示したり、又は、選択範囲から外されたサンプルのNMRスペクトルをNMRスペクトルチャート450から消去する。
【0179】
図31Aに示すように、スコアプロット440上で選択されたサンプルマークに関し、ユーザが「Del」キーを押すなどの削除要求を行うと、PCA解析画面制御部374は、図31Bに示すように、そのサンプルマークをスコアプロット440上から消去し、これと連携して、NMRスペクトル連携部378が、その選択されたサンプルのNMRスペクトルをNMRスペクトルチャート450から消去する。同時に、PCA計算部362が、その削除要求のあったサンプルのPCAテーブル上でのサンプルステータス(図24の参照番号414に相当)を「0」(解析対象に含まれる)から「1」(解析対象に含まれない)に切り替え、そして、サンプルステータスが「0」(解析対象に含まれる)であるサンプルのNMRヒストグラムデータだけを用いて、PCA解析計算を再度行い、その再計算の結果を解析データ記憶部364に出力する。PCA解析画面制御部374は、解析データ記憶部364から再計算の結果を受けて、UI画面430上に、再計算の結果に基づくスコアプロット440、ローディングプロット442、寄与率チャート444及びローディングロット446を表示する(図31Bは、再計算後に表示されたスコアプロット440の例を示す)。
【0180】
例えば、スコアプロット440上に、解析目的からみて支障になる或いは寄与しないと考えられるサンプルが表示されていた場合、そのサンプルを上記のようにして解析対象から除外した上で再度PCA計算を行うことにより、より望ましい解析結果が得られることになる。
【0181】
また、ユーザがキーボードの「Shift」キーを押しながら、スコアプロット440上の任意の部分領域をマウスにてドラッグし選択すると、PCA解析画面制御部374は、選択した部分領域を拡大してスコアプロット440上に表示する。その後、ユーザが拡大表示されたスコアプロット440の画面を選択して、キーボードの「Home」キーを押すと、PCA解析画面制御部374は、スコアプロット440上の拡大率を「1」に初期化し、全てのスコア範囲を表示する。
【0182】
また、ユーザがPCMコントロールパネル436上の「Reset_score」ボタンを操作すると、PCA計算部362が、PCAテーブル内の上記サンプル削除機能により「1」となっていたサンプルステータスを初期値「0」し、このように初期化されたPCAテーブルの内容に基づいて再度PCA解析計算を行い、そして、PCA解析画面制御部374が、そのPCA解析計算の結果に基づいたスコアプロット440、ローディングプロット442、寄与率チャート444及びローディングロット446を改めて表示する。
【0183】
次に、ローディングプロット442の各種操作について説明する。
【0184】
図32に示すように、ユーザがローディングプロット442内の任意の1以上の変数マークをマウスでドラッグして選択すると、PCA解析画面制御部374が、その選択範囲472をローディングプロット442上に表示する。これと連携して、PCA解析画面制御部374は、寄与率チャート444及びローディングチャート446内の選択された変数マークに対応する変数(ケミカルシフト値)の棒グラフを、他の変数の棒グラフとは異なる所定の選択色で表示する(図中では、選択された変数の棒グラフを黒塗りで表示している。)。これにより、ローディングプロット442、寄与率チャート444及びローディングチャート446上での各変数(ケミカルシフト値)の識別と相関が一目で分かる。
【0185】
ユーザがキーボードの「CTRL」キーを押しながら、ローディングプロット442上の任意の変数マークをマウスにてドラッグして選択すると、PCA解析画面制御部374は、その変数マークを選択範囲に追加し、又は、その変数マークが既に選択されている場合には、その変数マークを選択範囲から外す。これと連携して、PCA解析画面制御部374は、寄与率チャート444及びローディングチャート446上、選択範囲に追加された変数マークに対応する変数の棒グラフを追加的に選択色で表示したり、又は、選択範囲から外された変数の棒グラフの選択色表示を解除したりする。
【0186】
また、図33Bに示すように、上記のようにして或る選択範囲476で選択された変数マークについて、ユーザが「Del」キーを押すなどの削除要求を行うと、PCA解析画面制御部374は、その変数マークをローディングプロット440上から消去する。同時に、PCA計算部362が、その削除要求のあった変数マークに対応する変数(バケット)のPCAテーブル上でのステータス(図24の参照番号426に相当)を「0」(解析に使用する)から「1」(解析に使用しない)に切り替え、そして、解析対象のサンプルのNMRヒストグラムデータ中の、ステータスが「0」(解析に使用する)である変数(バケット)に対応する積分値だけを使用して、PCA解析計算を再度行い、その再計算の結果を解析データ記憶部364に出力する。PCA解析画面制御部374は、解析データ記憶部364から再計算の結果を受けて、UI画面430上に、再計算の結果に基づくスコアプロット440、ローディングプロット442、寄与率チャート444及びローディングロット446を表示する(図33Bは、再計算後に表示されたローディングプロット442の例を示す。)。
【0187】
例えば、ローディングプロット440上に、解析目的からみて支障になる或いは寄与しないと考えられる変数が表示されていた場合、その変数を上記のようにして解析に使用する変数から除外した上で再度PCA計算を行うことにより、より望ましい解析結果が得られることになる。
【0188】
また、ユーザが「Shift」キーを押しながら、ローディングプロット442上の任意の変数マークをマウスにてドラッグして選択すると、PCA解析画面制御部374は、ローディングプロット442上の選択範囲に相当する部分を拡大して表示する。この後、ユーザが拡大表示されたローディングプロット442を選択して、キーボードの「Home」キーを押すと、PCA解析画面制御部374は、ローディングプロット442の拡大率を「1」に初期化し、全てのケミカルシフト範囲を表示する。
【0189】
また、ユーザがPCMコントロールパネル436上の「Reset loading」ボタンを操作すると、PCA計算部362が、PCAテーブル内容の上記サンプル削除機能により「1」となっていたバケットのステータスを初期値「0」に戻し、このように初期化されたPCAテーブルの内容に基づいて再度PCA解析計算を行い、そして、PCA解析画面制御部374が、そのPCA解析計算の結果に基づいたスコアプロット440、ローディングプロット442、寄与率チャート444及びローディングロット446を改めて表示する。
【0190】
次に、寄与率チャート444とローディングチャート446の各種操作について説明する。
【0191】
ユーザが、寄与率チャート444又はローディングチャート446のケミカルシフト軸上の任意の変数(ケミカルシフト値)範囲をマウスにてドラッグして選択すると、PCA解析画面制御部374が、その選択範囲に属する変数のローディングチャート442上の変数マークと、寄与率チャート444及びローディングチャート446上の棒グラフを、選択範囲外の変数のそれと区別した所定の選択色で表示する。それにより、ローディングプロット442、寄与率チャート444及びローディングチャート446上での各変数(ケミカルシフト値)の識別と相関が一目で分かる。
【0192】
また、上記のようにして寄与率チャート444又はローディングチャート446上で選択された変数(ケミカルシフト値)範囲について、ユーザが「Del」キーを押すなどの削除要求を行うと、PCA解析画面制御部374は、その選択範囲に属する変数の変数マークをローディングプロット440上から消去する。同時に、PCA計算部362が、その選択範囲に属する変数(バケット)のPCAテーブル上でのステータス(図24の参照番号426に相当)を「0」(解析に使用する)から「1」(解析に使用しない)に切り替え、そして、解析対象のサンプルのNMRヒストグラムデータ中の、ステータスが「0」(解析に使用する)である変数(バケット)に対応する積分値だけを使用して、PCA解析計算を再度行い、その再計算の結果を解析データ記憶部364に出力する。PCA解析画面制御部374は、解析データ記憶部364から再計算の結果を受けて、UI画面430上に、再計算の結果に基づくスコアプロット440、ローディングプロット442、寄与率チャート444及びローディングロット446を表示する。
【0193】
例えば、寄与率チャート444又はローディングチャート446上に、解析目的からみて支障になる或いは寄与しないと考えられる変数(ケミカルシフト値)範囲が在る場合、その範囲の変数を上記のようにして解析に使用する変数から除外した上で再度PCA計算を行うことにより、より望ましい解析結果が得られることになる。
【0194】
また、図34Aに示すように、ユーザが「Shift」キーを押しながら、ローディングチャート446又は寄与率チャート444のケミカルシフト軸上の任意の変数(ケミカルシフト値)範囲をマウスにてドラッグして選択すると、PCA解析画面制御部374は、図34Bに示すように、ローディングチャート446及び寄与率チャート444の中の選択された変数(ケミカルシフト値)範囲に相当する部分を拡大して表示する。これに連携して、NMRスペクトル連携部378が、NMRスペクトルチャート450の中の選択された変数(ケミカルシフト値)範囲に相当する部分を拡大して表示する。従って、どのような拡大率で表示した場合でも常に、ローディングチャート446と寄与率チャート444とNMRスペクトルチャート450はケミカルシフト軸スケールが一致した状態に維持され、それらの間の相関関係が一目で分かるようになっている。
【0195】
このようにローディングチャート446及び寄与率チャート444並びにNMRスペクトルチャート450の拡大表示を行なった後、ユーザが拡大表示されたローディングチャート446又は寄与率チャート444を選択して、キーボードの「Home」キーを押すと、PCA解析画面制御部374とNMRスペクトル連携部378は、それらのチャート446、444、450の拡大率を「1」に初期化し、全てのケミカルシフト範囲を表示する。
【0196】
PCA解析を行なう場合、以上のような各種の操作がUI画面430上で行なうことができる。このような操作を逐次に行いながらPCA解析を進めていく過程の任意の段階で、ユーザがPCAコントロールパネル436内の「Add_Model」ボタンを操作すると、PCAモデル読込・追加・保存部360が、記憶装置106内の大量のサンプルのNMRヒストグラムデータ356の中から、ユーザに指定された追加のサンプルのNMRヒストグラムデータを選択して読み込み、これを現在処理中のPCAテーブル内の多変量データ行列に追加し、その多変量データ行列が追加されたPCAテーブルの情報をPCA計算部362に渡す。PCA計算部362は、その多変量データ行列が追加されたPCAテーブルの情報を用いてPCA解析計算を再実行する。PCA解析画面制御部374は、その再実行されたPCA解析計算の結果を、UI画面430に改めて表示する。
【0197】
また、上記のようにPCA解析を進めていく過程の任意の段階で、ユーザがPCAコントロールパネル436内の「Save_model」ボタンを操作すると、PCAモデル読込・追加・保存部360が、その時点で処理中の多変量データ行列を始めとするPCAテーブルの情報を、記憶装置106内にPCAテーブル350として保存する。
【0198】
以上が、PCA解析を行なう場合の各部の動作である。上述した説明から分かるように、PCA解析を行なう場合、UI画面430上では、スコアプロット440、ローディングプロット442、寄与率チャート444、ローディングチャート446及びNMRスペクトルチャート450の全ての情報が有機的に結合されて表示され、そして、いずれかの操作が行われると、その操作結果が、それに関連する全てのチャートにリアルタイムに反映される。特に、解析対象からのサンプルの削除や変数の削除などを行なった後にPCA解析をすばやく再実行し、より精度の高い解析結果を導き出すことが容易である。また、UI画面430上では、PCA解析結果に連携してNMRスペクトルも表示される。そのため、PCA解析結果とNMRスペクトルの形状とを合わせて評価することができ、解析結果の意味づけを考察することがより容易になる。PCA解析過程で必要な操作を行った後の最終的に評価結果からPCAの再解析およびスペクトルの再処理をすばやく実行しより精度の高い解析結果を導き出すことが容易になる。
【0199】
次に、SIMCA解析を行なう場合における動作について説明する。
【0200】
すなわち、まず、図26又は図27に示したUI画面430上のSIMCAコントロールパネル438内の「SIMCA」選択ラジオボタンが操作された上で「Model1」ボタンが操作されると、図25に示したSIMCA解析部348内のPCAモデル読込・追加・保存部370が動作して、記憶装置106内の大量のサンプルのNMRヒストグラムデータ356の中から、ユーザに指定された複数のサンプルのNMRヒストグラムデータを選択して読み込み、図24に示したような、多変量データ行列やその他の情報からなるPCAテーブルの情報を作成する。作成されたPCAテーブルの情報は、第1のクラスのPCAテーブル情報として扱われる。同様に、「Model2」ボタンが操作されると、PCAモデル読込・追加・保存部370が、記憶装置106内のNMRヒストグラムデータ356の中から、ユーザに指定された複数のサンプルのNMRヒストグラムデータを選択して読み込み、第2のクラスのPCAテーブルの情報を作成する。
【0201】
SIMCA解析を開始する場合には、少なくとも第1と第2クラスのPCAテーブルが定義される必要がある。更に、ユーザは、所望すればSIMCAコントロールパネル438内の「Model1」ボタンが操作されると、「Test_model」ボタンを操作することができる。「Test_model」ボタンが操作されると、PCAモデル読込・追加・保存部370が、記憶装置106内のNMRヒストグラムデータ356の中から、ユーザに指定された複数のサンプルのNMRヒストグラムデータを選択して読み込み、テストクラスのPCAテーブルの情報を作成する。
【0202】
PCAモデル読込・追加・保存部370は、作成した第1クラスと第2クラスのPCAテーブルの
情報をSIMCA計算部372に引渡す。テストクラスのPCAテーブルが更に作成された場合には、そのテストクラスのPCAテーブルの情報もSIMCA計算部372に引渡される。SIMCA計算部372は、それらのクラスのPCAテーブルの情報を用いて、PCA計算部362を呼び出してクラス毎のPCAモデルを算出させ、それらのクラスのPCAモデルを用いてSIMCA解析の計算を行なう。各種クラスのPCAモデルの主成分数は、SIMCAコントロールパネル438内の「SIMCA」選択ラジオボタンの右脇の入力ボックスにユーザが入力した数に従う。SIMCA計算部372は、SIMCA解析結果として、第1と第2の各クラスに対する各サンプルの距離、第1と第2の各クラスの残差標準偏差(RSD)、第1と第2の各クラスに対する各変数(ケミカルシシフト値)のモデリング力(modeling power)、及び各変数(ケミカルシシフト値)の識別力(discrimination power)などを算出する。算出されたSIMCA解析結果は、解析データ記憶部364に記憶される。
【0203】
SIMCA解析画面制御部374が、解析データ記憶部364から上記SIMCA解析結果を受け取る。SIMCA解析画面制御部376は、図27に示すように、第1と第2の各クラスに対する各サンプルの距離に基づいてクーマンプロット460を作成してUI画面430上に表示し、第1と第2の各クラスに対する各変数(ケミカルシシフト値)のモデリング力に基づいて、第1クラスのモデリング力チャート462と第2クラスのモデリング力チャート464を作成してUI画面430上に表示し、さらに、各変数(ケミカルシシフト値)の識別力に基づいて、識別力チャート466を作成してUI画面430上に表示する。
【0204】
図27に示すように、クーマンプロット460では、第1クラスと第2クラスからの距離をそれぞれX軸とY軸にとり、各サンプルのその2つのクラスまでの距離がプロットされる。プロットされるサンプルのマークの形状と色は、上記PCAテーブル情報の中のサンプル毎のプロットタイプとプロットカラー(図24の参照番号410、412に対応する情報)に従う。さらに、クーマンプロット460上には、第1クラスと第2クラスのそれぞれの残差標準偏差(RSD)の名称と値(例:RSD(1)0.5449)がX軸とY軸の近傍に表示され、かつ、それぞれのクラスの残差標準偏差(RSD)を示す直線(以下、「RSD」線という)480、482が表示される。
【0205】
クーマンプロット460上でのサンプルマークの配置状態が、次のような明快分類状態に近い状態であるほど、サンプルがより明確に第1クラスと第2クラスに分類されたと判断することができる。すなわち、その明快分類状態とは、サンプルマークが2つの塊に分かれ、一方の塊が第1クラスのRSD線480とY軸との間に領域に存在し、他方の塊が第2クラスのRSD線482とX軸との間の領域に存在するという状態である。
【0206】
SIMCAコントロールパネル438内の「Name」チェックボックスにユーザがチェックを入れると、SIMCA解析画面制御部374は、図28を参照して説明したスコアプロット440の場合と同様に、クーマンプロット460上の全てのサンプルマークの近傍に、対応するサンプルのNMRスペクトルのファイル名を表示する。マウスポインターが各サンプルの上に置かれた場合にも、クーマンプロット460の右上に自動的に対応するファイル名が表示される。これにより、ユーザは、クーマンプロット460の各サンプルマークが、具体的にどのサンプルに該当するのかを容易に把握できる。
【0207】
図27に示すように、第1クラスと第2クラスのモデリングチャート462、464では、ケミカルシフトを横軸にとり、各変数(ケミカルシフト値)の第1クラスと第2クラスについてのモデリング力(これは、それぞれのクラスのデータ構造を記述するための各変数の有効性を評価するための一つの指標である)が、棒グラフの形で表示される。各クラスのモデリングチャート462、464において、モデリング力(棒グラフの高さ)が高い変数ほど、各クラスのデータ構造を記述する有効性がより高いと判断することができる。
【0208】
図27に示すように、識別力チャート466では、ケミカルシフトを横軸にとり、各変数(ケミカルシフト値)の識別力(これは、第1と第2のクラスへの分類のための各変数の有効性を評価するための一つの指標である)が、棒グラフの形で表示される。識別力チャート466において、識別力(棒グラフの高さ)が高い変数ほど、第1と第2のクラスへの分類のための有効性がより高いと判断することができる。
【0209】
図27に示されたクーマンプロット460、モデリングチャート462、464、識別力チャート466のそれぞれにおいて、選択、拡大/縮小、削除、初期化等の各種操作を行うことが可能である。
【0210】
まず、クーマンプロット460の各種操作について説明する。
【0211】
図35に示すように、クーマンプロット460上の任意の1以上のサンプルマークをマウスのドラッグにより選択すると、SIMCA解析画面制御部376が、その選択範囲484をクーマンプロット460上に表示する。これと連携して、NMRスペクトル連携部378が動作して、選択されたサンプルマークに対応するサンプルのNMRスペクトルデータを、PCMテーブルに登録されているそのサンプルのパス名とファイル名とを用いて、記憶装置106内のNMRスペクトルデータ354から読み込み、そして、選択されたサンプルのNMRスペクトルをNMRスペクトルチャート450上に表示する。NMRスペクトルチャート450には、表示されたNMRスペクトルのファイル名も表示される。
【0212】
NMRスペクトルチャート450上で、複数のNMRスペクトルは、ケミカルシフト軸スケールを互いに一致させるようにして、ケミカルシフト軸に直交する縦軸方向に並んで表示され、且つ、規定の異なる色で区別して表示されるので、相互間の識別および相関が一目で分かる。加えて、図27に示されているように、NMRスペクトルチャート450上の各NMRスペクトルと識別力チャート466とが、ケミカルシフト軸スケールを互いに一致させて、縦軸方向に並んで表示されるので、それらの間の相関も一目で分かる。
【0213】
ユーザがキーボードの「CTRL」キーを押しながら、クーマンプロット460上の任意のサンプルマークをマウスにてドラッグして選択すると、SIMCA解析画面制御部376は、そのサンプルマークを選択範囲に追加し、又は、そのサンプルマークが既に選択されている場合には、そのサンプルマークを選択範囲から外す。これと連携して、NMRスペクトル連携部378が、選択範囲に追加されたサンプルマークに対応するサンプルのNMRスペクトルをNMRスペクトルチャート450上に追加表示したり、又は、選択範囲から外されたサンプルのNMRスペクトルをNMRスペクトルチャート450から消去する。
【0214】
図36Aに示すように、クーマンプロット460上で選択されたサンプルマークに関し、ユーザが「Del」キーを押すなどの削除要求を行うと、SIMCA解析画面制御部376は、図36Bに示すように、そのサンプルマークをクーマンプロット460上から消去し、これと連携して、NMRスペクトル連携部378が、その選択されたサンプルのNMRスペクトルをNMRスペクトルチャート450から消去する。同時に、SIMCA計算部372が、その削除要求のあったサンプルの該当クラスのPCAテーブル上でのサンプルステータス(図24の参照番号414に相当)を「0」(解析対象に含まれる)から「1」(解析対象に含まれない)に切り替え、そして、サンプルステータスが「0」(解析対象に含まれる)であるサンプルのNMRヒストグラムデータだけを用いて、SIMCA解析計算を再度行い、その再計算の結果を解析データ記憶部364に出力する。SIMCA解析画面制御部376は、解析データ記憶部364から再計算の結果を受けて、UI画面430上に、再計算の結果に基づくクーマンプロット460、モデリングプロット462、464及び識別力チャート466を表示する(図36Bは、再計算後に表示されたクーマンプロット460の例を示す)。
【0215】
例えば、クーマンプロット460上に、解析目的からみて支障になる或いは寄与しないと考えられるサンプルが表示されていた場合、そのサンプルを上記のようにして解析対象から除外した上で再度SIMCA計算を行うことにより、より望ましい解析結果が得られることになる。
【0216】
また、ユーザがキーボードの「Shift」キーを押しながら、クーマンプロット460上の任意の部分領域をマウスにてドラッグし選択すると、SIMCA解析画面制御部376は、選択した部分領域を拡大してクーマンプロット460上に表示する。その後、ユーザが拡大表示されたクーマンプロット460の画面を選択して、キーボードの「Home」キーを押すと、SIMCA解析画面制御部376は、クーマンプロット460上の拡大率を「1」に初期化し、元の表示範囲の全部を表示する。
【0217】
また、ユーザがSIMCAコントロールパネル438上の「Reset_score」ボタンを操作すると、SIMCA計算部372が、各クラスのPCAテーブル内の上記サンプル削除機能により「1」となっていたサンプルステータスを初期値「0」し、このように初期化されたPCAテーブルの内容に基づいて再度SIMCA解析計算を行い、そして、SIMCA解析画面制御部376が、そのSIMCA解析計算の結果に基づいたクーマンプロット460、モデリングプロット462、464及び識別力チャート466を改めて表示する。
【0218】
次に、モデリング力チャート462、464と識別力チャート466の各種操作について説明する。
【0219】
図37に示すように、識別力チャート466上で、ユーザが縦軸方向の任意の高さ位置(つまり、任意の識別力の値)をマウスでドラッグして閾値として指定すると、SMCA解析画面制御部376が、識別力チャート466上のその指定された閾値を示す閾値ライン486を表示するとともに、その指定された閾値より高い識別力を持つ変数のみを選択して、その選択された変数の棒グラフを、モデリング力チャート462、464及び識別力チャート466の全てにおいて、他の変数とは異なる所定の選択色で表示する。同時に、解析結果記憶部364が、選択された変数(すなわち、指定された閾値より識別力の高い変数)を特定する情報を記憶する。同様に、ユーザが第1クラス又は第2クラスモデリング力チャート462又は464上で、或るモデリング力の値を閾値として指定した場合にも、その閾値より高いモデリング力をもつ変数が他の変数とは異なる選択色で表示され、かつ、その選択された変数を特定する情報が解析結果記憶部364に記憶される。これにより、モデリング力チャート462、464、識別力チャート466及NMRスペクトルチャート450における選択された変数の識別や相関関係が一目で分かる。
【0220】
上記のようにして識別力又はモデリング力の高い変数が選択された後、ユーザがSIMCAコントロールパネル438内の「Set_D.P.」ボタンを操作すると、SIMCA計算部372が、解析データ記憶部364から選択された変数の特定情報を受け取り、各クラスのPCAテーブル情報中の選択されていない変数のステータスを「0」(解析に使用する)から「1」(解析に使用しない)に変更し、そして、選択された変数だけを用いて再度SIMCA計算を行なう。続いて、SIMCA解析画面制御部376が、図38に示すように、SIMCA再計算の結果を受けて、それに基づきクーマンプロット460、モデリングプロット462、464及び識別力チャート466を改めて表示する。このようにして識別力又はモデリング力の高い変数だけを用いてSIMCA解析を再度行うことで、より望ましい解析結果を得ることが可能になる。
【0221】
また、上記のようにして識別力又はモデリング力の高い変数が選択された後、ユーザがPCAコントロールパネル436内の「Set_D.P.」ボタンを操作すると、PCA計算部362が、解析データ記憶部364から選択された変数の特定情報を受け取り、SIMCA解析で使用されていた全クラスのPCAテーブル情報を統合して、全クラスのサンプルの多変量データ行列をもつPCA解析用のPCAテーブル情報を作成し、そのPCA解析用のPCAテーブル情報中の選択された変数のステータスを「0」(解析に使用する)とし、選択されてない変数のステータスを「1」(解析に使用しない)とする。そして、PCA計算部362は、その選択された変数だけを用いて、PCA解析用のPCAテーブル情報中の全クラスのサンプルの多変量データ行列についてPCA計算を再度行なう。続いて、PCA解析画面制御部374が、UI画面430を図27に示すようなSIMCA解析用のものから、図26に示すようなPCA解析用のもの切り替え、上述したPCA解析の再計算の結果に基づいたスコアプロット440、ローディングプロット442、寄与率チャート444及びローディングチャート446を改めて表示する。このようにして識別力又はモデリング力の高い変数だけを用いてPCA解析を再度行うことで、より望ましい解析結果を得ることが可能になる。
【0222】
また、図27に示すようなSIMCA解析用のUI画面430において、ユーザが「Shift」キーを押しながら、モデリング力チャート462、464又は識別力チャート466中のケミカルシフト軸上の任意の変数(ケミカルシフト値)範囲をマウスにてドラッグして選択すると、SIMCA解析画面制御部376は、モデリング力チャート462、464及び識別力チャート466中の選択された変数(ケミカルシフト値)範囲に相当する部分を拡大して表示する。これに連携して、NMRスペクトル連携部378が、NMRスペクトルチャート450の中の選択された変数(ケミカルシフト値)範囲に相当する部分を拡大して表示する。従って、どのような拡大率で表示した場合でも常に、識別力チャート466とNMRスペクトルチャート450はケミカルシフト軸スケールが一致した状態に維持され、それらの間の相関関係が一目で分かるようになっている。
【0223】
このようにモデリング力チャート462、464、識別力チャート466及びNMRスペクトルチャート450の拡大表示を行なった後、ユーザが拡大表示されたモデリング力チャート462、464又は識別力チャート466を選択して、キーボードの「Home」キーを押すと、SIMCA解析画面制御部376とNMRスペクトル連携部378は、それらのチャート462、464、466の拡大率を「1」に初期化し、全てのケミカルシフト範囲を表示する。
【0224】
以上が、SIMCA解析を行なう場合の各部の動作である。上述した説明から分かるように、SIMCA解析を行なう場合、UI画面430上では、クーマンプロット460、モデリングプロット462、464、識別力チャート466及びNMRスペクトルチャート450の全ての情報が有機的に結合されて表示され、そして、いずれかの操作が行われると、その操作結果が、それに関連する全てのチャートにリアルタイムに反映される。特に、解析対象からのサンプルの削除や変数の選択などを行なった後にSIMCA解析をすばやく再実行し、より精度の高い解析結果を導き出すことが容易である。また、UI画面430上では、SIMCA解析結果に連携してNMRスペクトルも表示される。そのため、SIMCA解析結果とNMRスペクトルの形状とを合わせて評価することができ、解析結果の意味づけを考察することがより容易になる。
【0225】
また、SIMCA解析では、各変数についてモデリング力と識別力という二つの尺度が算出される。識別力は2つのクラスについてどの変数が分類に有効であるかを表している。下がって、識別力に基づいて分類に寄与する変数を抽出することができ、他の変数は分類にあまり寄与しないノイズと考えることができる。この実施形態では、上述したように分類に有効な変数のみを用いて再度PCA解析もしくはSIMCA解析を実行することができる。それにより、サンプルをより一層明確にクラス分けすることが可能となる。
【0226】
図39は、SIMCA解析で選択された識別力の高い変数を使ってSIMCA解析計算又はPCA解析計算を再実行するための処理手順を示す。
【0227】
図39に示すように、ステップ500でSIMCA解析が実施され、ステップ502で、識別力チャート466上で識別力の閾値が指定されると、ステップ504で、その閾値以上の識別力をもつ変数が抽出される。その後、ステップ506で、SIMCAコントロールパネル438上の「Set_D.P.」ボタンが操作されると、ステップ508で、抽出された変数だけを用いてSIMCA解析計算が再度実行され、SIMCA解析結果が表示される。
【0228】
また、ステップ504の後、ステップ510で、PCAコントロールパネル436上の「Set_D.P.」ボタンが操作されると、ステップ512で、抽出された変数だけを用いて、SIMCA解析の対象となったサンプルについてPCA解析計算が再度実行され、PCA解析結果が表示される。また、ステップ504の後、ステップ514で、PCAコントロールパネル436上の「Add_D.P.」ボタンが操作されると、ステップ516で、現在の解析に使用することになっている変数に、抽出された変数を追加した上で、それらの変数を用いてSIMCA解析の対象となったサンプルについてPCA解析計算が再度実行され、PCA解析結果が表示される。
【0229】
ところで、上述した「Add_D.P.」ボタンを用いた変数の追加機能は、例えば次のような用途に利用可能である。すなわち、クラスが3つ以上存在する場合、それぞれ2つのクラスの組合せを第1と第2のクラスとしてSIMCA解析を行って、分類に有効な変数を求め、その有効な変数を、上述した「Add_D.P.」ボタン操作で逐次に加算して行くことができる。すなわち、まず、最初に選んだ2つのクラスの組合せでSIMCA解析を実施して有効な変数を選択した後、PCAコントロールパネル436上の「Set_D.P.」ボタン操作で、その選択された変数を使用対象に設定する。次に、別の2つのクラスの組合せでSIMCA解析を実施して有効な変数を選択した後、PCAコントロールパネル436上の「ADD_D.P.」ボタン操作で、その選択された変数を、最初に選択された変数に追加する。以後、その他の2つのクラスの組み合わせのそれぞれについて、SIMCA解析を実施して有効な変数を選択した後上記「ADD_D.P.」ボタン操作を繰り返す。これにより、ぞれぞれのクラスの組み合わせで有効な変数が使用対象にセットされることになり、いずれのクラスの組み合わせにおいても有効ではないとされた変数だけが、使用対象から外される。
【0230】
以上、図23〜図39を参照して、本発明の一実施形態にかかるNMRスペクトルの統計処理装置(図1に示した統計処理部116)の構成、機能、動作について説明した。以下では、このNMRスペクトルの統計処理装置を特定の用途に用いる場合の使用例を紹介する。
【0231】
図40は、メタボノミクスにおいてバイオマーカを決定する用途にこの統計処理装置を使用する場合の使用手順を示す。
【0232】
図40に示すように、ステップ520で分析が開始される。この分析では、例えば、人からの採取物に基づいてその人が特定の疾病に罹っているか否かを判断するためのバイオマーカを決定したいという場合、既にその疾病に罹っている人々からの採取物と健康な人々からの採取物とが分析対象のサンプルとして選ばれる。クラス毎に、異なるカラーがプロットカラーとして指定される。まず、ステップ522で、分析対象の多数のサンプルについてPCA解析が行われる。ステップ524で、スコアプロット440などに示された第1主成分(PC1)と第2主成分(PC2)のスコアの分散の和が、ユーザが決めた或る閾値、例えば60%、を超えているかどうかが、ユーザにより判断される。もし、上記スコアの分散の和が閾値60%を超えているならば、ステップ526で、ユーザは、ステップ522で行ったPCA解析で得られたPCAモデルにおいて、サンプルは明快にクラス分けされていると判断する。その場合、ステップ528で、ユーザは、ローディングプロット442、寄与率チャート444、ローディングチャート446及びNMRスペクトルチャート450などを参照しながら、寄与率の高いケミカルシフト値又はそれに対応するNMRスペクトルのピークを選定し、それに基づきバイオマーカを決定する。
【0233】
他方、ステップ524で、上記スコアの分散の和が閾値60%以下であるならば、ユーザは、ステップ522で行ったPCA解析で得られたPCAモデルでは、サンプルは明快にはクラス分けされていないと判断し、次に、ステップ532のSIMCA解析を実行する。SIMCA解析においては、ステップ534で、検査対象のサンプルが第1と第2の2つのクラスに分けられる。例えば、その疾病に罹っている人々から採取されたサンプルが第1のクラスに、健康な人々から採取されたサンプルが第2のクラスに割り当てられる。この2つのクラスについてSIMCA解析が実行され、そのSIMCA解析結果が表示されると、ユーザは、ステップ536で、識別力チャート466上で識別力の閾値を設定して、その閾値以上の識別力を持った変数を選択する。その後、ユーザは、PCAコントロールパネル436の「Set_D.P.」ボタンを操作する。それにより、ステップ522で、選択された変数だけを用いて、同じサンプルに対してPCA解析計算が再度実行される。その結果、前回のPCA解析計算の結果よりも、より明確にサンプルが分散したPCAモデルが得られ、バイオマーカの決定がより容易になる。
【0234】
図41は、テストサンプルの性向を診断する用途に、本発明の一実施形態にかかるNMRスペクトルの統計処理装置(図1に示した統計処理部116)を使用する場合における使用手順の一例を示す。
【0235】
図41に示すように、ステップ540で診断が開始される。この診断は、例えば、或る人々について特定の疾病に罹っているか否かを診断するものである。ステップ542で、2つの基本クラスつまり第1と第2のクラスが設定される。例えば、既に疾病に罹っている人々から採取されたサンプルが第1のクラスに、健康な人々から採取されたサンプルが第2のクラスに割り当てられる。また、ステップ544で、診断対象の人々から採取されたサンプルがテストクラスとして設定される。クラス毎に、異なるカラーがプロットカラーとして指定される。
【0236】
その後、ステップ546で、それら3つのクラスのサンプルを統合した多変量データ行列についてPCA解析が実行される。また、ステップ548で、それら3つのクラスのサンプルについてSIMCA解析が行なわれる。SIMCA解析では、テストクラスのサンプルの第1のクラスと第2のクラスにそれぞれに対する距離が求まり、それがクーマンプロット440上に表現される。スコアププロット440でも、クーマンプロットでも、3つのクラスのサンプルはクラス別の異なるプロットカラーで表示されるので、それらの相関が一目で分かる。
【0237】
ステップ550で、ユーザは、PCA解析結果とSIMCA解析結果を参照することで、テストサンプルである診断対象の人々と、第1クラスである当該疾病に罹っている人々と、第2クラスである健康な人々との間の相関を把握し、そこから、診断対象の人々が当該疾病に罹っているのか、健康であるのか、或は未定なのかなどの判断を下す。
【0238】
以上、本発明の実施形態を説明したが、この実施形態は本発明の説明のための例示にすぎず、本発明の範囲をこの実施形態にのみ限定する趣旨ではない。本発明は、その要旨を逸脱することなく、その他の様々な態様でも実施することができる。例えば、上記の実施形態では、多変量解析結果であるスコアプロット、ローディング及びクーマンプロットを、UI画面上で2本の座標軸からなる二次元図形の形で表示したが、それに代えて又はそれと併用して、3本の座標軸からなる三次元図形として形成し、その三次元図形を任意の視線方向から表示できるようにすることもできる。また、本発明は、メタボノミクスだけでなく、それ以外の用途にも適用することができる。
【図面の簡単な説明】
【0239】
【図1】本発明に従うNMRデータ処理装置の一実施形態の全体的な構成と機能を示すブロック図。
【図2】NMRスペクトル処理110の流れを示すフローチャート。
【図3】NMRスペクトル(実部)と、これに絶対値微分を施した結果であるADスペクトルの一例を示す図。
【図4】位相補正を説明する図。
【図5】ベースライン補正を説明する図。
【図6】最適化バケット積分を用いたデータ縮約処理112の流れを示すフローチャート。
【図7】スペクトル投影処理172の原理を説明する図。
【図8】スペクトル投影処理172の流れを示すフローチャート。
【図9】投影ADスペクトルのバケット積分処理172の原理を説明する図。
【図10】バケット積分処理172の流れを示すフローチャート。
【図11】自動積分ブロック設定に基づくバケットの自動修正処理174の原理を説明する図。
【図12】自動積分ブロック設定に基づくバケットの自動修正処理174の流れを示すフローチャート。
【図13】NMRスペクトル上の3分裂と4分裂のピークの例を示す図。
【図14】指定ピーク情報のデータ構造例を示す図。
【図15】指定ピーク情報に基づくバケット自動修正処理176の流れを示すフローチャート。
【図16】バケットの手動修正処理178の原理を示す図。
【図17】バケットの手動修正処理178の流れを示すフローチャート。
【図18】最適化バケットセットのデータ構造例を示す図。
【図19】多数ADスペクトルの最適化バケット積分処理180の流れを示す。
【図20】本発明に従うNMRデータ処理装置の別の実施形態の全体的な構成と機能を示すブロック図
【図21】最適化バケット積分を用いたデータ縮約処理312の流れを示すフローチャート。
【図22】ヒストグラムの分析処理314の流れを示すフローチャート。
【図23】本発明の一実施形態にかかるNMRスペクトルの統計処理装置、すなわち、図1に示した統計処理部116、の機能的な構成を示すブロック図。
【図24】PCAテーブル350の構成例を示す図。
【図25】図23に示した多変量解析部340のPCA解析部346とSIMCA解析部348並びに表示制御部344の機能をより詳細に示したブロック図。
【図26】PCA解析結果を表示した場合におけるUI346の画面例を示す図。
【図27】SIMCA解析結果を表示した場合におけるUI346の画面例を示す図。
【図28】ファイル名の表示機能を説明するためのスコアプロット440内の部分領域の拡大図。
【図29】ケミカルシフト値の表示機能を説明するためのローディングプロット442内の部分領域の拡大図。
【図30】スコアプロット440上でのプロット選択機能とNMRスペクトル連携機能とを説明するためのスコアプロット440とNMRスペクトルをャート450の例を示す図。
【図31】スコアプロット440上でのプロットの削除機能を説明するためのスコアプロット440の例を示す図。
【図32】ローディングプロット442上でのプロット選択機能とそれに連携する寄与率チャート444とローディングチャート446の表示変更機能とを説明するためのローディングプロット442と寄与率チャート444とローディングチャート446の例を示す図。
【図33】ローディングプロット442上でのプロットの削除機能を説明するためのローディングプロット442の例を示す図。
【図34】寄与率チャート444又はローディングチャート446の拡大機能とNMRスペクトル連携機能とを説明するための寄与率チャート444とローディングチャート446とNMRスペクトルをャート450の例を示す図。
【図35】クーマンプロット460上でのプロット選択機能とNMRスペクトル連携機能とを説明するためのクーマンプロット460とNMRスペクトルをャート450の例を示す図。
【図36】クーマンプロット460上でのプロットの削除機能を説明するためのクーマンプロット460の例を示す図。
【図37】モデリングチャート462、464及び識別力チャート466での変数の選択機能を説明するためのモデリングチャート462、464及び識別力チャート466の例を示す図。
【図38】変数選択後のSIMCA解析計算の再実行を説明するためのUI画面430の例を示す図。
【図39】変数選択後のSIMCA解析計算とPCA解析計算の再実行の手順を示すフローチャート。
【図40】メタボノミクスにおいてバイオマーカを決定する用途に、本発明の一実施形態にかかるNMRスペクトルの統計処理装置(図1に示した統計処理部116)を使用する場合における使用手順の一例を示すフローチャート。
【図41】テストサンプルの性向を診断する用途に、本発明の一実施形態にかかるNMRスペクトルの統計処理装置(図1に示した統計処理部116)を使用する場合における使用手順の一例を示すフローチャート。
【符号の説明】
【0240】
100、300 コンピュータシステム(NMRデータ処理装置)
102 NMR装置
104、304 プロセッサ
106、306 記憶装置
108、308 FIDデータ入力処理
110、310 NMRスペクトル処理
112、312 データ縮約処理
126 絶対値微分処理(ADスペクトル生成処理)
140 NMRスペクトル(実部)
144、Sa、Sb ADスペクトル
171 多数のADスペクトルの投影処理
172 投影ADスペクトルのバケット積分処理
174 自動積分ブロック設定に基づくバケットの自動修正処理
176 指定ピーク情報に基づくバケットの自動修正処理
178 バケットの手動修正処理
180 多数ADスペクトルの最適化バケット積分処理
Sp 投影ADスペクトル
200a−200f、200i−200k バケット
220x、220y 自動設定された積分ブロック
240x、240y 指定ピーク情報に基づくピーク領域
250A−250C 指定ピーク情報セット
280A−280C 最適化バケットセット
340 多変量解析部
342 ユーザ要求入力部
344 表示制御部
346 PCA解析部
348 SIMCA解析部
350 PCAテーブル
354 NMRスペクトルデータ
356 NMRヒストグラムデータ
360 PCAモデル読込・追加・保存部
362 PCA計算部
364 解析データ記憶部
366 解析結果保存部
370 PCAモデル読込・追加・保存部
372 SIMCA計算部
374 PCA解析画面制御部
376 SIMCA解析画面制御部
378 NMRスペクトル連携部
430 UI画面
440 スコアプロット
442 ローディングプロット
444 寄与率チャート
446 ローディングチャート
450 NMRスペクトルチャート
460 クーマンプロット
462、464 モデリング力プロット
466 識別力プロット
【技術分野】
【0001】
本発明は、NMR(核磁気共鳴)データを処理するための装置及び方法に関わり、特に、例えばメタボローム解析(メタボノミクスまたはメタボロミクス)のように多数のNMRスペクトルの多変量解析を行なう用途に好適なものである。
【背景技術】
【0002】
近年、ゲノムやプロテオーム科学の進展に伴って、代謝物全体(メタボローム又はメタボノーム)を網羅的に解析するメタボノミクス(メタボロミクスともいう)が注目を集めている。特に、NMR装置により測定される多数の生体サンプルのプロトンスペクトル(NMRスペクトル)を用い、多変量解析によってサンプル間のパターン分類を行うことで、例えば病態や未病に対する知見を得ようとする解析方法が、メタボノミクスにおいて採用される。
【0003】
すなわち、生体サンプルのプロトンスペクトルは、多種の低分子代謝物や生体高分子化合物を含むので多くのピークが重なり複雑なパターンを示す。また、微弱なピークも多くて、それをノイズと区別することが難しい。そのため、プロトンスペクトルに含まれる個々のピークを同定し構造解析することが困難である。そこで、メタボノミクスにおいては、多数の生体サンプルのプロトンスペクトルを測定し、測定された多数のプロトンスペクトルのデータを用いて多変量解析のような統計的解析を行ない、生体サンプル間の構成成分種や比率の相違をパターン(特徴量)として抽出するという解析方法が採用される。この方法により、代謝物の質的相違を捉えたり、経時変化を検出したりすることが可能になる。
【0004】
ところで、メタボノミクスを使用した薬物発見、疾患の処置及び診断のための方法が特許文献1に開示されている。ただし、特許文献1には、NMRスペクトルに関する開示はない。また、特許文献2及び3には、メタボノミクスのためのNMRスペクトルの処理に関する技術が開示されている。また、化学データの多変量解析の種々の手法が、非特許文献1に開示されている。
【0005】
【特許文献1】特表2003−530130号公報
【特許文献2】特表2004−526130号公報
【特許文献3】特表2004−538559号公報
【非特許文献1】「コンピュータ・ケミストリーシリーズ3 ケモメトリックス 化学パターン認識と多変量解析」宮下芳・佐々木慎一著、共立出版
【発明の開示】
【発明が解決しようとする課題】
【0006】
一般的なメタボノミクスのプロセスは、NMR装置から出力される多数のサンプルのFID(Free Induction Decay:自由誘導減衰)データを得ること、多数のサンプルのFID信号をそれぞれNMRスペクトルに変換すること、及び、多数のサンプルのNMRスペクトルに関して多変量解析に代表される統計処理を行なうことが含まれる。メタボノミクスのプロセスに含まれる複雑なNMRスペクトルデータの処理は、通常、コンピュータにより実行されるが、信頼できる処理結果を得るためには、FID信号から得られるNMRスペクトルの精度を向上し、かつ、多数のNMRスペクトルを統計処理プログラムで効率よく分析できるようにするためのデータ加工技術が必要である。
【0007】
NMRスペクトルの精度を向上させるための従来の処理技術として、位相補正とベースライン補正がある。位相補正とベースライン補正は、いずれも、コンピュータにより自動的に行い得るが、しかし最終的には、人が手動で、コンピュータの表示スクリーンに表示されたNMRスペクトルのグラフを見ながら、補正パラメータを最も適当と思われる値に調整するための操作をコンピュータに加えるという方法で行われる。しかし、この従来の補正方法は、長い作業時間を要して非効率的であるとともに、補正結果の適正レベルが人に依存するので常に最適なNMRスペクトルを得ることが難しい。
【0008】
また、NMRスペクトルを統計処理プログラムで効率よく分析できるようにするために、従来、NMRスペクトルを統計処理プログラムにインプットする前に、NMRスペクトルにバケット積分を適用して、これをデータ量のより小さいヒストグラムに縮約するという処理が行われている。すなわち、NMRスペクトルのケミカルシフト軸(周波数軸)に沿った観測範囲が、一定幅(典型的には0.04ppm)の刻みで多数のバケット(ケミカルシフトの小区間)に分割され、バケット毎にNMRスペクトルの強度の積分(バケット積分)が行われ、その結果として、多数のバケットの積分値のセットからなるヒストグラムが、NMRスペクトルの縮約として得られる。各サンプルのNMRスペクトルがヒストグラムに変換されるので、全体でサンプル数×バケット数に相当する数の積分値が得られ、それらの積分値が統計処理プログラムにインプットされる。
【0009】
しかしながら、従来のバケット積分の処理方法で得られるヒストグラムは、必ずしも、NMRスペクトルの特徴を十分に良く反映したものではない。すなわち、NMRスペクトル上の重要な幾つかの強度ピークが、ヒストグラム上では矮小化又は稀釈化されてしまう場合がある。この現象は、バケット積分のプロセスにおいて、一つの強度ピークが分布するケミカルシフト領域が複数のバケットに分割され、その結果、その強度ピークが複数の小さい積分値に分散されるときに生じる。
【0010】
上述した位相補正とベースライン補正に関わる問題、及びバケット積分に関わる問題に対しては、特許文献1−3はいずれも、格別有用な技術を提供していない。これらの問題は、メタボノミクスのためのNMRスペクトル処理だけに限らず、他の用途のためのNMRスペクトル処理においても同様に存在する。
【0011】
また、統計処理プログラムにより行なわれる多変量解析の処理については、上述した特許文献には格別の提案はない。
【0012】
ここで、非特許文献1に開示されているように、多変量解析と呼ばれる分析手法には多くの種類がある。代表的な分析手法の一つはPCA(Principal component Analysis:主成分分析)である。PCAでは、サンプルの成分である多数の変数の座標軸からなる多次元空間中で、サンプル間の相違(分散)が最も顕著に現れる少数本(例えば3本程度)の新しい座標軸が定義され、そして、新しい座標軸上での各サンプルの座標値が計算される。ここで、その新しい座標軸は「主成分軸」と呼ばれ、各主成分軸に沿った変数は「主成分」と呼ばれ、そして、各サンプルの各主成分軸上の座標値は「スコア」と呼ばれる。各主成分は、多数の変数の線形一次式で定義され、その線形一次式内の各変数項の係数は「ローディング」と呼ばれる。ある主成分についての各変数のローディングは、その主成分に対する各変量の寄与度合いつまり重みを表す。
【0013】
このようなPCAの結果に基づいて、主成分空間上に多数のサンプルをプロットすることにより、それらサンプルの性格を視覚的に把握することが容易になる。また、主成分空間上でのサンプルの配置や相互間の距離などを利用して、多数のサンプルのクラス分けを行なうことができる。
【0014】
また、PCAを応用したSIMCA(Soft Independent Modeling of Class Analogy:部分空間法)も、メタボノミクスにおいて有用であると考えられる。SIMCAでは、異なるクラスのサンプルに対してクラス毎にPCAを行ない、クラス毎に主成分を決定し、そして、或る主成分がそれらのクラスを分類するためにどの程度有効であるかを評価することができる。
【0015】
このようなPCA及びSIMCAの解析結果を巧く利用することにより、サンプルから得られる知見を有効に生かして、例えばマーカ変数の検出やその他の目的をより容易且つ精度良く達成できるようになることが期待される。
【0016】
しかしながら、上記の期待を満足させるために、特に、メタボノミクスのような応用分野で高い有用性を発揮するために、PCA及びSIMCAを具体的にどのように実行し、どのように関連させ、そして、その解析結果をどのようなにユーザに対して表示するかというような活用技術については、まだ満足できるものが従来提供されていない。そのため、多変量解析は、統計数学の専門家以外の人々にとってはまだ敷居が高く、メタボノミクスなどの応用分野で、期待されながらも、その真価を発揮するほどには十分に活用されていないというのが現状である。
【0017】
従って、本発明の目的は、NMRスペクトルの解析処理の精度を高めることにある。
【0018】
別の目的は、NMRスペクトルの解析処理の効率を高めることにある。
【0019】
別の目的は、NMRスペクトルをバケット積分によりヒストグラムに縮約するとき、NMRスペクトルのピークの特徴がヒストグラムに良く反映されるようにすることにある。
【0020】
さらに別の目的は、多数サンプルのNMRスペクトルの解析において、多変量解析を有効に活かすための処理技術を提供することにある。
【0021】
さらにまた別の目的は、メタボノミクスなどの応用分野において、多変量解析処理を活用して、より精度の高い結果又は結論を導くことを容易にすることにある。
【課題を解決するための手段】
【0022】
本発明の一つの側面に従えば、NMRデータの処理装置は、サンプルのNMR特性を示す対象スペクトルデータを生成するスペクトル生成手段と、前記対象スペクトルデータに対し、不均等な幅をもつ多数のバケットからなるバケットセットを用いたバケット積分を実行することにより、前記対象スペクトルデータをヒストグラムデータに縮約するデータ縮約手段と、前記ヒストグラムデータを記憶又は出力する手段とを備える。
【0023】
対象スペクトルデータのバケット積分を実行する際、適切に設定された不均等な幅をもつバケットセットを用いることにより、対象スペクトルデータがもつ重要なピークの情報を良好に維持したまま、対象スペクトルデータをバケット積分データのセットであるヒストグラムに縮約できる。そのため、そのヒストグラムを用いて行われるスペクトル解析の精度が向上する。
【0024】
好適な実施形態では、対象スペクトルデータがもつ重要なピークの情報を良好に維持するために、指定された1以上のピーク領域のいずれもが複数バケットに分割されないように、不均等幅のバケットセットが設定されている。さらに、対象スペクトルデータから検出された1以上のピーク領域のいずれもが複数バケットに分割されないように、不均等幅のバケットセットが設定されている。
【0025】
好適な実施形態では、上記のような不均等幅のバケットセットを自ら設定するバケット設定手段が、NMRデータの処理装置に備えられる。このバケット設定手段は、複数の対象スペクトルデータを入力し、それらの複数の対象スペクトルデータが投影された投影スペクトルデータを生成し、投影スペクトルデータからピーク領域を検出し、そして、検出された1以上のピーク領域のいずれもが複数バケットに分割されないようにして各バケットを設定する。さらに、このバケット設定手段は、1以上のピーク領域を指定し、指定された1以上のピーク領域のいずれもが複数バケットに分割されないようにして各バケットを設定する。さらに、このバケット設定手段は、オペレータから入力された要求に応答して、各バケットを修正することもできる。
【0026】
好適な実施形態では、上記対象スペクトルとして、サンプルのFIDデータから得られたNMRスペクトルデータに絶対値微分を施した結果である絶対値微分スペクトルデータが用いられる。ここで、NMRスペクトルデータの絶対値微分とは、NMRスペクトルの実部の周波数(ケミカルシフト)微分の二乗と、虚部の周波数(ケミカルシフト)微分の二乗との和の平方根である。このような絶対値微分スペクトルデータを用いてスペクトル解析を行うことで、面倒な位相補正やベースライン補正を行うことなしに、効率的に精度の良い解析結果を得ることが可能になる。
【0027】
本発明の別の側面に従うNMRデータの処理装置は、サンプルのFIDデータを取得する手段と、前記FIDデータからNMRスペクトルデータを生成する手段と、前記NMRスペクトルデータに絶対値微分を施して絶対値微分スペクトルデータを生成する手段と、前記絶対値微分スペクトルデータを記憶又は出力する手段とを備える。
【0028】
本発明のまた別の側面に従うNMRスペクトルの統計処理装置は、複数のサンプルのNMRヒストグラムデータからなる多変量データ行列を入力する多変量データ行列入力手段と、入力された前記多変量データ行列についてPCA解析計算を行なうPCA解析手段と、前記PCA解析計算の結果を受けて、複数種のPCA解析結果チャートをユーザインタフェース画面に表示するPCA解析結果表示手段と、前記ユーザインタフェース画面を用いてユーザ要求を入力するユーザ要求入力手段と、入力された前記ユーザ要求が1以上のサンプルを選択するものである場合、前記選択されたサンプルのNMRスペクトルのデータを入力して、入力された前記NMRスペクトルをケミカルシフト軸上に表したNMRスペクトルチャートを前記ユーザインタフェース画面に表示するNMRスペクトル連携手段とを備える。
【0029】
前記PCA解析結果チャートには少なくとも、複数の主成分に対する前記サンプルのスコアを表したスコアプロットと、変数たる所定の複数のケミカルシフト値の前記複数の主成分に対するローディングを表したローディングプロットと、前記所定の複数のケミカルシフト値の寄与率又はローディングをケミカルシフト軸上に表した寄与率/ローディングチャートとが含まれる。前記寄与率/ローディングチャートと前記NMRスペクトルチャートとは、それぞれの前記ケミカルシフト軸のスケールが一致するようにして、前記ケミカルシフト軸に直交する方向に並べられて表示されるようになっている。
【0030】
好適な実施形態では、入力された前記ユーザ要求が前記寄与率/ローディングチャートを拡大するものである場合、前記PCA解析結果表示手段と前記NMRスペクトル連携手段が、前記寄与率/ローディングチャートと前記NMRスペクトルチャートとの間の前記ケミカルシフト軸のスケールの一致が保持されるようにして、前記寄与率/ローディングチャートと前記NMRスペクトルチャートとを拡大して表示する。
【0031】
また、好適な実施形態では、入力された前記ユーザ要求が選択された1以上のサンプルを削除するものである場合、前記PCA解析手段が、前記削除されたサンプル以外のサンプルのNMRヒストグラムデータからなる多変量データ行列についてPCA解析計算を再度実行し、前記PCA解析結果表示手段が、再度実行された前記PCA解析計算の結果を受けて、前記PCA解析結果チャートを改めて表示する。
【0032】
また、好適な実施形態では、入力された前記ユーザ要求が選択された1以上の変数たるケミカルシフト値を削除するものである場合、前記PCA解析手段が、前記削除されたケミカルシフト値以外のケミカルシフト値を用いてPCA解析計算を再度実行し、前記PCA解析結果表示手段が、再度実行された前記PCA解析計算の結果を受けて、前記PCA解析結果チャートを改めて表示する。
【0033】
本発明のさらにまた別の側面に従うNMRスペクトルの統計処理装置は、数のクラスに割り当てられた複数のサンプルのNMRヒストグラムデータからなる複数クラスの多変量データ行列を入力する多変量データ行列入力手段と、入力された前記複数クラスの多変量データ行列についてSIMCA解析計算を行なうSIMCA解析手段と、前記SIMCA解析計算の結果を受けて、複数種のSIMCA解析結果チャートをユーザインタフェース画面に表示するSIMCA解析結果表示手段と、前記ユーザインタフェース画面を用いてユーザ要求を入力するユーザ要求入力手段と、入力された前記ユーザ要求が1以上のサンプルを選択するものである場合、前記選択されたサンプルのNMRスペクトルのデータを入力して、入力された前記NMRスペクトルをケミカルシフト軸上に表したNMRスペクトルチャートを前記ユーザインタフェース画面に表示するNMRスペクトル連携手段とを備える。
【0034】
前記SIMCA解析結果チャートには少なくとも、前記複数のクラスに対する前記サンプルの距離を表したクーマンプロットと、変数たる所定の複数のケミカルシフト値のモデリング力又は識別力をケミカルシフト軸上に表したモデリング力/識別力チャートとが含まれる。前記モデリング力/識別力チャートと前記NMRスペクトルチャートとは、それぞれの前記ケミカルシフト軸のスケールが一致するようにして、前記ケミカルシフト軸に直交する方向に並べられて表示されるようになっている。
【0035】
好適な実施形態では、入力された前記ユーザ要求が前記モデリング力/識別力チャートを拡大するものである場合、前記SIMCA解析結果表示手段と前記NMRスペクトル連携手段が、前記モデリング力/識別力チャートと前記NMRスペクトルチャートとの間の前記ケミカルシフト軸のスケールの一致が保持されるようにして、前記モデリング力/識別力チャートと前記NMRスペクトルチャートとを拡大して表示する。
【0036】
また、好適な実施形態では、入力された前記ユーザ要求が選択された1以上のサンプルを削除するものである場合、前記SIMCA解析手段が、前記削除されたサンプル以外のサンプルのNMRヒストグラムデータからなる複数クラスの多変量データ行列についてSIMCA解析計算を再度実行し、前記SIMCA解析結果表示手段が、再度実行された前記SIMCA解析計算の結果を受けて、前記SIMCA解析結果チャートを改めて表示する。
【0037】
また、好適な実施形態では、入力された前記ユーザ要求が、所定の閾値より前記識別力又はモデリング力が高い変数たるケミカルシフト値を選択するとともに再計算を要求するものである場合、前記SIMCA解析手段が、前記選択されたケミカルシフト値だけを用いてSIMCA解析計算を再度実行し、前記SIMCA解析結果表示手段が、再度実行された前記SIMCA解析計算の結果を受けて、前記SIMCA解析結果チャートを改めて表示する。
【0038】
本発明のまた更に別の側面に従うNMRスペクトルの統計処理装置は、複数のサンプルのNMRヒストグラムデータからなる多変量データ行列についてPCA解析計算を行なうPCA解析手段と、前記PCA解析計算の結果を受けて、複数種のPCA解析結果チャートをユーザインタフェース画面に表示するPCA解析結果表示手段と、複数のクラスに割り当てられた複数のサンプルのNMRヒストグラムデータからなる複数クラスの多変量データ行列を入力する多変量データ行列入力手段と、入力された前記複数クラスの多変量データ行列についてSIMCA解析計算を行なうSIMCA解析手段と、前記SIMCA解析計算の結果を受けて、複数種のSIMCA解析結果チャートをユーザインタフェース画面に表示するSIMCA解析結果表示手段と、前記ユーザインタフェース画面を用いてユーザ要求を入力するユーザ要求入力手段とを備える。
【0039】
前記PCA解析結果チャートには少なくとも、複数の主成分に対する前記サンプルのスコアを表したスコアプロットと、変数たる所定の複数のケミカルシフト値の前記複数の主成分に対するローディングを表したローディングプロットと、前記所定の複数のケミカルシフト値の寄与率又はローディングをケミカルシフト軸上に表した寄与率/ローディングチャートとが含まれる。前記SIMCA解析結果チャートには少なくとも、前記複数のクラスに対する前記サンプルの距離を表したクーマンプロットと、変数たる所定の複数のケミカルシフト値のモデリング力又は識別力をケミカルシフト軸上に表したモデリング力/識別力チャートとが含まれる。
【0040】
前記ユーザ要求入力手段により入力された前記ユーザ要求が、前記モデリング力/識別力チャートに表示された前記識別力又はモデリング力が所定閾値より高い変数たるケミカルシフト値を選択するとともにPCA解析計算の再実行を要求するものである場合、前記PCA解析手段が、前記選択されたケミカルシフト値だけを用いてPCA解析計算を再度実行し、前記PCA解析結果表示手段が、再度実行された前記PCA解析計算の結果を受けて、前記PCA解析結果チャートを改めて表示する。
【0041】
好適な実施形態では、前記ユーザ要求入力手段により入力された前記ユーザ要求が、前記モデリング力/識別力チャートに表示された前記識別力又はモデリング力が所定閾値より高い変数たるケミカルシフト値を選択するとともに変数を追加したPCA解析計算の再実行を要求するものである場合、前記PCA解析手段が、前記選択されたケミカルシフト値を現在の変数たるケミカルシフト値に追加してなる変数を用いてPCA解析計算を再度実行し、前記PCA解析結果表示手段が、再度実行された前記PCA解析計算の結果を受けて、前記PCA解析結果チャートを改めて表示する。
【0042】
また、好適な実施形態では、前記ユーザ要求入力手段により入力された前記ユーザ要求が、前記モデリング力/識別力チャートに表示された前記識別力又はモデリング力が所定閾値より高い変数たるケミカルシフト値を選択するとともにSIMCA解析計算の再実行を要求するものである場合、前記SIMCA解析手段が、前記選択されたケミカルシフト値だけを用いてPCA解析計算を再度実行し、前記SIMCA解析結果表示手段が、再度実行された前記SIMCA解析計算の結果を受けて、前記SIMCA解析結果チャートを改めて表示する。
【0043】
本発明は更に、上述した原理に基づくNMRデータの処理方法、NMRデータ処理のためのコンピュータプログラム、及びNMRスペクトルの統計処理のためのコンピュータプログラムも提供する。
【発明の効果】
【0044】
本発明のNMRデータの処理装置及び方法によれば、多数サンプルのNMRスペクトルの解析において、多変量解析を有効に活かすことができ、そのため、メタボノミクスなどの応用分野において、より精度の高い結果又は結論を導くことが容易になる。
【0045】
本発明のNMRデータの処理装置及び方法によれば、NMRスペクトルに絶対値微分を適用することで、NMRスペクトルの解析処理の効率が向上する。
【0046】
本発明のNMRスペクトルの統計処理装置によれば、多数サンプルのNMRスペクトルの解析において、多変量解析を有効に活かすことができる。
【0047】
本発明のNMRスペクトルの統計処理装置によれば、これをメタボノミクスなどの応用分野で利用することにより、多変量解析処理を活用して、より精度の高い結果又は結論を導くことが容易になる。
【発明を実施するための最良の形態】
【0048】
以下、図面を参照して本発明の実施形態を説明する。
【0049】
図1は、本発明に従うNMRデータ処理装置の一実施形態の全体的な構成と機能を示す。
【0050】
図1に示すように、本発明に従うNMRデータ処理装置としてのコンピュータシステム100が、NMR装置102と関連して用いられる。コンピュータシステム100は、プログラムされた1台コンピュータマシン(例えば、汎用のパーソナルコンピュータ、ワークステーション或いはメインフレームコンピュータマシンなど)であってもよいし、或は複数台のコンピュータマシンから構成されてもよい。なお、コンピュータシステムに代えて、1以上の専用ハードウェア回路、又は専用ハードウェア回路とコンピュータシステムとの組み合わせなどが、NMRデータ処理装置として用いられてもよい。
【0051】
コンピュータシステム100は、プロセッサ104と、プロセッサ104のためのコンピュータプログラム及びプロセッサ104により処理されるデータを格納するための記憶装置106とを有する。プロセッサ104は、記憶装置306に記憶されている所定のコンピュータプログラムを実行することによりNMRデータの処理を行う。NMRデータを処理する目的が異なれば、その処理の方法も当然に異なるが、ここでは、NMRデータの処理の一例として、メタボノミクスによりマーカ成分を確定することを目的として、多数のサンプルのNMRスペクトルを収集し、それらのスペクトルを統計的に解析する場合を取り上げて説明する。
【0052】
プロセッサ104が行うNMRデータの処理は、大きくFIDデータ入力処理108、NMRスペクトル処理110、データ縮約処理112、積分結果データ保存/出力処理114、及び統計処理116に分けられる。FIDデータ入力処理108では、NMR装置102から出力される各サンプルのFID(Free Induction Decay:自由誘導減衰)データが入力され、それにより、多数のサンプルのFIDデータが収集されて記憶装置106に記憶される。NMRスペクトル処理110では、各サンプルのFIDデータがフーリエ変換によりNMRスペクトルデータに変換され、更にそのNMRスペクトルデータが本発明の原理に従った「絶対値微分法(Absolute
Differential Calculation Method)」により「絶対値微分NMRスペクトル(Absolute Differential NMR Spectrum」データに変換され、それにより、多数のサンプルの「絶対値微分NMRスペクトル」データが記憶装置106に記憶される。ここで、「絶対値微分法」及び「絶対値微分NMRスペクトル」という用語は、この明細書で説明の便宜上用いられる特殊な用語であり、その詳細は後に説明する。「絶対値微分NMRスペクトル」は、以下、「ADスペクトル」と略称する。
【0053】
次のデータ縮約処理112では、本発明の原理に従った方法で「最適化バケットセット」が算出され、そして、その「最適化バケットセット」を用いて多数のサンプルのADスペクトルに「最適化バケット積分」が実行され、それにより、多数のサンプルのADスペクトルの縮約データであるヒストグラム(バケット積分データのセット)が生成される。ここで、「最適化バケットセット」及び「最適化バケット積分」という用語も、この明細書で説明の便宜上用いられる特殊な用語であり、その詳細は後に説明する。積分結果データ保存/出力処理114では、上記のデータ縮約処理112により生成された多数のサンプルのヒストグラムデータ(バケット積分データのセット)が、記憶装置106に記憶され、また必要に応じて外部へ出力される。統計処理116では、多数のサンプルのヒストグラムデータを用いて、処理目的に応じた統計処理、例えばマーカ成分を確定するための検出多変量解析、が行われる。そして、その統計処理の結果を表すデータが記憶装置106に記憶され、また必要に応じて外部へ出力される。
【0054】
ここで、FIDデータ入力処理108、積分結果データ保存/出力処理114及び統計処理116には、それぞれ、公知の各種の処理方法が採用可能であるため、これらについての詳細な説明は省略する。以下では、絶対値微分法を用いたNMRスペクトル処理110と、最適化バケット積分によるデータ縮約114について、詳細且つ具体的に説明する。
【0055】
図2は、NMRスペクトル処理110の流れを示す。
【0056】
図2に示すように、ステップ120で、NMR装置102から取得されて記憶装置106に保存されている各サンプルのFIDデータが、記憶装置106から読み込まれる。ステップ122で、そのFIDデータに対してウィンドウ処理が行われ、そのFIDデータのSN比が改善され、またリップルが除去される。ステップ124で、ウィンドウ処理122を経たFIDデータに対してフーリエ変換処理が行われて、そのFIDデータがNMRスペクトルデータに変換される。ステップ126で、そのNMRスペクトルデータに対して絶対値微分演算が行われて、そのNMRスペクトルデータがADスペクトルデータ(絶対値微分NMRスペクトルデータ)に変換される。ステップ128で、そのNMRスペクトルデータとADスペクトルデータとが記憶装置106に保存され、また、必要に応じて外部へ出力される。多数のサンプルの各々について、上記のステップ120〜128の処理が行われ、それにより、多数のサンプルのNMRスペクトルデータとADスペクトルデータが記憶装置106に蓄積される。
【0057】
ステップ126の絶対値微分演算について、以下、具体的に説明する。
【0058】
絶対値微分の対象であるNMRスペクトルは、δをケミカルシフト、jを虚数記号としたとき、次式
NMRスペクトル=R(δ)+j・I(δ) …(1)
で表現することができる。ここで、R(δ)はNMRスペクトルの実部であり、I(δ)は虚部である。そして、NMRスペクトルを絶対値微分した結果であるADスペクトルは、次式
【0059】
【数1】
で表現することができ(又は、ケミカルシフトδに代えて周波数ωで微分してもよい)。すなわち、これは、NMRスペクトルの実部R(δ)と虚部I(δ)それぞれの微分値の2乗和の平方根である。
【0060】
図3Aは、NMRスペクトルの一例の実部の波形を示し、図3BはこのNMRスペクトルの絶対値微分であるADスペクトルの波形を示す。
【0061】
図3Aに示されたNMRスペクトルの実部140から分かるように、このNMRスペクトルには位相ずれ(例えば、溶媒信号の部分142に位相ずれが顕著に表れている)が含まれ、かつ、そのベースライン成分は平坦ではなく歪んでいる。FIDデータから得られたNMRスペクトルは、殆ど例外なく、位相ずれと歪んだベースライン成分を含んでいる。従来技術によれば、NMRスペクトルに位相補正とベースライン補正が施される必要がある。
【0062】
位相補正は位相ずれを除去するための操作である。位相ずれが含まれたNMRスペクトルでは、実部R(δ)と虚部I(δ)におけるピーク波形はそれぞれ図4Aに例示するような波形になる。位相補正では、位相ずれを低減して、図4Bに例示するような波形に整形する。また、ベースライン補正は、NMRスペクトルからベースライン成分を差し引くための補正である。図5Bに例示するように歪んだベースラインBLを、図5Bに例示するようなゼロで一定のベースラインBLに修正するのである。しかし、位相補正とベースライン補正は、オペレータにより手動で調整される必要があり、時間がかかり、かつ、オペレータの主観や技量のバイアスが入ってしまう。さらに、苦労して調整しても、十分満足できる結果に到達することが難しい。
【0063】
これに対し、図3Bに例示されるように、NMRスペクトルの絶対値微分結果であるADスペクトル144においては、位相ずれが解消され、さらに、ベースラインもゼロ近傍でほぼ一定である。このことは、ADスペクトル144を用いれば、位相補正とベースライン補正が実質的に不要になることを意味する。その理由について具体的に説明する。
【0064】
NMRスペクトルの実部R(δ)と虚部I(δ)は、次式
R(δ)=A(δ)・cos(θ(δ)) …(3)
I(δ)=A(δ)・sin(θ(δ)) …(4)
で表現することができる。ここで、A(δ)は振幅であり、θ(δ)は位相である。位相θ(δ)は、大雑把にはケミカルシフトδの一次関数、
θ(δ)=K・δ+L …(5)
で表すことができ、ここで、KとLは一定の係数である。これらの式を用いて絶対値微分を計算すると、ADスペクトルは次式、
【0065】
【数2】
に変換される。
【0066】
上記(6)式から分かるように、ADスペクトルには位相θ(δ)の成分が含まれていない。また、(6)式において支配的な部分は第1項であるが、そこでは振幅A(δ)がケミカルシフトδで微分されており、この微分によりベースライン成分(これは、図5Aの例から分かるようにケミカルシフトδに対して緩やかな傾きで歪んでいる)は実質的にゼロになる。そのため、ADスペクトルでは、ベースライン成分はかなり小さく低減される。このように、絶対値微分という簡易な演算により、位相補正およびベースライン補正をすることなく高品位なスペクトルを得ることができる。
【0067】
また、NMRスペクトルには、図3Aに参照番号142で示すような溶媒(例えば軽水)信号の巨大なピークが存在する。その巨大な溶媒ピークの裾野部分は幅広く広がっており、これも、スペクトルの精度低下の主原因の一つである。しかし、ADスペクトルにおいては、ベースラインと同様に上記理由によって溶媒ピークの裾野部分も良好に低減されるので、溶媒ピークの影響を極めて小さくすることができる。
【0068】
なお、ADスペクトルの一つの欠点は、NMRスペクトルの絶対的な定量性が失われること、特に、ブロードなピークの信号強度が微分により減衰してしまうことである。しかしながら、複数のNMRスペクトル相互間の相対的な関係(例えば、どのケミカルシフトδの位置にピークが現れるかという点での相対的関係)は、ADスペクトルにおいても保たれるため、メタボノミクスのように多数のNMRスペクトルを解析する目的においては、ADスペクトルは非常に有用な情報である。
【0069】
再び図2を参照して、ステップ126で上述したADスペクトルが生成された後、ステップ128でそのADスペクトルが記憶装置106に保存される。統計処理に必要な多数のサンプルのNMRスペクトルのそれぞれについて、図2に示す処理が繰り返され、その結果、多数のサンプルのADスペクトルが記憶装置106に蓄積される。その後、図1に示すように、最適化バケット積分を用いたデータ縮約処理112が実行される。
【0070】
図6は、最適化バケット積分を用いたデータ縮約処理112の流れを示す。
【0071】
図6に示すように、ステップ170で、記憶装置106に蓄積された多数のADスペクトルのそれぞれについて、そのケミカルシフト(δ)軸スケールの基準点(δ基準点)(原点)が自動的に設定される。δ基準点の設定は公知の方法で行うことができ、それにより、いずれのADスペクトルについても、同じ特定物質のピークが現れるケミカルシフト軸上のポイントが基準点として設定される。
【0072】
その後、ステップ171で、多数のADスペクトルを共通のスペクトル上に投影する処理が行われる。このスペクトル投影処理171は、それらのADスペクトルのケミカルシフト軸のスケールを合わせた上で、ケミカルシフトδのポイント毎に全てのADスペクトルの最大値又は総和を計算するという処理である。その結果、多数のADスペクトルの最大値又は総和として1つの投影ADスペクトルが生成され、その投影ADスペクトルには、全てのADスペクトルに含まれる全てのピークが現れることになる。
【0073】
図7A,Bは、このスペクトル投影処理171の原理を説明する図であり、図8は、このスペクトル投影処理171の流れを示す。
【0074】
スペクトル投影処理171では、図8に示すように、ステップ190で、多数のADスペクトルの中から一つのADスペクトルSaが選択される。例えば図7Aに示すようなスペクトルSaが選択される。このADスペクトルSaが、投影ADスペクトルSpに初期設定される。ステップ192で、別の一つのADスペクトルSbが選択される。例えば、図7Bに示すようなADスペクトルSbが選択される。
【0075】
ステップ194で、両スペクトルSbとSpのケミカルシフト軸スケールを一致させた上で(例えば、両スペクトルの基準点rbとraの差分(rb-ra)だけ、スペクトルSbのδスケール(ケミカルシフト軸スケール)をシフトさせて、基準点rbとraを一致させた上で)、両スペクトルSbとSpの強度の最大値又は和がδポイント毎に計算される。具体的には、
最大値: if(Sp > Sb(rb-ra)) Sp=Sa else Sp =Sb(rb-ra)
和: Sp = Sp+Sb (rb-ra)
という計算がδポイント毎に行われる。それにより、図7Cに示すように、投影ADスペクトルSpには、処理された複数のスペクトルSaとSbに含まれている全てのピークが投影されることになる。なお、最大値と和のうち、いずれか一方のみが計算されてもよいし、或いは、最大値と和の両方が別個の投影ADスペクトルとして計算されてもよい。
【0076】
ステップ196により、処理対象である全てのADスペクトルについて、上述したステップ192と194が繰り返される。全てのADスペクトルについての繰り返し処理が終わると、その全てのADスペクトルに含まれる全てのピークが投影された投影ADスペクトルSpが完成する。ステップ198で、その投影ADスペクトルSpが記憶装置106に保存され、また、必要に応じて外部へ出力される。
【0077】
再び図6を参照する。上述したスペクトル投影処理171が終わると、ステップ172で、投影ADスペクトルのバケット積分が計算される。
【0078】
図9は、この投影ADスペクトルのバケット積分処理172の原理を説明する図であり、図10は、このバケット積分処理172の流れを示す。
【0079】
図9において、参照番号200は、バケット積分が実行される1単位の積分範囲を示し、「バケット」と呼ばれる。バケット200は、このバケット積分処理172においては、規定された一定の幅W(例えば0.04ppm)をもつが、後の処理において、この幅Wが修正され最適化されることになる。参照番号202は、バケット積分を実行すべきケミカルシフトδの全範囲を示し、例えば0ppm〜約16ppmの範囲である。全範囲202は、例えば約200個のバケット200に分割される。このように全範囲202内に設定された多数のバケット200の集合を、以下、「バケットセット」という。また、参照番号204は、バケット積分を実行しない範囲を示し、「ダークリジョン」と呼ばれる。
【0080】
図10に示すように、バケット積分処理172では、ステップ210で、図9に示された全範囲202が多数の一定幅Wのバケット200に均等に分割され、そして、バケット200毎に投影ADスペクトルSpの積分値(すなわち、各バケットにおける投影ADスペクトルSpとケミカルシフト軸とにより挟まれた領域の面積)が計算される。それにより、バケット200の個数に相当する個数のバケット積分データの集合が得られる。この多数のバケット積分データの集合を、以下「積分データセット」という。この積分データセットは、投影ADスペクトルSpのバケット毎のピーク面積を示す一種のヒストグラムである。
【0081】
その後、ステップ212で、ダークリジョン204に該当するバケットと、そのバケットセットのバケット積分データが、ステップ210で得られたバケットセットと積分データセットの中から削除される。ステップ214では、その積分データセットの総和が所定値になるように、その積分データセットがノーマライズされる。そして、ノーマライズされた積分データセット(ヒストグラムデータ)と、バケットセットに含まれる全てのバケットの位置(始点と終点)を表したバケットセット情報とが、記憶装置106に保存され、また、必要に応じて外部出力される。
【0082】
再び図6を参照する。上述したバケット積分処理172が終わると、ステップ174で、自動積分ブロック設定に基づくバケットの自動修正処理が行われる。ここでは、公知技術である自動積分ブロック設定処理により、投影ADスペクトルSp上の種々のピークが自動的に検出され、検出された各ピークが複数のバケットにより分割されないようにバケットの位置と幅Wが修正される。以下では、「ピーク」という用語は、単一の孤立したピークだけでなく、一つのピークと看做せるような一塊の複数のピークを指す意味でも用いる。
【0083】
図11は、この自動積分ブロック設定に基づくバケットの自動修正処理174の原理を説明する図であり、図12は、このバケット自動修正処理174の流れを示す。
【0084】
このバケット自動修正処理174では、図12に示すように、ステップ230で、公知技術である自動積分ブロック設定処理が投影ADスペクトルSpに対して施される。それにより、投影ADスペクトルSp上の種々のピークが自動的に検出され、そして、検出されたピークが存在するケミカルシフトδ領域(以下、「ピーク領域」という)にそれぞれ1対1の関係で積分ブロック(積分区間)が自動的に設定される。例えば、図11Aに示されるように、ADスペクトルSp上に2つのピーク(例えば、左側のものは3つのピークの塊であり、右側は単一のピークである)が存在する場合、その2つのピークが自動的に検出され、そして、図11Bに例示するように、左側のピーク領域には一つの積分ブロック220xが設定され、また、右側のピーク領域には別の一つの積分ブロック220yが設定される。いずれの積分ブロック220x、220yも、対応するピーク領域をカバーしており、一つのピーク領域が複数の積分ブロックにより分割されることはない。
【0085】
これに対し、図11Cに例示するように、現在のバケット200a、200b、200c、…は、図9を参照して既に説明したように、全範囲202を単純に一定幅W(例えばm0.04ppm)で均等分割したものであるから、一つのピーク領域を複数のバケットが分割しているおそれがある。図11A,Cに示す例では、左側のピーク領域が2つのバケット200bと200cにより分割されている。記憶装置106に現在保存されている積分データセット(ヒストグラム)は、このようなバケットセットを用いて計算されたものであるため、分割されたピークの情報が異なる積分データに分散され稀釈化されてしまっていおり、精度が良くない。そこで、この問題を解消するために、以下に述べる後続のステップが行われて、ピークを分割しないようにバケットセットが修正される。
【0086】
すなわち、図12に示すように、ステップ232で、それぞれの積分ブロックの始点に最も近いバケットの終点が記憶装置106内のバケットセット情報からサーチされ、見つかったバケットの終点が、それぞれ対応する積分ブロックの始点と同一値に修正される。さらに、ステップ234で、それぞれの積分ブロックの終点に最も近いバケットの始点が記憶装置106内のバケットセット情報からサーチされ、見つかったバケットの始点が、それぞれ対応する積分ブロックの終点と同一値に修正される。例えば、図11B,C,Dに示された例では、左側の積分ブロック200xの始点s(x)に最も近いバケット200aの終点e(a)がその始点s(x)と同一値に修正され、また、右側の積分ブロック200yの始点s(y)に最も近いバケット200dの終点e(d)がその始点s(y)と同一値に修正される。また、左側の積分ブロック200xの終点e(x)に最も近いバケット200dの始点s(d)がその終点e(x)と同一値に修正され、右側の積分ブロック200yの終点e(y)に最も近いバケット200fの始点s(f)がその終点e(y)と同一値に修正される。
【0087】
上記始点/終点の修正の後、ステップ236で、一つの積分ブロックを分割する複数のバケットがサーチされ、その複数のバケットが一つのバケットに統合される。例えば、図11B,C,Dに示された例では、上記始点/終点の修正の後は、左側の積分ブロック200xだけが2つのバケット200bと200cにより分割されるので、その2つのバケット200bと200cが一つのバケット200bcに統合される。
【0088】
そして、ステップ238で、上述したステップ232〜236で修正された全てのバケットについてバケット積分が再計算される。そして、記憶装置106に現在記憶されている積分データセットのうち、該当するバケットの積分データが、再計算された積分データに置き換えられる。例えば図11Dに示された例の場合、バケット200a、200bc、200d、200e及び200fの全てに修正がなされたので、それらバケット200a、200bc、200d、200e及び200fのそれぞれについてバケット積分が再計算されて、再計算された積分データが、前の積分データに置き換えられる。
【0089】
ステップ239では、以上のようにして修正された積分データセットと修正されたバケットセット情報とが記憶装置106に保存され、また、必要に応じて外部へ出力される。上記修正されたバケットセット情報によれば、自動積分ブロック設定処理によって投影ADスペクトルSpから自動的に検出された全てのピーク領域のいずれもが複数バケットにより分割されないように(つまり、一つのピーク領域は必ず一つのバケットによりカバーされる)ように、バケットセットが定義される。上記修正された積分データセットは、上記修正されたバケットセットに基づいているので、検出された全てのピークの情報は稀釈されておらず、よって、以前の積分データセットより精度が良い。
【0090】
しかしながら、公知の自動積分ブロック設定処理により自動検出されたピークに基づいて設定されたケミカルシフトδ区間(積分区間)が必ずしも適切であるとはいえない。そこで、更にバケットデータセットと成分データセットを最適化するための処理が後続して行われる。すなわち、図6に示すように、上述した自動積分ブロック設定に基づくバケット自動修正処理174の後、更にバケットデータセットと成分データセットを最適化するために、指定ピーク情報に基づくバケット自動修正処理176と、バケットの手動修正処理178とが実行される。
【0091】
まず、指定ピーク情報に基づくバケット自動修正処理176について説明する。
【0092】
この処理176では、既に同定されているNMRスペクトル(ADスペクトルではない)上の特定のピークが指定され、その指定されたピークのピーク領域をカバーするように積分ブロックが決定され、その積分ブロックに基づいて、指定ピークのピーク領域が複数バケットにより分割されないように、現在記憶されているバケットセットが修正される。指定されるピークは、典型的には、このスペクトル解析の用途においてマーカになり得るようなピークである。スペクトル解析の用途が異なればマーカも異なることになるから、用途に応じて、指定されるピークが異なってくる。
【0093】
ピークを指定するためのソースデータとしては、学会誌などで規定するNMRデータの一般的な発表フォーマット(Bull. Chem. Soc. Japan等)に従ったピーク定義データ用いることができる。そのようなフォーマットによるピーク定義データの一例を挙げると、
1H-NMR (CDCl3) δ: 8.06 (2H, t, J = 8.1 Hz, CH2), 7.24 (1H, s, CH3),…
というようなものである。このデータ例において、最初の「1H-NMR」は測定核名を示し、次の「(CDCl3)」は溶媒名を示し、次の「δ: 8.06」は1つ目のピークの中心のケミカルシフトを示し、次の「2H」は1つ目のピークのプロトン数を示し、次の「t」は1つ目のピークの分裂パターンを示し、次の「J = 8.1 Hz」は1つ目のピークのスピン結合定数を示し、次の「CH2」は1つ目のピークに関するコメントである。1つ目のピークの定義の後に、2つ目のピークの定義、3つ目のピークの定義、…が順次続く。ここで、ピークの分裂パターンには種々のものがあるが、代表的な分裂パターンは例えば以下の5種のパターン、
「s」:単一(singlet)
「d」:2分裂(doublet)
「t」:3分裂(triplet)
「q」:4分裂(qualtet)
「m」:多分裂(multiplet)
の組合せとなる。
【0094】
図13Aは3分裂ピークの例を示しており、図13Bは4分裂ピークの例を示している。
【0095】
図13Aに示すように、3分裂ピークの場合、上述したようなフォーマットのピーク定義データにより、その中心のケミカルシフトδ(単位:ppm)と1つのスピン結合定数J(単位:Hz)が定義される。図示は省略するが、2分裂ピークの場合も、同様に、中心のケミカルシフトδと1つのスピン結合定数Jが定義される。単一ピークの場合は、中心のケミカルシフトδが定義されるが、スピン結合定数Jは当然に定義されない。また、図13Bに例示するように、4分裂ピークの場合、中心のケミカルシフトδと、広狭2つのスピン結合定数Ja、Jb(単位:Hz)が定義される。図示は省略するが、多分裂(5以上の分裂)ピークの場合、中心のケミカルシフトδと、分列数に応じた数の異なるスピン結合定数が定義される。なお、中心のケミカルシフトδが決め難い複数分裂ピークの場合、「δa−δb」というようにケミカルシフトδの範囲でピークが定義される場合もあり得る。
【0096】
図13A、Bに例示するように、各ピークのピーク領域(そのピークが位置するケミカルシフトδ区間)は、上述したピーク定義データに含まれる数値、特に中心のケミカルシフトδとスピン結合定数Jとに基づいて決定することができる。例えば図13Aに示す3分裂ピークの場合には、そのピーク領域240xの始点s(x)と終点e(x)は、
s(x)=δ−(J+PW/2)
e(x)=δ+(J+PW/2)
により、また、図13Bに示す4分裂ピークの場合には、そのピーク領域240yの始点s(y)と終点e(y)は、
s(y)=δ−(Jb+PW/2)
e(y)=δ+(Jb+PW/2)
により計算することができる。ここで、「PW」はピーク幅(単位:Hz)を指し、これはNMR装置の分解能やサンプルの状態などの幾つかの条件によって異なってくるので、その条件セットに応じた適当な値を予め設定しておけばよい。図示以外の分裂パターンの場合についても、中心ケミカルシフトδとスピン結合定数J(ここで、単一ピークの場合はJ=0とすればよい)を用いてピークが定義されていれば、上記と同様のやり方でピーク領域が決定できる。また、「δa−δb」というようにケミカルシフトδの範囲でピークが定義されている場合には、そのピーク領域の始点sと終点eは、
s=δa−PW/2
e=δb+PW/2
により計算することができる。
【0097】
さて、本実施形態にかかるNMRデータ処理装置100は、指定ピークについて上述したようなフォーマットのピーク定義データを入力し、そのピーク定義データに基づいて、指定ピークのピーク領域を決定するために必要な情報(以下、「指定ピーク情報」という)を自動的に生成する。生成された指定ピーク情報は、後に何時でも利用できるように、記憶装置106に登録されることができる。
【0098】
図14A,Bは、記憶装置106に登録される指定ピーク情報のデータ構造例を示す。
【0099】
図14Aに示すように、NMRスペクトル解析の異なる用途にそれぞれ対応した異なる指定ピーク情報セット250A、250B、250Cが、記憶装置106に登録されている。例えば、特定の疾病に罹患した者の血液に共通するマーカを確定しようとする用途と、特定種類の食品に共通するマーカを確定しようとする用途とでは、マーカとなり得るピークは異なるから、用途毎に異なるピークが指定されることになる。そのため、用途毎に別の指定ピーク情報セット250A、250B、250Cが登録される。指定ピーク情報セット250A、250B、250Cの各々には、指定された1以上のピークの各々のピーク指定情報が記録されている。各ピークのピーク指定情報には、そのピークを識別するためのピークIDと、そのピークのピーク領域を計算するためのケミカルシフト、分裂パターン及びスピン結合定数などの数値データが含まれている。これらの数値データは、NMRデータ処理装置100に入力された上述したようなフォーマットのピーク定義データの中から、NMRデータ処理装置100により自動抽出されたものである。
【0100】
また、図14Bに例示するように、予め設定されたピーク幅PWを示すピーク幅セット252も、記憶装置106に登録されている。前述したように分解能やその他の条件が異なるとピーク幅PWが異なってくるため、ピーク幅セット252には、異なる条件セットに対応して異なるピーク幅PWが設定されている。
【0101】
ところで、変形例として、図14Aに例示された指定ピーク情報セット250A、250B、250Cには、ケミカルシフト、分裂パターン及びスピン結合定数などの数値データと共に、又はそれに代えて、それらの数値データに基づき上記計算方法により計算されたピーク領域を示すデータ(例えば、始点と終点の数値データ)が登録されてもよい。
【0102】
さて、以上のような指定ピーク情報を用いて、図6に示されたステップ176の、指定ピーク情報に基づくバケットの自動修正処理が、次の手順で行われる。
【0103】
図15は、このバケット自動修正処理176の流れを示す。
【0104】
図15に示すように、ステップ260で、任意に指定された1以上のピークのそれぞれについてピーク定義情報が入力され、そのピーク定義情報に基づいて各指定ピークのピーク定義情報が生成される。或いは、予め記憶装置106に登録されている図14Aに例示されたような指定ピーク情報セット250A、250B、250Cの中から、今回の用途に対応した指定ピーク情報セットが選択され、その選択された指定ピーク情報セットからピーク毎の指定ピーク情報が読み込まれる。さらに、予め設定されている図14Bに例示されたような条件毎のピーク幅データの中から、今回の解析に最適なピーク幅データが読込まれる。
【0105】
そして、ステップ262で、各指定ピークの指定ピーク情報とピーク幅データに基づいて、上述したような計算方法により、各指定ピークのピーク領域が決定され、そのピーク領域がそのまま積分ブロックとして設定される。例えば、図13A,Bに例示された2種類のピークの場合、それらのピークのピーク領域240x及び240yがそれぞれ積分ブロックとして設定される。
【0106】
その後、ステップ264で、図12に示した自動積分ブロック設定に基づくバケット修正処理174のステップ232〜238と同様の手順で、記憶装置106に記憶されている1度修正されたバケットセットが、指定ピークに対応する積分ブロックに応じて更に修正される。この2回目のバケット修正により、いずれの指定ピークのピーク領域も複数のバケットにより分割されないようになる(つまり、いずれの指定ピークのピーク領域の必ずいずれか一つのバケット内に入るようになる)。また、ここで修正がなされたバケットについては、投影ADスペクトルSpのバケット積分が再計算され、再計算されたバケットの積分データにより、記憶装置106に記憶されている対応するバケットの積分データが置き換えられる。
【0107】
そして、ステップ239で、このように2度修正されたバケットセットと積分データセットが、記憶装置106に保存され、また、必要に応じて外部に出力される。
【0108】
次に、図6に示されたステップ178の、バケットの手動修正処理について説明する。この処理178は、上述した2回の自動的なバケット修正だけでは満足できない場合、オペレータが手動でバケットを更に修正できるようにするためのものである。
【0109】
図16A,Bはバケットの手動修正処理178の原理を示し、図17はバケットの手動修正処理178の流れを示す。
【0110】
この処理178において、記憶装置106に保存されている投影ADスペクトルSpと前述した2度の自動修正を終えたバケットセットが、NMRスペクトル処理装置100のディスプレイスクリーンに表示される。オペレータはその表示を見ながら、任意のバケットの始点又は終点に対する修正要求をNMRスペクトル処理装置100に入力する。例えば、図16Aに例示するように、或るバケット200jを修正したい場合、オペレータは、そのバケット200jを指定した上で、その始点を終点の修正要求として、新たな始点s(j)と新たな終点e(j)を入力する。すると、図17に示すように、ステップ270で、指定されたバケット200jの始点と終点が、オペレータから入力された始点s(j)と終点e(j)と同一値に修正される。また、ステップ272で、指定されたバケットの始点s(j)側の隣バケットの終点e(i)が指定バケットの始点s(j)と同一値に修正され、ステップ274で、指定バケットの終点e(j)側の隣バケットの始点s(k)が指定バケットの終点e(j)と同一値に修正される。その後、ステップ276で、修正されたバケット毎にバケット積分が再計算され、再計算された積分データにより、記憶装置106に記憶されている対応するバケットの積分データが置き換えられる。そして、ステップ278で、手動修正の終わったバケットセットと、そのバケットセットに基づいて上記のように修正された積分データセットとが、記憶装置106に保存され、また必要に応じて外部へ出力される。
【0111】
以上のように、図6のステップ172で、全バケットが一定幅(例えば0.04ppm)をもつ均等幅のバケットセットが初期的に設定され、その後、ステップ174と176と178の3段階のバケット修正が行われて、バケットにより幅の異なる不均等幅のバケットセットが完成する。なお、ステップ174と176と178の3つの修正段階は、必ずしもその全てが実行されなければならないわけではなく、いずれかの修正段階(例えば手動修正)が省略されても良い。いずれにしても、最終的に完成された不均等幅のバケットセットは「最適化バケットセット」と呼ばれる。
【0112】
図18は、記憶装置106に保存された最適化バケットセットのデータ構造例を示す。
【0113】
図18に示すように、スペクトル解析の異なる用途にそれぞれ対応して異なる最適化バケットセット280A、280B、280Cが、記憶装置106に記憶されている。用途が異なれば、既に説明したように指定ピークが異なり、また、処理対象のNMRスペクトル自体も異なるので、当然、出来上がる最適化バケットセットが異なるからである。最適化バケットセット280A、280B、280Cの各々には、用途を示す用途ID、ピーク幅PWを示す数値データ、ケミカルシフト軸スケールの基準点(原点)を示す数値データ、並びに、このバケットセットを構成する多数のバケットのバケット番号、始点及び終点のデータなどが登録されている。さらに、いずれかの指定ピークに対応するバケットには、その対応する指定ピークを指すピークIDも登録されている。
【0114】
上述した3段階のバケット修正処理の説明から分かるように、最適化バケットセットにおいては、全てのバケットが均等な幅(例えば0.04ppm)をもってはおらず、それぞれに特有の不均等な幅をもっている。そして、投影ADスペクトルSpから自動的に検出された全てのピークについても、加えて、指定ピーク情報により指定された全てのピークについても、各ピークのピーク領域は必ずいずれか一つのバケットの中に入っており、いずれのピーク領域も複数バケットにより分割されてはいない。さらに、この最適化バケットセットの作成の基礎となった投影ADスペクトルSpには、解析対象である多数のADスペクトル上のほぼ全てのピークが投影されており、それらのピークのピーク領域が最適化バケットセット反映されている。さらに、解析用途のために重要であると考えられる既知の指定ピークのピーク領域も、最適化バケットセットに反映されている。従って、この最適化バケットセットを用いて、解析対象である多数のADスペクトルのそれぞれのバケット積分を行なうことにより、いずれのADスペクトルも、そこに含まれるほぼ全てのピークの情報が良好に維持された状態で、積分データセット(ヒストグラム)に変換されることになる。
【0115】
再び図6を参照する。最適化バケットセットが完成すると、ステップ180の、多数ADスペクトルの最適化バケット積分処理が行われる。
【0116】
図19は、多数ADスペクトルの最適化バケット積分処理180の流れを示す。
【0117】
図19に示すように、ステップ290で、最適化バケットセットが記憶装置106から読込まれる。ステップ292で、解析対象である多数のADスペクトルの各々が記憶装置106から読込まれる。ステップ292で、読込まれたADスペクトルのケミカルシフト軸スケール(δスケール)が、最適化バケットセットのケミカルシフト軸スケール(δスケール)に合わされる(例えば、ADスペクトルの基準点が最適化バケットセットの基準点に一致するように、ADスペクトルのケミカルシフト軸スケールがシフトされる。)。そして、ステップ296で、そのADスペクトルのバケット積分が、最適化バケットセットを用いて実行され、ステップ298で、そのバケット積分で求まった積分データセット(ヒストグラムデータ)が記憶装置106に保存され、必要に応じて外部へ出力される。
【0118】
ステップ299により、解析対象の全てのADスペクトルについて、上述したステップ292〜298の処理が繰り返される。その結果、解析対象の全てのADスペクトルが、それぞれ積分データセット(ヒストグラムデータ)に縮約されて、記憶装置106に保存される。
【0119】
再び図6を参照する。その後、ステップ182で、解析対象の全てのADスペクトルの最適化バケット積分データセット(ヒストグラムデータ)が、次の統計処理に渡すのに適したデータ形式に整えられた上で、記憶装置106に保存され、必要に応じて外部へ出力される。
【0120】
以上図6に示された流れに沿って説明した処理が実行されることにより、図1に示された最適化バケット積分を用いたデータの縮約処理112と、積分結果データの保存/出力処理114が完了する。その後に、図1に示される統計処理116が実行される。この統計処理116では、解析対象の全てのADスペクトルの積分データセット(ヒストグラムデータ)が記憶装置106から読込まれ、それらの積分データセット(ヒストグラムデータ)を用いて、所定の統計処理(例えば多変量解析法の一つである主成分分析)が実行され、そして、マーカとなるピークの確定などの解析結果が生成され出力される。統計処理の具体的な手法としては、公知の種々の方法を用いることができる。例えば、後に詳述するように、本発明の原理に従う統計処理では、いずれも多変量解析法の一つである主成分分析(Principal component Analysis:PCA)と部分空間法(Soft Independent Modeling of Class Analogy:SIMCA)とが組み合わせて用いられる。既に説明するようなしたように、統計処理の材料であるADスペクトルの積分データセット(ヒストグラムデータ)には、ADスペクトル上の重要なピークの情報が良好に含まれているので、統計処理の結果は精度の高いものとなる。
【0121】
図20は、本発明に従うNMRデータ処理装置の別の実施形態の全体的な構成と機能を示す。
【0122】
このNMRデータ処理装置300は、前述のNMRデータ処理装置100とは別の用途に使用される。すなわち、前述のNMRデータ処理装置100の用途は、多数のサンプルのNMRスペクトルを解析し統計的なデータを得ることであるのに対し、このNMRデータ処理装置300の用途は、基本的に一つのサンプルのNMRスペクトルを分析してそのサンプルの性質又は成分などを検査すること(例えば、或る人の血液のNMRスペクトルを分析して、その人が特定の疾病に罹患してないかどうか検査すること、あるいは、或る食品のNMRスペクトルを分析して、そこに如何なる物質が含有されているか検査すること、など)にある。このNMRデータ処理装置300も、前述のNMRデータ処理装置100と同様に、プログラムされたコンピュータシステムを用いて実現することができる。
【0123】
図20に示すように、NMRデータ処理装置300のプロセッサ304は、記憶装置306に記憶されている所定のコンピュータプログラムを実行することにより、FIDデータ入力処理308、NMRスペクトル処理310、最適化バケット積分を用いたデータ縮約処理312、ヒストグラム分析処理314、分析結果データ保存/出力処理316を行う。記憶装置306には、上記コンピュータプログラムの他に、予め、図18に例示したような用途別の最適化バケットセット280A、280B、280Cが記憶されている。さらに記憶装置306には、検査目的に対応した参照モデルデータが記憶されている。検査目的に対応した参照モデルデータとは、検査の判断を行う際に検査対象のNMRデータと対比される基準のデータである。例えば、人の血液からその人が特定の疾病に罹患してないかどうか検査するという用途の場合であれば、その特定の疾病に罹患している多数の人々の血液サンプルのNMRデータを前述のNMRデータ処理装置200で解析することによって確定されたマーカの情報が、参照モデルデータの一つとして採用することができる。
【0124】
FIDデータ入力処理312では、NMR装置102から出力される検査対象の一サンプルのFIDデータが入力され、記憶装置306に記憶される。NMRスペクトル処理310では、入力されたFIDデータに対して、図2に示されたと同様の流れの処理が行われて、そのFIDデータの絶対値微分であるADスペクトルが生成され、記憶装置306に記憶される。
【0125】
データ縮約処理312では、記憶装置306に予め記憶されている用途に応じた最適化バケットセットを用いた最適化バケット積分が、検査対象のADスペクトルに対して実行され、それにより、検査対象のADスペクトルが最適化された積分データセット(ヒストグラム)に縮約される。ヒストグラム分析処理314では、検査対象の積分データセット(ヒストグラム)が、記憶装置306に予め記憶されている用途に応じた参照モデルデータと対比され、対比結果に基づく判断がなされて検査結果が生成される。分析結果の保存/出力処理316では、生成された検査結果が記憶装置306に保存され、また外部へ出力される。
【0126】
図21は、図20に示された最適化バケット積分を用いたデータ縮約処理312の流れを示す。
【0127】
ステップ320で、検査対象のADスペクトルが記憶装置306から読込まれ、ステップ322で、用途に対応した最適化バケットセットが記憶装置306から読込まれる。ステップ324で、検査対象のADスペクトルのケミカルシフト軸スケール(δスケール)が最適化バケットセットのそれに一致させられる。その後、ステップ326で、最適化バケットセットを用いた最適化バケット積分が、検査対象のADスペクトルに対して実行され、検査対象の積分データセット(ヒストグラム)が求まる。ステップ328で、検査対象の積分データセット(ヒストグラム)が記憶装置306に保存され、必要に応じて外部へ出力される。
【0128】
図22は、図20に示されたヒストグラムの分析処理314の流れを示す。
【0129】
ステップ330で、検査対象の積分データセット(ヒストグラム)が記憶装置306から読込まれる。ステップ332で、検査目的に対応した参照モデルデータが記憶装置306から読込まれる。ステップ334で、検査対象の積分データセット(ヒストグラム)と、検査目的に対応した参照モデルデータとが対比され、検査結果が判断される。ステップ336で、検査結果が記憶装置306に保存され、また外部へ出力される。
【0130】
以上のようなサンプルの検査を用途とするNMRデータ処理においても、用途に応じて予め用意された最適化バケットセットを用いた最適化バケット積分がスペクトルに対して行われるので、スペクトルがもつピーク情報が良好に維持され、精度の高い検査結果を得ることができる。また、分析には、NMRスペクトルの絶対値微分であるADスペクトルが用いられるため、面倒な位相補正やベースライン補正が不要になり、処理効率が向上する。
【0131】
次に、本発明の一実施形態にかかるNMRスペクトルの統計処理装置について説明する。
【0132】
本発明の一実施形態にかかる統計処理装置は、図1に示したNMRデータ処理装置100内に統計処理部116として組み込まれており、そして、典型的には、既に説明した前処理部分(図1内の処理部108,110,112,114)と一緒にコンピュータプログラムとして具現化されている。しかし、これは説明のための一つの例示にすぎず、本発明に従うNMRスペクトルの統計処理装置は、既に説明した前処理部分からは分離された単独装置として構成されることもできる。
【0133】
図22は、本発明の一実施形態にかかるNMRスペクトルの統計処理装置、すなわち、図1に示した統計処理部116、の機能的な構成を示す。
【0134】
図22に示すように、統計処理部116は、多変量解析部340と、ユーザ要求入力部342と、表示制御部344とを有する。
【0135】
多変量解析部340は、PCA解析部346とSIMCA解析部348とを有する。PCA解析部346は、記憶装置106に保存されている多数のサンプルのNMRスペクトルの積分データセット(以下、「NMRヒストグラム」という)を入力して、主成分分析(Principal component Analysis: PCA)による多変量解析を行なう。また、SIMCA解析部348は、記憶装置106に保存されている多数のサンプルのNMRヒストグラムを入力して、部分空間法(Soft Independent Modeling of Class Analogy:SIMCA)(以下、SIMCAという)による多変量解析を行なう。PCA解析部346とSIMCA解析部348の入力となる解析対象としての多数のサンプルのヒストグラムのデータは、記憶装置106内のPCAテーブル350に記録されている。PCAテーブル350の構成については、後に説明する。
【0136】
記憶装置106内には、図1に示した積分結果データの保存/出力処理114により書き込まれた大量のサンプルのNMRヒストグラムデータ356がある。PCA解析部346とSIMCA解析部348は、それぞれ、その大量のサンプルのNMRヒストグラムデータ356の中から、任意の多数のサンプルのNMRヒストグラムのデータを解析対象として抽出してPCAテーブル350に登録することができる。多変量解析部340は、ユーザからの要求に応じてPCAテーブル350の更新も行なう。また、PCA解析部346とSIMCA解析部348は、それぞれ、PCA解析結果(例えば、サンプルのスコア及び変数のローディングなど)とSIMCA解析結果(サンプルの各クラスまでの距離、変数のモデリング力及び識別力など)を、解析結果データ352として、記憶装置106内に保存することができる。
【0137】
SIMCA解析部348とPCA解析部346は、後に詳述するように、前者による解析結果が後者の解析にフィードバックされるように連携して動作することができる。それにより、このような多変量解析を行なう目的、例えばメタボノミクスにおいてバイオマーカを探し当てる目的が、より容易に達成されるようになる。
【0138】
表示制御部344は、PCA解析部346からPCA解析結果(スコア及びローディングなど)を受け、また、SIMCA解析部348からとSIMCA解析結果(各クラスまでの距離、モデリング力及び識別力など)を受けて、そして、そのPCA解析結果とSIMCA解析結果を表示したグラフィカルユーザインタフェース(以下、「UI」という)346を作成し、そのUI346をコンピュータシステム100(図1)のディスプレイ装置(図示省略)に表示する。表示制御部344は、記憶装置106に記憶されている多数のサンプルのNMRスペクトルデータ350の中から、ユーザにより選択された1以上のサンプルのNMRスペクトルデータを読み込み、そのUI346上に、PCA解析結果とSIMCA解析結果と一緒に、ユーザにより選択されたサンプルのNMRスペクトルを表示する。なお、この実施形態では、表示されるNMRスペクトルデータは、元のNMRスペクトルデータではなく、それを絶対値微分して得られたADスペクトルデータであるが、これを以下では単に「NMRスペクトルデータ」と呼ぶ。
【0139】
表示制御部344は、UI346上のPCA解析結果とSIMCA解析結果の表示とNMRスペクトルの表示とが連携するように、UI346上での両者の表示を制御する。それにより、オペレータは多変量解析結果とNMRスペクトルとの関連性が視覚的に容易に理解できるようになり、このような多変量解析を行なう目的、例えばメタボノミクスにおいてバイオマーカを探し当てる目的が、より容易に達成されるようになる。さらに、そのUI346上には、ユーザが各種の要求を入力するための各種の入力ボタンも表示される。そのUI346の詳細については、後に説明する。
【0140】
ユーザ要求入力部342は、ユーザによりマウスまたはキーボードなどから上記UIに入力された各種の要求を受け、その入力要求を上述した多変量解析部340および表示制御部344に渡す。多変量解析部340および表示制御部344は、ユーザから入力された要求に応答して、後述するような各種の動作を行う。
【0141】
図24は、図23に示したPCAテーブル350の構成例を示す。
【0142】
既に述べたように、PCAテーブル350には、解析の対象となる多数のサンプルのNMRヒストグラムのデータが記録されている。すなわち、図24に示すように、PCAテーブル350には、ヒストグラムを作成するときに行なわれたバケット積分に関するバケット積分条件400が記録されており、これには、バケット積分が行なわれたケミカルシフトδの全範囲(図9に示した全範囲202に相当)、バケットの基本的な幅(図9に示した幅Wに相当)、自動積分ブロック設定でバケット幅の調整を行ったか否か、全範囲の合計積分値、及びダークリジョン((図9に示したダークリジョン204に相当)(図示の例では、5.3ppmから4.3ppmという1つのダークリジョンだけが登録されているが、複数のダークリジョンが登録され得る)が含まれる。
【0143】
また、PCAテーブル350には、解析対象のサンプルの数402、各サンプルを構成する多数の変数の数(つまり、バケットの数)404、及び、各サンプルのNMRスペクトルデータが格納されているフォルダ名406とファイル名408のセット(つまり、各サンプルのNMRスペクトルデータファイルのパス名)が記録されている。ここで、前述した図23では、図示の都合から、多数のサンプルのNMRスペクトルデータは纏めて1つのブロック354で示されているが、このブロック354は実際には、サンプル毎のNMRスペクトルデータを格納した多数のスペクトルデータファイルの集まりであり、それら多数のスペクトルデータファイルのパス名(フォルダ名406とファイル名408)がPCAテーブル350に記録されている。図24では、図示の都合から、3つのサンプルのスペクトルデータファイルのパス名しか示されていないが、実際には、サンプル数402に示された数のサンプルの全てのスペクトルデータファイルのパス名がPCAテーブル350に記録されている。
【0144】
さらに、PCAテーブル350には、UI346の画面上にプロットされるサンプル毎のマークの形状とカラーをそれぞれ指定したプロットタイプ410とプロットカラー412が定義されている。プロットタイプ410は、例えば、値「0」が×形マーク、値「1」が塗りつぶしの無い円形マーク、値「−1」が黒く塗りつぶされた円形マーク、…などを指定する。また、プロットカラー412は、3原色である赤(R)、緑(G)及び青(B)の明度(濃度)値のセットで定義される。後述するように、UI346上にはPCA解析結果の一つであるスコアプロットや、SIMCA解析結果の一つであるクーマンプロットが表示されるが、そのスコアプロットやクーマンプロット上では、各サンプルは、PCAテーブル350で指定された形状とカラーを持ったマークで表示されることになる。
【0145】
さらに、PCAテーブル350には、サンプル毎のサンプルステータス414が登録されている。各サンプルのサンプルステータス414は、該当のサンプルが解析対象に含まれるか否かを示すものであり、例えば、値「0」が該当のサンプルが解析対象に含まれることを意味し、値「1」が該当のサンプルがユーザからの要求により解析対象から除外されたことを意味する。後に説明するように、PCAテーブル350に登録されているサンプルの全ては初期的には解析対象に含まれるのである(つまり、サンプルステータスが「0」である)が、ユーザは、UI346のスコアプロット上でクーマンプロット上で任意のサンプルを選択して、選択したサンプルを解析対象から除外することができ、そのようにして除外されたサンプルのサンプルステータスは「1」に変わる。サンプルステータスが「1」であるサンプルは、PCA解析やSIMCA解析において計算に入れられない。
【0146】
さらに、PCAテーブル350には、実質的な解析対象である多変量データ行列418が登録されている。この多変量データ行列418には、上記積分全範囲に含まれる全バケットのそれぞれの中点のケミカルシフト値(これは、多変量解析における変数つまり記述子に相当する)418と、サンプル毎のNMRヒストグラムのデータ(すなわち、サンプル毎の最適化バケット積分で得られた積分データのセットであり、解析対象である多変量データ行列の正味の部分である)420、それぞれのバケットの始点のケミカルシフト値422と終点のケミカルシフト値424、及び、それぞれのバケットのステータス426が登録されている。各バケットのステータス426は、そのバケット(つまり、その変数)を解析に使用するか否かを示すものであり、例えば、値「0」はそのバケットを解析に使用することを意味し、値「1」は解析に使用しないことを意味する。後述するように、UI346上に表示されるSIMCA解析結果の一つである識別力に基づいて、ユーザは任意のレベル以上に高い識別力をもつ変数(バケット)だけを選択し、選択されたバケットだけを用いて再度PCA解析やSIMCA解析を行なうことを要求することができる。全てのバケットは、初期的にはステータスが「0」であって、解析に使用されるようになっているが、上記のようにして特定のバケットだけが後の解析のために選択された場合、選択されなかったバケットのステータスは「1」に変わり、ステータスが「1」であるバケットは後の解析では使用されないことになる。
【0147】
以上のような構成を持つPCAテーブル350を使用して、PCA解析とSIMCA解析が実行されることになる。
【0148】
図25は、図23に示した多変量解析部340のPCA解析部346とSIMCA解析部348並びに表示制御部344の機能をより詳細に示している。
【0149】
図25に示すように、PCA解析部346は、PCAモデル読込・追加・保存部360と、PCA計算部362とを有する。PCAモデル読込・追加・保存部360は、記憶装置106上の大量サンプルのNMRヒストグラムデータ356の中から、解析対象となる多数のサンプルのNMRヒストグラムデータを選んで、その選ばれた多数のサンプルのNMRヒストグラムデータに基づいてPCAテーブルの情報を新規に作成する機能や、記憶装置106上の大量サンプルのNMRヒストグラムデータ356の中から追加のサンプルのNMRヒストグラムデータを選んで、それをPCAテーブルの多変量データ行列に追加する機能をもつ。さらに、PCAモデル読込・追加・保存部360は、作成されたり追加されたり或は変更されたりしたPCAテーブルの情報を、記憶装置106にPCAテーブル350として保存する機能をもつ。PCA計算部362は、PCAモデル読込・追加・保存部360により用意されたPCAテーブルの情報を用いてPCA解析の計算を行ってPCAモデルを作成し、そのPCAモデルに基づいたPCA解析結果(例えば、各サンプルのスコアや、各変数(各バケット)のローディングなど)を出力する。なお、PCA解析の計算方法それ自体は周知であるから(例えば、非特許文献1を参照)、これについての詳細な説明はこの明細書では省略する。
【0150】
SIMCA解析部370は、PCAモデル読込・追加・保存部370と、SIMCA計算部370を有する。PCAモデル読込・追加・保存部370は、記憶装置106上の大量サンプルのNMRヒストグラムデータ356の中からユーザが第1と第2のクラスにそれぞれ割り当てたサンプルのNMRヒストグラムデータを読込んで、第1と第2の2つのクラスのPCAテーブルの情報を用意する機能や、記憶装置106上の大量サンプルのNMRヒストグラムデータ356の中からユーザがテストクラスに割り当てたサンプルのNMRヒストグラムデータを読込んで、テストクラスのPCAテーブルの情報を用意する機能をもつ。さらに、PCAモデル読込・追加・保存部370は、各クラスのPCAテーブルの情報を、記憶装置106に各クラスのPCAテーブル350として保存する機能をもつ。SIMCA計算部372は、PCAモデル読込・追加・保存部370により用意された複数のクラスのPCAテーブルの情報を用いてSIMCA解析の計算を行って各クラスのPCAモデルを作成し、それらのPCAモデルに基づいたSIMCA解析結果(例えば、各サンプルの各クラスからの距離や、各変数(各バケット)のモデリング力や識別力など)を出力する。SIMCA解析の計算には、クラス毎のPCA計算が含まれており、このクラス毎のPCA計算を行うために、SIMCA計算部372は、PCA解析部346のPCA計算部362を使用する。なお、SIMCA解析の計算方法それ自体は周知であるから(例えば、非特許文献1を参照)、これについての詳細な説明はこの明細書では省略する。
【0151】
PCA解析部346とSIMCA解析部348は、解析データ記憶部364と解析データ保存部366とを有する。解析データ記憶部364は、PCA解析部346から出力されたPCA解析結果と、SIMCA解析部348から出力されたSIMCA解析結果を記憶する。解析データ保存部366は、解析データ記憶部364に記憶されたPCA解析結果とSIMCA解析結果を、記憶装置106上に解析結果データ352として保存する。
【0152】
後に詳述するように、解析データ記憶部364に記憶されるSIMCA解析結果の中には、或るレベル以上に高い識別力をもつ変数(バケット又はそれに対応するケミカルシフト値)を選択する情報が含まれている。この変数選択情報は、解析データ記憶部364を通じて、PCA計算部362及びSIMCA計算部372にフィードバックされることができる。そして、PCA計算部362とSIMCA計算部372はそれぞれ、フィードバックされた変数選択情報に従って、選択された変数(つまり、或るレベル以上に高い識別力をもつバケット又はそれに対応するケミカルシフト値)だけを用いて、再度、PCA解析とSIMCA解析を行なって、修正されたPCA解析結果とSIMCA解析結果を再度出力することができるようになっている。これにより、より望ましいPCA解析結果とSIMCA解析結果を得ることができるようになる。
【0153】
表示制御部344は、PCA解析画面制御部374と、SIMCA解析画面制御部376と、NMRスペクトル連携部378とを有する。PCA解析画面制御部374は、PCA計算部362から解析データ記憶部364に出力されたPCA解析結果を受けて、後に具体的に説明するように、UI346上にPCA解析結果を示した複数種のチャート(例えば、スコアプロット、ローディングプロット、寄与率チャート及びローディングチャート)(以下、「PCA解析結果チャート」と総称する)を表示し、また、UI346に入力されたユーザからの選択、拡大、削除及び初期化などの要求に応答して、UI346上のそれらのチャートを変化させる。SIMCA解析画面制御部376は、SIMCA計算部372から解析データ記憶部364に出力されたSIMCA解析結果を受けて、後に具体的に説明するように、SIMCA解析結果を示す複数種のチャート(例えば、クーマンプロット、モデリング力チャート及び識別力チャート)(以下、「SIMCA解析結果チャート」と総称する)をUI346上に表示し、また、UI346に入力されたユーザからの選択、拡大、削除及び初期化などの要求に応答して、UI346上のそれらのチャートを変化させる。
【0154】
NMRスペクトル連携部378は、記憶装置106上の大量のサンプルのNMRスペクトルデータ354の中から、UI346上でユーザにより選択された1又は複数のサンプルのNMRスペクトルデータを読込んで、その選択されたサンプルのNMRスペクトルを示すチャートを、UI346上に上述したPCA解析結果チャートまたはSIMCA解析結果チャートと並べて表示する。
【0155】
以下では、図25に示した各部の機能を、UI346の画面例を参照しつつ説明する。
【0156】
図26は、PCA解析結果を表示した場合におけるUI346の画面例を示す。図27は、SIMCA解析結果を表示した場合におけるUI346の画面例を示す。
【0157】
図26と図27に示すように、この実施形態におけるUI346の画面430(以下、「UI画面」という)は、PCA解析結果とSIMCA解析結果とが交互に切り替え可能な別の画面に表示されるようになっているが、これは表示方法の一例にすぎない。十分に大型のディスプレイ装置を使用する場合のために、同一画面にPCA解析結果とSIMCA解析結果とを表示できるようになっていてもよい。
【0158】
図26と図27に示すように、PCA解析結果とSIMCA解析結果のいずれを表示する場合にも、UI画面430には、コントロールパネル432があり、そこには、図1に示したステップ108〜114の前処理を制御するための各種要求をユーザが入力するための前処理コントロールパネル434と、PCA解析を制御するための各種要求をユーザが入力するためのPCAコントロールパネル436と、SIMCA解析を制御するための各種要求をユーザが入力するためのSIMCAコントロールパネル438とが図示のように配置される。
【0159】
このUI画面430上のPCAコントロールパネル436の一番上の「PCA」選択ラジオボタンがユーザにより操作された(例えばクリックされた)場合には、それに応答して、図25に示したPCA解析画面制御部374が動作する。PCA解析画面制御部374は、解析データ記憶部364からPCA解析結果を受けて、UI画面430上に図26に示すように、複数のPCA解析結果チャート、すなわち、スコアプロット440、ローディングプロット442、寄与率プロット444及びローディングプロットを表示する。他方、SIMCAコントロールパネル438の一番上の「SIMCA」選択ラジオボタンが操作された場合には、それに応答して図25に示したSIMCA解析画面制御部376が動作する。SIMCA解析画面制御部376は、解析データ記憶部364からSIMCA解析結果を受けて、UI画面430上に図27に示すように、複数のSIMCA解析チャート、すなわち、クーマンプロット462、第1のクラスに対するモデリング力チャート464、第2のクラスに対するモデリング力チャート466及び識別力チャート468を表示する。
【0160】
さらに、図26と図27に示すように、PCA解析結果とSIMCA解析結果のいずれを表示する場合にも、図25に示したNMRスペクトル連携部378が動作して、UI画面430上に、NMRスペクトルチャート450を表示する。NMRスペクトルチャート450には、ユーザに選択された1以上のサンプルのNMRスペクトルのグラフが表示される。ここで、注目すべき点は、PCA解析結果を表示した場合、図26に示すように、NMRスペクトルチャート450と寄与率チャート444とローディングチャート446とが、それぞれの横軸であるケミカルシフト軸のスケールが互に一致するようにして、ケミカルシフト軸に直交する縦軸方向に配列される点である。また、同様に、SIMCA解析結果を表示した場合、図27に示すように、NMRスペクトルチャート450と識別力チャート468とが、それぞれの横軸であるケミカルシフト軸のスケールが互に一致するようにして、ケミカルシフト軸に直交する縦軸方向に配列される。これにより、ユーザは、寄与率、ローディング又は識別力の大きい変数(バケット又はそれに対応するケミカルシフト値)とNMRスペクトルのピークとの相関関係が視覚的に容易に把握でき、例えばメタボノミクスにおいてバイオマーカを決定することがより容易になる。
【0161】
以下では、PCA解析を行なう場合と、SMCA解析を行なう場合とに分けて、それぞれの場合における動作をより具体的に説明する。まず、PCA解析を行なう場合について説明する。
【0162】
まず、図26に示したUI画面430上のPCAコントロールパネル436内の「PCA」選択ラジオボタンが操作された上で「Open_Model」ボタンが操作されると、図25に示したPCAモデル読込・追加・保存部360が動作して、記憶装置106内の大量のサンプルのNMRヒストグラムデータ356の中から、ユーザに指定された複数のサンプルのNMRヒストグラムデータを選択して読み込み、図24に示したような、多変量データ行列やその他の情報をからなるPCAテーブルの情報を作成する。ユーザ指定されたサンプルの数がN個で、各サンプルのNMRスペクトルを構成する変数(バケット)の数がM個であるならば、PCAテーブルの情報に含まれる多変量データ行列はN×Mのデータ行列となる。
【0163】
PCAモデル読込・追加・保存部360は、作成したPCAテーブルの 情報をPCA計算部362に引渡す。PCA計算部362は、そのPCAテーブルの情報を用いてPCA解析の計算を行なって、そのPCAテーブルの情報に含まれている多変量データ行列についてのPCAモデルを算出する。ここで、PCA解析計算において計算される主成分の数は、UI画面430上のPCAコントロールパネル436の一番上の「PCA」選択ラジオボタンの右脇に置かれた入力ボックスにユーザが入力した数で決まる(図示の例では主成分数として「6」が設定されている)。PCA計算部362は、算出されたPCAモデルに基づくPCA解析結果として、各主成分に対する各サンプルのスコア、そのスコアの分散、各主成分に対する各変数のローディング及び各変数の寄与率(全主成分に対するローディングの絶対値の和)などを算出する。算出されたPCA解析結果は、解析データ記憶部364に記憶される。
【0164】
PCA解析画面制御部374が、解析データ記憶部364から上記PCA解析結果を受け取る。PCA解析画面制御部374は、図26に示すように、各主成分に対する各サンプルのスコアに基づいて、スコアプロット440を作成してUI画面430上に表示し、各主成分に対する各変数のローディングに基づいて、ローディングプロット442とローディングチャート446を作成してUI画面430上に表示し、さらに、各変数の寄与率に基づいて、寄与率チャート444を作成してUI画面430上に表示する。
【0165】
図26に示すように、スコアプロット440では、ユーザにより選択された2つの主成分に対するそれぞれのスコアをそれぞれX軸とY軸にとり、各サンプルのその2つの主成分に対するスコアがプロットされる。X軸とY軸に相当する主成分は、PCAコントロールパネル436内の「X」軸プルダウンメニュー及び「Y」軸プリダウンメニューからユーザにより選ばれた番号の主成分である(図示の例では、X軸が第「1」主成分(PCA1)、Y軸が第「2」主成分(PCA2)。)。プロットされるサンプルのマークの形状と色は、上記PCAテーブル情報の中のサンプル毎のプロットタイプとプロットカラー(図24の参照番号410、412に対応する情報)に従う。さらに、X軸とY軸には、対応する主成分番号とその分散も表示される(例:PC1(39.8%))。さらに、計算に使用されたサンプル数も表示される。
【0166】
スコアプロット440上で、複数のサンプルマーク間の位置が近いほど、それらのサンプルは特徴的に互いにより似ており、他方、位置が遠いほどより違っていることを意味する。従って、スコアプロット440上に、例えば互いに分離された幾つかのサンプルマークの塊が存在するならば、分析対象のサンプルが、それぞれの塊に対応する特徴的に異なる幾つかのクラスに分けられたと判断することができる。
【0167】
また、各主成分におけるスコアの分散は、その値が大きいほど、その主成分がサンプルのクラス分けに寄与する度合いが高いことを意味する。例えば、X軸とY軸の主成分の分散の和が、或る値(例えば、60%程度)より大きければ、それらの主成分を用いたPCAモデルにおいてサンプルがかなり明確にクラス分けされ得ると判断することができる。
【0168】
PCAコントロールパネル436内の「Name」チェックボックスにユーザがチェックを入れると、PCA解析画面制御部374は、図28(スコアプロット440内の部分領域の拡大図)に示すように、スコアプロット440上の全てのサンプルマークの近傍に、対応するサンプルのNMRスペクトルのファイル名を表示する。マウスポインターが各サンプルの上に置かれた場合にも、スコアプロット440の右上に自動的に対応するファイル名が表示される。これにより、ユーザは、スコアプロット440上の各サンプルマークが、具体的にどのサンプルに該当するのかを容易に把握できる。
【0169】
図26に示すように、ローディングプロット442では、PCAコントロールパネル436内の「X」軸プルダウンメニュー及び「Y」軸プリダウンメニューで選択された2つの主成分におけるローディングをそれぞれX軸とY軸にとり、その2つの主成分に対する各変数(バケット又はそれに対応するケミカルシフト値)のローディングが、所定の形状とカラーをもつ変数マークでプロットされる。また、X軸とY軸には、対応する主成分願号とその分散が表示される(例:PC1(39.8%))。また、計算に使用された変数(バケット)の数も表示される。
【0170】
ローディングプロット442上で、X軸とY軸の原点から遠くに存在する変数ほど、X軸とY軸にそれぞれ対応する主成分に対する寄与度が高い、つまり、サンプルのクラス分けに寄与する度合いが高いことを意味する。
【0171】
PCAコントロールパネル436内の「Name」チェックボックスにユーザがチェックを入れると、PCA解析画面制御部374は、図29(ローディングプロット442内の部分領域の拡大図)に示すように、ローディングプロット442上の全ての変数マークの近傍に、対応する変数(バケット)のケミカルシフト値(ppm)を表示する。また、マウスポインターが各変数マークの上に置かれた場合にも、ローディングプロット442の右上に自動的に対応するケミカルシフト値が表示される。これにより、ユーザは、ローディングプロット442上の各変数マークが、具体的にどの変数(ケミカルシフト値)に該当するのかを容易に把握できる。
【0172】
図26に示すように、寄与率チャート444では、ケミカルシフトを横軸にとり、各変数(ケミカルシフト値)の第1、2、3主成分に対するローディングの絶対値と残差(residual)成分の和が、棒グラフの形で表示される。第1、2、3主成分のスコアの分散と残差成分の分散も表示される。寄与率チャート444において、寄与率(棒グラフの高さ)が高い変数ほど、サンプルのクラス分けに寄与する度合いが高いと判断することができる。
【0173】
図26に示すように、ローディングチャート446では、ケミカルシフトを横軸にとり、PCAコントロールパネル436内の「X」軸プルダウンメニューで選択された1つの主成分に対する各変数のローディングが、棒グラフの形で表示される。また、そのX軸に選択された主成分のスコアの分散も表示される。ローディングチャート446において、ローディングの絶対値(棒グラフの高さ)が高い変数ほど、その主成分に寄与する度合いが高いと判断することができる。
【0174】
図26に示されたスコアプロット440、ローディングプロット442、寄与率プロット444及びローディングチャート446のそれぞれにおいて、選択、拡大/縮小、削除、初期化等の各種操作を行うことが可能である。
【0175】
まず、スコアプロット440の各種操作について説明する。
【0176】
図30に示すように、スコアプロット440上の任意の1以上のサンプルマークをマウスのドラッグにより選択すると、PCA解析画面制御部374(図25)が、その選択範囲470をスコアプロット440上に表示する。これと連携して、NMRスペクトル連携部378(図25)が動作して、選択されたサンプルマークに対応するサンプルのNMRスペクトルデータを、PCMテーブルに登録されているそのサンプルのパス名とファイル名とを用いて、記憶装置106内のNMRスペクトルデータ354から読み込み、そして、選択されたサンプルのNMRスペクトルをNMRスペクトルチャート450上に表示する。NMRスペクトルチャート450には、表示されたNMRスペクトルのファイル名も表示される。
【0177】
NMRスペクトルチャート450上で、複数のNMRスペクトルは、ケミカルシフト軸スケールを互いに一致させるようにして、ケミカルシフト軸に直交する縦軸方向に並んで表示され、且つ、規定の異なる色で区別して表示されるので、相互間の識別および相関が一目で分かる。加えて、図26に示されているように、NMRスペクトルチャート450上の各NMRスペクトルと、寄与率チャート444とローディングチャート446とが、ケミカルシフト軸スケールを互いに一致させて、縦軸方向に並んで表示されるので、それらの間の相関も一目で分かる。
【0178】
ユーザがキーボードの「CTRL」キーを押しながら、スコアプロット440上の任意のサンプルマークをマウスにてドラッグして選択すると、PCA解析画面制御部374は、そのサンプルマークを選択範囲に追加し、又は、そのサンプルマークが既に選択されている場合には、そのサンプルマークを選択範囲から外す。これと連携して、NMRスペクトル連携部378が、選択範囲に追加されたサンプルマークに対応するサンプルのNMRスペクトルをNMRスペクトルチャート450上に追加表示したり、又は、選択範囲から外されたサンプルのNMRスペクトルをNMRスペクトルチャート450から消去する。
【0179】
図31Aに示すように、スコアプロット440上で選択されたサンプルマークに関し、ユーザが「Del」キーを押すなどの削除要求を行うと、PCA解析画面制御部374は、図31Bに示すように、そのサンプルマークをスコアプロット440上から消去し、これと連携して、NMRスペクトル連携部378が、その選択されたサンプルのNMRスペクトルをNMRスペクトルチャート450から消去する。同時に、PCA計算部362が、その削除要求のあったサンプルのPCAテーブル上でのサンプルステータス(図24の参照番号414に相当)を「0」(解析対象に含まれる)から「1」(解析対象に含まれない)に切り替え、そして、サンプルステータスが「0」(解析対象に含まれる)であるサンプルのNMRヒストグラムデータだけを用いて、PCA解析計算を再度行い、その再計算の結果を解析データ記憶部364に出力する。PCA解析画面制御部374は、解析データ記憶部364から再計算の結果を受けて、UI画面430上に、再計算の結果に基づくスコアプロット440、ローディングプロット442、寄与率チャート444及びローディングロット446を表示する(図31Bは、再計算後に表示されたスコアプロット440の例を示す)。
【0180】
例えば、スコアプロット440上に、解析目的からみて支障になる或いは寄与しないと考えられるサンプルが表示されていた場合、そのサンプルを上記のようにして解析対象から除外した上で再度PCA計算を行うことにより、より望ましい解析結果が得られることになる。
【0181】
また、ユーザがキーボードの「Shift」キーを押しながら、スコアプロット440上の任意の部分領域をマウスにてドラッグし選択すると、PCA解析画面制御部374は、選択した部分領域を拡大してスコアプロット440上に表示する。その後、ユーザが拡大表示されたスコアプロット440の画面を選択して、キーボードの「Home」キーを押すと、PCA解析画面制御部374は、スコアプロット440上の拡大率を「1」に初期化し、全てのスコア範囲を表示する。
【0182】
また、ユーザがPCMコントロールパネル436上の「Reset_score」ボタンを操作すると、PCA計算部362が、PCAテーブル内の上記サンプル削除機能により「1」となっていたサンプルステータスを初期値「0」し、このように初期化されたPCAテーブルの内容に基づいて再度PCA解析計算を行い、そして、PCA解析画面制御部374が、そのPCA解析計算の結果に基づいたスコアプロット440、ローディングプロット442、寄与率チャート444及びローディングロット446を改めて表示する。
【0183】
次に、ローディングプロット442の各種操作について説明する。
【0184】
図32に示すように、ユーザがローディングプロット442内の任意の1以上の変数マークをマウスでドラッグして選択すると、PCA解析画面制御部374が、その選択範囲472をローディングプロット442上に表示する。これと連携して、PCA解析画面制御部374は、寄与率チャート444及びローディングチャート446内の選択された変数マークに対応する変数(ケミカルシフト値)の棒グラフを、他の変数の棒グラフとは異なる所定の選択色で表示する(図中では、選択された変数の棒グラフを黒塗りで表示している。)。これにより、ローディングプロット442、寄与率チャート444及びローディングチャート446上での各変数(ケミカルシフト値)の識別と相関が一目で分かる。
【0185】
ユーザがキーボードの「CTRL」キーを押しながら、ローディングプロット442上の任意の変数マークをマウスにてドラッグして選択すると、PCA解析画面制御部374は、その変数マークを選択範囲に追加し、又は、その変数マークが既に選択されている場合には、その変数マークを選択範囲から外す。これと連携して、PCA解析画面制御部374は、寄与率チャート444及びローディングチャート446上、選択範囲に追加された変数マークに対応する変数の棒グラフを追加的に選択色で表示したり、又は、選択範囲から外された変数の棒グラフの選択色表示を解除したりする。
【0186】
また、図33Bに示すように、上記のようにして或る選択範囲476で選択された変数マークについて、ユーザが「Del」キーを押すなどの削除要求を行うと、PCA解析画面制御部374は、その変数マークをローディングプロット440上から消去する。同時に、PCA計算部362が、その削除要求のあった変数マークに対応する変数(バケット)のPCAテーブル上でのステータス(図24の参照番号426に相当)を「0」(解析に使用する)から「1」(解析に使用しない)に切り替え、そして、解析対象のサンプルのNMRヒストグラムデータ中の、ステータスが「0」(解析に使用する)である変数(バケット)に対応する積分値だけを使用して、PCA解析計算を再度行い、その再計算の結果を解析データ記憶部364に出力する。PCA解析画面制御部374は、解析データ記憶部364から再計算の結果を受けて、UI画面430上に、再計算の結果に基づくスコアプロット440、ローディングプロット442、寄与率チャート444及びローディングロット446を表示する(図33Bは、再計算後に表示されたローディングプロット442の例を示す。)。
【0187】
例えば、ローディングプロット440上に、解析目的からみて支障になる或いは寄与しないと考えられる変数が表示されていた場合、その変数を上記のようにして解析に使用する変数から除外した上で再度PCA計算を行うことにより、より望ましい解析結果が得られることになる。
【0188】
また、ユーザが「Shift」キーを押しながら、ローディングプロット442上の任意の変数マークをマウスにてドラッグして選択すると、PCA解析画面制御部374は、ローディングプロット442上の選択範囲に相当する部分を拡大して表示する。この後、ユーザが拡大表示されたローディングプロット442を選択して、キーボードの「Home」キーを押すと、PCA解析画面制御部374は、ローディングプロット442の拡大率を「1」に初期化し、全てのケミカルシフト範囲を表示する。
【0189】
また、ユーザがPCMコントロールパネル436上の「Reset loading」ボタンを操作すると、PCA計算部362が、PCAテーブル内容の上記サンプル削除機能により「1」となっていたバケットのステータスを初期値「0」に戻し、このように初期化されたPCAテーブルの内容に基づいて再度PCA解析計算を行い、そして、PCA解析画面制御部374が、そのPCA解析計算の結果に基づいたスコアプロット440、ローディングプロット442、寄与率チャート444及びローディングロット446を改めて表示する。
【0190】
次に、寄与率チャート444とローディングチャート446の各種操作について説明する。
【0191】
ユーザが、寄与率チャート444又はローディングチャート446のケミカルシフト軸上の任意の変数(ケミカルシフト値)範囲をマウスにてドラッグして選択すると、PCA解析画面制御部374が、その選択範囲に属する変数のローディングチャート442上の変数マークと、寄与率チャート444及びローディングチャート446上の棒グラフを、選択範囲外の変数のそれと区別した所定の選択色で表示する。それにより、ローディングプロット442、寄与率チャート444及びローディングチャート446上での各変数(ケミカルシフト値)の識別と相関が一目で分かる。
【0192】
また、上記のようにして寄与率チャート444又はローディングチャート446上で選択された変数(ケミカルシフト値)範囲について、ユーザが「Del」キーを押すなどの削除要求を行うと、PCA解析画面制御部374は、その選択範囲に属する変数の変数マークをローディングプロット440上から消去する。同時に、PCA計算部362が、その選択範囲に属する変数(バケット)のPCAテーブル上でのステータス(図24の参照番号426に相当)を「0」(解析に使用する)から「1」(解析に使用しない)に切り替え、そして、解析対象のサンプルのNMRヒストグラムデータ中の、ステータスが「0」(解析に使用する)である変数(バケット)に対応する積分値だけを使用して、PCA解析計算を再度行い、その再計算の結果を解析データ記憶部364に出力する。PCA解析画面制御部374は、解析データ記憶部364から再計算の結果を受けて、UI画面430上に、再計算の結果に基づくスコアプロット440、ローディングプロット442、寄与率チャート444及びローディングロット446を表示する。
【0193】
例えば、寄与率チャート444又はローディングチャート446上に、解析目的からみて支障になる或いは寄与しないと考えられる変数(ケミカルシフト値)範囲が在る場合、その範囲の変数を上記のようにして解析に使用する変数から除外した上で再度PCA計算を行うことにより、より望ましい解析結果が得られることになる。
【0194】
また、図34Aに示すように、ユーザが「Shift」キーを押しながら、ローディングチャート446又は寄与率チャート444のケミカルシフト軸上の任意の変数(ケミカルシフト値)範囲をマウスにてドラッグして選択すると、PCA解析画面制御部374は、図34Bに示すように、ローディングチャート446及び寄与率チャート444の中の選択された変数(ケミカルシフト値)範囲に相当する部分を拡大して表示する。これに連携して、NMRスペクトル連携部378が、NMRスペクトルチャート450の中の選択された変数(ケミカルシフト値)範囲に相当する部分を拡大して表示する。従って、どのような拡大率で表示した場合でも常に、ローディングチャート446と寄与率チャート444とNMRスペクトルチャート450はケミカルシフト軸スケールが一致した状態に維持され、それらの間の相関関係が一目で分かるようになっている。
【0195】
このようにローディングチャート446及び寄与率チャート444並びにNMRスペクトルチャート450の拡大表示を行なった後、ユーザが拡大表示されたローディングチャート446又は寄与率チャート444を選択して、キーボードの「Home」キーを押すと、PCA解析画面制御部374とNMRスペクトル連携部378は、それらのチャート446、444、450の拡大率を「1」に初期化し、全てのケミカルシフト範囲を表示する。
【0196】
PCA解析を行なう場合、以上のような各種の操作がUI画面430上で行なうことができる。このような操作を逐次に行いながらPCA解析を進めていく過程の任意の段階で、ユーザがPCAコントロールパネル436内の「Add_Model」ボタンを操作すると、PCAモデル読込・追加・保存部360が、記憶装置106内の大量のサンプルのNMRヒストグラムデータ356の中から、ユーザに指定された追加のサンプルのNMRヒストグラムデータを選択して読み込み、これを現在処理中のPCAテーブル内の多変量データ行列に追加し、その多変量データ行列が追加されたPCAテーブルの情報をPCA計算部362に渡す。PCA計算部362は、その多変量データ行列が追加されたPCAテーブルの情報を用いてPCA解析計算を再実行する。PCA解析画面制御部374は、その再実行されたPCA解析計算の結果を、UI画面430に改めて表示する。
【0197】
また、上記のようにPCA解析を進めていく過程の任意の段階で、ユーザがPCAコントロールパネル436内の「Save_model」ボタンを操作すると、PCAモデル読込・追加・保存部360が、その時点で処理中の多変量データ行列を始めとするPCAテーブルの情報を、記憶装置106内にPCAテーブル350として保存する。
【0198】
以上が、PCA解析を行なう場合の各部の動作である。上述した説明から分かるように、PCA解析を行なう場合、UI画面430上では、スコアプロット440、ローディングプロット442、寄与率チャート444、ローディングチャート446及びNMRスペクトルチャート450の全ての情報が有機的に結合されて表示され、そして、いずれかの操作が行われると、その操作結果が、それに関連する全てのチャートにリアルタイムに反映される。特に、解析対象からのサンプルの削除や変数の削除などを行なった後にPCA解析をすばやく再実行し、より精度の高い解析結果を導き出すことが容易である。また、UI画面430上では、PCA解析結果に連携してNMRスペクトルも表示される。そのため、PCA解析結果とNMRスペクトルの形状とを合わせて評価することができ、解析結果の意味づけを考察することがより容易になる。PCA解析過程で必要な操作を行った後の最終的に評価結果からPCAの再解析およびスペクトルの再処理をすばやく実行しより精度の高い解析結果を導き出すことが容易になる。
【0199】
次に、SIMCA解析を行なう場合における動作について説明する。
【0200】
すなわち、まず、図26又は図27に示したUI画面430上のSIMCAコントロールパネル438内の「SIMCA」選択ラジオボタンが操作された上で「Model1」ボタンが操作されると、図25に示したSIMCA解析部348内のPCAモデル読込・追加・保存部370が動作して、記憶装置106内の大量のサンプルのNMRヒストグラムデータ356の中から、ユーザに指定された複数のサンプルのNMRヒストグラムデータを選択して読み込み、図24に示したような、多変量データ行列やその他の情報からなるPCAテーブルの情報を作成する。作成されたPCAテーブルの情報は、第1のクラスのPCAテーブル情報として扱われる。同様に、「Model2」ボタンが操作されると、PCAモデル読込・追加・保存部370が、記憶装置106内のNMRヒストグラムデータ356の中から、ユーザに指定された複数のサンプルのNMRヒストグラムデータを選択して読み込み、第2のクラスのPCAテーブルの情報を作成する。
【0201】
SIMCA解析を開始する場合には、少なくとも第1と第2クラスのPCAテーブルが定義される必要がある。更に、ユーザは、所望すればSIMCAコントロールパネル438内の「Model1」ボタンが操作されると、「Test_model」ボタンを操作することができる。「Test_model」ボタンが操作されると、PCAモデル読込・追加・保存部370が、記憶装置106内のNMRヒストグラムデータ356の中から、ユーザに指定された複数のサンプルのNMRヒストグラムデータを選択して読み込み、テストクラスのPCAテーブルの情報を作成する。
【0202】
PCAモデル読込・追加・保存部370は、作成した第1クラスと第2クラスのPCAテーブルの
情報をSIMCA計算部372に引渡す。テストクラスのPCAテーブルが更に作成された場合には、そのテストクラスのPCAテーブルの情報もSIMCA計算部372に引渡される。SIMCA計算部372は、それらのクラスのPCAテーブルの情報を用いて、PCA計算部362を呼び出してクラス毎のPCAモデルを算出させ、それらのクラスのPCAモデルを用いてSIMCA解析の計算を行なう。各種クラスのPCAモデルの主成分数は、SIMCAコントロールパネル438内の「SIMCA」選択ラジオボタンの右脇の入力ボックスにユーザが入力した数に従う。SIMCA計算部372は、SIMCA解析結果として、第1と第2の各クラスに対する各サンプルの距離、第1と第2の各クラスの残差標準偏差(RSD)、第1と第2の各クラスに対する各変数(ケミカルシシフト値)のモデリング力(modeling power)、及び各変数(ケミカルシシフト値)の識別力(discrimination power)などを算出する。算出されたSIMCA解析結果は、解析データ記憶部364に記憶される。
【0203】
SIMCA解析画面制御部374が、解析データ記憶部364から上記SIMCA解析結果を受け取る。SIMCA解析画面制御部376は、図27に示すように、第1と第2の各クラスに対する各サンプルの距離に基づいてクーマンプロット460を作成してUI画面430上に表示し、第1と第2の各クラスに対する各変数(ケミカルシシフト値)のモデリング力に基づいて、第1クラスのモデリング力チャート462と第2クラスのモデリング力チャート464を作成してUI画面430上に表示し、さらに、各変数(ケミカルシシフト値)の識別力に基づいて、識別力チャート466を作成してUI画面430上に表示する。
【0204】
図27に示すように、クーマンプロット460では、第1クラスと第2クラスからの距離をそれぞれX軸とY軸にとり、各サンプルのその2つのクラスまでの距離がプロットされる。プロットされるサンプルのマークの形状と色は、上記PCAテーブル情報の中のサンプル毎のプロットタイプとプロットカラー(図24の参照番号410、412に対応する情報)に従う。さらに、クーマンプロット460上には、第1クラスと第2クラスのそれぞれの残差標準偏差(RSD)の名称と値(例:RSD(1)0.5449)がX軸とY軸の近傍に表示され、かつ、それぞれのクラスの残差標準偏差(RSD)を示す直線(以下、「RSD」線という)480、482が表示される。
【0205】
クーマンプロット460上でのサンプルマークの配置状態が、次のような明快分類状態に近い状態であるほど、サンプルがより明確に第1クラスと第2クラスに分類されたと判断することができる。すなわち、その明快分類状態とは、サンプルマークが2つの塊に分かれ、一方の塊が第1クラスのRSD線480とY軸との間に領域に存在し、他方の塊が第2クラスのRSD線482とX軸との間の領域に存在するという状態である。
【0206】
SIMCAコントロールパネル438内の「Name」チェックボックスにユーザがチェックを入れると、SIMCA解析画面制御部374は、図28を参照して説明したスコアプロット440の場合と同様に、クーマンプロット460上の全てのサンプルマークの近傍に、対応するサンプルのNMRスペクトルのファイル名を表示する。マウスポインターが各サンプルの上に置かれた場合にも、クーマンプロット460の右上に自動的に対応するファイル名が表示される。これにより、ユーザは、クーマンプロット460の各サンプルマークが、具体的にどのサンプルに該当するのかを容易に把握できる。
【0207】
図27に示すように、第1クラスと第2クラスのモデリングチャート462、464では、ケミカルシフトを横軸にとり、各変数(ケミカルシフト値)の第1クラスと第2クラスについてのモデリング力(これは、それぞれのクラスのデータ構造を記述するための各変数の有効性を評価するための一つの指標である)が、棒グラフの形で表示される。各クラスのモデリングチャート462、464において、モデリング力(棒グラフの高さ)が高い変数ほど、各クラスのデータ構造を記述する有効性がより高いと判断することができる。
【0208】
図27に示すように、識別力チャート466では、ケミカルシフトを横軸にとり、各変数(ケミカルシフト値)の識別力(これは、第1と第2のクラスへの分類のための各変数の有効性を評価するための一つの指標である)が、棒グラフの形で表示される。識別力チャート466において、識別力(棒グラフの高さ)が高い変数ほど、第1と第2のクラスへの分類のための有効性がより高いと判断することができる。
【0209】
図27に示されたクーマンプロット460、モデリングチャート462、464、識別力チャート466のそれぞれにおいて、選択、拡大/縮小、削除、初期化等の各種操作を行うことが可能である。
【0210】
まず、クーマンプロット460の各種操作について説明する。
【0211】
図35に示すように、クーマンプロット460上の任意の1以上のサンプルマークをマウスのドラッグにより選択すると、SIMCA解析画面制御部376が、その選択範囲484をクーマンプロット460上に表示する。これと連携して、NMRスペクトル連携部378が動作して、選択されたサンプルマークに対応するサンプルのNMRスペクトルデータを、PCMテーブルに登録されているそのサンプルのパス名とファイル名とを用いて、記憶装置106内のNMRスペクトルデータ354から読み込み、そして、選択されたサンプルのNMRスペクトルをNMRスペクトルチャート450上に表示する。NMRスペクトルチャート450には、表示されたNMRスペクトルのファイル名も表示される。
【0212】
NMRスペクトルチャート450上で、複数のNMRスペクトルは、ケミカルシフト軸スケールを互いに一致させるようにして、ケミカルシフト軸に直交する縦軸方向に並んで表示され、且つ、規定の異なる色で区別して表示されるので、相互間の識別および相関が一目で分かる。加えて、図27に示されているように、NMRスペクトルチャート450上の各NMRスペクトルと識別力チャート466とが、ケミカルシフト軸スケールを互いに一致させて、縦軸方向に並んで表示されるので、それらの間の相関も一目で分かる。
【0213】
ユーザがキーボードの「CTRL」キーを押しながら、クーマンプロット460上の任意のサンプルマークをマウスにてドラッグして選択すると、SIMCA解析画面制御部376は、そのサンプルマークを選択範囲に追加し、又は、そのサンプルマークが既に選択されている場合には、そのサンプルマークを選択範囲から外す。これと連携して、NMRスペクトル連携部378が、選択範囲に追加されたサンプルマークに対応するサンプルのNMRスペクトルをNMRスペクトルチャート450上に追加表示したり、又は、選択範囲から外されたサンプルのNMRスペクトルをNMRスペクトルチャート450から消去する。
【0214】
図36Aに示すように、クーマンプロット460上で選択されたサンプルマークに関し、ユーザが「Del」キーを押すなどの削除要求を行うと、SIMCA解析画面制御部376は、図36Bに示すように、そのサンプルマークをクーマンプロット460上から消去し、これと連携して、NMRスペクトル連携部378が、その選択されたサンプルのNMRスペクトルをNMRスペクトルチャート450から消去する。同時に、SIMCA計算部372が、その削除要求のあったサンプルの該当クラスのPCAテーブル上でのサンプルステータス(図24の参照番号414に相当)を「0」(解析対象に含まれる)から「1」(解析対象に含まれない)に切り替え、そして、サンプルステータスが「0」(解析対象に含まれる)であるサンプルのNMRヒストグラムデータだけを用いて、SIMCA解析計算を再度行い、その再計算の結果を解析データ記憶部364に出力する。SIMCA解析画面制御部376は、解析データ記憶部364から再計算の結果を受けて、UI画面430上に、再計算の結果に基づくクーマンプロット460、モデリングプロット462、464及び識別力チャート466を表示する(図36Bは、再計算後に表示されたクーマンプロット460の例を示す)。
【0215】
例えば、クーマンプロット460上に、解析目的からみて支障になる或いは寄与しないと考えられるサンプルが表示されていた場合、そのサンプルを上記のようにして解析対象から除外した上で再度SIMCA計算を行うことにより、より望ましい解析結果が得られることになる。
【0216】
また、ユーザがキーボードの「Shift」キーを押しながら、クーマンプロット460上の任意の部分領域をマウスにてドラッグし選択すると、SIMCA解析画面制御部376は、選択した部分領域を拡大してクーマンプロット460上に表示する。その後、ユーザが拡大表示されたクーマンプロット460の画面を選択して、キーボードの「Home」キーを押すと、SIMCA解析画面制御部376は、クーマンプロット460上の拡大率を「1」に初期化し、元の表示範囲の全部を表示する。
【0217】
また、ユーザがSIMCAコントロールパネル438上の「Reset_score」ボタンを操作すると、SIMCA計算部372が、各クラスのPCAテーブル内の上記サンプル削除機能により「1」となっていたサンプルステータスを初期値「0」し、このように初期化されたPCAテーブルの内容に基づいて再度SIMCA解析計算を行い、そして、SIMCA解析画面制御部376が、そのSIMCA解析計算の結果に基づいたクーマンプロット460、モデリングプロット462、464及び識別力チャート466を改めて表示する。
【0218】
次に、モデリング力チャート462、464と識別力チャート466の各種操作について説明する。
【0219】
図37に示すように、識別力チャート466上で、ユーザが縦軸方向の任意の高さ位置(つまり、任意の識別力の値)をマウスでドラッグして閾値として指定すると、SMCA解析画面制御部376が、識別力チャート466上のその指定された閾値を示す閾値ライン486を表示するとともに、その指定された閾値より高い識別力を持つ変数のみを選択して、その選択された変数の棒グラフを、モデリング力チャート462、464及び識別力チャート466の全てにおいて、他の変数とは異なる所定の選択色で表示する。同時に、解析結果記憶部364が、選択された変数(すなわち、指定された閾値より識別力の高い変数)を特定する情報を記憶する。同様に、ユーザが第1クラス又は第2クラスモデリング力チャート462又は464上で、或るモデリング力の値を閾値として指定した場合にも、その閾値より高いモデリング力をもつ変数が他の変数とは異なる選択色で表示され、かつ、その選択された変数を特定する情報が解析結果記憶部364に記憶される。これにより、モデリング力チャート462、464、識別力チャート466及NMRスペクトルチャート450における選択された変数の識別や相関関係が一目で分かる。
【0220】
上記のようにして識別力又はモデリング力の高い変数が選択された後、ユーザがSIMCAコントロールパネル438内の「Set_D.P.」ボタンを操作すると、SIMCA計算部372が、解析データ記憶部364から選択された変数の特定情報を受け取り、各クラスのPCAテーブル情報中の選択されていない変数のステータスを「0」(解析に使用する)から「1」(解析に使用しない)に変更し、そして、選択された変数だけを用いて再度SIMCA計算を行なう。続いて、SIMCA解析画面制御部376が、図38に示すように、SIMCA再計算の結果を受けて、それに基づきクーマンプロット460、モデリングプロット462、464及び識別力チャート466を改めて表示する。このようにして識別力又はモデリング力の高い変数だけを用いてSIMCA解析を再度行うことで、より望ましい解析結果を得ることが可能になる。
【0221】
また、上記のようにして識別力又はモデリング力の高い変数が選択された後、ユーザがPCAコントロールパネル436内の「Set_D.P.」ボタンを操作すると、PCA計算部362が、解析データ記憶部364から選択された変数の特定情報を受け取り、SIMCA解析で使用されていた全クラスのPCAテーブル情報を統合して、全クラスのサンプルの多変量データ行列をもつPCA解析用のPCAテーブル情報を作成し、そのPCA解析用のPCAテーブル情報中の選択された変数のステータスを「0」(解析に使用する)とし、選択されてない変数のステータスを「1」(解析に使用しない)とする。そして、PCA計算部362は、その選択された変数だけを用いて、PCA解析用のPCAテーブル情報中の全クラスのサンプルの多変量データ行列についてPCA計算を再度行なう。続いて、PCA解析画面制御部374が、UI画面430を図27に示すようなSIMCA解析用のものから、図26に示すようなPCA解析用のもの切り替え、上述したPCA解析の再計算の結果に基づいたスコアプロット440、ローディングプロット442、寄与率チャート444及びローディングチャート446を改めて表示する。このようにして識別力又はモデリング力の高い変数だけを用いてPCA解析を再度行うことで、より望ましい解析結果を得ることが可能になる。
【0222】
また、図27に示すようなSIMCA解析用のUI画面430において、ユーザが「Shift」キーを押しながら、モデリング力チャート462、464又は識別力チャート466中のケミカルシフト軸上の任意の変数(ケミカルシフト値)範囲をマウスにてドラッグして選択すると、SIMCA解析画面制御部376は、モデリング力チャート462、464及び識別力チャート466中の選択された変数(ケミカルシフト値)範囲に相当する部分を拡大して表示する。これに連携して、NMRスペクトル連携部378が、NMRスペクトルチャート450の中の選択された変数(ケミカルシフト値)範囲に相当する部分を拡大して表示する。従って、どのような拡大率で表示した場合でも常に、識別力チャート466とNMRスペクトルチャート450はケミカルシフト軸スケールが一致した状態に維持され、それらの間の相関関係が一目で分かるようになっている。
【0223】
このようにモデリング力チャート462、464、識別力チャート466及びNMRスペクトルチャート450の拡大表示を行なった後、ユーザが拡大表示されたモデリング力チャート462、464又は識別力チャート466を選択して、キーボードの「Home」キーを押すと、SIMCA解析画面制御部376とNMRスペクトル連携部378は、それらのチャート462、464、466の拡大率を「1」に初期化し、全てのケミカルシフト範囲を表示する。
【0224】
以上が、SIMCA解析を行なう場合の各部の動作である。上述した説明から分かるように、SIMCA解析を行なう場合、UI画面430上では、クーマンプロット460、モデリングプロット462、464、識別力チャート466及びNMRスペクトルチャート450の全ての情報が有機的に結合されて表示され、そして、いずれかの操作が行われると、その操作結果が、それに関連する全てのチャートにリアルタイムに反映される。特に、解析対象からのサンプルの削除や変数の選択などを行なった後にSIMCA解析をすばやく再実行し、より精度の高い解析結果を導き出すことが容易である。また、UI画面430上では、SIMCA解析結果に連携してNMRスペクトルも表示される。そのため、SIMCA解析結果とNMRスペクトルの形状とを合わせて評価することができ、解析結果の意味づけを考察することがより容易になる。
【0225】
また、SIMCA解析では、各変数についてモデリング力と識別力という二つの尺度が算出される。識別力は2つのクラスについてどの変数が分類に有効であるかを表している。下がって、識別力に基づいて分類に寄与する変数を抽出することができ、他の変数は分類にあまり寄与しないノイズと考えることができる。この実施形態では、上述したように分類に有効な変数のみを用いて再度PCA解析もしくはSIMCA解析を実行することができる。それにより、サンプルをより一層明確にクラス分けすることが可能となる。
【0226】
図39は、SIMCA解析で選択された識別力の高い変数を使ってSIMCA解析計算又はPCA解析計算を再実行するための処理手順を示す。
【0227】
図39に示すように、ステップ500でSIMCA解析が実施され、ステップ502で、識別力チャート466上で識別力の閾値が指定されると、ステップ504で、その閾値以上の識別力をもつ変数が抽出される。その後、ステップ506で、SIMCAコントロールパネル438上の「Set_D.P.」ボタンが操作されると、ステップ508で、抽出された変数だけを用いてSIMCA解析計算が再度実行され、SIMCA解析結果が表示される。
【0228】
また、ステップ504の後、ステップ510で、PCAコントロールパネル436上の「Set_D.P.」ボタンが操作されると、ステップ512で、抽出された変数だけを用いて、SIMCA解析の対象となったサンプルについてPCA解析計算が再度実行され、PCA解析結果が表示される。また、ステップ504の後、ステップ514で、PCAコントロールパネル436上の「Add_D.P.」ボタンが操作されると、ステップ516で、現在の解析に使用することになっている変数に、抽出された変数を追加した上で、それらの変数を用いてSIMCA解析の対象となったサンプルについてPCA解析計算が再度実行され、PCA解析結果が表示される。
【0229】
ところで、上述した「Add_D.P.」ボタンを用いた変数の追加機能は、例えば次のような用途に利用可能である。すなわち、クラスが3つ以上存在する場合、それぞれ2つのクラスの組合せを第1と第2のクラスとしてSIMCA解析を行って、分類に有効な変数を求め、その有効な変数を、上述した「Add_D.P.」ボタン操作で逐次に加算して行くことができる。すなわち、まず、最初に選んだ2つのクラスの組合せでSIMCA解析を実施して有効な変数を選択した後、PCAコントロールパネル436上の「Set_D.P.」ボタン操作で、その選択された変数を使用対象に設定する。次に、別の2つのクラスの組合せでSIMCA解析を実施して有効な変数を選択した後、PCAコントロールパネル436上の「ADD_D.P.」ボタン操作で、その選択された変数を、最初に選択された変数に追加する。以後、その他の2つのクラスの組み合わせのそれぞれについて、SIMCA解析を実施して有効な変数を選択した後上記「ADD_D.P.」ボタン操作を繰り返す。これにより、ぞれぞれのクラスの組み合わせで有効な変数が使用対象にセットされることになり、いずれのクラスの組み合わせにおいても有効ではないとされた変数だけが、使用対象から外される。
【0230】
以上、図23〜図39を参照して、本発明の一実施形態にかかるNMRスペクトルの統計処理装置(図1に示した統計処理部116)の構成、機能、動作について説明した。以下では、このNMRスペクトルの統計処理装置を特定の用途に用いる場合の使用例を紹介する。
【0231】
図40は、メタボノミクスにおいてバイオマーカを決定する用途にこの統計処理装置を使用する場合の使用手順を示す。
【0232】
図40に示すように、ステップ520で分析が開始される。この分析では、例えば、人からの採取物に基づいてその人が特定の疾病に罹っているか否かを判断するためのバイオマーカを決定したいという場合、既にその疾病に罹っている人々からの採取物と健康な人々からの採取物とが分析対象のサンプルとして選ばれる。クラス毎に、異なるカラーがプロットカラーとして指定される。まず、ステップ522で、分析対象の多数のサンプルについてPCA解析が行われる。ステップ524で、スコアプロット440などに示された第1主成分(PC1)と第2主成分(PC2)のスコアの分散の和が、ユーザが決めた或る閾値、例えば60%、を超えているかどうかが、ユーザにより判断される。もし、上記スコアの分散の和が閾値60%を超えているならば、ステップ526で、ユーザは、ステップ522で行ったPCA解析で得られたPCAモデルにおいて、サンプルは明快にクラス分けされていると判断する。その場合、ステップ528で、ユーザは、ローディングプロット442、寄与率チャート444、ローディングチャート446及びNMRスペクトルチャート450などを参照しながら、寄与率の高いケミカルシフト値又はそれに対応するNMRスペクトルのピークを選定し、それに基づきバイオマーカを決定する。
【0233】
他方、ステップ524で、上記スコアの分散の和が閾値60%以下であるならば、ユーザは、ステップ522で行ったPCA解析で得られたPCAモデルでは、サンプルは明快にはクラス分けされていないと判断し、次に、ステップ532のSIMCA解析を実行する。SIMCA解析においては、ステップ534で、検査対象のサンプルが第1と第2の2つのクラスに分けられる。例えば、その疾病に罹っている人々から採取されたサンプルが第1のクラスに、健康な人々から採取されたサンプルが第2のクラスに割り当てられる。この2つのクラスについてSIMCA解析が実行され、そのSIMCA解析結果が表示されると、ユーザは、ステップ536で、識別力チャート466上で識別力の閾値を設定して、その閾値以上の識別力を持った変数を選択する。その後、ユーザは、PCAコントロールパネル436の「Set_D.P.」ボタンを操作する。それにより、ステップ522で、選択された変数だけを用いて、同じサンプルに対してPCA解析計算が再度実行される。その結果、前回のPCA解析計算の結果よりも、より明確にサンプルが分散したPCAモデルが得られ、バイオマーカの決定がより容易になる。
【0234】
図41は、テストサンプルの性向を診断する用途に、本発明の一実施形態にかかるNMRスペクトルの統計処理装置(図1に示した統計処理部116)を使用する場合における使用手順の一例を示す。
【0235】
図41に示すように、ステップ540で診断が開始される。この診断は、例えば、或る人々について特定の疾病に罹っているか否かを診断するものである。ステップ542で、2つの基本クラスつまり第1と第2のクラスが設定される。例えば、既に疾病に罹っている人々から採取されたサンプルが第1のクラスに、健康な人々から採取されたサンプルが第2のクラスに割り当てられる。また、ステップ544で、診断対象の人々から採取されたサンプルがテストクラスとして設定される。クラス毎に、異なるカラーがプロットカラーとして指定される。
【0236】
その後、ステップ546で、それら3つのクラスのサンプルを統合した多変量データ行列についてPCA解析が実行される。また、ステップ548で、それら3つのクラスのサンプルについてSIMCA解析が行なわれる。SIMCA解析では、テストクラスのサンプルの第1のクラスと第2のクラスにそれぞれに対する距離が求まり、それがクーマンプロット440上に表現される。スコアププロット440でも、クーマンプロットでも、3つのクラスのサンプルはクラス別の異なるプロットカラーで表示されるので、それらの相関が一目で分かる。
【0237】
ステップ550で、ユーザは、PCA解析結果とSIMCA解析結果を参照することで、テストサンプルである診断対象の人々と、第1クラスである当該疾病に罹っている人々と、第2クラスである健康な人々との間の相関を把握し、そこから、診断対象の人々が当該疾病に罹っているのか、健康であるのか、或は未定なのかなどの判断を下す。
【0238】
以上、本発明の実施形態を説明したが、この実施形態は本発明の説明のための例示にすぎず、本発明の範囲をこの実施形態にのみ限定する趣旨ではない。本発明は、その要旨を逸脱することなく、その他の様々な態様でも実施することができる。例えば、上記の実施形態では、多変量解析結果であるスコアプロット、ローディング及びクーマンプロットを、UI画面上で2本の座標軸からなる二次元図形の形で表示したが、それに代えて又はそれと併用して、3本の座標軸からなる三次元図形として形成し、その三次元図形を任意の視線方向から表示できるようにすることもできる。また、本発明は、メタボノミクスだけでなく、それ以外の用途にも適用することができる。
【図面の簡単な説明】
【0239】
【図1】本発明に従うNMRデータ処理装置の一実施形態の全体的な構成と機能を示すブロック図。
【図2】NMRスペクトル処理110の流れを示すフローチャート。
【図3】NMRスペクトル(実部)と、これに絶対値微分を施した結果であるADスペクトルの一例を示す図。
【図4】位相補正を説明する図。
【図5】ベースライン補正を説明する図。
【図6】最適化バケット積分を用いたデータ縮約処理112の流れを示すフローチャート。
【図7】スペクトル投影処理172の原理を説明する図。
【図8】スペクトル投影処理172の流れを示すフローチャート。
【図9】投影ADスペクトルのバケット積分処理172の原理を説明する図。
【図10】バケット積分処理172の流れを示すフローチャート。
【図11】自動積分ブロック設定に基づくバケットの自動修正処理174の原理を説明する図。
【図12】自動積分ブロック設定に基づくバケットの自動修正処理174の流れを示すフローチャート。
【図13】NMRスペクトル上の3分裂と4分裂のピークの例を示す図。
【図14】指定ピーク情報のデータ構造例を示す図。
【図15】指定ピーク情報に基づくバケット自動修正処理176の流れを示すフローチャート。
【図16】バケットの手動修正処理178の原理を示す図。
【図17】バケットの手動修正処理178の流れを示すフローチャート。
【図18】最適化バケットセットのデータ構造例を示す図。
【図19】多数ADスペクトルの最適化バケット積分処理180の流れを示す。
【図20】本発明に従うNMRデータ処理装置の別の実施形態の全体的な構成と機能を示すブロック図
【図21】最適化バケット積分を用いたデータ縮約処理312の流れを示すフローチャート。
【図22】ヒストグラムの分析処理314の流れを示すフローチャート。
【図23】本発明の一実施形態にかかるNMRスペクトルの統計処理装置、すなわち、図1に示した統計処理部116、の機能的な構成を示すブロック図。
【図24】PCAテーブル350の構成例を示す図。
【図25】図23に示した多変量解析部340のPCA解析部346とSIMCA解析部348並びに表示制御部344の機能をより詳細に示したブロック図。
【図26】PCA解析結果を表示した場合におけるUI346の画面例を示す図。
【図27】SIMCA解析結果を表示した場合におけるUI346の画面例を示す図。
【図28】ファイル名の表示機能を説明するためのスコアプロット440内の部分領域の拡大図。
【図29】ケミカルシフト値の表示機能を説明するためのローディングプロット442内の部分領域の拡大図。
【図30】スコアプロット440上でのプロット選択機能とNMRスペクトル連携機能とを説明するためのスコアプロット440とNMRスペクトルをャート450の例を示す図。
【図31】スコアプロット440上でのプロットの削除機能を説明するためのスコアプロット440の例を示す図。
【図32】ローディングプロット442上でのプロット選択機能とそれに連携する寄与率チャート444とローディングチャート446の表示変更機能とを説明するためのローディングプロット442と寄与率チャート444とローディングチャート446の例を示す図。
【図33】ローディングプロット442上でのプロットの削除機能を説明するためのローディングプロット442の例を示す図。
【図34】寄与率チャート444又はローディングチャート446の拡大機能とNMRスペクトル連携機能とを説明するための寄与率チャート444とローディングチャート446とNMRスペクトルをャート450の例を示す図。
【図35】クーマンプロット460上でのプロット選択機能とNMRスペクトル連携機能とを説明するためのクーマンプロット460とNMRスペクトルをャート450の例を示す図。
【図36】クーマンプロット460上でのプロットの削除機能を説明するためのクーマンプロット460の例を示す図。
【図37】モデリングチャート462、464及び識別力チャート466での変数の選択機能を説明するためのモデリングチャート462、464及び識別力チャート466の例を示す図。
【図38】変数選択後のSIMCA解析計算の再実行を説明するためのUI画面430の例を示す図。
【図39】変数選択後のSIMCA解析計算とPCA解析計算の再実行の手順を示すフローチャート。
【図40】メタボノミクスにおいてバイオマーカを決定する用途に、本発明の一実施形態にかかるNMRスペクトルの統計処理装置(図1に示した統計処理部116)を使用する場合における使用手順の一例を示すフローチャート。
【図41】テストサンプルの性向を診断する用途に、本発明の一実施形態にかかるNMRスペクトルの統計処理装置(図1に示した統計処理部116)を使用する場合における使用手順の一例を示すフローチャート。
【符号の説明】
【0240】
100、300 コンピュータシステム(NMRデータ処理装置)
102 NMR装置
104、304 プロセッサ
106、306 記憶装置
108、308 FIDデータ入力処理
110、310 NMRスペクトル処理
112、312 データ縮約処理
126 絶対値微分処理(ADスペクトル生成処理)
140 NMRスペクトル(実部)
144、Sa、Sb ADスペクトル
171 多数のADスペクトルの投影処理
172 投影ADスペクトルのバケット積分処理
174 自動積分ブロック設定に基づくバケットの自動修正処理
176 指定ピーク情報に基づくバケットの自動修正処理
178 バケットの手動修正処理
180 多数ADスペクトルの最適化バケット積分処理
Sp 投影ADスペクトル
200a−200f、200i−200k バケット
220x、220y 自動設定された積分ブロック
240x、240y 指定ピーク情報に基づくピーク領域
250A−250C 指定ピーク情報セット
280A−280C 最適化バケットセット
340 多変量解析部
342 ユーザ要求入力部
344 表示制御部
346 PCA解析部
348 SIMCA解析部
350 PCAテーブル
354 NMRスペクトルデータ
356 NMRヒストグラムデータ
360 PCAモデル読込・追加・保存部
362 PCA計算部
364 解析データ記憶部
366 解析結果保存部
370 PCAモデル読込・追加・保存部
372 SIMCA計算部
374 PCA解析画面制御部
376 SIMCA解析画面制御部
378 NMRスペクトル連携部
430 UI画面
440 スコアプロット
442 ローディングプロット
444 寄与率チャート
446 ローディングチャート
450 NMRスペクトルチャート
460 クーマンプロット
462、464 モデリング力プロット
466 識別力プロット
【特許請求の範囲】
【請求項1】
複数のサンプルのNMRヒストグラムデータからなる多変量データ行列を入力する多変量データ行列入力手段と、
入力された前記多変量データ行列についてPCA解析計算を行なうPCA解析手段と、
前記PCA解析計算の結果を受けて、複数種のPCA解析結果チャートをユーザインタフェース画面に表示するPCA解析結果表示手段と、
前記ユーザインタフェース画面を用いてユーザ要求を入力するユーザ要求入力手段と、
入力された前記ユーザ要求が1以上のサンプルを選択するものである場合、前記選択されたサンプルのNMRスペクトルのデータを入力して、入力された前記NMRスペクトルをケミカルシフト軸上に表したNMRスペクトルチャートを前記ユーザインタフェース画面に表示するNMRスペクトル連携手段と
を備え、
前記PCA解析結果チャートには少なくとも、複数の主成分に対する前記サンプルのスコアを表したスコアプロットと、変数たる所定の複数のケミカルシフト値の前記複数の主成分に対するローディングを表したローディングプロットと、前記所定の複数のケミカルシフト値の寄与率又はローディングをケミカルシフト軸上に表した寄与率/ローディングチャートとが含まれ、
前記寄与率/ローディングチャートと前記NMRスペクトルチャートとは、それぞれの前記ケミカルシフト軸のスケールが一致するようにして、前記ケミカルシフト軸に直交する方向に並べられて表示されるようになった、
NMRスペクトルの統計処理装置。
【請求項2】
請求項1記載の装置において、
入力された前記ユーザ要求が前記寄与率/ローディングチャートを拡大するものである場合、
前記PCA解析結果表示手段と前記NMRスペクトル連携手段が、前記寄与率/ローディングチャートと前記NMRスペクトルチャートとの間の前記ケミカルシフト軸のスケールの一致が保持されるようにして、前記寄与率/ローディングチャートと前記NMRスペクトルチャートとを拡大して表示する、
NMRスペクトルの統計処理装置。
【請求項3】
請求項1記載の装置において、
入力された前記ユーザ要求が選択された1以上のサンプルを削除するものである場合、
前記PCA解析手段が、前記削除されたサンプル以外のサンプルのNMRヒストグラムデータからなる多変量データ行列についてPCA解析計算を再度実行し、
前記PCA解析結果表示手段が、再度実行された前記PCA解析計算の結果を受けて、前記PCA解析結果チャートを改めて表示する、
NMRスペクトルの統計処理装置。
【請求項4】
請求項1記載の装置において、
入力された前記ユーザ要求が選択された1以上の変数たるケミカルシフト値を削除するものである場合、
前記PCA解析手段が、前記削除されたケミカルシフト値以外のケミカルシフト値を用いてPCA解析計算を再度実行し、
前記PCA解析結果表示手段が、再度実行された前記PCA解析計算の結果を受けて、前記PCA解析結果チャートを改めて表示する、
NMRスペクトルの統計処理装置。
【請求項5】
複数のサンプルのNMRヒストグラムデータからなる多変量データ行列を入力する多変量データ行列入力手段と、
入力された前記多変量データ行列についてPCA解析計算を行なうPCA解析手段と、
前記PCA解析計算の結果を受けて、複数種のPCA解析結果チャートをユーザインタフェース画面に表示するPCA解析結果表示手段と、
前記ユーザインタフェース画面を用いてユーザ要求を入力するユーザ要求入力手段と、
入力された前記ユーザ要求が1以上のサンプルを選択するものである場合、前記選択されたサンプルのNMRスペクトルのデータを入力して、入力された前記NMRスペクトルをケミカルシフト軸上に表したNMRスペクトルチャートを前記ユーザインタフェース画面に表示するNMRスペクトル連携手段と
を備え、
前記PCA解析結果チャートには少なくとも、複数の主成分に対する前記サンプルのスコアを表したスコアプロットと、変数たる所定の複数のケミカルシフト値の前記複数の主成分に対するローディングを表したローディングプロットと、前記所定の複数のケミカルシフト値の寄与率又はローディングをケミカルシフト軸上に表した寄与率/ローディングチャートとが含まれ、
前記寄与率/ローディングチャートと前記NMRスペクトルチャートとは、それぞれの前記ケミカルシフト軸のスケールが一致するようにして、前記ケミカルシフト軸に直交する方向に並べられて表示されるようになった、
NMRスペクトルの統計処理装置として、コンピュータを動作させるコンピュータプログラム。
【請求項6】
複数のクラスに割り当てられた複数のサンプルのNMRヒストグラムデータからなる複数クラスの多変量データ行列を入力する多変量データ行列入力手段と、
入力された前記複数クラスの多変量データ行列についてSIMCA解析計算を行なうSIMCA解析手段と、
前記SIMCA解析計算の結果を受けて、複数種のSIMCA解析結果チャートをユーザインタフェース画面に表示するSIMCA解析結果表示手段と、
前記ユーザインタフェース画面を用いてユーザ要求を入力するユーザ要求入力手段と、
入力された前記ユーザ要求が1以上のサンプルを選択するものである場合、前記選択されたサンプルのNMRスペクトルのデータを入力して、入力された前記NMRスペクトルをケミカルシフト軸上に表したNMRスペクトルチャートを前記ユーザインタフェース画面に表示するNMRスペクトル連携手段と
を備え、
前記SIMCA解析結果チャートには少なくとも、前記複数のクラスに対する前記サンプルの距離を表したクーマンプロットと、変数たる所定の複数のケミカルシフト値のモデリング力又は識別力をケミカルシフト軸上に表したモデリング力/識別力チャートとが含まれ、
前記モデリング力/識別力チャートと前記NMRスペクトルチャートとは、それぞれの前記ケミカルシフト軸のスケールが一致するようにして、前記ケミカルシフト軸に直交する方向に並べられて表示されるようになった、
NMRスペクトルの統計処理装置。
【請求項7】
請求項6記載の装置において、
入力された前記ユーザ要求が前記モデリング力/識別力チャートを拡大するものである場合、
前記SIMCA解析結果表示手段と前記NMRスペクトル連携手段が、前記モデリング力/識別力チャートと前記NMRスペクトルチャートとの間の前記ケミカルシフト軸のスケールの一致が保持されるようにして、前記モデリング力/識別力チャートと前記NMRスペクトルチャートとを拡大して表示する、
NMRスペクトルの統計処理装置。
【請求項8】
請求項6記載の装置において、
入力された前記ユーザ要求が選択された1以上のサンプルを削除するものである場合、
前記SIMCA解析手段が、前記削除されたサンプル以外のサンプルのNMRヒストグラムデータからなる複数クラスの多変量データ行列についてSIMCA解析計算を再度実行し、
前記SIMCA解析結果表示手段が、再度実行された前記SIMCA解析計算の結果を受けて、前記SIMCA解析結果チャートを改めて表示する、
NMRスペクトルの統計処理装置。
【請求項9】
請求項6記載の装置において、
入力された前記ユーザ要求が、所定の閾値より前記識別力又はモデリング力が高い変数たるケミカルシフト値を選択するとともに再計算を要求するものである場合、
前記SIMCA解析手段が、前記選択されたケミカルシフト値だけを用いてSIMCA解析計算を再度実行し、
前記SIMCA解析結果表示手段が、再度実行された前記SIMCA解析計算の結果を受けて、前記SIMCA解析結果チャートを改めて表示する、
NMRスペクトルの統計処理装置。
【請求項10】
複数のクラスに割り当てられた複数のサンプルのNMRヒストグラムデータからなる複数クラスの多変量データ行列を入力する多変量データ行列入力手段と、
入力された前記複数クラスの多変量データ行列についてSIMCA解析計算を行なうSIMCA解析手段と、
前記SIMCA解析計算の結果を受けて、複数種のSIMCA解析結果チャートをユーザインタフェース画面に表示するSIMCA解析結果表示手段と、
前記ユーザインタフェース画面を用いてユーザ要求を入力するユーザ要求入力手段と、
入力された前記ユーザ要求が1以上のサンプルを選択するものである場合、前記選択されたサンプルのNMRスペクトルのデータを入力して、入力された前記NMRスペクトルをケミカルシフト軸上に表したNMRスペクトルチャートを前記ユーザインタフェース画面に表示するNMRスペクトル連携手段と
を備え、
前記SIMCA解析結果チャートには少なくとも、前記複数のクラスに対する前記サンプルの距離を表したクーマンプロットと、変数たる所定の複数のケミカルシフト値のモデリング力又は識別力をケミカルシフト軸上に表したモデリング力/識別力チャートとが含まれ、
前記モデリング力/識別力チャートと前記NMRスペクトルチャートとは、それぞれの前記ケミカルシフト軸のスケールが一致するようにして、前記ケミカルシフト軸に直交する方向に並べられて表示されるようになった、
NMRスペクトルの統計処理装置として、コンピュータを動作させるコンピュータプログラム。
【請求項11】
複数のサンプルのNMRヒストグラムデータからなる多変量データ行列についてPCA解析計算を行なうPCA解析手段と、
前記PCA解析計算の結果を受けて、複数種のPCA解析結果チャートをユーザインタフェース画面に表示するPCA解析結果表示手段と、
複数のクラスに割り当てられた複数のサンプルのNMRヒストグラムデータからなる複数クラスの多変量データ行列を入力する多変量データ行列入力手段と、
入力された前記複数クラスの多変量データ行列についてSIMCA解析計算を行なうSIMCA解析手段と、
前記SIMCA解析計算の結果を受けて、複数種のSIMCA解析結果チャートをユーザインタフェース画面に表示するSIMCA解析結果表示手段と、
前記ユーザインタフェース画面を用いてユーザ要求を入力するユーザ要求入力手段と、
を備え、
前記PCA解析結果チャートには少なくとも、複数の主成分に対する前記サンプルのスコアを表したスコアプロットと、変数たる所定の複数のケミカルシフト値の前記複数の主成分に対するローディングを表したローディングプロットと、前記所定の複数のケミカルシフト値の寄与率又はローディングをケミカルシフト軸上に表した寄与率/ローディングチャートとが含まれ、
前記SIMCA解析結果チャートには少なくとも、前記複数のクラスに対する前記サンプルの距離を表したクーマンプロットと、変数たる所定の複数のケミカルシフト値のモデリング力又は識別力をケミカルシフト軸上に表したモデリング力/識別力チャートとが含まれ、
前記ユーザ要求入力手段により入力された前記ユーザ要求が、前記モデリング力/識別力チャートに表示された前記識別力又はモデリング力が所定閾値より高い変数たるケミカルシフト値を選択するとともにPCA解析計算の再実行を要求するものである場合、
前記PCA解析手段が、前記選択されたケミカルシフト値だけを用いてPCA解析計算を再度実行し、
前記PCA解析結果表示手段が、再度実行された前記PCA解析計算の結果を受けて、前記PCA解析結果チャートを改めて表示する、
NMRスペクトルの統計処理装置。
【請求項12】
請求項11記載の装置において、
前記ユーザ要求入力手段により入力された前記ユーザ要求が、前記モデリング力/識別力チャートに表示された前記識別力又はモデリング力が所定閾値より高い変数たるケミカルシフト値を選択するとともに変数を追加したPCA解析計算の再実行を要求するものである場合、
前記PCA解析手段が、前記選択されたケミカルシフト値を現在の変数たるケミカルシフト値に追加してなる変数を用いてPCA解析計算を再度実行し、
前記PCA解析結果表示手段が、再度実行された前記PCA解析計算の結果を受けて、前記PCA解析結果チャートを改めて表示する、
NMRスペクトルの統計処理装置。
【請求項13】
請求項11記載の装置において、
前記ユーザ要求入力手段により入力された前記ユーザ要求が、前記モデリング力/識別力チャートに表示された前記識別力又はモデリング力が所定閾値より高い変数たるケミカルシフト値を選択するとともにSIMCA解析計算の再実行を要求するものである場合、
前記SIMCA解析手段が、前記選択されたケミカルシフト値だけを用いてPCA解析計算を再度実行し、
前記SIMCA解析結果表示手段が、再度実行された前記SIMCA解析計算の結果を受けて、前記SIMCA解析結果チャートを改めて表示する、
NMRスペクトルの統計処理装置。
【請求項14】
複数のサンプルのNMRヒストグラムデータからなる多変量データ行列についてPCA解析計算を行なうPCA解析手段と、
前記PCA解析計算の結果を受けて、複数種のPCA解析結果チャートをユーザインタフェース画面に表示するPCA解析結果表示手段と、
複数のクラスに割り当てられた複数のサンプルのNMRヒストグラムデータからなる複数クラスの多変量データ行列を入力する多変量データ行列入力手段と、
入力された前記複数クラスの多変量データ行列についてSIMCA解析計算を行なうSIMCA解析手段と、
前記SIMCA解析計算の結果を受けて、複数種のSIMCA解析結果チャートをユーザインタフェース画面に表示するSIMCA解析結果表示手段と、
前記ユーザインタフェース画面を用いてユーザ要求を入力するユーザ要求入力手段と、
を備え、
前記PCA解析結果チャートには少なくとも、複数の主成分に対する前記サンプルのスコアを表したスコアプロットと、変数たる所定の複数のケミカルシフト値の前記複数の主成分に対するローディングを表したローディングプロットと、前記所定の複数のケミカルシフト値の寄与率又はローディングをケミカルシフト軸上に表した寄与率/ローディングチャートとが含まれ、
前記SIMCA解析結果チャートには少なくとも、前記複数のクラスに対する前記サンプルの距離を表したクーマンプロットと、変数たる所定の複数のケミカルシフト値のモデリング力又は識別力をケミカルシフト軸上に表したモデリング力/識別力チャートとが含まれ、
前記ユーザ要求入力手段により入力された前記ユーザ要求が、前記モデリング力/識別力チャートに表示された前記識別力又はモデリング力が所定閾値より高い変数たるケミカルシフト値を選択するとともにPCA解析計算の再実行を要求するものである場合、
前記PCA解析手段が、前記選択されたケミカルシフト値だけを用いてPCA解析計算を再度実行し、
前記PCA解析結果表示手段が、再度実行された前記PCA解析計算の結果を受けて、前記PCA解析結果チャートを改めて表示する、
NMRスペクトルの統計処理装置として、コンピュータを動作させるコンピュータプログラム。
【請求項1】
複数のサンプルのNMRヒストグラムデータからなる多変量データ行列を入力する多変量データ行列入力手段と、
入力された前記多変量データ行列についてPCA解析計算を行なうPCA解析手段と、
前記PCA解析計算の結果を受けて、複数種のPCA解析結果チャートをユーザインタフェース画面に表示するPCA解析結果表示手段と、
前記ユーザインタフェース画面を用いてユーザ要求を入力するユーザ要求入力手段と、
入力された前記ユーザ要求が1以上のサンプルを選択するものである場合、前記選択されたサンプルのNMRスペクトルのデータを入力して、入力された前記NMRスペクトルをケミカルシフト軸上に表したNMRスペクトルチャートを前記ユーザインタフェース画面に表示するNMRスペクトル連携手段と
を備え、
前記PCA解析結果チャートには少なくとも、複数の主成分に対する前記サンプルのスコアを表したスコアプロットと、変数たる所定の複数のケミカルシフト値の前記複数の主成分に対するローディングを表したローディングプロットと、前記所定の複数のケミカルシフト値の寄与率又はローディングをケミカルシフト軸上に表した寄与率/ローディングチャートとが含まれ、
前記寄与率/ローディングチャートと前記NMRスペクトルチャートとは、それぞれの前記ケミカルシフト軸のスケールが一致するようにして、前記ケミカルシフト軸に直交する方向に並べられて表示されるようになった、
NMRスペクトルの統計処理装置。
【請求項2】
請求項1記載の装置において、
入力された前記ユーザ要求が前記寄与率/ローディングチャートを拡大するものである場合、
前記PCA解析結果表示手段と前記NMRスペクトル連携手段が、前記寄与率/ローディングチャートと前記NMRスペクトルチャートとの間の前記ケミカルシフト軸のスケールの一致が保持されるようにして、前記寄与率/ローディングチャートと前記NMRスペクトルチャートとを拡大して表示する、
NMRスペクトルの統計処理装置。
【請求項3】
請求項1記載の装置において、
入力された前記ユーザ要求が選択された1以上のサンプルを削除するものである場合、
前記PCA解析手段が、前記削除されたサンプル以外のサンプルのNMRヒストグラムデータからなる多変量データ行列についてPCA解析計算を再度実行し、
前記PCA解析結果表示手段が、再度実行された前記PCA解析計算の結果を受けて、前記PCA解析結果チャートを改めて表示する、
NMRスペクトルの統計処理装置。
【請求項4】
請求項1記載の装置において、
入力された前記ユーザ要求が選択された1以上の変数たるケミカルシフト値を削除するものである場合、
前記PCA解析手段が、前記削除されたケミカルシフト値以外のケミカルシフト値を用いてPCA解析計算を再度実行し、
前記PCA解析結果表示手段が、再度実行された前記PCA解析計算の結果を受けて、前記PCA解析結果チャートを改めて表示する、
NMRスペクトルの統計処理装置。
【請求項5】
複数のサンプルのNMRヒストグラムデータからなる多変量データ行列を入力する多変量データ行列入力手段と、
入力された前記多変量データ行列についてPCA解析計算を行なうPCA解析手段と、
前記PCA解析計算の結果を受けて、複数種のPCA解析結果チャートをユーザインタフェース画面に表示するPCA解析結果表示手段と、
前記ユーザインタフェース画面を用いてユーザ要求を入力するユーザ要求入力手段と、
入力された前記ユーザ要求が1以上のサンプルを選択するものである場合、前記選択されたサンプルのNMRスペクトルのデータを入力して、入力された前記NMRスペクトルをケミカルシフト軸上に表したNMRスペクトルチャートを前記ユーザインタフェース画面に表示するNMRスペクトル連携手段と
を備え、
前記PCA解析結果チャートには少なくとも、複数の主成分に対する前記サンプルのスコアを表したスコアプロットと、変数たる所定の複数のケミカルシフト値の前記複数の主成分に対するローディングを表したローディングプロットと、前記所定の複数のケミカルシフト値の寄与率又はローディングをケミカルシフト軸上に表した寄与率/ローディングチャートとが含まれ、
前記寄与率/ローディングチャートと前記NMRスペクトルチャートとは、それぞれの前記ケミカルシフト軸のスケールが一致するようにして、前記ケミカルシフト軸に直交する方向に並べられて表示されるようになった、
NMRスペクトルの統計処理装置として、コンピュータを動作させるコンピュータプログラム。
【請求項6】
複数のクラスに割り当てられた複数のサンプルのNMRヒストグラムデータからなる複数クラスの多変量データ行列を入力する多変量データ行列入力手段と、
入力された前記複数クラスの多変量データ行列についてSIMCA解析計算を行なうSIMCA解析手段と、
前記SIMCA解析計算の結果を受けて、複数種のSIMCA解析結果チャートをユーザインタフェース画面に表示するSIMCA解析結果表示手段と、
前記ユーザインタフェース画面を用いてユーザ要求を入力するユーザ要求入力手段と、
入力された前記ユーザ要求が1以上のサンプルを選択するものである場合、前記選択されたサンプルのNMRスペクトルのデータを入力して、入力された前記NMRスペクトルをケミカルシフト軸上に表したNMRスペクトルチャートを前記ユーザインタフェース画面に表示するNMRスペクトル連携手段と
を備え、
前記SIMCA解析結果チャートには少なくとも、前記複数のクラスに対する前記サンプルの距離を表したクーマンプロットと、変数たる所定の複数のケミカルシフト値のモデリング力又は識別力をケミカルシフト軸上に表したモデリング力/識別力チャートとが含まれ、
前記モデリング力/識別力チャートと前記NMRスペクトルチャートとは、それぞれの前記ケミカルシフト軸のスケールが一致するようにして、前記ケミカルシフト軸に直交する方向に並べられて表示されるようになった、
NMRスペクトルの統計処理装置。
【請求項7】
請求項6記載の装置において、
入力された前記ユーザ要求が前記モデリング力/識別力チャートを拡大するものである場合、
前記SIMCA解析結果表示手段と前記NMRスペクトル連携手段が、前記モデリング力/識別力チャートと前記NMRスペクトルチャートとの間の前記ケミカルシフト軸のスケールの一致が保持されるようにして、前記モデリング力/識別力チャートと前記NMRスペクトルチャートとを拡大して表示する、
NMRスペクトルの統計処理装置。
【請求項8】
請求項6記載の装置において、
入力された前記ユーザ要求が選択された1以上のサンプルを削除するものである場合、
前記SIMCA解析手段が、前記削除されたサンプル以外のサンプルのNMRヒストグラムデータからなる複数クラスの多変量データ行列についてSIMCA解析計算を再度実行し、
前記SIMCA解析結果表示手段が、再度実行された前記SIMCA解析計算の結果を受けて、前記SIMCA解析結果チャートを改めて表示する、
NMRスペクトルの統計処理装置。
【請求項9】
請求項6記載の装置において、
入力された前記ユーザ要求が、所定の閾値より前記識別力又はモデリング力が高い変数たるケミカルシフト値を選択するとともに再計算を要求するものである場合、
前記SIMCA解析手段が、前記選択されたケミカルシフト値だけを用いてSIMCA解析計算を再度実行し、
前記SIMCA解析結果表示手段が、再度実行された前記SIMCA解析計算の結果を受けて、前記SIMCA解析結果チャートを改めて表示する、
NMRスペクトルの統計処理装置。
【請求項10】
複数のクラスに割り当てられた複数のサンプルのNMRヒストグラムデータからなる複数クラスの多変量データ行列を入力する多変量データ行列入力手段と、
入力された前記複数クラスの多変量データ行列についてSIMCA解析計算を行なうSIMCA解析手段と、
前記SIMCA解析計算の結果を受けて、複数種のSIMCA解析結果チャートをユーザインタフェース画面に表示するSIMCA解析結果表示手段と、
前記ユーザインタフェース画面を用いてユーザ要求を入力するユーザ要求入力手段と、
入力された前記ユーザ要求が1以上のサンプルを選択するものである場合、前記選択されたサンプルのNMRスペクトルのデータを入力して、入力された前記NMRスペクトルをケミカルシフト軸上に表したNMRスペクトルチャートを前記ユーザインタフェース画面に表示するNMRスペクトル連携手段と
を備え、
前記SIMCA解析結果チャートには少なくとも、前記複数のクラスに対する前記サンプルの距離を表したクーマンプロットと、変数たる所定の複数のケミカルシフト値のモデリング力又は識別力をケミカルシフト軸上に表したモデリング力/識別力チャートとが含まれ、
前記モデリング力/識別力チャートと前記NMRスペクトルチャートとは、それぞれの前記ケミカルシフト軸のスケールが一致するようにして、前記ケミカルシフト軸に直交する方向に並べられて表示されるようになった、
NMRスペクトルの統計処理装置として、コンピュータを動作させるコンピュータプログラム。
【請求項11】
複数のサンプルのNMRヒストグラムデータからなる多変量データ行列についてPCA解析計算を行なうPCA解析手段と、
前記PCA解析計算の結果を受けて、複数種のPCA解析結果チャートをユーザインタフェース画面に表示するPCA解析結果表示手段と、
複数のクラスに割り当てられた複数のサンプルのNMRヒストグラムデータからなる複数クラスの多変量データ行列を入力する多変量データ行列入力手段と、
入力された前記複数クラスの多変量データ行列についてSIMCA解析計算を行なうSIMCA解析手段と、
前記SIMCA解析計算の結果を受けて、複数種のSIMCA解析結果チャートをユーザインタフェース画面に表示するSIMCA解析結果表示手段と、
前記ユーザインタフェース画面を用いてユーザ要求を入力するユーザ要求入力手段と、
を備え、
前記PCA解析結果チャートには少なくとも、複数の主成分に対する前記サンプルのスコアを表したスコアプロットと、変数たる所定の複数のケミカルシフト値の前記複数の主成分に対するローディングを表したローディングプロットと、前記所定の複数のケミカルシフト値の寄与率又はローディングをケミカルシフト軸上に表した寄与率/ローディングチャートとが含まれ、
前記SIMCA解析結果チャートには少なくとも、前記複数のクラスに対する前記サンプルの距離を表したクーマンプロットと、変数たる所定の複数のケミカルシフト値のモデリング力又は識別力をケミカルシフト軸上に表したモデリング力/識別力チャートとが含まれ、
前記ユーザ要求入力手段により入力された前記ユーザ要求が、前記モデリング力/識別力チャートに表示された前記識別力又はモデリング力が所定閾値より高い変数たるケミカルシフト値を選択するとともにPCA解析計算の再実行を要求するものである場合、
前記PCA解析手段が、前記選択されたケミカルシフト値だけを用いてPCA解析計算を再度実行し、
前記PCA解析結果表示手段が、再度実行された前記PCA解析計算の結果を受けて、前記PCA解析結果チャートを改めて表示する、
NMRスペクトルの統計処理装置。
【請求項12】
請求項11記載の装置において、
前記ユーザ要求入力手段により入力された前記ユーザ要求が、前記モデリング力/識別力チャートに表示された前記識別力又はモデリング力が所定閾値より高い変数たるケミカルシフト値を選択するとともに変数を追加したPCA解析計算の再実行を要求するものである場合、
前記PCA解析手段が、前記選択されたケミカルシフト値を現在の変数たるケミカルシフト値に追加してなる変数を用いてPCA解析計算を再度実行し、
前記PCA解析結果表示手段が、再度実行された前記PCA解析計算の結果を受けて、前記PCA解析結果チャートを改めて表示する、
NMRスペクトルの統計処理装置。
【請求項13】
請求項11記載の装置において、
前記ユーザ要求入力手段により入力された前記ユーザ要求が、前記モデリング力/識別力チャートに表示された前記識別力又はモデリング力が所定閾値より高い変数たるケミカルシフト値を選択するとともにSIMCA解析計算の再実行を要求するものである場合、
前記SIMCA解析手段が、前記選択されたケミカルシフト値だけを用いてPCA解析計算を再度実行し、
前記SIMCA解析結果表示手段が、再度実行された前記SIMCA解析計算の結果を受けて、前記SIMCA解析結果チャートを改めて表示する、
NMRスペクトルの統計処理装置。
【請求項14】
複数のサンプルのNMRヒストグラムデータからなる多変量データ行列についてPCA解析計算を行なうPCA解析手段と、
前記PCA解析計算の結果を受けて、複数種のPCA解析結果チャートをユーザインタフェース画面に表示するPCA解析結果表示手段と、
複数のクラスに割り当てられた複数のサンプルのNMRヒストグラムデータからなる複数クラスの多変量データ行列を入力する多変量データ行列入力手段と、
入力された前記複数クラスの多変量データ行列についてSIMCA解析計算を行なうSIMCA解析手段と、
前記SIMCA解析計算の結果を受けて、複数種のSIMCA解析結果チャートをユーザインタフェース画面に表示するSIMCA解析結果表示手段と、
前記ユーザインタフェース画面を用いてユーザ要求を入力するユーザ要求入力手段と、
を備え、
前記PCA解析結果チャートには少なくとも、複数の主成分に対する前記サンプルのスコアを表したスコアプロットと、変数たる所定の複数のケミカルシフト値の前記複数の主成分に対するローディングを表したローディングプロットと、前記所定の複数のケミカルシフト値の寄与率又はローディングをケミカルシフト軸上に表した寄与率/ローディングチャートとが含まれ、
前記SIMCA解析結果チャートには少なくとも、前記複数のクラスに対する前記サンプルの距離を表したクーマンプロットと、変数たる所定の複数のケミカルシフト値のモデリング力又は識別力をケミカルシフト軸上に表したモデリング力/識別力チャートとが含まれ、
前記ユーザ要求入力手段により入力された前記ユーザ要求が、前記モデリング力/識別力チャートに表示された前記識別力又はモデリング力が所定閾値より高い変数たるケミカルシフト値を選択するとともにPCA解析計算の再実行を要求するものである場合、
前記PCA解析手段が、前記選択されたケミカルシフト値だけを用いてPCA解析計算を再度実行し、
前記PCA解析結果表示手段が、再度実行された前記PCA解析計算の結果を受けて、前記PCA解析結果チャートを改めて表示する、
NMRスペクトルの統計処理装置として、コンピュータを動作させるコンピュータプログラム。
【図1】

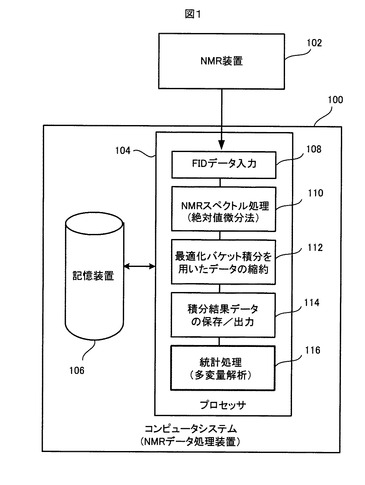
【図2】
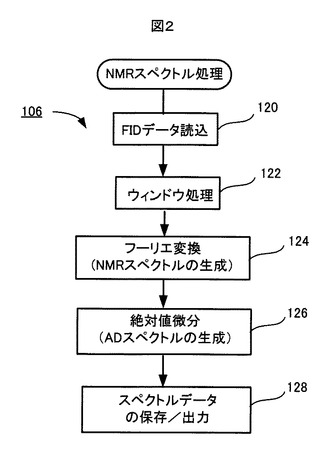
【図3】
【図4】
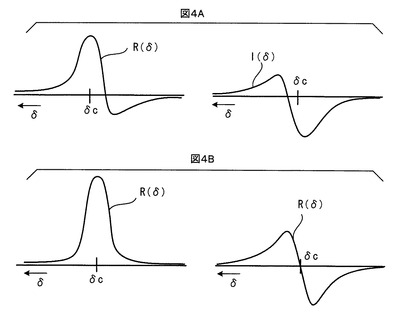
【図5】
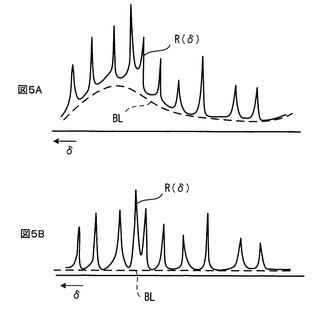
【図6】
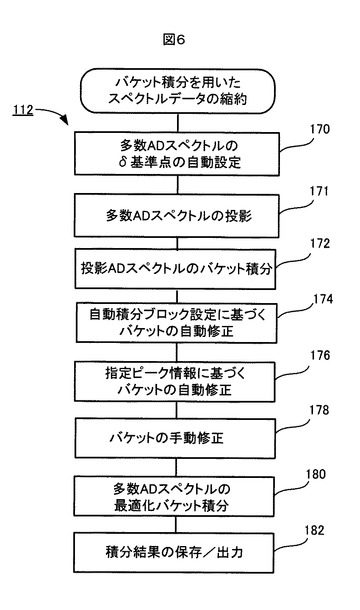
【図7】
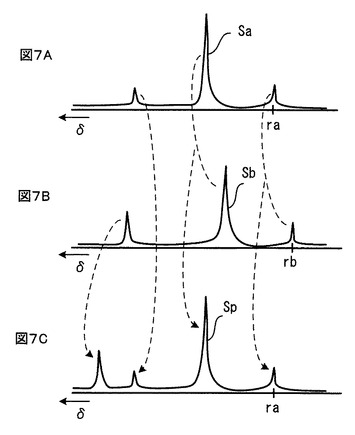
【図8】
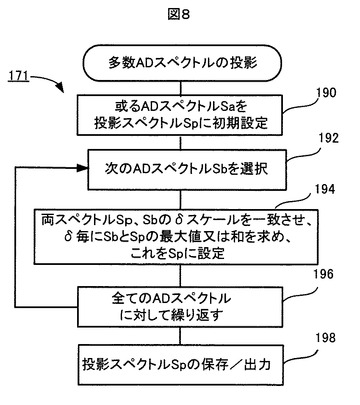
【図9】
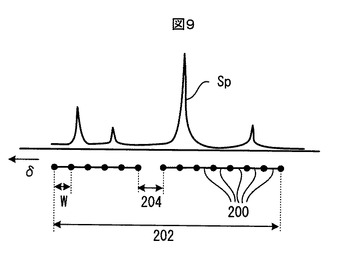
【図10】
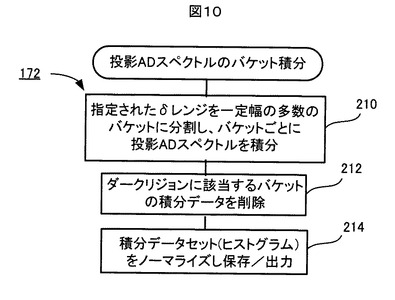
【図11】
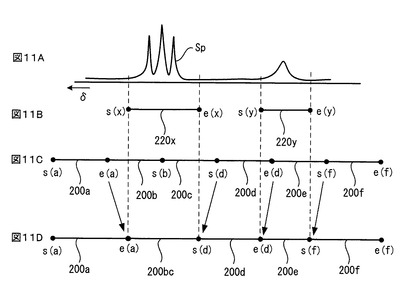
【図12】
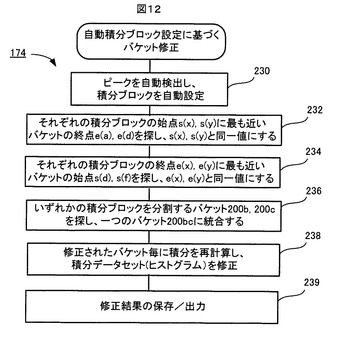
【図13】
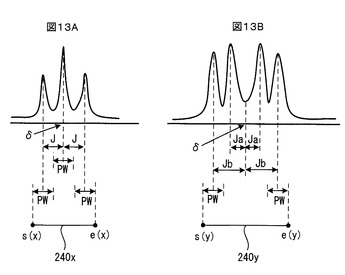
【図14】
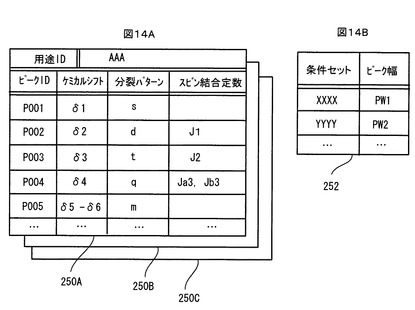
【図15】
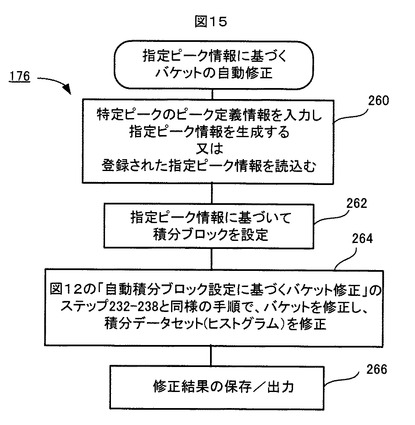
【図16】
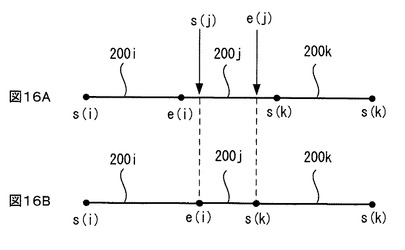
【図17】
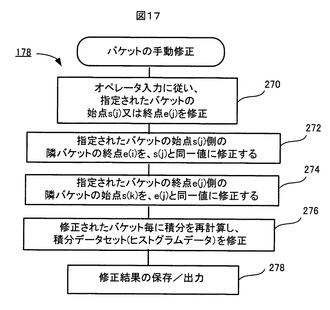
【図18】
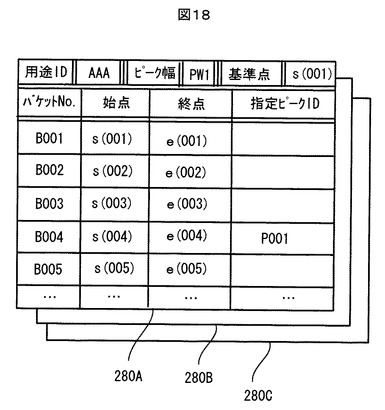
【図19】
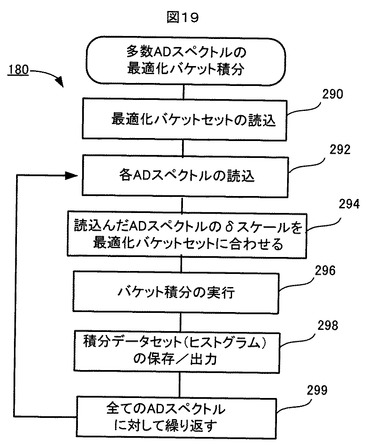
【図20】
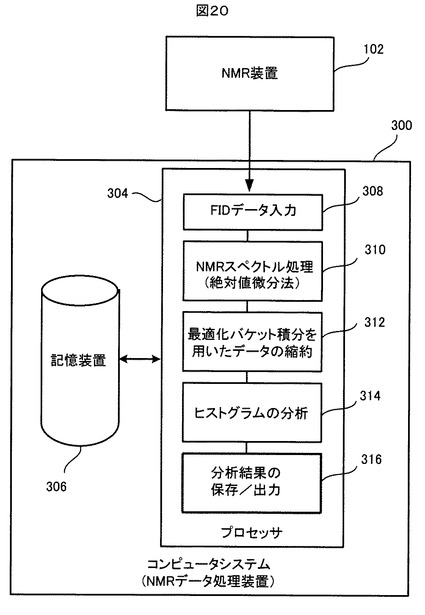
【図21】
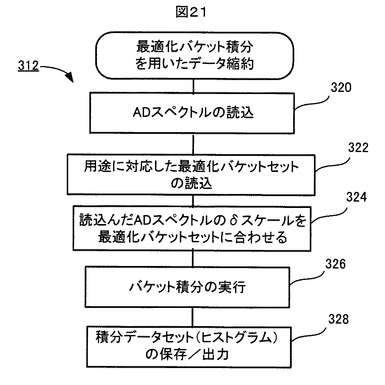
【図22】
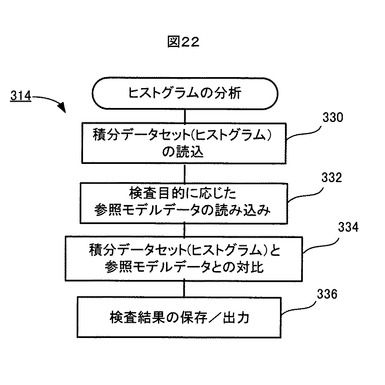
【図23】
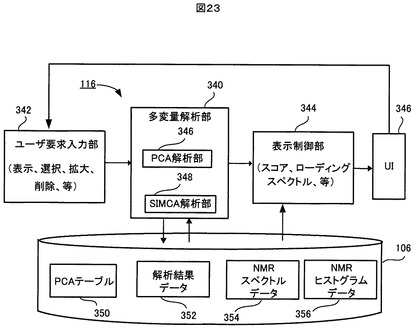
【図24】
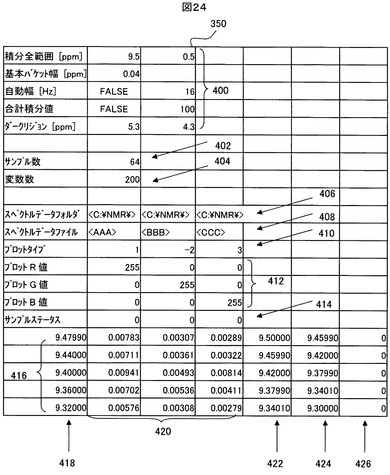
【図25】
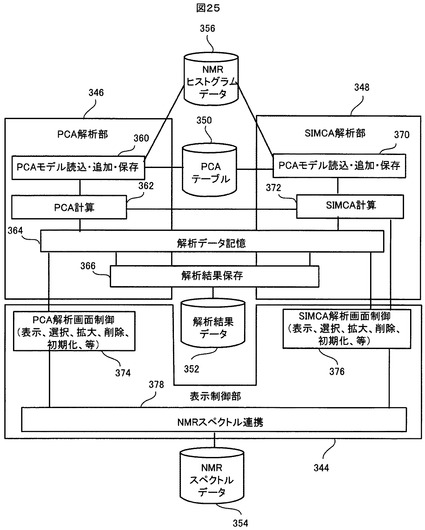
【図26】
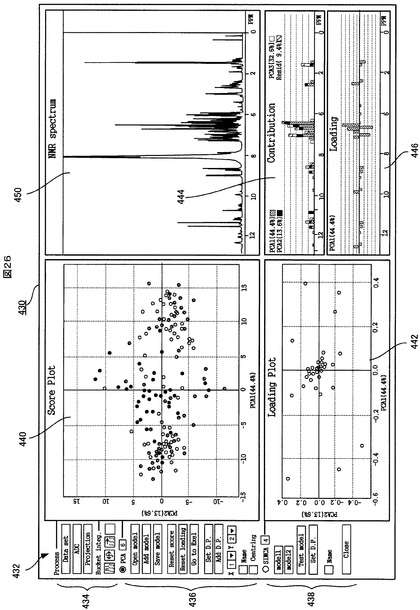
【図27】
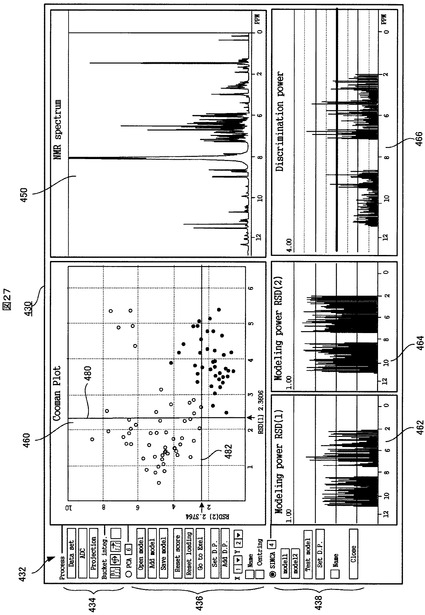
【図28】
【図29】
【図30】
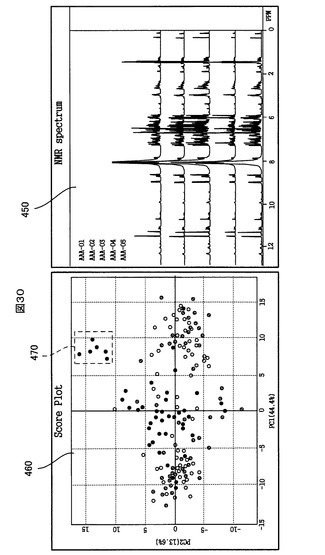
【図31】
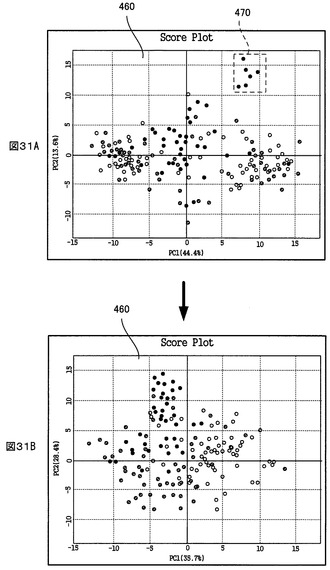
【図32】
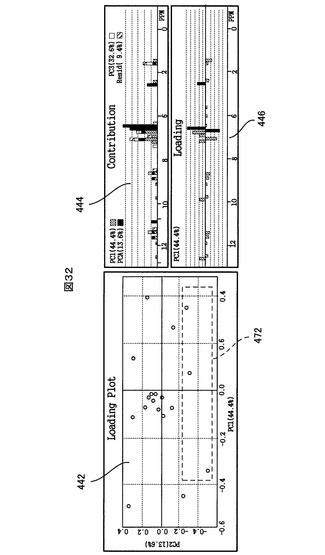
【図33】
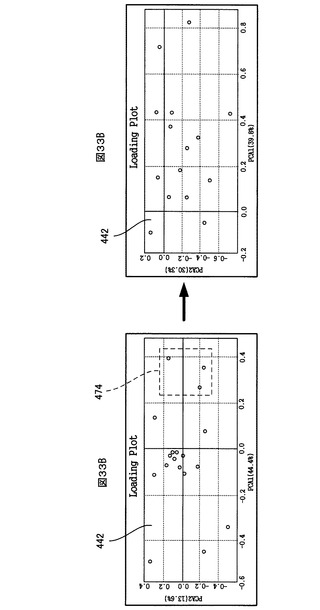
【図34】
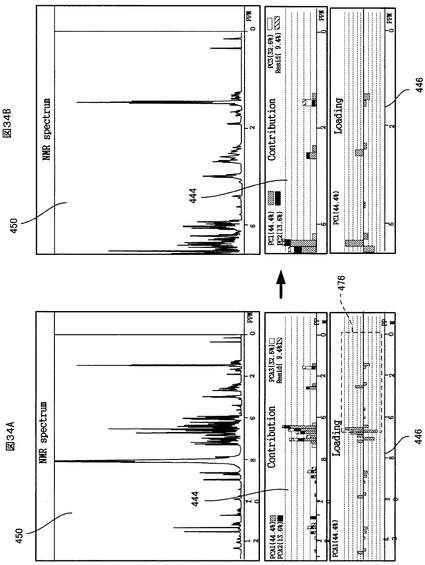
【図35】
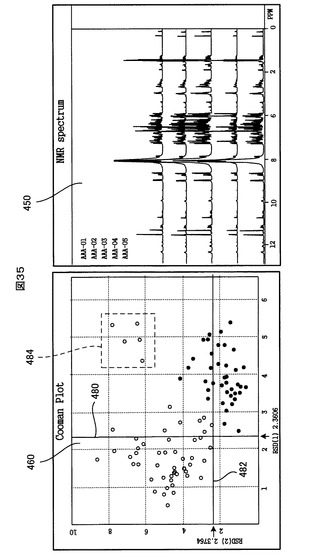
【図36】
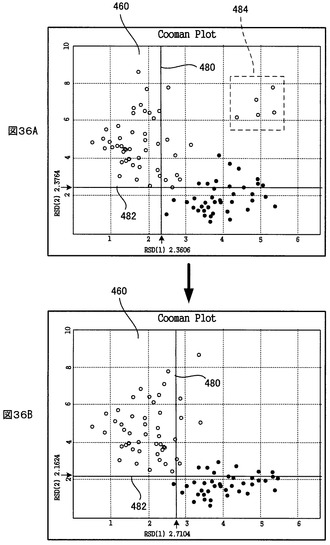
【図37】
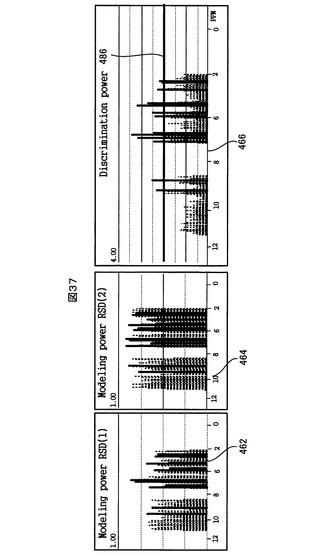
【図38】
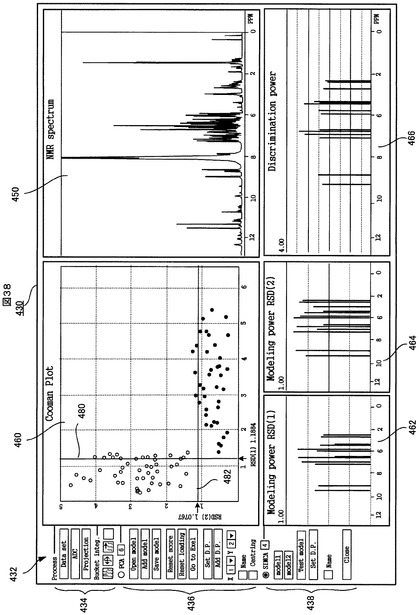
【図39】
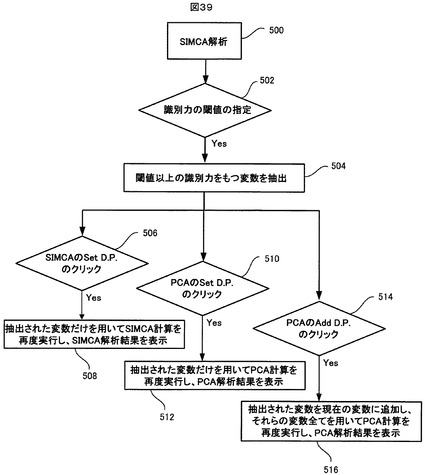
【図40】
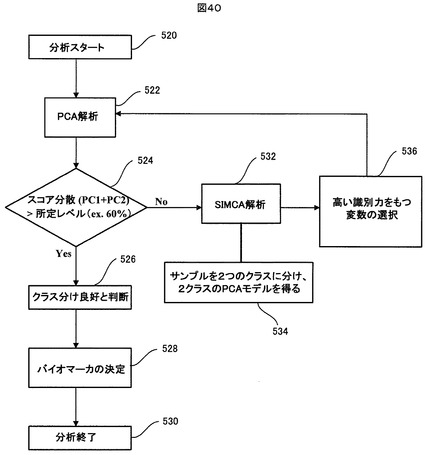
【図41】
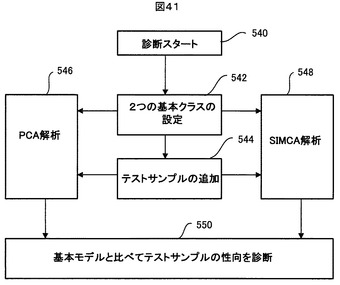
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【図15】
【図16】
【図17】
【図18】
【図19】
【図20】
【図21】
【図22】
【図23】
【図24】
【図25】
【図26】
【図27】
【図28】
【図29】
【図30】
【図31】
【図32】
【図33】
【図34】
【図35】
【図36】
【図37】
【図38】
【図39】
【図40】
【図41】
【公開番号】特開2011−141298(P2011−141298A)
【公開日】平成23年7月21日(2011.7.21)
【国際特許分類】
【出願番号】特願2011−95717(P2011−95717)
【出願日】平成23年4月22日(2011.4.22)
【分割の表示】特願2005−274503(P2005−274503)の分割
【原出願日】平成17年9月21日(2005.9.21)
【出願人】(000004271)日本電子株式会社 (811)
【出願人】(803000034)学校法人日本医科大学 (37)
【公開日】平成23年7月21日(2011.7.21)
【国際特許分類】
【出願日】平成23年4月22日(2011.4.22)
【分割の表示】特願2005−274503(P2005−274503)の分割
【原出願日】平成17年9月21日(2005.9.21)
【出願人】(000004271)日本電子株式会社 (811)
【出願人】(803000034)学校法人日本医科大学 (37)
[ Back to top ]