
Fターム[5B042JJ18]の内容
デバッグ、監視 (27,428) | 動作監視、異常又は誤りの検出 (3,508) | 異常又は誤りの検出方法 (1,125)
Fターム[5B042JJ18]の下位に属するFターム
時間を監視するもの (556)
複数個のタイマを有するもの (19)
単一計時手段で複数事象を監視 (14)
比較によるもの (456)
異常が所定回数以上発生 (63)
Fターム[5B042JJ18]に分類される特許
1 - 17 / 17
情報処理装置、処理システム、処理方法、及びプログラム
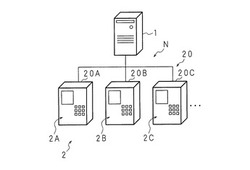
【課題】様々なノウハウの蓄積が可能となり、またより適切な対処方法をユーザに提供することが可能な情報処理装置等を提供する。
【解決手段】コンピュータ2Aは成膜装置20Aに関する情報を処理する。コンピュータ2Aは、成膜装置20Aに異常が発生した場合に、発生した異常に関する異常情報を表示する。コンピュータ2Aは、発生した異常に対処した際の対処情報を受け付ける。コンピュータ2Aは、受け付けた対処情報を、発生した異常を特定するための異常特定情報に対応付けて記憶する。コンピュータ2Aは記憶した異常特定情報及び対処情報を、サーバコンピュータ1へ出力する。成膜装置20Bに異常が発生した場合、コンピュータ2Bは異常特定情報に対応する対処情報をサーバコンピュータ1から受信し、表示する。
(もっと読む)
監視システム及び監視方法

【課題】監視装置がネットワークを介して被監視装置に接続することができなくなった場合にも、監視装置が被監視装置の情報収集を行うことができるようにする。
【解決手段】監視装置10と被監視装置A、BとがLAN30により接続され、監視装置10と情報端末40とが別のLAN20により接続されており、また、被監視装置A、Bと情報端末40とがシリアル接続装置100を介してシリアル接続されて構成されている。シリアル接続装置100は、情報端末40から制御可能であり、監視装置10と被監視装置A、Bとの間でLAN30を介して通信ができなくなった場合に、監視装置10から遠隔操作で情報端末40の起動、停止を行い、かつ、被監視装置A、Bの情報を監視装置10に収集させることができる。
(もっと読む)
制御装置
【課題】異常処理に何らかの障害が生じた場合であっても、発生した故障等に対し適切に対処することができる制御装置を提供する。
【解決手段】車載装置の制御部は、自車両のIG OFFにより異常処理検査タイミングが到来すると(S130:Yes)、対応する異常処理についての異常処理検査を実行し(S140)、該異常処理が正常に動作するかを検査する。そして、水温センサ等の各種センサである検査対象1〜6、或いは該検査対象が設けられた外部装置に異常が発生している場合には(S110:Yes)、発生した異常に対応する異常処理のうち、異常処理検査で正常に動作することが確認されたいずれかの異常処理を選択して実行する(S115,S120)。
(もっと読む)
監視システム、監視装置、サービス実行環境の監視方法、及び監視装置用プログラム
【課題】装置使用者がサービス実行環境に関する膨大な知識や経験を有することなく監視ルールを適切に修正可能ならしめる監視システム等を提供する。
【解決手段】サービス実行環境30の状態が監視ルールの各監視条件を満たすか否かを判定する分析部11を備え各判定の違いを検出して当該各監視条件にかかる監視設定が不適切であることを示す監視不良を告知可能としたマネージャ装置10を備えた監視システムであって、前記マネージャ装置10が、前記各判定に使用された各監視条件に対応するサービス実行環境30の状態(各性能情報)を履歴として各々蓄積する分析履歴蓄積部19と、複数の各監視条件が異なる判定結果の場合に前記分析履歴蓄積部19の性能情報の履歴に基づいて前記複数の各監視条件が同一の判定結果となるしきい値を算出しこれを前記監視不良の修正にかかる監視条件として生成する条件生成部18と、を備えたこと。
(もっと読む)
障害復旧システム、障害復旧方法および障害復旧プログラム
【課題】
最適な復旧計画を迅速に計算することが可能な障害復旧システム、障害復旧方法、および、障害復旧プログラムを提供する。
【解決手段】
本発明の障害復旧システムは、予測手段と手引き作成手段と計算手段とを備える。予測手段は、障害復旧システムにおいて発生しうる障害を予測する。手引き作成手段は、予測された障害と障害復旧システムの状態とから復旧方法を示す手引きを作成する。計算手段は、障害発生時に、該障害発生時の障害復旧システムの状態と手引きとから復旧計画を計算する。
(もっと読む)
プロセッサシステム、障害処理方法及び障害処理プログラム
【課題】 固定障害が発生した場合でも、その障害を回避できる電気的条件を自動的に見つけ出して、処理の継続を可能とする。
【解決手段】 一又は二以上のプロセッサ11,12と、障害の発生箇所を解析する診断プロセッサ(DGP30)と、この解析の結果にもとづいて、その障害が間欠障害又は固定障害のいずれであるかを判断するサービスプロセッサ(SVP40)とを備え、このサービスプロセッサ40が、固定障害と判断したときに、所定の電気量を変化させながらテストプログラムを実行し、障害が発生しない電気量があると、この電気量により、固定障害が発生したプロセッサ11,12に障害発生前の処理を続行させる。
(もっと読む)
計算機システム及び障害情報管理方法
【課題】各計算機の物理的経路を二重化構成とすることで上記の正常動作の計算機を誤って再起動してしまう問題を回避し、さらに複数台の計算機の障害発生情報を管理する。
【解決手段】複数の計算機100は、通信制御装置112を制御するBMC114を有し、SVP140は、ネットワークを介してBMC114と接続し、BMC114の監視をする。RAS−U141は、複数の計算機100から送出される障害情報をSVP140から収集すると共に、障害情報に対する処理を行いながら障害情報を管理する。操作機143は、障害情報の処理結果に基づいてRAS−U141に対して障害情報に対応する計算機の切替、停止、再起動を含む操作要求信号を送出する。
(もっと読む)
強制終了条件監視装置、強制終了条件監視方法および強制終了条件監視プログラム
【課題】ユーザ側においてアプリケーションが処理中かどうかの確認の有無にかかわらず、ASP側でアプリケーションの起動を終了させる。
【解決手段】監視装置は、ユーザ識別情報により特定されるユーザ端末に対して情報処理プログラムが起動することによりサービスを提供する情報処理装置の使用状態を監視する手段と、情報処理装置の使用状態が所定条件を満たすかを判定する手段と、使用状態が所定条件を満たす場合、情報処理プログラムの起動を終了させる手段と、情報処理プログラムの起動の終了をユーザ端末に通知する手段とを備える。
(もっと読む)
情報処理装置、機能検査方法、およびプログラム
【課題】情報処理装置に対してプラグイン・モジュールまたはアドイン・モジュールで実装された追加モジュールの機能検査を容易にする、情報処理装置、機能検査方法、およびプログラムを提供すること。
【解決手段】本発明の情報処理装置は、情報処理装置からの呼出しに応答して追加モジュールが機能を拡張しており、追加モジュールからの出力値を取得して、出力値が情報処理装置の指定する形式か否かを検査し、エラー内容を作成するエラーチェック処理部52と、エラーチェック処理部の検査によりエラーと判断された場合に、作成されたエラー内容を受け取り、通知処理を行うエラー通知処理部54とを備えていて、追加モジュールが実装された状態でのエラーチェックを可能としている。
(もっと読む)
メモリトレース装置及び方法
【課題】 実行時間を増大させることなく、効率よくマイクロコンピュータのメモリをトレースする。
【解決手段】 複数の命令ユニット104と、命令コードに該当する命令ユニットを選択する命令デコーダ103と、命令コードが扱うデータを格納する汎用レジスタ105とを有し、さらに、命令ユニット毎に例外を発生させるか否かを設定するステータスフラグを記憶するステータスレジスタ111と、プログラムに記述されたステータスフラグの状態を設定する設定コードに従いステータスフラグを更新するステータス更新部110と、命令ユニットが選択された時点で、命令ユニットに対応するステータスフラグをチェックし、ステータスフラグがオン状態の場合に例外を発生する命令ユニット毎に設けられた例外発生部121と、例外が発生したか否かを監視し、例外が発生した時点で汎用レジスタ105に格納されたデータをデータ記憶領域12に書き込む。
(もっと読む)
ポリシ型管理装置、方法、及び、プログラム
【課題】 ポリシ記述の適用により、問題が発生することを未然に防ぐことができるポリシ型管理装置を提供する。
【解決手段】 モデル管理器113は、管理対象システム13の状態を表す情報モデルを作成する。命令定義解釈器114は、ポリシ記述の適用条件が成立すると、管理対象システム13に対する作用を情報モデルに対する作用として記述した命令定義記述を情報モデルに対して適用する。モデル検査器115は、検査規則記憶部123を参照し、酩酊定義記述適用後の情報モデルが、検査規則を満たすか否かを判断する。検査規則を満たす場合には、命令実行器116は、ポリシ記述の作用を、管理対象システム13に適用する。
(もっと読む)
印刷システムにおける発生文脈反映型不具合対処方法及び装置
【課題】マーキングシステム例えばプリンタ・印刷システムにて不具合が発生し診断メッセージが表示されたときにユーザがフラストレーションを感じることを防ぎ又はそのレベルを抑えることが可能な方法及び装置を実現する。
【解決手段】マーキングシステムの動作中に不具合が発生したとき使用状態情報をログしてテーブル化し(202)、そのログに基づきトレンド解析を実行して(204)診断メッセージを表示する(206)ことにより発生文脈反映型不具合対処を実現する。そのため、不具合の種類毎に求めた発生頻度が所定条件を満足していない場合はその不具合の症状に関する第1診断メッセージを表示させ、満足していればこれに代えて又はこれと共に別の第2診断メッセージ即ちその症状の根本原因に関するメッセージを表示させる。ユーザが根本原因に直截に導かれるためフラストレーションを(さほど)感じない。
(もっと読む)
店頭端末装置、障害案内表示方法及び障害案内表示プログラム
【課題】顧客に不快感を与えることなく発生した障害の内容を知らせる。
【解決手段】CPU72が、障害の発生を検知すると(S11)、発生した障害を項目に分類し、その障害項目に対応する障害レベルをHDD75から特定し、発生した障害に対応する障害レベルと、障害対応レベル設定画面で設定された障害対応レベルとを比較する。そして、発生した障害に対応する障害レベルが発生した障害に対応する障害対応レベル以上であるか否かを判断する(S12)。“YES”の場合、店頭端末装置によるサービスを停止する旨の案内を表示する障害案内画面であるサービス停止画面を表示装置80に表示する(S13)。“NO”の場合、店員を呼び出す必要がある旨の案内を表示する障害案内画面である店員呼び出し画面を表示装置80に表示する(S14)。
(もっと読む)
仮想計算機制御方法
【課題】仮想計算機移動の際の構成の再設定の煩雑さを解消するとともに、仮想計算機および仮想計算機制御プログラムの移動、複製あるいは保存を行うことによってシステムの可用性を向上する。
【解決手段】実計算機で稼動中の仮想計算機および仮想計算機制御プログラムを一時停止させ、一時停止させた仮想計算機および仮想計算機制御プログラムの状態をデータ情報としてデータ化し、データ化された仮想計算機および仮想計算機制御プログラムの状態に関するデータ情報を情報伝達手段を介して他の実計算機に転送し、他の実計算機において転送された仮想計算機および仮想計算機制御プログラムの状態に関するデータ情報に基づいて仮想計算機および仮想計算機制御プログラムを構築する。
(もっと読む)
WWWサーバ障害時の代理応答装置及び代理応答装置を備えたWWWサーバ装置
【課題】サーバ最小構成である小規模のサーバ装置1台に対して、そのサーバ装置と独立に動作する代理応答装置をPCIボードとして当該サーバ装置に組み込み、サーバ装置の障害検知を行わせることでサーバ装置の高信頼化を図ること。
【解決手段】主系202のインCPU、LANコントローラと独立して動作可能なローカルCPU211、代替LANコントローラ215を一体化した代理応答装置をPCIボードとして搭載し、主系のハードウェア障害監視にセンサIC216を搭載する。リアルタイムな外部障害情報方法として、WWWサーバ正常時・障害時において、管理者226は常時稼動している代替LANコントローラ215へのアクセスを可能とし、専用Webアプリケーション212の組み込んで、主系202の稼動情報の収集機能を持たせる。また、一般ユーザ223には主系の障害時に当該障害の情報を提供する。
(もっと読む)
ゲストOSデバッグ支援方法及び仮想計算機マネージャ
【課題】ゲストOSに対する従来にはない優れたデバッグ環境を実現し、より効果的にデバッグが行えるように支援できるようにする。
【解決手段】VMM(仮想計算機マネージャ)は、第1のゲストOSが動作する第1の仮想計算機実行環境とは異なる第2の仮想計算機実行環境を構築する(S2)。VMMは、第1のゲストOSを、当該第1のゲストOSの実行状態及び当該第1のゲストOSが使用するメモリの状態を含めて、第2の仮想計算機実行環境にコピーすることにより、第1のゲストOSのコピーである第2のゲストOSを第2の仮想計算機実行環境に生成する(S3)。このときVMMは、第2の仮想計算機実行環境に生成された第2のゲストOSを停止状態にして当該第2のゲストOSの状態を保存する。
(もっと読む)
画像システム
【課題】 携帯電話機など携帯端末装置を用いて、簡単にすばやく対応でき、より利便性の高い異常対処をおこなうことができる画像システムを提供する。
【解決手段】 エラーコードを表示できる画像処理装置の異常対処をおこなう画像システムにおいて、そのエラーコードに対応したエラー対処方法が記憶されているデータベース2をサーバー装置1側に備え、画像処理装置に異常が発生し、その画像処理装置の表示手段にエラー発生理由ごとに決められた所定のエラーコードが表示され、そのエラーコードが携帯端末装置3に入力されたとき、その携帯端末装置3はそのエラーコードをメールによりサーバー装置1へ送信し、そのエラーコードを受信したサーバー装置1はそのエラーコードに対応したエラー対処方法記載の情報をデータベース2から検索し、該当するエラー対処方法記載のメールを携帯端末装置3へ送信する構成にした。
(もっと読む)
1 - 17 / 17
[ Back to top ]