
Fターム[5B091BA04]の内容
Fターム[5B091BA04]の下位に属するFターム
一部分可変 (45)
Fターム[5B091BA04]に分類される特許
1 - 20 / 51
財務文書対訳表示システム
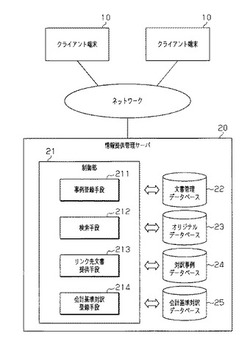
【課題】財務文書について、利用しやすい形態で、複数の言語による対訳を表示するための財務文書対訳表示システムを提供する。
【解決手段】情報提供管理サーバ20の制御部21は、第1言語、第2言語の財務文書を各文章に分割し、第1言語の文章に対応する第2言語の文章を特定し、これらを関連付けて対訳事例データベース24に記録する。制御部21は、クライアント端末10から、検索キーワードを取得した場合、このキーワードを含む第1言語事例文章、第2言語事例文章を検索して抽出する。制御部21は、抽出した文章の言語とは異なる言語の対応する文章を、対訳事例データベース24に記憶したデータを用いて特定し、これら文章を企業名及び文書種類に関連付けて検索結果としてクライアント端末10に出力する。
(もっと読む)
情報検索翻訳システム、情報検索サーバ、通信端末、情報検索翻訳方法及び情報検索翻訳装置

【課題】情報の検索機能と翻訳機能との連携を実現し、使用頻度の高い質問についての翻訳文を、検索結果を反映させた態様で、正確かつ迅速に提供できるようにする。
【解決手段】 地図検索サーバから提供された検索結果情報を含む翻訳文の作成指示を、キー操作部411を通じて受け付ける。この場合に、穴埋め翻訳処理部434が、翻訳DB431から目的とする翻訳文を読み出し、当該目的とする翻訳文の所定の位置に、選択された検索結果情報に対応する翻訳情報を挿入して、翻訳文を完成させる。この完成させた翻訳文を、表示制御部412を通じて表示部413の表示画面に表示する。
(もっと読む)
用例翻訳システム、用例翻訳方法及び用例翻訳プログラム
【課題】類似度の計算方法に翻訳対象の分野情報を指標の一つとして加えることで、利用者の求める翻訳結果により近い用例訳文を提供することである。
【解決手段】用例検索部は翻訳対象原文と翻訳用例データベースの翻訳用例原文との類似度を計算し類似度が予め定めた閾値以上の翻訳用例を翻訳用例データベースから検索する。形態素解析部は用例検索部により複数の翻訳用例が検索されたとき複数の翻訳用例のそれぞれの訳文を形態素解析辞書の形態素解析情報を参照して形態素解析し単語を抽出する。加点値計算部は形態素解析部で抽出された前記単語につきコーパスの単語頻度情報を参照し単語の出現頻度に応じて翻訳用例の類似度の加算値を計算する。翻訳用例選出部は用例検索部で計算された類似度に加点値計算部で計算された加算値を加算して最も大きい類似度の翻訳用例を選出する。
(もっと読む)
類義性尺度用パラメタ学習装置およびそのプログラム、並びに、類義性尺度計算装置
【課題】本発明は、正解データの作成コストを低減でき、正確性が高い類義性尺度を計算可能なパラメタを学習する類義性尺度用パラメタ学習装置を提供する。
【解決手段】類義性尺度学習装置100は、対訳コーパスを用いて、後記する類義関係単語対一覧および非類義関係単語対一覧を正解データとして作成する正解データ作成装置1と、正解データ作成装置1が作成した類義関係単語対一覧および非類義関係単語対一覧を用いて、単語間の類義性尺度を算出するためのパラメタを学習するパラメタ学習装置3と、パラメタ学習装置3が学習したパラメタを用いて、類義性尺度を計算する類義性尺度計算装置5とを備える。
(もっと読む)
情報出力装置及び情報出力プログラム
【課題】中国語テキストの四声をユーザに分かりやすく表示する。
【解決手段】電子辞書1は、中国語の漢字文字列と当該漢字文字列に対応するピンイン文字列とが含まれる中国語テキストを記憶する中国語会話データベースを備えている。そして、記憶されている中国語テキストから漢字文字列とピンイン文字列とをそれぞれ抽出して、ピンイン文字列に含まれる四声データを漢字文字列の各漢字に対応付けるとともに、この四声データの発音の抑揚を視覚的に示す四声マークを、当該四声データと対応付けられた各漢字の近くに表示する。
(もっと読む)
例文表示制御装置及びプログラム
【課題】例文表示でユーザが一方の言語の例文中の任意の単語をマーキングした際に、他方の言語の例文の該当する単語を自動的にマーキングする。
【解決手段】ユーザが入力部13を通じて第1言語と第2言語の一方の言語の例文中の文字列を指定すると、CPU11は、その指定された文字列を識別表示(マーキング)する。その際、CPU11は、当該指定文字列から辞書検索のための単語を抽出し、この抽出した単語の対訳を辞書データベース23から検索することにより、第2言語の例文中の該当する文字列に対して同じ表示形態で識別表示を行う。
(もっと読む)
機械翻訳装置及び機械翻訳プログラム
【課題】用例ベース方式による中国語の入力語の翻訳精度を向上させる。
【解決手段】差分文字列検索部5が、翻訳対象の差分文字列を前後方向にN文字拡張した拡張パターン及び類似用例の差分文字列を前後方向にN文字拡張した拡張パターンを作成し、文字数を順次短くしながら翻訳対象の拡張パターン及び類似用例の拡張パターンの日本語訳を辞書データベース6bから検索する。翻訳対象の拡張パターンの日本語訳と類似用例の拡張パターンの日本語訳の双方の検索に成功した場合、組立部8が、類似用例の日本語訳を構成する文字列中の拡張パターンに対応する部分を翻訳対象の拡張パターンの日本語訳に置換した文字列を出力する。
(もっと読む)
自動翻訳装置、自動翻訳方法、プログラム及び記録媒体
【課題】1つの原言語の文例から複数の翻訳例が得られるような場合でも、ユーザに対して正確な翻訳結果を提供できるようにする。
【解決手段】自動翻訳装置は、翻訳対象となる原言語と前記原言語に対応する翻訳先の目的言語とからなる辞書を保持する翻訳辞書保持手段と、入力された原言語データに対応する目的言語データを翻訳辞書保持手段から取得する翻訳手段と、翻訳手段により取得された目的言語データが複数存在する場合に、複数の目的言語データを翻訳結果の候補として提示する翻訳候補提示手段と、翻訳候補提示手段により提示された複数の目的言語データから選択された目的言語データを最終的な翻訳結果として提示する翻訳結果提示手段と、を有する。
(もっと読む)
翻訳支援方法、翻訳支援装置及びコンピュータプログラム
【課題】翻訳メモリを共有メモリとして用いて翻訳効率を改善すると共に、翻訳メモリの機密性を効果的に維持することができる翻訳支援方法、翻訳支援装置及びコンピュータプログラムを提供する。
【解決手段】原文情報、翻訳文情報及び翻訳に係る局面に関する局面情報を含む付随情報の入力を受け付け、入力を受け付けた局面情報と既に翻訳メモリに記憶されている局面情報との類似度である局面類似度を算出する。算出された局面類似度が所定の閾値より小さい局面情報が存在する場合、局面情報に対応する翻訳文情報についてのみ、入力を受け付けた翻訳文情報との類似度である訳文類似度を算出する。算出された訳文類似度が所定の閾値より大きい翻訳文情報が存在する場合、入力を受け付けた原文情報、翻訳文情報及び付随情報を共有メモリへ複写する。
(もっと読む)
フレーズベースの統計的機械翻訳方法及びシステム
【課題】翻訳品質を効果的に高めるフレーズベースの統計的機械翻訳方法及びシステムを提供する。
【解決手段】統計的機械翻訳方法は、以下のステップから構成される。まずステップ305において翻訳すべき入力文を取得する。ステップ310において、予め構築されたフレーズテーブルからフレーズファジーマッチング手法を用いて入力文における各句について同一または最も類似した対訳句対を検索する。そして、最も類似した対訳句対について修正を行うことにより、各句の正確な翻訳文を得る。ステップ315において、ステップ310において得られた対訳句対と予め構築された言語モデルに基づいて、入力文についての目的言語の全ての翻訳文を検出する。そして、統計モデルを用いて最も高いスコアの翻訳文を入力文の正しい目的言語翻訳文として選択する。ステップ320において、生成された目的言語翻訳文を出力する。
(もっと読む)
翻訳メモリ翻訳装置および翻訳プログラム
【課題】 従来の翻訳メモリ翻訳装置を改良し、翻訳カバー率を向上させた翻訳メモリ翻訳装置を提供する。
【解決手段】 翻訳メモリ翻訳装置100は、例文対訳辞書128を参照し、入力文と完全に一致する第1言語の例文を検索する検索手段と、検索手段により一致する例文が検索されないとき、入力文と第1言語の例文との差分に基づき入力文に類似する第1言語の例文候補を選択する例文選択部142と、例文候補の対訳となる第2言語の例文の中から差分に対応する文字列を識別し、入力文と第2言語の例文の対応関係を求める単語アライメント部144と、識別された文字列を差分に基づき変換することで入力文の第2言語の訳文を生成する訳文生成部148とを有する。
(もっと読む)
例文検索装置および例文検索処理プログラム
【課題】電子辞書装置等の例文データベースを活用して翻訳に似た機能を実現することが可能になる例文検索装置を提供する。
【解決手段】格納例文メモリ12dに記憶されている全ての例文のそれぞれを構成する形態素の各単語をキーワードとし、当該キーワードが含まれる例文の文章IDを対応付けて記憶した検索インデックスメモリ12eを用意する。そして、ユーザ入力された文字列(文章)を形態素解析した各単語のそれぞれに対応する文章IDを前記検索インデックスメモリ12eから検索し、その検索された文章IDの出現頻度(出現数)が多い順に当該文章IDに対応する例文とその対訳文を前記格納例文メモリ12dから読み出して、例文検索結果の表示画面Gとして表示する。このため、高度で負荷の重い翻訳機能を必要とすることなく、例文のデータベースを有効に活用して翻訳に似た機能を実現できる。
(もっと読む)
使用者製作問答データに基づいた会話辞書サービスの提供方法及びシステム
【課題】使用者により拡張することのできる会話辞書サービス方法及びシステムを提供する。
【解決手段】使用者の要請によって、会話データベースから獲得した会話情報の含まれた結果ページを使用者に提供すると共に、提供された結果ページを使用者が修正できるようにする編集エディターを提供し、使用者が編集エディターを利用して会話情報を編集して格納することができる。これによれば、個々人の使用者が会話例文を自分の趣向に合わせて編集して会話辞書を生成でき、他の使用者はこれを利用してまた他の会話辞書を生成できる。このように使用者の編集した会話例文を利用して会話表現のカバレージを広めることができる効果がある。
(もっと読む)
機械翻訳を行う装置、方法およびプログラム
【課題】確実性や自然性を損なわずにコーパスベースの機械翻訳を実行する機械翻訳装置を提供する。
【解決手段】用例記憶部121に記憶された用例対それぞれについて、第1言語の用例に含まれる語句に対応する第1概念と第2言語の用例に含まれる語句に対応する第2概念とを概念記憶部122から取得する概念取得部103と、第1概念と第2概念との間で一致しない不一致概念が存在するか否かを判断し、不一致概念が存在する用例対が利用できないと判断する利用可否判断部104と、第1言語による入力文を受付ける受付部101と、入力文に類似または一致する第1言語の用例を含む用例対を検索する用例対検索部102と、検索された用例対のうち、利用できないと判断された用例対を除く用例対に含まれる第2言語の用例を翻訳結果として出力する出力制御部105と、を備えた。
(もっと読む)
訳文生成方法及び装置並びに機械翻訳
【課題】本発明は訳文並びに機械翻訳生成方法及び装置を提供する。
【解決手段】翻訳対象第1言語の文が複数に分離され、整列二ヶ国語用例コーパスが第1言語と第2言語の複数の例文対並びに各文対間の配列情報を含み、第1言語の各断片に対応する第2言語の訳文断片により構成される、方法であって、訳文断片の組み合わせに関する複数の特徴関数から得られる積算得点に基づいて第1言語の文に対応する第2言語の複数の可能訳文断片の組み合わせから第2言語の最適訳文断片の組み合わせを選択し、最適訳文組み合わせに基づいて第2言語の訳文を生成することを含む。
(もっと読む)
用例データベース作成装置及び用例データベース作成プログラム、並びに、翻訳装置及び翻訳プログラム
【課題】第一言語の1つの文が第二言語の複数の文に翻訳されている場合に、日本語の1つの文における部分と英語の1つの文とが対応するようにした用例データベースを作成することができる用例データベース作成装置及びそのプログラム、並びに、第一言語の文を第二言語の自然な文に翻訳することができる翻訳装置及びそのプログラムを提供する。
【解決手段】用例データベース作成装置1は、第一言語の文を第二言語の文に翻訳した翻訳データが収められている対訳データベース2に、第一言語の1つの文の部分と第二言語の1つの文とが対応するようにした一文対応翻訳データを追加して、用例データベース4を作成するものであって、翻訳データ判別手段3と、引用表現判別手段5と、引用表現分離手段9と、第二言語複数文判別手段11と、第一言語表現特定手段15と、第一言語分割手段19と、分割第一言語対応第二言語追加手段21と、を備える。
(もっと読む)
入力された原言語文を目的言語に機械翻訳する装置、方法およびプログラム
【課題】音声翻訳の翻訳精度を向上させる機械翻訳装置を提供する。
【解決手段】第1言語の用例と第2言語の用例とを対応づけて記憶する用例記憶部123と、入力された第1言語文に対応する第2言語の用例を用例記憶部123から取得する用例翻訳部104と、予め定められた規則に基づいて、第1言語文を第2言語に翻訳する規則翻訳部103と、用例翻訳部104の翻訳結果と規則翻訳部103の翻訳結果とから最も確からしい翻訳結果を選択する選択部102aと、第1言語文に含まれる第1単語と、選択された翻訳結果に含まれる第2単語との間の対応関係を記憶するキャッシュメモリ122と、選択された翻訳結果を出力する出力部105と、を備え、規則翻訳部103は、さらに、第1単語に対応する第2単語をキャッシュメモリ122から取得し、取得した第2単語で第1単語を変換した第2単語を置換する。
(もっと読む)
情報処理装置、情報処理方法及びソフトウェア
【課題】外国語を翻訳するための翻訳データのデータサイズは小さくし、翻訳の概要と詳細のどちらも表示できる手段を備えた携帯電話を提供すること。
【解決手段】
上記課題を解決するために、例えば、請求項1記載の如く、他の装置と通信する通信部と、画像情報を出力する撮像部と、該撮像部により出力された画像情報に含まれる識別情報を認識する認識部と、該認識部により認識された識別情報に関連した関連情報の取得を指示する関連情報取得指示部と、該関連情報取得指示部により該関連情報の取得が指示された場合に該関連情報を該通信部を介して取得し表示するように制御する制御部とを備えればよい。
(もっと読む)
例文検索装置および例文検索処理プログラム
【課題】言語の学習に際して例文を検索するための例文検索装置において、第2言語を殆ど理解できない状況でも、所望の第1言語の単語を入力するだけで、入力された第1言語に対応する第2言語の単語を含んでいる、適切な第2言語の例文検索を行う。
【解決手段】所望の日本語の単語をキーワードとしてユーザ入力すると(S4〜S7)、内部的には当該ユーザ入力された日本語キーワードの中国語訳である中国語単語が日中辞書の日中単語対応テーブルから高速に検索されて例文キーワードとして設定される(S8)。すると、この中国語単語の例文キーワードを含む各例文が例文検索テーブルに基づき中日辞書から検索されて一覧表示され(S9〜S12)、反転カーソルにより任意の例文が選択表示されると(S13)、この選択表示された例文の日本語訳である説明情報が前記中日辞書から読み出されウインドウ表示される(S14)。
(もっと読む)
翻訳装置、翻訳方法および翻訳プログラム
【課題】 例文対訳辞書を有効に活用し、迅速に正確な対訳を得ることができる翻訳メモリ装置を提供する。
【解決手段】 翻訳メモリ装置は、第1言語の複数の例文と当該第1言語の複数の例文の対訳である第2の言語の複数の例文を記憶する例文対訳辞書部116と、第1または第2言語の入力文を入力する入力部100、200と、入力文と同一言語の例文が例文対訳辞書部に含まれているか否かを検索する例文照合部112、212と、一致する例文が検索されないとき、入力文に類似する例文候補を検索する類似例文検索部114、214と、検索された例文の対訳の例文を出力する出力部118とを有する。
(もっと読む)
1 - 20 / 51
[ Back to top ]