
グーグル・インクにより出願された特許
1 - 10 / 25
双対分解を用いた組み合わせモデル型アライナ
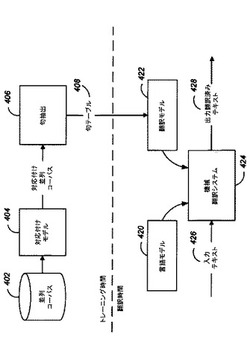
【課題】機械翻訳において用いる、並列翻訳文中の単語を対応付けるための方法、システムおよび装置。
【解決手段】トレーニング時間中に動作するコンポーネントを備え、コンポーネントは、一対の言語の、正しく翻訳された文対よりなる並列コーパス402を含む。他のトレーニング時間コンポーネントは、対応付けモデルコンポーネント404であり、並列コーパス402から文対を受信し、対応付けされた並列コーパスを生成する。該並列コーパスは、句抽出コンポーネント406により受信され、句抽出器は、翻訳された句および対応するスコアのスニペットを含む、句テーブル408を生成する。翻訳時間コンポーネントは、句テーブル408のデータから生成される翻訳モデル422を含み、言語モデル420、および、言語モデル420や翻訳モデル422を用い、入力テキスト426から翻訳済み出力テキスト428を生成する機械翻訳コンポーネント424を含む。
(もっと読む)
母集団情報を用いて探索ランク付けを改善する方法とシステム

【課題】探索問い合わせの探索ランク付けを、その探索問い合わせに関する問い合わせと関連するデータを用いることによって改善するシステムと方法を提供する。
【解決手段】探索問い合わせが受信され、この探索問い合わせと関連する母集団が決定され、その探索問い合わせと関連する(Webページなどの)項目が決定されて、その母集団と関連するデータに少なくとも部分的に基づいたその項目のランク付け得点が決定される。
(もっと読む)
ドキュメントをスコア付けする方法
【課題】ユーザーのサーチクエリに応答して、検索エンジンによりもっとも関連性の高い検索結果すなわち品質の高い検索結果をユーザーへ提供する。
【解決手段】ドキュメントを特定し且つドキュメントに関連付けられた一つ以上のヒストリデータを獲得し、一つ以上のヒストリデータの少なくとも一部に基づいてドキュメントについてのスコアを生成することで、もっとも関連性の高い検索結果すなわち品質の高い検索結果をユーザーへ提供する。
(もっと読む)
集計されたニュースコンテンツを個人化するためのシステムおよび方法
【課題】ニュース集計サービスのユーザに関連付けられたニュースドキュメントをカスタマイズするシステムを提供する。
【解決手段】本発明におけるシステムは、ニュースコンテンツおよびリモートニュース集計サーバ(120)を格納する多数のニュースソースサーバ(130)を含む。このニュース集計サーバ(120)は、ユーザから受信した1つ以上の個人化されたサーチクエリに基づいてカスタマイズされたニュースドキュメントを作成する。ニュース集計サーバ(120)は、多数のニュースソースサーバ(130)からニュースコンテンツを取り出し、ニュースコンテンツを集計し、1つ以上の個人化されたサーチクエリに基づいて集計されたニュースコンテンツを検索する。ニュース集計サーバ(120)は、この検索結果に基づいてカスタマイズされたニュースドキュメントに対し選択されたニュースコンテンツを提供する。
(もっと読む)
検索結果に対し選好国偏向をもたらすシステムおよび方法
【課題】検索結果について選好国での順序付けを提供するシステムおよび方法を提供する。
【解決手段】複数の検索結果国において提供される、潜在的に取出し可能な情報を表す検索問合せを受信する(81)。検索可能なデータレポジトリに保持されている情報特性に対して検索問合せを評価することによって検索(82)が実行される。作成された検索結果に適用可能な少なくとも一つの選好国が、実行された検索に応答して動的に決定される(85)。検索結果のうちの少なくともいくつかは、少なくとも一つの選好国を考慮して順序付けされる(86)。
(もっと読む)
ユーザ情報及びコンテキストに基づいて自動的に生成されるリンクを用いる高品質なドキュメント・ブラウジング
【課題】自動的に生成される関連情報へのリンクを閲覧者に提供することで、ドキュメント・ブラウジングの品質を高めるための改良された技術を開発することが望まれる。
【解決手段】ユーザに読まれるドキュメントといったオリジナル・ドキュメントに関連する追加ドキュメントは、自動的に探し出され、且つユーザの個人情報に潜在的に関連する。追加ドキュメントは、ユーザの個人情報および読まれるドキュメントのコンテンツ情報を含む記述情報に基づき探し出されてもよい。追加ドキュメントまたは追加ドキュメントへのリンクは、読まれるドキュメントに含まれてもよい。いくつかの実施態様において、追加ドキュメントは、インリンク・リンク(in−link link)またはテキスト断片(text snippet)を経て、読まれるドキュメントのインラインに提供されてもよい。ユーザは、このように、読まれるオリジナル・ドキュメントに関連する追加情報を効率よく提供され得る。
(もっと読む)
ライティングシステム及び言語の検出
ライティングシステム及び言語を検出するための方法、システム、及びコンピュータプログラム製品を含む装置が開示される。一実施例では、方法が提供される。この方法は、テキストを受け入れ、かなりの量が第1言語を表現するテキストの第1セグメントを検出し、かなりの量が第2言語を表現するテキストの第2セグメントを検出し、テキスト中に含まれるサイズxの各nグラムに対してスコアを確認し、スコアの変化に基づき、テキストにおいて第1言語から第2言語への遷移を識別するエッジを検出することを含む。  (もっと読む)
(もっと読む)
並列処理を用いた復号システムおよび方法
【課題】少なくとも第1の符号化方式を用いて、圧縮されている複数のパーティションを含む符号化動画データストリームを復号する方法を提供する。
【解決手段】符号化動画データストリームを復号する方法を開示する。動画ストリームは、ロスレス符号化を用いて、圧縮されているパーティションを含む。各パーティションは、例えば、イントラフレーム符号化またはインターフレーム符号化を用いて符号化されている列も含む。復号処理時、1つのパーティションのエントロピー復号出力の少なくとも1つのパーティションを、エントロピー復号と他方のイントラ/インターフレーム復号への入力として用いることができるように、フレーム中の隣接列を含むパーティションが、オフセットにより復号されることを除き、2つ以上のパーティションが、2つ以上のプロセッサで並列にエントロピー復号される。
(もっと読む)
適応セグメンテーションを用いた動画符号化システムおよび方法
【課題】ループフィルタを用いた動画符号化を提供する。
【解決手段】圧縮動画情報を復号する方法を開示する。動画情報は、各々複数のブロックを有する複数のフレームを含むことができる。この方法は、フレーム中のブロックを4つのセグメント識別子に関連付けるセグメントマップを動画情報から読み出すことを含む。各セグメント識別子は、量子化パラメータ、ループフィルタ種別、ループフィルタ強度、および部分画素補間フィルタなどの、1つ以上のセグメントパラメータに関連している。関連セグメントパラメータを用いて、各セグメントのブロックが復号される。後続フレームによって上書きされない限り、セグメントパラメータは、以下のフレームに対して存続できる。フレームは、ビット抑制セグメンテーションを含み、この場合、ディフォルトのパラメータは、フレームの全ブロックに対して用いられる。
(もっと読む)
適応ループフィルタを用いた動画符号化システムおよび方法
【課題】圧縮動画情報フレームから再構成された隣接ブロック間境界でのブロッキング偽像を低減させる適応ループフィルタを用いた動画符号化システムを提供する。
【解決手段】ここで開示したのは、圧縮動画情報フレームから再構成した隣接ブロック間境界で、ブロッキングアーチファクトを低減する方法である。この動画情報は、少なくとも1つブロックに関する予測ステージパラメータを含む。また、この方法は、予測ステージパラメータに基づいて、少なくとも1つのブロックを再構成することと、再構成ブロックから残差エラー属性を算出することと、基準フィルタ強度と少なくとも1つの増加値に基づいて、フィルタ強度値を計算することとを含み、予測段階パラメータとブロックに関連した残差属性の少なくとも1つに基づき、複数のプリセット値から増加値を選択し、選択したフィルタ強度値を用いて、少なくとも1つのブロックに隣接する境界をフィルタ処理する。
(もっと読む)
1 - 10 / 25
[ Back to top ]