
Fターム[5B075ND03]の内容
Fターム[5B075ND03]に分類される特許
141 - 160 / 3,390
文書インデックス作成装置
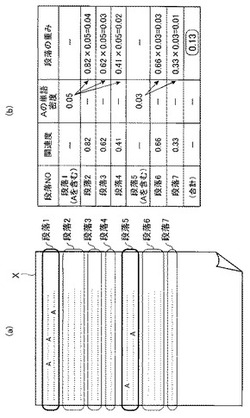
【課題】文書ファイルの記述内容に可及的に即した文書インデックスを作成する。
【解決手段】ネットワークシステムSは、文書データベース10と、この文書データベース10に対して所定の検索アルゴリズムを用いて検索処理を行う検索エンジン20と、ユーザが利用する端末装置30と、文書検索用の文書インデックスの作成処理を行うデータ処理装置40とを含む。データ処理装置40は、一の文書ファイルの文書データを複数の段落に区分すると共に、注目単語Aを含む第1単位文章(段落)と、注目単語Aを含まない第2単位文章(段落)とに区別する。そして、第1単位文章と第2単位文章との文章関連度を評価し、第2単位文章の段落重み値を求める。注目単語Aの出現頻度に基づく基礎重み値に、前記段落重み値を加算することで、当該注目単語Aの重み値を設定する。
(もっと読む)
話題出力装置及び方法及びプログラム

【課題】 一定期間よりも大きな周期の既によく知られた話題に関する語句を出力しないよう選択する。
【解決手段】 本発明は、時刻情報、階層カテゴリ情報が付与された一定期間の文書を取得し、文書集合に含まれる語句の出現数を求め、該出現数に基づいて、該一定期間に話題になった語句の話題度を算出し、話題度の高い語句に対して、周期性があるかどうかを判断し、周期性があると判断した各語句に対して、階層カテゴリの上位階層から順に、同一階層カテゴリ間において語句の出現に偏りがあるかどうか調べ、上位階層において偏りが少ないほど高い認知レベルを付与する。利用者に指示された認知レベルや、予めシステムに設定した認知レベルに合わせて、語句を選択して出力する。
(もっと読む)
ユーザ区分けシステム
【課題】多数のユーザを、目的に応じて的確に区分けする。
【解決手段】解析処理装置30は、各々のユーザが作成した文書ファイル(業務文書ファイルや電子メール文書ファイル)に基づいて、多数のユーザを所定のグループに区分けする処理を行う。例えば解析処理装置30は、研修テキスト文書のような基準文書ファイルに係る文書に用いられている単語群と、各ユーザが作成したユーザ文書ファイルに用いられている単語群との類似度をJACCARD係数で評価することで、各ユーザの研修内容に関する事前理解度を評価する。また、1のユーザの作成に係る文書ファイルに用いられている単語群と、他のユーザの作成に係る文書ファイルに用いられている単語群との類似度をクラスター分析で評価することで、1のユーザと他のユーザとの業務類似性を評価する。
(もっと読む)
事例解析装置および事例解析方法。
【課題】解析者が事例をより客観的に解析して深層要因を見つけ出し、データベース化することを支援し、深層要因が類似する事例を検索することが出来る事例解析装置を提供することを目的とする。
【解決手段】事例解析装置は、複数の構成要素と構成要素間の相互作用とによって活動を表す活動構造図で失敗事例を記述し、活動構造図におけるいずれかの構成要素おいて発生した矛盾にキーワードを割り当てて事例とともに蓄積し、構成要素とキーワードとに基づいて、ある事例と類似する事例を検索する。
(もっと読む)
電子書籍表示装置、書籍一覧プログラムおよびコンピュータ読み取り可能な記録媒体
【課題】書籍等の一覧表示で各項目の既読率をグラフ表示することができるように改良された電子書籍表示装置を提供する。
【解決手段】電子書籍表示装置は、端末内に存在する書籍をリストにして表示する書籍リスト表示手段と、上記端末内の上記書籍を閲覧した時に、未読部分と既読部分を加えたものに対する既読部分の割合である既読率を算出し、既読率情報として記録する既読率情報記録手段と、上記端末内に存在する上記書籍をリスト表示する際に、上記既読率情報を元に、上記既読率を書籍リストの背景にグラフにして表示する既読率グラフ表示手段と、を備える。
(もっと読む)
構造化文書を分類するためのルールを生成するための方法、並びにそのコンピュータ・プログラム及びコンピュータ
【課題】 XML文書のような構造化文書を効率的に分類するためのルールを生成するための方法、コンピュータ及びコンピュータ・プログラムを提供することを目的とする。
【解決手段】 本発明は、同一のスキーマが適用される複数の電子化された構造化文書を分類するためのルールを生成するための方法を提供する。当該方法は、スキーマを走査して、当該スキーマによって定義される1以上の変動部分を特定するステップと、当該特定された変動部分の特徴値を複数の構造化文書それぞれから取得し、当該取得された特徴値それぞれを当該特徴値が取得された構造化文書に関連付けるステップと、構造化文書に関連付けられた特徴値に基づいて、上記ルールを生成するステップとを含む。また、本発明は、同一のスキーマが適用される複数の電子化された構造化文書を分類するためのルールを生成するコンピュータ及びそのコンピュータ・プログラムを提供する。
(もっと読む)
対話装置
【課題】対話の自然さを保持しつつ対話内容をコントロールすることができる対話装置を提供する。
【解決手段】対話順序記憶部は、対話文のパターンを複数記憶する。出力部は、第1出力文を出力する。第1受付部は、入力文の入力を受け付ける。第2受付部は、質問文の入力を受け付ける。第1確率算出部は、第1出力文と同一または類似する対話文が出力され、更にその次に対話文記憶部に記憶された対話文のいずれかである第1対話文のそれぞれが出力される確率を表す第1確率をパターンに基づいて算出する。第2確率算出部は、パターンに基づいて、第1対話文ごとに、第1対話文の次の次に質問文と同一または類似する対話文が出力される確率を表す第2確率を算出する。選択部は、第1確率と第2確率とを重み付け加算した値が最も大きい第1対話文を第2出力文として選択する。
(もっと読む)
文書分析装置およびプログラム
【課題】複数のカテゴリの内容を相互に比較するのに好適な特徴語を抽出することが可能な文書分析装置およびプログラムを提供することにある。
【解決手段】単語抽出手段は、カテゴリ情報格納手段に格納されているカテゴリ情報によって示される第1のカテゴリに属する複数の文書に含まれる単語を抽出する。文書数算出手段は、抽出された単語が第1のカテゴリに属する複数の文書において出現する文書の数を示す第1の文書数および第1のカテゴリの下位に位置する第2のカテゴリに属する複数の文書において出現する文書の数を示す第2の文書数を算出する。特徴度算出手段は、第1のカテゴリに属する文書の数、第2のカテゴリに属する文書の数、第2のカテゴリの数、第1および第2の文書数に基づいて、前記抽出された単語の特徴度を算出する。特徴語抽出手段は、特徴度に基づいて前記第1のカテゴリに対する特徴語を抽出する。
(もっと読む)
文書処理システム、文書情報漏洩防止方法、文書処理装置及びその制御方法と制御プログラム
【課題】ユーザが文書を登録する際に誤って広すぎる開示範囲を指定する事態を事前に防止すること。
【解決手段】登録された文書情報の漏洩を防止する文書処理装置であって、文書情報を登録する文書情報登録手段と、前記文書情報登録手段に登録された文書情報について、該文書情報の登録者と、該文書情報に含まれる単語と、前記登録者が指定した該文書情報の開示範囲とに基づいて、開示範囲が限定されている文書情報のなかに所定閾値より高い頻度で出現する単語を要注意語として抽出する要注意語抽出手段と、前記文書情報の登録者と前記要注意語抽出手段により抽出された前記要注意語とを対応付けて格納する要注意語格納手段と、前記登録者が新たに登録する文書情報に対し、前記要注意語格納手段を参照して前記登録者に対応付けられた要注意語を含むか否かを検査する文書検査手段と、を備えることを特徴とする。
(もっと読む)
テキスト分割装置、テキスト分割学習装置、テキスト分割方法、テキスト分割学習方法、プログラム
【課題】あらかじめ決められた話題に合わせて、個々の境界ごとに最適な特徴パラメータを用いてテキストを分割する。
【解決手段】本発明のテキスト分割装置は、単語分割部、削除部、ベクトル化部、学習情報取得部、線形変換学習部、重心学習部、分割対象情報取得部、割付部を備える。線形変換学習部は、隣接する2つの話題ブロックの組ごとに、割付けられた単語の単語ベクトルを用いて、隣接する話題ブロックを分離するための線形変換係数ベクトルを求める。重心学習部は、隣接する2つの話題ブロックの組ごとに、各話題ブロックに割付けられた単語の単語ベクトルを用いて各話題ブロックの重心点を求める。割付部は、線形変換係数ベクトルと前記重心点を用いて、前記分割対象のテキストの単語をどの話題ブロックに割付けるかを決める。
(もっと読む)
入力支援装置
【課題】従来は、辞書の登録単語の読みと、ユーザ入力の読みが異なる場合、辞書に意図する候補が登録されておらず入力に手間が掛り、又、うろ覚え状態での読み入力による表記選択の場合、意図する予測変換結果が得られない。
【解決手段】読みと表記を格納した検索目的物名辞書と、同一表記で読みが異なる語を格納した読み異なり語辞書と、入力または選択された提示候補の読みで検索目的物名辞書から検索された次段階の提示候補を元に候補絞り込み過程での選択結果と読みと表記が前方一致する提示候補リストを読み表記前方一致候補生成手段で生成し、該リスト中の表記を検索キーに、同一表記で読みが異なる語を、読み異なり語検索手段で読み異なり語辞書から検索した結果を、読み異なり語表記前方一致候補生成手段で提示候補リストに追加して、候補表示手段で追加された提示候補リストを表示する。
(もっと読む)
悪性ウェブコード判別システム、悪性ウェブコード判別方法および悪性ウェブコード判別用プログラム
【課題】取得された文字列データに基づいて、自動的に精度良く悪性ウェブコードの判別を行うことが可能な悪性ウェブコード判別システム、悪性ウェブコード判別方法および悪性ウェブコード判別用プログラムを提供すること。
【解決手段】悪性ウェブコード判別システム1は、ウェブページを介して取得された文字列データを複数の文字列に分割する文字列分割手段20と、分割された文字列の中から、少なくとも行末コメントに該当する文字列をトークンとして抽出する文字列抽出手段20と、抽出された文字列に基づいてウェブページの特徴を示した特徴ベクトルを生成する特徴ベクトル生成手段20と、生成された特徴ベクトルに基づいて、文字列が、SQLインジェクションに該当するか否かを判別する判別手段20とを有する。
(もっと読む)
文書分類装置及びプログラム
【課題】 より分類精度の高い文書分類を可能にする。
【解決手段】 本発明は、正解文書から処理対象となる全ての対象単語に関して、制限無単語クラス間関連度を算出する。正解文書から処理対象となるいくつかの対象単語について、条件単語制限付単語クラス間関連度を算出する(事前処理)。処理対象となる文書が入力されると、入力文書に含まれる単語群の各単語について、該単語群と制限無単語クラス間関連度と条件単語制限付単語クラス間関連度とから、単語クラス間関連度を算出し、入力文書に含まれる単語群の各単語の出現頻度と該単語の重要度との積、あるいは、頻度と重要度に関して単調増加な演算結果である重みと、該入力文書に関する単語クラス間関連度とから、文書クラス間関連度を算出し、文書クラス間関連度と事前確率を用いて、入力文書が属するクラスを決定する(分類処理)。
(もっと読む)
検索インデックス作成システム、文書検索システム、インデックス作成方法、文書検索方法及びプログラム
【課題】検索システムにおいて、地図画像入り文書に対して位置情報を検索キーに用いた検索を可能とする。
【解決手段】検索インデックス作成システムを、(1) 文書ファイルに含まれる1つ又は複数の地図画像又は写真画像の付属データから画像範囲を示す経度緯度情報を抽出する手段と、(2) 経度緯度情報と、当該経度緯度情報に対応する地図画像又は写真画像を特定する識別情報とを含む検索インデックスを作成する手段とで構成する。
(もっと読む)
文書管理装置及び文書管理プログラム
【課題】どのようなキーワードで検索すればよいのか分からない場合であっても、所望の文書を効率よく検索することができる技術を提供する。
【解決手段】画像形成装置は、ボックス部に各文書データ(文書A,文書B,文書C)を記憶する際に、各文書データに含まれる単語を抽出し、抽出した単語のうち各文書データにおける出現頻度の高い上位数個の単語をキーワードとして選択し、そのキーワードを各文書データに関連付けて記憶しておく。文書データを検索する際には、全ての文書データ(文書A,文書B,文書C)における出現頻度の高い上位数個のキーワードを表示する(単語B;16回、単語A;14回、単語C;8回)。表示されたキーワードのいずれかをユーザが選択することにより、選択されたキーワードに関連付けられた文書データが検索される。これらの表示処理、選択処理、検索処理を繰り返すことにより、文書データの絞り込み検索が行えるようになる。
(もっと読む)
特許検索装置、特許検索方法、およびプログラム
【課題】適切な特許検索式を用いた検索が容易に可能な特許検索装置を提供する。
【解決手段】検索式受付部103が受け付けた特許検索式のキーワードと一致する用語と対応付けられた関連用語を関連用語情報から検索する関連用語検索部104と、検索結果に応じて特許検索式を修正するか否かを判断する修正判断部106と、修正すると判断した場合に、各キーワードと一致する用語と対応する関連用語を候補キーワードとして取得する候補キーワード取得部107と、指定指示受付部111が受け付けた指定指示で指定された候補キーワードで特許検索式を修正する特許検索式修正部112と、修正判断部106が修正すると判断した場合は修正した特許検索式を用いて特許公報の検索を行い、修正しないと判断した場合には検索式受付部103が受け付けた特許検索式で検索を行い検索結果を出力する検索部113とを備えた。
(もっと読む)
情報検索装置および情報検索方法
【課題】複数の検索要求用キーワードを用いて高速で誤検索の無い秘匿検索を行う情報検索装置を実現する。
【解決手段】情報検索装置は、検索履歴を記憶するインデックス3001を備え、検索要求が有った場合に、全データ検索を行わず、インデックス3001内の検索履歴を検索することで、検索の高速化を図る。インデックス3001は、検索要求用キーワードの数毎のキーワード数別インデックス3002を備える。更にキーワード数別インデックス3002は、検索要求用キーワードに対応したエントリ用代表元タグ3004とエントリ用検索クエリ3006を有する複数のエントリを備える。本構造により検索条件によって分類されたインデックス3001が形成され、情報検索装置は、誤検索の無い秘匿検索を行う。
(もっと読む)
テストデータの作成装置
【課題】文書ファイルの検索システムの検証のために用いられるテストデータを、安価に且つ柔軟に、大量に作成する。
【解決手段】テストデータ作成装置は、所謂モンテカルロ法を基づいて、複数の単語を含む多数の文書ファイルに相当するテストデータ、つまり単語頻度及び文書頻度を含むデータを大量に作成する処理を行う。模擬的な文書1〜1000と、模擬的な単語a、単語b、単語cが設定され、各々の単語について、単語頻度の合計値がテーブル61の領域61Aに設定される。この単語頻度の合計値をベースとして、擬似乱数を用いてモンテカルロ法により、各単語についての各々の文書における単語頻度と、各単語の文書頻度とが求められる。
(もっと読む)
フィルタリング装置およびフィルタリング方法
【課題】テキストデータを適切にフィルタリングする。
【解決手段】フィルタリング装置120は、番組ストリームに含まれる字幕データまたは番組情報を抽出し、形態素に分割して、その形態素を許可ワードテーブル200に登録し、出現回数を更新するテーブル更新部180と、任意のテキストデータを取得するデータ取得部182と、任意のテキストデータを形態素に分割し、分割した形態素が許可ワードテーブルに登録されていない、または、分割した形態素が許可ワードテーブルに登録されているが、その形態素に対応した出現回数が予め定められた第1閾値未満であれば、形態素を、予め定められた記号に置換し、テキストデータとして再結合するデータ加工部184とを備える。
(もっと読む)
文書検索装置及び方法及びプログラム
【課題】 キーワードと日時表現が同一の文に出現しない場合でもキーワードに関する指定した日時の範囲内の内容を表す文書を提示する。
【解決手段】 本発明は、入力されたキーワードを含み、入力された日時の範囲内の日時表現を含む文書及び文書の適合性スコアを取得し、取得した文書に含まれるキーワード及び日時表現をもとに、日時表現の有効範囲を考慮して文書内でキーワードと日時とがどの程度関連しているかを表す日時スコアを算出し、文書の適合性スコア及び日時スコア記憶手段の日時スコアをもとに、文書スコアを算出し、文書スコアをもとに、文書を並び替える。
(もっと読む)
141 - 160 / 3,390
[ Back to top ]