
Fターム[5D015AA03]の内容
Fターム[5D015AA03]に分類される特許
1 - 20 / 293
音声調整装置およびデジタル放送受信装置
議事録作成システム、議事録作成装置、議事録作成プログラム、議事録作成端末及び議事録作成端末プログラム
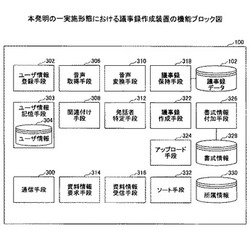
【課題】会議の議事録に記録された発話内容が、どの資料に関連するものであるのかが分かるようにすることを目的とする。
【解決手段】議事録作成装置は、ユーザが発話した場合に、当該発話したユーザが用いる情報端末に資料の情報を要求する資料情報要求手段と、前記ユーザの発話内容と前記資料の情報とを関連付けた議事録を作成する議事録作成手段と、を有し、前記情報端末は、前記資料情報要求手段からの要求を受けつける資料情報要求受付手段と、前記資料情報要求受付手段が前記要求を受け付けた場合に当該端末が表示中の前記資料の情報を取得する資料情報取得手段と、取得された前記資料の情報を前記議事録作成装置に送信する資料情報送信手段と、を有する、議事録作成システムを提供する。
(もっと読む)
情報処理装置、および情報処理方法、並びにプログラム

【課題】不確実で非同期な入力情報に基づく情報解析により、ユーザ位置や識別情報、発話者情報などを生成する構成を実現する。
【解決手段】画像情報や音声情報に基づいてユーザの推定位置および推定識別データを含むイベント情報を入力し、入力イベント情報に基づいて、各ユーザの位置およびユーザ識別情報を含むターゲット情報と、イベント発生源の確率値を示すシグナル情報を生成する情報統合処理部を有し、情報統合処理部は、発話源確率算出部を有し、発話源確率算出部は、各ターゲットの発話源確率を示す指標値としての発話源スコアを、イベント検出部から入力する複数の異なる情報に対して発話状況に応じた重みを乗算して算出する処理を行う。
(もっと読む)
男女声識別方法、男女声識別装置及びプログラム
【課題】入力された音声信号の時間長が非常に短い場合であっても、音声信号の話者の性別を正確に識別することができるようにする。
【解決手段】入力された音声信号から音声特徴量を抽出し、その音声特徴量を男声音響モデル及び女声音響モデルと照合した尤度に基づいて音声信号の話者の性別を識別する男女声識別方法において、音声信号の時間長が所定の時間長L未満の場合、音声信号を時間長L以上となるまで繰り返して伸長させ、その伸長させた音声信号を用いて音声特徴量の抽出を行い、前記繰り返しに対応した認識文法を用いて前記照合及び識別を行う。
(もっと読む)
位置出力装置、位置出力システムおよびプログラム
【課題】音声を発生する話者の三次元位置を、より良好に把握することができる位置出力装置等を提供する。
【解決手段】装着者の口からの距離が互いに異なる2つと水平方向の距離が離れた2つを含み話者の音声を取得する少なくとも3個以上設けられるマイクロフォン11a,11b,11cと、装着者の口からの距離が互いに異なる2つのマイクロフォン11a、マイクロフォン11cで取得される音声の音圧差に基づいて、話者が装着者か他者かを識別する識別手段と、識別手段によって話者が他者と識別された場合に、話者の三次元位置を導出するための数値計算の初期値を選択する初期値選択手段と、初期値選択手段により選択された初期値を用いた数値計算により話者の三次元位置を導出する位置導出手段と、を備えることを特徴とする端末装置10。
(もっと読む)
会議データの統合管理方法および装置
【課題】会議参加者のそれぞれの発言やその文書化データの管理を容易にし、会議データの利便性を向上させることが可能な統合管理方法および装置を提供する。
【解決手段】会議の参加者ごとに対応づけられた個別の音声チャネルに複数の参加者の発言を時間情報と共にそれぞれ格納したチャネル別音声データ格納部(207、208)と、音声チャネルごとに音声データの再生機能および音声データの時系列表示機能を含む複数機能から任意の機能を選択実行できる会議データ画面を操作可能に表示する制御部(201、212、213)と、を有する。
(もっと読む)
音声解析装置および音声解析システム
【課題】音声取得手段にて音声を取得し、取得した音声の非言語情報に基づいて話者を識別する。
【解決手段】端末装置は、使用者の口からの距離が相異なる位置となるように使用者に装着される第1マイクロフォン11および第2マイクロフォン12と、第1マイクロフォン11により取得された音声の音声信号と第2マイクロフォン12により取得された音声の音声信号との比較結果に基づき、第1マイクロフォン11および第2マイクロフォン12により取得された音声が第1マイクロフォン11および第2マイクロフォン12を装着した使用者の発話音声か、使用者以外の他者の発話音声かを識別する音声解析部と、を備える。ホスト装置は、複数の端末装置から発話者の識別結果を含む発話情報を取得して解析し、発話者間のコミュニケーションの傾向を表す情報を出力する。
(もっと読む)
音声認識装置、音声認識方法およびプログラム
【課題】音声認識の精度を向上させる。
【解決手段】音声認識装置は、番組情報記憶部と、辞書記憶部と、算出部と、更新部と、認識部と、操作制御部とを備える。番組情報記憶部は、放送番組のメタデータとユーザの視聴状態とを記憶する。辞書記憶部は、音声認識の対象となる認識語と優先度とを含む認識辞書を記憶する。算出部は、メタデータと視聴状態とに基づいて、放送番組の特徴語と特徴語に対するユーザの嗜好の度合いを表す第1スコアとを算出する。更新部は、特徴語を含む認識語の優先度を第1スコアに応じて更新する。認識部は、認識辞書を用いて音声を認識する。操作制御部は、認識結果に基づいて放送番組に対する操作を制御する。
(もっと読む)
話者クラスタリング方法、話者クラスタリング装置、プログラム
【課題】同一クラスタ内の話者間の知覚的類似度を高くできる話者クラスタリング方法を提供する。
【解決手段】N名の話者による同一内容の発話の音声データのうちk番目とj番目(1≦k,j≦N)の話者の発話の音声データの知覚的類似度の主観評価値をj番目の要素として有する話者ベクトルを生成する話者ベクトル生成サブステップと、話者ベクトルのベクトル間距離に基づいて、N名の話者をクラスタ数Mにクラスタリングするクラスタリングサブステップと、話者の属するクラスタ毎に当該話者の発話の音声データから選択用モデルを学習する選択用モデル学習サブステップと、任意の話者の音声データを入力とし当該入力された任意の話者の音声データと各クラスタの選択用モデルとの尤度を計算する尤度計算サブステップと、計算された尤度が最も高いクラスタを入力された音声データの話者が属するクラスタとして選択するクラスタ選択サブステップとを有する。
(もっと読む)
話者分類装置、話者分類方法および話者分類プログラム
【課題】発話に含まれる言語的な特徴を利用して、音響的な特徴による誤分類を検出する話者分類装置を提供することである。
【解決手段】実施形態の話者分類装置は、音響分類手段と、言語特徴抽出手段と、誤分類検出手段とを備える。音響分類手段は、入力された音響信号に含まれる発話を、前記音響信号から抽出した音響的な特徴を利用して話者毎に分類し分類結果を取得する。言語特徴抽出手段は、前記発話の内容を表す文字列を取得し、この文字列を利用して前記分類結果に含まれる話者の言語的な特徴を抽出する。誤分類検出手段は、前記発話の内容を表す文字列が、前記分類結果においてこの発話が分類された話者の前記言語的な特徴に適合するか否かを判別し、適合しない場合は、この発話は前記音響分類手段によって誤分類された発話であると判別する。
(もっと読む)
画像処理装置及びカメラ
【課題】 複数の人物に対してそれぞれが所望する画像を容易に分配することができる画像処理装置を提供する。
【解決手段】 集音された音声を入力する音声入力部22と、前記音声入力部から入力された音声の人物特定要素を抽出する音声処理部24と、特定の人物の声が有する固有のパターンを記録する音声記録部26と、前記人物特定要素と前記パターンとの特徴を比較することにより話者を特定する話者特定部4と、画像データを取得する画像取得部4と、前記画像データに基づく画像を出力する画像出力部20と、前記画像出力部により前記画像を出力している間に前記話者特定部により特定された前記話者を示す情報と前記画像データとを関連付けた分類データを作成する画像分類部4とを備える。
(もっと読む)
話者判別装置、話者判別プログラム及び話者判別方法
【課題】話者の判別を簡易かつ正確に行うことを課題とする。
【解決手段】話者判別装置50は、2人の話者に配置されるマイクから2つの音声データを取得する。さらに、話者判別装置50は、2つの音声データの各々をフレーム化する。さらに、話者判別装置50は、第1の確率モデルに基づいて、フレームが有声音領域又は無声音領域のいずれであるかを識別する。さらに、話者判別装置50は、有声音領域であると識別されたフレームの識別結果を有効又は無効とするかを決定する。このとき、話者判別装置50は、2つの音声データのエネルギー比を複数の確率分布が混合するモデルにモデル化した上でフレーム間のエネルギー比が複数の確率分布のうちいずれに属するかに応じて先の決定を行う。さらに、話者判別装置50は、第2の確率モデルに基づいて、有効又は無効が決定された後のフレームの識別結果から2つの音声データにおける発話領域及び沈黙領域を識別する。
(もっと読む)
撮像装置
【課題】撮影者が意図する対象に合焦された撮影画像を、容易に取得することができる撮像装置を提供する。
【解決手段】
光学系による画像を取得する画像取得部(13)と、前記画像に含まれる顔画像である第1顔画像(68)を認識する顔画像認識部(56)と、周囲環境の音声の特徴に関する第1音声情報(80)を取得する音声取得部(28)と、特定の顔画像の特徴に関する第2顔情報(72〜78)と、特定の音声の特徴に関する第2音声情報(82〜88)とを、予め互いに関連付けて記憶する記憶部(32)と、前記音声取得部で取得された前記第1音声情報と、前記記憶部に記憶された前記第2音声情報との類似性に基づき、前記第1音声情報と前記第2音声情報とを関連付ける音声判定部(54)と、前記音声判定部による関連付けの結果と、前記顔画像認識部による認識の結果とを用いて、前記光学系の合焦位置を制御する合焦位置制御部(52)と、を有する撮像装置。
(もっと読む)
情報処理システム
【課題】サーバーの処理負荷をより軽減させた情報処理システムを提供する。
【解決手段】被写体を撮像して画像データを取得する撮像部11を備えた端末10と、撮像部11による撮像により取得された画像データに基づいて被写体を識別するサーバー110とを備える情報処理システム1であって、端末10は、画像データに対して所定のフィルター処理を施すフィルター処理部14と、所定のフィルター処理が施された画像データをサーバー110に送信する通信部15と、を備え、サーバー110は、送信された画像データを受信する通信部111と、受信された画像データと被写体の識別のための照合用データとの照合の結果に基づいて被写体を識別する制御部112と、を備える。
(もっと読む)
情報処理システム
【課題】複数の人物のうち声を発した人物の識別の精度をより高める。
【解決手段】複数の端末10と、当該複数の端末10から送信された画像データ及び音声データを受信するサーバー110とを備える情報処理システム1であって、端末10は、被写体の顔を撮像して画像データを取得する撮像部11と、被写体の声を含む音声を取得して前記音声データを生成する音声取得部12と、画像データ及び音声データを送信する通信部15と、を備え、サーバー110は、複数の端末10の夫々から送信された画像データ及び音声データを受信する通信部111と、複数の画像データ及び複数の音声データに基づいて声を発した被写体を識別する制御部112と、を備える。
(もっと読む)
話者判別装置、話者判別プログラム及び話者判別方法
【課題】話者の判別を簡易かつ正確に行うことを課題とする。
【解決手段】話者判別装置50は、各々の話者に配置される複数のマイクから各々の音声データを取得する。さらに、話者判別装置50は、取得された音声データを所定の区間のフレームにフレーム化する。さらに、話者判別装置50は、第1の確率モデルに基づいて、フレームが有声音領域または無声音領域のいずれであるかを識別する。さらに、話者判別装置50は、各音声データにおける同一区間のフレームで有声音領域が重複して識別された場合に、当該同一区間で有声音領域と識別されたフレームのうち最大のエネルギーを持つフレームの識別結果を有効化する。さらに、話者判別装置50は、第2の確率モデルに基づいて、有効化された後のフレームの識別結果から各々の音声データにおける発話領域および沈黙領域を識別する。
(もっと読む)
話者分類装置、話者分類方法、プログラム
【課題】精度よく話者分類を行うことができる。
【解決手段】再抽出手段は、統合済みの音声区間セグメントを再分割し、再分割された音声区間サブセグメントの音響特徴量からサブセグメント代表特徴を抽出する。仮分類手段は、音声区間サブセグメントをサブクラスタに仮分類する。スコアリング手段は、クラスタ毎の各サブクラスタに属する音響特徴量から第1サブクラスタ代表特徴を抽出し、当該第1サブクラスタ代表特徴と同一のサブクラスタに属する音響特徴量との照合スコア平均を仮分類後スコアとし、サブクラスタ数を1としてクラスタ毎にサブクラスタに属する音響特徴量から第2サブクラスタ代表特徴を抽出し、当該第2サブクラスタ代表特徴と同一のサブクラスタに属する音響特徴量との照合スコアの平均を仮分類前スコアとする。再分類判定手段は、仮分類前後のスコア差分が再分類閾値を超える場合にサブクラスタへの仮分類結果に基づいて再分類判定する。
(もっと読む)
録音装置、録音装置の制御方法、および、プログラム
【課題】特定の話者の音声データが存在する区間における音データを記憶する。
【解決手段】本発明の録音装置は、周囲の音を集音し、音データとして出力する取得部と、前記取得部から出力された音データに音声データが含まれているか否かを判定し、前記音声データが含まれている場合には、声紋に応じて音声データを分類するとともに、分類した各音声データを示す分類情報を出力する話者解析部と、前記分類情報をユーザに通知する通知部と、前記分類情報の通知に基づく音声データの指定を受け取る入力部と、前記取得した音データから、前記指定された音声データが存在する区間における音データを抽出する録音制御部と、を有する。
(もっと読む)
メッセージ映像編集プログラムおよびメッセージ映像編集装置
【課題】ユーザが入力するメッセージテキストに合致する音声を再現した任意のメッセージ映像データの作成を容易に実現する。
【解決手段】映像データに付随し時刻毎に分割された音声データの発声内容を示すと共に前記映像データと前記発声内容とを対応付ける対応情報を格納する素材情報データベース17と、ユーザにより入力されたテキストデータを構成する最小単位のテキストデータにそれぞれ対応する発声内容の音声データおよび前記音声データに対応付けられた映像データを、対応情報に基づいて元映像データベース3から抽出する素材選択部23と、前記抽出した音声データおよび映像データを前記テキストデータの並び順に連結して音声データが付随した映像データの候補を提示する候補提示部25と、を備える。
(もっと読む)
音声をテキストに変換する装置及び方法
【課題】音声をテキストに変換する装置及び方法を提供することを目的とする。
【解決手段】音声受信モジュール、音声識別モジュール、表示モジュール、格納モジュール、話者識別モジュール及び制御モジュールを備え、格納モジュールは異なる音声データに対応するテキストデータ及び異なる音声信号に対応する話者データを格納し、音声受信モジュールは、外部の音声信号を受け取り、音声識別モジュールは、前記音声信号を音声データに変換してから、格納モジュールから前記音声データに対応するテキストデータを探して制御モジュールに送信し、話者識別モジュールは、格納モジュールから前記音声信号に対応する話者データを探して制御モジュールに送信し、制御モジュールは、前記テキストデータ及び前記話者データを表示モジュールに表示させる。
(もっと読む)
1 - 20 / 293
[ Back to top ]