
Fターム[5B075NS10]の内容
Fターム[5B075NS10]に分類される特許
81 - 100 / 842
投稿文章分析装置、投稿文章分析方法、および、投稿文章分析装置用プログラム
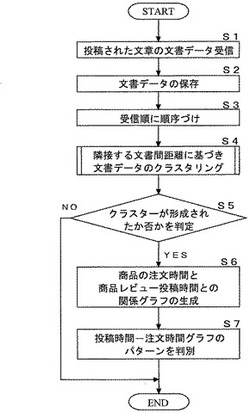
【課題】ユーザから投稿される文章を高速に分析できる投稿文章分析装置、投稿文章分析方法、および、投稿文章分析装置用プログラムを提供する。
【解決手段】本発明は、ユーザ端末30からユーザが投稿してくる文章データを受信し(S1)、文書データを記憶し(S2)、文章データに関する時間情報に基づき、文章データを順序付けし(S3)、順序で隣接する文章データの文書間の文書間距離を算出して、文書間距離に基づき、文書データをクラスタリングする(S4)。
(もっと読む)
キーワードの時系列解析のための処理方法、並びにその処理システム及びコンピュータ・プログラム

【課題】キーワードの大局的なトレンドを効率良く発見する方法が求められている。
【解決手段】本発明は、キーワードの時系列解析のための処理方法を提供する。当該方法は、自然言語による事象の記述である文書データを当該文書データ中のキーワードの出現頻度に基づきクラスタリング又は分類するステップであって、当該文書データのクラスタリング又は分類によって個々のキーワードもクラスタリング又は分類される、上記クラスタリング又は分類するステップと、上記文書データをクラスタリング又は分類したクラスタ又はクラス内における個々のキーワードを含む文書データの出現頻度に対して、又は上記個々のキーワードをクラスタリング又は分類したクラスタ又はクラスを含む文書データの出現頻度に対して時系列解析を行うステップとを含む。時系列の解析によって上記文書データの出現頻度の変化を示す周波数分布が求められる。
(もっと読む)
トレンド分析装置、トレンド分析方法およびトレンド分析プログラム
【課題】文書について、トピック毎の時間変化の速度の差も考慮した上でトレンド分析を行うことを課題とする。
【解決手段】本発明のトレンド分析装置1000は、時期毎に設けられたトレンドクラスを有する所定の確率分布モデルにおいて、スイッチ変数に応じた単語生成分布、第1の計算式、第2の計算式などを用いて、各文書が確率的に属するトレンドクラスを計算することができる。つまり、文書について、トピック毎の時間変化の速度の差も考慮した上でトレンド分析を行うことができる。
(もっと読む)
情報評価装置、情報評価方法、及び情報評価プログラム
【課題】カテゴリにおける単語の重要度について、信頼性の高い評価値を算出すること。
【解決手段】単語処理部103は、選択カテゴリに属する文書で共起する単語の組について、選択カテゴリに属する文書で共起する頻度を示す選択カテゴリ共起頻度情報を算出する。交互作用算出部104は、選択カテゴリ共起頻度情報と、単語の組について全文書での出現頻度を示す全文書単語組出現頻度情報と、に基づいて、選択カテゴリに属する文書に現れる単語について、選択カテゴリでの重要度を示す評価値を算出する。
(もっと読む)
ユーザ情報処理プログラム、ユーザ情報処理装置、及び、ユーザ情報処理方法
【課題】従来の技術では、ユーザ間の類似度を精度良く算出することができない。
【解決手段】ユーザ情報処理装置1は、ユーザ識別情報と、コンテンツの再生位置を示す位置情報と、位置情報に対応するユーザの状態情報とを関連付けた反応データを読み込んで、位置情報を所定の開始位置と所定の終了位置を持つ各フレームに対応させ、フレームごとに複数のユーザの反応データを集計した反応データ集計値を算出する反応データ集計手段18と、1つ以上のフレームをグループ化してブロック情報を生成するブロック情報生成手段19と、反応データの位置情報をブロックに対応させて、ユーザ識別情報ごとに、ブロックごとに複数の反応データを集約した集約データを計算する集約データ計算手段12と、一のユーザ及び他のユーザの集約データを用いて、一のユーザと他のユーザとの類似度を計算する類似度計算手段13と、を有する。
(もっと読む)
データ解析システム、及びその方法
【課題】順序関係を示す情報を含む時系列データから、時系列パターンを抽出するデータ解析システム及び方法を提供する。
【解決手段】システムを構成するコンピュータ100のプロセッサ101は、メモリ102に記憶されたプログラムを実行し、時系列パターンの各時系列データにおいて繰り返される回数と、時系列パターンの繰り返し回数が所定の回数以上となる時系列データの数である出現頻度を数え上げることによって、所定の繰り返し回数以上であり、かつ、所定の時系列データの数以上で所定の繰り返し回数以上となる時系列パターンを抽出する。更に、時系列データ各々に所定の間隔でチェックポイントを設け、各チェックポイントにおいて各時系列データにおける時系列パターンの繰り返し回数の上限値を算出し、この上限値を用いて出現頻度を数え上げることによって、繰り返し回数を数え上げる時系列パターンと時系列データの範囲を限定する。
(もっと読む)
情報抽出システム及び情報抽出プログラム
【課題】構文解析技術を用いることなく、自然文から構造化された情報を抽出する技術の提供。
【解決手段】企業名、企業活動、活動対象物を示す具体的な表現文字列毎にその種類を示す抽象化文字列を登録した辞書記憶部26と、文を形態素単位に分解し、各形態素に対応の抽象化タグを関連付ける形態素解析処理部12と、企業活動の抽象化タグが付与された形態素を文の述語と認定すると共に、主語に付属する助詞毎及び目的語に付属する助詞毎に対応語の格納欄が設けられた格スロットに、文の述語単位で対応語を充填し、述語を関連付ける格スロット充填処理部20と、抽出すべき主語の抽象化タグ及び助詞を特定する条件と、抽出すべき述語の抽象化タグを特定する条件と、抽出すべき目的語の抽象化タグ及び助詞を特定する条件が規定された抽出フレーム定義を、対応語充填済みの格スロットに適用し、文の主語、述語、目的語に該当する情報要素を抽出する情報抽出処理部22を備えた情報抽出システム10。
(もっと読む)
情報マップ作成装置、情報マップ作成方法、及びプログラム
【課題】特定のノードへの関係線の集中と重要な情報の欠落とが適切に回避された情報マップを作成すること。
【解決手段】情報マップ作成装置は、情報要素ごとに接続可能な関係線の上限値を設定する上限値設定手段と、前記情報要素間の関連ごとに該関連の強度を記憶した関連情報記憶手段に基づいて、前記強度の大きい順に、前記上限値の範囲内で前記関係線として表示させる前記関連を選択する関連選択手段と、前記上限値の範囲を超えるため表示対象として選択されなかった前記関連の数を、前記情報要素ごとに上限超過回数記憶手段に記録する記録手段と、前記上限超過回数記憶手段に記録された数が最大である前記情報要素の前記上限値を所定数増加させる上限値更新手段とを有し、前記関連選択手段は、更新された前記上限値の範囲内で前記関連の選択を再実行する。
(もっと読む)
ドキュメント作成支援システム
【課題】テキストを装飾するテキストボックスを含む文書ファイル(ドキュメント)の分析を行い、各々のテキストボックスの配置パタン及びカテゴリの因果関係を管理し、不足するテキストボックス等を報知するためのコメントを付与することでドキュメントの作成支援、品質管理を行うシステムを提供する。
【解決手段】ユーザが作成支援を所望してドキュメントを登録した場合、情報整理機能32によって当該ドキュメントの情報整理を行い、差分抽出機能35にてデータベース4に蓄積される配置パタン等と、情報整理されたドキュメントの配置パタン等との差分を抽出し、差分に基づきコメントを作成してドキュメントに付与することで、足りないテキストボックスやカテゴリの不一致をユーザに報知することでドキュメント作成の支援を行うことができる。
(もっと読む)
内装企画計画支援システム
【課題】一般消費者が抱えている住宅を含む建築物のインテリアデザイン、リフォーム計画等に関する真のニーズを把握して適切なコンサルティング情報を提供することができるインターネットを利用した内装企画計画支援システムを提供する。
【解決手段】ユーザと専門家がユーザの相談依頼に対して、サーバを介して双方向に相談依頼した情報のすべてを登録したコンサルティング情報DBと、専門家が保有している専門情報を登録した専門情報DBと、コンサルティング情報DBに登録された情報についてユーザのニーズを把握するためにテキストマイニング処理を行って抽出した情報を登録したニーズ情報DBを備えている。そして、ニーズ情報DBと専門情報DBに登録されている情報を検索手段により抽出することにより、ユーザの真のニーズを把握して、ユーザのニーズに対応した質の高いコンサルティング情報をユーザに提供することができるようにした内装企画計画支援システムである。
(もっと読む)
ネットワーク上のWWW文書掲載装置と関連情報紹介装置とが協働してブラウザ端末に情報を提供する方法
【課題】利用者がブラウザ端末を操作してネットワーク上に存在する複数のWWW文書掲載装置の中の任意の装置にアクセスして任意のWWW文書を閲覧するコンピュータネットワーク環境において、ネットワーク上に設けた関連情報紹介装置がWWW文書掲載装置と協働し、利用者が閲覧中のWWW文書に含まれる特定用語に紐付けした関連情報を利用者に紹介できるようにする。
【解決手段】ブラウザ端末の利用者がWWW文書掲載装置から取り寄せたWWW文書を見てWWW文書に付加表示された「リンク用語をオンにしますか?」をクリックした。すると図2のように、WWW文書の本文中の「伊達政宗」「直江兼続」「徳川家康」「長谷堂城」「米沢」という単語がハイパーリンク形式に変わった。「米沢」をクリックすると、関連情報紹介装置は、受信した用語対応URLに対応づけされている関連情報紹介ページをブラウザ端末に返信する。
(もっと読む)
情報処理装置、情報処理方法及びプログラム
【課題】2つの批評対象物に関する各批評情報の比較分析を高い精度で容易かつ迅速に行うこと。
【解決手段】PC100は、比較対象の2つの商品についての各高評価レビュー記事の総数に対する、所定のレビューポイント毎に設定された所定のキーワードを含むレビュー記事の数の比率を、各商品についての高評価レビュー記事の総数に対する、特定のビューポイントを高評価するレビュー記事の数の比率として算出し、その各比率をビューポイント毎に比較可能に出力する。
(もっと読む)
購買ステージ判定装置及び購買ステージ判定方法
【課題】購買履歴を用いない場合であっても、ユーザの購買行動を判定できる購買ステージ判定装置及び購買ステージ判定方法を提供すること。
【解決手段】クエリ集合抽出部104は、検索履歴から所定のユーザにより用いられたクエリを抽出し、カテゴリ分類部105は、カテゴリDB111に記憶されるカテゴリ及びキーワードに基づいて、クエリ集合抽出部104により抽出されたクエリの集合をカテゴリごとに分類する。使用頻度算出部106は、抽出されたクエリの集合及びこのクエリの集合がカテゴリ分類部105において分類されたカテゴリに基づいて、カテゴリごとの使用頻度を算出し、グラフ生成部107は、算出されたカテゴリごとの使用頻度を用いて所定の形式のグラフを生成する。判定部108は、生成されたグラフが所定の期間内に所定の状態であるか否かを判定する。
(もっと読む)
検索情報解析プログラム、検索情報解析装置、及び検索情報解析方法
【課題】話題となっている単語の背景を示す情報の提示を適切に支援すること。
【解決手段】コンピュータに、検索語と該検索語の属性情報とを対応付けて格納した検索ログに基づいて、該検索語に含まれている単語間の関係を抽出し、各単語と関係する単語を対応付けて関係情報記憶手段に記録する関係生成手順と、検索語に含まれる話題語に基づき、該話題語と関係を有する単語である周辺語を関係情報記憶手段を参照して抽出し、抽出した周辺語ごとに、該周辺語と関係を有する第一の単語と第一の単語であってかつ該周辺語以外の周辺語に該当する第二の単語とを関係情報記憶手段を参照して抽出し、該抽出した第一の単語の数と該第二の単語の数とをそれぞれ計数し、該第一の単語の数及び該第二の単語の数に基づいて該周辺語が話題語の背景を示す度合を算出し、該算出した度合に基づいて周辺語の一部を抽出する選択手順とを実行させる。
(もっと読む)
ニュース記事評価システム
【課題】個々のニュース記事の影響力を定量的に算出することを可能とする技術の提供。
【解決手段】分析案件毎にキーワードを設定しておくユーザ設定記憶部24と、インターネット26上に設置されたニュースサーバ30及びブログサーバ28からキーワードを含むニュース記事及びブログ記事を取得し、それぞれニュース記事記憶部14及びブログ記事記憶部16に格納する記事収集部12と、各ブログ記事と対応関係にあるニュース記事を特定する対応関係判定部18と、ニュース記事毎に対応関係にあるブログ記事の件数を集計し、このブログ記事の総数を各ニュース記事に関連付けて解析結果記憶部22に格納する影響力解析部20を備え、対応関係判定部18は、各ブログ記事中に設定されたリンク情報と各ニュース記事のURLを比較し、両者が一致している場合にブログ記事とニュース記事との対応関係を認定するニュース記事評価システム10。
(もっと読む)
特有コンテンツ判定装置、特有コンテンツ判定方法、特有コンテンツ判定プログラム及びコンテンツ生成装置
【課題】Webページを構成しているコンテンツの中からのそのWebページ特有のコンテンツを容易に抽出する。
【解決手段】指定されたWebページを構成しているコンテンツを抽出する抽出手段と、指定されたWebページを構成している各コンテンツの出現頻度を計算する計算手段と、指定されたWebページを構成しているコンテンツのうち、出現頻度が最も小さいコンテンツを当該Webページに特有のコンテンツであると判定する判定手段と、を備える。
(もっと読む)
文書データ解析装置、方法及びプログラム
【課題】対象データに含まれる文章の意味内容をより正確に推定する。
【解決手段】複数の対象データを含む文書データを解析するための文書データ解析装置に、正規表現を用いて定義された複数の検索キーを保持する保持部22と、保持された複数の検索キーを用いて複数の対象データを検索する検索部24と、検索の結果得られた情報を変数として設定して、類似する対象データ同士をグループ化するクラスタリング処理を行うクラスタリング部28と、対象データの属性情報として、クラスタリング処理の結果において同一グループに属する他の対象データに設定されている属性情報を取得する、情報取得/推定部27と、を備えた。
(もっと読む)
情報処理装置、情報処理方法、及びプログラム
【課題】文書データから文をより適切に抽出することを目的とする。
【解決手段】情報処理装置が、文字列データが含まれる複数のオブジェクトに係る文書データから、複数のオブジェクトの各々に含まれる文字列データと、複数のオブジェクトの各々を解析して得る解析結果情報とを抽出し、抽出した文字列データの各々を文の区切り毎に分割する処理を行い、分割する処理を行った後のデータを断片データとして抽出し、抽出した解析結果情報に基づいて抽出した断片データの各々を結合するか否かを判別し、結合すると判別した断片データの各々を結合することによって課題を解決する。
(もっと読む)
確率分布関数を用いて行動をモデル化するための方法及び装置
【課題】人間又は他の生物の行動パターンをモデル化して反復的な行動パターンの違反を検出するための方法及び装置が開示される。
【解決手段】1人又は複数の人の行動が時間に対して観察され、行動の特徴が多次元空間で記録される。多次元データは、時間に対して、人間の行動パターンの表示を提供する。時間、位置及び動作に関して反復的である動作、例えば睡眠及び食事は、多次元データにおいてガウス分布又はクラスタとして現れる。確率分布関数は、反復的な行動パターン及びその特性(例えば平均及び分散)を識別するために既知のガウス分布又はクラスタリング技術を用いて分析されることができる。反復的な行動パターンからの逸脱が検出されることができ、適当ならばアラームが起動されることができる。
(もっと読む)
情報分析装置、情報分析方法、及びプログラム
【課題】テキストにおける語の出現頻度及び語の属性に影響されることなく、弊害語を特定し得る、情報分析装置、情報分析方法、及びプログラムを提供する。
【解決手段】情報分析装置30は、分析対象テキスト11と共通のトピックを含む補助テキスト12を用いて、分析対象テキスト11を構成する各ユニットの頻度を算出し、算出した頻度が設定された閾値以上となるユニットを高頻度ユニットとして特定する、高頻度ユニット特定部31と、分析対象テキスト11を構成する各ユニットのうち、トピックの変化が発生しているユニットを、トピック変化ユニットとして特定する、トピック変化ユニット特定部35と、高頻度ユニットのうち、トピック変化ユニットに該当するユニットを除き、残った高頻度ユニットの中から、弊害となる語又は語集合を含む弊害ユニットを特定する、弊害ユニット特定部36とを備えている。
(もっと読む)
81 - 100 / 842
[ Back to top ]