
Fターム[5B075NR05]の内容
Fターム[5B075NR05]の下位に属するFターム
検索キー情報の格納形態の整理 (228)
Fターム[5B075NR05]に分類される特許
1 - 20 / 492
制御プログラム
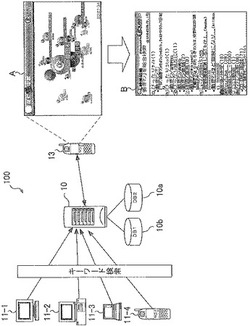
【課題】複数の端末装置から通信ネットワークを介して検索エンジンに入力された検索情報を管理する。
【解決手段】複数の端末装置11−1〜11−4から通信ネットワークを介して検索エンジンに入力された検索情報を管理するサーバ10の制御プログラムであって、各端末装置11−1〜11−4から通信ネットワークを介して検索エンジンに入力された検索キーワードを収集し、リスト化してデータベースに保存する処理と、いずれかの端末装置からデータを取得するリクエストを受信する処理と、リクエストを受けたときに、予め定められた規則に該当する検索キーワードを前記データベースから抽出する処理と、前記抽出した検索キーワードを、前記リクエストを発した端末装置に送信する処理と、の一連の処理を、コンピュータに読み取り可能および実行可能にコマンド化した。
(もっと読む)
コンテンツ管理装置

【課題】コンテンツに含まれるオブジェクトの属性値を正確に特定する。
【解決手段】記憶手段2は、コンテンツと、コンテンツに含まれるオブジェクトの属性値との組合せを記憶し、記憶手段3は、コンテンツに含まれるオブジェクトに対応付けて、オブジェクトの属性値の候補と、候補を提示した利用者名とを含む認識情報を記憶し、記憶手段4は、利用者名に対応付けて影響度を記憶する。登録手段5は、利用者から、コンテンツに含まれるオブジェクトについて、属性値の候補と、候補を提示した利用者名とを含む認識情報を受信し、該受信した認識情報を記憶手段3に記憶する。更新手段6は、記憶手段3から認識情報を読み出し、前記オブジェクトについて前記属性値の候補を提示した利用者の影響度を考慮して、前記属性値の候補のポイントを算出し、算出したポイントが第1の閾値を超える候補の属性値とコンテンツとオブジェクトとの組合せを記憶手段2に追加する。
(もっと読む)
構造化文書管理装置、方法およびプログラム
【課題】構造照合処理を高速に行うことができる構造化文書管理装置、方法およびプログラムを提供することである。
【解決手段】実施形態の構造化文書管理装置は、入力されたクエリデータが、構造化文書データの論理構造における階層の上下関係を指定する第1条件と、要素IDで特定される要素の順序関係を指定する第2条件とを含む場合に、クエリデータ分解手段が、該クエリデータを、第1条件のみを含む第1の部分クエリデータと、第1の部分クエリデータによる照合結果を、第2条件に応じて結合演算する手順を含む第2の部分クエリデータとに分解する。構造照合処理手段は、構造化文書データのデータ集合に対して第1の部分クエリデータによる照合を行い、照合結果を出力する。結合演算処理手段は、構造照合処理手段から出力された照合結果を、第2の部分クエリデータに含まれる結合演算の手順に従って結合演算処理する。
(もっと読む)
データ分析支援装置およびプログラム
【課題】任意のデータテーブル間において適切な属性の対応づけを行うことが可能なデータ分析支援装置およびプログラムを提供することにある。
【解決手段】第1の単語抽出手段は、第1のデータテーブルを構成する第1の文字列型属性が有する属性値から第1の単語を抽出する。第2の単語抽出手段は、第2のデータテーブルを構成する第2の文字列型属性が有する属性値から第2の単語を抽出する。類似度算出手段は、第1の抽出手段によって抽出された第1の単語および第2の抽出手段によって抽出された第2の単語に基づいて、第1のデータテーブルを構成する第1の文字列型属性および第2のデータテーブルを構成する第2の文字列型属性の類似度を算出する。類似属性候補抽出手段は、類似度算出手段によって算出された類似度に基づいて、第1の文字列型属性および第2の文字列型属性を類似属性候補として抽出する。
(もっと読む)
関連語抽出装置、関連語抽出方法、関連語抽出プログラム
【課題】多様性のある関連語をより少ないデータの解析で抽出し、ユーザに提示する。
【解決手段】バースト検出手段4は、検索ログDB3のクエリログを任意の日時単位で解析し、検索回数が急増した検索語を検出する。検出結果はバースト情報DB5に保存する。関連語抽出手段6は、前記DB5の保存データを参照して検出日毎に検索語を取得し、クエリログから検索語の関連語群を抽出する。抽出された関連語群はバースト関連語情報DB7に保存される。関連語出力手段8は、検索エンジン2からの要求としてユーザ入力の検索語を受け取る。受け取った検索語の関連語を前記DB7から取得し、検索エンジン2に返答する。
(もっと読む)
複合語生成装置、複合語生成方法、および複合語生成プログラム
【課題】 学習テキストなどを利用することなく、複合語を生成することができる複合語生成装置および複合語生成方法を提供することを目的とする。
【解決手段】 テキスト分割部101が入力されたテキストを、空白文字に基づいて複数の文字列に分割し、文字列生起回数集計部102が、テキスト分割部101により分割された文字列の各々について生起回数を計数するとともに、分割された文字列を候補文字列として含む文字列集合を作成する。そして、文字列生起回数集計部102により作成された文字列集合に含まれる候補文字列に基づいて、要素文字列組合せ抽出部103は、複合語の要素となる要素文字列を複数連結して候補文字列を構成可能な要素文字列の組み合わせを文字列集合から抽出する。
(もっと読む)
クエリ提供装置、クエリ提供方法及びクエリ提供プログラム
【課題】推薦されるクエリを高速に選択することを第1の課題とする。
【解決手段】キーワードの意味的な類似性に基づいてキーワード間の距離を計算し、キーワードからキーワード間距離を探索可能な距離行列データを生成して記憶手段に記憶しておくと共に、距離行列データを用いてキーワードを階層的クラスタリングし、階層的クラスタリングによって構築されたデンドログラムを下層から上層に探索可能なボトムアップインデックスとして記憶手段に記憶しておく。
(もっと読む)
セキュア検索システム、秘密検索装置、セキュア検索方法、セキュア検索プログラム
【課題】検索キーの大小関係の情報を漏らすことなく、対数時間での検索を行う。
【解決手段】本発明のセキュア検索システムは、ランダムスライド手段、要素探索手段、検索手段を備える。ランダムスライド手段は、乱数[r]を生成し、m番目の情報([km],[vm])を秘密計算によって(m−r mod M)番目もしくは(m+r mod M)番目に移動させ、移動後の情報を情報([k1’],[v1’]),…,([kM’],[vM’])とする。要素探索手段は、取得した値[t]と検索キー[km’]との大小比較を、t−k1’ mod qとkm’−k1’ mod qの大小比較によって行う。検索手段は、要素探索手段の大小比較の結果に基づいて、秘密分散された検索値もしくは秘密分散された検索区間に該当する検索キーkmを持つ情報([km’],[vm’])を検索する。
(もっと読む)
情報検索装置、情報検索方法、及び情報検索プログラム
【課題】略語に基づく情報検索の精度を向上させる。
【解決手段】略語を含んだクエリに適合する文書を検索する情報検索装置1において、追加キーワード取得部4はクエリ入力部2からクエリとして供された略語からなるキーワード及び検索範囲に対応する対応語群を追加キーワードDB3から取得する。そして、追加キーワード取得部4は対応語の主要度に基づき前記対応語群から取得した対応語を前記クエリの追加キーワードとする。範囲検索部6は前記キーワード、前記検索範囲及び前記追加キーワードに基づき文書DB5から情報検索を行う。この検索により得られた検索結果は検索結果出力部7から出力される。
(もっと読む)
管理装置、管理方法及びプログラム
【課題】ユーザの通信端末とは異なる管理装置に記憶されたファイル群のうちユーザが望むファイルをより正確に検索し得る仕組みを提供する。
【解決手段】管理装置30は、複数のユーザに共通する内容の一般振分定義と、各々のユーザで異なる内容のユーザ別定義とを記憶している。また、管理装置30は、ユーザ別に論理的に区分された記憶領域を有しており、各々の記憶領域に各ユーザが利用するファイル群が記憶される。さらに、管理装置30は、二次分析を行うことで各ファイルに対して属性情報と呼ばれる検索用の情報を生成し、そのファイルに対応付けて蓄積する。よって、ユーザが望むファイルをより正確に特定することができる。
(もっと読む)
サーバ、辞書生成方法、辞書生成プログラム、及びそのプログラムを記録するコンピュータ読み取り可能な記録媒体
【課題】ユーザの思考や行動が考慮された関連語辞書を生成すること。
【解決手段】検索サーバ10は、地理的位置を示す位置情報と、該位置に付与された語句と、該位置に該語句を付与したユーザを特定するユーザIDとが互いに関連付けられたカテゴリ情報を記憶するカテゴリデータベース14と、第1のユーザにより第1の語句が付与された位置を示す第1入力情報と、第2のユーザにより第2の語句が付与された位置を示す第2入力情報とを読み出し、これらの情報に基づいて、該第1及び第2のユーザが所定数以上の共通の位置で語句を付与したと判定した場合に、第1及び第2の語句が関連付けられた辞書データを生成し、該辞書データを辞書データベース16に登録する辞書登録部15とを備える。
(もっと読む)
サーバ、情報管理方法、情報管理プログラム、及びそのプログラムを記録するコンピュータ読み取り可能な記録媒体
【課題】各ユーザにより入力された場所に関する情報を適切に結合すること。
【解決手段】サーバは、地理的位置を示す位置情報と、該位置に付与された語句と、該位置に該語句を付与したユーザを特定するユーザIDとが互いに関連付けられた入力情報を記憶する入力情報データベース14と、語句間の関連を示す辞書データを記憶する辞書データベース15と、これらのデータベースを参照して、地理的位置が所定の一の地理的範囲に含まれ、且つ語句同士が互いに関連している複数の入力情報を抽出し、共通の識別子を抽出された複数の入力情報に割り当てることで該複数の入力情報を互いに関連付けた上で、該複数の入力情報を入力情報データベース14に登録する関連付け部17とを備える。
(もっと読む)
管理装置、管理方法、及びプログラム
【課題】フィルタの優先度の設定を変更することなく、フィルタ処理の工数を低減し得る、管理装置、管理方法、及びプログラムを提供する。
【解決手段】管理装置100は、機器210から受信したメッセージのメタデータから、出現頻度が閾値以上となるメタデータをキーワードとして抽出するキーワード分析部113と、メッセージを選別するフィルタ群を、キーワードに関連する第1のフィルタとこれ以外の第2のフィルタとに分け、キーワード毎の第1のフィルタグループと第2のフィルタグループとを作成するフィルタグループ作成部114と、受信したメッセージのメタデータが、抽出されたキーワードと一致するか判定し、判定結果に基づいて、適用するフィルタグループを選択するフィルタグループ振分け部115と、受信したメッセージに対して、選択されたフィルタグループを適用する、フィルタグループ適用部116とを備える。
(もっと読む)
サーバ、情報管理方法、情報管理プログラム、及びそのプログラムを記録するコンピュータ読み取り可能な記録媒体
【課題】各ユーザにより入力された場所に関する情報を適切に結合すること。
【解決手段】検索サーバ10は、地理的位置を示す位置情報と、該位置に関する入力操作を行なったユーザを特定するユーザIDとが互いに関連付けられた入力情報を記憶する入力情報データベース14と、入力情報データベース14を参照して、所定数以上の共通の地理的範囲において複数の共通のユーザが入力操作を行ったか否かを判定する判定部17と、所定数以上の共通の地理的範囲において複数の共通のユーザが入力操作を行ったと判定された場合に、所定数以上の共通の地理的範囲のそれぞれについて、位置情報で示される地理的位置が共通の地理的範囲に含まれ、且つ、複数の共通のユーザに対応する複数の入力情報を抽出し、抽出された前記複数の入力情報に対して共通のロケーションIDを割り当てることで複数の入力情報を互いに関連付けた上で、該複数の入力情報を入力情報データベース14に登録する関連付け部18とを備える。
(もっと読む)
プログラムコンポーネント検索方法、プログラムコンポーネント検索システムおよびコンポーネント検索プログラム
【課題】 あまりスキルの高くない技術者でも導入が容易で、使っているうちに、自分たちの技術に合せた検索が出来るような、ソフトウェア開発効率向上のためのコンポーネントの登録・検索技術を提供することを目的とする。
【解決手段】 これまでの機能名やあいまい検索を中心とした検索のほかに、コンポーネントに検索用のインデックス情報を付加し、検索に利用する。利用者による検索が行われたときには、キーワードと検索結果を履歴情報として登録しておく。履歴情報から抽出したキーワードを優先度を付けて検索インデックスに登録していく。これにより、利用者の利用状況やコンポーネントの実績情報を取り込みながら、利用者にとって有用な検索キーワードを増やしていくことで、使えば使うほど利用者のレベルや経験にそった検索が可能になる。
(もっと読む)
データ分類システム、データ分類方法およびプログラム
【課題】データの文字列が完全に一致しない場合や表現が異なる場合においても、データを分類することができるデータ分類システム、データ分類方法およびプログラムを提供する。
【解決手段】データ分類システム100は、データ取得部11、文字列抽出部12、判定部13、変換部14および分類部15を含む処理装置1と、データ情報21、辞書情報22、変換ルール23およびカテゴリ情報24などを記憶する記憶部2、入力部3および出力部4を備える。データ取得部11は、検索可能な文字列を含むデータを取得する。文字列抽出部12は、データに含まれる所定の文字列を抽出する。変換部14は、変換ルール23に基づき所定の文字列を変換する。判定部13は、所定の文字列または変換した文字列と基準の文字列との類似度をカテゴリ情報24に基づき判定する。分類部15は、所定の文字列を対応するカテゴリ情報24のカテゴリにグルーピングする。
(もっと読む)
文書インデックス作成装置
【課題】文書ファイルの記述内容に可及的に即した文書インデックスを作成する。
【解決手段】ネットワークシステムSは、文書データベース10と、この文書データベース10に対して所定の検索アルゴリズムを用いて検索処理を行う検索エンジン20と、ユーザが利用する端末装置30と、文書検索用の文書インデックスの作成処理を行うデータ処理装置40とを含む。データ処理装置40は、一の文書ファイルの文書データを複数の段落に区分すると共に、注目単語Aを含む第1単位文章(段落)と、注目単語Aを含まない第2単位文章(段落)とに区別する。そして、第1単位文章と第2単位文章との文章関連度を評価し、第2単位文章の段落重み値を求める。注目単語Aの出現頻度に基づく基礎重み値に、前記段落重み値を加算することで、当該注目単語Aの重み値を設定する。
(もっと読む)
サジェスチョンクエリ抽出装置及び方法、並びにプログラム
【課題】ジェネリックパターンの存在に起因して生ずる意味ドリフトを抑制し、サジェスチョンクエリの抽出の精度の向上を図ること。
【解決手段】インスタンスパターン行列生成部62のうち、正規化自己相互情報量演算部71は、インスタンスパターン行列の各要素毎に、正規化自己相互情報量を演算する。エッジカット部72は、正規化自己相互情報量の値が閾値th以下である要素のエッジを削除する。正規化ラプラシアン行列演算部63は、このようなインスタンスパターン行列生成部62によって生成されたインスタンスパターン行列を用いて、正規化ラプラシアン行列を演算し、カーネルとして正規化ラプラシアン行列保持部43に保持させる。
(もっと読む)
キーワード提示装置、方法及びプログラム
【課題】電子文書集合からキーワードを抽出し、クラスタリングして提示する。
【解決手段】実施形態に係るキーワード提示装置は、文書集合から、所定の汎用概念辞書に規定されている形態素列を基本用語候補として抽出する抽出部101と、文書集合から、汎用概念辞書に規定されていない形態素列を専門用語として抽出する抽出部104とを含む。このキーワード提示装置は、基本用語候補の各々と専門用語との間の関連性を評価し、関連性の高い基本用語候補を優先的に基本用語として選定する選定部106を含む。このキーワード提示装置は、文書集合に基づく基本用語間の統計的な相関度と汎用概念辞書に基づく基本用語間の概念的な相関度との重み付き和を計算し、重み付き和に基づいて基本用語をクラスタリングするクラスタリング部107を含む。
(もっと読む)
Nグラム検索のための転置インデックスの生成方法および生成装置、当該転置インデックスを用いた検索方法および検索装置、ならびに、コンピュータプログラム
【課題】データ容量が効率的に抑えられた転置インデックスの生成方法等を提供する。
【解決手段】文書入換ステップと、生成ステップと、合成ステップと、を備えた転置インデックスの生成方法であって、文書入換ステップでは、それぞれが、見出し語と対応する複数の説明文とから構成される複数の文書データ18のうち、少なくとも1つの文書データ18の複数の説明文の順序を入れ換えて、入換文書データを作成し、生成ステップでは、文書データ18もしくは作成された入換文書データから、「N文字の文字列であるNグラム(Nは自然数)」を抽出し、抽出されたNグラムのそれぞれについて、当該文書データ18もしくは当該入換文書データ中の出現位置を対応付けて、部分転置インデックスを生成し、複数の文書データ18について生成された複数の部分転置インデックスから、転置インデックスを合成する。
(もっと読む)
1 - 20 / 492
[ Back to top ]