
Fターム[5B075UU06]の内容
検索装置 (67,127) | 用途 (6,943) | 文書管理装置(ワープロなど) (1,105) | 文書ファイル (854)
Fターム[5B075UU06]に分類される特許
1 - 20 / 854
検索方法、検索装置、ならびに、コンピュータプログラム
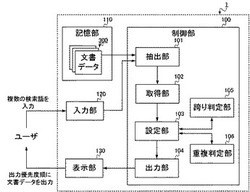
【課題】ユーザの意図にあった検索結果を提示するのに好適な検索方法、検索装置、ならびに、コンピュータプログラムを提供する。
【解決手段】検索装置1において、抽出部101は、複数の文書データ(文書データ群300)のうちから、複数の検索文字列を含む文書データを抽出する。取得部102は、抽出された文書データのそれぞれにおいて、複数の検索文字列を全て包含する文字列を取得する。設定部103は、抽出された文書データのそれぞれに、当該文書データにおいて取得された文字列の文字数に基づいて、出力優先度を設定する。出力部104は、設定された出力優先度を対応付けて、抽出された文書データを出力する。跨り判定部105は、取得された文字列が複数のセンテンスに跨っているか否かを判定する。重複判定部106は、取得された文字列に包含される複数の検索文字列が同一位置にある文字を共有しているか否かを判定する。
(もっと読む)
文書処理装置およびプログラム

【課題】類義語として適切な用語を文書から抽出することが可能な文書処理装置およびプログラムを提供することにある。
【解決手段】用語抽出手段は、文書格納手段に格納されている複数の文書から第1および第2の用語を抽出する。クラスタ生成手段は、複数の文書の各々が属するクラスタを生成する。特徴度算出手段は、複数の文書および生成されたクラスタに属する文書における第1の用語の出現頻度に基づいて当該クラスタに対する第1の用語の特徴度を算出し、複数の文書およびクラスタ生成手段によって生成されたクラスタに属する文書における第2の用語の出現頻度に基づいて当該クラスタに対する第2の用語の特徴度を算出する。類義語抽出手段は、算出された類似度、算出された第1の用語の特徴度および第2の用語の特徴度に基づいて当該第1および第2の用語を類義語として抽出する。
(もっと読む)
Nグラム検索のための転置インデックスの生成方法および生成装置、当該転置インデックスを用いた検索方法および検索装置、ならびに、コンピュータプログラム
【課題】データサイズを抑えつつ高速な検索処理を実現するのに好適な転置インデックスの生成方法等を提供する。
【解決手段】生成装置1において、抽出部101は、文書データ300のうちから「3文字の文字列であるトライグラム」を、当該文書データ300中での出現位置と対応付けて、抽出する。分類部102は、抽出されたトライグラムのうち中央の文字が共通なトライグラムを、先頭および末尾の文字に基づいて、トライグラム群に分類する。生成部103は、分類されたトライグラム群のそれぞれに、当該トライグラム群に分類されたトライグラムに対応付けられた出現位置を対応付けて、転置インデックス900を生成する。
(もっと読む)
要約文生成装置及びプログラム
【課題】機器の使用に関する事項を含むテキストから、本質となる部分を抽出した要約文を生成する。
【解決手段】機器の使用に関する事項を含むテキストを、事項分割部24で、予め定めた事項分割ルールに従って、「状況」、「操作」、「現象」、「要望・意見・質問」に関する事項の各々に該当する部分毎に分割し、重要部分抽出部28で、重要単語辞書26を参照して、各部分に含まれる重要単語数をカウントし、最も多く重要単語を含む部分を重要部分として抽出し、要約文生成部30で、抽出された重要部分の終端に述部を連接するか、重要部分の終端を終止形に変形するか、または重要部分からガ格及び述語を抽出して要約文を生成する。
(もっと読む)
電子書籍装置、サーバ装置、読書情報処理方法、およびプログラム
【課題】読書履歴情報を用いてコミュニケーション支援ができなかった。
【解決手段】電子書籍の読書行為指示を受け付ける受付部と、読書行為指示に応じて電子書籍を表示する電子書籍表示部と、読書行為指示に応じて表示している電子書籍のページをめくるページめくり部と、読書行為指示に応じて読書履歴情報を取得する読書履歴情報取得部と、読書履歴情報を蓄積する読書情報蓄積部と、他人の1以上の読書履歴情報を受信する読書情報受信部と、読書情報受信部が受信した他人の1以上の読書履歴情報と、格納されている1以上の読書履歴情報とから、ユーザと他人との読書に関する関連を示す情報である1以上の関連読書情報を取得する関連読書情報取得部と、1以上の関連読書情報を表示する関連読書情報表示部とを具備する電子書籍装置により、読書履歴情報に基づいて、他人とコミュニケーションをとることを支援できる。
(もっと読む)
構造化文書管理装置、方法およびプログラム
【課題】構造照合処理を高速に行うことができる構造化文書管理装置、方法およびプログラムを提供することである。
【解決手段】実施形態の構造化文書管理装置は、入力されたクエリデータが、構造化文書データの論理構造における階層の上下関係を指定する第1条件と、要素IDで特定される要素の順序関係を指定する第2条件とを含む場合に、クエリデータ分解手段が、該クエリデータを、第1条件のみを含む第1の部分クエリデータと、第1の部分クエリデータによる照合結果を、第2条件に応じて結合演算する手順を含む第2の部分クエリデータとに分解する。構造照合処理手段は、構造化文書データのデータ集合に対して第1の部分クエリデータによる照合を行い、照合結果を出力する。結合演算処理手段は、構造照合処理手段から出力された照合結果を、第2の部分クエリデータに含まれる結合演算の手順に従って結合演算処理する。
(もっと読む)
文書要約装置、方法、およびプログラム
【課題】要約内容の劣化や要約率の低下を回避しつつ、秘密文書から公開可能な要約を作成する。
【解決手段】重要文抽出部14Aで、入力された原文書から重要文を抽出し、秘密事項判定部14Bで、これら重要文に秘密事項が含まれるかを判定し、隠蔽処理部14Cで、秘密事項を含むと判定された重要文から当該秘密事項が含まれない隠蔽文を作成し、文圧縮部14Dで、秘密事項が含まれないと判定された重要文、および隠蔽処理部で作成された隠蔽文について、それぞれの文長を削減する。
(もっと読む)
文書管理システム及び文書管理方法
【課題】管理対象文書を、公開先として指定した組織とともに、閲覧が必要な関連組織にも効率的に設定するための文書管理システム及び文書管理方法を提供する。
【解決手段】文書管理システム20の制御部31は、ユーザ端末10から文書登録依頼を受信すると、管理対象文書、公開先の登録処理を実行する。制御部31は、登録した管理対象文書に対して公開制限フラグが関連付けられている場合には、上位組織及び公開先の特定処理を実行し、関連公開先の登録処理を実行する。文書管理システム20の制御部41は、インデックスの登録処理において、公開制限する管理対象文書については、公開組織コード及び公開等級コードを、インデックスレコードに含めて記録する。制御部41は、検索条件の組織識別子と、検索条件のキーワードとが記録されたインデックスレコードを抽出することにより、検索処理を実行する。
(もっと読む)
文書検索装置
【課題】重要な文書は印刷されることが多いことに着目し、重要性のある文書を効率良く探し出すことのできる装置を提供する。
【解決手段】文書検索装置1は、プリンタドライバ17が文書の印刷指示を受けると、プリンタドライバ17が生成した印刷ジョブから所定の印刷情報を取得し、印刷情報を少なくとも記述した索引データを索引DB11に記憶する索引データ管理手段10を備え、更に、少なくとも印刷情報に係る検索条件を受け付けるUIに入力された検索条件に適合する文書を、索引データを利用して検索し、検索した文書の索引データのスコア順に従い、検索結果に含まれる文書を一覧表示する検索手段12を備えている。
(もっと読む)
文書画像データベースの登録方法および検索方法
【課題】文書画像データベースの大規模化に伴って顕在化するLocally Likely Arrangement Hashing (LLAH) のメモリ効率の問題、および、特徴量の識別性の問題を解決する改善手法を提供する。LLAH は高いロバスト性を実現するために、必要メモリ量が多く、また、大規模化に対処するには、特徴量の識別性・安定性が十分でないという側面がある。
【解決手段】以下の3 点の改良を施す。第1は、ハッシュに保存する特徴点をサンプリングすることによる必要メモリ量の削減である。第2は、特徴量の次元数を増加させることによる識別性向上である。第3は、特徴量のうち冗長性のある次元を削除することによる安定性向上である。
(もっと読む)
データ極性判定装置、方法、及びプログラム
【課題】分野依存性を考慮した上で、観測データの極性を精度よく判定することができるようにする。
【解決手段】パラメータ初期値設定部22によって、極性付き文書生成モデルのパラメータの初期値を設定する。単語極性判定部23によって、ラベルあり文書データ及びラベルなし文書データの各々について、文書データに含まれる各単語について、単語の極性及び分野依存性を決定し、決定された極性及び分野依存性である確率を算出する。パラメータ更新部24によって、極性付き文書生成モデルのパラメータを更新する。そして、繰り返し判定部25によって、所定の収束条件を満たすまで、単語極性判定部23とパラメータ更新部24とを繰り返す。文書極性判定部26によって、その時点のラベルなし文書データの各単語について算出された確率に基づいて、各単語の極性を判定し、判定された各単語の極性に基づいて、ラベルなし文書データの極性を判定する。
(もっと読む)
代表文抽出装置およびプログラム
【課題】文タイプを考慮して文書群において頻度の高い内容を表す代表文を抽出することが可能な代表文抽出装置およびプログラムを提供することにある。
【解決手段】解析手段は、入力手段によって入力された複数の文書を構成する文が表された構造木であって当該文の文タイプが付与された構造木を生成する。代表文候補抽出手段は、構造木に付与された文タイプに対応づけて抽出ルール格納手段に格納されている抽出ルールに従って当該文タイプが付与された代表文候補を抽出する。文生成手段は、抽出された代表文候補に付与された文タイプに対応づけて文生成ルール格納手段に格納されている文生成ルールに従って当該文タイプが付与された代表文候補文を生成する。集約手段は、同一の代表文候補文を1つに集約して集約代表文候補文を生成する。決定手段は、生成された集約代表文候補文に集約された代表文候補文の数に基づいて代表文を決定する。
(もっと読む)
文書処理装置
【課題】特定フォーマットに依存せずに要求仕様書と自社技術体系とを比較し、要注意箇所または合致箇所を抽出することが課題となる。
【解決手段】評価対象である評価対象テキスト文書の記述内容が含まれる知識分野を構成する語句群における、相互の関連性が高い語句どうしをネットワーク接続した標準知識ネットワークデータを保持し、前記テキスト文書を構成する語句群について関連性の高い語句どうしをネットワーク接続した評価対象文書知識ネットワークデータを作成する文書知識作成機能を有し、評価対象文書知識ネットワークデータの構造と標準知識ネットワークデータの構造に対し、それらを構成する特定語句に着目し、当該特定語句にネットワーク接続している語句群の情報が相互に異なる場合に、当該特定語句の情報を含む差異情報とを出力する。
(もっと読む)
マージン生成機能を有するランキング関数生成装置を用いた文書検索装置、マージン生成機能を有するランキング関数生成装置を用いた文書検索方法およびマージン生成機能を有するランキング関数生成装置を用いた文書検索プログラム
【課題】ランキング関数生成の性能を向上し検索ランキングの精度向上を実現した文書検索装置を提供する。
【解決手段】訓練データ中の各クエリの異なる適合度の組合せの順序を変更したときの検索結果評価指標値の変更幅を求め、クエリ毎の最大の変更幅を基準にクエリ毎のマージンを求め、該マージンと訓練データによって、相対的に高い適合度の文書が検索結果上位となるスコア要因を保持したランキングモデルDB104を生成しておく。入力された検索クエリに対応するスコア要因重みを前記DB104から取得し、該スコア要因重みと、クエリ処理部150により算出された、検索結果集合とスコア要因を要素とするスコア要因値行列とを検索スコア計算部160で積算し、該算出された検索スコアの降順に入力検索クエリに対応する検索結果を提示する。
(もっと読む)
ファイル分類装置
【課題】既に実行された分類の基となった分類規則を、その後のファイルの分類に適切に反映することが可能なファイル分類装置を提供すること。
【解決手段】ファイル分類装置100は、ディレクトリに格納されているファイルが有する情報であるファイル情報に基づいて、当該ディレクトリに格納されるファイルが有するべきファイル情報を定める規則である分類規則を推定する分類規則推定部101を備える。
(もっと読む)
文書管理システム、文書管理方法、及びプログラム
【課題】使い勝手のよいファイルシステム上において高度で効率的な検索機能を実現し、ファイルシステム上での電子文書の作業効率を高める文書管理システム等を提供する。
【解決手段】本発明に係るクライアント端末は、ローカルファイルをローカル・ファイルシステム空間で管理・記憶した記憶手段と、ローカルファイルを表示するとともに電子文書が格納されるリモート・ファイルシステム空間をウインドウ画面に表示する表示制御手段と、ウインドウ画面を介して入力された検索キーを含む検索要求を送信し、文書DBに記憶された電子文書を検索する検索要求手段とを有し、文書管理サーバは、検索要求を受信するとウインドウ画面に表示されるリモート・ファイルシステム空間内の電子文書を文書DBから検索し該電子文書を含む検索結果を応答する検索手段とを有し、表示制御手段は、文書管理サーバから検索結果を受信すると、ウインドウ画面に該検索結果を表示する。
(もっと読む)
検索式生成装置、検索システム、検索式生成方法
【課題】概念検索の根拠となる検索式を正確かつ効率的に生成する技術を提供する。
【解決手段】本発明に係る検索式生成装置は、検索タームの論理積を論理和で結合した積和標準形で表される検索条件式を構築し、再現率と精度を基準としてその検索条件式を評価する。次に、検索タームの論理積のうち評価値が最大となるものを論理和で結合することを繰り返し、検索条件式を構築する。
(もっと読む)
文書分類学習制御装置、文書分類装置およびコンピュータプログラム
【課題】文書分類装置に使用される識別器の文書分類能力を高める学習の効率を向上させることを図る。
【解決手段】識別部12に対して学習データ110(ラベル有)を入力するか、又は、強化学習データ120(ラベル無)を入力するか、又は、学習データ110(ラベル有)とアノテーション対象データ310(ラベル有)とを入力するか、を切り替える入力制御部11と、識別部12によって正例文書か負例文書かが判定された強化学習データに対して、正例側ソフトマージン内に在る文書のみを対象にして類似する文書をグループ化し、又、負例側ソフトマージン内に在る文書のみを対象にして類似する文書をグループ化するクラスタリング部14と、グループ化されたクラスタ内の文書をアノテーション対象データとするデータ分類部15とを備える。
(もっと読む)
文書検索装置、文書検索方法、文書検索プログラム
【課題】ユーザに検索キーワードにマッチする文書群と地理的範囲との関連性を容易に把握可能な情報検索サービスを提供する。
【解決手段】文書検索部4は、ユーザ端末2に入力された検索キーワードに基づきDB5を参照して検索キーワードを含む文書群を取得する。地理範囲特定部6は、DB7を参照して取得した各電子文書の地理的表現を示す正規住所を抽出し、DB8を参照して抽出された正規住所に応じた最小の地理範囲を特定する。メッシュ地理スコア算出部9は、ユーザ端末2に表示された地図画面の範囲を区切ったメッシュのスコアを、該メッシュを包含する前記地理範囲の広さに応じて算出する。地図重畳画像描画部10は、メッシュ毎に前記スコアの大小を表す画像を描画する。この画像は送受信部3を通じてユーザ端末2に表示される。
(もっと読む)
特徴語抽出装置、プログラム及び方法
【課題】テキストマイニングの対象となる文書のデータに対して適切な語の区切りを自動的に設定する。
【解決手段】本特徴語抽出装置は、複数の文書のデータが格納されている文書格納部と、当該複数の文書のデータのうち第1の文書のデータにおける文節の各々を、区切り位置及び区切りの数を変化させつつ分割し、当該分割により得られた文字列をデータ格納部に格納する生成部と、データ格納部に格納されている文字列の各々について、当該文字列が第1の文書のデータに出現する回数と文書格納部に格納されている複数の文書のデータのうち当該文字列が出現する文書のデータの件数とを用いて特徴度を算出する算出部と、第1の文書のデータにおける文節の各々について、当該文節についての文字列のうち特徴度が最も高い文字列を特定し、特徴語格納部に格納する特定部とを有する。
(もっと読む)
1 - 20 / 854
[ Back to top ]