
Fターム[5B075ND03]の内容
Fターム[5B075ND03]に分類される特許
21 - 40 / 3,390
ミニブログ解析装置及び方法
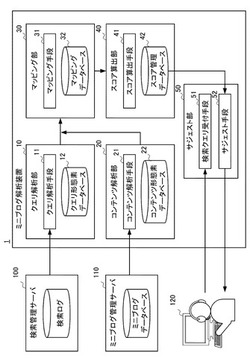
【課題】ミニブログ内における注目度の高い話題を正確かつ自動的に抽出すること。
【解決手段】ミニブログ解析装置(1)は、検索ログに記憶される複数のクエリから様々な長さからなるクエリ形態素を生成するクエリ解析手段(11)と、複数のクエリ毎に、生成されたクエリ形態素に基づいてミニブログ内のコンテンツを検索し、様々な長さからなるクエリ形態素のうちコンテンツに含まれる最も長いクエリ形態素を当該コンテンツに対して対応付けるマッピング手段(31)と、コンテンツに対応付けられたクエリ形態素を含むミニブログ内のコンテンツの数に基づいて、ミニブログ内における当該クエリ形態素の注目度を算出するスコア算出手段(41)と、を備える。
(もっと読む)
文書管理装置、文書管理方法、プログラム。

【課題】 全文検索時に文書テンプレートに含まれる文言によらない、適切な検索結果を提示可能な文書管理システムを提供する。
【解決手段】 登録されている文書の全文検索が可能な文書管理システムであって、文書テンプレートと文書テンプレートに基づいて作成された文書とを対応付けて登録するメイン制御部301と、登録された文書に検索語が含まれているかどうか検索する文書検索部305と、検索語の含まれている文書を検索結果として、検索語が文書テンプレートにのみ含まれている文書と、検索語が文書テンプレート以外の部分にも含まれている文書とを識別可能に表示する入出力管理部302とを有する。
(もっと読む)
電子書籍装置、オブジェクト表示方法、およびプログラム
【課題】今後、登場するオブジェクトを把握できなかった。
【解決手段】電子書籍に対するオープン指示やページめくり指示などの読書行為指示に対応した読書履歴情報を取得する読書履歴情報取得部と、1以上の読書履歴情報から、既読の箇所を特定する情報である1以上の既読箇所情報を取得する既読箇所情報取得部と、1以上の既読箇所情報から、既読の箇所に出現した一の種類のオブジェクトである1以上の出現オブジェクトを取得する出現オブジェクト取得部と、1以上の既読箇所情報から、未読の箇所に出現する一の種類のオブジェクトである1以上の未出現オブジェクトを取得する未出現オブジェクト取得部と、1以上の出現オブジェクトと1以上の未出現オブジェクトとを異なる表示態様で表示するオブジェクト表示部とを具備する電子書籍装置により、今後、登場するオブジェクトを把握できる。
(もっと読む)
特徴量算出装置、文書類似度算出装置、特徴量算出方法およびプログラム
【課題】文書間の類似度を算出するために用いられる文書の特徴量を適切に算出する技術を提供する。
【解決手段】文書類似度算出装置10は特徴量算出装置(部)100を有し、特徴量算出装置100は単語間類似度情報記憶部194とtf−idf算出部110と特徴量ベクトル算出部130とを有する。単語間類似度情報記憶部194は、外部の文書の単語又はユーザによって設定された単語を含む単語間の類似度を示す単語間類似度情報を記憶する。tf−idf算出部110は、文書を構成する各単語のtf−idfを算出する。特徴量ベクトル算出部130は、tf−idf算出部110によって算出された上記文書を構成する各単語のtf−idfと、単語間類似度情報記憶部194に記憶されている単語間類似度情報とに基づいて、上記文書の特徴量ベクトルを算出する。
(もっと読む)
文書要約装置、方法、およびプログラム
【課題】要約内容の劣化や要約率の低下を回避しつつ、秘密文書から公開可能な要約を作成する。
【解決手段】重要文抽出部14Aで、入力された原文書から重要文を抽出し、秘密事項判定部14Bで、これら重要文に秘密事項が含まれるかを判定し、隠蔽処理部14Cで、秘密事項を含むと判定された重要文から当該秘密事項が含まれない隠蔽文を作成し、文圧縮部14Dで、秘密事項が含まれないと判定された重要文、および隠蔽処理部で作成された隠蔽文について、それぞれの文長を削減する。
(もっと読む)
単語抽出装置、単語抽出方法及びプログラム
【課題】辞書を用いずに、テキストに頻出する単語を精度良く抽出する。
【解決手段】単語抽出装置1は、文字数が所定文字数以上の文字列であって、テキストに所定回数以上出現する文字列を対象文字列として前記テキストから抽出する対象文字列抽出部と、他の対象文字列の部分文字列であって、前記テキストにおいて前記他の対象文字列に包含される位置以外に出現する回数が前記所定回数より小さい文字列を前記対象文字列抽出部により抽出された対象文字列の集合から削除する第1の削除部と、前記第1の削除部により文字列を削除した後の対象文字列の集合に含まれる文字列を単語とする単語抽出部とを備える。
(もっと読む)
電子書籍装置、サーバ装置、読書情報処理方法、およびプログラム
【課題】読書履歴情報を用いてコミュニケーション支援ができなかった。
【解決手段】電子書籍の読書行為指示を受け付ける受付部と、読書行為指示に応じて電子書籍を表示する電子書籍表示部と、読書行為指示に応じて表示している電子書籍のページをめくるページめくり部と、読書行為指示に応じて読書履歴情報を取得する読書履歴情報取得部と、読書履歴情報を蓄積する読書情報蓄積部と、他人の1以上の読書履歴情報を受信する読書情報受信部と、読書情報受信部が受信した他人の1以上の読書履歴情報と、格納されている1以上の読書履歴情報とから、ユーザと他人との読書に関する関連を示す情報である1以上の関連読書情報を取得する関連読書情報取得部と、1以上の関連読書情報を表示する関連読書情報表示部とを具備する電子書籍装置により、読書履歴情報に基づいて、他人とコミュニケーションをとることを支援できる。
(もっと読む)
携帯可能電子装置、携帯可能電子装置の処理装置、及び携帯可能電子装置の処理システム
【課題】 より簡易で且つ高速に処理を行うことができる携帯可能電子装置、携帯可能電子装置の処理装置、及び携帯可能電子装置の処理システムを提供する。
【解決手段】 一実施形態に係る携帯可能電子装置は、レコード構造でレコードデータを記憶する記憶部と、外部機器から送信されたコマンドを受信する受信部と、前記受信部により受信された前記コマンドを解析し、比較対象データを取得する解析部と、前記解析部により取得された前記比較対象データに基づいて、前記記憶部により記憶されている前記レコードデータを抽出する抽出部と、前記抽出部の結果に基づいて、前記コマンドに対するレスポンスを生成するコマンド処理部と、前記コマンド処理部により生成された前記レスポンスを前記外部機器に送信する送信部と、を具備する。
(もっと読む)
検索装置、検索装置の制御方法及び検索装置の制御プログラム
【課題】オペレータによる管理負担を増大させることなく、高精度な文字列の正規化を実現すること。
【解決手段】文書の情報から索引となる文字列を抽出して検索対象の情報として格納する登録処理部201と、検索条件を生成する検索条件作成部205と、検索条件に基づいて検索対象の情報を検索する検索処理部206と、入力された文字列を単位文字列に分割すると共に、分割された単位文字列を代表表記に変換する文字列処理部203とを含み、登録処理部201は、文書の情報を文字列処理部203に入力し、代表表記に変換された単位文字列を索引となる文字列として抽出し、検索条件作成部205は、文字列を文字列処理部203に入力し、代表表記に変換された単位文字列に基づいて検索条件を生成し、文字列処理部203は連続して配置されている単位文字列を連結した連結文字列をも代表表記に変換することを特徴とする。
(もっと読む)
構造化文書管理装置、方法およびプログラム
【課題】構造照合処理を高速に行うことができる構造化文書管理装置、方法およびプログラムを提供することである。
【解決手段】実施形態の構造化文書管理装置は、入力されたクエリデータが、構造化文書データの論理構造における階層の上下関係を指定する第1条件と、要素IDで特定される要素の順序関係を指定する第2条件とを含む場合に、クエリデータ分解手段が、該クエリデータを、第1条件のみを含む第1の部分クエリデータと、第1の部分クエリデータによる照合結果を、第2条件に応じて結合演算する手順を含む第2の部分クエリデータとに分解する。構造照合処理手段は、構造化文書データのデータ集合に対して第1の部分クエリデータによる照合を行い、照合結果を出力する。結合演算処理手段は、構造照合処理手段から出力された照合結果を、第2の部分クエリデータに含まれる結合演算の手順に従って結合演算処理する。
(もっと読む)
話題抽出装置及びプログラム
【課題】指定した対象期間において、話題の変遷を提示する。
【解決手段】一つの実施形態によれば、話題抽出装置は、話題抽出手段及び話題提示手段を備えている。前記話題抽出手段は、単語抽出手段及び話題語抽出手段を備えている。前記単語抽出手段は、対象文書集合から各単語を抽出し、当該各単語の出現頻度及び当該各単語が出現する文書頻度を算出する。前記話題語抽出手段は、前記抽出された各単語について、前記対象期間における出現文書の文書集合を取得し、話題語らしさを表す尺度である話題度を算出し、前記話題度が所定の値以上の単語を話題語として抽出すると共に、当該抽出された話題語について当該対象期間における出現日時に基づいて新鮮度を算出する。前記話題提示手段は、前記抽出された話題語を前記新鮮度の順に提示すると共に、当該提示した各話題語について単位期間毎の出現文書数を提示する。
(もっと読む)
検索装置、プログラム及び方法
【課題】高速に類似する文字列の検索を行う。
【解決手段】本装置は、検索対象文字列の第1検索用データと、1以上第1所定文字数以下の整数Nの各々について各検索対象文字列におけるN文字以降の文字の順番を入れ替えた反転文字列についての第2検索用データを格納するデータ格納部と、第1検索用データに対して検索文字列の前方一致検索を行って、第2所定文字数以上前方一致する検索対象文字列を検出する第1検索部と、検索文字列における整数M文字以降の文字の順番を入れ替えた検索キーの前方一致検索を、整数Mについての第2検索用データに対して行って、第2所定文字数以上前方一致する反転文字列を検出し、整数M-2文字一致した反転文字列が存在するか否かを判断する第2検索部と、第2検索部に対して、第2所定文字数から整数Mについての検索指示を、第2検索部により整数M-2文字一致した反転文字列が存在しないと判断された直後を除き出力する制御部とを有する。
(もっと読む)
入力支援プログラム,入力支援装置および入力支援方法
【課題】ユーザによる文例を修正する操作において,ユーザの操作負担を軽減する技術を提供する。
【解決手段】入力支援部10の文例修正部100において,抽出部101は,編集対象の文書からユーザが指定した文字列を受け付ける。抽出部101は,辞書記憶部11の文例辞書から,指定文字列を含む置換候補文例を抽出する。提示部105は,ユーザに対して,置換候補文例を画面で提示する。検出部103は,ユーザが文字列を指定した位置にある編集対象の文書中の文例を検出する。置換部106は,ユーザが置換候補文例から選択した置換対象文例を受け付ける。置換部106は,検出された編集対象の文書中の文例を,置換対象文例に置き換える。
(もっと読む)
自然言語バンキング処理サーバ及び自然言語バンキング処理方法
【課題】ミニブログ等に入力した自然言語テキストをそのまま銀行等の金融機関のネット取引に利用することのできるシステムを提供する。
【解決手段】自然言語バンキング処理サーハは、インターネットに接続されたミニブログ等の自然言語入力手段から自然言語テキストを受信する。受信した自然言語テキストを形態素解析し、金融機関の取引に用いられるキーワードを予め登録したキーワードDBを用いて所定のキーワードを抽出する。そして、抽出したキーワードと、取引を行なおうとするユーザの登録情報に基づいて、金融取引の要求データを生成し、専用ネットワークで接続された金融機関のシステムに送信する。取引の要求が完了した際には、ユーザへの返信のための自然言語テキストを生成して自然言語入力手段に返信する。
(もっと読む)
情報処理装置、自然言語解析方法、プログラムおよび記録媒体
【課題】 係り受け構造を有する照会パターンに対する文のマッチング・スコアを演算すること。
【解決手段】 本発明の情報処理装置100は、解析対象の文150と、照会パターン160と、上記文内の言語単位間の係り易さを指標する指標値170とを入力として取得する入力部110と、文が照会パターンにマッチする程度を指標するマッチングのスコアを、上記照会パターン160に含まれる各係り受け関係が対応付けられる各指標値を少なくとも変数とする関数で表して演算するスコア演算部120とを含む。スコア演算部120は、上記照会パターンの部分構造と文の範囲との対応付けを試行して、上記関数の部分演算結果を、再利用するため記憶領域130に格納しながら、この部分構造および範囲の内部に関して再帰的に演算することによって、上記スコアを算出する。
(もっと読む)
集合拡張処理装置、集合拡張処理方法、プログラム、及び、記録媒体
【課題】意味的に同一のカテゴリに含まれる語を選択するのに好適な集合拡張処理装置等を提供する。
【解決手段】受付部101がシード文字列を受け付ける。検索部102がシード文字列を含む文書のスニペットを得る。セグメント取得部103が当該スニペットをセグメント区切文字列で区切ってセグメントを得る。セグメント要素取得部104がセグメントをセグメント要素区切文字列で区切ってセグメント要素を得る。セグメントスコア計算部105がセグメントのセグメントスコアをセグメント要素の長さの標準偏差から計算する。セグメント要素スコア計算部106がセグメント要素のセグメント要素スコアをシード文字列の位置とセグメント要素の位置との距離とセグメントスコアから計算する。選択部107がセグメント要素スコアに基づいてセグメント要素からいずれかをシード文字列の拡張集合に含まれるインスタンスの候補として選択する。
(もっと読む)
電子書籍提供サーバ、および電子書籍提供プログラム
【課題】ユーザにとって有効な地域情報を提供する。
【解決手段】電子書籍を表示する電子書籍端末100に電子書籍情報を提供する電子書籍提供サーバ301〜30Nが、観光地など所定の範囲を示す緯度経度情報とタグとが対応付けされた情報である観光地ポリゴン情報を記憶する観光地ポリゴン情報管理DB211と、タグが付与された電子書籍情報を記憶する電子書籍情報管理DB212と、タグが付与された任意の文字列を示す文字列情報を記憶する文字列情報管理DB213とを備え、電子書籍端末100に電子書籍情報を送信し、観光地ポリゴン情報に基づいて、文字列情報管理DB213に記憶された文字列情報の中から、送信される電子書籍情報に付与されたタグと対応するタグが付与された文字列情報を関連文字列情報として検索し、検索した関連文字列情報を電子書籍情報と対応付けて電子書籍端末100に送信する。
(もっと読む)
データ分析支援装置およびプログラム
【課題】任意のデータテーブル間において適切な属性の対応づけを行うことが可能なデータ分析支援装置およびプログラムを提供することにある。
【解決手段】第1の単語抽出手段は、第1のデータテーブルを構成する第1の文字列型属性が有する属性値から第1の単語を抽出する。第2の単語抽出手段は、第2のデータテーブルを構成する第2の文字列型属性が有する属性値から第2の単語を抽出する。類似度算出手段は、第1の抽出手段によって抽出された第1の単語および第2の抽出手段によって抽出された第2の単語に基づいて、第1のデータテーブルを構成する第1の文字列型属性および第2のデータテーブルを構成する第2の文字列型属性の類似度を算出する。類似属性候補抽出手段は、類似度算出手段によって算出された類似度に基づいて、第1の文字列型属性および第2の文字列型属性を類似属性候補として抽出する。
(もっと読む)
代表文抽出装置およびプログラム
【課題】文タイプを考慮して文書群において頻度の高い内容を表す代表文を抽出することが可能な代表文抽出装置およびプログラムを提供することにある。
【解決手段】解析手段は、入力手段によって入力された複数の文書を構成する文が表された構造木であって当該文の文タイプが付与された構造木を生成する。代表文候補抽出手段は、構造木に付与された文タイプに対応づけて抽出ルール格納手段に格納されている抽出ルールに従って当該文タイプが付与された代表文候補を抽出する。文生成手段は、抽出された代表文候補に付与された文タイプに対応づけて文生成ルール格納手段に格納されている文生成ルールに従って当該文タイプが付与された代表文候補文を生成する。集約手段は、同一の代表文候補文を1つに集約して集約代表文候補文を生成する。決定手段は、生成された集約代表文候補文に集約された代表文候補文の数に基づいて代表文を決定する。
(もっと読む)
ロシア語検索装置およびプログラム
【課題】電子辞書等によるロシア語検索装置において、アルファベット文字の入力からロシア語辞書の見出し語を容易且つ迅速に検索することを可能にする。
【解決手段】[英字キリル文字読み変換入力]モードを設定した検索語入力画面G1の英字検索語入力エリアAeにおいて、ロシア語の読みに応じた英字の文字列[lemon]を入力すると、当該入力された英字の文字列は英字キリル文字類似音声変換テーブルに従いキリル文字の文字列[лемон(第1候補)][лэмон(第2候補)]に変換される。そして、当該変換されたキリル文字の文字列と一致するロシア語の見出し語が[露和辞書]に存在するか否かスペルチェックに掛けられ、一致する見出し語が存在しない場合には、最も近似する見出し語と一致する検索文字列[лимон]に訂正された後、該当する見出し語の説明情報[лимон レモン」が読み出されて説明情報表示画面G2として表示される。
(もっと読む)
21 - 40 / 3,390
[ Back to top ]