
Fターム[5B075NK32]の内容
検索装置 (67,127) | 検索キー情報 (8,147) | 検索キー情報の自動抽出 (2,419) | 自然言語解析による検索キーの抽出 (1,229)
Fターム[5B075NK32]の下位に属するFターム
不要語辞書 (35)
限定辞書 (43)
類義語拡張を伴うもの (357)
Fターム[5B075NK32]に分類される特許
1 - 20 / 794
検索装置、検索方法、および、検索装置用のプログラム
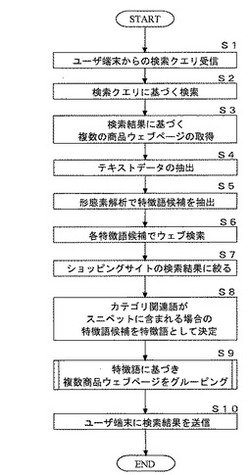
【課題】ユーザが見やすい検索結果を提示してユーザの利便性の向上を図る。
【解決手段】ユーザ端末45からユーザ検索クエリを受信し(S1)、ユーザ検索クエリに基づく複数の商品ウェブページを同一のカテゴリに属している商品ウェブページの中から取得し(S3)、各商品ウェブページ内に記述されているテキストデータを抽出し(S4)、テキストデータを言語解析して各商品ウェブページの特徴語候補を抽出し(S5)、特徴語候補を検索キーワードとする検索クエリを作成して検索クエリに基づく検索結果を取得し(S6)、検索結果のスニペット中にカテゴリ関連語が存在するか否かを判定し、スニペット中にカテゴリ関連語が存在する場合の特徴語候補を特徴語に決定し(S8)、複数の商品ウェブページを特徴語毎にグルーピングし(S9)、特徴語毎にグルーピングした商品ウェブページに関する情報を検索結果としてユーザ端末に送信する(S10)。
(もっと読む)
商品ウェブページ分析装置、商品ウェブページ分析方法、および、商品ウェブページ分析装置用のプログラム

【課題】商品ウェブページの商品の類似性を求めてユーザの利便性の向上を図る。
【解決手段】第1の商品ウェブページおよび第2の商品ウェブページを取得し(S1)、各商品ウェブページ内に記述されているテキストデータを抽出し(S2)、テキストデータを言語解析して各商品ウェブページの特徴語候補を抽出し(S3)、特徴語候補を検索キーワードとする検索クエリを作成して検索クエリに基づく検索結果を取得し(S4)、検索結果のスニペット中にカテゴリ関連語が存在するか否かを判定し、スニペット中にカテゴリ関連語が存在する場合の特徴語候補を特徴語に決定し(S6)、特徴語に基づき、第1および第2の商品ウェブページ間の類似度を算出し(S7)、類似度が所定の値以上である場合、第1および第2の商品ウェブページは類似商品を扱う商品ウェブページであると判定する(S8)。
(もっと読む)
情報検索装置、情報検索方法、及び情報検索プログラム
【課題】ユーザの感覚に関連する商取引の対象を検索する。
【解決手段】商取引の対象についてユーザが入力した文章情報を端末装置から受信する文章情報受信手段と、受信された文章情報からキーワードを抽出し、抽出されたキーワードを、受信された文章情報が入力された商取引の対象の画像に関連する関連キーワードとして、キーワード記憶装置に記憶させるキーワード抽出手段と、複数の商取引の対象の画像を端末装置に表示させる画像表示情報を、端末装置に送信する画像表示情報送信手段と、画像表示情報を受信した端末装置から、端末装置により表示された画像のうちユーザにより選択された画像を示す選択画像情報を受信する選択画像情報受信手段と、受信された選択画像情報が示す画像に関連する関連キーワードを検索のキーワードとして、商取引の対象を検索する検索手段と、を備える。
(もっと読む)
情報処理装置及び情報処理方法
【課題】コンテンツから抽出したキーワードを表示する情報処理装置を提供する。
【解決手段】実施形態によれば、情報処理装置はコンテンツ表示手段と、抽出手段と、記憶手段と、キーワード表示手段とを具備する。抽出手段は表示手段により表示されているコンテンツからキーワードを抽出する。記憶手段は抽出された第1キーワードを記憶する。キーワード表示手段は抽出された第1キーワードと記憶手段から読み出された第2キーワードとを表示する。
(もっと読む)
拾い読み支援システム、拾い読み支援方法及びプログラム
【課題】多数の文書の拾い読みを支援すること。
【解決手段】実施形態によれば、文書記憶部、表示部、入力部、分類情報記憶部、抽出部、特定部を含む。文書記憶部は、複数の文書を識別情報とともに記憶する。ユーザは、表示部の文書を閲覧し、文書と付与する分類タイプを入力部から指示する。分類情報記憶部は、ユーザ指示された文書の分類タイプを記憶する。抽出部は、同一の分類タイプが対応付けられている1又は複数の前記文書から、当該分類タイプについてハイライト表示すべき1又は複数の単語又はフレーズを抽出する。特定部は、ユーザから分類タイプが付与されていない文書の各々について、当該文書中で上記単語又はフレーズをハイライト表示すべき箇所を特定する。表示部は、文書を表示するにあたって、上記箇所で上記単語又はフレーズをハイライト表示する。
(もっと読む)
プログラムおよび情報処理装置
【課題】特定の患者本人の傷病に言及する傷病名であるか否かに応じたコードの付与を支援する。
【解決手段】傷病名文字列検出部120は、傷病名を表す用語の情報を含む傷病名辞書101を参照して、ある患者に関して記述された文章に含まれる文字列である対象文字列のうち、傷病名の文字列を特定する。一般論条件情報104は、特定の患者の傷病に言及していない表現の条件として予め設定された条件を表す。一般論判定部150は、特定された傷病名の文字列が、対象文字列中の文字列であって一般論条件情報104が表す条件を満たす文字列に含まれる場合に、当該特定された傷病名の文字列を、対象文字列を含む文章の記述の対象である患者本人の傷病に言及していない傷病名であると判定する。
(もっと読む)
広告閲覧システムおよび広告閲覧方法
【課題】ユーザの操作を必要とせずに、ユーザの周囲から収集した情報をもとに、ユーザが遭遇した広告に関する情報を提供することができる広告閲覧システムおよび広告閲覧方法を提供する。
【解決手段】携帯端末20と情報連携サーバ30とWebサーバ40とを含み、携帯端末20は、位置情報ログまたは音声情報ログを収集し、収集した位置情報ログまたは音声情報ログを情報連携サーバ30に送信し、情報連携サーバ30は、広告を特定するための情報を含む広告情報が1つまたは複数登録された広告情報リストを記憶する記憶手段31と、受信した位置情報ログまたは音声情報ログに対応した広告を広告情報リストから抽出する抽出手段32と、抽出された広告に関する情報が登録された広告抽出リストをWebサーバ40に送信する送信手段33とを含み、Webサーバ40は、受信した広告抽出リストをWebページとして提供する。
(もっと読む)
Webサービス連携システム、Webサービス連携方法、及びプログラム
【課題】複数のキーワードの入力を要するWebサービスを文書に関連付ける
【解決手段】Webサービス連携装置10の属性読み出し部15は、文書に含まれる複数の単語の属性を特定し、Webサービス読み出し部17は、特定した属性の組み合わせを用いることで利用できるWebサービスを特定する。そして、Webサービス読み出し部17は、当該単語の属性値の組み合わせに特定したWebサービスを適用した文書を生成し、出力部19は、当該文書を利用者端末20に出力する。
(もっと読む)
Nグラム検索のための転置インデックスの生成方法および生成装置、当該転置インデックスを用いた検索方法および検索装置、ならびに、コンピュータプログラム
【課題】検索漏れを抑えるのに好適な転置インデックスの生成方法等を提供する。
【解決手段】生成装置1は、複数の文書データ(文書データ群500)のそれぞれを、所定の変換規則に基づいて、変換文書データに変換する文書文字列変換部101と、変換された複数の文書データに含まれる文字列から、「N文字の文字列であるNグラム(Nは自然数)」を抽出する文書Nグラム抽出部102と、抽出されたNグラムと、変換文書データ中における当該Nグラムの出現位置と、を構成要素とする転置インデックス600を生成するインデックス生成部103と、を備えることを特徴とする。
(もっと読む)
情報提供プログラム、情報提供装置および情報提供方法
【課題】被提供者に対して被写体の状態についてわかりやすい情報を提供すること。
【解決手段】読影画像P1は、読影の対象の画像であり、被写体の画像である。所見文書データDtは、読影画像P1に対する所見の文書データである。説明文書データDvは、読影画像P1に対する説明の説明音声データから変換された文書データである。ここで、所見文書データDtにおける医学用語が一般的な用語に変換される。そして、変換後の所見文書データDtの文字列から、説明文書データDvの文字列と一致する一致文字列が抽出される。抽出された一致文字列が、読影画像P1に設けられたキーワードの欄に印字され、患者用読影画像P2として出力される。これにより、一般的な用語を添付した患者用読影画像P2が作成される。
(もっと読む)
ミニブログ解析装置及び方法
【課題】ミニブログ内における注目度の高い話題を正確かつ自動的に抽出すること。
【解決手段】ミニブログ解析装置(1)は、検索ログに記憶される複数のクエリから様々な長さからなるクエリ形態素を生成するクエリ解析手段(11)と、複数のクエリ毎に、生成されたクエリ形態素に基づいてミニブログ内のコンテンツを検索し、様々な長さからなるクエリ形態素のうちコンテンツに含まれる最も長いクエリ形態素を当該コンテンツに対して対応付けるマッピング手段(31)と、コンテンツに対応付けられたクエリ形態素を含むミニブログ内のコンテンツの数に基づいて、ミニブログ内における当該クエリ形態素の注目度を算出するスコア算出手段(41)と、を備える。
(もっと読む)
単語抽出装置、単語抽出方法及びプログラム
【課題】辞書を用いずに、テキストに頻出する単語を精度良く抽出する。
【解決手段】単語抽出装置1は、文字数が所定文字数以上の文字列であって、テキストに所定回数以上出現する文字列を対象文字列として前記テキストから抽出する対象文字列抽出部と、他の対象文字列の部分文字列であって、前記テキストにおいて前記他の対象文字列に包含される位置以外に出現する回数が前記所定回数より小さい文字列を前記対象文字列抽出部により抽出された対象文字列の集合から削除する第1の削除部と、前記第1の削除部により文字列を削除した後の対象文字列の集合に含まれる文字列を単語とする単語抽出部とを備える。
(もっと読む)
画像処理装置およびプログラム
【課題】複数の頁から構成される原稿の特徴文字列を、本構成を有していない場合と比較して効率的に決定可能な画像処理装置を提供する。
【解決手段】特徴文字列候補抽出部32は、原稿に関する文字列である特徴文字列の候補を、頁ごとに1つずつ抽出する。頁情報算出部34は、特徴文字列候補それぞれに関する頁に関する頁情報を頁ごとに算出する。特徴文字列決定部36は、各頁から特徴文字列候補が算出されその特徴文字列候補に関する頁情報が算出されるごとに、その特徴文字列候補に関する頁情報に基づいて、原稿全体の特徴文字列を決定する。
(もっと読む)
評価装置および評価方法
【課題】イベントにおいて出現した語句がそのイベントの主題に適合している程度をより正確に評価する。
【解決手段】個別イベント内語句出現頻度特定部112は、イベントメタデータの内容に基づき、各個別イベントにおいて出現した各語句の出現頻度(個別イベント内語句出現頻度)を個別イベントごとに特定する。イベント群内語句出現頻度特定部113は、イベントメタデータの内容に基づき、イベント群において出現した各語句の出現頻度(イベント群内語句出現頻度)を特定する。制御部11は、個別イベント内語句出現頻度とイベント群内語句出現頻度とに基づいて、語句がイベントの主題に適合している程度に応じた評価値を算出する。視聴者にとって有用な内容の個別イベントを選別するとき、主題との適合の程度が低いと評価された語句よりもその適合の程度が高いと評価された語句を優先的に用いる。
(もっと読む)
話題抽出装置及びプログラム
【課題】指定した対象期間において、話題の変遷を提示する。
【解決手段】一つの実施形態によれば、話題抽出装置は、話題抽出手段及び話題提示手段を備えている。前記話題抽出手段は、単語抽出手段及び話題語抽出手段を備えている。前記単語抽出手段は、対象文書集合から各単語を抽出し、当該各単語の出現頻度及び当該各単語が出現する文書頻度を算出する。前記話題語抽出手段は、前記抽出された各単語について、前記対象期間における出現文書の文書集合を取得し、話題語らしさを表す尺度である話題度を算出し、前記話題度が所定の値以上の単語を話題語として抽出すると共に、当該抽出された話題語について当該対象期間における出現日時に基づいて新鮮度を算出する。前記話題提示手段は、前記抽出された話題語を前記新鮮度の順に提示すると共に、当該提示した各話題語について単位期間毎の出現文書数を提示する。
(もっと読む)
情報提供装置及び情報提供方法、プログラム
【課題】ユーザが興味のある情報を、適切なタイミングで提供する。
【解決手段】受信部101は、受動的にデータを受信し、関心情報抽出部103へ出力する。関心情報抽出部103は、受信部101が受信した情報から、ユーザが関心を示す可能性のある情報を抽出し、興味情報判断部111へ出力する。興味情報判断部111は、ユーザが興味を有すると判断した興味情報を分類分けして蓄積し、興味情報伝達部117は、表示部121を介して興味情報を表示させるために、興味情報に関連付けられたアプリケーションに当該興味情報を伝達する。
(もっと読む)
自然言語バンキング処理サーバ及び自然言語バンキング処理方法
【課題】ミニブログ等に入力した自然言語テキストをそのまま銀行等の金融機関のネット取引に利用することのできるシステムを提供する。
【解決手段】自然言語バンキング処理サーハは、インターネットに接続されたミニブログ等の自然言語入力手段から自然言語テキストを受信する。受信した自然言語テキストを形態素解析し、金融機関の取引に用いられるキーワードを予め登録したキーワードDBを用いて所定のキーワードを抽出する。そして、抽出したキーワードと、取引を行なおうとするユーザの登録情報に基づいて、金融取引の要求データを生成し、専用ネットワークで接続された金融機関のシステムに送信する。取引の要求が完了した際には、ユーザへの返信のための自然言語テキストを生成して自然言語入力手段に返信する。
(もっと読む)
集合拡張処理装置、集合拡張処理方法、プログラム、及び、記録媒体
【課題】意味的に同一のカテゴリに含まれる語を選択するのに好適な集合拡張処理装置等を提供する。
【解決手段】受付部101がシード文字列を受け付ける。検索部102がシード文字列を含む文書のスニペットを得る。セグメント取得部103が当該スニペットをセグメント区切文字列で区切ってセグメントを得る。セグメント要素取得部104がセグメントをセグメント要素区切文字列で区切ってセグメント要素を得る。セグメントスコア計算部105がセグメントのセグメントスコアをセグメント要素の長さの標準偏差から計算する。セグメント要素スコア計算部106がセグメント要素のセグメント要素スコアをシード文字列の位置とセグメント要素の位置との距離とセグメントスコアから計算する。選択部107がセグメント要素スコアに基づいてセグメント要素からいずれかをシード文字列の拡張集合に含まれるインスタンスの候補として選択する。
(もっと読む)
電子書籍用目次生成システム
【課題】電子書籍において一般ユーザが興味のある分野に即した目次を新たに生成することができ、ひいてはユーザが興味のある分野に関する記事を効率的に閲覧することが可能な電子書籍用目次生成システムを提供する。
【解決手段】電子書籍用目次生成装置100は、一般ユーザの興味のある分野に即した複数のカテゴリと、各カテゴリに関連付けられた一ないし複数の所定の単語とから構成されるカテゴリ表を予め記憶しているカテゴリ記憶部110と、電子書籍のコンテンツデータから単語を抽出する単語抽出部130と、カテゴリ記憶部110のカテゴリ表を参照することにより、単語抽出部130により抽出された単語に基づいて複数のカテゴリを設定するカテゴリ設定部140と、カテゴリ設定部140により設定された複数のカテゴリを使用して電子書籍の目次を生成する目次生成部160とを備える。
(もっと読む)
候補提示装置、方法及びプログラム
【課題】従来よりも適切に候補を提示することにより、映像等のコンテンツの検索を容易にする技術を提供する。
【解決手段】メタデータ記憶部1には、コンテンツについての情報をメタデータとして、各コンテンツのメタデータが記憶されている。言語処理部2が、メタデータを構成する文字列を予測変換候補語として抽出する。抽出された予測変換候補語は予測変換候補語記憶部3に記憶される。露出度計算部5が、予測変換候補語がコンテンツに関連する所定のデータに現れる頻度についての情報をその予測変換候補語のその所定のデータについての露出度として、各予測変換候補語の露出度を計算する。予測変換候補語抽出部7が、ユーザによって入力された文字列を含む予測変換候補語を予測変換候補語記憶部から抽出する。候補語ソート部8が、抽出された予測変換候補語を露出度が高い順に出力する。
(もっと読む)
1 - 20 / 794
[ Back to top ]