
株式会社サン・フレアにより出願された特許
1 - 3 / 3
中継サーバ
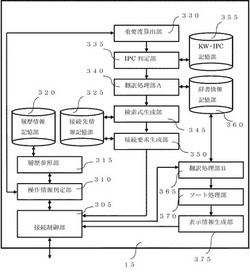
【課題】現場の研究開発者が自ら英語以外の言語を用いた特許調査を接続先を意識せずに容易に行うことが可能な特許検索システムのための中継サーバを提供する。
【解決手段】検討対象特許データから重要語を抽出するために検討対象特許データの各単語の重要度を算出する重要度算出手段(330)と、前記重要度に基づいて抽出された重要語を用いて前記検討対象特許データの特許分類を判定する第1の特許分類判定手段(335)と、前記判定した特許分類を用いて専門辞書を特定し、該特定した専門辞書を用いて前記重要語を所望の言語に翻訳する第1の翻訳処理手段(340)と、前記所望の言語に翻訳された重要語を用いて検索式を生成する第1の検索式生成手段(345)と、前記所望の言語に応じた接続先である特許データベースサーバに対して、前記接続先に応じた接続要求を生成する第1の接続要求生成手段(350)とを備えた。
(もっと読む)
テンプレート−テンプレート構造に基づく対話式学習システム
本発明の学習システムにはテンプレート・オートマトンの概念が導入されており、「正しい」回答と「誤った」回答からなる多くの「多様な学習者の予想される例」を収集し、効率的なエラー診断エンジンとしてHCS(最重共通文字列)またはLCS(最長共通文字列)アルゴリズム等の代表的なNLP技術を言語学習システムに用い、テンプレート内に埋め込まれたこれらの例を学習者の回答の診断解析のために用いる。この診断は、テンプレートデータベースの膨大な数の候補パスの中から学習者の入力文に最も近似度の高いパスを選択することによって行われる。言語指向インテリジェント学習システムに使用される時間の掛かるオーサリング・タスクの自動化と簡素化が実現される。  (もっと読む)
(もっと読む)
テンプレート・オートマトンとレイテント・セマンティック・インデックス原理に基づく新しいコンピュータ支援メモリ翻訳スキーム
テンプレート・オートマトン(130)のいわゆる次元縮小機能とLSI(レイテント・セマンティック・インデックス)技法を別々に用いて、近くまで絞り込んだ翻訳候補からターゲット言語における最適な訳文の獲得(図1)を容易にする新しくて、さらに効率のよい翻訳アルゴリズム(図2)。テンプレート・オートマトンとLSI原理はどちらも、それぞれの独自の検索空間縮約機能(130)を用いてターゲット言語のデータベースの多くの文例(図1)から効率よい解決策の絞り込み空間(130)の効率よいプロセスを実施する上で重要な役割を担う。完全に実用可能なシステムに発展すると、熟練翻訳者ではなく熟練編集者でも翻訳メモリ・システムをチューニングすることが可能となり(図1)、システムを利用することができる熟練者の範囲が著しく広くなる。  (もっと読む)
(もっと読む)
1 - 3 / 3
[ Back to top ]