
Fターム[5B013AA02]の内容
先行制御 (1,991) | 先行制御 (774) | 命令先取、命令バッファ (334) | オペランド先取、オペランドバッファ (58)
Fターム[5B013AA02]に分類される特許
1 - 20 / 58
プロセッサ、及びプロセッサの制御方法
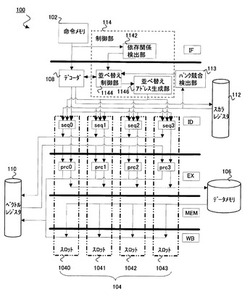
【課題】複数のパイプラインを有するプロセッサにおいて、処理効率を低下させることなくバンク競合を回避する。
【解決手段】メモリの複数のバンクに第1のバンクアクセス順序でアクセスする第1の処理部と、前記第1の処理部のアクセスの開始に続いて第2のバンクアクセス順序で前記複数のバンクにアクセスを開始する第2の処理部と、前記第1の処理部及び前記第2の処理部による前記複数のバンクへのアクセスが競合する場合に、前記第2のバンクアクセス順序を前記競合が生じない第3のバンクアクセス順序に並べ替えて前記第2の処理部を前記複数のバンクにアクセスさせる制御部とをプロセッサに備えることで、処理効率を低下させることなくバンク競合を回避できる。
(もっと読む)
ベクトル演算処理装置、ベクトル演算処理方法およびベクトル演算処理プログラム

【課題】キャッシュメモリと主記憶装置との間の負荷を軽減し、ロードバッファの解放タイミングを早める。
【解決手段】投機的に実行されるベクトルロード命令が発行された場合に、ベクトルデータのバッファ領域M2を確保するロードバッファ管理部31と、メモリアクセスリクエストに基づいて要素データをキャッシュメモリM1又は主記憶装置9から読み出し、読み出した要素データをバッファ領域M2に格納させるキャッシュ処理部4と、投機的実行に成功した場合にバッファ領域の要素データをベクトルレジスタM3に転送してからバッファ領域M2を解放し、一方、投機的実行に失敗した場合にバッファ領域M2の要素データをベクトルレジスタM3に転送せずにバッファ領域M2を解放するベクトル処理部6とを備え、キャッシュ処理部4は投機的実行に失敗した場合に要素データの主記憶装置9からの読み出しを抑止する。
(もっと読む)
共用データ・バスに対する階層的バッファ・システムのための方法、集積回路デバイス、およびプロセッサ・デバイス
【課題】本発明は、階層的バッファ・システム中でデータ・エントリを制御するためのシステムおよび方法を提供する。
【解決手段】該システムは、メモリ・コア、共用データ・バス、およびメモリからデータを受信する複数の第一ティア・バッファを包含する集積回路デバイスを含む。該システムは、データを共用データ・バス上に所定のタイミングで配信する第二ティア転送バッファをさらに含む。また、本発明は、階層的バッファ・システム中で移動式データ・エントリを制御する方法を提供していると見ることもできる。該方法は、データが複数の第一ティア・バッファから第二ティア転送バッファに流通するのを可能にするようバッファ群を管理するステップと、該データを共用データ・バス上に所定のタイミングで配信するステップとを含む。
(もっと読む)
プロセッサ
【課題】より小さいサイズのプログラムで動作させることが可能な、消費電力の小さいプロセッサを提供する。
【解決手段】第2の命令が含むソースレジスタ情報が示すレジスタと第1の命令が含むディスティネーションレジスタ情報が示すレジスタとが一致し、かつ第2の命令が第1の命令によって得られる演算値を使用する最後の命令であることを第2の命令又は第2の命令に先行する命令が指定している場合、パイプラインレジスタに格納されている演算値を第1の命令が含むディスティネーションレジスタ情報が示すレジスタに格納せず、それ以外の場合、パイプラインレジスタに格納されている演算値を第1の命令が含むディスティネーションレジスタ情報が示すレジスタに格納する。
(もっと読む)
情報処理装置及びマイクロ命令処理方法
【課題】ソフトウェア命令の実行順序が確定前に、当該ソフトウェア命令に対応するマイクロ命令を実行可能な状態にすること
【解決手段】ソフトウェア命令先取部21は実行前のソフトウェア命令を先取りする。ソフトウェア命令記憶部22は取得したソフトウェア命令を格納し、格納されたソフトウェア命令が実行されたか否かの判定であるソフトウェア命令実行判定を行う。ソフトウェア命令実行部23はソフトウェア命令記憶部22からソフトウェア命令を取得して実行する。マイクロ命令先取部24はソフトウェア命令実行判定において実行されていないソフトウェア命令が存在すると判定された場合に、先取り済みのソフトウェア命令に対応するマイクロ命令が読出し可能か否かを判定し、読出し可能である場合に当該マイクロ命令を読み出す。マイクロ命令実行部26は読み出したマイクロ命令を取得して実行する。
(もっと読む)
非アラインドメモリアクセス予測
【課題】命令実行パイプラインにおけるメモリアクセス命令のミスアライメントを早期に予測する。
【解決手段】複数のメモリアクセス命令のミスアラインメントを予測し、追加のマイクロ操作を実効アドレス生成に先立って生成する。該追加のマイクロ操作は、所定のアドレス境界を横切る範囲に入るメモリにアクセスする。追加のマイクロ操作を生成して追跡するのに十分なパイプライン制御資源が利用可能であることが保証され、実効アドレス生成時にそれら資源が利用可能でない場合のパイプラインフラッシュを回避する。ミスアラインメント予測は、フラッグ、二重モードカウンタ、局所プレディクタ、広域プレディクタおよび統合プレディクタなど、既知の条件付分岐予測技術を使用することができる。ミスアラインメントプレディクタは、メモリアクセス命令フラッグまたはミスアラインド命令タイプによって使用可能にされてもよいし、あるいはバイアスされてもよい。
(もっと読む)
情報処理装置およびキャッシュメモリ制御装置
【課題】メモリアクセスをアウトオブオーダで処理する情報処理装置において、不要な命令再実行を確実に抑止し、処理性能の低下を招くことなく確実にTSO保証を実現する。
【解決手段】ロード命令の対象データがキャッシュ212から演算器400に転送された後にキャッシュ212のデータに対する無効化要求を受信し、受信した無効化要求の対象アドレスのキャッシュインデクスと一致するキャッシュインデクスを有するロード命令が命令ポート210に存在する場合、第1判定部214Aは、第1フラグ(RIM)を有効化する。命令ポート210のエントリに保持されたロード命令の対象データについてキャッシュミスした後に対象データが転送されてきたと判定した場合、第2判定部215Aは第2フラグ(RIF)を有効化する。命令再実行判定部216は、第1フラグおよび第2フラグがいずれも有効化されている場合に命令の再実行を指示する。
(もっと読む)
ハードウェアプロセッサおよびハードウェアプロセッサ制御方法並びに情報処理装置
【課題】キャッシュ中の有効なデータが排除されてしまうことがなく、メモリ帯域利用効率に優れ、ハードウェアプロセッサにより生成される全てのプリフェッチ命令を有効に活用することができるハードウェアプロセッサの提供。
【解決手段】メモリへのロード命令及びメモリへデータを書込むストア命令を含む演算命令を発行する命令発行部11を備えるハードウェアプロセッサ10であり、命令発行部が発行した演算命令を受付て演算命令に基づきプリフェッチ命令を生成し、演算命令およびプリフェッチ命令を送信するプリフェッチ命令生成部12とプリフェッチ命令生成部12により送信された演算命令を受付け、かつ演算命令を処理する演算命令リザベーションステーション部13とプリフェッチ命令生成部12により送信されたプリフェッチ命令を受付け、かつプリフェッチ命令を前記演算命令と平行して処理するプリフェッチリザベーションステーション14部とを備える
(もっと読む)
データ処理装置、データ処理方法、プログラム変換処理装置およびプログラム変換処理方法
【課題】実行結果の再利用による再利用区間における処理時間を短縮させる
【解決手段】履歴メモリ430は、関数の識別情報ごとに関数の入力値および実行結果を関連付けて実行履歴として保持する。命令デコーダ320は、フェッチ部310からの関数を予告する予告命令に含まれる関数の識別情報を実行履歴検索部410に供給する。また、命令デコーダ320は、予告命令の後に読み出される命令のうち、関数の入力値を設定する入力値設定命令に基づいて、入力選択部332から出力される入力値を実行履歴検索部410に取得させる。実行履歴検索部410は、関数の呼出し命令の前に、その取得された識別情報および入力値と一致する実行履歴を検索する。実行結果出力部420は、実行履歴検索部410により検出された実行結果を実行部330に出力する。フェッチ部310は、関数の次に読み出すべき命令を読み出す。
(もっと読む)
SIMDオペレーションを実行するデータ処理システム及び方法
【課題】様々なロード及び格納命令を用いて、多重ベクトル・エレメントをレジスタ・ファイル内のレジスタとメモリとの間で転送する。
【解決手段】オペランド及びデータ・エレメントを格納するメモリと、少なくとも1つの汎用レジスタと、少なくとも第1の命令、及び、第1の命令に続く第2の命令を実行するプロセッサ回路と、を備え、第1の命令によって、少なくとも1つの汎用レジスタにおいてキューされるべき、メモリからのデータ・エレメントのストリームの転送を開始し、第2の命令が、少なくとも第1のソース・オペランドを含み、少なくとも1つの汎用レジスタが、第2の命令のソース・オペランドとして現れることに基づいて、プロセッサ回路が、条件付きで、メモリから、データ・エレメントのストリームの次の部分を、少なくとも1つの汎用レジスタの中にロードする、データ処理システム。
(もっと読む)
半導体集積回路
【課題】性能低下を招くことなく回路面積を削減出来る半導体集積回路を提供すること。
【解決手段】データを保持する第1メモリ30と、前記第1メモリ30に対するキャッシュメモリとして働く第2メモリ10とを備え、前記データに対する読み出し処理と書き込み処理とを複数の処理ステージによりパイプライン実行する半導体集積回路1であって、前記読み出し処理の対象となるデータを前記第1メモリ30から読み出すと決定された場合に、該データの前記第1メモリ30からの読み出しを前記処理ステージのいずれかRR、RR/CRにおいて行う。
(もっと読む)
プロセッサ
【課題】低電力で高速にループ処理などを実行させるプロセッサを提供する。
【解決手段】プロセッサ100は、通常命令バッファ122と、TAR用命令バッファ123と、命令がTAR用命令バッファ123に充填されたか否かを示すValid bitが記憶されるフラグ記憶部と、通常命令バッファ122およびのTAR用命令バッファ123のいずれかを命令供給源に選択するセレクタ121と、第1の充填命令が実行された場合には、第1のアドレスから命令を取り出してTAR用命令バッファ123に格納し、ループ命令が実行された場合には、TAR用命令バッファ123から命令を繰り返し供給する命令フェッチ制御部102とを備え、命令キャッシュ10の第1のアドレスから取り出された命令がTAR用命令バッファ123に充填された場合に、そのことを示すValid bitがフラグ記憶部に記憶される。
(もっと読む)
情報処理装置及びシステム
【課題】メインメモリの異なる複数のキャッシュラインへのアクセス時にキャッシュメモリの同一のキャッシュラインを使用する際、キャッシュミスの発生を抑制可能な情報処理技術を提供する。
【解決手段】出力プログラム生成部303は、入力プログラム解析部302が出力した内部表現プログラムに含まれるメモリアクセス命令に対して、ロードキャッシュ命令、キャッシュヒット判定命令、キャッシュヒット判定命令に従って行われる判定結果に応じて行うキャッシュミス処理命令を生成し、メインメモリの異なる複数のキャッシュラインへのアクセス時に使用されるキャッシュメモリのキャッシュラインが同一である可能性がある複数のメモリアクセス命令が内部表現プログラムに含まれる場合、キャッシュヒット判定命令に従って行われる判定の判定結果を1つに融合する融合命令を生成してこれらを含む出力プログラム103を出力する。
(もっと読む)
情報処理装置及びシステム
【課題】同一キャッシュラインにアクセスする複数のアクセス処理を並行させる場合にも、不必要なキャッシュミスの発生を抑制可能な情報処理技術を提供する。
【解決手段】出力プログラム生成部303は、入力プログラム解析部302が出力した内部表現プログラムに含まれるメモリアクセス命令に対して、ロードキャッシュ命令、キャッシュヒット判定命令、及びキャッシュヒット判定命令に従って行われる判定結果に応じて行うキャッシュミス処理命令を生成し、キャッシュメモリの同一のキャッシュラインへアクセスする可能性がある複数のメモリアクセス命令が内部表現プログラムに含まれる場合、キャッシュヒット判定命令に従って行われる判定の判定結果を1つに融合する融合命令を生成して、これらを含む出力プログラム103を出力する。
(もっと読む)
情報処理装置、および情報処理方法、並びにコンピュータ・プログラム
【課題】レジスタ、演算部などを備えたデータ処理部において、効率的なデータ処理および実装面積の削減を実現した構成を提供する。
【解決手段】レジスタ、演算部などを備えたデータ処理部において、複数の命令テーブルの切り替えや命令の多重化により効率的に命令を実行し、またダブルバッファ構成とした入出力レジスタを利用したデータ格納制御により入出力のオーバーヘッドや命令のレイテンシの解消を図り処理の高速化を実現した。本構成により、命令の圧縮・伸長によるバスバンド幅、外部IO、メモリ容量の小型化が実現され、データ処理部を構成するLSIの論理回路の実装面積の削減、さらに消費電力の低減が実現される。
(もっと読む)
プロセッサ及びプリフェッチ制御方法
【課題】本来の処理命令の実行に対する影響を抑えつつ、複数のキャッシュブロックを転送する。
【解決手段】本プロセッサは、実行ユニットとキャッシュとキャッシュブロックを主記憶からキャッシュに転送する主記憶制御部とキャッシュブロックの転送指示を主記憶制御部に出力するマルチブロックプリフェッチ制御部とを有する。そして、実行ユニットは、プログラム内の所定の処理の前に挿入された第1prefetch開始命令を実行し、プリフェッチ対象領域情報を含む第2prefetch開始命令をマルチブロックプリフェッチ制御部に出力する。また、マルチブロックプリフェッチ制御部は、第2prefetch開始命令を受信した場合、当該命令に含まれるプリフェッチ対象領域情報とキャッシュブロックの大きさとに基づき、転送すべき複数のキャッシュブロックを特定し、複数のキャッシュブロックを所定の処理の実行時間内で転送するようにスケジューリングし、転送指示を出力する。
(もっと読む)
演算処理装置
【課題】レジスタウィンドウ方式のレジスタファイルを備え、ウィンドウ切り替え命令の後続命令のアウトオブオーダ実行が可能な演算処理装置の回路規模を削減し、その消費電力も低減する。
【解決手段】MRF10は、レジスタファイル、MRF_RA1及びMRF_RA2と5つの読み出しポートio0、io1、io2、l0、l1を備える。レジスタ制御部210によってMRF_RA1を制御し、それらの読み出しポートから、CWPレジスタ213の値(cwp)で指定されるレジスタウィンドウのインレジスタ/アウトレジスタ、ローカルレジスタのウィンドウを選択出力する。次に、レジスタ制御部210によってMRF_RA2を制御し、該選択出力されたウィンドウのデータと前記レジスタファイルから入力するグローバルレジスタのウィンドウのデータから、演算部30が必要とするレジスタのデータを選択し、該データを演算部30に出力する。
(もっと読む)
プロセッサシステム
【課題】パイプラインにおける有効な命令の処理率を向上させるプロセッサシステムを提供すること。
【解決手段】本発明の一形態のプロセッサシステムは、パイプラインに、キャッシュメモリ(2)と、複数の命令を格納する命令フェッチバッファ(41)と、前記キャッシュメモリに対するデータアクセスを要求する実行モジュール(6)と、前記実行モジュールのデータアクセスに係る情報を出力するタグメモリ(32)と、前記命令フェッチバッファのエントリ情報と、前記タグメモリからのデータアクセスに係る情報とに基づき、前記キャッシュメモリに対するアクセスを調停する調停回路(1)と、を備える。
(もっと読む)
文字列を処理するための命令及び論理回路
ストリング比較演算を実行する方法、装置、及びプログラム手段である。一実施形態では、一装置は第1の命令を実行する実行リソースを含む。前記第1の命令に応じて、前記実行リソースは、第1と第2のテキストストリングに対応する第1と第2のオペランドの各データ要素間の比較結果を記憶する。 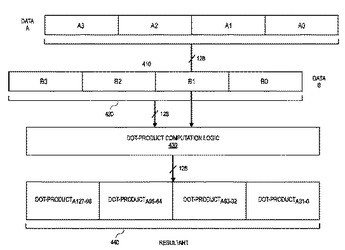 (もっと読む)
(もっと読む)
ロード操作の推測結果をレジスタ値にリンクするためのシステムおよび方法
【課題】マイクロプロセッサにおいてデータ推測を実行し、誤推測に対する効率的な復旧機構を提供する。
【解決手段】第1アドレッシングパターン(206)および第1タグ(208)を記憶するように構成されたエントリ(220)を含むメモリファイル(132)と、前記メモリファイルに結合される実行コア(124)とを含むシステムである。メモリファイルは、エントリに含まれる第1アドレッシングパターンをロード操作の第2アドレッシングパターンと比較するように構成される。第2アドレッシングパターンがエントリに記憶されている第1アドレッシングパターンに合致するとき、メモリファイルは第1タグによって指定されるデータ値をロード操作の推定結果にリンクするように構成される。実行コアはロード操作に依存する第2操作を実行するときに推測結果にアクセスするように構成される。
(もっと読む)
1 - 20 / 58
[ Back to top ]