
Fターム[5B091AB00]の内容
機械翻訳 (6,566) | 処理対象要素 (373)
Fターム[5B091AB00]の下位に属するFターム
記号、数字、数式 (7)
年号、単位、数詞 (6)
大文字、小文字、字体 (1)
カタカナ、ローマ字、外来語 (5)
固有名詞 (79)
学術用語、技術用語 (12)
複合語、熟語、イディオム (33)
冠詞
活用形、時制、単数・複数、性 (13)
代名詞、指示代名詞 (18)
同義語、類似語、反対語 (144)
主語省略文 (27)
並列構造、複文 (5)
Fターム[5B091AB00]に分類される特許
1 - 20 / 23
文書処理方法、プログラム及び装置
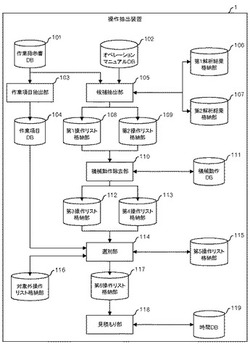
【課題】作業内容を説明した文書から、実際に作業者が行う作業のうち適切な作業を抽出する。
【解決手段】文書処理方法は、作業内容を説明した第1文書データを格納する第1DBから、動詞又はサ変名詞を含む自立語のうち、当該自立語に係る主語が無いという条件を満たす自立語を抽出し第1データ格納部に格納する工程と、作業内容を第1文書データより詳細に説明した第2文書データを格納する第2DBから、動詞又はサ変名詞を含む自立語のうち、上記条件を満たす自立語を抽出し第2データ格納部に格納する工程と、第1データ格納部に格納されておらず且つ第2データ格納部に格納されている自立語と、抽出すべきでない自立語を格納する第3データ格納部に格納されている自立語とを、第1及び第2データ格納部に格納されている自立語の集合から除外し、当該自立語の集合における残余の自立語を第4データ格納部に格納する工程とを含む。
(もっと読む)
スパムブログ判定装置及び方法

【課題】管理者による作業を容易にしてスパムブログを判定するスパムブログ判定装置及び方法を提供する。
【解決手段】スパムブログ判定装置1は、登録指定を受け付けた所定キーワードを所定キーワードDB21に記憶する所定キーワード記憶制御手段12と、判定対象のブログ記事を受け付けたことに応じて、所定キーワードDB21に記憶した所定キーワードを素性として用いてブログ記事がスパムブログであるか否かを機械学習により判定する機械学習手段14と、機械学習手段14による判定対象のブログ記事のうち、所定キーワードDB21に記憶された所定キーワードを含むブログ記事と、スパムブログであるか否かの機械学習による判定結果とを対応付けて出力するスパム判定結果出力手段15と、所定キーワードの削除指定を受け付けたことに応じて、所定キーワードDB21に記憶された所定キーワードを削除する調整戻し手段17とを備える。
(もっと読む)
特徴量算出装置、品詞推定装置およびプログラム
【課題】高い信頼性で未知文字列から単語を特定する技術を提供する。
【解決手段】特徴量算出装置1は、文章データ内において単語の境界を推定し、該境界によって特定される各単語の品詞を推定し、各単語と各単語の品詞を示す品詞ラベルとから構成されるラベル付データを生成するラベル付データ生成部110と、文字、単語および品詞を数値に変換するための変換テーブルを記憶する変換テーブル記憶部104と、上記ラベル付データと上記変換テーブルとを用いて、文章データ内の一の単語の特徴量を示す特徴量データを生成する特徴量データ生成部130とを備え、特徴量データ生成部130は、文章データ内において、一の単語の出現位置の前後所定個数迄の各位置に出現する文字、単語、単語の品詞の種類毎の出現回数を集計し、各集計結果を特徴量として含む特徴量データを生成する。
(もっと読む)
多言語単語分類装置及び多言語単語分類プログラム
【課題】単語の持つ統計的な特徴を用いることなく、単語の品詞が分類された電子辞書が用意できなくても、当該言語に含まれる単語を内容語と機能語とに分類することができる多言語単語分類装置及び多言語単語分類プログラムを提供する。
【解決手段】多言語単語分類装置1は、内容語と機能語とが分類されている第一言語を用い、この第一言語の文字と同一の文字から構成される又は同一の文字を含む言語において、内容語と機能語とが分類されていない第二言語について、当該第二言語の単語を、内容語と機能語とに分類するものであって、単語類似度計算手段3と、第一言語内容語記憶手段5と、単語判定手段7と、を備える構成とした。
(もっと読む)
多言語単語分類装置及び多言語単語分類プログラム
【課題】単語の持つ統計的な特徴を用いることなく、単語の品詞が分類された電子辞書が用意できなくても、当該言語に含まれる単語を内容語と機能語とに分類することができる多言語単語分類装置及び多言語単語分類プログラムを提供する。
【解決手段】多言語単語分類装置1は、複数の単語を含む単語リストが備えられる複数の言語と、内容語と機能語とが分類されていない対象言語とが、同一の文字列から構成される又は同一の文字を予め設定した個数以上含む場合に、前記単語リストを用い、前記対象言語の単語を、内容語と機能語とに分類するものであって、単言語内単語類似度計算手段3と、単語リスト群記憶手段5と、多言語間単語類似度計算手段7と、単語判定手段9と、を備えた。
(もっと読む)
意見文出力装置,意見文出力方法,意見文出力プログラム及びそのプログラムを格納した記録媒体
【課題】アクション時期の異なるオブジェクトに対する意見文を、当該アクション起動日からの経過時間と、当該意見文が記述された日と、に応じた比較が困難であった。
【解決手段】オブジェクトの名前,アクションの種類,アクション起動日からの経過時間を情報入力装置を用いて入力する(1)。前記入力された名前と、アクションの種類と、に応じて、アクション起動日をアクション情報記憶装置5から取得する(2)。前記入力されたオブジェクトに対するアクションの種類に応じて取得されたアクション起動日と、前記入力された経過時間と、前記オブジェクトの名前と、に応じた記述日に対応する意見文をオブジェクト文記憶装置6から取得する(3)。前記名前,前記アクション種類,前記経過時間,取得された意見文を出力する(4)。
(もっと読む)
テキスト分析装置およびテキスト分析プログラム
【課題】文全体の特徴、前後数文の特徴を基に、その文が説明区間に入るか否かを統計的に判定することのできるテキスト分析装置およびテキスト分析プログラムを提供する。
【解決手段】テキスト分析装置が、機械学習処理により得られた素性関数ごとの重要度値からなる学習結果データ記憶部と、複数の文を含む処理対象文章データを読み込み、処理対象文章データに含まれる各々の文を解析して特徴値データを求める特徴抽出部と、前記特徴値データを基に素性関数の値を計算し、学習結果データ記憶部から素性関数ごとの前記重要度値を読み出し、計算された素性関数の値と読み出された重要度値とを基に処理対象文章データに対する出力系列ごとの生起確率値を算出し、算出された前記生起確率値に基づいて一つの出力系列を選択し、この選択された出力系列により前記処理対象文章データ中の特定区間を抽出する判定処理部を備える。
(もっと読む)
電子機器、不適切語句判定方法、プログラム、及び、記録媒体
【課題】特に、第1言語では認識できない、翻訳後の第2言語中に不適切語句が含まれることを確実に防止する。
【解決手段】第1言語による文章を入力するための入力手段4、5と、入力手段4、5により入力された文章を第2言語に翻訳する翻訳手段10、13、17と、不適切語句を記憶する不適切語句記憶手段14と、不適切語句記憶手段14に記憶させた不適切語句が、翻訳手段10、13、17により翻訳された文章中に含まれるか否かを判定する不適切語句判定手段19と、不適切語句判定手段19により不適切語句が含まれていると判定されれば、その旨を報知する報知手段4、6とを備えた構成とする。
(もっと読む)
語彙階層構造抽出方法,装置,およびプログラム
【課題】 形態素情報が連結された語句,文書などのコーパスから,語彙の階層構造情報を自動的に抽出する。
【解決手段】 二語間階層関係導出手段11は,コーパス2の形態素が連結された文書などの集合体から,形態素ごとに連結関係にある他の形態素との包含関係を,統計的指標を用いて包含度を算出し,包含度から当該2語間の階層関係を導出し,情報ベース13に記憶する。階層構造構築手段15は,情報ベース13の同一形態素を上位語とする2語間の階層関係を抽出し,当該上位語の包含度が最も高い2語間の階層関係を初期階層に設定し,設定された2語間の階層関係の下位語が上位語であって包含度が最も高い2語間の階層関係を選択して前記初期階層の下位階層として連結し,前記抽出された2語間の階層関係が連結された語彙階層構造情報3を出力する。
(もっと読む)
情報検索装置および情報検索方法
【課題】ユーザが関心を持つ蓋然性の高い語句として、未だ必ずしも常識化せず目新しい
印象を与えると予測されるような語句をある程度乃至は完全に自動的に選出し、該選出し
た語句をキーワードとして設定し、インターネット検索エンジンによって関連情報のキー
ワード検索を行なう。
【解決手段】供給されるテキスト情報の入力をテキスト情報入力部101で受け、このテ
キスト情報に含まれる語句を語句識別部104で各個に識別し、該識別された語句を予め
準備されている語句データベース110と照合して当該語句の難易度を評価し該評価によ
る難易度が所定水準を上回る語句をキーワードの候補としてキーワード選別部104で選
別し、該選別されたキーワードの候補である語句のうちからユーザによって選択された語
句をキーワードとしてキーワードネット検索部107でインターネット検索を実行する。
(もっと読む)
属性表現獲得方法及び評価表現獲得方法及び装置及びプログラム
【課題】入力評価表現との共起頻度が少ない属性表現であっても属性表現集合をも獲得し、入力属性表現との共起頻度が少ない評価表現であっても評価表現集合をも獲得する。
【解決手段】本発明は、1つの評価表現が入力されると、文書記憶手段から単語の出現位置に関する情報を基に属性表現候補を抽出し、属性表現候補の出現頻度を利用して、属性表現候補を絞り込み、絞り込まれた属性表現候補毎に、共起語を単語の出現位置に関する情報を基に文書記憶手段から抽出し、予め決められた数以上に同じ共起語を持つ属性表現候補をまとめて属性表現集合として抽出する。評価表現集合の抽出についても同様に行う。
(もっと読む)
上下関係判定方法、上下関係判定装置、上下関係判定プログラムおよび記録媒体
【課題】文に関連する人間の上下関係をより具体的に判定することができる上下関係判定方法、上下関係判定装置、上下関係判定プログラム、および、記録媒体を提供する。
【解決手段】指示対象特定部17aは、抽出部16により抽出された名詞が話者、相手および対象者の3者の何れに該当するかを特定する。敬語判断部17bは、検出部14から抽出された敬語に基づいて上記3者間の上下関係を判断する。ランク判断部17cは、ランクDB18に基づいて上記3者間の上下関係を判断する。内外判断部17dは、敬語辞書15の単語の内外関係に基づいて上記3者間の上下関係を判断する。親密度判断部17eは、指示対象間の親密度に基づいて上記3者間の上下関係を決定する。これにより、入力文における上記3者間の上下関係が判定される。
(もっと読む)
用語抽出装置、およびプログラム
【課題】従来の用語抽出装置において、同時翻訳に有用な用語を抽出できない、と言う課題があった。
【解決手段】用語収集の元になる情報である元情報を受け付ける元情報受付部と、元情報と、格納している2以上の各情報群との関連度である情報関連度を、情報群ごとに算出する情報関連度算出部と、2以上の情報群から1以上の用語を抽出する用語抽出部と、用語抽出部が抽出した1以上の各用語の、2以上の情報群における出現頻度と情報関連度に関する情報である出現頻度情報を用語ごとに取得する出現頻度情報取得部と、用語抽出部が抽出した1以上の各用語の、特殊性に関する情報である特殊性情報を用語ごとに取得する特殊性情報取得部と、出現頻度情報および特殊性情報に基づいて、用語抽出部が抽出した用語のうち、1以上の用語を出力する出力部を具備する用語抽出装置により、同時翻訳に有用な用語を抽出できる。
(もっと読む)
翻訳装置、翻訳方法およびプログラム
【課題】 ある言語で作成された文書を異なる言語の文書に翻訳する際に、翻訳文のレイアウトを原文と同一にすることのできる技術の提供を目的とする。
【解決手段】 翻訳装置1は、原文を構成する単位領域毎に、当該単位領域に配置されている原文に対応する翻訳文を原文と同一のレイアウトにて当該単位領域に配置することができるか否かを判定する。判定の結果、翻訳文を原文と同一のレイアウトにて当該単位領域に配置することができない場合に、予め定められた第1の条件を満たす語句を省略対象語句として翻訳文から抽出する。次に、省略対象語句を構成する文字列の一部を省略した省略語を決定する。次に、省略対象語句を省略語に変換した翻訳文を生成し、翻訳文の画像を原文と同一のレイアウトにて生成し、省略語の定義を表す画像を生成する。
(もっと読む)
翻訳装置、翻訳方法およびプログラム
【課題】省略語の本来の意味を表す翻訳結果を得ることのできる技術の提供を目的とする。
【解決手段】原文の記載された原稿の画像を入力し、原文のレイアウトを解析して、語句の省略語とその定義内容とを関連付けた省略語定義領域を抽出する。抽出された省略語定義領域に含まれる定義内容に対応する翻訳語を辞書から抽出し、翻訳語の先頭文字を用いて翻訳省略語を生成する。翻訳省略語と原文の省略語とを対応付けて省略語辞書に記憶させる。そして、原文の文字列に対応する翻訳語および翻訳省略語を辞書および省略語辞書から抽出して翻訳文を生成して出力する。
(もっと読む)
翻訳システム及びプログラム
【課題】翻訳精度を向上させた翻訳システム及びこのプログラムを提供する。
【解決手段】本発明は、第1言語による文を入力する入力部と、省略表現が登録された省略表現記憶部を参照して前記入力部により入力された文について省略された表現を持つか否かを検出し当該検出された省略表現と当該省略前の本来表現との対応リストを作成する省略表現検出部と、前記入力部により入力された文について形態素を解析して単語列を得る形態素解析部と、前記省略表現検出部で省略表現が検出された単語列について前記対応リストを用いて本来表現に変換する表現変換部と、前記形態素解析部で得られた単語列及び該当する場合には前記表現変換部で変換された本来表現について構文解析を行い構文木を得る構文解析部と、前記構文解析部で得られた構文木を用いて第2言語への変換処理を行う変換処理部、及び構文生成部と形態素生成部とを具備する。
(もっと読む)
表現検出システム、表現検出方法、及びプログラム
【課題】商品等に対する人々の嗜好を示す嗜好表現を適切に検出する。
【解決手段】 特定の評価対象についての評価が記述されたテキストから、特定の評価対象に対する評価者の嗜好を示す嗜好表現を検出する表現検出システムは、特定の評価対象についての評価が記述された複数のテキストの各々を、当該テキストの属性に対応付けて格納しており、各々のテキストから、特定の評価対象の評価を示す評価表現を抽出し、抽出した評価表現が、特定の評価対象に対する肯定的な評価を示す正極性か、又は、特定の評価対象に対する否定的な評価を示す負極性かを判断し、嗜好表現を検出する対象として指定されるテキストの属性を入力し、抽出した評価表現のうち、入力された属性を有するテキストから検出された評価表現を嗜好表現として検出し、当該属性を有するテキストにおいて当該嗜好表現が正極性又は負極性と判断された頻度に対応付けて出力する。
(もっと読む)
会話用合理的エージェント、このエージェントを用いるインテリジェント会話システム、インテリジェント会話を制御する方法、及びそれを用いるプログラム
【課題】会話用合理的エージェントが、人間のユーザ又は他のソフトウェアエージェントである接続相手とのマルチモード対話を包括的に管理できるようにする。
【解決手段】合理的エージェントには、イベントを変換し、外部エージェントの通信活動を着信形式レコードに翻訳する解釈手段と、着信形式レコードの機能として、発信形式レコード及び合理的エージェントの行動モデルを生成する合理的ユニットと、発信形式レコードを発信イベントに変換して、外部エージェントとの合理的エージェントの通信活動を具現化する発信イベント生成手段と、が含まれる。解釈手段には、幾つかの解釈モジュールが含まれ、合理的エージェントには、入出力管理層が含まれる。入出力管理層は、着信形式レコードを互いに関係付け、このようにして互いに関係付けられた着信形式通信レコードを合理的ユニットに送出する。
(もっと読む)
単語抽出方法、装置、およびプログラム
【課題】 高精度な未知語抽出を行う。
【解決手段】 単語選別部40は、形態素解析部30による形態素解析結果、統計的単語分割部20による統計的単語分割結果、テキスト中の文字列の統計量、文字列長、の少なくとも1つの情報を用いて、統計的単語分割された文字列から単語として不適切なものを所定の条件によって除いて単語の選別を行い、選別された単語を未知語として抽出する。
(もっと読む)
機械翻訳システム、機械翻訳方法及びプログラム
【課題】表や箇条書きなどの構造を有する文書の翻訳において、高精度かつ安定した機械翻訳システムを提供する。
【解決手段】構造を有する文書から当該構造上で同一の属性あるいは等価な配置関係を有する第1の言語の第1の語・文集合を抽出し、任意のカテゴリに属する第1の言語の語・文集合に属する各語・文に対応し、当該各語・文を第2の言語の当該カテゴリに属する語・文に翻訳するための、当該語・文集合をそれぞれ含む複数の解釈データを記憶する記憶手段から、第1の語・文集合の各語・文に対応する各解釈データを検索し、検索された解釈データに含まれる語・文集合が第1の語・文集合と同一か否かを判定し、第1の語・文集合と同一と判定された語・文集合を含む各解釈データを用いて、第1の語・文集合の各語・文を翻訳する。
(もっと読む)
1 - 20 / 23
[ Back to top ]