
Fターム[5B075NK31]の内容
Fターム[5B075NK31]の下位に属するFターム
自然言語解析による検索キーの抽出 (1,229)
抽出領域指定 (82)
特徴箇所を検索キー情報とするもの (542)
Fターム[5B075NK31]に分類される特許
141 - 160 / 566
インデックス生成方法、プログラム及びサーバ
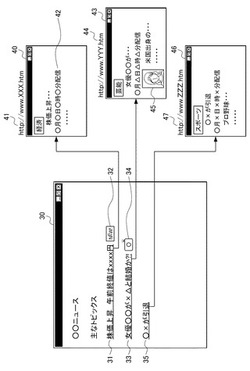
【課題】Webページの検索で使用することが可能な、キーワードとは異なるインデックスを生成するインデックス生成方法、プログラム及びサーバを提供する。
【解決手段】インデックス生成サーバが、検索対象になるWebページを記憶するWebページDBからWebページを読み込んで、Webページ30に配置されたアンカーテキスト31と、表示されたアンカーテキスト31の行に隣接して配置された絵文字32とを取得するデータ取得手段と、取得したアンカーテキスト31と絵文字32との間の関係を判定する関係判定手段と、アンカーテキスト31と絵文字32とに関係があると判定されたことに応じて、絵文字32をアンカーテキスト31からのリンク先のWebページ40のURLのインデックスとして対応付けて、インデックスDBを生成するインデックス生成手段と、を備える。
(もっと読む)
広告表示方法及び装置、並びに広告表示プログラム

【課題】入力された画像だけを元に広告を表示する。
【解決手段】特徴量取得部36は、サーバ11に入力された入力画像の特徴量を取得する。キーワード取得部37は、入力画像の特徴量に基づいて、入力画像のキーワードを取得する。関連画像取得部38は、入力画像のキーワードに基づいて、関連画像を取得する。特徴量取得部36は、関連画像の特徴量を取得する。キーワード取得部37は、関連画像の特徴量に基づいて、関連画像のキーワードを取得する。広告取得部39は、入力画像のキーワード、及び関連画像のキーワードに基づいて、広告を取得する。入力画像、そのキーワード、関連画像、そのキーワード、及び広告は、通信I/F35に読み出され、サーバ11から出力される。
(もっと読む)
検索支援装置及び方法、ならびに、コンピュータプログラム
【課題】電子メールを利用して検索対象について関連性の高い人物を検索し、提示する。
【解決手段】検索支援装置1は、電子メールのヘッダの情報から取得した、関連する他の電子メールのメッセージIDがメールテーブルに登録されていない場合はスレッドIDを新たに生成し、登録されている場合はメールテーブルからスレッドIDを取得する。そして、ヘッダ情報から取得したメッセージID、送信者及び受信者と、スレッドIDとを設定したレコードをメールテーブルに追加し、電子メールの件名を形態素解析して得たキーワードとスレッドIDとを対応づけてスレッドテーブルに書き込む。検索条件を受けると、キーワードテーブルから一致するキーワードのスレッドIDを取得し、そのスレッドIDで特定されるメールテーブルのレコードから送信者又は受信者として設定されているユーザと、その設定数とを取得し、設定数が多いユーザをスレッドID毎に出力する。
(もっと読む)
情報処理装置、対比情報出力方法およびプログラム
【課題】キーワードを含む電子情報の基準期間の前後での変化内容を知りたいという要望に応えられる情報処理装置、対比情報出力方法およびプログラムを提供する。
【解決手段】テキストとテキストの作成日または更新日を表す日付情報とを含む複数の電子情報を記憶する記憶装置と通信可能な情報処理装置は、開始日と終了日とを表す期間情報とキーワードとを含む検索要求が入力されると、記憶装置内の複数の電子情報の中から、テキスト内に該キーワードが含まれかつ日付情報が開始日より前の日付を示す第1電子情報と、テキスト内に該キーワードが含まれかつ日付情報が開始日と終了日のいずれかである特定日以降の日付を示す第2電子情報と、を抽出する抽出手段と、第1電子情報の抽出結果と第2電子情報の抽出結果との違いを表す対比情報を生成する生成手段と、を含む。
(もっと読む)
画像処理装置、画像処理方法、制御プログラム及び記録媒体
【課題】文字を含む画像を文字認識することにより文字検索の検索対象として格納する場合に、文字検索の適合率を向上すること。
【解決手段】画像から文字領域を抽出して文字情報を生成し、検索対象情報として格納する画像処理装置であって、画像を取得する入力情報取得部121と、第一の領域抽出方法に基づいて画像から文字領域を抽出して第一の文字情報を生成し、第一の領域抽出方法とは異なる第二の領域抽出方法に基づいて画像から文字領域を抽出して第二の文字情報を生成する文字情報認識部122と、第一の文字情報及び第二の文字情報を検索対象情報として検索対象DB106に登録する情報登録部123とを含むことを特徴とする。
(もっと読む)
電子辞書、辞書検索方法及びプログラム
【課題】予め決められた辞書データ量でより多くの辞書の機能を操作性良く提供する。
【解決手段】電子辞書1は、文字データの入力を行う文字入力手段と、見出し語と、当該見出し語に対応する訳データを保持する辞書データを記憶する辞書データ記憶手段と、前記文字入力手段により入力された文字データを見出し語として、当該見出し語に対応する訳データを第1の辞書種別に対応する辞書データから抽出する第1の抽出手段と、前記第1の抽出手段により抽出された訳データを見出し語として、第2の辞書種別に対応する辞書データから当該見出し語に対応する訳データを抽出する第2の抽出手段と、前記第2の抽出手段により抽出された訳データを表示する表示手段と、を備える。
(もっと読む)
コンテクスト抽出サーバ、コンテクスト抽出方法、およびプログラム
【課題】編集によりメディアデータに付与されたメタ情報に基づき、他のメディアデータと関連付けられたコンテクストを抽出するコンテクスト抽出サーバ、コンテクスト抽出方法、およびプログラムを提供することにある。
【解決手段】特徴量算出機能部207により、映像中の物体の大まかな位置を検出するアルゴリズムや、平均の色を算出するアルゴリズム等の基礎的な特徴量を抽出するアルゴリズムをメディアデータに適用し、得られる時系列的な特徴量ベクトルと、メタ情報整形機能部206により、メディアデータに時系列的に付与されたコメントを、その発生頻度や言語自体の特性から形成されるメタ情報との相関が、相関計算機能部305により演算される。
(もっと読む)
サーバ装置、情報処理方法およびプログラム
【課題】検索結果から除外すべき、不要な汎用語のリストをユーザに代わって作成するサーバ装置を提供する。
【解決手段】外部からの指示により、または、所定の時刻になったとき、格納部に記憶されているテキストを収集し、収集したテキストから単語を抽出し、第1の所定の期間の出現頻度が第1の既定値より高く、かつ、第1の所定の期間よりも短い第2の所定の期間毎の出現頻度が第2の既定値範囲内で変動している単語を汎用語として決定し、汎用語のリストである汎用語リストを作成する制御部を有する。
(もっと読む)
キーワード抽出装置、キーワード抽出方法及びプログラム
【課題】ユーザの嗜好や興味に合致するキーワードを精度高く抽出することができるキーワード抽出装置、キーワード抽出方法及びプログラムを提供する。
【解決手段】映像データを入力するとともに、入力した映像データを視聴中の視聴者の反応を検出し、検出のタイミングで映像データにマーキングを行い、マーキングを行った部分近傍の映像データに対して文字認識及び音声認識の少なくとも一つを行ってキーワードを抽出し、抽出したキーワードを示すキーワードデータを出力する。
(もっと読む)
文章検索装置、文章検索方法、文章検索プログラムおよびその記録媒体
【課題】 クリックログの解析によりアクセスの集中するサイトを的確に特定し、少ない拡張語数で大幅な検索精度向上を可能にするクエリ拡張を実現する。
【解決手段】 文章検索装置1の解析部A123および解析部B124は、入力されたクエリを用いてサイトがクリックされた履歴であるクリックログDB126を解析する。解析結果統合部122は、前記両解析部123.124の解析結果からアクセスが集中しているサイトを特定する。情報抽出部128は、アクセスが集中しているサイトのタイトルと概要文とを抽出する。拡張語選択部120は、抽出したタイトルと概要文から検索に用いる拡張語を選択する。検索実行部140は、前記拡張語と前記クエリとを用いて検索を行い、検索結果を出力する。
(もっと読む)
文書処理装置およびプログラム
【課題】読み取り画像の歪みが生じている場合でも、文字認識を行う前に、一つの文字として認識されるべき文字は同じ文字認識結果を得られるようにする。
【解決手段】文字画像切り出し部12が、画像入力装置101から入力された文書画像から、文字画像を切り出し、文字画像分類部13が、切り出した文字画像を分類する。平均文字画像特徴取得部15が、カテゴリごとに、分類した文字画像を平均化した画像特徴を生成し、文字認識部16が、この平均化した画像特徴に対して文字認識を行う。カテゴリに含まれる文字画像に一律に認識文字コードを割り当てて文書の文字認識結果を生成する。
(もっと読む)
キーフレーズ抽出装置、シーン分割装置およびプログラム
【課題】番組映像等を分割するため、人手で与える手がかり語を用いることなく、語彙分布がそれほど変わらないシーン間の切れ目を効率的に検出する。
【解決手段】キーフレーズ抽出装置は、相対時刻に関連付けられたテキストを記憶する番組テキスト記憶部と、相対時刻およびテキストに基づき、番組を時間で区切ったセグメント毎に、言語的単位の出現頻度を表わすセグメント特徴量を算出するセグメント特徴量生成部と、セグメント特徴量のセグメント間の類似度を算出することにより、複数の番組に属するセグメントから類似のセグメントを選択し、それら選択されたセグメントから成るセグメント系列を生成するセグメントアラインメント処理部と、生成されたセグメント系列内における言語的単位の出現頻度に基づき言語的単位毎のスコアを算出し、算出されたスコアの良い言語的単位をキーフレーズとして抽出するスコア算出部とを備える。
(もっと読む)
留守番電話装置
【課題】留守番メッセージの優先度を決定する際の指標となるキーワードを自動更新し、留守番メッセージに対して常に適正な優先度を設定できる留守番電話装置を提供する。
【解決手段】言語モデルを記憶した言語モデルDB12と、キーワードを重み値と対応付けて記憶するキーワードDB15と、音声メッセージを言語モデルに基づく音声認識処理でテキストに変換するテキスト処理部14と、テキストから単語を抽出する単語抽出部17aと、テキストに基づいて要約メッセージを作成する要約作成部17bと、要約メッセージに含まれるキーワードの重み値に基づいて優先度を決定する優先度決定部18と、抽出された単語に基づいてキーワードDB15を更新する更新部19と、要約メッセージまたはその音声メッセージおよびテキストのいずれかを優先度に応じた形態で出力する出力制御部20とを含む
(もっと読む)
情報処理装置、情報処理方法及び情報処理プログラム
【課題】映像内の文字列を用いて情報検索システムにネットワーク上の情報を検索させた結果を、従来と比してユーザに容易に提供する。
【解決手段】インターネットテレビ装置1は、テレビ放送の映像から文字認識により文字列を検出し、検出した文字列から単語を検出し、検出した単語から、所定の条件に従って、ネットワーク上の情報を検索するためのキーワードを決定し、そのキーワードをネットワーク上の情報を検索する情報検索システムに送信して、そのシステムによる検索結果情報を取得し、その検索結果情報を表示部に表示させるようにしたことにより、ユーザに映像内の文字列を装置に入力するなどの煩雑な作業をさせることなく、映像内の文字列を用いて情報検索システムにネットワーク上の情報を検索させた結果を、従来と比してユーザに容易に提供することができる。
(もっと読む)
関連データを表示するための方法、サーバ、およびプログラム
【課題】表示されているコンテンツに関連する、ユーザにとって有用なデータを効果的に提示できる方法を提供すること。
【解決手段】サーバ10は、表示装置20から、コンテンツに含まれるテキストデータを受信して複数の単語を抽出する。続いて、複数の単語のうち、予め記憶した選択補助データと所定の類似度を有するものを、キーワードデータとして選択し、表示装置20に送信する。そして、表示装置20から、表示されたキーワードデータのうち、少なくとも一を選択する選択データを受信し、受信した選択データに応じて、対応するキーワードデータと関連する関連データを、ネットワーク上から検索し、表示装置20に送信する。
(もっと読む)
電子メールシステム
【課題】受信したメール文章を迅速に解析することができる電子メールシステムを提供する点にある。
【解決手段】メール内の単語に関する解説文が記憶された複数種類のデータベース5,6,7を備えたサーバ4に、受け取ったメール内の文章の中から単語を抜き出す単語抜き出し手段8と、単語抜き出し手段8にて抜き出された多数の単語を一個ずつ、予め決められた順番のデータベースから検索し、検索された単語に関する解説文を抽出する単語抽出手段9と、単語抽出手段9による抽出が完了した時点で抜き出した単語を受け取ったメールの文章の所定箇所に戻し、単語抽出手段9にて抽出された単語を抽出されなかった他の単語と区別してメール文章表示箇所に再表示する区別表示手段10と、区別表示手段10にて区別して表示された単語に関する解説文を表示可能とするための解説文表示手段11とを備えた。
(もっと読む)
画像処理装置、画像処理方法、そのプログラムおよび記憶媒体
【課題】PDLデータ中のテキストオブジェクトから文字コードを抽出するだけでは、有効な検索インデックスを付与することができないことがあった。
【解決手段】画像読み取り装置で読み取られた画像データ、および、ホストから送信されたPDLデータをレンダリングした画像データに対し、関連するメタデータを付与して格納する画像処理装置において、PDLデータをレンダリングした後の画像データに対して、画像データ中のオブジェクト毎にそれを含むように領域分割を行う分割手段と、分割手段により分割された領域の中から文字オブジェクトを判別する判別手段と、判別手段により判別された文字オブジェクトに対して文字認識処理を施して文字コード情報を抽出する文字認識手段と、文字認識手段により抽出された文字コード情報を含むメタデータを前記画像データ付与するメタデータ付与手段とを備える。
(もっと読む)
情報収集方法、装置及びプログラム
【課題】Web文書に含まれるタグに基づいて、項目、属性及び属性値の関係を有する情報を抽出することにより、項目に関する情報をWeb文書から自動的に収集する。
【解決手段】情報収集装置1は、通信ネットワークNを介してアクセス可能なWeb文書から、Web文書に含まれるタグに基づいて表形式あるいはデータベース形式の情報を抽出する情報群抽出手段12と、抽出した表形式あるいはデータベース形式の情報から、前記タグが示す各情報間の従属関係に基づいて、所定の項目に対して従属する関係にある属性及び前記属性の内容を示す属性値の関係を有する情報を抽出し、抽出した前記項目、属性及び属性値の関係を有する情報を関連付けて記憶手段に記憶する属性関係抽出手段13と、を備える。
(もっと読む)
質問回答検索システム及びその方法とプログラム
【課題】入力された質問文からでは回答が絞り込めない場合に、適切な絞込みキーワードを提示し、回答の特定を支援する質問回答検索システム及びその方法とプログラムを提供すること。
【解決手段】質問文と回答文との対を含む事例が記憶された事例データベースと、事例の質問文に含まれるキーワードの重要度を質問文の対の回答文同士の類似度を用いて計算し、重要度に基づいて、問い合わせ文に対する回答を絞り込む為の絞込みキーワードを前記キーワードから選択する絞込みキーワード選択手段とを有する質問回答検索システムである。
(もっと読む)
他言語の概念ベクトル生成装置及び方法及びプログラム及びコンピュータ読取可能な記録媒体
【課題】概念ベースを持たない言語において、固有名詞を含んだ概念ベクトルを高精度に算出する。
【解決手段】本発明は、言語Bの単語が2言語辞書記憶手段に登録されていない場合に、該言語Bの単語に基づいて、言語B固有名詞意味カテゴリ表記憶手段を参照して、該単語に対応付けられている意味カテゴリ名を取得し、該意味カテゴリ名に基づいて言語A概念ベース記憶手段を参照して、該言語Bの単語の概念ベクトルを生成する。更に、生成された言語Bの単語の概念ベクトルを言語B単語概念ベース記憶手段に格納し、言語Bの文書が入力されると、該文書を単語分割し、分割された単語の該文書における出現頻度を求め、単語に基づいて言語B単語概念ベース記憶手段を参照して、該単語をベクトルに変換し、出現頻度による加重平均をとり、該加重平均を文書ベクトルして出力する。
(もっと読む)
141 - 160 / 566
[ Back to top ]