
Fターム[5B075PP24]の内容
Fターム[5B075PP24]の下位に属するFターム
Fターム[5B075PP24]に分類される特許
1 - 20 / 216
情報検索サービス提供装置及びコンピュータプログラム
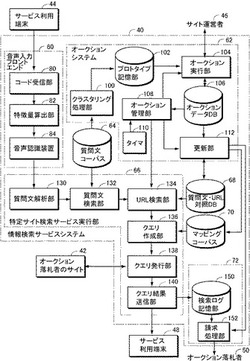
【課題】検索要求に対する情報検索サービスをビジネス上の利益に結びつけることができる情報検索サービス提供装置を提供する。
【解決手段】情報検索サービスシステム40は、質問文コーパスを記憶する記憶装置64と、質問文をクラスタ化し、各クラスタのプロトタイプを定めるクラスタリング処理部100と、プロトタイプのオークションを行なうオークション実行部104と、質問文の各々に、その属するクラスタのプロトタイプ文の落札者を関係付ける更新部112と、質問文の各々について、落札者の指定するURLを記憶する質問文―URL対照DB68と、検索要求を受信し、検索要求との間の距離が最も小さな質問文を検索する質問文検索部132と、検索された質問文に対応するURLに、検索要求から生成したクエリを送信し、得られる情報をサービス利用端末48に送信するURL検索部134、136、及びクエリ発行部138とを含む。
(もっと読む)
質問予測装置および質問予測方法

【課題】ユーザの様々な状況を想定した上でユーザに提示する質問を予測する質問予測装置を提供することである。
【解決手段】
実施形態の質問予測装置は、質問を予測する質問予測装置であって、ユーザの状態を取得する状態取得手段と、当該状態取得手段で取得されたユーザの状態を用いて遷移確率を更新する遷移確率更新手段と、前記状態取得手段で取得されたユーザの状態と前記遷移確率更新手段で更新された遷移確率とを用いてユーザの次の状態を予測する状態予測手段と、質問と状態遷移列とを対応付けた質問対応表を蓄積する質問対応表蓄積手段と、前記状態予測手段で予測されたユーザの次の状態を含む状態遷移列と前記質問対応表蓄積手段に蓄積された質問対応表とを用いてユーザの質問を予測する質問予測手段とを備える。
(もっと読む)
データ抽出装置、データ抽出方法、及びプログラム
【課題】効率的にセマンティックドリフトを軽減する。
【解決手段】正例エンティティとその属性とのペアの素性と、負例エンティティとその属性とのペアの素性とを教師あり学習データとした学習処理によって識別モデルを生成し、対象エンティティと対象属性とのペアの素性を識別モデルに入力して、対象エンティティが正例エンティティを識別する。この際、対象属性が正例か否かの判定結果を出力し、人手による修正内容の入力を受け付ける。人手による修正内容を利用して正例属性を定める。
(もっと読む)
意図抽出装置、方法及びプログラム
【課題】入力された検索クエリで直接表現されていない検索意図を抽出すること。
【解決手段】入力された一又は二以上の検索クエリに基づいて、その検索クエリと直接又は間接にAND検索されるような共起クエリのグループを複数取得し、グループ間で交わる共通クエリを抽出すれば、この共通クエリは、入力された検索クエリから間接的な共起関係が複数存在する語であるから、ユーザの隠れた検索意図であって入力された検索クエリで直接表現されていない検索意図を抽出できたことになる。
(もっと読む)
処理装置、処理方法及び処理プログラム
【課題】テキスト情報を含む表示データ内から単語等の所定の文字列を抽出する処理に係る利便性を向上する。
【解決手段】処理装置1は、第1データのうち第2データを表示部に表示させる表示制御部35と、表示される第2データに含まれるテキスト情報を、第1データのうち第2データ以外のテキスト情報で補正し、第2データに含まれるデータ及び補正したデータから1つ以上の所定の文字列を抽出する文字列抽出部33と、を備える。
(もっと読む)
テキスト分割装置、テキスト分割学習装置、テキスト分割方法、テキスト分割学習方法、プログラム
【課題】あらかじめ決められた話題に合わせて、個々の境界ごとに最適な特徴パラメータを用いてテキストを分割する。
【解決手段】本発明のテキスト分割装置は、単語分割部、削除部、ベクトル化部、学習情報取得部、線形変換学習部、重心学習部、分割対象情報取得部、割付部を備える。線形変換学習部は、隣接する2つの話題ブロックの組ごとに、割付けられた単語の単語ベクトルを用いて、隣接する話題ブロックを分離するための線形変換係数ベクトルを求める。重心学習部は、隣接する2つの話題ブロックの組ごとに、各話題ブロックに割付けられた単語の単語ベクトルを用いて各話題ブロックの重心点を求める。割付部は、線形変換係数ベクトルと前記重心点を用いて、前記分割対象のテキストの単語をどの話題ブロックに割付けるかを決める。
(もっと読む)
検索装置、検索方法、検索プログラム及び検索システム
【課題】高精度に検索文字列の展開を行い、的確な文書の検索を可能とすることを目的としている。
【解決手段】検索文字列を解析して形態素に分割する解析手段と、解析結果に基づき検索文字列を展開して展開文字列群を取得する文字列展開処理手段と、展開文字列群により検索対象のデータベースを検索する検索手段と、検索手段による検索結果を表示させる結果表示手段と、を有し、文字列展開処理手段は、一以上の形態素を含む形態素列を生成する形態素列生成手段と、形態素と展開文字列群とが対応付けられた辞書データベースを形態素列で検索する辞書検索手段と、生成された形態素列のうち最も長い形態素列で辞書データベースを検索した結果の展開文字列群を出力する結果出力手段と、を有し、検索手段は、結果出力手段により出力された展開文字列群によりデータベースを検索する。
(もっと読む)
検索装置
【課題】施設の正式名称を知らず、施設名を検索する装置に、単語や音節等を単位として、入力文字列と検索対象施設名を比較照合し、マッチした単語や音節の数に基づいて検索スコアを算出し、スコアの高い順に候補を提示する従来の装置では、単語や音節の並び順により不自然な検索結果が生じる。
【解決手段】入力文字列と複数個の検索対象文書を照合し、複数個の文書と、文字列が文書中に出現する回数に応じた検索スコアとを出力する検索手段と、検索対象文書の形態素と、検索時の重要度に応じ形態素毎に付与したペナルティ値とを保持する形態素辞書と、前記検索結果を、形態素辞書を参照し、文書中には存在するが、文字列中からは抽出されない形態素に対し、ペナルティ値を減算した修正検索スコアに基づき検索結果の出力順位を再構成する検索順位修正手段を備える。
(もっと読む)
情報検索装置及び情報検索方法
【課題】
利用者の意図や嗜好に沿った適切な情報を話題に応じて迅速に提供する。
【解決手段】
抽出手段720が、利用者が発話した語句の中からキーワード記憶手段710に記憶されている語句を抽出し、話題語句グループ生成手段730、嗜好リスト生成手段740、拡大嗜好リスト生成手段750及び提示手段790へ送る。話題語句グループ生成手段730では、抽出語句が意図キーワード、対象キーワード及び属性キーワードのいずれかである場合に、話題語句グループを作成する。検索手段770は、話題語句グループの対象キーワードが特定されたときに話題関連情報の検索処理を行うとともに、属性キーワードが追加されて更新されたときに話題関連情報の検索処理を行う。そして、提示手段790が、抽出語句が検索指示キーワードである場合に、話題関連情報から提示すべき情報を選択し、情報を利用者に提示する。
(もっと読む)
画像選定装置、方法及びプログラム
【課題】ブログ等の文書の印象に適した画像を自動付与する画像選定装置を提供する。
【解決手段】入力文書から印象語と当該印象語の入力文書中での印象の強さを表す文書印象関連度を抽出する印象情報抽出部2と、画像とその画像印象語と画像印象関連度とを保存する印象・画像DB30と、抽出された文書印象語が印象・画像DB30の画像印象語と一致する画像を検索して、検索された画像の文書印象関連度と画像印象関連度とから画像選択スコアを求める画像検索部3とを備えて画像選定装置を構成する。
(もっと読む)
談話要約生成システムおよび談話要約生成プログラム
【課題】話し言葉やノイズといった談話データの特性に強く、談話データの構造を解析した結果から、所望の項目や内容が含まれ、かつ不要な項目が含まれない形で要約を生成する談話要約生成システムを提供する。
【解決手段】談話データ101および談話構造の解析結果である談話セマンティクス200を入力とし、談話についての要約を生成して出力する談話要約生成システム1であって、談話データ101において要約300に含めるべき部分を特定するための単語の連接のパターンと、要約300に含める要約文章のひな型との対応のリストを指定した要約テンプレート72と、要約テンプレート72に指定された各パターンと談話データ101とのマッチングを行い、マッチした場合に要約テンプレート72におけるマッチしたパターンに対応する要約文章のひな型から要約文章を生成して要約300に追加する談話要約部70とを有する。
(もっと読む)
関連コンテンツ提示装置及びプログラム
【課題】 関連コンテンツの候補のキーワード分布特性が一致していない場合やテキスト量が少ない場合においても精度の高い関連コンテンツを提示する。
【解決手段】 本発明は、対象文書がWeb文書である場合は主要コンテンツの抽出を行い、文書内のテキストからキーワード候補を抽出し、抽出されたキーワードの重要度をWebIDFやBM25といったアルゴリズムを用いて出現頻度及び、キーワードの形態素の固有名詞の出現頻度、キーワード辞書のリンク構造に基づいて得られた文書のランキング、閲覧された回数、検索エンジンに投入された回数、キーワードが文の先頭に存在するか否か等の要素により重要度を計算し、重要度に基づいてキーワードを選択し、当該キーワードを組み合わせて検索クエリを生成し、検索することにより関連コンテンツを取得する。
(もっと読む)
記号入力支援装置、記号入力支援方法、及びプログラム
【課題】入力文中へ絵文字等の記号を挿入する際に、文の内容を考慮した記号を決定し、実際の使用方法に沿った役割と位置を考慮した記号の挿入を、自動的に行う。
【解決手段】記号入力支援装置において、学習用の文中の各記号について、共起する単語との出現頻度を表す共起単語情報と、コンテクスト情報と、当該記号と記号ごとに与えられた所定の辞書中の語との共起情報とを算出し、算出結果を学習結果として学習結果格納手段に格納する記号出現頻度学習手段と、入力文中における記号挿入位置候補の位置ごとに、挿入対象である各記号について、前記学習結果格納手段に格納された前記学習結果を用いて、前記記号挿入位置候補の各位置に記号を挿入した場合における文特徴量を算出し、当該文特徴量に基づき、挿入に最も適した記号と挿入位置を特定し、当該記号と挿入位置とを変換候補記号格納手段に格納する挿入記号選定手段と、を備えて構成する。
(もっと読む)
情報提供システム
【課題】ユーザから入力された単語に関連する情報であって、当該単語が入力された時以降に更新された情報を、以後の単語入力や検索実行命令を要せずに、ユーザが任意の時点で得られ、ユーザが入力した単語に限定することなく幅を持たせた情報をユーザに提供することができる情報提供システムを提供する。
【解決手段】情報提供サーバ1にネットワークを介して接続されたユーザ端末10により登録された単語の蓄積後、一定期間毎に、前記単語を検索単語として、所定サイト内から検索単語を含む単語を検索する情報提供システムとする。
(もっと読む)
情報処理装置、コンテンツ表示方法及びコンピュータプログラム
【課題】コンテンツに対する検索結果を視覚的に表示させることでコンテンツの効率の良い試聴を提供することが可能な情報処理装置を提供する。
【解決手段】ユーザからの入力操作を受け付ける入力部と、入力部に対する入力操作によって指定された検索条件をメタデータに含むコンテンツを検索する検索部と、検索部の検索に用いた検索条件に関連する関連語を取得する関連語取得部と、検索条件を表示すると共に、検索部の検索の結果得られるコンテンツ及び関連語取得部が取得した関連語を、該検索条件との関連を明示して該検索条件の周囲に配置して表示させる表示制御部と、を備え、検索部は、関連語取得部が取得し表示制御部により表示された関連語に対してされた入力部に対する入力操作によって更なる検索を実行する、情報処理装置が提供される。
(もっと読む)
情報推薦装置、情報推薦方法およびプログラム
【課題】入力情報に対して意外性を有し、且つ、入力情報から見て妥当性のある情報を推薦し得る、情報推薦装置、情報推薦方法、およびプログラムを提供する。
【解決部】情報推薦装置10は、言語表現と、それが示す性質又は機能を表す特徴表現とを対応付けて格納するデータ集合から、入力言語表現に対応する特徴表現を取得し、この特徴表現と入力言語表現との第1の連想度合を求める特徴連想部13と、取得された特徴表現の中から、第1の連想度合に基づいて、設定条件を満たす特徴表現を選出する特徴選出部13と、データ集合から、選出された特徴表現に対応する言語表現を推薦候補として選出し、選出された特徴表現と対応する推薦候補との第2の連想度合を求める候補連想部14と、推薦候補の中から、推薦候補と入力言語表現との類似度と第2の連想度合とに基づいて、推薦対象を絞り込む候補絞込部15とを備える。
(もっと読む)
コミュニケーション端末、システム、情報提示システム、方法およびプログラム
【課題】コミュニケーションの内容に十分に適合する情報を提供する。
【解決手段】コミュニケーション属性とコミュニケーション内容とを取得するコミュニケーション情報取得手段11と、取得されたコミュニケーション内容からキーワードを抽出するキーワード抽出手段12と、取得されたコミュニケーション属性もしくは抽出されたキーワードまたはその双方に含まれる、絶対的な尺度を表す情報と相対的な尺度を表す情報から検索属性を作成する検索属性作成手段13と、作成された検索属性に適合するデータを検索する検索実行手段14と、検索されたデータを提示する検索情報提示手段15とを備える。
(もっと読む)
コンテンツ提供システム、コンテンツ提供方法、およびコンテンツ提供プログラム
【課題】ユーザ固有の話し方等の音声特徴に基づき、適切なコンテンツを提供する。
【解決手段】コンテンツ提供システム100は、音声特徴と、当該音声特徴を有するユーザに提示したいコンテンツとを対応付けて記憶するコンテンツ記憶部126と、入力されたユーザの音声データに基づき算出した当該ユーザの音声要素の値を、標準に対する傾向を判断するための指標データと比較して、当該ユーザに固有の音声特徴を検出する音声特徴検出部104と、コンテンツ記憶部126に記憶されたコンテンツの中から、音声特徴検出部104が検出した音声特徴に対応付けられたコンテンツを選択するコンテンツ選択部106と、そのコンテンツを提示する提示部108と、を含む。
(もっと読む)
話題推薦装置、話題推薦装方法およびプログラム
【課題】現在の会話の中心となっている観点を特定し、その観点に関して近く、他の観点では遠いような話題を提供することができる話題推薦装置、話題推薦装方法およびプログラムを提供する。
【解決手段】話題推薦装置100は、話題を表す情報と、複数の話題に共通する異なる2以上の観点の話題の内容を表すキーワードとを、関連づけて記憶する記憶部1の話題データベース11と、ユーザの会話から抽出した語句にもとづいて、観点ごとの重みを算出する観点判定部2と、直近にユーザに提示した話題と話題データベースの話題とについて、キーワードにもとづいて所定の類似度を算出する類似度算出部3と、話題データベースの中から、重みの大きい観点における類似度に所定の正数を乗じた値と重みの小さい観点における類似度に所定の負数を乗じた値、の和が最も大きい話題を検索する話題検索部4と、その話題をユーザに提示する提示部5と、を備える。
(もっと読む)
FAQ候補抽出システムおよびFAQ候補抽出プログラム
【課題】話し言葉やノイズといった談話データの特性に強く、談話の文章構造の枠組みを規定せずに、談話データの構造を解析した結果からQ&A対を抽出するFAQ候補抽出システムを提供する。
【解決手段】談話データ101および談話セマンティクス200を入力とし、談話データ101からFAQ候補300となる質問−回答対を抽出して出力するFAQ候補抽出システム1であって、談話セマンティクス200は各ステートメントのフロー情報21を含み、質問文であることを示すフローが設定された第1のステートメントを同定し、さらに第1のステートメントの後に最初に現れ、かつ話者が異なり、談話に固有の事項について具体的な内容を述べているものであることを示すフローが設定された第2のステートメントを同定し、第1のステートメントと第2のステートメントとを質問−回答対として抽出するQ&A対抽出部60を有する。
(もっと読む)
1 - 20 / 216
[ Back to top ]