
Fターム[5D015DD00]の内容
音声認識 (5,191) | 音声信号の検出 (328)
Fターム[5D015DD00]の下位に属するFターム
Fターム[5D015DD00]に分類される特許
1 - 9 / 9
音源位置推定装置、音源位置推定方法、及び音源位置推定プログラム
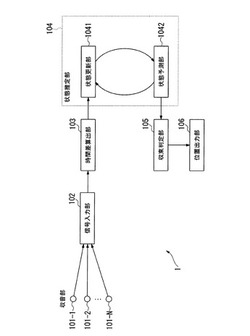
【課題】音声信号の入力と同時に音源位置を実時間で推定する。
【解決手段】信号入力部は複数のチャネルの音声信号を入力し、時間差算出部はチャネル間の音声信号の時間差を算出する時間差算出部と、状態予測部は音源位置を含む音源状態情報である過去の音源状態情報から現在の前記音源状態情報を予測し、状態更新部は前記時間差算出部が算出した時間差と前記状態予測部が予測した前記音源状態情報に基づく時間差との間の誤差を減少させるように前記音源状態情報を推定する。
(もっと読む)
出力オーディオ信号が生ずる間に入力音声信号を処理する方法および装置

【課題】入力音声信号を処理する方法および装置を提供すること。
入力音声信号の開始は、決定される(701)際の出力オーディオ信号に対する、出力オーディオ信号と入力開始時間との生成の間に検出される。入力開始時間は、次に、入力音声信号に応答するのに使用されるために提供される(704)。入力音声信号が、出力オーディオ信号が生ずる間に検出されるとき、出力オーディオ信号の識別は、入力音声信号に応答するのに使用されるために提供される。データおよび/または制御信号を備えている情報の信号(705)は、少なくとも提供されるコンテキスト上の情報、すなわち、入力開始時間および/または出力オーディオ信号の識別に応じて提供される。本発明は、基礎をなす通信システムの遅延特性にかかわらず、出力オーディオ信号に対する入力音声信号のコンテキストを精密に確立する。
(もっと読む)
保留関連発話抽出方法、装置及びプログラム
【課題】より適切に保留に関連する発話を抽出することができる技術を提供する。
【解決手段】
音声特徴量算出部2が、音声信号の音声特徴量を抽出する。音声認識部3が、音声特徴量、音響モデル及び言語モデルを用いて上記音声信号に対して音声認識を行い、音声信号に含まれる発話を検出し、検出された発話についての情報を生成する。保留区間検出部4が、発話についての情報を用いて、隣接する発話の間隔が所定の時間以上である保留区間を検出する。抽出部5が、保留区間に隣接する発話の集合から、保留区間が長いほど多くの数の発話を抽出する。
(もっと読む)
音源方向推定装置とその方法と、プログラム
【課題】音源方向の推定精度を高める。
【解決手段】この発明の音源方向推定装置は、正三角形の頂点に配置された3つのマイクロホンからなるマイクロホンアレーと、マイクロホンアレーの各マイクロホンで受信された信号を周波数領域の信号に変換する周波数変換部と、異なるマイクロホンのマイクロホン対の組み合わせのそれぞれに対して到達時間差を計算する到達時間差算出部と、到達時間差から音源候補を求め、音源方向候補を分類する音源方向推定部と、を具備する。音源方向推定部は、到達時間差の周波数ビン毎にスパース性が仮定できるか仮定できないかを判定するスパース性判定部を備え、スパース性が仮定できる周波数ビンの到達時間差から音源候補を求め、音源方向候補を分類する。
(もっと読む)
音処理装置およびプログラム
【課題】音声/非音声を高精度に判定する。
【解決手段】変調スペクトル特定部32は、複数の単位区間TUの各々について入力音VINの変調スペクトルMSを特定する。指標算定部34は、変調スペクトルMSのうち変調周波数が10Hz以下の強度L1に応じた指標値D1を算定する。記憶装置24は、母音の音声から生成された音響モデルMを記憶する。指標算定部54は、入力音VINと音響モデルMとの類否を示す指標値D2を単位区間TU毎に算定する。判定部42は、各単位区間TUの入力音VINが音声か非音声かを当該単位区間TUの指標値D1と指標値D2とに基づいて判定する。
(もっと読む)
音処理装置およびプログラム
【課題】音声/非音声を高精度に判定する。
【解決手段】変調スペクトル特定部32は、複数の単位区間TUの各々について入力音VINの変調スペクトルMSを特定する。指標算定部34は、変調スペクトルMSのうち変調周波数が10Hz以下の強度L1と変調周波数の全範囲にわたる強度L2とに応じた指標値D1(D1=1−(L1/L2))を算定する。判定部42は、指標値D1が閾値THd1を上回る単位区間TUの入力音VINを非音声と判定し、指標値D1が閾値THd1を下回る単位区間TUの入力音VINを音声と判定する。
(もっと読む)
音声処理装置、およびプログラム
【課題】従来の音声処理装置においては、音声の話者である評価対象者の話者特性に応じた音声処理(歌声評定など)が行えず、その結果、精度の高い音声処理ができない、という課題があった。
【解決手段】格納している第一サンプリング周波数で、受け付けた音声をサンプリングし、第一音声データを取得するサンプリング部と、前記音声受付部が受け付けた音声の話者である評価対象者のフォルマント周波数である評価対象者フォルマント周波数を格納しており、第二サンプリング周波数「前記第一サンプリング周波数/(教師データのフォルマント周波数/評価対象者フォルマント周波数)」で、前記受け付けた音声に対して、サンプリング処理を行い、第二音声データを得る声道長正規化処理部と、前記第二音声データを処理する音声処理部を具備する音声処理装置により、話者特性に応じた音声処理ができる。
(もっと読む)
音声情報処理装置及び方法
【課題】 音声配信と音声蓄積を実施する装置において、適切な無音処理を実行する。
【解決手段】 本発明に係る音声情報処理装置は、相手装置に配信するための音声データが有音、または無音かを判定する配信用無音判定手段と、前記音声データを記憶領域に蓄積するための音声データが有音、または無音かを判定する蓄積用無音判定手段と、前記配信用無音判定手段と前記蓄積用無音判定手段に、前記音声データが無音であると判定するために必要な条件を指定する無音判定条件設定手段とを備える。
(もっと読む)
撮像装置及びその制御方法
【課題】 動画中の選択されたフレーム画像と、音声認識された文字コードとは必ずしも一致したものにならず、ユーザが所望する動画の中のフレーム画像を選択するのは容易ではなかった。
【解決手段】 動画に含まれる音声を認識する音声認識部105と、音声認識部105により認識された音声の区切りを基に印刷候補のフレーム画像を選択する画像選択部107と、画像選択部107により選択されたフレーム画像108と、音声認識部105により認識された音声を示すテキスト画像110とを画像合成部111で合成して出力する。
(もっと読む)
1 - 9 / 9
[ Back to top ]