
Fターム[5D015DD02]の内容
Fターム[5D015DD02]に分類される特許
1 - 20 / 123
音声解析装置
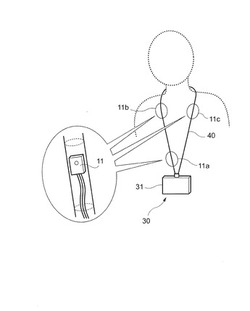
【課題】使用者に装着された音声取得手段にて音声を取得し、取得した音声の非言語情報に基づいて、使用者の顔の向きを検知する。
【解決手段】端末装置10は、使用者の口を挟んで対称な位置となるように装着される第2マイクロフォン11bおよび第3マイクロフォン11cと、これらとは使用者の口からの距離が異なる位置となるように装着される第1マイクロフォン11aと、第1マイクロフォン11aにより取得された音声の音声信号と第2マイクロフォン11bにより取得された音声の音声信号との比較結果に基づき、取得された音声が使用者の発話音声か、使用者以外の他者の発話音声かを識別し、使用者の顔の向きを検知する音声解析部と、を備える。
(もっと読む)
情報処理装置、情報処理方法及びプログラム

【課題】音声入力モードになったことをユーザに確実に報知する。
【解決手段】状態検出部と、タッチセンサと、マイクロフォンと、制御部とを有する情報処理装置が提供される。上記状態検出部は、当該情報処理装置の第1の状態変化を検出可能である。上記タッチセンサは、ユーザのタッチを検出可能である。上記マイクロフォンは、入力された上記ユーザの音声を音声信号に変換可能である。上記制御部は、上記音声信号を文字情報として認識する音声入力モードを実行可能である。また制御部は、上記第1の状態変化が検出された場合に、上記音声入力モードが準備状態であることを示す第1の画像を出力するための第1のコマンドを生成可能である。さらに制御部は、上記第1の状態変化に続いて上記タッチが検出された場合に、上記音声入力モードが実行可能な状態であることを示す第2の画像の出力するための第2のコマンドを生成可能である。
(もっと読む)
医療用実習システム
【課題】同時に複数の医療用実習装置を用いて医療実習を実施するための技術を提供する。
【解決手段】医療用実習システム100は、それぞれで歯科実習が実施される複数の医療用実習装置10を備えている。複数の医療用実習装置10のそれぞれは、擬似患者体2および診療台3を備えている。また、医療用実習システム100は、擬似患者体2の動作を制御する中央制御部90と、擬似患者体2の頭部模型2aの表情を変化させる擬似患者体駆動部2Aと、医療実習において、擬似患者体2の動作内容を示す情報が記述されている複数の医療用実習シナリオの中から、特定の医療用実習シナリオを選択するための表示部92(シナリオ選択部)とを備えており、中央制御部90は、選択された医療用実習シナリオを実行する。
(もっと読む)
音声選択装置並びにそれを使用したメディア機器およびハンズフリー通話装置
【課題】定められた車種専用ではなくあらゆる車種に対し汎用で取り付け可能であり、エアコンの風の吹き出し口がどのように配置されていても、エアコンの風の吹き出し雑音等の影響を低減することができる音声選択装置並びにそれを使用したメディア機器およびハンズフリー通話装置を提供する。
【解決手段】車両の運転者が音声コマンドによりメディア機器102,108,111を操作する場合に音声コマンドを受け取る内蔵マイク104,105,109,110,114,115は、メディア機器102,108,111の左上および中央下の2箇所に設置されている。メディア機器102,108,111に内蔵マイク104,105,109,110,114,115を複数設けてエアコンの風の吹き出し口からの雑音の影響を最も受けていない内蔵マイクを選択する。
(もっと読む)
音声誤検出判別装置、音声誤検出判別方法、およびプログラム
【課題】様々な雑音環境化において音声認識の精度を向上させることが可能な音声誤検出判別装置、音声誤検出判別システム、音声誤検出判別方法、およびプログラムを提供する。
【解決手段】入力信号取得部は、所定方向の音源からの音声を含む周囲音を複数のマイクによりそれぞれ収音した複数の音声信号を取得する。認識結果取得部は、音声信号に基づく音声認識を行った結果検出された、音声信号の音声区間を示す音声区間情報を含む認識結果を取得する。到来率算出部は、それぞれの複数の音声信号の単位時間毎の信号と所定方向とに基づき、単位時間における所定方向からの音声が周囲音に占める割合を示す音声到来率を算出する。誤り検出部は、認識結果と音声到来率とに基づき、音声区間情報が誤検出でないか否かを検出する。これにより、音声認識による音声区間の誤検出を判別できる。
(もっと読む)
音源推定方法及び音源推定装置
【課題】観測点で採取した音の音圧信号と映像信号とから音源を推定するとともに、推定された音源と観測点との距離をリアルタイムで算出する。
【解決手段】マイクロフォンM1〜M5とカメラとを備えた音・映像採取ユニットを第1の観測点P1に配置して音圧信号と映像信号とを採取し、マイクロフォンM6〜M9を備えた音採取ユニットを第2の観測点P2に配置して音圧信号を採取し、これらの音圧信号をA/D変換した音圧波形データを用いて推定した第1の観測点P1からみた音源方向の水平角θ1及び仰角φ1と第2の観測点P2からみた音源方向の水平角θ2とから第1の観測点P1と音源との距離Lを求めるとともに、第1の観測点P1で採取した映像信号をA/D変換した画像データと水平角θ1と仰角φ1とを用いて作成した画像中に音源の方向を示す図形が描画された音源推定用画像Gkと距離Lのデータとを表示画面に表示するようにした。
(もっと読む)
音声認識装置および音声認識方法
【課題】非定常騒音の混入に対して頑健な音声認識を行う。
【解決手段】体内に密閉装着され音声を収音する第1気導音マイク11と、体外に装着され音声を収音する第2気導音マイク21と、第1気導音マイク11が収音した音声から第1単語列を認識する第1デコーダ部16と、第1単語列を構成する各単語に対応する発話区間を抽出する第1単語区間抽出部19と、第1単語区間抽出部19が抽出した発話区間について第2気導音マイク21が収音した音声から第2単語列を認識する第2デコーダ部26と、第1単語列のうち騒音レベルが所定値以下の単語列を第2単語列に置き換える単語列置換部28とを備えた。
(もっと読む)
音声認識装置と認識方法
【構成】
複数個の無指向性信号を増幅器で増幅し、無指向性信号を駆動回路で組み合わせて、音源の方向への指向性の有る指向性信号を求め、前記指向性信号あるいは前記無指向性信号に対して発話の有無を検出し、指向性信号を音声認識部で音声認識する。モード切替部により、無指向性信号中あるいは指向性信号中のノイズレベルを繰り返し測定し、ノイズレベルが低い際に、無指向性信号を音声認識部で音声認識するようにモードを切り替える。
【効果】 ノイズが少ない際に、音声認識部への入力信号の質を向上できる。
(もっと読む)
電動車椅子
【課題】雑音中であっても正確に使用者の発生する操作用の音声を聞き取り、それに基づき制御する電動車椅子を提供する。
【解決手段】電動車椅子は、ユーザ音声をマルチチャンネルで複数受音するために任意数のマイクロフォンを設けたマイクロフォンアレイ30a、30bを複数個相互に離間して配置してなる受音手段を備えた音声入力手段と、3次元空間中の任意の位置に配置された前記受音手段で受音したマルチチャネル音声データに基づいてMUSIC法によりユーザの発声位置を推定し発声位置推定信号を出力する発声位置推定手段と、前記発声位置推定信号に基づき車輪35a、35b、36bの駆動源を制御する制御手段を有する。
(もっと読む)
ナビゲーション装置、音声認識方法、およびプログラム
【課題】音声入力用マイクロフォンの指向性軸を音源に対して向ける。
【解決手段】ナビゲーション装置は、音声入力用の複数のマイクロフォンと、上記複数のマイクロフォンからの出力信号のそれぞれにディレイを加え、上記ディレイが加えられたそれぞれの信号を加算した音声信号を生成する音声信号生成部と、を有し上記出力信号に加えられるディレイ量を変更することにより指向性軸が変更されるマイクロフォンシステムと、上記複数のマイクロフォンからの出力信号にそれぞれサンプルディレイを加えた信号を加算したサンプル音声信号の出力レベルに基づいて、上記出力信号のそれぞれに対して加えるディレイ量の複数の組合せの中から、選択するディレイ量選択部、選択されたディレイ量の組合せを用いて生成された上記音声信号を認識する認識部と、上記認識部の認識結果に基づいて当該装置の動作を制御する制御部と、を有する。
(もっと読む)
音声認識システム及び音声認識方法
【課題】音源位置を推定せずに、雑音と区別して発話を検出する。
【解決手段】複数の指向性のマイクロホンと、前記複数の指向性のマイクロホン中の少なくとも1個のマイクロホンからの信号に対して音声認識を行う音声認識部とを備えた音声認識システムであって、無指向性のマイクロホンと、該無指向性のマイクロホンからの信号により発話区間を検出する発話検出部とを備え、前記音声認識部は発話区間の信号に対して音声認識を行う。
(もっと読む)
車載用音響処理装置
【課題】車室内音響空間において、使用条件にしたがう最適なハンズフリー通話および音声認識環境を提供する。
【解決手段】車室内に設置された複数のマイクロフォンM−1〜M−Nを備えた車載用音響処理装置(ヘッドユニット30)であって、座席位置、および車室内音響空間の状態に基づき選択されるマイクロフォンと、選択されたマイクロフォンの指向特性を制御する補正パラメータとが予め記憶された記憶手段(記憶部311)と、話者の座席位置と話者が発話したとき車室内音響空間の状態を検知し、記憶手段を参照して複数のマイクロフォンの中からマイクロフォンを選択し、選択されたマイクロフォンに対応する補正パラメータに基づきマイクロフォンの指向特性を可変制御する制御手段(条件判定部308、座標位置入力部309、エアコン使用状態通知部310)とにより構成される。
(もっと読む)
音声処理装置、音声処理方法、及び、プログラム
【課題】複数の音声入力部から入力された音声から、特定方向から発せられる目的音と撮影者音声とを抽出し、当該撮影者音声を含むシーンの切れ目情報からなるチャプター情報を再生時に利用する音声処理装置等を提供する。
【解決手段】本発明に係る音声処理装置は、複数の音声を取得する音声取得部と、取得される複数の音声から、所定の音声を抽出する音声抽出部と、抽出される所定の音声に基づいて、複数の音声の区切りを判定する判定部と、判定される区切りに基づいて、所定の音声に対応付けられる区切りを示す情報を生成する生成部と、生成される区切りを示す情報を表示する表示部と、を備える。
(もっと読む)
音データ処理装置、及び、プログラム
【課題】推定された音源の方向に誤差が生じていたとしても、ユーザにより指定された、又は自動で検出された音源の方向から補正値を算出することが可能な音データ処理装置を提供する。
【解決手段】本発明の音データ処理装置は、推定した音源の方向を映像上に描画する機能を有し、ユーザが指定した映像内の位置を基に音源の方向の補正値を算出する機能を有する。また、本発明の音データ処理装置は、顔検出機能を有し、検出された顔から音源の方向の補正値を算出する機能を有する。
(もっと読む)
対話装置
【課題】専用のセンサやマイクを新たに設ける必要がなく操作者までの距離検出を行い、適切なゲインで対話処理を行う。
【解決手段】受付端末20は、音声を入力するためのマイク207と、音声を出力するためのスピーカ208と有し、マイク207を介し入力された雑音により対応する雑音情報を取得し、取得した雑音情報に基づき生成された疑似雑音をスピーカ208を介し出力し、マイク207を介し入力された疑似雑音の対象物での反射音により対応する反射音情報を取得し、取得された反射音情報に基づき所定の演算処理を行い対象物が来訪者Mであると推測して来訪者Mまでの距離を検出し、この検出結果に基づき、マイク207のゲインを調整する。
(もっと読む)
音源の推定方法とその装置
【課題】現場において、測定データの任意の部分を抽出して音源位置の推定を行う方法とその装置を提供する。
【解決手段】複数のマイクロフォンM1〜M5とカメラ12とを一体化した音・映像採取ユニット10を用いて音の情報と映像の情報とを同時に採取し、音の情報である音声波形データと映像の情報である画像データとを記憶手段24に保存するとともに、音圧波形データのみを記憶手段24から抽出して表示手段25の表示画面25Mに音圧レベルの時系列波形のグラフを表示し、このグラフ上で音源方向の解析を行う時刻tzを指定した後、この指定された時刻tzを中心とした解析時間長Twの音圧波形データを用いて、複数のマイクロフォンM1〜M5で採取した音の音圧信号間の位相差を算出して音源の方向を推定するようにした。
(もっと読む)
ロボット、収音装置、及び音声処理方法
【課題】高いS/N比で収音することができるロボット、収音装置、及び音声処理方法を提供する。
【解決手段】本発明の一態様にかかるロボット10は、複数のマイクが配列されたマイクユニット24を有するロボット10であって、胴体部11と、胴体部11に上に取り付けられた頭部12と、上方を向いた複数のマイク素子M1〜M6を有し、頭部12に設けられたマイクユニット24と、を備え、複数のマイクM1〜M6のうち、最外周にあるマイクが、三角形を構成する三辺上に配列されているものである。
(もっと読む)
複数信号区間推定装置とその方法とプログラム
【課題】発話者の追跡の精度を向上させる。
【解決手段】この発明の複数信号区間推定装置は、センサ部と、音声信号区間推定部と、発話者方向推定部と、顔位置検出部と、情報統合部とを具備する。音声信号区間推定部はマイクロホンからの音響信号を周波数分析した周波数スペクトルを入力として、センサ部を中心とする平面の全領域に対する音声の存在確率を推定する。発話者方向推定部は音響信号の周波数スペクトルを用いて各領域における発話者の存在確率を推定する。顔位置検出部はカメラからの映像信号を入力として、談話参加者の顔の重心の方向に基づき各領域における談話参加者の存在確率を推定する。情報統合部は音声の存在確率と発話者の存在確率と談話参加者の存在確率を入力として各領域内の特定領域において談話参加者が発話した確率を算出する。
(もっと読む)
音声認識処理装置および音声認識処理方法
【課題】車内の異なる座席に位置する各ユーザごとに、独立したオペレーションを実現することができ、座席ごとに個別の音場環境を提供することを課題とする。
【解決手段】音声認識システムは、車内の各座席に設けられた音声認識用マイクを介して、複数の音声信号の入力を受け付けると、各音声信号の入力元の座席をそれぞれ特定する。続いて、音声認識システムは、音声信号の入力元として特定された各座席に対応する音声認識結果として得られたオペレーション内容に応じて、各座席ごとの音響制御を実行する。
(もっと読む)
内蔵音声フィードバック及び音声コマンドを用いる装着可能(wearable)なヘッドセット
ヘッドセット100が、装着可能な本体104と、装着可能な本体から延びる第1のイヤホン140a及び第2のイヤホン140bと、外部通信/マルチメディア装置90を無線制御する制御部170と、ヘッドセットのユーザー50からの音声データをピックアップするマイク130と、信号処理ユニット180とを含む。信号処理ユニット180は、音声データ132を処理してはっきりと聞こえる音声フィードバック信号にする回路120と、音声フィードバック信号を強化することによって強化された音声フィードバック信号を生成する回路120と、強化された音声フィードバック信号と、外部通信/マルチメディア装置90由来のオーディオ信号112とを混合することによって、混合された出力信号165を生成し、次いで混合された出力信号165をイヤホン140a、140bを介してユーザーへ送信する回路160とを含む。外部通信/マルチメディア装置90は音声コマンドアプリケーション200を備え、ヘッドセット100は、外部通信/マルチメディア装置90及び音声コマンドアプリケーション200へ音声コマンドを送信する音声コマンド制御部190をさらに備える。 (もっと読む)
1 - 20 / 123
[ Back to top ]