
Fターム[5B042JJ03]の内容
デバッグ、監視 (27,428) | 動作監視、異常又は誤りの検出 (3,508) | 監視 (1,259) | 集中監視 (355)
Fターム[5B042JJ03]に分類される特許
1 - 20 / 355
広域分散構成変更システム
ディペンダブルシステム並びにディペンダブルシステムを実現するための障害対応言語システム及び情報装置
【課題】予め想定することが困難な障害の発生に対応する。
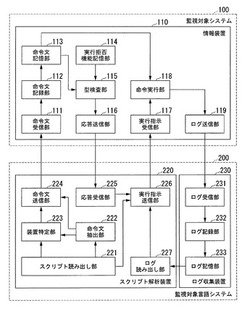
【解決手段】障害対応言語システムは、スクリプトから命令文を抽出する命令文抽出部222と、スクリプトから抽出した命令文が示す命令を実行させる情報装置110を特定する装置特定部223と、特定した情報装置110に命令文を送信する命令文送信部224と、命令文を全ての装置に送信した後に、全ての装置に命令の実行を指示する実行指示を送信する実行指示送信部226とを備える。また、監視対象システム100を構成する各情報装置110は、命令文を受信する命令文受信部111と、実行指示を受信する実行指示受信部117と、実行指示を受信したときに、命令文受信部111が受信した命令文が示す命令を実行する命令実行部118とを備える。
(もっと読む)
列車運行管理システム

【課題】連動装置で障害が発生したときに、進路制御装置や連動装置とは別に監視装置を用いずとも、進路制御装置が連動装置の送信する誤った情報を利用しない、高信頼多重化制御列車運行管理システムを提供する。
【解決手段】高信頼多重化制御列車運行管理システムは、制御対象40の制御を行う複数の連動装置20,21,22と、これらの連動装置に制御の指示を行う進路制御装置10とが送受信可能にネットワーク50により接続されている構成において、連動装置20,21,22のそれぞれは、自身の連動装置が認識する当該自身の連動装置の状態と自身以外の連動装置の状態との統合した連動装置状態情報を進路制御装置10に送信し、進路制御装置10は、複数の連動装置20,21,22のうちの連動装置20または21または22が送信する情報をもとに連動装置の状態判断を行い、情報の取捨選択をする。
(もっと読む)
コア監視装置、情報処理装置
【課題】マルチコアマイコンにおいて、異常の生じたコアをソフト的な負荷増大を抑制して判別可能なコア監視装置を提供すること。
【解決手段】複数のコアから共通の周期で通知を受け付けるコア監視装置17であって、 コアから通知を受け付けた際、各コアに固有のコア識別数値(例えば、カウンタ値×ID)をコア毎に生成するコア識別数値生成手段31と、複数のコアのコア識別数値を合計した合計値を算出する合計値算出手段32と、最後に算出された合計値を記憶する合計値記憶手段36と、合計値算出手段が算出した合計値と、合計値記憶手段に記憶された合計値との差である第一の差を算出する第一の差算出手段33と、第一の差を記憶する第一の差記憶手段37と、第一の差算出手段が算出した第一の差と第一の差記憶手段に記憶された第一の差との差である第二の差を算出する第二の差算出手段34と、を有する。
(もっと読む)
ゲートウェイ管理方法、ゲートウェイ管理装置、およびゲートウェイ装置
【課題】ゲートウェイ装置からアプリケーションソフトウェアの実行に必要なリソース値をサービス事業者へ提供可能とするゲートウェイ管理方法を提供する。
【解決手段】ゲートウェイ管理装置100は、サービス事業者が提供した各アプリケーションを管理するサービス管理テーブル2000、各アプリケーションが実行されたゲートウェイ装置200の機器数と、各アプリケーションが実行された際に必要なリソース実測値とが関連付けられた実測リソース情報集計管理テーブル2200を有する記憶部を備え、各ゲートウェイ装置200から、導入済みの各アプリケーションが実行された際に必要となったリソース実測値を受信した場合、該受信したリソース実測値に基づき実測リソース情報集計管理テーブル2200を更新し、機器数が所定値に達した場合、サービス管理テーブル2000に登録されているサービス事業者に、リソース実測値を通知する。
(もっと読む)
データ格納制御装置、データ格納制御プログラムおよびデータ格納制御方法
【課題】ユーザが参照する性能データの格納に遅延が発生することを抑制する。
【解決手段】データ格納制御装置10は、記憶部11と決定部12とを有する。記憶部11は複数種類の性能データそれぞれについて、ある種類の性能データの次に参照された割合を記憶する。決定部12はクライアント装置15がある種類の性能データを参照した場合に、記憶部11に記憶した複数種類の性能データそれぞれについての割合に基づいて、サーバ装置13から収集した複数種類の性能データを記憶装置14へ格納する格納順位を決定する。
(もっと読む)
運用管理システム及びその監視設定方法
【課題】大量の監視設定情報を、容易に、かつ構成情報の内容に応じて柔軟に生成することが可能な運用管理システム及びその監視設定方法を提供する。
【解決手段】記憶装置に、予め入力された、被監視装置毎の構成情報、監視種別に対応する設定情報の集まりである属性設定情報、監視種別に対応する監視設定情報を生成するためのテンプレートである監視設定テンプレート、構成情報に対応する監視種別の監視設定テンプレートを選択するための構成情報変換定義を蓄積しておく。管理装置は、構成情報変換定義に基づいて、構成情報から被監視装置毎の監視設定テンプレートを選択し、該選択した監視設定テンプレートで指定された属性設定情報及び構成情報を含む監視設定情報を生成する。
(もっと読む)
障害監視システムおよび障害監視ソフトウェアによる監視方法
【課題】ネットワークに連接した複数の情報処理装置を利用してソフトウェアサービスを提供するシステムにおいて、ソフトウェアサービスの提供を継続するための情報処理装置とソフトウェアの無応答を含む障害監視をハートビート方式等により一括して行なった場合、短周期監視時のシステム内の監視負荷増大、または、長周期監視時のサービス停止時間増大の課題がある。
【解決手段】短周期ハートビート監視の必要な無応答を含むソフトウェアの障害監視範囲を個々の情報処理装置内に限定して障害発生時の障害情報を情報処理装置間で情報共有装置を使用して共有し、かつ、情報共有装置の障害情報を使用して障害監視装置が障害対処する。情報共有装置により、任意の情報処理装置が障害監視装置の障害を検出した場合に自律的に障害監視装置となって、システム障害への継続対処を図る。
(もっと読む)
制御機器及びその障害情報収集方法
【課題】障害が発生した場合に全ての処理ユニットからログを収集することなく障害情報を取得することができ、障害情報の収集処理を容易化して迅速に行なえるようにした制御機器及びその障害情報収集方法を提供すること。
【解決手段】実施の形態によれば、制御機器は、複数の処理ユニットと記憶手段と収集手段とを備える。複数の処理ユニットは、それぞれが動作履歴を示す情報を蓄積し、自己に障害が発生した場合にその障害元となる処理ユニットを判断する。記憶手段は、複数の処理ユニットがそれぞれ判断した障害元となる処理ユニットを示す情報を記憶する。収集手段は、記憶手段に記憶された情報に基づいて機器全体の障害発生原因となる処理ユニットを特定し、当該特定された処理ユニットからその動作履歴を示す情報を取得する。
(もっと読む)
保守装置、保守方法および保守プログラム
【課題】多数の保守対象装置の中から保守作業における優先度の高い機体を把握する。
【解決手段】本発明の一実施形態に係る保守装置は、読取部、通信部、外れ値度算出部および保守優先度算出部を備えることを特徴とする。読取部は、保守作業の対象となる機体のシリアル番号、モデル名、設定項目および設定値を含む設定情報を格納した記録媒体を読み取る。通信部は、ネットワーク接続されたサーバからモデル名ごとに、設定情報に関する統計情報を取得する。外れ値度算出部は、読取部が読み取った設定情報を通信部が取得した統計情報と比較して設定値に係る外れ値度を算出する。保守優先度算出部は、外れ値度算出部で算出された外れ値度をシリアル番号ごとに集計すると共に、集計の結果に基づいてシリアル番号ごとに保守作業における優先度を算出する。
(もっと読む)
メンテナンス作業支援装置、メンテナンス作業支援システム、メンテナンス作業支援方法及びメンテナンス作業支援プログラム
【課題】メンテナンス対象機器について、稼働状況に応じて、メンテナンスとして必要な作業内容を見つけ、優先度を付けて端末装置に送信するメンテナンス作業支援装置を提供する。
【解決手段】メンテナンス対象機器から当該メンテナンス対象機器を識別する識別情報と、機器の稼働状態を示す稼働情報とをメンテナンス対象機器から読み出した端末装置から取得する情報取得手段と、取得した前記識別情報に基づいて、該識別情報に対応するメンテナンス対象機器の作業内容に関する基準値を取得し、該基準値と前記メンテナンス対象機器の稼働状態を示す情報とに基づいて、メンテナンスが必要となる時期を算出する算出部と、前記算出されたメンテナンスが必要となる時期に応じて、前記メンテナンスが必要となる作業に対し、優先度を決定する優先度決定手段と、決定された優先度と前記メンテナンスが必要となる作業とを前記端末装置に送信する送信手段とを有する。
(もっと読む)
セキュリティイベント監視装置、方法およびプログラム
【課題】操作者を特定不可能な操作が含まれていても、セキュリティイベントを適切に検出して操作者を推定することを可能とすることを可能とするセキュリティイベント監視装置等を提供する。
【解決手段】セキュリティイベント監視装置10は、相関ルールを予め記憶する記憶手段12と、各監視対象装置から各ログを受信するログ収集部101と、各々のログを関連づけたシナリオ候補を生成する相関分析部103と、各シナリオ候補に対して重要度を算出するシナリオ候補評価部104と、重要度の高いシナリオ候補を表示出力する結果表示部105とを有すると共に、シナリオ候補評価部が、ユーザ関連度を算出するユーザ関連度評価機能104aと、操作関連度を算出する操作関連度評価機能104bと、ユーザ関連度および操作関連度によってユーザごとに各シナリオ候補の重要度を再算出するシナリオ候補重要度再評価機能104cとを備える。
(もっと読む)
プログラム、情報処理装置、及び、情報処理方法
【課題】遅延を引き起こしている処理を特定することが可能なプログラム等を提供する。
【解決手段】情報処理装置は、要求データの要求時刻及び応答データの応答時刻を制御部により取得する。情報処理装置は一の要求データの要求時刻から前記一の要求データに対応する応答データの応答時刻までの間に要求時刻を有する他の要求データ数を制御部により計数する。情報処理装置は計数した計数値が第1の閾値を超える場合に、複数の要求データの要求時刻に基づき算出される第1の時間及び複数の応答データの応答時刻に基づき算出される第2の時間を制御部により算出する。情報処理装置は、算出した第1の時間と第2の時間との差または比が第2の閾値を超える場合に、制御部により遅延情報を出力する。
(もっと読む)
運用監視装置、運用監視プログラム及び記録媒体
【課題】ネットワークシステム全体という視点から、ノード間に存在する相関関係をも直感的に把握できるよう、各ノード及び各ノード間のネットワークの負荷状況を包括的・一元的に表示し、障害要因の迅速な特定・復旧に寄与する運用監視装置等を提供する。
【解決手段】本発明に係る運用監視装置は、監視機器及び前記ネットワークの監視データ値を記憶する第1記憶手段と、監視機器に対応する少なくとも2以上の監視機器表示とネットワークに対応する2以上の監視機器を結線して接続するネットワーク表示とを含むネットワーク構成マップを記憶する第2記憶手段と、ネットワーク構成マップを表示するとともに、監視機器表示及びネットワーク表示に対応付けて監視データ値を表示する表示手段とを有し、表示手段は、監視データ値が異常値と判定されたときは、異常値と判定された監視データ値とともに異常識別情報を表示する。
(もっと読む)
管理装置、管理プログラム及び管理システム
【課題】ネットワークに接続された機器の管理を効率的に行なうことを課題とする。
【解決手段】管理装置は、監視対象の機器が属するグループごとに、監視間隔の設定値と、該グループに振り分ける振分条件とを対応付けて記憶する記憶部を有する。また、管理装置は、監視対象の機器から該機器のログ情報を取得する。また、管理装置は、取得したログ情報と記憶部に記憶された振分条件とに基づいて、監視対象の機器をいずれかのグループに振り分ける。また、管理装置は、監視対象の機器に対する監視間隔を、機器が振り分けられたグループに応じた監視間隔の設定値に設定する。
(もっと読む)
運用管理装置、運用管理方法、及び運用管理プログラム
【課題】管理対象ノードの性能情報を収集することなく、異常を検知する。
【解決手段】運用管理装置21のメッセージ取得部201は、管理対象ノードが出力したメッセージを取得してメッセージDB202に記録する。学習情報生成部204が、指定した期間内における管理対象ノード毎、メッセージの識別情報毎、単位時間毎のメッセージの数の最大値、又は最小値を算出して学習結果情報DB205に記録する。分析情報生成部206が、対象ノード毎、メッセージの識別情報毎、単位時間毎のメッセージ出力数を算出して分析結果情報DB207に記録する。分析判定部208は、学習結果情報DB205に記録された最大最小値情報と、分析結果情報DB207から読み出した分析データ情報とに基づいて、分析対象の各管理対象ノードが正常であるか否かを判定し、判定結果を分析結果情報DB207に記録し、出力部209に出力する。
(もっと読む)
情報処理システム運用管理装置、運用管理方法及び運用管理プログラム
【課題】
並列分散処理システム、例えばMapReduce方式のように、複数の情報処理装置から取得した監視データを基に障害検知を行おうとしても、どの装置の間に相関関係が生じるかが事前に決定できない。また、稼働中に相関関係が生じる組み合わせが変化するようなシステムにおいて、障害の検知を行う。
【解決手段】
複数の情報処理装置が協調して動作する情報処理システムを運用管理する情報処理システム運用管理装置であって、前記情報処理装置を、その特性によって分類し、2つの前記情報処理装置の間の典型的な関係を各々の前記特性の組をキーとして記憶し、記憶された前記典型的な関係を用いて前記情報処理装置の状態を判定する。
(もっと読む)
遠隔監視端末装置
【課題】端末装置が格納する、端末装置の所定情報であるIPアドレス情報やセンタ装置のIPアドレス情報に誤りがあった場合でも、短時間で確実に提供サービスを復旧できるようにする。
【解決手段】不揮発性記憶装置4には端末装置の電源起動時およびシステムリセット時にシステムを起動するために必要な情報を、不揮発性記憶装置5から読込むのか、または不揮発性記憶装置6から読込むかの情報を格納し、現在電源起動時に読込む不揮発性記憶装置以外の不揮発性記憶装置に対し、新しいオペレーションシステムと稼動用プログラムと所定情報である端末装置およびセンタ装置のIPアドレス情報を書込み、センタ装置とのテスト通信が正常に完了できない場合は、不揮発性記憶装置4の情報を、元々稼動用に使用していた不揮発性記憶装置に変更しシステムを再起動する。
(もっと読む)
プロセス障害判定復旧装置、プロセス障害判定復旧方法、プロセス障害判定復旧プログラム、および記録媒体
【課題】システム内で稼動するプロセスの優先度を判断し、プロセス障害復旧の1手段であるプロセスの再起動、プロセスが稼動しているOSの再起動を自動的に行うことが可能なプロセス障害判定復旧装置、プロセス障害判定復旧方法、プロセス障害判定復旧プログラム、および記録媒体を提供する。
【解決手段】ネットワークを介して監視対象となるサーバ上で稼動するプロセスを監視し、プロセスに生じた障害を検知するプロセス障害検知部と、プロセス障害検知部によって障害が生じたプロセスが検知された場合に、障害が生じたプロセスを再起動した回数に基づいて、プロセスを再起動させるかまたはプロセスを稼動しているサーバを再起動させるかを判定し、判定した結果に従ってプロセスまたはサーバを再起動させ、障害を復旧させる障害判定復旧部と、を備える。
(もっと読む)
リモートモニタリング方法
【課題】一時的な通信障害によって、監視用コンピュータと監視対象コンピュータ間で通信が行えない場合でも、稼動情報を取得できるプログラムのリモートモニタリング方法を提供する。
【解決手段】ネットワークに接続したコンピュータにおけるプログラムのリモートモニタリング方法であって、前記コンピュータ上で動作中のアプリケーションプログラムの稼動情報を取得する稼動情報収集プロセス215をオペレーティングシステムに組み込み、かつ前記コンピュータの設置場所と離れた位置に設置された監視用コンピュータ上で稼動情報収集プロセスが取得した稼動情報を保存するリモート監視プログラムをオペレーティングシステムに組み込み、かつ前記監視用コンピュータ間で一時的な通信障害が発生した場合にも、稼動情報収集プロセスが収集した稼動情報を前記コンピュータ上に一時的に保存することで、稼動情報の抜け落ちを防止する。
(もっと読む)
1 - 20 / 355
[ Back to top ]