
Fターム[5B091CA05]の内容
Fターム[5B091CA05]の下位に属するFターム
Fターム[5B091CA05]に分類される特許
1 - 20 / 258
文書処理装置、文書構成要素間の関係解析方法およびプログラム
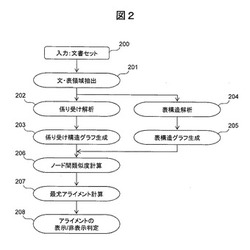
【課題】記載内容が複数の文や表に分かれて存在する文書間や表現の異なる文書間の比較を可能とする文書解析技術を提供する。
【解決手段】複数の文書から文及び表を抽出する。抽出された各文について係り受け関係を解析し、その解析結果に基づいて、単語又は文節をノードとし、文節間の修飾関係や被修飾関係の候補をエッジで表すグラフ構造に変換する。抽出された各表を、枠又は文字行をノードとし、枠間や文字行間の隣接関係をエッジで表すグラフ構造に変換する。次に、枠間や文字行間の隣接関係を表すエッジ間の強度を、枠の隣接パターンや文字列共起頻度に基づいて計算する。異なる文書から生成されたグラフの各ノードペアについて、ノード間の文字列の類似性・同義性と、近傍ノード又は論理関係を持つ遠方のノードの類似性とに基づいて、文及び/又は表の構成要素間のアライメントを判定する。
(もっと読む)
文書処理装置およびプログラム

【課題】助詞「は」を含む文を検出し、当該文の修正を促すことが可能な文書処理装置およびプログラムを提供することにある。
【解決手段】入力手段は、自立語および助詞「は」を含む第1の文節と第1の文節を係り受け元とする第2の文節とを含む複数の文節から構成される文を入力する。構文解析手段は、入力された文を構文解析し、当該文を構成する文節間の係り受け関係を含む構文解析結果を取得する。抽出手段は、入力された文を構成する第1の文節と第2の文節との間の係り受け関係を、構文解析結果から抽出する。メッセージ生成手段は、抽出された係り受け関係に応じた入力された文に対する指摘事項を含むメッセージを、当該係り受け関係に対応づけて格納手段に格納されているメッセージ生成情報に基づいて生成する。出力手段は、生成されたメッセージを出力する。
(もっと読む)
文変換装置およびそのプログラム
【課題】大量の文例によることなく、入力される文の文法構造を利用して、平易な文に変換することのできる文変換装置を提供する。
【解決手段】係り受け解析部は、文データを入力し前記文データの係り受け関係を解析し係り受け構造データを出力する。修飾句認定部は、係り受け構造データに基づき文データに含まれる修飾句を抽出するとともに、属性認定用辞書を参照することによって、抽出された修飾句ごとの属性を認定する。対象修飾句判定部は、修飾句認定部によって認定された属性に基づいて、修飾句が変換対象の修飾句か否かを判定する。長さ判定部は、修飾句の長さに応じて変換対象とするか否かを判定する。文変換部は、文変換規則記憶部から読み出した文変換規則に基づいて、変換対象と判定された修飾句を文に変換して出力する。文短縮部は、変換対象とした修飾句に対応して元の文データを短縮する。
(もっと読む)
換喩判定プログラム及び情報処理装置
【課題】換喩を考慮せずに格要素が記述された格フレーム辞書を用いた場合であっても、文に換喩が含まれるか否かを判定する換喩判定プログラム及び情報処理装置を提供する。
【解決手段】情報処理装置1は、文から動詞及び当該動詞の格要素を抽出する換喩判定対象抽出手段101と、格フレーム情報111から、抽出した動詞と動詞の格要素の少なくとも1つとが一致する格フレームを検索する格フレーム検索手段102と、検索した格フレームのうち抽出した動詞と動詞の格要素とが一致する数の最も多い格フレームを基本格フレームとし、他の格フレームと比較する格フレーム比較手段103と、基本格フレームと他の格フレームとで一致しない格に含まれる格要素どうしから予め定めた方法で用例を生成し、当該用例が換喩判定用情報112に予め定めた頻度で出現する場合、文に換喩が含まれると判定する換喩判定手段104とを有する。
(もっと読む)
FAQ作成支援システム及びプログラム
【課題】FAQ作成支援システムを提供する。
【解決手段】実施形態のFAQ作成支援システムは、問合せ代表文(問合せ文とその回答文を含む文書の文書集合において各文書それぞれの問合せ文から抽出される複数の問合せ代表文のうち同一の問合せ代表文に基づいて、一の問合せ代表文に複数の抽出元の問合せ文に対応する文書が関連付けられた文)と、回答代表文(各文書それぞれの回答文から抽出される複数の回答代表文のうち同一の回答代表文に基づいて、一の回答代表文に複数の抽出元の回答文に対応する文書が関連付けられた文)との対を、問合せ代表文に関連付く各文書が回答代表文それぞれに関連付いている各文書とマッチングする文書数で評価し、問合せ代表文と回答代表文との対に基づくFAQの作成環境を提供する。
(もっと読む)
構文解析情報作成装置、翻訳装置、翻訳システム、構文解析情報作成方法およびコンピュータプログラム
【課題】 文字認識処理および翻訳処理の高精度化を図りつつ、文字を認識する速度の向上を図る。
【解決手段】 構文解析情報作成装置は、情報作成部1を備える。情報作成部1は、文法制約条件を示す第1構文解析情報(例えば、翻訳用の構文解析情報)から、解析対象の単語候補に対応する文法情報を抽出し、当該抽出した文法情報に基づいて、前記単語候補に対応する文法制約条件を示す第2構文解析情報(例えば、文字認識用の構文解析情報)を作成する。
(もっと読む)
多義語抽出システム、多義語抽出方法、およびプログラム
【課題】情報システム構築に関する提案書や仕様書といった特定の案件に関する文書群で一般的な意味と異なる意味を有して使用されている多義語を判別してその文章の曖昧さを改善する。
【解決手段】多義語抽出システムとして、入力を受けた所定の文章中の各単語を抽出する単語分析部と、任意の単語を基軸単語として選択し、該基軸単語と共起関係とみなされる基軸単語共起語とその共起数とで表される基軸単語共起ベクトルを抽出する基軸単語共起ベクトル抽出部と、基軸単語共起ベクトルの各基軸単語共起語の共起語概念を一般概念から推定する共起語概念推定部と、推定した共起語概念群について、対応する共起語概念間の類似性に基づき、選択した基軸単語に関する各基軸単語共起語のクラスタリングを行う共起語分類部と、複数のクラスタが存在した際に多義語候補として抽出する多義語候補推定部と、抽出した候補を出力する多義語候補出力部とを設ける。
(もっと読む)
機械翻訳装置、方法及びプログラム
【課題】第1言語の文書の原文が構文解析に失敗した場合でも、ユーザに負担を課すことなく読みやすい訳文を生成できるとともに、開発者による機械翻訳のチューニングの効率化や省力化を図ることである。
【解決手段】文書解析手段30は、第1言語で表現された文書の各原文を構文解析する。訳文生成手段33は、文書解析手段30で構文解析に成功したときは原文の訳文を生成する。第1言語単語除去手段34は、文書解析手段30で構文解析に失敗したときは原文から1単語を除去した単語列を作成する。また、文書解析手段30は、第1言語単語除去手段34で得られた1単語を除去した単語列を構文解析し、訳文生成手段33は、1単語を除去した単語列の構文解析に成功したときはその単語列の訳文を生成し、1単語を除去した単語列の構文解析に失敗したときは原文の不完全な訳文を生成する。
(もっと読む)
入力文の細部意味を表示する文作成支援自然文処理法。
【課題】入力自然文の意味を表現する意味構造を構築し、その意味構造を細分化し、その細分化した意味構造から自然文を生成し、自然文の細部の意味を提示する。
【解決手段】
入力自然文に形態素解析や構文解析を行い、その解析結果に意味構築処理を行って、部分的な意味構造を構築し、部分的な意味構造を意味根で結合しながら、入力自然文の全体の意味構造を構築する。その意味構造を意味根で細分化して、細分化した当該意味構造から自然文を生成して明示すると入力自然文の意味が細部にまで検証できる。
書き手は、文法と知識を用いて文を作成するが、読み手も書き手と同じ知識を共有するとはかぎらない。本発明では、知識を持たない読み手の立場に立ち、主に文法情報だけで意味解析する。それによって、知識を持たない読み手でも精確に理解できる文を書き手が作成できるように支援する。そのような文作成支援自然文処理法。
(もっと読む)
契約チェック支援装置及び契約チェック支援プログラム
【課題】契約書に含まれる文章の危険度を判定し契約書のチェックを支援する契約チェック支援装置を提供する。
【解決手段】文章分解部12が、契約書データ格納部2に格納された契約書データ21に含まれる文章の各々を分解して、文章に含まれる目的語、述語及び修飾語を抽出すると、文章分解部12が抽出した目的語と述語との組合せが注意目的語/注意述語組合せテーブル24に存在し、文章分解部12が抽出した修飾語が注意修飾語/危険度テーブル25に存在する場合に、危険判定部13が、注意修飾語/危険度テーブル25から修飾語に対応する危険度を求める。
(もっと読む)
文書処理装置およびプログラム
【課題】類義語として適切な用語を文書から抽出することが可能な文書処理装置およびプログラムを提供することにある。
【解決手段】用語抽出手段は、文書格納手段に格納されている複数の文書から第1および第2の用語を抽出する。クラスタ生成手段は、複数の文書の各々が属するクラスタを生成する。特徴度算出手段は、複数の文書および生成されたクラスタに属する文書における第1の用語の出現頻度に基づいて当該クラスタに対する第1の用語の特徴度を算出し、複数の文書およびクラスタ生成手段によって生成されたクラスタに属する文書における第2の用語の出現頻度に基づいて当該クラスタに対する第2の用語の特徴度を算出する。類義語抽出手段は、算出された類似度、算出された第1の用語の特徴度および第2の用語の特徴度に基づいて当該第1および第2の用語を類義語として抽出する。
(もっと読む)
文書処理装置およびプログラム
【課題】構文的にわかりにくい文を自動的に検出し、ユーザに対して提示することが可能な文書処理装置およびプログラムを提供することにある。
【解決手段】ルール格納手段は、構文的にわかりにくい文を検出するための予め定められた条件および当該条件に応じたメッセージを対応づけて格納する。入力手段は、ユーザによって指定された文を入力する。解析手段は、入力手段によって入力された文の構造を解析する。判定手段は、解析手段による解析結果に基づいて、入力手段によって入力された文がルール格納手段に格納されている条件を満たすかを判定する。出力手段は、条件を満たすと判定手段によって判定された場合、入力手段によって入力された文の構造および当該条件に対応づけてルール格納手段に格納されている当該条件に応じたメッセージを出力する。
(もっと読む)
情報処理装置、自然言語解析方法、プログラムおよび記録媒体
【課題】 係り受け構造を有する照会パターンに対する文のマッチング・スコアを演算すること。
【解決手段】 本発明の情報処理装置100は、解析対象の文150と、照会パターン160と、上記文内の言語単位間の係り易さを指標する指標値170とを入力として取得する入力部110と、文が照会パターンにマッチする程度を指標するマッチングのスコアを、上記照会パターン160に含まれる各係り受け関係が対応付けられる各指標値を少なくとも変数とする関数で表して演算するスコア演算部120とを含む。スコア演算部120は、上記照会パターンの部分構造と文の範囲との対応付けを試行して、上記関数の部分演算結果を、再利用するため記憶領域130に格納しながら、この部分構造および範囲の内部に関して再帰的に演算することによって、上記スコアを算出する。
(もっと読む)
翻訳装置、翻訳プログラムおよび翻訳方法
【課題】各翻訳部品を整合性のとれた自然な文に組み合わせること。
【解決手段】翻訳装置100は、翻訳対象となる文章を、複数の構造部品に分割し、各構造部品のパターンに対応する文法によって機械翻訳することで、複数の翻訳部品を作成する。そして、翻訳装置100は、翻訳部品の主要部を特定し、主要部を変数に置き換えた検索キーおよび主要部をそのままにした検索キーを作成する。翻訳装置100は、主要部を変数に置き換えた検索キーよりも、変数に置き換えていない検索キーのほうが優位になるように、検索キーに重みをつける。翻訳装置100は、各検索キーを利用して、コーパスデータ103dを検索し、ヒット数と検索キーの重みに基づいて、翻訳候補を評価する。
(もっと読む)
翻訳装置、および翻訳方法
【課題】複数の機械翻訳システムの翻訳結果から精度の高い翻訳結果を得られなかった。
【解決手段】2以上の機械翻訳システムの2以上の翻訳結果を構文解析し、2以上の構文解析木を取得する構文解析部と、2以上の構文解析木からルールの集合を取得するルール取得部と、トップノードが共通するルールのトップノードを共通化して構文森を構成する構文森構成部と、構文森において、トップノードが共通であるルールに対して、スコアを算出するスコア算出部と、トップノードが共通であるルールのうち、スコア算出部が算出したスコアが最も高い一のルールに対応するサブツリーを選択し構文解析木を取得するルール選択部と、構文解析木から翻訳文を取得する翻訳文取得部と、翻訳文を出力する翻訳文出力部とを具備する翻訳装置により、複数の機械翻訳システムの翻訳結から精度の高い翻訳結果を得ることができる。
(もっと読む)
係り受け解析支援装置
【課題】 長文の係り受けを人手のインタラクションによって正確に効率的に決定するための係り受け解析支援装置を提供する。
【構成】 文を句読点によって分割し、分割された部分に対して形態素解析および構文解析を行い、各部分の係り受け解析結果を目視確認し、間違っているところがあれば、予め用意している規則集合から別の係り受け規則を選択することを繰り返し、正しい係り受け解析を行い、各部分の係り受け解析を終了すると、分割された部分間の係り受け解析を行い、部分間の係り受け解析結果を目視確認し、間違っているところがあれば、予め用意している規則集合から別の係り受け規則を選択することを繰り返し、正しい部分間の係り受け解析を行うことが出来る係り受け解析支援装置。
(もっと読む)
機械翻訳装置、および機械翻訳方法
【課題】従来、精度の高い機械翻訳ができなかった。
【解決手段】係り受け森を構成する各頂点に対して、1以上の各翻訳規則を適用し、頂点ごとに、合致する1以上の翻訳規則を取得する翻訳規則取得部と、係り受け森を構成する各頂点をヘッドとした1以上の超辺であり、各頂点に対応する1以上の翻訳規則の左辺における変数部分に対応する頂点をテイルとした1以上の超辺を取得する超辺取得部と、係り受け森を構成する全頂点と、超辺取得部が取得した1以上の超辺とを有する翻訳森を取得する翻訳森取得部と、翻訳森の各頂点に対応する1以上の各超辺が有する翻訳規則の右辺と単語辞書とを用いて、1以上の翻訳候補を取得する翻訳候補取得部と、1以上の翻訳候補のうちいずれか1以上の翻訳候補である翻訳結果を出力する出力部とを具備する機械翻訳装置により、精度の高い機械翻訳が可能となる。
(もっと読む)
基本木獲得装置、構文解析装置、方法、及びプログラム
【課題】メモリの消費量を抑制しつつ、あらゆる言語の構文木コーパスに対応する。
【解決手段】ラベル付与部15で、基本木e(u)の情報に基づいて、接合操作に関する内容を含む木接合文法に従った非終端ノードの内容を示すラベルを、構文木各々の各非終端ノードに付与し、構文木分解部16で、ラベルが付与された構文木を、深さ1の部分木に分解すると共に、ラベルの内容及び推定する確率モデルに基づいて各部分木の生成確率を計算する。内側確率計算部18で、部分木の生成確率に基づいて、非終端ノード毎に内側確率を計算し、基本木サンプリング部20で、非終端ノード毎の内側確率に基づいて、新たな基本木を生成し、全ての葉ノードが終端ノードとなるまで新たな基本木の生成を繰り返し、構文木が観測された下での基本木の事後確率が最大となるときの基本木、及び確率モデルのパラメータを獲得する。
(もっと読む)
敬語誤用判定プログラム、及び敬語誤用判定装置
【課題】入力された日本語の発話文に対し、敬語の誤用の有無を柔軟に判定できるプログラム及び装置を提供する。
【解決手段】発話文テキスト、発話文に関わる人物と人物間の社会的関係を示す人間関係ラベル、難易度の入力を受け付け、発話文テキストに対する形態素解析や構文解析を行い、発話文中の主語及び補語、文末表現、述語について敬語特徴量として数値化するとともに、発話文に関わる人数に依らず汎化した規範ルールを参照して発話文中の主語及び補語と人間関係ラベルに該当する規範ルールを特定し、各規範ルールについて現代の一般の人々の敬語規範意識に基づく正誤の妥当性を数値化した妥当性の程度の値と難易度とを比較することで、判定に用いるべき規範ルールを定め、その規範ルールで正しいとされる敬語特徴量と発話文テキストに用いられた敬語特徴量とを対比することで、発話文テキスト中の敬語の正誤判定を実行できるようにした。
(もっと読む)
言語変換装置、言語変換方法及び言語変換プログラム
【課題】トレーサビリティマトリクスを容易に作成すること。
【解決手段】抽出部は、文字ファイルに含まれる文字列を相互の関連性に従って解析することで求めた文字ファイルの木構造において、各ノードに配置された文字列から第1の言語で示された所定の文字列群である第1文字列群と第2の言語で示された所定の文字列群である第2文字列群とをそれぞれ抽出する。配置状態算出部は、第1文字列群及び第2文字列群に含まれる文字列それぞれについて、木構造における配置状態から文字列相互の影響度を算出する。類似度算出部は、影響度に基づいて、第1文字列群に含まれる第1文字列に対する第2文字列群に含まれる第2文字列の関連性の高低を示す類似度をそれぞれ算出する。変換部は、文字ファイルにおける第1文字列を類似度が最も高い第2文字列に変換する。
(もっと読む)
1 - 20 / 258
[ Back to top ]