
Fターム[5B091CA24]の内容
Fターム[5B091CA24]に分類される特許
1 - 20 / 43
文書処理装置およびプログラム
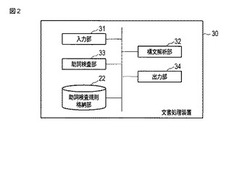
【課題】助詞「は」を含む文を検出し、当該文の修正を促すことが可能な文書処理装置およびプログラムを提供することにある。
【解決手段】入力手段は、自立語および助詞「は」を含む第1の文節と第1の文節を係り受け元とする第2の文節とを含む複数の文節から構成される文を入力する。構文解析手段は、入力された文を構文解析し、当該文を構成する文節間の係り受け関係を含む構文解析結果を取得する。抽出手段は、入力された文を構成する第1の文節と第2の文節との間の係り受け関係を、構文解析結果から抽出する。メッセージ生成手段は、抽出された係り受け関係に応じた入力された文に対する指摘事項を含むメッセージを、当該係り受け関係に対応づけて格納手段に格納されているメッセージ生成情報に基づいて生成する。出力手段は、生成されたメッセージを出力する。
(もっと読む)
文変換装置およびそのプログラム

【課題】大量の文例によることなく、入力される文の文法構造を利用して、平易な文に変換することのできる文変換装置を提供する。
【解決手段】係り受け解析部は、文データを入力し前記文データの係り受け関係を解析し係り受け構造データを出力する。修飾句認定部は、係り受け構造データに基づき文データに含まれる修飾句を抽出するとともに、属性認定用辞書を参照することによって、抽出された修飾句ごとの属性を認定する。対象修飾句判定部は、修飾句認定部によって認定された属性に基づいて、修飾句が変換対象の修飾句か否かを判定する。長さ判定部は、修飾句の長さに応じて変換対象とするか否かを判定する。文変換部は、文変換規則記憶部から読み出した文変換規則に基づいて、変換対象と判定された修飾句を文に変換して出力する。文短縮部は、変換対象とした修飾句に対応して元の文データを短縮する。
(もっと読む)
機械翻訳装置、機械翻訳方法および機械翻訳プログラム
【課題】原言語文の多様性に対応することができる機械翻訳装置を低コストで開発することである。
【解決手段】本実施形態の機械翻訳装置は、第1言語による原言語文を第2言語による目的言語文に翻訳する機械翻訳装置であって、原言語文変換手段と翻訳手段と命題文変換手段とを備える。原言語文変換手段は、第1言語による原言語文から表現素性を抽出し、前記原言語文を、前記表現素性を含まない原言語命題文に変換する。翻訳手段は、前記原言語命題文を前記第2言語による目的言語命題文に翻訳する。命題文変換手段は、前記表現素性に基づいて、前記目的言語命題文を第2言語による目的言語文に変換する。
(もっと読む)
構文解析情報作成装置、翻訳装置、翻訳システム、構文解析情報作成方法およびコンピュータプログラム
【課題】 文字認識処理および翻訳処理の高精度化を図りつつ、文字を認識する速度の向上を図る。
【解決手段】 構文解析情報作成装置は、情報作成部1を備える。情報作成部1は、文法制約条件を示す第1構文解析情報(例えば、翻訳用の構文解析情報)から、解析対象の単語候補に対応する文法情報を抽出し、当該抽出した文法情報に基づいて、前記単語候補に対応する文法制約条件を示す第2構文解析情報(例えば、文字認識用の構文解析情報)を作成する。
(もっと読む)
機械翻訳装置、方法及びプログラム
【課題】第1言語の文書の原文が構文解析に失敗した場合でも、ユーザに負担を課すことなく読みやすい訳文を生成できるとともに、開発者による機械翻訳のチューニングの効率化や省力化を図ることである。
【解決手段】文書解析手段30は、第1言語で表現された文書の各原文を構文解析する。訳文生成手段33は、文書解析手段30で構文解析に成功したときは原文の訳文を生成する。第1言語単語除去手段34は、文書解析手段30で構文解析に失敗したときは原文から1単語を除去した単語列を作成する。また、文書解析手段30は、第1言語単語除去手段34で得られた1単語を除去した単語列を構文解析し、訳文生成手段33は、1単語を除去した単語列の構文解析に成功したときはその単語列の訳文を生成し、1単語を除去した単語列の構文解析に失敗したときは原文の不完全な訳文を生成する。
(もっと読む)
電子機器
【課題】入力した文章を有効に活用することができる電子機器を提供することにある。
【解決手段】文章を入力可能な入力部と、文章中の単語を所定の規則に基づいて項目ごとに分類する解析部と、単語が分類された項目の種類を当該単語と共に記憶する記憶部と、文章を翻訳する翻訳アプリケーションを実行する制御部と、を備え、制御部は、入力部により入力された文章を翻訳アプリケーションにより翻訳する際に、文章中の単語ごとに翻訳し、翻訳される言語における項目の配列規則に従って翻訳された単語を並び変えることで上記課題を解決する。
(もっと読む)
同一意図テキスト生成装置、意図推定装置および同一意図テキスト生成方法
【課題】異なる意図を示すテキストから新たなテキストを生成する。
【解決手段】テキスト解析部1はテキスト解析用辞書2を用いてテキストを形態素列にし、一致/差分テキスト抽出部3は意図の関係性に従って階層化した意図階層データ4を用いて、上位下位関係または同位の兄弟関係にある意図を抽出してこれら意図に対応付いたテキストから一致部分および不一致部分を抽出し、意図一致テキスト生成部6が一致部分および不一致部分を用いて、上位下位関係のいずれか一方の意図または兄弟関係のいずれか一方の意図を示す新たなテキストを生成する。
(もっと読む)
機械翻訳装置、方法およびプログラム
【課題】翻訳結果を得るまでの時間を短縮できるとともに、信頼度の高い機械翻訳結果を得ることができる機械翻訳装置を提供する。
【解決手段】言い換え文生成手段81は、入力されたテキスト文と同一の言語でそのテキスト文の内容を示す別の表現へ言い換えた1つまたは複数の言い換え文を生成する。機械翻訳手段82は、言い換え文を翻訳後の言語である目的言語へと機械翻訳する。翻訳信頼度決定手段83は、目的言語へ翻訳された言い換え文の信頼度を示す翻訳信頼度を決定する。言い換え文特定手段84は、言い換え文生成手段81が生成した言い換え文の中から、翻訳信頼度に基づいて言い換え文の候補を抽出し、候補の中から翻訳の対象とする言い換え文である翻訳対象言い換え文を特定する。
(もっと読む)
文章生成装置及び文章生成方法
【課題】文章の作成を適切に支援する技術を提供する。
【解決手段】文章生成装置10は、文の一部に取替部分を有するテンプレートを格納した管理テーブル60と、取替部分に代入すべき文字列をユーザから受け付ける際に、代入すべき文字列の内容を問う質問をユーザに提示する質問提示部42と、ユーザから受け付けた文字列を取替部分に代入したときに文の意味が通るようにするために、テンプレートにおける取替部分の前後の文脈に応じて、代入すべき文字列を入力するための領域の直前及び直後に直前文字列及び直後文字列をそれぞれ提示する前後文字列提示部44と、入力された文字列を取得して記録する記録部46とを備える。
(もっと読む)
文章学習用ブロックおよび言語学習プログラムを格納するコンピュータで読み取り可能な記録媒体
【課題】文章を構成する各単語をブロックでイメージ化して結合する方式によって特定言語の構造を覚えさせる言語学習プログラムを格納するコンピュータで読み取り可能な記録媒体と文章学習用ブロックが提供される。
【解決手段】一実施形態の言語学習プログラムは、複数の単語(vocabulary)ブロックを格納する単語ブロックデータベースおよび前記複数の単語ブロックのうちから主語(subject)ブロック、動詞(verb)ブロック、および目的語(objective)ブロックが選択される段階と、前記動詞ブロックと前記主語ブロックが結合可能なペアであれば2つのブロックを並べて結合する段階と、前記結合したブロックの動詞ブロックの部分と前記目的語ブロックが結合可能なペアであれば2つのブロックを並べて結合して全体的に1つの文章を完成する段階とを実行するユーザインターフェースモジュールを含む。
(もっと読む)
機械翻訳装置、機械翻訳方法、およびプログラム
【課題】高精度な翻訳文を得ることができなかった。
【解決手段】元フレーズとパラフレーズとパラフレーズ確率を有するパラフレーズ情報と、原言語フレーズと目的言語フレーズとフレーズ翻訳確率を有するフレーズ翻訳情報を格納しており、原文を受け付ける受付部と、原文をフレーズに分割する分割部と、1以上の各元フレーズと対になるパラフレーズを取得するパラフレーズ取得部と、1以上のフレーズと1以上のパラフレーズを用いてパラフレーズラティスを取得するパラフレーズラティス取得部と、フレーズの1以上の素性、原文と各パラフレーズ文の1以上の素性、目的言語文の1以上の素性のうちの1以上の素性を取得する素性取得部と、1以上の素性を用いて各文のスコアを算出するスコア算出部と、最大のスコアに対応する目的言語文を取得する翻訳部と、目的言語文を出力する出力部とを具備する機械翻訳装置である。
(もっと読む)
語順変換装置、機械翻訳用統計モデル作成装置、機械翻訳装置、語順変換方法、機械翻訳用統計モデル作成方法、機械翻訳方法、プログラム
【課題】非主辞後置型言語である原言語(例えば英語)の文の単語について、構文解析結果を用いて、主辞後置型言語の目的言語(例えば日本語)の語順に並び替えることを課題とする。
【解決手段】非主辞後置型言語である原言語の文の単語を、主辞後置型言語である目的言語の語順に並び替える語順変換装置100である。処理部101は、原言語の文について、その構造木のルートノードから始めてすべてのノードについて、その子ノードのうち、語順を変えるべきでないノード以外のノードに対して、主辞ノードを最後の位置に移動する処理を繰り返すことで、原言語の文の単語を目的言語の語順に並び替える。
(もっと読む)
情報処理装置、訳文接続方法、およびプログラム
【課題】対訳テンプレートを用いて生成した複数の文を用いて文章を作成可能な翻訳装置を提供する。
【解決手段】翻訳装置1は、第1言語による第1原文を翻訳することにより得られる第2言語による第1訳文と、第1言語による第2原文を翻訳することにより得られる第2言語による第2訳文とを出力部11に表示させる表示制御部25と、入力部10を介して、第1訳文と第2訳文とを接続するための第1指示、および当該接続の態様を指定する第2指示を受け付ける受付部31と、第1指示および第2指示に基づいて、第1訳文と第2訳文とを接続する接続部33とを備える。表示制御部25は、接続後の文章を出力部11に表示させる。
(もっと読む)
文書処理装置およびプログラム
【課題】言い換え生成規則の作成にかかっていたコストを削減することを可能とする。
【解決手段】解析部32は、入力文、言い換え前用例および言い換え後用例を解析することによって、解析済み入力文、解析済み言い換え前用例および解析済み言い換え後用例を作成する。類似用例選択部33は、解析済み入力文および解析済み言い換え前用例の類似度を算出する。類似用例選択部33は、算出された類似度に基づいて、解析済み言い換え前用例および解析済み言い換え後用例を解析済み類似用例ペアとして選択する。差分抽出部34は、解析済み類似用例ペアとして選択された解析済み言い換え前用例および解析済み言い換え後用例の差分を抽出する。言い換え生成部35は、解析済み入力文に、差分抽出部34によって抽出された差分を適用することによって、入力文が言い換えられた言い換え文を生成する。出力部36は、入力文の言い換え文を出力する。
(もっと読む)
情報処理装置及びプログラム
【課題】意味内容は対応するが係り受け構造は異なる別の文への言い換えを実現するための情報処理装置を提供する。
【解決手段】互いに対応する意味を持つ2つの文から、互いに対応する文要素の組であって、一方は動詞を含み、他方は付属語を含む文要素の組を抽出し、抽出される文要素の組に基づいて、言い換え可能な動詞と付属語の対情報を出力する情報処理装置である。
(もっと読む)
機械翻訳装置、機械翻訳方法、およびプログラム
【課題】翻訳規則として記述しにくいまたは記述しきれない文法現象に対する正確な翻訳規則を必要とすることなく、機械翻訳を行う。
【解決手段】翻訳規則として記述しにくいまたは記述しきれない文法現象を持つ語彙を、特定パターンとして予め特定パターンDB103に登録しておき、この特定パターンが第1言語の入力文に含まれていた場合には、当該特定パターンの解析結果と対応する第2言語の語彙または構文情報を翻訳DB108から取得し、この第2言語の語彙または構文情報と第2言語統計的モデル104に格納されている統計的共起情報とを用いて、誤り検出・校正部107により、第1言語を翻訳して得られた第2言語翻訳文の誤りを検出し、当該第2言語翻訳文を校正する。
(もっと読む)
対訳情報作成装置、機械翻訳装置及びプログラム
【課題】対訳データベースを用いて翻訳する場合に対訳ペアの使用される状況が翻訳対象文とそぐわない翻訳を回避することである。
【解決手段】文分割部24は、入力処理部23を介して記憶装置22に記憶された対訳文書のデータの第一言語の原文文書及び第二言語の訳文文書についてそれぞれ文単位に分割し、文対応付け部27は、文単位に分割された原文と訳文とを対応付けて対訳ペアとし、その対訳ペアに対して、原文・訳文対応関係解析部28は原文と訳文とを構成する語の対応関係を解析し、訳文中付加情報検出部29は対訳ペアにおいて訳文中に存在し原文中に存在しない付加情報の有無を検出し、置き換え訳文生成部30は、この付加情報の存在が検出された訳文の該当部分を対応する原文に忠実な訳語で置き換えた追加訳文を生成し対訳ペアとして対訳データベースに記憶する。
(もっと読む)
文短縮装置、その方法およびプログラム
【課題】原文の内容を維持したまま、自然で読み易い要約文を生成すること。
【解決手段】文侯補生成部6が、文入力部5で受け付けた、形態素解析および係り受け解析済みの入力文の依存構造に基づいて当該入力文を構成する文節を組み合わせて要約文の候補を生成し、コーパスから得られる任意の単語の重要度を格納する単語重要度テーブル1、コーパスから得られる任意の文節間の連接確率を格納する文節連接テーブル2、文節情報取得部3および文情報計算部4を用いて、各候補の長さおよび生成確率を求めて文候補テーブル7に格納し、制御部8が、文候補テーブル7から予め指定された長さの範囲で最も生成確率が高い要約文の候補を出力する。
(もっと読む)
機械翻訳システム及び機械翻訳プログラム
【課題】翻訳速度の高速化が可能で、しかも精度の高い翻訳結果を得ることができる機械翻訳システムを提供することである。
【解決手段】原文分割部29は入力装置20から入力された第一言語の原文を特定の単位で分割し、翻訳部30は辞書部34の情報を使って原文分割部29で得られた複数の分割原文を並列して翻訳するとともに、原文翻訳の過程で判断される翻訳情報のうち一つに特定できた翻訳情報を翻訳情報蓄積部32に蓄積する。そして、訳文結合部31は翻訳部30で翻訳された分割原文の分割訳文を結合する際に、分割訳文の中に翻訳部30で一つに特定できなかった翻訳情報がある場合には、翻訳情報蓄積部32に蓄積された翻訳情報に一致するように翻訳結果の訳語の置き換えを行い、翻訳部30で翻訳された分割訳文を結合する。
(もっと読む)
機械翻訳装置及び機械翻訳プログラム
【課題】第一言語文と翻訳非対象文とが混在する文書を翻訳する際に、翻訳非対象の文章から訳語決定に左右する情報を抽出して翻訳に利用し、適切な第二言語の訳語を得ることである。
【解決手段】第二言語文解析処理部27は、第一言語と第二言語とが混在した文書データのうち第二言語の文章データを解析して予め定めた品詞の語句を抽出し第二言語文抽出語句データベース28に抽出語句として格納する。第一言語の語句の訳語候補となる第二言語の語句が翻訳辞書部31に複数存在した場合に、訳語選択処理部35は、第二言語文抽出語句データベース28に格納された抽出語句と第二言語用機械翻訳知識データベース38の共起情報又は分野情報に基づいて第一言語の語句の訳語候補を一つの第二言語の語句に絞り込み選択する。そして、訳文生成処理部32により訳文を生成し、出力処理部34を介して表示装置に出力する。
(もっと読む)
1 - 20 / 43
[ Back to top ]