
Fターム[5B091BA11]の内容
Fターム[5B091BA11]の下位に属するFターム
Fターム[5B091BA11]に分類される特許
1 - 20 / 71
翻訳システム
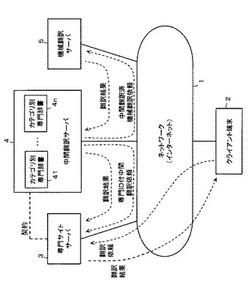
【課題】汎用の機械翻訳を用いる場合においても、使用者は、翻訳依頼をするだけで、より高精度の翻訳結果を得られるようにした翻訳システムを提供する。
【解決手段】汎用の機械翻訳用辞書を用いて機械翻訳を実行する機械翻訳実行手段5と、第1の言語による特定の専門用途に関する翻訳対象文を、第1の言語とは異なる第2の言語に翻訳する翻訳依頼を受け付ける翻訳依頼受付手段と、翻訳依頼受付手段で受け付けた翻訳依頼に基づき、第1の言語による翻訳対象文を解析し、特定の専門用途における第1の言語の語を第2の言語の語に変換するための専門辞書により変換可能な語のみを第2の言語の語に変換する中間翻訳を実行して中間翻訳結果を得、その中間翻訳結果を機械翻訳実行手段5に渡す中間翻訳実行手段を備える。機械翻訳実行手段で中間翻訳結果について機械翻訳が実行されて得られた機械翻訳結果を翻訳依頼に応じた翻訳結果とする。
(もっと読む)
情報処理装置、プログラム、および翻訳テンプレート生成方法

【課題】構文構造が異なった対訳文対から翻訳テンプレートを生成できるようにする。
【解決手段】取得手段1aは、第1の言語文と第2の言語文とを取得する。分割手段1bは、取得した第1および第2の言語文それぞれを、複数の形態素に分割する。カウント手段1cは、取得した第1および第2の言語文から分割された各形態素の出現頻度をカウントする。検出手段1eは、取得した第1の言語文から出現頻度が2以上の形態素を検出し、該検出された形態素の第2の言語における訳語であり、出現頻度が1の形態素を、取得した第2の言語文から検出する。生成手段1fは、取得した第1および第2の言語文それぞれから検出された形態素を変数に置き換える置換処理を行い、該置換処理後の第1および第2の言語文を含む翻訳テンプレートを生成する。
(もっと読む)
構文解析情報作成装置、翻訳装置、翻訳システム、構文解析情報作成方法およびコンピュータプログラム
【課題】 文字認識処理および翻訳処理の高精度化を図りつつ、文字を認識する速度の向上を図る。
【解決手段】 構文解析情報作成装置は、情報作成部1を備える。情報作成部1は、文法制約条件を示す第1構文解析情報(例えば、翻訳用の構文解析情報)から、解析対象の単語候補に対応する文法情報を抽出し、当該抽出した文法情報に基づいて、前記単語候補に対応する文法制約条件を示す第2構文解析情報(例えば、文字認識用の構文解析情報)を作成する。
(もっと読む)
機械翻訳装置、および機械翻訳方法
【課題】従来、精度の高い機械翻訳ができなかった。
【解決手段】係り受け森を構成する各頂点に対して、1以上の各翻訳規則を適用し、頂点ごとに、合致する1以上の翻訳規則を取得する翻訳規則取得部と、係り受け森を構成する各頂点をヘッドとした1以上の超辺であり、各頂点に対応する1以上の翻訳規則の左辺における変数部分に対応する頂点をテイルとした1以上の超辺を取得する超辺取得部と、係り受け森を構成する全頂点と、超辺取得部が取得した1以上の超辺とを有する翻訳森を取得する翻訳森取得部と、翻訳森の各頂点に対応する1以上の各超辺が有する翻訳規則の右辺と単語辞書とを用いて、1以上の翻訳候補を取得する翻訳候補取得部と、1以上の翻訳候補のうちいずれか1以上の翻訳候補である翻訳結果を出力する出力部とを具備する機械翻訳装置により、精度の高い機械翻訳が可能となる。
(もっと読む)
翻訳装置、翻訳プログラムおよび翻訳方法
【課題】各翻訳部品を整合性のとれた自然な文に組み合わせること。
【解決手段】翻訳装置100は、翻訳対象となる文章を、複数の構造部品に分割し、各構造部品のパターンに対応する文法によって機械翻訳することで、複数の翻訳部品を作成する。そして、翻訳装置100は、翻訳部品の主要部を特定し、主要部を変数に置き換えた検索キーおよび主要部をそのままにした検索キーを作成する。翻訳装置100は、主要部を変数に置き換えた検索キーよりも、変数に置き換えていない検索キーのほうが優位になるように、検索キーに重みをつける。翻訳装置100は、各検索キーを利用して、コーパスデータ103dを検索し、ヒット数と検索キーの重みに基づいて、翻訳候補を評価する。
(もっと読む)
音声翻訳装置、方法、及びプログラム
【課題】円滑なコミュニケーションを実現できる。
【解決手段】音声翻訳装置は、入力部、音声認識部、感情認識部、平静文生成部、翻訳部、補足文生成部、及び音声合成部を含む。入力部は、第1言語の音声を音声信号に変換する。音声認識部は、音声信号を音声認識処理し文字列を生成する。感情識別部は、文字列がどの感情種別を含むかを識別して1以上の感情種別を含む感情識別情報を得る。平静文生成部は、感情に伴って語句が変化した非平静語句と、非平静語句に対応しかつ感情による変化を伴わない平静語句とを対応付けたモデルより、文字列に第1言語の非平静語句が含まれる場合、第1言語の非平静語句を対応する第1言語の平静語句に変換した平静文を生成する。翻訳部は、平静文を第2言語に翻訳した訳文を生成する。補足文生成部は、感情識別情報の感情種別を第2言語で説明する補足文を生成する。音声合成部は、訳文と補足文とを音声信号に変換する。
(もっと読む)
翻訳装置、翻訳方法、及び翻訳プログラム
【課題】正確な翻訳文を得るととともに、表現可能な範囲の拡張性を確保した翻訳技術を提供する。
【解決手段】第1の言語で記述された第1の例文と、当該第1の例文を第2の言語で記述した第2の例文とを格納する例文格納手段を備えた翻訳装置において、複数の候補例文の中から利用者により選択された前記第1の例文と、当該第1の例文における所定の構成部に埋め込まれる文字列として利用者により入力された文字列とを取得する制御手段と、前記文字列を前記第2の言語の文字列に翻訳するとともに、前記第1の例文に対応する前記第2の例文を前記例文格納手段から読み出し、前記所定の構成部に対応する前記第2の例文における構成部に、前記第2の言語の文字列を埋め込むことにより翻訳文を生成し、当該翻訳文を出力する翻訳手段と、を備える。
(もっと読む)
機械翻訳装置及び機械翻訳プログラム
【課題】第一言語の原文には必ずしも表現されておらず、解釈に言外の知識を要する曖昧性がある場合であっても精度よく翻訳可能とすることである。
【解決手段】実施形態の機械翻訳装置によれば、曖昧箇所検出手段は、翻訳対象となる第一言語文書では明示されていないが文書解析翻訳手段で得た第二言語の訳文には必要となる情報が欠落している曖昧箇所を検出する。質問文作成手段は、曖昧箇所ごとに第二言語の訳文に必要となる情報を得るためのユーザへの質問文を作成する。質問文付与手段は第一言語の原文の該当箇所にその質問文を付与し、表示装置に第一言語の原文及び質問文を表示する。回答解析手段は、質問文に対するユーザからの回答から第二言語の訳文に必要となる情報を獲得して第二言語の訳文に反映させる。
(もっと読む)
自動単語対応付け装置とその方法とプログラム
【課題】トピックを導入した同義語辞書モデルを構築させ、その同義語辞書モデルと従来の単語対応付けモデルとを同時に用いた自動単語対応付け装置を提供する。
【解決手段】この発明の自動単語対応付け装置は、訓練データ記憶部と、アライメント確率学習部と、自動対応付け部と、を具備する。訓練データ記憶部は、単語で区切られた原言語と目的言語の対訳文の組みで構成される対訳文コーパスと、上記目的言語の同義語の組の集合である同義語辞書とから成る。アライメント確率学習部は、トピック毎に、対訳文コーパスの対数尤度と同義語辞書の対数尤度との重み付き和を最大にするパラメータを学習する。自動対応付け部は、対象翻訳文とそのパラメータを入力として対象翻訳文の原言語と目的言語の単語間のアライメントを生成する。
(もっと読む)
素性重み学習装置、N−bestスコアリング装置、N−bestリランキング装置、それらの方法およびプログラム
【課題】入力に対する尤もらしい上位N個の変換結果を、任意に設定した複数の素性に基づきスコアリングやリランキングする際に、当該複数の素性の中に疎な素性が含まれていても精度の高いスコアリングやリランキングを行うことを可能とする。
【解決手段】複数の学習用データを用い、任意に設定した複数の素性それぞれに対する重みを学習用データごとに別々のタスクとしてマルチタスク学習法により学習し、その重みの値を指標として、当該複数の素性のうち各学習用データに共通して作用している素性を抽出し、この抽出した素性に絞り込んで素性重みを学習してスコアリングやリランキングを実行する。
(もっと読む)
機械翻訳装置、機械翻訳方法、およびそのプログラム
【課題】高い翻訳精度の機械翻訳技術を提供する。
【解決手段】本発明は、部分仮説を拡張する手法によって、翻訳元言語の単語列から翻訳先言語の単語列を生成する機械翻訳装置2であって、(a)翻訳候補となる翻訳先言語の単語列だけでなく、少なくとも、(b)翻訳元言語の文を翻訳先言語の語順に並び替えた単語列、および、(c)翻訳先言語の文を翻訳元言語の語順に並び替えた単語列、のいずれかを考慮して部分仮説の評価値を示す部分仮説スコアを算出することで、翻訳精度を向上させることができる。
(もっと読む)
機械翻訳装置、機械翻訳方法、およびそのプログラム
【課題】部分列に分割された入力文に対する機械翻訳において、手作業で作成した規則を用いることなく部分列翻訳を適切な順序に結合可能とする。
【解決手段】構文解析に基づき各ブロックが1以上の単語と下位のブロックの挿入位置を表す非終端記号とからなる複数のブロックに分割された原言語の学習文と、当該分割されたブロックごとの目的言語による前記非終端記号を含む理想翻訳文とからなるブロック分割対訳文を用いてブロック翻訳モデルを学習し、目的言語への翻訳対象である原言語の入力文を、構文解析に基づき複数のブロックに分割し、前記ブロック翻訳モデルを用いて前記入力文の分割された各ブロックをそれぞれ目的言語による前記非終端記号を含む翻訳文に翻訳し、各ブロックの翻訳文を前記非終端記号で表されるブロック挿入位置に基づき結合することにより、入力文に対する翻訳文を生成する。
(もっと読む)
句テーブル生成器及びそのためのコンピュータプログラム
【課題】複数のソース言語単語セグメント化方式をSMTデコード処理に統合して翻訳の品質を高める、単語セグメント化システム及び単語セグメント化方法を提供する。
【解決手段】句テーブル生成器10は、翻訳対のバイリンガルコーパス32及び34を記憶する記憶部30を含む。翻訳対の各々は第1の言語34のソース文と、第2の言語32のターゲット文とを含む。生成器はさらに、コーパスを利用して統計的機械翻訳機(SMT)をトレーニングする分類器トレーニング装置12を含む。SMTはトレーニングの間に句テーブル16を出力する。生成器10はさらに、複数の句テーブル16を統合された句テーブル20に統合するための句テーブルマージ部18を含む。
(もっと読む)
一般化された巡回セールスマン問題としてのフレーズ−ベースの統計的機械翻訳
【課題】一般化された巡回セールスマン問題としてのフレーズ−ベースの統計的機械翻訳を行う。
【解決手段】統計的機械翻訳(SMT)および一般化された非対称巡回セールスマン問題(GTSP)グラフを使用して2つの言語を翻訳する方法は、SMT問題をGTSPとして定義するステップ(120)と、入力文のブロックを、前記GTSPを表すGTSPグラフ内のノードに対応するバイ−フレーズを使用して翻訳するステップ(122)と、前記GTSPを解くステップ(124)と、前記GTSPの解によって定義される順序で前記翻訳済みブロックを出力するステップ(126)と、を包含する。
(もっと読む)
翻訳支援装置及び翻訳支援プログラム
【課題】 翻訳対象となる文の構造の正確さを損なわないように翻訳支援する翻訳支援装置及び翻訳支援プログラムを提供することを目的とする。
【解決手段】 入力画面上の表示欄に表示された翻訳対象を、分解に関する第1の指示に基づいて、文の骨格をなす主構造と文の構成要素をなす副構造とに分解する分解手段110と、主構造及び副構造を、翻訳に関する第2の指示に基づいて、それぞれ翻訳する翻訳手段120と、翻訳手段によって翻訳された主構造及び副構造を、合成に関する第3の指示に基づいて、合成する合成手段150と、合成手段により合成された主構造及び副構造を表示装置に表示させる表示制御手段160と、を有する。
(もっと読む)
文章変換システム、文章変換方法、およびプログラム
【課題】複数のユーザのそれぞれに対して、翻訳された文章の内容を容易に理解させること。
【解決手段】文章変換システムは、複数の語句のそれぞれに対応付けて、当該語句をイメージさせる語句イメージ画像を格納する語句画像格納部と、文章を取得する文章取得部と、文章取得部が取得した文章に含まれる複数の語句のそれぞれの、文章における役割を判断する役割判断部と、文章取得部が取得した文章に含まれる複数の語句のそれぞれについて、当該語句に対応付けられている語句イメージ画像を語句画像格納部から取得する語句画像取得部と、語句画像取得部が取得した複数の語句イメージ画像のそれぞれが、役割判断部が判断した役割に応じた位置に配置された、文章の内容をイメージさせる文章イメージ画像を生成する文章画像生成部とを備える。
(もっと読む)
検索結果出力プログラム、検索結果出力装置、および検索結果出力方法
【課題】例文の検索結果を適切な順序で提示可能な検索結果出力装置を提供することを目的とする。
【解決手段】検索結果出力装置100は、評価手段100aが入力例文110aを基準に検索例文110bを評価して抽出例文110dを得る。そして、抽出例文110dの評価110cに寄与した部分を除外した入力例文110aの一部を再評価対象部分110eとして選択する。再評価手段100dは、再評価対象部分110eを基準に検索例文110bを評価(再評価)する。これにより、検索結果出力装置100は、評価110cの高評価と再評価110fの高評価とが必ずしも一致せず、同じ評価基準による同じような検索結果が連続することを好適に避けることができる。
(もっと読む)
翻訳装置、方法、及びプログラム
【課題】ソフトウェアのドキュメントの翻訳に好適な翻訳装置、方法、及びプログラムを提供する。
【解決手段】ソフトウェアのソースコードを記憶するソースコード記憶部32と、ソースコードの仕様が記載されたドキュメントを原言語で生成する生成部45と、生成されたドキュメントを記憶するドキュメント記憶部34と、ドキュメント記憶部からドキュメントを取得するとともに、ドキュメントの生成元のソースコードをソースコード記憶部から取得する取得部50と、取得されたソースコードを参照して、取得されたドキュメントからソースコード中に出現するプログラム要素を検出する検出部60と、検出されたプログラム要素を、目的言語への翻訳が不要な翻訳不用語句に設定する設定部70と、ドキュメントの翻訳不要語句以外の語句を目的言語に翻訳する翻訳部80と、ドキュメントの翻訳結果を出力する出力部20と、を備える。
(もっと読む)
翻訳プログラム、翻訳システム、翻訳システムの製造方法及び対訳データ生成方法
【課題】処理負荷が小さく、かつ、翻訳精度の高い翻訳システム及び翻訳プログラムを提供する。
【解決手段】第1言語で表現された原文データ13を受け取り、翻訳処理部40は、前記原文データに基づいて第1の対訳データ記憶部32に記憶されたいずれかの第1言語単文データを翻訳対象として選択する翻訳対象選択処理部44と、翻訳対象として選択された第1言語単文データと対訳関係を有する第2言語単文データを第1の対訳データ記憶部34から読み出して、読み出した第2言語単文データに基づき訳文データを出力する対訳出力処理部48とを含む。前記第1言語単文データの語句にキーワード情報が設定され、前記キーワード情報に基づき前記原文データと前記第1言語単文データとを比較して、比較結果に基づき前記第1の対訳データ記憶部からいずれかの第1言語単文データを翻訳対象として選択する。
(もっと読む)
フレーズベースの統計的機械翻訳方法及びシステム
【課題】翻訳品質を効果的に高めるフレーズベースの統計的機械翻訳方法及びシステムを提供する。
【解決手段】統計的機械翻訳方法は、以下のステップから構成される。まずステップ305において翻訳すべき入力文を取得する。ステップ310において、予め構築されたフレーズテーブルからフレーズファジーマッチング手法を用いて入力文における各句について同一または最も類似した対訳句対を検索する。そして、最も類似した対訳句対について修正を行うことにより、各句の正確な翻訳文を得る。ステップ315において、ステップ310において得られた対訳句対と予め構築された言語モデルに基づいて、入力文についての目的言語の全ての翻訳文を検出する。そして、統計モデルを用いて最も高いスコアの翻訳文を入力文の正しい目的言語翻訳文として選択する。ステップ320において、生成された目的言語翻訳文を出力する。
(もっと読む)
1 - 20 / 71
[ Back to top ]