
Fターム[5B075NS10]の内容
Fターム[5B075NS10]に分類される特許
141 - 160 / 842
特徴パターン抽出装置、特徴パターン抽出方法、分類支援装置および分類支援方法
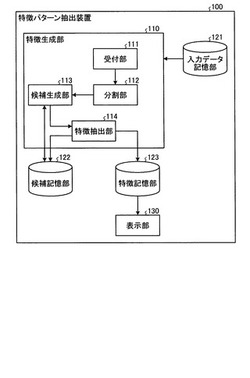
【課題】意思決定支援に利用可能な情報を効率的に生成する。
【解決手段】分析対象となる情報を表す少なくとも1つのアイテムを含む集合であって、集合が分類されるクラスを対応づけたアイテム集合の入力を受付ける受付部111と、アイテム集合に含まれるアイテムのパターンに特徴的な特徴パターンの候補であって、アイテム集合に含まれる少なくとも1つのアイテムを含む候補パターンを生成する候補生成部113と、クラスごとに、クラスに対応づけられたアイテム集合での候補パターンの出現頻度を算出し、算出した出現頻度が予め定められた条件を満たす候補パターンである特徴パターンを抽出する特徴抽出部114と、抽出された特徴パターンを出力する表示部130と、を備える。
(もっと読む)
レコメンド情報評価装置およびレコメンド情報評価方法

【課題】ユーザが潜在的に望んでいるコンテンツなどのレコメンド情報を漏れなく配信することができるように、その評価を行うことができる装置を提供する。
【解決手段】所定のタイミングで、特徴ベクトル生成部209は、Webページなどのコンテンツを収集し、そのコンテンツの特徴を示すキーワードを抽出して、特徴ベクトルを生成する。生成した特徴ベクトルは、コンテンツ特徴ベクトル管理テーブル207bに記憶され、更新される。この収集のタイミングは、任意のタイミングや、Webページが更新されたタイミング(これは更新通知信号を受信するなどして)である。このように更新されたコンテンツ特徴ベクトルを用いてコンテンツの評価を行う。
(もっと読む)
分析システム及び情報分析方法
【課題】分類基準を外部から与えることなく文書そのものの内容に従って文書を分類し、かつ、分類された結果得られる文書グループの意味が利用者にとって明瞭である情報分析システムを提供する。
【解決手段】文書集合を作成し、文書集合中の文書から数値表現を抽出し、数値表現の周辺から説明語を抽出し、抽出された数値表現を具体的な数値と単位との組に変換し、単位毎に変換された値の大きさに従って文書を分類し、抽出された説明語のうち、数値表現と関連性の高いものを数値と関係付けて、関係付けられた結果をユーザに表示する。
(もっと読む)
電子スクラップシステム、電子スクラップ方法、電子スクラップサーバ、および利用者端末
【課題】サーバにあらかじめ登録しておかなくても、記事を電子データとして、検索が可能なようにスクラップする電子スクラップシステムおよび電子スクラップ方法を提供する。
【解決手段】本発明の電子スクラップシステムは、利用者の操作に従って記事を含む画像を撮影し、該記事に関する記事情報を取得し、撮影された画像データと記事情報とを含む登録要求を送信する利用者端末と、利用者端末から登録要求を受信すると、登録要求に含まれている画像データの記事からキーワードを抽出し、画像データと記事情報とキーワードを関連付けて前記利用者のスクラップデータとして登録し、利用者からキーワードが指定されると、該利用者のスクラップデータの中から、該キーワードを含むスクラップデータの一覧を提供し、利用者により該一覧からいずれかのスクラップデータが選択されると、選択されたスクラップデータの画像を提供するスクラップ管理サーバを有する。
(もっと読む)
メール利用状況分析システム、業務効率化支援システム、方法、及び、プログラム
【課題】電子メールを利用するユーザに対して電子メールの利用状況を分析可能なメール利用状況分析システムを提供する。
【解決手段】電子メール格納部104は、対象ユーザが送受信した電子メールを格納する。メールスレッド生成部101は、ユーザが発信した電子メールを含むメールスレッドを生成する。メールスレッド分類部102は、メールスレッドを、メールスレッドの段数と枝の広さとに応じて複数の分類に分類する。
(もっと読む)
コミュニケーション活性化装置、コミュニケーション活性化方法およびプログラム
【課題】全てのユーザのそれぞれが過去にコミュニケーションを交わしたことがあるかないかに関わらず、将来コミュニケーションをとる可能性の高い2ユーザを発見し、発見された上記2ユーザに、互いを発見させコミュニケーションを促進することができるコミュニケーション活性化装置を提供することを目的とする。
【解決手段】3ユーザのコミュニケーションの構造(3ノード間の有向枝の出現パターン)の時間的変化を分析し、どの構造においてコミュニケーションが成立しやすいかを分析し、この分析結果に基づいて、コミュニケーションを取る可能性の高い2ユーザを発見する。
(もっと読む)
アンケートデータからの評価分析システム及び評価分析方法
【課題】 具現化していない製品やサービスのあいまいな情報に対する解釈の相違の抽出と補正を可能にする評価分析方法を提供する。
【解決手段】 同一対象について情報提示の詳細さを変えて行ったアンケートの結果から各被験者の情報の提示による評点データの変化を解釈のズレとして抽出し、さらに対象特徴と関係する解釈全体傾向成分と、個人特徴と関係する解釈個人差成分とに分離して特徴に関するデータとの関係パターンを抽出、蓄積しておくことで、アンケートの質問項目に被験者特徴及び対象特徴に関する設問を加えるだけで、解釈のズレを補正可能にした。
(もっと読む)
画像データベース形成方法、ナビゲーション方法、データベースシステム、ナビゲーション用モバイル装置、ナビゲーションシステムおよび画像データベースを形成するためのプログラム
【課題】ユーザによるユーザ自身のよりよい方向付けを支援する。
【解決手段】取得画像データを受信し、前記取得画像データに対応するカメラ位置データおよびカメラ方位データを受信し、前記カメラ位置データおよび前記カメラ方位データを、関連メタデータとして、対応する取得画像データに関連付け、前記関連メタデータを含む前記取得画像データのデータベースを形成する。前記取得画像データは動画像を含み、前記カメラ位置データおよび前記カメラ方位データを、関連メタデータとして、対応する取得画像データに関連付けることは、各動画像について、タイムスタンプが付加されたカメラ位置変化イベントおよびカメラ方位変化イベントのリストを導出し、前記動画像のトランジションに、前記関連メタデータとしてタグを付けることを含んでもよい。
(もっと読む)
人間関係推定装置、及び、人間関係推定方法
【課題】ユーザ同士の人間関係の程度のみではなく、ユーザ同士がどのような人間関係にあるのかを推定することが人間関係推定装置、及び、人間関係推定方法を提供する。
【解決手段】人間関係推定装置の10のコミュニケーション頻度判定部106は、ユーザ同士のコミュニケーション頻度を判定する。エリア判定部108は、各ユーザがどのエリアに存在したかを判定する。人間関係推定部109は、コミュニケーション頻度判定部106及びエリア判定部108による判定結果から判断された、各ユーザがどの程度の頻度でコミュニケーションを行いどのエリアに同時に存在していたかに基づいて、ユーザ同士の人間関係を推定する。
(もっと読む)
情報分析装置、情報分析方法、及び情報分析用プログラム
【課題】話題語の出現数にかかわらず、ドキュメントの特徴が大きく変化した時点を特徴点として検出できるようにする。
【解決手段】本発明では、時間情報が付与された時間情報つきドキュメントの集合を入力し、入力した時間情報つきドキュメントの集合に属する各ドキュメントに対して、各ドキュメントの特徴を示す情報を計算し、入力した時間情報つきドキュメントの集合を時間情報に基づいて分割したタイムスライス毎に、各タイムスライスに属する各ドキュメントに対して計算したドキュメントの特徴を示す情報に基づいて、各タイムスライスの特徴を示す情報を計算し、タイムスライスの特徴を示す情報の計算結果に基づいて、タイムスライスの特徴間の距離を計算し、計算したタイムスライスの特徴間の距離が予め定められた閾値を超えるタイムスライスの組を特徴点として検出する。
(もっと読む)
表現補完装置およびコンピュータプログラム
【課題】大量のルール等を予め準備する手間をかけずに、与えられる文データに基づき、文中において欠落している評価表現を補完する表現補完装置を提供する。
【解決手段】情報抽出処理部は、文のうち、評価表現を含む文については当該文の特徴データと当該文の評価表現とを抽出して評価付き抽出情報として評価付き抽出情報記憶部に書き込み、評価表現を含まない文については当該文の特徴データを抽出して評価欠落抽出情報として評価欠落抽出情報記憶部に書き込む。評価補完処理部は、クラスタリング処理を行なうことにより前記特徴データ間の類似度を算出し、前記評価欠落抽出情報に含まれる前記特徴データとの類似度が高い所定範囲の前記特徴データを有する前記評価付き抽出情報を特定し、該特定された評価付き抽出情報に含まれる前記評価表現を用いて当該評価欠落抽出情報の評価表現を補完する。
(もっと読む)
情報選別装置
【課題】特定テーマに関連する情報をWebなどから収集して網羅的かつ効率的に絞り込むことができる情報選別装置を提供すること。
【解決手段】検索手段11は、Web検索の結果レポートをクライアント端末20に提示する。テーマ空間構築手段12は、クライアント端末20からの習得情報フィードバックによりテーマ情報DB13内のテーマ情報を更新し、Web検索してテーマ空間を構築する。検索手段11は、対象テーマ全体に対するユーザ習得済み部分の割合である網羅度を算出する網羅度算出手段を備える。また、検索手段11は、対象Webページをユーザが習得した場合の習得済み範囲とそれ以前のユーザ習得済み範囲との差分を算出する差分算出手段、対象Webページの、対象テーマに対する関連度を算出する関連度算出手段を備える。
(もっと読む)
外部格納装置からコンテンツの提供を受けるデジタルコンテンツ提供装置およびその方法
【課題】外部格納装置からコンテンツの提供を受け、該当コンテンツに対するメタデータを生成し、販売時に要求される仕様にコンテンツを変換するデジタルコンテンツ提供装置およびその方法を提供する。
【解決手段】外部格納装置を認識する装置認識部、外部格納装置に格納されているコンテンツファイルを検索するコンテンツ検索部、コンテンツファイルを調べ、コンテンツファイルから代表画面を抽出する代表画面抽出部、およびコンテンツファイルに対してコンテンツ名、サービスタイプ、再生時間、解像度、再生時に必要なライブラリー、あらすじ、配布条件、製作者、代表画面のファイル名、販売価格のうちのいずれか一つ以上の情報を含むメタデータを生成するメタデータ生成部を備える。該デジタルコンテンツ提供装置を管理する販売者だけでなく、一般人も、自分が保有している多様なコンテンツを該デジタルコンテンツ提供装置にアップロードできる。
(もっと読む)
行動分析支援システム及び行動分析支援プログラム
【課題】容易な操作で行動分析に要する時間を短縮する行動分析ツールとして機能する行動分析支援システム及び行動分析支援プログラムを提供する。
【解決手段】ユーザの取得開始操作と取得終了操に応じて動画データを取得するデータ取得制御部50aと、取得中の画像に対してユーザによる付加情報の入力を受け付け、その入力された付加情報を画像に対応付ける付加情報処理部50eと、取得した複数の動画データのそれぞれの再生画像が付加情報とともに表示されるサムネイル画像を生成して一覧表示するサムネイル画像生成部50cとを有する。
(もっと読む)
選択装置、選択方法、及びコンピュータプログラム
【課題】 検査リストから検査を選択する場合、状況によって選択したい検査グループが異なっている。そのため、簡易な方法で複数の項目を選択する必要がある。
【解決手段】 ディスプレイ1004に表示され複数の項目を含んだ患者情報を表示し、表示されたリストを指示することで項目を選択し、選択された項目の内容と、指示された項目内の位置とに応じてリスト内の項目の表示状態を変更する。
(もっと読む)
状況推定システム、状況推定方法、状況推定プログラム
【課題】ユーザ端末に搭載させる複数のセンサとして多種多様なセンサを搭載させることを許容する状況推定システムを提供すること。
【解決手段】本発明に係る状況推定システムは、ユーザが存在するものと仮定しうる所定の状況において、ユーザ端末200に搭載されうるセンサと同種のセンサを含む複数のセンサが予め設置されており、それら複数のセンサから状況ごとにセンサ観測値を収集するセンサデータ収集手段101と、収集したセンサ観測値から、各状況ごとにセンサ観測値の出力確率を所定の確率分布として生成して確率分布記憶部104に記憶するセンサデータ管理手段102と、ユーザ端末200のセンサ観測値と、確率分布記憶部105に記憶された確率分布に基づいて、ユーザ端末200のセンサ観測値を受信した場合にユーザが各状況に存在する条件付確率を推定する特徴ベクトル生成手段103と、を備える。
(もっと読む)
大規模WEBサイトの評価装置、大規模WEBサイトの評価方法および大規模WEBサイトの評価プログラム
【課題】ページ作成者の不正な自己作成によるリンクを無効、もしくは低く扱う評価値を各WEB文書に付与することができる評価装置を提供する。
【解決手段】サイト集約ルールが蓄積されたサイト集約ルールデータベース400と、前記データベース400に蓄積されたサイト集約ルールに基づいて、WEB文書蓄積装置200に蓄積されたWEB文書のリンク情報をサイト単位に集約し、サイト間のリンク構造を分析し、サイト毎にページランク相当の評価値を求め、それら情報に基づいて、関連が強いサイト同士をまとめて新たにサイト集約ルールを作成し、前記サイト集約ルールを更新するサイト分析装置300と、前記蓄積装置200内の各WEB文書に対して、前記サイト集約ルールに基づいて、サイト間のリンク情報を使って文書毎の評価値を付与するWEB文書評価装置500と、それを蓄積する評価済WEB文書蓄積装置600とを備える。
(もっと読む)
データ集計などのデータ操作に使用するプログラム、装置および方法
【課題】効率的な集計処理を実現する集計プログラム、集計装置および集計方法を提供する。
【解決手段】TRIE構造の統計ヒドラを用いて複数のアプリケーションによって蓄積されたファイルを、境界値に関する節と、境界値間を補間して得た値に関する節と、で構成し、集計処理を行う。まず、境界値情報を第1の分割した範囲情報と補間値情報を記憶する第1の記憶手段を用意する。同様に、第2、第3の範囲情報、補間値情報を記憶させた第2、第3の記憶手段を用意して集計処理を実行する。
(もっと読む)
ストリームデータ処理方法、及びシステム
【課題】
時間ウィンドウを含むクエリのメモリ使用量を一定に保ち、かつ全ての入力データを考慮した正確な計算処理を実現するストリームデータを提供する。
【解決手段】
ストリームデータ処理サーバ111は、クエリ時間解像度変更部130で、時間ウィンドウをより小さい幅のサブウィンドウに区切り、クエリ処理エンジン140はストリームデータ受付時にサブウィンドウ単位の集計処理を実行して集約タプルを生成し、時間ウィンドウを含むクエリの計算結果を、この集約タプルに対する集計処理によって計算する。
(もっと読む)
評価装置、及び、コンピュータプログラム
【課題】相互に関連を持つデータをその関連の深さとともに把握可能とし、調査対象のデータに関連する他のデータを関連の深いものから取りこぼしなく所望の数だけ抽出する。
【解決手段】クリーク抽出部121は、複数のノードと、当該複数のノードそれぞれが関連する他のノードとを示す関係データに基づいて極大クリークを抽出し、ノードの重複割合が所定以上の極大クリークの組み合わせから擬似クリークを生成する。行列作成部122は、ノード及び擬似クリークを行及び列に対応させ、ノードが擬似クリークに含まれる場合は対応する要素に1を、他の要素に0を設定した行列を生成し、対応分析部123は、生成された行列の対応分析を行い、ノード及び擬似クリークそれぞれのスコアを算出する。抽出対象リスト作成部124は、ノードをスコア順に並べた結果から、注目するノードの近傍の他のノードを所定数抽出して出力する。
(もっと読む)
141 - 160 / 842
[ Back to top ]