
Fターム[5B013DD01]の内容
Fターム[5B013DD01]に分類される特許
1 - 20 / 135
情報処理装置、情報処理方法、及びプログラム
情報処理装置、情報処理方法及び制御プログラム
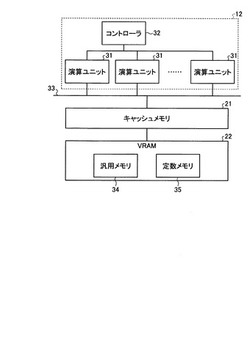
【課題】メモリに対するアクセス時間を低減し、ひいては、実行パフォーマンスを向上する。
【解決手段】実施形態の情報処理装置は、並列処理が可能な複数のプロセッサと、前記複数のプロセッサで共有されるメモリと、を備えている。そして、割当手段は、メモリのアクセス範囲が予め記述可能とされるとともに複数のスレッドで構成されたワークグループを、それぞれ記述されたアクセス範囲を参照して複数のプロセッサのいずれかに実行させるために割り当てる。
(もっと読む)
データ処理装置およびデータ処理方法およびプログラム

【課題】演算部の演算開始タイミングを変化させてデータ処理を行うデータ処理装置を実現する。
【解決手段】メモリ400aは、先行して演算を実行する処理部200aが生成したデータを蓄積する。メモリ監視部450は、メモリ400aが蓄積するデータのデータ数を監視し、後続して演算を実行する処理部200bが演算に必要なデータ数が蓄積されたら、メモリ400aが蓄積するデータを処理部200bに出力させる。処理部200bはデータが出力されるタイミングで演算を開始し、データが出力されるタイミングの変化に対応して、処理部200bの演算開始タイミングが変化する。
(もっと読む)
演算処理装置及び演算器同時実行制御方法
【課題】異なるプロセッサ間で同時に演算器が起動する電圧変動最悪パターンを改善すること。
【解決手段】本発明にかかる演算処理装置100は、同時に実行可能な複数の演算器を有する複数の処理回路120A〜120Nと、各処理回路で実行中の演算器の総数を集計する制御回路110と、を備え、複数の処理回路120A〜120Nのそれぞれは、制御回路110が集計した集計結果に応じて自己が有する演算器のうち未実行の演算器を実行するか否かを決定する。
(もっと読む)
命令語圧縮装置、命令語圧縮方法及びコンピュータで読み取り可能な記録媒体
【課題】命令語圧縮装置、命令語圧縮方法及びコンピュータで読み取り可能な記録媒体を提供する。
【解決手段】命令語圧縮装置100は、有効命令語バンドルの間に存在する無演算命令語バンドルの個数に対応した命令語圧縮ビットを生成させる生成部120、生成された命令語圧縮ビットを有効命令語バンドルに挿入する挿入部130、無演算命令語バンドルを削除する削除部140、とを備えることによって、命令語を効率的に圧縮することができる。したがって、プロセッサ内で並列処理されうる命令語の個数が増加する。
(もっと読む)
情報処理装置、情報処理方法
【課題】各プロセッサ間で効率的に演算結果を共有可能な情報処理装置を提供する。
【解決手段】プログラムを記憶するプログラム記憶手段11と、コア毎の演算結果を記憶する演算結果記憶手段45と、コア数分の命令の命令セットを実行順にプログラム記憶手段から読み出し一次記憶部に記憶する命令読み出し手段21と、命令セットに含まれる命令を各コアの命令キューに記憶する命令配信手段32と、一次記憶部に記憶された第一の命令セットに含まれる命令を第一のコアが演算した演算結果を演算対象とする命令が第一の命令セットよりも後に実行される第二の命令セットに含まれ第一のコアと異なる第二のコアが実行するか否かを判定する命令依存関係判定手段33と、命令依存関係判定手段が第二のコアが第二の命令セットに含まれる命令を実行すると判定した場合第一のコアの演算結果記憶手段の値を第二のコアの演算結果記憶手段に複写する複写手段34と、を有する。
(もっと読む)
プロセッサにおける効率的なパラレル浮動小数点例外処理
【課題】SIMD命令を実行するプロセッサにおいて浮動小数点例外を効率的に処理する。
【解決手段】SIMD浮動小数点演算の数値例外を特定するステップと、前記SIMD浮動小数点演算の第1Packed部分結果を生成するため、第1SIMDマイクロ演算を開始するステップと、前記SIMD浮動小数点演算の第2Packed部分結果を生成するため、第2SIMDマイクロ演算を開始するステップと、前記第1及び第2Packed部分結果を合成し、前記合成された第1及び第2Packed部分結果の第1要素を非正規化して非正規化要素を有する第3Packed結果を生成するため、SIMD非正規化マイクロ演算を開始するステップと、前記SIMD浮動小数点演算の第3Packed結果を格納するステップと、前記第3Packed結果の非正規化要素を特定するフラグを前記第1Packed部分結果に設定するステップと、を有する。
(もっと読む)
埋込み浮動小数点構造を有するDSPブロック
【課題】浮動小数点機能を特殊処理ブロックの外に構築する必要性を減少させる、特殊処理ブロックを提供すること。
【解決手段】プログラマブル集積回路デバイス上の特殊処理ブロックであって該特殊処理ブロックは、第一の浮動小数点算術演算子段と、第二の浮動小数点算術演算子段と、該特殊処理ブロック内の構成可能インターコネクトであって、該構成可能インターコネクトは、該第一および第二の浮動小数点算術演算子段の各々に信号をルート付け、各々の外に該信号をルート付ける、構成可能インターコネクトとを含む、特殊処理ブロック。
(もっと読む)
演算処理装置及び演算処理方法
【課題】レジスタからの読み出しデータにおける誤り検出時に、プログラム実行動作を停止することなく、継続して実行可能である演算処理装置を提供する。
【解決手段】演算処理装置は、レジスタから読み出したデータのエラーを検出し訂正する訂正制御部と、命令の実行要求に応じてキャッシュ領域又はノンキャッシュ領域にアクセスするとともに、実行要求された一の命令がノンキャッシュ領域にアクセスするロード命令であることを通知するキャッシュ制御部と、一の命令がノンキャッシュ領域にアクセスするロード命令であることがキャッシュ制御部により通知されると、一の命令をキャッシュ制御部に実行させる間、他の命令の実行を待たせることにより、ノンキャッシュ領域にアクセスするロード命令の実行中にエラーが検出されないようにする命令実行制御部とを含む。
(もっと読む)
プロセッサ装置及びその演算方法
【課題】複数のPEを備えた並列型SIMDプロセッサにおいて並列性の高い行列転置方法等を提供する。
【解決手段】プロセッサ装置は、各PE方向に行ベクトルデータが配列され、かつ各PE内レジスタ方向に列ベクトルデータがそれぞれ配列された複数個の行列データの数学的転置を行うときに、各PE間のレジスタ参照、格納又は移動を行う単一命令複数データ型の演算命令を用いて、対角位置の要素データ又はベクトルデータの移動をして交換を行うステップを含み、行列に含まれる2のべき乗次の部分行列を対象にして、最小2次の行列(2×2要素)では対角要素データの移動又は交換を行い、上位のべき乗次数の部分行列では対角位置の下位の部分行列の要素データ群をブロックとして一括に移動又は交換し、これらの手順を上位次数から最小次数まで、又は最小次数から上位次数まで順次繰り返して行って複数の行列データを一括して並列同時に転置処理する。
(もっと読む)
プロセッサ内のマルチスレッド間通信
【課題】プロセッサコアで実行するマルチスレッドにおいて、非常に低いオーバーヘッドでスレッド間の同期を可能にする。
【解決手段】SMT動作実施形態において、第2のスレッドの実行中に、第1のスレッドに関連するレジスタにアクセスする方法を含む。この方法は、ソースオペランドに関連する同期インジケータが第2のスレッドのプロデューサ演算が終っていないことを示す場合、第2のスレッドのレジスタファイルからソースオペランドにアクセスする第1のスレッドの命令を実行しないようにし、同期インジケータが第2のスレッドのプロデューサ演算が終了したことを示す場合、命令を実行する段階を備える。他の実施形態において、マルチコアであってもよい。
(もっと読む)
サブワード実行を用いるVLIWベースのアレイプロセッサで条件付き実行をサポートする方法及び装置
【課題】複合条件に基づくサブワード並列実行をサポートする。
【解決手段】汎用フラグ(ACF)は階層を使用して定義され、エンコードされる。加えられた各ビットは、前の機能性のスーパーセットを提供する。条件の組合せを用いて、複合条件に基づく条件付き分岐の順次シリーズを回避することができ、次いで複合条件を条件付き実行のために使用することができる。フラグの数を変えることによって、条件付きオペレーションの並列性は、例えばVLIW実行での単一の処理からオクタル処理まで、かつ処理要素のアレイにわたって広範に変化することができる。異なるプロセッサ中で生成された条件に基づいて1つのプロセッサ中の条件付き実行を指定することを可能にして、多数のPEは、条件情報を同時に生成することができる。多数のプロセッサアレイ中の各プロセッサは、異なるユニットをそれらのACFに基づいて条件付きで独立に動作させることができる。
(もっと読む)
2次元マトリクス処理のためのレジスタ
【課題】SIMDマルチメディア処理を効率的に実装するために、複数の関連データ・アイテムを単一のMMXレジスタ内に配置する。
【解決手段】プロセッサがレジスタの二組のセットを有し、第1のセットはデータのマトリクスをストアし、第2のセットは、データのマトリクスの転置されたコピーをストアする。第1のセットのいずれかの行のいずれかの部分が変更されたとき、第2のセット内の転置されたコピーの対応する列の部分が自動的に変更される。データのマトリクスをレジスタの第1のセットにストアし、レジスタの第1のセットは第1の数のレジスタを有し、各レジスタは第1の数のストレージ・ユニットを含み、各ストレージ・ユニットはマトリクスの要素をストアし、レジスタの第2のセット内に転置するステップであって、レジスタの第2のセットは第2の数のレジスタを有し、各レジスタは第2の数のストレージ・ユニットを包含する。
(もっと読む)
画像処理用のタイルレンダリング
【課題】実際に、バックエンドワークを実行することなく、当該バックエンドワークに要する時間が推算されうる。
【解決手段】フロンドエンドのカウンタが、コストモデルおよびヒューリスティック(heuristic)関する情報であって、タイルを分割して、順序付けられたワークをコアに配送するときに用いられる可能性のある情報を記録する。専用のラスタライザ(special rasterizer)は、サブタイルの外側の三角形状および断片を放棄する。
(もっと読む)
命令発行制御装置及び方法
【課題】複数スレッドを実行可能なマルチスレッドプロセッサにおいて、マルチスレッドプロセッサのスループットを改善させるスレッド及び命令を選択する。
【解決手段】マルチスレッドプロセッサが備える命令発行制御装置220であって、命令発行制御装置220は、実行中のスレッドの各々がストール中であるか否かを示すストール情報を管理するリソース管理部210と、実行中のスレッドのうち、ストール中でないスレッドを選択するスレッド選択部206と、選択されたスレッドから同時発行可能な命令が発行されるよう制御する命令発行制御部204とを備える。
(もっと読む)
演算処理装置及び並列演算装置
【課題】ALUアレイ回路における電力消費を低減する。
【解決手段】ALUアレイ回路は、ALU12を内包する単位回路10cを複数個備え、複数のALU12を並列動作させる。各単位回路10cでは、命令コードをデコードすることで演算制御信号OpCを生成し、これによってALU12での演算処理の内容を制御する。ALU12の前段にはラッチ素子21及び22が設けられる。ALUアレイ回路に設けられた複数の単位回路10cの内、幾つかの単位回路10c中のALU12の演算動作は時として不要である。或るALU12の演算動作が不要であるとき、命令コードによって生成された演算休止信号(nop)をラッチ素子21及び22に与えて、そのALU12にデータ入力信号AIN及びBINの変化が伝播することを阻止する。
(もっと読む)
マルチコアプロセッサ
【課題】逐次処理用プログラムでも、ループ部分の繰り返し処理を並列に実行するマルチコアプロセッサの実現。
【解決手段】メインプロセッサ10を含む複数個のプロセッサエレメントPE20-1,20-N-1を含み、逐次処理プログラムを実行するマルチコアプロセッサであって、メインプロセッサは、ループ部分を検出するループ部分検出部11を含み、マルチコアプロセッサは、ループ部分を検出した時に、複数個のPEがループ部分を命令バッファにコピーし、ループカウンタの初期値を各PEごとにずらして格納し、更新量をPEの個数に応じて設定する展開制御部12と、を含み、いずれか1個のPEが終了通知を出力した際に,終了通知を出力したPEより前のループカウンタ値の処理を行っているすべてのPEの現在の処理の終了を待ち,終了通知を出力したPEより後ろのループカウンタ値の処理を行っているPEの処理を終了させた後,逐次処理のプログラムの処理を続行する。
(もっと読む)
命令スケジューリング装置、命令スケジューリング方法および命令スケジューリングプログラム
【課題】 処理の遅延を抑えてレジスタの利用期間を短縮する命令列を生成することができる命令スケジューリング装置を提供すること。
【解決手段】 依存関係のある一連の命令を1つの命令群として命令ブロック内の命令を複数の命令群に分割する命令群分割部2と、各命令に対して、該命令が含まれる命令群における処理順序の優先度を表す命令単位優先度を設定するとともに、各命令群に対して、命令ブロックにおける処理順序の優先度を表す命令群別優先度を設定する優先度設定部3と、命令群別優先度の高い命令群から順に、該命令群に含まれる命令を命令単位優先度に基づいてスケジューリングし、該命令群内の命令が配置された処理サイクルのうち実機によって他の命令群の命令を並列実行可能な処理サイクルに、次に命令群別優先度の高い命令群に含まれる命令を命令単位優先度に基づいて配置する命令スケジューリング部4とを備える。
(もっと読む)
マイクロプロセッサ、電子制御ユニット、アドレス変換方法
【課題】マルチスレッドが可能なプロセッサにおいて、プログラムを修正することなく又は修正箇所を抑制して、スレッド間のアドレス空間が重複することを防止するマイクロプロセッサ等を提供すること。
【解決手段】プログラムの命令をデコードする命令デコード手段12と、ハードウェアスレッドのスレッド判定手段17と、命令デコード手段による命令のデコード結果に基づきアクセス先のアドレスを決定し、メモリにアクセスするメモリアクセス手段15と、命令デコード手段がデコードした命令が、アドレスを相対アドレス指定により決定する命令である場合、前記プログラム毎に異なるオフセット値をメモリアクセス手段に通知するオフセットアドレス制御手段18と、を有し、メモリアクセス手段は、オフセット値だけオフセットしたアドレスをアクセス先に決定する、ことを特徴とする。
(もっと読む)
半導体信号処理装置
【課題】大量のデータを高速で効率的に演算処理する処理装置を実現する。
【解決手段】主演算回路(20)に対する演算処理命令を、マイクロ命令メモリ(21)にマイクロプログラムの形態で格納し、このマイクロプログラムに従ってコントローラ22の制御の下に主演算回路の動作制御を実行する。主演算回路(20)においてはメモリセルマット(30)が、それぞれが複数ビットのデータを格納するエントリに分割され、各エントリに対応して演算器(ALU)が配置される。エントリとALUとの間で、ビットシリアル態様で各エントリ並列に演算処理を実行する。マイクロプログラム制御方式に従って効率的に大量のデータを処理することができる。
(もっと読む)
1 - 20 / 135
[ Back to top ]