
独立行政法人情報通信研究機構により出願された特許
61 - 70 / 1,071
立体映像符号化装置およびその方法、ならびに、立体映像復号化装置およびその方法

【課題】立体映像としてある視点の映像とともに奥行値を符号化して伝送する場合、至近距離から遠方までの被写体に対応した奥行値を、限られた語長で精度よく表すことが可能な立体映像符号化装置を提供する。
【解決手段】立体映像符号化装置1は、符号化手段12の前段に、カメラCから被写体Oまでの予め定めた最短距離に対応する奥行値を制限付き奥行値が取り得る最大値となるように予め定めた非線形変換式によって、被写体Oまでの距離に対応した奥行値を制限付き奥行値に変換する奥行変換手段11を備えることを特徴とする。
(もっと読む)
光パケット・光パス統合ネットワークにおける光信号受信ノードシステム及びその構成方法

【課題】 波長帯域の動的割当や強度変動に対応できる受信ノードシステムを提供する。
【解決手段】 波長帯選択器3と,複数の光増幅器4と,複数の波長分波器5と,複数のレシーバ6と,コンピュータ7とを含む光パケットと光パスとを統合した統合ネットワークにおける受信ノードシステム1。波長帯選択器3は,光パケットと光パスとを選別する。光増幅器4は,出力ポート2に接続され,入力光の強度を増幅する。波長分波器5は,波長に応じて入力光を分波する。レシーバ6は,光信号を受信する。コンピュータ7は,統合ネットワークの光パケット用及び光パス用の波長帯域の変動情報を受け取り,受け取った変動情報に基づいて,波長帯選択器3の中で光パケット用と光パス用の波長帯を分離し,光パケット信号及び光パス信号を,光パケット又は光パス用のレシーバと接続された出力ポート2に出力するよう,波長帯選択器3に指令を出す。
(もっと読む)
対訳フレーズ学習装置、フレーズベース統計的機械翻訳装置、対訳フレーズ学習方法、および対訳フレーズ生産方法
【課題】種々の粒度のフレーズペアを学習できなかったり、不適切なフレーズペアを学習したりした。
【解決手段】フレーズテーブルと、フレーズペアの取得を試みて、取得できなかった場合、一の記号を取得する記号取得部と、フレーズペアを取得できなかった場合、当該フレーズペアより小さい2つのフレーズペアを生成する部分フレーズペア生成部と、取得した記号に従って、新しいフレーズペアを生成する、または、2つのフレーズペアを順に繋げた新しいフレーズペアを生成する、または、2つのフレーズペアを逆順に繋げたフレーズペアを生成する、のいずれかを行う新フレーズペア生成部とを具備し、上記の処理を再帰的に行い、フレーズテーブルの各フレーズペアに対するスコアを算出し、当該スコアを各フレーズペアに対応付けて蓄積する対訳フレーズ学習装置により、多数の適切なフレーズペアを学習できる。
(もっと読む)
フォトニック結晶
【課題】 バックグラウンドノイズの発生を防止して高感度に光検出を行うことができるフォトニック結晶を提供する。
【解決手段】 所定の屈折率の媒質で構成される高屈折率部4と、高屈折率部4より屈折率の低い媒質で構成される低屈折率部5とによって周期的構造が形成されたフォトニック結晶1であって、高屈折率部4は、屈折率が二酸化ケイ素より高く、光の吸収スペクトルの吸収端が330nmより短波長側にある純物質または当該純物質を一部に含む化合物を含む低バックグラウンド発光材料を有する。
(もっと読む)
機械翻訳装置、および機械翻訳方法
【課題】従来、精度の高い機械翻訳ができなかった。
【解決手段】係り受け森を構成する各頂点に対して、1以上の各翻訳規則を適用し、頂点ごとに、合致する1以上の翻訳規則を取得する翻訳規則取得部と、係り受け森を構成する各頂点をヘッドとした1以上の超辺であり、各頂点に対応する1以上の翻訳規則の左辺における変数部分に対応する頂点をテイルとした1以上の超辺を取得する超辺取得部と、係り受け森を構成する全頂点と、超辺取得部が取得した1以上の超辺とを有する翻訳森を取得する翻訳森取得部と、翻訳森の各頂点に対応する1以上の各超辺が有する翻訳規則の右辺と単語辞書とを用いて、1以上の翻訳候補を取得する翻訳候補取得部と、1以上の翻訳候補のうちいずれか1以上の翻訳候補である翻訳結果を出力する出力部とを具備する機械翻訳装置により、精度の高い機械翻訳が可能となる。
(もっと読む)
翻訳装置、および翻訳方法
【課題】複数の機械翻訳システムの翻訳結果から精度の高い翻訳結果を得られなかった。
【解決手段】2以上の機械翻訳システムの2以上の翻訳結果を構文解析し、2以上の構文解析木を取得する構文解析部と、2以上の構文解析木からルールの集合を取得するルール取得部と、トップノードが共通するルールのトップノードを共通化して構文森を構成する構文森構成部と、構文森において、トップノードが共通であるルールに対して、スコアを算出するスコア算出部と、トップノードが共通であるルールのうち、スコア算出部が算出したスコアが最も高い一のルールに対応するサブツリーを選択し構文解析木を取得するルール選択部と、構文解析木から翻訳文を取得する翻訳文取得部と、翻訳文を出力する翻訳文出力部とを具備する翻訳装置により、複数の機械翻訳システムの翻訳結から精度の高い翻訳結果を得ることができる。
(もっと読む)
パターン分類の学習装置
【課題】LGM‐MCE学習によるパターン分類器の学習装置において、分類器の汎化能力を高くできる装置を提供する。
【解決手段】クラスCyに属する標本xが誤分類される度合いを測る誤分類尺度値Dy(x;Λ)を式(1)で定義する。ψ>0、gy(x;Λ)はxがCyに属する度合いの判別関数。学習装置は、Cyに属する標本の誤分類尺度値を求め、それらを生成した真の確率分布を、各誤分類尺度値を中心とする窓幅hyのParzen分布として、hyの関数で分布の尤度を評価して交差確認型最尤推定により推定する。最尤分布を与えるhyに対し、αy=4/((2π)1/2*hy)により損失平滑度の最適値αyを算出し、αyの関数である経験的平均損失を最小化するように学習パラメータΛを調整する。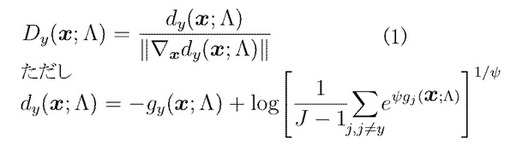 (もっと読む)
(もっと読む)
コグニティブ無線通信システム
【課題】セカンダリシステムが増加した場合においても、通信干渉を効果的に防止する。
【解決手段】プライマリシステム10における無線通信を妨害しないようにコーディネータ22と一以上のデバイス21間で無線通信を行うセカンダリシステム20と、プライマリシステム10及び/又は他のセカンダリシステム20の属性データが記録されるデータベースと5を備え、コーディネータ22は、デバイス21との間で無線信号を送受信するための送受信部32と、データベース5に対して自己の属性データを記録するとともに、通信開始時にはデータベース5にアクセスし、プライマリシステム10及び/又は他のセカンダリシステム20の属性データを取得し、その取得した属性データに基づいてデバイス21との間で行う通信チャネル又は通信時間を決定する制御部31とを備える。
(もっと読む)
敬語誤用判定プログラム、及び敬語誤用判定装置
【課題】入力された日本語の発話文に対し、敬語の誤用の有無を柔軟に判定できるプログラム及び装置を提供する。
【解決手段】発話文テキスト、発話文に関わる人物と人物間の社会的関係を示す人間関係ラベル、難易度の入力を受け付け、発話文テキストに対する形態素解析や構文解析を行い、発話文中の主語及び補語、文末表現、述語について敬語特徴量として数値化するとともに、発話文に関わる人数に依らず汎化した規範ルールを参照して発話文中の主語及び補語と人間関係ラベルに該当する規範ルールを特定し、各規範ルールについて現代の一般の人々の敬語規範意識に基づく正誤の妥当性を数値化した妥当性の程度の値と難易度とを比較することで、判定に用いるべき規範ルールを定め、その規範ルールで正しいとされる敬語特徴量と発話文テキストに用いられた敬語特徴量とを対比することで、発話文テキスト中の敬語の正誤判定を実行できるようにした。
(もっと読む)
音響モデル学習装置、および音響モデル学習方法
【課題】マイナーな言語において学習データが十分ではない音響モデルを用いた音声認識の精度は低かった。
【解決手段】第一言語の第一音響モデルと、第二言語の第二音響モデルと、第一言語の第一発音辞書と、第二言語の第二音素関連情報を選択し、第一単語発音情報が有する音素識別子列に含まれる音素識別子を選択された第二音素関連情報が有する音素識別子に置換して、仮第一単語発音情報を構成し、第一音響モデルと第一発音辞書に仮第一単語発音情報を加えた仮第一発音辞書とを用いて、音声認識処理を行い1以上の認識結果を取得し、仮第一単語発音情報の置換数情報を取得し、置換数情報が大きい場合に第二言語の音素情報と置換された第一単語発音情報の音素識別子とを対応付けた新第一音素関連情報を構成し、新第一音素関連情報を第一音響モデルに蓄積する音響モデル学習装置により、数多くの言語の音響モデルを効率よく構築できる。
(もっと読む)
61 - 70 / 1,071
[ Back to top ]