
合同会社シンタックスにより出願された特許
1 - 10 / 10
文字検索装置、文字検索システム、文字検索方法、入力端末装置、検索サーバおよびプログラム
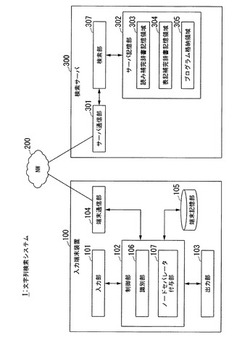
【課題】複数の入力フィールドに対して文字入力する場合であっても、効率的な文字入力を行うことができる。
【解決手段】入力端末装置が、文字入力領域の入力内容を検出し、文字入力領域を識別する識別部と、識別部によって識別された文字入力領域を表すノードセパレータと、検出された入力内容とを関連付けた検索キーを生成するノードセパレータ付与部とを備え、検索サーバが、互いに係り受け関係にある単語を、文字入力領域と対応付けられたノードとして木構造に構成した辞書データを利用して、入力端末装置から受信する検索キーのノードセパレータに基づき、検索キーに含まれる入力内容の文字入力領域に対応する辞書データのノードを検出し、ノードとしての単語を変換候補を、入力端末装置に表示させる
(もっと読む)
文字列入力装置、文字列入力方法、および、プログラム

【課題】日本語とアルファベットとが入り混じった文章をより効率的に入力可能とする。
【解決手段】制御部100は、変換処理が完了した確定部文字列と変換処理が完了する前の未確定ひらがな部文字列とを分離し、未確定部の半角カタカナを全角カタカナに、全角英数字を半角英数字に変換した第1の検索キー、第1の検索キーの全角カタカナをひらがなに変換した第2の検索キー、さらに第2の検索キーの全てのひらがなを、ひらがな変換テーブルに基づいて、ローマ字に変換した第3の検索キーからなる未確定部キーリストを生成する。さらに、前回確定部と未確定部キーリストとを結合して検索キーリストを生成し、該検索キーと読み補完辞書データと綴り補完辞書データとに基づいて、変換候補を抽出する。
(もっと読む)
文字列入力装置、文字列入力方法、および、プログラム
【課題】より効率的な文字列入力を行うことができる文字列入力装置を提供する。
【解決手段】記憶部400は、入力端末1が用いられる業務内容などに基づく入力内容に応じて用意された辞書データとして、入力される読みに基づいて構成された「読み補完辞書データ」と、変換後の綴りに基づいて構成された「綴り補完データ」とを対応付けて保持している。それぞれのデータは、互いに係り受け関係にある単語をノードとして木構造に構成される。制御部100は変換処理が完了した確定部文字列またはその先頭の文字を削除した末尾部と、変換処理が完了する前の未確定ひらがな部文字列とが結合された検索キーを生成し、該検索キーと読み補完辞書データと綴り補完辞書データとに基づいて、変換候補を抽出する。
(もっと読む)
情報検索装置、情報検索方法、端末装置、およびプログラム
【課題】文の意味合いを重視した検索結果を用いて、分かりやすい表示を効率よく実現すること。
【解決手段】前記マッチプロファイル情報に基づき、関連付けられている前記マッチング条件に応じた前記検索キー文と前記マッチ辞書情報との照合を行い、照合の結果として、前記マッチング条件を満たす単語が、前記マッチ辞書情報の文中に出現する位置を表す位置情報を得る検索処理部と、前記検索処理部によって得られた照合の結果に基づき、前記マッチング条件を満たす単語を含む文と前記位置情報とが関連付けられている検索結果情報を、端末装置に送信する通信部とを備える。
(もっと読む)
文字列入力装置及び文字列入力方法
【課題】効率的に作成可能な辞書データを用い、複数の単語列からなる使用頻度の高い表現を簡易な操作によって入力する。
【解決手段】記憶部400は、入力端末1が用いられる業務内容などに基づいて、入力内容に応じて用意された辞書データとして、入力される読みに基づいて構成された「読み補完辞書データ」と、変換後の綴りに基づいて構成された「綴り補完辞書データ」とを対応付けて保持している。それぞれのデータは、互いに係り受け関係にある単語を、ノードとして木構造に構成される。制御部100は、入力された文字列から得られる検索キーを用いて、読み補完辞書データ、綴り補完辞書データを検索し、変換候補となるノード列を綴り補完辞書データから読み出す。変換候補を読み出すとき、制御部100は、補完辞書データにおいて、同一の補完単位番号が付与されているノード列については、1つのノード列としてまとめて読み出す。
(もっと読む)
情報検索装置、情報検索方法、辞書作成装置、およびプログラム
【課題】一つの辞書データを利用して異なるマッチング条件に基づく検索ができる。
【解決手段】前記マッチプロファイル情報に基づき、関連付けられている前記マッチング条件に従って、前記検索キー文と前記マッチ辞書情報との照合を行い、照合の結果、前記マッチング条件を満たす前記文に対して、当該マッチプロファイル情報に関連付けられている前記評価基準に従って、前記検索キー文と前記マッチ辞書情報との照合の度合いを表すスコアを算出する検索処理部を備える。
(もっと読む)
文字列入力装置、文字列入力方法、およびプログラム
【課題】より効率的な文字列入力を行うことができる文字列入力装置を提供する。
【解決手段】記憶部400は、入力端末1が用いられる業務内容などに基づいて、入力内容に応じて用意された辞書データとして、入力される読みに基づいて構成された「読み補完辞書データ」と、変換後の綴りに基づいて構成された「綴り補完辞書データ」とを対応付けて保持している。それぞれのデータは、互いに係り受け関係にある単語を、ノードとして木構造に構成される。制御部100は、変換処理が完了した確定部文字列と変換処理が完了する前の未確定ひらがな部文字列とが連結された検索キーを生成し、該検索キーと読み補完辞書データと綴り補完辞書データとに基づいて、変換候補を抽出する係り受け機能を、係り受け機能を機能させるか否かを示す係り受け識別子に基づいて機能させる。
(もっと読む)
文字列入力装置、文字列入力方法、およびプログラム
【課題】ユーザの期待する半角文字を含んだ正規表現を変換候補語として提示できる文字列入力装置、文字列入力方法、および、プログラムを提供する。
【解決手段】文字列入力装置が、互いに係り受け関係にある単語を、ノードとして木構造に構成した読み補完辞書データを記憶する記憶部400と、変換処理前と後の単語をノードとして対応付けて、木構造と合致した木構造に構成した綴り補完辞書データを記憶する記憶部400と、入力エリアから文字列を取得して検索キーを生成する検索キー生成部120と、検索キー生成部120により生成された検索キーと、記憶部400に記憶されている読み補完辞書データと、記憶部400に記憶されている綴り補完辞書データとに基づいて、変換候補を抽出する変換候補抽出部130と、を備える。
(もっと読む)
候補語抽出装置、候補語抽出方法及び候補語抽出プログラム
【課題】入力語に応じてより多くの候補語を抽出し、過去に入力された文章と同様の文章を完成させる際により有用な候補語を抽出して表示する。
【解決手段】候補語抽出装置が、辞書データの基である文に含まれる複数の語の係り受け関係に基づいて、係る語を子ノード、受ける語を親ノードとする親子関係が解析され、文字列に含まれる各語をノードとした親子関係が構文木によって表されたノード情報を生成し、ノード情報に含まれるノードのうち、子ノードを入力語とし、子ノードに対応する親ノードを候補語として対応付けて辞書データ記憶部に記憶し、同一の親ノードに対応する子ノードの組み合わせを抽出し、抽出した子ノードの一方を入力語とし、他方を候補語として対応付けて辞書データ記憶部に記憶し、ユーザから入力された入力語に対応する候補語を辞書データ記憶部から抽出し、表示部に表示させる。
(もっと読む)
端末装置
【課題】文の意味合いを重視した検索結果を用いて、分かりやすい表示を効率よく実現すること。
【解決手段】前記マッチプロファイル情報に基づき、関連付けられている前記マッチング条件に応じた前記検索キー文と前記マッチ辞書情報との照合を行い、照合の結果として、前記マッチング条件を満たす単語が、前記マッチ辞書情報の文中に出現する位置を表す位置情報を得る検索処理部と、前記検索処理部によって得られた照合の結果に基づき、前記マッチング条件を満たす単語を含む文と前記位置情報とが関連付けられている検索結果情報を、端末装置に送信する通信部とを備える。
(もっと読む)
1 - 10 / 10
[ Back to top ]