
Fターム[5B075NS02]の内容
Fターム[5B075NS02]に分類される特許
1 - 20 / 45
サーバ装置
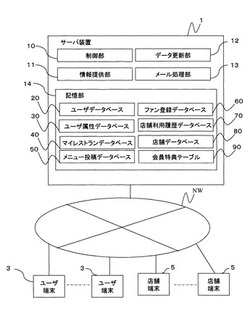
【課題】複数のユーザ端末とネットワークを介して接続され且つ各ユーザ端末に対して店舗情報を提供するサーバ装置において、店舗の選定に有効な情報を提供することを目的とする。
【解決手段】ユーザ端末3とネットワークNWを介して接続され且つ各ユーザ端末3に対して店舗情報を提供するサーバ装置1であって、ユーザ端末3のユーザを識別する識別情報毎にそのユーザの飲食に関する嗜好を示した嗜好情報を関連付けたユーザ属性データベース30と、ユーザ端末3からの要求に応じて、ユーザ属性データベース30を用いてユーザ端末のユーザ用の画像情報を生成しユーザ端末3に該画像情報を送信する情報提供部11とを設ける。画像情報には、ユーザ端末のユーザの飲食に関する嗜好をグラフ化して示したユーザ嗜好情報が含まれている。
(もっと読む)
有向グラフ作成装置、有向グラフ作成方法、及び有向グラフ作成プログラム

【課題】複数のイベント連鎖が統合された有向グラフより元のイベント連鎖には存在しない経路を除去すること。
【解決手段】有向グラフ作成装置は、複数のイベント連鎖を記憶するイベント連鎖記憶部と、該複数のイベント連鎖を統合して作成された有向グラフを記憶する有向グラフ記憶部とを参照して、該有向グラフが含む経路の中で、該複数のイベント連鎖のいずれにも存在しない経路を特定する特定部と、特定された経路において下流側に複数のエッジが接続するノードの中で該経路の端点ノードを除く最下流のノード及び該ノードに接続するエッジの複製を作成する複製部と、複製されたエッジの中で、当該エッジを削除したとしても前記複数のイベント連鎖が含むいずれかの経路が前記有向グラフから除去されないエッジを削除する削除部とを有する。
(もっと読む)
データ解析装置、プログラム、記録媒体、データ解析方法、およびタンパク質解析装置
【課題】複数の測定データにおいて対応するポイント同士の対応付けを行う際の時間と労力を削減するとともに、複数の測定データにおいて対応するポイント同士の対応付けに要する時間や生じる間違いを軽減すること。
【解決手段】測定データ内から検出される測定対象を表わすポイントについて、前記測定対象が関連するポイント同士の対応付けを行うデータ解析装置であって、複数の前記測定データと、前記測定データにおける複数の前記ポイントの出現位置を表わすポイント情報とを入力する入力手段と、前記測定データにおける前記ポイントの出現位置が異なる前記測定データ間において互いに類似している程度を示す類似度を前記ポイント情報に基づき算出し、当該類似度に基づき前記ポイント同士を対応付けたポイント対応付け情報を作成する対応ポイント検出手段と、を備えることを特徴とする。
(もっと読む)
知識創造プロセスにおける技術軌道分析装置および分析方法
【課題】知識創造プロセスの分析に好適な分析装置が提案されていない。
【解決手段】ある一件の特許公報テキストは、ある一時点の技術課題、解決手段、作用・効果の要素からなるコンテキスト(一つの問題解決シナリオ)として記述されているものである。従って、Fタームのような特許分類を使用して技術課題、解決手段、作用・効果の3種類のいずれか1つ以上の技術要素の組合せによる論理関数の定義による技術知識特性(分析概念という)の時系列的な出現数の積分として所定の時間軸上に表示する(技術軌道という)ことを特徴とする知識創造プロセスの分析に好適な技術軌道分析装置を提供する。
(もっと読む)
ライフログ表示制御装置、方法及びプログラム
【課題】ユーザがライフログデータを閲覧するときの条件に応じてライフログデータに対する表示の優先度を可変設定できるようにし、ライフログデータの閲覧効率を高める。
【解決手段】ライフログデータの表示中に、表示されている時間帯と現在時刻を表す情報を定期的に取得してこれをスクロール操作履歴として時間軸操作情報一時記憶部31に記憶しておく。この状態で、ユーザ端末において再描画命令が入力された場合に、各ライフログデータについて、上記時間軸操作情報一時記憶部31に蓄積されているスクロール操作履歴情報を用い、ユーザ操作により表示画面上に表示されている時間が長いライフログデータと、当該ライフログデータに関連する他のライフログデータほど値が大きくなるように表示指数を計算し直す。そして、この計算し直された表示指数に従い、表示すべきライフログデータを選択し直して表示させる。
(もっと読む)
トークスクリプト利用状況算出システムおよびトークスクリプト利用状況算出プログラム
【課題】談話データの構造を解析した結果に基づいて、各業務におけるトークスクリプトの利用状況を算出するトークスクリプト利用状況算出システムを提供する。
【解決手段】談話データ101および談話セマンティクス200を入力とし、トークスクリプトの利用状況300を出力するトークスクリプト利用状況算出システム1であって、談話セマンティクス200は簡約情報61を含み、簡約された談話データ101におけるブロックと各トークスクリプトとの間の類似度を算出し、最も類似するトークスクリプトを類似度情報71として出力する類似度算出部70と、トークスクリプト毎に、簡約された談話データ101における各ブロックのうち、最も類似するものが当該トークスクリプトでありかつ類似度が所定の閾値より高いブロックの数を算出し、対象の応対業務が行われた数に対する利用頻度を算出して利用状況300として出力する利用状況算出部80とを有する。
(もっと読む)
文書解析プログラム及び文書解析システム
【課題】異なる文書の集合を対象にした異なるグラフ間について、比較する手段を提供する。
【解決手段】選択処理では、グラフ選択部202が、表示装置102に、比較する複数のグラフデータを、利用者に選択させる画面を表示させる。利用者によりグラフデータP及びQが選択されると、グラフデータ記憶部212から選択されたグラフデータP及びQを取得する。比較項目選択処理では、グラフ選択部202は、利用者に、比較されるグラフデータP及びQにおいて強調表示される比較項目を選択させるために、比較項目の種類を表示装置に表示させる。比較表示処理において、比較表示制御部204は、選択処理で選択されたグラフデータP及びQ及び比較項目に基づき、グラフデータPを表示しつつ、グラフデータQとの差分を強調する比較表示を行う。
(もっと読む)
臨床検査データ解析表示装置
【課題】臨床検査データの項目間の隠れた関係を、少ない検査項目で明確に抽出し、未病を検知することができる臨床検査データ解析表示装置を提供する。
【解決手段】あらかじめ格納していた検査データと正常と判断させる範囲の上限・下限よりなる基準値とを基に、クライアントの検査データから健康度を判断して表示するインタラクティブインタフェースを用い、臨床検査データの項目間の隠れた関係を抽出する。この関係抽出では、各検査項目における異常回数に注目する。そのため、インタラクティブインタフェースの特徴抽出部に関係行列算出部を付加するとともに、表示制御装置と表示装置の間の表示インタフェースに関係行列表示インタフェースを追加する。これにより、ある検査項目値から他の検査項目値の推定が可能となる。
(もっと読む)
コンテンツリスト選択支援装置およびコンテンツリスト選択支援方法
【課題】ユーザがコンテンツリストにどのようなコンテンツが登録されているのかを画面表示から一見して直感的に把握できるようにすることが可能な「コンテンツリスト選択支援装置およびコンテンツリスト選択支援方法」を提供する。
【解決手段】プレイリスト選択画面において、プレイリストに登録されている楽曲の全体数に対して占めるジャンル毎の楽曲数の比率をジャンル比率として算出し、当該算出したジャンル比率を横棒グラフ400〜440として表示することにより、その表示を見たユーザが、各ジャンルの楽曲がそれぞれプレイリスト全体の中でどの程度の割合を占めているかを視覚的に捉えることができるようにして、各プレイリストにどのような楽曲が登録されているのかを画面表示から一見して直感的に把握することができるようにする。
(もっと読む)
情報出力装置、情報出力方法、およびプログラム
【課題】従来、ブログ等の文章群の文脈を可視化できなかった。
【解決手段】一人以上の個人が入力した1以上の文章群を格納し得る文章群格納部と、前記文章群格納部に格納されている文章群に含まれる文から、動作や状態の主体である主体語または動作や状態の客体である客体語である対象物を取得する対象物取得部と、前記文章群格納部に格納されている文章群に含まれる文から、前記対象物に対応する用語であり、動作や状態を示す用語である動作状態を取得する動作状態取得部と、前記対象物と、当該対象物に対応する動作状態とを対応付けた図である対応図を出力する対応図出力部とを具備する情報出力装置により、ブログ等の文章群の文脈を可視化できる。
(もっと読む)
ファイル管理装置
【課題】個々のサブフォルダやファイルの内容を確認することなく、効率的にフォルダの中にあるファイルの概要について理解するためのファイル(文書)管理処理を提供する。
【解決手段】動的に(フォルダにカーソルを合わせる等アクセスする度に)フォルダ内に含まれる複数のファイルの概要を生成し、それを表示する。例えば、フォルダ内に含まれるファイルの属性における特徴または傾向に基づいて、siblingフォルダに含まれる複数のファイルとの比較において差が認められた特徴について概要を記述することおよび、クエリにヒットした文書の階層フォルダ内における位置の分布を表示する。
(もっと読む)
情報検索装置、情報検索方法、制御プログラム及び記録媒体
【課題】情報の検索結果の可視化において、表示される検索結果の態様を、ユーザの理解を助けるより有効な態様とすること。
【解決手段】本発明の一態様は、指定条件情報取得部101と、適合情報抽出部102と、抽出結果処理部103と、座標記憶部143とを有し、抽出結果処理部103は、適合情報抽出部102が抽出して分類情報に基づいて集計された集計結果情報が、座標記憶部143に記憶されている情報においてその分類情報に関連付けられている座標によって特定される位置に表示されるように抽出結果表示情報を生成し、座標記憶部143に記憶されている情報は、内容の類似する分類情報が座標空間上において近傍乃至隣接して配置されるように生成された情報であることを特徴とする。
(もっと読む)
コンテンツ評価装置
【課題】ユーザ同士のコンテンツの交換及びこのコンテンツの評価を迅速かつ容易に行うことが可能なコンテンツ評価装置を提供する。
【解決手段】コンテンツ評価装置103を、ユーザが投稿したテーマ1及び評価軸3を記憶するテーマテーブル30、テーマ1に対して投稿されたコンテンツ4を記憶する画像テーブル50、並びに、コンテンツ4の評価データをユーザタイプ2に対応付けて記憶する画像評価テーブル60を有するユーザ情報記憶部204と、テーマ1に対して設定された評価軸3、当該テーマ1に対して投稿されたコンテンツ4、及び、当該コンテンツ4のユーザタイプ2毎の評価データ5を取り出して、当該評価データ5からコンテンツ4の各々の評価軸3及び当該評価軸3上の表示位置を決定し、さらに、評価軸3及び表示位置に応じて当該評価軸3上に配置されたコンテンツ4を含むグラフを作成するグラフ処理部205とから構成する。
(もっと読む)
情報検索装置、情報検索方法、制御プログラム
【課題】情報の検索における検索結果の表示において、検索条件と検索対象情報との適合度を算出する前の、検索条件と検索対象情報との適合状況について、よりユーザに理解し易いように表示することを目的とする。
【解決手段】指定された条件に適合する適合文献を抽出する情報検索装置1であって、文献抽出条件となる文言に関する情報を取得する指定条件情報取得部101と、取得した指定条件情報に基づいて適合文献を抽出する文献情報抽出部103と、抽出された適合文献に関する情報を表示する適合文献表示情報を生成して出力する抽出結果処理部104とを有し、抽出結果処理部104は、抽出された複数の適合文献及び複数の文言うち一方を行とし、他方を列とするマトリクスを構成し、そのマトリクスにおける各セルに、当該セルが対応する適合文献における当該セルが対応する文言の使用回数を表示するように適合情報表示情報を生成することを特徴とする。
(もっと読む)
グラフ表示装置およびプログラム
【課題】分析対象の文単位集合全体における代表的な複数の語およびそれら語の間の関係をグラフ表示して文単位集合全体の傾向を示唆する。
【解決手段】語出現データ記憶部150は、語がどのメッセージで出現するかを示す語出現データを保持する。頻度計算部170は、対象語の各々が出現するメッセージが、対象メッセージ集合内にいくつあるかを計算する。語特定部180は、頻度計算部170で計算された頻度に基づいて、頻度が1位からL位までのL個の語を特定する。部分集合導出部160は、部分集合を導出して対応する語を特定し、ノードデータおよびリンクデータを生成する。グラフ表示部190は部分集合導出部160からノードデータおよびリンクデータを取得してグラフのネットワーク構造を決定しグラフ表示を行う。
(もっと読む)
中心性値計算装置および中心性値計算方法
【課題】グラフのサブグラフに含まれるノードの中心性を示す中心性値を計算する。
【解決手段】グラフ検索部16は、グラフデータベース11のグラフGから、指定された条件を基にして、サブグラフを検索する(S17)。中心性値計算部17は、サブグラフに含まれる各ノードにつき、当該サブグラフにおける中心性を示す中心性値を計算する(S27)。
(もっと読む)
議論展開検出方法、議論展開検出装置、議論展開検出プログラム、および議論展開検出プログラムを記録した記録媒体
【課題】メッセージ集合から選択した重要メッセージに関する議論の展開レベルを検出する。
【解決手段】議論構造グラフ作成部15Cにより、メッセージ集合14Aから所定の重要度より高い関連度16Bを有するメッセージ対を選択し、これらメッセージ対ごとに両メッセージの開示順に応じた向きを有する有向枝で当該メッセージ間を結ぶことにより、議論の展開を示す議論構造グラフ16Cを作成し、メッセージ分類部15Dにより、この議論構造グラフ16Cに示された各メッセージに出入りする有向枝に基づいて各メッセージを予め設けた議論の展開レベルにそれぞれ分類し、各メッセージと展開レベルとの対応関係を示す検出結果情報14Bを出力する。
(もっと読む)
検索処理方法及びプログラム
【課題】検索者が直感的に検索結果の分析を行うことができるようにする。
【解決手段】検索により抽出された複数の文献のデータが次の処理キー及び選択可能な表示項目として第1の表示形態にてユーザに提示されると共に、ユーザによる表示項目の選択に応じて、選択された表示項目に対応する文献のデータを、さらに次の処理キー及び選択可能な表示項目としてユーザにより指定された第2の表示形態にてユーザに提示されるようになる。従って、直感的なインターフェースにて分析対象及び表示形態を変更してゆき、分析を進めることができるようになる。
(もっと読む)
自然言語のテキストからオントロジを開発するための、コンピュータによって使用される方法
本発明は、自然言語のテキスト(10)のオントロジ(70)を開発するための、コンピュータによって使用される方法であって、
前記テキスト(10)からテキスト・データを受信するステップと、
前記受信データの文法的分析(S100)によって、前記テキストから構文と有意味の単語(20)を抽出するステップと、
前記テキストの前記有意味の単語(20)のうちの少なくとも一部ごとに、少なくとも1つの電子辞書(30、35)を用いてその単語(20)の定義(40)を検索するステップ(S200)と、前記定義の前記構文と前記有意味の単語を抽出するステップと、およびその定義の基本の語彙グラフ(50)をその定義の前記構文と前記有意味の単語に基づいて作成するステップ(S300)と、
前記テキストの前記構文に応じて、前記テキストの少なくとも1つの意味グラフ(60)を作成するために、作成された前記基本の語彙グラフ(50)のうちの少なくとも2つを統合するステップ(S400)とを含む方法に関する。
本発明はさらに、本発明の方法のステップを実装するように適合された、コンピュータ・プログラム製品と、コード手段を含む電子データ処理システムに関する。 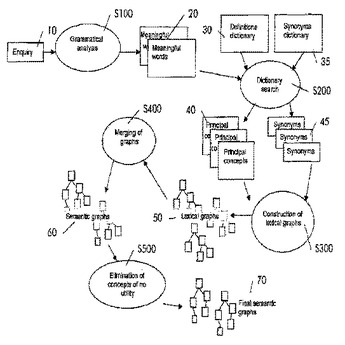 (もっと読む)
(もっと読む)
情報の抽出及びモデリングの方法並びにそのシステム
【課題】 文書群から得られる情報をモデル化するシステム及びその方法を開示する。
【解決手段】 ツールにより、使用者が、関心の高いコンセプトと、文書群から得られるコンセプト間のリレーションと、を抽出でき、かつ、モデル化できる。このツールは、モデル及び文書群から抽出されたコンセプトがカスタマイズされ、変更され、及び共有され得るように、モデルのデータベースを自動的に構成する。
(もっと読む)
1 - 20 / 45
[ Back to top ]