
Fターム[5B075ND03]の内容
Fターム[5B075ND03]に分類される特許
101 - 120 / 3,390
情報検索システム、検索キーワード提示方法、およびプログラム
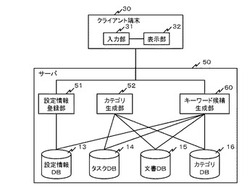
【課題】単語間の関連を保持する辞書や、ユーザが入力した検索キーワードと参照文書を記録するログ情報などを用いず、所望する情報を検索可能な検索キーワードの候補をユーザに提示できる情報検索システムを提供する。
【解決手段】情報検索システムは、検索対象の文書データを格納する文書データベースと検索対象の文書データに対するクラスタリング分析によるカテゴリ分類に関する情報を含むカテゴリ情報を格納するカテゴリデータベースとを備える。また、情報検索システムは、ユーザによって入力される検索キーワードを含む検索条件に基づいて文書データベースから文書データを検索し、検索した文書データがカテゴリのうちのどのカテゴリに属するかを判定し、検索した文書データが属すると判定されたカテゴリ、もしくは当該カテゴリの文書データから、キーワード候補を抽出し、抽出したキーワード候補をユーザに提示する。
(もっと読む)
発話抽出プログラム、発話抽出方法、発話抽出装置

【課題】対話時の発話から特定の発話を抽出する発話抽出プログラム、発話抽出方法、発話抽出装置を提供する。
【解決手段】第1の話者および第2の話者の発話区間を抽出して、日時または経過時間に関連付けて記録させる処理と、特徴操作記憶部を参照して、対話中に機器を第1の話者が操作した機器の状態を、日時または経過時間に関連付けて記録した操作情報から、特徴操作テーブルに合致する操作情報を抽出し、抽出した操作情報の発生した日時または経過時間を示す特徴操作時刻情報を取得させる処理と、発話抽出条件を参照して、発話抽出条件に合致する区間を、第1の話者および第2の話者の抽出した発話区間と抽出した特徴操作時刻情報を用いて抽出し、抽出した合致する区間から発話抽出条件に関連付けられている時間範囲に存在する第1の話者の発話区間に対応する発話を抽出させる処理と、をコンピュータに実行させる発話抽出プログラム。
(もっと読む)
検索装置、検索方法および検索プログラム
【課題】効率的な検索を行う技術の提供。
【解決手段】複数の登録名称のそれぞれに各登録名称を示すハングル文字を字母に分解した順列である蓄積順列が対応付けられて記録媒体に記録され、かつ、前記蓄積順列の一部を構成する部分順列が共通である前記蓄積順列の中から前記部分順列に従って字母を組み合わせた場合に当該部分順列の最後の字母でハングル文字が完成する前記蓄積順列を特定するための順列特定情報が記録媒体に記録される。そして、前記ハングル文字単位で前記検索対象が指定された後に前記字母単位で前記検索対象が指定された場合、前記順列特定情報を参照し、前記ハングル文字単位で指定された前記検索対象を字母に分解した順列を前記部分順列とした場合に当該部分順列の最後の字母でハングル文字が完成する前記蓄積順列を特定し、特定された前記蓄積順列に基づいて検索を行う。
(もっと読む)
検索装置、索引作成装置および検索システム
【課題】特徴ベクトル法を用いて演算量を抑制したあいまい検索を実現する。
【解決手段】入力データを部分文字列に分解する部分文字列分解部31と、部分文字列分解部31において分解された部分文字列をクラスタリングし、対応する特徴ベクトルを取得する特徴ベクトル変換部32と、検索対象データの特徴ベクトルと、入力データの特徴ベクトルとを照合して仮スコアを算出する特徴ベクトル照合部33と、特徴ベクトル照合部33が算出した仮スコアが上位の検索対象データとの部分文字列と、入力データの部分文字列とを照合して詳細スコアを算出し、当該詳細スコアが上位の検索対象データを検索結果として出力する詳細照合部34とを備える。
(もっと読む)
情報処理装置及びプログラム
【課題】ウェブページ等の特性に配慮した付加情報の記録・表示を可能とした情報処理装置を提供する。
【解決手段】実体情報とともに、当該実体情報の構造を規定する構造規定情報を含む文書を処理対象として、当該文書の構文解析を実行し、文書上の位置の指定とともに、当該指定された位置に付加する付加情報の入力を受け入れ、受け入れた付加情報を文書を特定する情報と、指定された位置を構造規定情報を用いて表す位置情報とに関連づけて記録するよう指示する情報処理装置である。
(もっと読む)
辞書機能を備えた電子機器およびプログラム
【課題】撮影画像に含まれる調べたい文字が、特殊な態様で書かれていたり字形が崩れていたりした場合でも、正しく文字認識させて同文字に対応する辞書情報を検索することが可能になる辞書機能を備えた電子機器を提供する。
【解決手段】ユーザが撮影した例えばノートや案内板などの画像データGをタッチパネル式表示部(メイン画面)16に表示させ、当該画像データGに含まれる任意の文字列「恒星」について、その一部の文字「恒」が汚れや字形の崩れにより「明」と誤認識された場合でも、当該誤認識された文字「恒」の画像を手書き入力部(サブ画面)15に表示させ、手書きで上書きして正しく再認識させ、容易に内蔵の辞書で見出し語検索しその説明情報Hを表示させることができる。
(もっと読む)
検索システム及び方法
【課題】検索対象の文字列項目の内容がユニークでないデータベース内の部分一致検索の処理負担を軽減し、高速な部分一致検索を実現すること。
【解決手段】検索システム(1)は、検索対象DB(101)から部分一致検索の対象となる文字列項目の内容(文字列)を重複を排除して抽出し、この抽出したユニークな文字列に対してユーザからの要求に基づく部分一致検索を実行する。そして、ユーザから受け付けた部分一致検索の条件式を、部分一致検索の結果得られた文字列項目の内容のみを検索するための完全一致検索の検索条件式に変換し、この変換後の検索条件式に基づいて、検索対象DB(101)に対する完全一致検索を実行する。
(もっと読む)
情報処理装置、情報処理方法、及びコンピュータプログラム
【課題】 複数の文字列をコンパクトに格納することができる簡潔木構造において、検索処理の計算コストを抑えた文字列登録検索装置及びその制御方法、文字列登録検索システム、プログラムを提供する。
【解決手段】 ダブル配列構造を構築してから簡潔木構造に変換する方法により、簡潔木構造において検索処理の計算コストを抑えた新たな簡潔木構造を実現する。
(もっと読む)
電子学習装置及びプログラム
【課題】複数のマーカ文字列を関連付けて学習する。
【解決手段】見出し語となる文字列と当該見出し語の説明文とを対応付けた文書を複数種類記憶する辞書・教科書データベース22Aと、該データベース22Aが記憶する複数の文書に対し、全文検索の検索キーワードとなる文字列の入力を受付けるキー入力部14と、入力された検索キーワードに基づいて該データベース22Aが記憶する複数種類の文書の説明文を全文検索し、検索キーワードと一致する文字列を含む説明文に対応付けられた見出し語をメイン画面17で表示し、検索で得られた検索キーワード及び見出し語の各文字列を関連付けてマーカ学習帳データ22Bに登録し、登録した内容に対するキー入力部14での表示の指示を受付け、その指示に従い、マーカ学習帳データ22Bで記憶した複数の文字列を関連付けに応じてメイン画面17で隣り合うように表示させるCPU21とを備える。
(もっと読む)
検索アルゴリズム評価システム
【課題】検索アルゴリズムを的確に評価することができる検索アルゴリズム評価システムを提供する。
【解決手段】評価装置60は、検索処理部63が検索処理を開始してから表示部53にその検索結果が表示されるまでの時間に基づいて、検索レスポンスの速さの指標となるレスポンス減損率を求めるレスポンス減損率算出部72と、文書ファイルの各々について予め与えられた評価フラグと前記レスポンス減損率とを用いて減損利得を算出する減損利得算出部73と、前記減損利得を累積加算し、ランキング表示の順位ごとに減損累積利得を求める減損累積利得算出部74と、理想条件で前記レスポンス減損率及び前記減損利得を算出すると共に、これに基づき理想減損累積利得を求める理想値算出部75と、前記理想減損累積利得と、前記減損累積利得との比に基づいて、検索アルゴリズムの評価値を導出するアルゴリズム評価部76とを備える。
(もっと読む)
画像処理装置、有識者情報蓄積方法および有識者情報蓄積プログラム
【課題】キーワードに関する知識を有するユーザを特定する。
【解決手段】MFPは、文書を処理するためのジョブを受け付けるジョブ受付部53と、ジョブを実行するジョブ実行部55と、ジョブ実行部により実行されたジョブの対象となった文書からキーワードを抽出するキーワード抽出部57と、ジョブ実行部によるジョブの実行に応じて、ジョブの対象となった文書から抽出されたキーワードと、ジョブの実行を指示した指示者を識別するユーザ識別情報または/およびジョブの対象となった文書の作成者を識別するためのユーザ識別情報とを含むジョブ履歴情報91を記憶するジョブ履歴記憶部116と、を備える。
(もっと読む)
情報処理装置、情報処理方法、及びコンピュータプログラム
【課題】 トライ構造における検索の高速性を保ちつつ、部分一致検索、前後一致検索を可能とするために、N-gram構造の特徴をさらに取り込んで文字列キーワード検索を行う技術を提供すること。
【解決手段】 登録キーワードとして入力されたキーワードを用いてトライ構造データ及びN-gramデータを作成する。そして検索時には、それら両方のデータを使用して検索キーワードとして入力されたデータが含まれる登録キーワードを検索する。
(もっと読む)
文書検索装置、文書検索方法及び文書検索プログラム
【課題】与えられたキーワードを含む電子文書の数(DF値)を、少ないメモリ使用量で高速に計算できる文書検索装置を提供する。
【解決手段】入力された複数の検索キーワードの各々の重要度を用いて、複数の文書から所望の文書を検索する文書検索装置であって、複数の文書の各々に含まれる文字列に対する接尾辞配列を構築し、接尾辞配列の各接尾辞と、各接尾辞と同じ文書に由来し、且つ、辞書順序で一つ前又は後の接尾辞と、を先頭の文字から順番に比較した場合に一致する文字の数を、各接尾辞に対応する要素とする整数配列を構築し、構築された整数配列において、入力された複数の検索キーワードの各々で始まる接尾辞に対応する要素のうち、検索キーワードの文字数より小さい値の要素の数を、当該検索キーワードを含む文書の数として算出し、算出された文書の数を用いて、当該検索キーワードの重要度を計算する。
(もっと読む)
携帯電子機器、表示方法および表示制御プログラム
【課題】入力文字をより有効に利用可能となり、有効な情報を表示させることができる携帯電子機器、表示方法および表示制御プログラムを提供することを目的とする。
【解決手段】表示部と、文字を入力するための操作部と、操作部による文字の入力が可能な第1アプリケーションと検索機能を有する第2アプリケーションとを実行可能であり、操作部の操作により第1アプリケーションで入力文字が入力されると、入力文字を検索条件として第2アプリケーションで検索を実行し、検索結果を前記表示部に表示させる制御部と、を有することで上記課題を解決する。
(もっと読む)
管理装置、管理方法、及びプログラム
【課題】フィルタの優先度の設定を変更することなく、フィルタ処理の工数を低減し得る、管理装置、管理方法、及びプログラムを提供する。
【解決手段】管理装置100は、機器210から受信したメッセージのメタデータから、出現頻度が閾値以上となるメタデータをキーワードとして抽出するキーワード分析部113と、メッセージを選別するフィルタ群を、キーワードに関連する第1のフィルタとこれ以外の第2のフィルタとに分け、キーワード毎の第1のフィルタグループと第2のフィルタグループとを作成するフィルタグループ作成部114と、受信したメッセージのメタデータが、抽出されたキーワードと一致するか判定し、判定結果に基づいて、適用するフィルタグループを選択するフィルタグループ振分け部115と、受信したメッセージに対して、選択されたフィルタグループを適用する、フィルタグループ適用部116とを備える。
(もっと読む)
検索装置、方法及びプログラム
【課題】あいまい検索の検索精度を向上させる。
【解決手段】本検索装置は、あいまい検索において検索対象となる複数のキーワードを格納するキーワード格納部と、キーワード格納部に格納されている複数のキーワードの各々について、当該キーワードを所定のルールに従い文節に分割した場合における文節数を算出し、算出された当該文節数又は当該文節数の分布に関するデータを文節データ格納部に格納する第1算出部と、文節データ格納部に格納されているデータを用いて、文節数の小さい順に出現回数を計数した場合に複数のキーワードの総数に対する当該出現回数の割合が所定割合に達した文節数又は当該出現回数が所定数に達した文節数を特定し、あいまい検索を実行する際の検索キーワードの文節数に決定する第2算出部とを有する。
(もっと読む)
イメージ可視化システム及び情報提供システム並びにそれらのコンピュータプログラム
【課題】入力単語間の連想的関係性を提示することができるイメージ可視化システムを提供する。
【解決手段】イメージ可視化システム1は、単語の入力部60と、単語同士の関係性が設定されたデータベース5と、データベース5の探索部61と、を備えている。探索部61は、入力単語W1,W2に関係する他の単語Wnを繰り返し探索する。探索された単語に基づいて、関連する単語同士がノードで接続された単語空間が生成される。単語空間の中から、入力単語W1,W2同士を結ぶノード経路が、複数個抽出され、さらに複数個のノード経路の中から、一のノード経路が選択される。システム1は、選択された一のノード経路上に含まれる単語又は当該単語に関連する情報を出力する。
(もっと読む)
情報表示装置及び情報表示プログラム
【課題】現在地の位置情報に対応する内容をコンテンツから適切に読み出して表示する。
【解決手段】電子辞書1は、各項目に対してテキストを対応付けた項目情報を複数含むコンテンツ70を複数種類記憶するROM80と、コンテンツ70毎に、位置情報に対応する位置対応キーワードを複数記憶したコンテンツ別−位置対応検索条件テーブル82と、検索対象のコンテンツ70を指定する入力部30と、GPS受信機50と、GPS受信機50により検知された現在地の位置情報と、検索対象のコンテンツ70とに対応する位置対応キーワードをコンテンツ別−位置対応検索条件テーブル82から検出するCPU20とを備える。CPU20は、検出された位置対応キーワードを検索文字列として入力し、入力された検索文字列に対応する項目情報を検索対象のコンテンツ70から検索するとともに、検索された項目情報を表示させる。
(もっと読む)
情報表示装置及び情報表示プログラム
【課題】従来よりも教材テキストの学習効率を向上させる。
【解決手段】電子辞書1は、表示部40と、教材テキスト830のテキストデータを記憶するフラッシュROM80と、教材テキスト830に含まれる複数の単語に対し、読解用単語及び筆記学習用単語の何れか一方の区分を対応付けて記憶する教材ガイドテーブル840と、ユーザ操作に基づいて、教材テキスト830内の文字列をマーカ表示文字列として指定する入力部30と、表示部40に教材テキスト830が表示される場合に、当該表示されるテキスト中のマーカ表示文字列に含まれる単語のうち、教材ガイドテーブル840により読解用単語の区分に対応付けられた単語と、筆記学習用単語の区分に対応付けられた単語とに、それぞれ異なる表示形態のマーカを付けて表示させるCPU20と、を備える。
(もっと読む)
中継サーバ
【課題】現場の研究開発者が自ら英語以外の言語を用いた特許調査を接続先を意識せずに容易に行うことが可能な特許検索システムのための中継サーバを提供する。
【解決手段】検討対象特許データから重要語を抽出するために検討対象特許データの各単語の重要度を算出する重要度算出手段(330)と、前記重要度に基づいて抽出された重要語を用いて前記検討対象特許データの特許分類を判定する第1の特許分類判定手段(335)と、前記判定した特許分類を用いて専門辞書を特定し、該特定した専門辞書を用いて前記重要語を所望の言語に翻訳する第1の翻訳処理手段(340)と、前記所望の言語に翻訳された重要語を用いて検索式を生成する第1の検索式生成手段(345)と、前記所望の言語に応じた接続先である特許データベースサーバに対して、前記接続先に応じた接続要求を生成する第1の接続要求生成手段(350)とを備えた。
(もっと読む)
101 - 120 / 3,390
[ Back to top ]