
Fターム[5D015EE00]の内容
音声認識 (5,191) | 前処理 (287)
Fターム[5D015EE00]の下位に属するFターム
Fターム[5D015EE00]に分類される特許
1 - 16 / 16
音声認識方法、音声認識装置及び音声認識プログラム
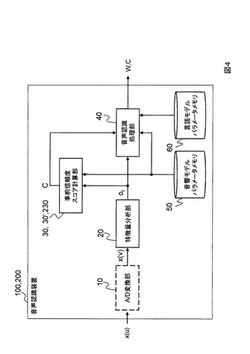
【課題】音声認識処理を行うこと無く短い処理時間で信頼度スコアを計算し、言語モデルに依存しない信頼度スコアを出力する音声認識装置と音声認識方法と、音声認識プログラムを提供する。
【解決手段】フレーム毎の音声特徴量系列を用いて、その音声特徴量系列に対するモノフォンHMMの各状態に属するGMMから得られる出力確率bs(ot)と、その各状態sの出現確率P(s)との積が最も高いものを求め、最も高い積P(s^)bs^(ot)の対数または出力確率bs^(ot)の対数と、その入力に対する音声モデルの状態に属するGMMまたはポーズモデルHMMの各状態に属するGMMから得られる最も高い出力確率bg^(ot)の対数との差を当該フレームの事前信頼度とし、その事前信頼度を平均化して音声ファイル単位の信頼度スコアを求め、音声特徴量系列を用いて、信頼度スコアに基づき音声認識処理を行う。
(もっと読む)
音声認識装置とその方法と、プログラムと記録媒体

【課題】音声認識装置の処理効率を向上させる。
【解決手段】この発明の音声認識装置のフレーム音質推定部は、フレーム毎に音声ディジタル信号の音質を評価してフレーム音質を出力し、平均音質推定部は、複数フレームのフレーム音質から音質レベルを推定する。そして、音声認識処理制御部が、音質レベルに基づいて音声認識処理時の動作を制御する制御信号を音声認識処理部出力にする。音声認識処理部はその制御信号に基づいて音声認識処理を行う。
(もっと読む)
受付装置
【課題】ユーザの発話音声以外の音が混入して入力される場合であっても確実にユーザ情報を取得する。
【解決手段】受付端末20は、タッチパネル210と、マイク207L,207Rとを有し、マイク207L,207Rを介し入力された音により音情報を取得し、マイク207L,207Rに入力された来訪者の発話音声による音声情報か、若しくは、タッチパネル210に入力された操作情報に基づき、来訪者情報を取得し、取得される音情報が所定の音情報を含むかどうかの判断を行い、音情報が所定の音情報を含むと判断された場合に、所定の切替タイミングで、来訪者情報の取得方法を、音声認識か、若しくは、タッチパネル210に切替制御し、この切替制御に対応した、音声情報に基づく来訪者情報、若しくは、操作情報に基づく来訪者情報を取得する。
(もっと読む)
音声認識装置及び音声認識装置のマスク生成方法
【課題】複数音源の音声を同時認識する音声認識に適したソフトマスクを備え、音声認識率の向上を図る。
【解決手段】音声認識装置は、複数音源からの混合音を分離する音源分離部101と、前記音源分離部が分離を行った際の分離信頼度に対応して、分離された音声ごとに、0から1の間の連続的な値をとりうるソフトマスクを生成するマスク生成部103と、前記音源分離部によって分離された音声を、前記マスク生成部で生成されたソフトマスクを使用して認識する音声認識部105と、を備えている。
(もっと読む)
音声認識装置および音声認識装置の制御プログラム
【課題】音声認識処理における処理負荷の軽減と応答時間の短縮を図る。
【解決手段】音声認識要求および音声信号を入力する認識処理要求受信手段10と、音声認識要求と共に入力された音声信号と、過去にデータベースに蓄積された音声信号との類似度を測定する類似度測定手段31と、音響モデル21および言語モデル22を用いて、入力された音声信号の音声認識処理を行なう音声認識処理手段20と、を備え、認識処理要求受信手段10は、認識処理を実行する前に、過去にデータベースに蓄積された該当ユーザの音声信号との類似度を測定し、類似度が高い音声信号が存在した場合は、該当音声信号に対する音声認識結果をデータベース33から読み出して、音声認識要求と共に入力された音声信号に対する音声認識結果として出力する。
(もっと読む)
音声認識装置、音声認識システムおよび音声認識方法
【解決手段】音声認識システムはサーバを含み、サーバでのデータベースには、複数の動作の各々に対応して作成された複数の動作雑音モデルと、複数の場所の各々に対応して作成された複数の環境雑音モデルとが記憶される。また、サーバには、複数の中継器が接続され、通信可能に携帯端末が接続される。携帯端末は、入力音声を取得するとともに、被験者の動作を検出し、入力音声に関する音声データおよび動作に関する加速度データを中継器に送信する。中継器は、音声データおよび加速度データに自身の中継器IDを付してサーバに送信する。サーバは、被験者の動作を特定し、また、中継器の設置場所を被験者の現在位置として推定する。そして、動作に応じた動作雑音モデルと被験者の現在位置に応じた環境雑音モデルとを用いて、入力音声に含まれる被験者の音声を認識する。
【効果】入力音声に含まれる雑音を適切に抑圧して、正確に音声認識することができる。
(もっと読む)
音声認識装置および音声認識方法,音声認識用プログラム
【課題】発声者が周囲の状況に影響されて通常とは違う発声を行った場合でも精度よく音声認識できる音声認識装置および音声認識方法,音声認識用プログラムを提供する。
【解決手段】人密度推定手段1が、発話者の周囲の人密度を推定し、音声認識手段2が、人密度に基づいて入力音声を音声認識する。例えば、発話者の周囲の電波密度,足音等から人密度を算出し、人密度が高い場合に、早口の音声に対応した音響モデル、または、聞かれてもよい単語を用いた発話に対応する辞書を用いて音声認識処理を実行する。
(もっと読む)
仮音声区間決定装置、方法、プログラム及びその記録媒体、音声区間決定装置
【課題】音声区間非音声区間の仮判定の精度を上げることによって、最終的な音声区間非音声区間の判定の精度を上げることを目的とする。
【解決手段】入力された音声信号からフレーム毎に音声パラメータを計算する。上記音声パラメータを予め定められたフレーム数分だけ遅延バッファに蓄積する。上記音声パラメータから、その音声パラメータに係るフレームが、音声区間に属するか非音声区間に属するかを仮に決定する。上記決定された、音声区間に属するか非音声区間に属するかについての仮の情報(以下、仮VADフラグとする。)を、予め定められたフレーム数分だけVADフラグバッファに蓄積する。VADフラグバッファに蓄積された仮VADフラグを、上記遅延バッファから読み出した音声パラメータの経時的変化を観測し、予め定めた規則に基づいて過去に遡って修正する。上記修正された仮VADフラグを出力する。
(もっと読む)
受音装置と音声認識装置とそれらを搭載している可動体
【課題】 受音装置で受音した音源の存在方向を周囲に知らせる表示器を備えた受音装置を提供する。
【解決手段】 高い指向性を持つ方向(受音方向)を調整可能なマイク20と、マイク20で受音した音源が存在する方向を検出する音源方向検出部101と、検出した音源の存在方向とマイク20の受音方向を、ロボット1の周囲から視認可能に表示する表示器10を備えている。周囲にいる人間が、受音装置で受音している音源がいずれであるのかを理解することができる。
(もっと読む)
車載収音装置及び車内収音情報表示方法
【課題】音源の方向とその音量を従来よりもさらに直感的に把握することができる車載収音装置及び車内収音情報表示方法を提供する。
【解決手段】車内に設置した2つのマイクロフォン17A及び17Bにて車内で話者の音声を収音し、入力音圧レベルを表す画像データと2つのマイクロフォン17A及び17Bによる指向性を表す画像データをデータメモリ14から読み出して、それらの画像データからドット展開した表示データを生成してディスプレイ15上に表示するので、話者の発声を音源とするその方向とその音量を従来よりもさらに直感的に把握することが可能となり、例えばナビゲーション装置を適切な発声音量で音声操作を行うことができる。
(もっと読む)
近接音分離収音方法、近接音分離収音装置、近接音分離収音プログラム、記録媒体
【課題】目的音源の近傍に雑音源が存在し、双方が同時に鳴っている場合でも、目的音をSN比よく取り出す。
【解決手段】目的音信号と雑音信号とが混合された信号を複数の帯域信号に分割し、分割された各帯域信号の特徴量を求める。或る帯域信号の特徴量が目的音を表わす値である場合その帯域信号を目的音として判定し、特徴量が雑音を表わす値である場合、その帯域信号を雑音と判定し、その判定結果に従って各帯域信号に重み付けを施し、この重み付けにより雑音成分を除去し、目的音をSN比よく取り出す。
(もっと読む)
混合信号分離・抽出装置
【課題】原信号を連続的かつ忠実に再生することの可能な混合信号分離・抽出装置を提供すること。
【解決手段】連続する2つのサンプリング期間Δt1、Δt2ごとに独立成分分析による分離・抽出処理を実施し、信号分離出力XA(XA1,…,XAi),XB(XB1,…,XBi)を得る。さらにΔt1+Δt2における信号分離出力XC(XC1,…,XCi)を生成し、XCを期間△t1に相当する成分(XA’)と、△t2に相当する成分(XB’)とに分割する。そして(XA1,…,XAi)の各成分と、(XB1,…,XBi)の各成分との連結すべき組み合わせを、XAとXA’との相関値、およびXBとXB’との相関値に基づいて算出する。
(もっと読む)
信号分離システム、信号分離方法及び信号分離プログラム
【課題】 信号源信号の分離処理を任意の条件下で精度良く行うことができる信号分離システムを提供する。
【解決手段】 信号分離部12のウェーブレット・パケット変換部13において、ウェーブレット・パケット変換を施し、時間領域の観測行列Xを時間周波数領域の観測行列X′に変換する。次に、混合行列推定部14において、変換された時間周波数領域の観測行列X′に基づいて、時間周波数領域の観測行列X′と時間周波数領域の信号源行列S′との間の関係を規定する混合行列Aを推定する。推定された混合 行列Aと変換された時間周波数領域の観測行列X′とに基づいて、時間周波数領域の信号源行列S′を推定する。
(もっと読む)
信号源数の推定方法、推定装置、推定プログラム及び記録媒体
【課題】 実環境において信号源の数を正しく推定する。
【解決手段】 周波数領域変換部20が、観測信号xj(t)(j={1,...,M})を周波数毎の時系列データXj(f,τ)に変換し、信号分離部31が、この時系列データXj(f,τ)から分離信号Yi(f,τ)を生成してメモリ10に格納する。次に、パワー算出部32が、各分離信号Yi(f,τ)のパワー値を求めてメモリに格納し、エンベロープ相関算出部33が、異なる分離信号Yi(f,τ)間の時間差Δτに対するエンベロープ相関値を算出してメモリに格納する。そして、判定部34が、各分離信号Yi(f,τ)のパワー値及びエンベロープ相関値と、残響レベル及びエンベロープ相関値のそれぞれのしきい値を示すパラメータthnoise、threv及びthcorとを比較し、当該分離信号Yi(f,τ)が源信号成分であるか否かを判断する。
(もっと読む)
信号分離方法および装置ならびに信号分離プログラムおよびそのプログラムを記録した記録媒体
【課題】 局所解に陥ることなく安定した最適化を行うと共に、分離信号の歪みを抑制する。
【解決手段】 歪み補正部2は、歪みが内在する分離信号と所定量だけ遅延させた観測信号から、歪みを補正した分離信号を算出する。このため、分離信号生成部1は、分離信号の歪みを考慮せず、分離信号の独立性などを高めることを最優先にして最適化を行う。信号分離装置は、分離信号の独立性制約条件を満たす分離信号を抽出し、所定の遅延を持つ観測信号と当該観測信号の重み付け線形和との誤差が最小となるようなフィルタを選択し、歪みを補正した分離信号を生成出力する。
(もっと読む)
ダイアログシステムの駆動方法
本発明は、音声信号を処理する音声インタフェースを有するダイアログシステムを駆動する方法を記載する。本方法は、予想される音声入力信号の特性を推定し、当該特性に従って音声インタフェース制御パラメータを生成する。音声インタフェースの動作は、この音声インタフェース制御パラメータに基づき最適化される。さらに本発明は、音声インタフェースと、ダイアログ制御ユニットと、予想される音声入力信号の特性を推定する予測モジュールと、前記特性に基づき音声入力制御パラメータを生成することにより、前記音声インタフェースの動作を最適化する音声最適化装置とを有することを特徴とするダイアログシステムを記載する。 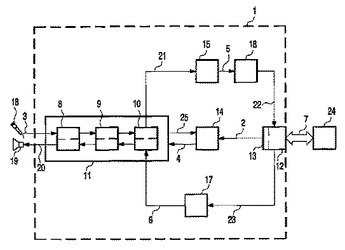 (もっと読む)
(もっと読む)
1 - 16 / 16
[ Back to top ]