
Fターム[5B091CA06]の内容
Fターム[5B091CA06]に分類される特許
1 - 10 / 10
情報処理装置及びプログラム
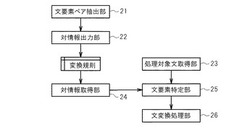
【課題】意味内容は対応するが係り受け構造は異なる別の文への言い換えを実現するための情報処理装置を提供する。
【解決手段】互いに対応する意味を持つ2つの文から、互いに対応する文要素の組であって、一方は動詞を含み、他方は付属語を含む文要素の組を抽出し、抽出される文要素の組に基づいて、言い換え可能な動詞と付属語の対情報を出力する情報処理装置である。
(もっと読む)
情報処理装置、情報処理方法、及びプログラム

【課題】機械翻訳や、異なる言語間を横断する情報検索などで行われる訳語選択処理において、訳質の向上を図り得る、情報処理装置、情報処理方法、及びプログラムを提供する。
【解決手段】第一言語の語に対応する第二言語の訳語を選択する情報処理装置100であって、情報処理装置100は、第一言語の入力文の形態素情報に基づいて形態素の係り受け関係を解析する係り受け解析部101と、対訳辞書105を用いて、解析された係り受け関係を有する、対象語彙の第二言語の訳語候補を取得する訳語候補取得部102と、取得された訳語候補における字数又は音節数を計算する計算部103と、入力文の内容に応じて、計算部103によって計算された値に基づき、第二言語における、係り側の語彙の字数又は音節数と受け側の語彙の字数又は音節数との組み合わせの優先順位を規定する規則を用いて、訳語候補の中から訳語を選択する訳語選択部104とを備えている。
(もっと読む)
言語解析システム、言語解析方法、プログラム及び機械翻訳システム、言語解析方法、プログラム
【課題】格フレーム情報を取得したいドメインのコーパスが少量しか存在しなくても、その目的のドメインに適した格フレーム情報を取得可能とし、そのドメインに対する解析精度を向上させる。
【解決手段】目的のドメインの少量のコーパスと目的のドメインとは異なるドメインの大量のコーパスの係り受け情報を作成し、この複数のドメインのコーパスから取得した係り受け情報を使って補語をクラスタリングし、このクラスタリングした係り受け情報の目的ドメインの情報のみを使って格フレームの選択制約を作成し、この選択制約に基づいて解析する。
(もっと読む)
言語モデル作成装置および言語モデル作成方法
【課題】より有効な未知語の言語モデルを作成することができる言語モデル作成装置および言語モデル作成方法を提供する。
【解決手段】言語モデル作成装置は、対象単語の前に隣接する単語と対象単語の後ろに隣接する単語の両方または片方を含む隣接単語と、対象単語とを含む単語列の単語情報を抽出する単語列抽出手段と、単語列抽出手段により抽出された単語列の単語情報に基づいて、言語モデル保持部から、単語列の単語情報を含むモデルを抽出するモデル抽出手段と、モデル抽出手段により抽出されたモデルから、対象単語に対応するモデルを作成するモデル作成手段と、を具備する。
(もっと読む)
言語処理装置、言語処理方法および言語処理プログラム並びに言語処理プログラムを記録した記録媒体
【課題】適切な変換ルールが記述された格変換ルールを用いて必須表層格を得る。
【解決手段】述語または動作性名詞おそれ以外の単語または単語属性間の係り受け状態を述語または動作性名詞とそれ以外の単語との格関係へ変換する規則を記憶した格変換規則テーブル2を設け、テキストの係り受け状態および格変換規則テーブル2の規則を用いて、格変換部3にて入力されたテキストを述語および動作性名詞の項構造に変換して出力する。
(もっと読む)
自然言語解析装置、自然言語解析方法および自然言語解析プログラム
【課題】単一の処理モジュールで文節にまとめ上げる処理と係り受け解析処理とを同時に行うことができ、文のスキャンを一度で済むようにして処理を速める。
【解決手段】文節に区切ることが可能で、文節間の係り受け関係が存在する自然言語文を解析する自然言語解析装置であって、解析対象の文を形態素に分解する形態素解析手段と、形態素列の各単語間の依存関係を決定してくことで、文節のまとめ上げと係り受け解析とを行う文節まとめ上げ係り受け解析手段とを備え、前記文節まとめ上げ係り受け解析手段は、前記解析対象の文末まで前記文節のまとめ上げを行う過程で、文節の先頭の検出を行いながら依存先が未確定の単語をスタックしていき、依存関係の判定により文節の区切りが決定した後に、スタックに蓄積された単語の依存関係の決定を行って文節間の係り受けを決定する。
(もっと読む)
テキストから因果関係を自動発見するための統語パターン学習
【課題】収集されたテキストから自動的に因果関係を抽出する。
【解決手段】本発明は、テキストデータ中の単語間の関係を抽出する方法を提供する。
最初に、因果関係を記述する三連単語のような訓練関係データが、訓練関係データを含む追加テキストデータを収集するために、受け付けられ使用される。訓練データを受け付け、追加テキストデータを収集するために、分散データコレクションが使用される。これにより、多くのソースから広範囲のデータを入手し得る。統語パターンが追加テキストデータから抽出され、抽出された統語パターンを使用して、1又は複数の因果関係を記述する追加関係データを抽出するために、分散データソースが走査される。抽出された追加関係データは格納される前に教師付学習アルゴリズムによって有効化され、分類部が追加関係データを自動的に有効化するのを訓練するために使用される。
(もっと読む)
テキストマイニング装置、テキストマイニング方法、テキストマイニングプログラム
【課題】依存構造木が異なる同義表現を同一視してマイニングを行うことができるテキストマイニング装置等を提供すること
【解決手段】テキストマイニング装置10では、言語解析手段21が同義表現辞書に登録されている表現の依存構造木(同義表現依存構造木)とテキストマイニングの対象となる文の依存構造木(対象文依存構造木)を生成する。同義表現識別手段22は、対象文依存構造木の中に同義表現部分木と一致する部分木(一致部分木)が含まれているかどうかを識別する。節点置換手段は24、一致部分木を同義表現が属するグループを示す特別な節点(同義表現節点)で置き換え、特徴部分木抽出手段25は、置き換え後の対象文依存構造木から特徴部分木を抽出する。
(もっと読む)
自然言語解析装置、自然言語解析方法、及び、自然言語解析プログラム
【課題】入力文に含まれる語や句の意味的な対応関係を自動的に解釈することを課題とする。
【解決手段】自然言語の意味を特定するために所定形式で構成された複数の意味表現に関し、これら複数の意味表現の意味的対応関係を解析する自然言語解析装置1であって、所定手段にて生成された複数の意味表現のうち、相互に意味的対応関係を持ち得る複数の意味表現を特定する対応意味表現特定手段と、前記対応意味表現特定手段にて特定された前記複数の意味表現の各々に含まれる属性表現の中から、相互に意味的な対応関係を持ち得る複数の属性表現を特定する対応属性表現特定手段と、前記対応属性表現特定手段にて特定された前記複数の属性表現の各々に含まれる情報を相互に対比し、この対比の結果に基づく所定の処理を行う属性表現処理手段とを備える。
(もっと読む)
自然言語解析装置及び方法、自然言語解析プログラム
【課題】内包する構文木を個々に評価することなく一括して係り受け解析を施すことが可能な構造を有した統語森を生成する自然言語解析装置及び同装置による係り受け解析方法を提供すること。
【解決手段】入力形態素列を構文解析することにより、複数の構文木を内包する統語森を生成する自然言語解析装置であって、文法規則を記憶する第1のメモリを具備し、前記文法規則に基づいて、前記入力形態素列から主辞及び前記主辞が支配する部分構造に相当する主辞支配域を検出する検出手段を具備する。また、検出手段により検出された主辞支配域を有する主辞構造付統語森を生成する構文解析手段を具備する。
(もっと読む)
1 - 10 / 10
[ Back to top ]