
Fターム[5B075NK31]の内容
Fターム[5B075NK31]の下位に属するFターム
自然言語解析による検索キーの抽出 (1,229)
抽出領域指定 (82)
特徴箇所を検索キー情報とするもの (542)
Fターム[5B075NK31]に分類される特許
121 - 140 / 566
コンテンツ識別方法及び装置
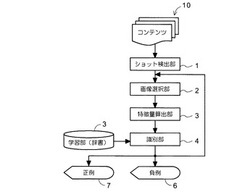
【課題】任意の未知コンテンツが識別対象(正例)であるか識別対象外(負例)であるかを高精度に判定できるコンテンツ識別方法および装置を提供する。
【解決手段】映像ショットの切り替わりで映像を構造化するショット検出手段1と、前記ショット検出手段によって検出されたショット情報を用いて識別対象となる画像候補を選択する画像選択手段2と、前記画像選択手段で選択された画像候補から特徴量を算出する特徴量算出手段3と、前記特徴量算出手段で算出された特徴量を用いて正例7と負例6に識別する識別手段4とを備える。また、前記特徴量算出部3は、ピラミッド画像生成部、色特徴量算出部、形状特徴量算出部および特徴量判定部から構成することができる。この構成により、例えば、映像コンテンツが青少年に有害な画像であるか否かを、精度良く識別できるようになる。
(もっと読む)
代表語抽出方法及び装置及びプログラム及びコンピュータ読取可能な記録媒体

【課題】文書に適切に特徴付ける代表語を複数抽出することが可能で、また、多数の単語から構成される文書においても適切な代表語を抽出することを可能にする。
【解決手段】本発明は、文書概念ベクトルを取得し、単語及び該単語の概念ベクトルが蓄積されている単語概念ベクトル蓄積手段から取得した該単語概念ベクトルと、決定済みの代表語概念ベクトルが蓄積されている代表語概念ベクトル蓄積手段から代表語概念ベクトルを取得し、文書概念ベクトルと、該単語概念ベクトルと該代表語概念ベクトルとがなす空間の距離を、全ての単語概念ベクトルについて計算し、距離記憶手段に格納し、距離記憶手段に格納されている距離に基づいて代表語を出力する。
(もっと読む)
文書処理装置
【課題】 段組構成になっているページのテキスト抽出を行う場合、単にページ内のテキスト描画コマンドの座標でソートするだけではテキスト抽出として不十分である。よって、ブロック内での読み順と、それぞれのブロック間での読み順を勘案したテキスト抽出を行う必要がある。
【解決方法】 1つ1つのテキスト列のベースラインの「オフセット座標」と「終端座標」を取得し、作成したベースラインの座標情報を元に、平行かつ近傍の条件に当てはまるテキスト列をブロック化し、さらに、ブロック内のテキストをY座標でソートしておく。また、ブロック間での読み順を決定するために、各種条件式によりブロック間での連鎖性の判定と整列を行い、整列された順番でテキスト抽出を行う。
(もっと読む)
アノテーション付けを行う方法およびそのためのコンピュータプログラム
【課題】計算機を効率的に利用した、大規模なメディアファイルを利用するアノテーション付与のための高効率かつスケーラブルな手法を提供する。
【解決手段】アノテーション付与方法は、アノテーションを含む複数の第1のデジタルファイルの第1の複数の特徴から複数の分類器を生成し、複数の第2のデジタルファイルから抽出された複数の第2の特徴を複数の分類器を用いてソートし、第2の特徴とそれぞれの分類器に対応する第1の特徴との間の距離ベクトルを決定し、この距離に応じてランク付けを行う。ランキングに基づいて、マッチファイルのサブセットが選択される。サブセットにはそれぞれ一以上のアノテーションが関連付けられ、新たに受信したデジタルファイルに対し、このサブセットのアノテーションが分類器に応じて関連付けられる。
(もっと読む)
印刷装置、印刷装置の制御方法及び制御プログラム
【課題】ユーザーに検索条件の設定を意識させることなく、所望の検索結果を得る。
【解決手段】プリンター13は、印刷データに基づいて所定の記録媒体に印刷を行うプリントエンジン26と、外部の検索サーバーに通信ネットワークを介してアクセスし、印刷データに対応する印刷内容に関連する情報あるいは当該印刷内容に関連する情報の所在を検索結果情報として収集するコントローラ21と、検索結果情報を更新可能に記憶するハードディスク24と、を備える。
(もっと読む)
文書処理プログラム及び文書処理装置
【課題】文書の分類精度を向上させることを可能とする。
【解決手段】重要語抽出部311は、文書格納部22に格納されている文書毎に、当該文書における文字列の出現頻度に基づいて重要語を抽出する。対象文抽出部312は、抽出された重要語を含む要旨文を当該重要語が抽出された文書から抽出する。言い換え文生成部322は、抽出された要旨文に含まれる重要語及び要旨文の係り受け解析結果に基づいて当該重要語を含む言い換え文を生成する。素性抽出部42は、言い換え文生成部322によって生成された言い換え文に含まれる重要語を含む素性の組を抽出し、当該素性の組を素性格納部26に格納する。文書ベクトル生成部442は、文書格納部22に格納されている文書毎に、当該文書から抽出された要旨文における素性格納部26に格納された素性の組の出現頻度を示す文書ベクトル成分値に基づいて文書ベクトルを生成する。
(もっと読む)
番組放送中に他のチャンネルの番組検索サービスを提供する方法及び装置
【課題】現在放送中の番組と同じような時間帯に放映される他のチャンネルの推薦番組リストを順位別に提供すること。
【解決手段】双方向放送端末に番組放送中に他のチャンネルの番組検索サービスを提供する方法は、(a)ユーザ入力手段のキー入力に応答して、双方向放送端末の画面に検索サービスを提供するための検索領域を提供し、(b)検索領域に、放送中の番組に関連したキーワードが自動入力された検索ウィンドウを提供し、(c)検索領域に、放送中の番組と同じような時間帯に放映される他のチャンネルの推薦番組リストを順位別に提供し、(d)検索領域に、放送中の番組の放送時間に近い順に各チャンネル別の番組リストを整列して提供することを含む。
(もっと読む)
コンテンツ関連情報検索システム、コンテンツ関連情報検索方法、およびコンテンツ関連情報検索プログラム
【課題】コンテンツに含まれるキーワードを検索するとともに、検索結果とコンテンツの内容の同期をとる。
【解決手段】コンテンツ関連情報検索システムであって、再生中のコンテンツを解析してキーワードを抽出し、抽出したキーワードと当該キーワードの抽出元のコンテンツに関する抽出元情報とを蓄積手段21に登録する解析手段13と、ユーザが選択したキーワードについてWeb検索して検索結果を取得するとともに、ユーザが選択したキーワードの抽出元情報を前記蓄積手段21から取得する検索手段17と、検索結果と抽出元情報とを含む検索結果提示情報を生成し、ユーザに提示する生成手段18と、検索結果提示情報に提示された抽出元情報のコンテンツの再生指示を受け付けると、抽出元情報を用いて選択されたキーワードが抽出された時点からコンテンツを再生させる再生手段19と、を有する。
(もっと読む)
文章体特定装置およびコンピュータに文章体を特定させるためのプログラム
【目的】検索条件に沿う文章体を見つけ出す。
【構成】複数の文章体のそれぞれを処理対象にして,受付けられた複数の検索キーワードのそれぞれについて,検索キーワードの存在の有無が検出される。検索キーワードの存在有無の検出に基づいて,複数の文章体のそれぞれに存在する検索キーワード種類数が算出される。同数の検索キーワード種類数を持つ文章体がグループ化され(ステップ52),同一グループに含まれる文章体が,各文章体に含まれる検索キーワードの重要度(網羅度フラグ)に基づいて,重要度の大きな検索キーワードを含む文章体の順に並び替えられる(ステップ56,57)。検索キーワード種類数が大きい順に上記グループが並べられ,かつ一のグループ内においては上記グループ内並び替えに基づく順に文章体を並べられて,処理対象の複数の文章体のそれぞれに順位が付与される(ステップ58,59)。
(もっと読む)
動画像検索装置
【課題】検索に使用する動画像固有識別情報を自動的に抽出して動画像を検索することができる動画像検索装置を提供する。
【解決手段】本発明の動画像検索装置は、所定の動画像データから各フレームの動画像特徴量情報103を抽出する動画像特徴量情報抽出部102と、動画像特徴量情報抽出部102で抽出された動画像特徴量情報103に基づいて、動画像を識別するための動画像固有識別情報105を抽出する動画像固有識別情報抽出部104と、動画像固有識別情報抽出部104で抽出された動画像固有識別情報105と検索対象の動画像に基づいて準備された検索対象の動画像固有識別情報108とを比較することによって、検索対象の動画像から所定の動画像を検索して同定する動画像固有識別情報検索部109と、を備えることを特徴とする。
(もっと読む)
画像データの管理
【課題】 画像データのデータベースを容易に構築し、画像データを用いて画像データに関する情報を取得することができる画像データのデータベースを構築すること。
【解決手段】CPU111は、WWWサーバから画像データを取得し、取得した画像データから撮影位置情報および特徴量を取得する。CPU111は、画像データを取得したWebデータを解析してキーワードを取得する。CPU111は、取得した撮影位置情報、特徴量およびキーワードを、取得した画像データに関連づけて画像データベースに登録する。
(もっと読む)
操作シーケンス抽出方法及び装置及びプログラム
【課題】異なる目的で閲覧したページがそれぞれ別のシーケンスとなるような、操作シーケンスの抽出を行う。
【解決手段】本発明は、操作ログから検索行動とその結果得られる検索結果ページと、その検索結果から実際に閲覧したページをまとめる。1つの検索結果ページに着目し、閲覧したページに存在する語句の割合(全ページに対する存在ページの割合)を要素(成分)とする特徴ベクトルで表現する。特徴ベクトルの類似度(内積)により類似したものをまとめ(どのような検索語句で検索したかをグループ化)、これを操作シーケンスとして抽出する。
(もっと読む)
情報端末及び会話補助プログラム
【課題】利用者の操作を伴わずに、会話をスムーズに進めるためのデータを提供することができる携帯通信端末を提供することを課題とする。
【解決手段】携帯通信端末100は、マイク107から音声を取得し、会話に含まれる単語を抽出して記憶部114に記憶しておく。並行して取得される音声の音量が、音量閾値を下回る時間(無音時間)を計測し、計測した無音時間が時間閾値以上である場合、記憶している語句を基に、インターネットを介して会話に関連する情報を取得し、利用者に提示する。
(もっと読む)
情報処理装置、情報処理方法、プログラム、および情報処理システム
【課題】コンテンツデータに含まれる情報をユーザに伝達し、特定の再生開始位置からのコンテンツデータの再生を補助することが可能な情報処理装置、情報処理方法、プログラム、および情報処理システムを提供する。
【解決手段】コンテンツデータを記憶可能な記憶部と、コンテンツデータに基づいてコンテンツデータに含まれるテロップを検出し、検出されたテロップに関する情報と検出されたテロップに対応するコンテンツデータの再生開始位置の情報とが対応付けられて記録されたインデックス項目情報を生成するインデックス項目生成部と、インデックス項目情報に基づいてユーザによる選択が可能なインデックスを含みインデックスが選択された場合には対応するコンテンツデータの再生開始位置からコンテンツデータを再生させることが可能なインデックスリストコンテンツを生成するインデックスリストコンテンツ管理部とを備える情報処理装置が提供される。
(もっと読む)
関連ウェブページ発見装置、関連ウェブページ発見方法および関連ウェブページ発見プログラム
【課題】、特性の類似した関連ウェブページ群を容易に発見することができる関連ウェブページ発見装置を提供する。
【解決手段】インターネット50からウェブページを収集してウェブページ情報DB102に登録するウェブページ収集手段101と、前記DB102からハイパーリンク情報を抽出してハイパーリンク情報DB104に登録する事で、ネットワークを隣接行列形式で表現するネットワーク抽出手段103と、前記ネットワークを基に、ノード毎に該ノードとその周辺ノードとのエッジの接続状態に基づいた特徴量を算出し、当該特徴量をウェブページ特徴量DB106に登録するウェブページ特徴量算出手段105と、各ページの特徴量を基に、処理対象のページと関連するウェブページを算出し、関連ウェブページ群を出力として提示する関連ウェブページ算出手段107と、を有する。
(もっと読む)
コンピュータ実施方法
【課題】トピック識別を提供する。
【解決手段】粗粒度トピックモデル生成60で、アーティクルのセットはコーパスから任意に選択され(61)、特徴的単語のベースラインがアーティクルの任意のセットから抽出され、ベースラインに基づいて各特徴的単語の発生頻度が求められ(62)、アーティクルはポジティブ訓練例のセットであるコーパスから選択され(63)、特徴的単語の発生頻度が求められ(64)、測度又は得点がTF−IDFの重み付け法を用いて各特徴的単語に割り当てられ(65)、各特徴的単語の得点を調整し(66)、特徴的単語とそれらの得点の表が作成される(67)。
(もっと読む)
数値表現処理装置
【課題】文書から数値表現を抽出し、抽出した数値表現の属性名を検出し、属性名と数値に対して適切な尺度を対応づける。
【解決方法】文書から数値表現、数値表現を値とする属性名、数値表現と属性名の組を特徴とする事物名を抽出し、属性名と数値に対して適切な尺度を対応づける。事物と、事物を特徴づける属性名、属性名の数値の3つを1つの組として文書中から抽出することで、抽出した数値を適切な尺度に対応づけられるようになる。その結果、正確に数量表現を扱えるようになり、数値表現を含むテキストマイニングや文書要約、文書検索を従来よりも精度よく実現できるようになる。
(もっと読む)
Web文書主要コンテンツ抽出装置及びプログラム
【課題】人手を用いて抽出規則を作成することなく、主要コンテンツの自動抽出を可能にする。
【解決手段】本発明は、Web文書が入力されると、該Web文書を所定の分割規則に基づいてセグメントに分割し、記憶手段に格納し、分割されたセグメント毎に、主要コンテンツ判定のための特徴量を抽出し、セグメント毎に記憶手段に格納し、セグメント毎の特徴量に基づいて、機械学習アルゴリズムを用いて主要コンテンツか否かの判定を行い、主要コンテンツと判定された部位を結合して、主要コンテンツとして出力する。
(もっと読む)
メタデータのアクセスを単純化するための方法および装置
【課題】 個人用ビデオ録画のための入手可能な記憶媒体容量は絶え間なく増大している。記録の編成、コンテンツの検索および特定記録へのアクセスのためにメタデータを用いることができる。マルチメディア・コンテンツの範囲内に埋め込まれたメタデータの場合、能率が悪くて時間がかかる検索となる。
【解決手段】 本発明に従ったメタデータ情報は集められ、分析され、メタデータ実体を形成するために処理される。またコンテンツへの参照により補正される。結果として生じるメタデータ実体とコンテンツ参照との対から記述子ストリーム(DS)が形成され、マルチメディア・コンテンツを含むファイルとは別個に記憶される。このようにして、MPEG-2トランスポート・ストリームのデータのために、全てのストリームの解析の必要性なしにメタデータにアクセスすることができる。
(もっと読む)
情報処理システム
【課題】従来の情報処理システムにおいては、クライアント装置−サーバ装置間の通信の際に機密情報が漏洩する可能性があるという課題があった。
【解決手段】サーバ装置と1以上のクライアント装置を備える情報処理システムであって、サーバ装置は、クライアント装置からのリクエスト情報に含まれるキーワードに対応付けられた定型文情報を検索し、その結果であるレスポンス情報をクライアント装置に送信し、クライアント装置は、サーバ装置にキーワードを含むリクエスト情報を送信し、そのリクエスト情報に対するレスポンス情報を受信することで説明文情報を取得し、その説明文情報を含む特許出願に関する情報である特許出願文書を作成する情報処理システムにより、クライアント装置において蓄積している最低限の情報のみをサーバ装置に送信することで、機密情報の漏洩を防ぐことができる。
(もっと読む)
121 - 140 / 566
[ Back to top ]