
Fターム[5B057BA04]の内容
Fターム[5B057BA04]の下位に属するFターム
超音波 (292)
Fターム[5B057BA04]に分類される特許
1 - 16 / 16
画像処理装置、その処理方法及びプログラム
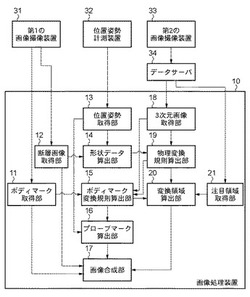
【課題】
対象物体が表示されたボディマーク上に、異なる形状で撮像された当該対象物体における注目領域を合成して表示できるようにした技術を提供する。
【解決手段】
画像処理装置は、第1の形状の対象物体を表すボディマーク上に該対象物体における注目領域の位置を表示する。ここで、画像処理装置は、第1の形状とは異なる第2の形状の対象物体の画像を取得する画像取得手段と、第2の形状の対象物体における注目領域の位置を、第1の形状の前記対象物体における対応位置に変換する変換手段と、当該変換された注目領域の位置をボディマーク上に表示する合成手段とを具備する。
(もっと読む)
情報処理装置、情報処理方法及び情報処理プログラム

【課題】本発明は、同一人物が写っている画像を的確に分類する。
【解決手段】本発明は、人物を撮影して生成された動画像データを取得して、当該取得した動画像データに基づく動画像に写っている人物を検出し、その検出した人物を特定すると共に、当該検出した複数の人物の関係を判別するようにして、動画像から検出した複数の人物のうち、少なくとも一人の人物を特定し、他の人物を特定し得ないときには、判別した当該複数の人物の関係と、記憶媒体28に記憶された、複数の人物の関係を示す人物関係情報とに基づき当該他の人物を特定することにより、動画像から検出した人物が、他の動画像から検出した人物と顔つきの変わっている同一人物であっても、人物同士の関係に基づいて、当該動画像から検出した人物を、他の動画像から検出した人物と同一人物として特定することができ、同一人物が写っている動画像を的確に検索し得る。
(もっと読む)
情報処理装置、情報処理方法、およびプログラム
【課題】動画像を用いた読唇技術において、不特定話者の発話内容を高い精度で認識する。
【解決手段】発話認識装置10は、学習処理を実行する学習系11、登録処理を行う登録系12、および認識処理を行う認識系13から構成される。学習系11では、口形素ラベルが付加された唇画像を学習サンプルとし、入力された唇画像に対応する口形素を判別する口形素判別器31が生成される。登録系12では、登録用発話単語を話す話者の唇の動きに対応する時系列特徴量が生成されてモデル化されて登録される。認識系13では、話者の動画像から時系列特徴量が生成されて、登録されているモデルと比較され、発話内容が認識される。本発明は、話者をビデオ撮影した動画像から、その発話内容を認識する場合に適用することができる。
(もっと読む)
国籍判定装置、方法およびプログラム
【課題】個人の人種・形質のような生物学的特性、民族といった文化人類学的特性、発声した言語の属する母国語ないし方言といった言語学的特性その他の個人の外部的特徴を客観的に測定し、その測定結果に基づいて個人の国籍を自動的・総合的に判定し、それに応じたアクションを実行する。
【解決手段】国籍判定装置5は、画像解析装置2または音声解析装置4による個々の解析結果に対応する国籍情報を国籍情報DB6から抽出する。次に、国籍判定装置5は、国籍情報DB6から抽出された個々の国籍情報に基づいて人物の最終的な国籍を判定する。これは例えば、各解析結果に対応する個別の国籍情報に優先度を予め国籍情報DB6などの記憶媒体に定義しておき、最も高い優先度を有する個別の国籍情報を最終的な国籍とする。
(もっと読む)
画像認識アルゴリズム、それを用いて目標画像を識別する方法、および、携帯用電子装置へ送信するデータを選択する方法
【課題】カメラの視野内にある人の位置および物体を示すパラメータである文脈情報(位置および方向のような)に基づいて、画像および映像内に対象物体を提供し、かつ一致させる。
【解決手段】画像認識アルゴリズムは、キーポイントに基づく比較および領域に基づく色彩比較を含む。画像認識アルゴリズムを用いて目標画像を識別する方法は、処理装置で入力を受信する段階であって、その入力は、目標画像に関連するデータを含む段階、画像を画像データベースから検索することを含む検索ステップを実行する段階であって、その画像が受理または拒絶されるまで、その画像を候補画像として指定する。画像認識アルゴリズム出力を得るために、目標画像および候補画像上で画像認識アルゴリズムを実行するために、処理装置を使用することを含む画像認識ステップを実行する。
(もっと読む)
撮像装置、画像検出装置及びプログラム
【課題】被写体の検出精度の向上を図る。
【解決手段】被写体を撮像して主要被写体を含む被写体画像の画像データを取得する撮像部1と、被写体画像内の主要被写体である人物から発せられた音声を集音する集音部6とを備える撮像装置100に、撮像部により取得された画像データ及び集音部により集音された音声に基づいて、被写体画像内の主要被写体を検出する処理を行うCPU71を備え、CPUは、集音部により集音された音に基づいて主要被写体の属性を特定し、当該属性に基づいて、検出すべき当該主要被写体の検出基準を変更する。
(もっと読む)
超音波診断装置
【課題】対象組織の全体的な形状を極力維持しつつ対象組織の輪郭を適切に抽出する。
【解決手段】輪郭形成部18は、超音波を介して得られる受信信号に基づいて、対象組織の輪郭を示す原輪郭データを形成する。輪郭修正部20は、原輪郭データを楕円に基づいたフーリエ級数に展開して得られる所定の低次数までのフーリエ級数により全容輪郭データを形成する。次に、輪郭修正部20は、原輪郭データに対応した領域と全容輪郭データに対応した領域との論理和により得られる合成領域に対応した合成輪郭データを形成する。そして、輪郭修正部20は、合成輪郭データを楕円に基づいたフーリエ級数に展開して得られる所定の高次数までのフーリエ級数により修正輪郭データを形成する。
(もっと読む)
データ品位を向上する方法及びシステム
【課題】シーンまたは信号を表現する画像データ、ビデオデータ、及び音声データの品位(例えば解像度)を、シーンまたは信号の同一部分の高品位表現及び低品位表現上で学習させた品位向上関数によって品位向上させる。
【解決手段】学習アルゴリズムは、シーンまたはシーンの一部分の低品位画像を、同じシーンまたはシーンの一部分の高品位画像と共に用いて、品位向上関数のパラメータを最適化する。次に最適化した品位向上関数を用いて、シーンまたはシーンの一部分の他の低品位画像を品位向上させる。信号の一部分の低分解能サンプル、及び同じ信号部分の高分解能サンプルを用いて品位向上関数を学習させ、そしてこの品位向上関数を用いて信号の残り部分を品位向上させることによって、音声データを品位向上させる。
(もっと読む)
超音波撮像装置
【課題】超音波画像の鮮明度が不足する場合にも、治療前のリファレンス画像との位置ずれを補正することが可能な超音波撮像装置を提供する。
【解決手段】被検体の被識別位置を識別するための位置識別デバイス1と、前記被識別位置の位置情報を含む、前記被検体の断層画像データを作成する断層画像作成部6と、前記被検体に超音波を送受信するプローブ2と、前記プローブ2が受信した超音波に基づいて複数の超音波画像データを作成する超音波画像作成部3と、前記複数の超音波画像データから、前記被識別部位を含む超音波画像データを選択する画像選択部7と、前記断層画像データと前記被識別部位を含む超音波画像データとについて、前記被識別部位で位置合わせをする画像処理部4と、前記画像処理部の処理結果を表示する表示部5を有する画像処理システム。
(もっと読む)
情報処理装置、情報処理方法、及びプログラム
【課題】ユーザが煩雑な行動をしなくても、ユーザに適切なサービスを提供する。
【解決手段】オペレータ確率算出部42は、状態を検知するセンサ部41の出力に基づいて、周囲に存在するユーザである1以上のターゲットそれぞれが、HDレコーダ3を操作するオペレータであるオペレータ確率を算出する。インタラクション部14や番組推薦部15は、オペレータ確率に基づいて、所定の処理を行う。すなわち、例えば、オペレータ確率が最も高いターゲットの行動に対応したアクションや、そのターゲットの嗜好に合致した番組の推薦が行われる。本発明は、例えば、ユーザとのインタラクションを通じて、各種の処理を行うインタラクション装置に適用できる。
(もっと読む)
画像処理方法
【課題】撮影画像、特に人物画像において、その人物の感情の種類に応じて、強調したい内容を視覚化して、画像形成を行うようにして、写真、ビデオ、TV電話等の画像形成媒体における娯楽性を高める。
【解決手段】撮影画像に付属する音声データ、あるいは撮影画像中から抽出された人物の表情、または抽出された人物のジェスチャー、のうちの少なくとも1つの情報に基づいて、予め登録された感情の種類を判定し、予め設定された画像処理パターンのうち判定された感情の種類に対応する画像処理パターンを適用した画像処理を、撮影画像に対して行う。
(もっと読む)
第2の対象物に対する第1対象物の相対位置を決定する方法及びシステム及び、対応するコンピュータプログラム及び対応するコンピュータ可読記録媒体
本発明は、第2の対象物に対する第1の対象物の相対位置を決定する方法及びシステム、並びに対応するコンピュータプログラム及び対応するコンピュータ可読記録媒体に関する。この発明は、特に、多様な複雑性を有する環境において、測定装置の空間的な位置及び方向を決定することに使用することが出来る。
コンピュータシミュレーションで対象物の相対位置を決定し、そうして決定された位置及び方向に関するバーチャル座標から、対象物の位置及び方向の実際の座標を決定することを提案する。  (もっと読む)
(もっと読む)
カラオケシステム
【課題】少なくとも、歌い手の表情を反映させた画像および音声を楽しむことができるカラオケシステムを提供。
【解決手段】ネットカラオケシステム10は、中継サーバ14の情報管理部106で複数の端末装置から歌う要求を受信し歌う順番を設定しこの歌う順番により歌い手側に指定された端末装置から第1歌唱情報22を受信し、この端末装置からの情報に含まれる選曲した楽曲に対応したカラオケデータ130を歌い手の端末装置に配信し、聞き手側の端末装置に第2歌唱情報126および130を配信し、第1の端末装置にてカラオケおよび歌唱による音、ならびに画像から抽出された表情パラメータを中継サーバ14から聞き手側の端末装置に送り、背景付モデルの画像に表情パラメータを活かし連続的に生成し、カラオケ演奏と歌を音声とし出力する。
(もっと読む)
CPA算出方法、CPA算出装置および画像処理装置
【課題】グラム表示からCPA算出までの一連の操作を自動化できるようにし、これにより操作員の負荷の軽減を図ったCPA算出方法、CPA算出装置および画像処理装置を提供すること。
【解決手段】音響グラム表示画像データを二値化したうえで画素膨張処理を施し、でシフト領域を前処理する。次に、前処理されたシフト領域の境界線を追跡してシフト領域を分割したのち、分割されたシフト領域を細線化処理してデジタルラインとする。次に、得られたデジタルラインを線分近似したのち上限周波数F1、下限周波数F2、中心周波数F0を求め、これらのパラメータを用いてCPAレンジRdを算出する。
(もっと読む)
情報処理装置、情報処理方法及びプログラム
【課題】 見逃しシーン又は聞き逃しシーンを効率的に振り返ることができる情報処理装置を提供する。
【解決手段】 情報検索システム1は、所定の空間を撮影した映像情報に同期された人物の生体情報に基づいて、所定の人物の注視対象を判定する注視対象判定部10と、映像情報に同期された音声情報に基づいて、音圧対象を判定する音圧対象判定部11と、人物の注視対象と音圧対象に基づいて、映像情報内の見逃しシーン又は聞き逃しシーンに対して索引を付与する索引付与部12と、索引付与部12によって付与された索引を参照して、見逃しシーン又は聞き逃しシーンを検索する検索部16と、検索部16によって検索された見逃しシーン又は聞き逃しシーンを表示する表示制御部17とを備える。
(もっと読む)
情報変換装置及び情報変換方法、並びに通信装置及び通信方法
【課題】 通信手段を介してユーザが他者とコミュニケーションする場合に、ユーザが感じるストレスを減らすことができるようにする。
【解決手段】 通信部13が音声情報を受信して距離感表現部14に供給する。距離感表現部14は、通信部13から供給される相手の音声情報に含まれる感情情報を、情報入力部11から供給される距離感情報に応じて制御した後、情報入力部11から供給される距離感情報に応じた位置に出力音声が音源定位されるように、感情情報が制御された相手の音声情報を変換し、音声出力部15に供給する。音声出力部15は、距離感表現部14から供給される音声情報に基づき音声を出力する。
(もっと読む)
1 - 16 / 16
[ Back to top ]