
Fターム[5D015EE02]の内容
Fターム[5D015EE02]に分類される特許
1 - 17 / 17
音声処理装置及び音声処理装置の制御方法
話者判別装置、話者判別プログラム及び話者判別方法
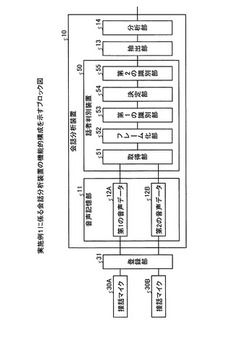
【課題】話者の判別を簡易かつ正確に行うことを課題とする。
【解決手段】話者判別装置50は、2人の話者に配置されるマイクから2つの音声データを取得する。さらに、話者判別装置50は、2つの音声データの各々をフレーム化する。さらに、話者判別装置50は、第1の確率モデルに基づいて、フレームが有声音領域又は無声音領域のいずれであるかを識別する。さらに、話者判別装置50は、有声音領域であると識別されたフレームの識別結果を有効又は無効とするかを決定する。このとき、話者判別装置50は、2つの音声データのエネルギー比を複数の確率分布が混合するモデルにモデル化した上でフレーム間のエネルギー比が複数の確率分布のうちいずれに属するかに応じて先の決定を行う。さらに、話者判別装置50は、第2の確率モデルに基づいて、有効又は無効が決定された後のフレームの識別結果から2つの音声データにおける発話領域及び沈黙領域を識別する。
(もっと読む)
音声認識装置

【課題】現在の騒音状況に適した入力ゲインを設定することができる「音声認識装置」を提供する。
【解決手段】第1騒音振幅分布検出部11と第2騒音振幅分布検出部12は、音声認識エンジン7が音声認識処理中に発声音声を検出している時間区間である発声音声区間以外の時間区間において、騒音の振幅分布gb(n)を繰り返し算出する。音声振幅分布検出部14は、発声音声区間の発声音声の平均の振幅分布f(n)を算出する。入力ゲイン制御部10は、音声認識処理開始時に、最後に算出された騒音の振幅分布と、発声音声の平均の振幅分布の双方を考慮し、音声認識エンジン7に入力する入力音声データのレンジが、音声認識エンジン7の規格レンジに対して適正なレンジを持つように入力アンプ5の入力ゲインGを制御する。
(もっと読む)
音声処理装置
【課題】発話音声及び騒音が混在する環境において得られる音声信号を適正に処理することのできる「音声処理装置」を提供することである。
【解決手段】利用者の発話に応答してマイクから出力される音声信号を設定されたゲイン値に基づいて増幅する増幅手段12と、増幅手段12での増幅を経た音声信号を処理する音声処理手段120とを有する音声処理装置であって、利用者の発話に際して増幅手段13での増幅を経た音声信号のピーク値を検出する音声ピーク値検出手段130と、ピーク値検出手段130にて検出される音声信号のピーク値の統計的分布を表わす音声ピーク値分布情報を生成する手段140と、前記音声ピーク値分布情報と予め定めた基準ピーク値範囲内とに基づいて増幅手段12に設定すべきゲイン値を決定するゲイン値決定手段150とを有する構成となる。
(もっと読む)
音声認識装置
【課題】発話において突発的な音量変化が生じた場合であっても、確実に認識漏れなく音声認識を行う。
【解決手段】受付端末20は、来訪者Mの発話音声により音声情報を入力するマイク207と、マイク207で入力された音声情報を増幅するオペアンプ217とを有し、互いに異なる複数の値N1,N2,N3が時系列的に順次繰り返されるようにオペアンプ217の増幅率を切替制御し、この切替制御に連動し、複数の値N1,N2,N3に制御された増幅率を用いてオペアンプ217で増幅された音声情報を所定周期でサンプリングし、音声データSDを取得し、この取得された音声データSDを、切替制御された増幅率の複数の値N1,N2,N3それぞれに対応させた複数のデータ群に分類して抽出し、この抽出された複数のデータ群のうち、特定のデータ群を選択し、この選択されたデータ群を用いて音声認識を行う。
(もっと読む)
対話装置
【課題】専用のセンサやマイクを新たに設ける必要がなく操作者までの距離検出を行い、適切なゲインで対話処理を行う。
【解決手段】受付端末20は、音声を入力するためのマイク207と、音声を出力するためのスピーカ208と有し、マイク207を介し入力された雑音により対応する雑音情報を取得し、取得した雑音情報に基づき生成された疑似雑音をスピーカ208を介し出力し、マイク207を介し入力された疑似雑音の対象物での反射音により対応する反射音情報を取得し、取得された反射音情報に基づき所定の演算処理を行い対象物が来訪者Mであると推測して来訪者Mまでの距離を検出し、この検出結果に基づき、マイク207のゲインを調整する。
(もっと読む)
音声対話装置及び支援方法
【課題】
音声認識精度を向上させるために利用者の発話に適した領域を推定することのできる対話型ロボットを提供する。
【解決手段】
音声認識可能な音声対話型ロボット100であって、音声認識部302で認識された語彙に対応する処理を実行する。利用者音声強度DB306に記憶された利用者201の音声の特性から、必要なS/N比を満たす推奨距離範囲を推定し、推奨距離範囲提示部309へ出力する。推奨距離範囲提示部309は、推奨距離範囲推定部307から通知された対話型ロボット100と利用者201との音声に適した距離範囲である推奨距離範囲を利用者201に対して提示する。それによって利用者が音声認識精度を満たす発話に適した推奨距離範囲から発話が可能なように支援することが可能な対話型ロボットを提供することが出来る。
(もっと読む)
音量調整装置、方法及びプログラム
【課題】周波数等の音の所定の特徴量をなるべく変化させないようにしつつ、音量調整を行う技術を提供する。
【解決手段】入力された音を一定の時間長のフレームで分割する。フレームに含まれる音の大きさを表す特徴量である外形値をフレームごとに求める。予め定められた数B1以上連続する無音フレームに挟まれ、予め定められた数B2以上のフレームから構成された音区間を第一音区間として、第一音区間を構成する複数のフレームの外形値から、外形値が大きい方から複数の外形値を除外して、除外されずに残った外形値の最大値をその第一音区間の外形値として求める。求まった第一音区間の外形値が予め定められた範囲に入るように、入力された音の音量を調整するための情報(以下、第一音量調整情報とする。)を決定して、出力する第一音量調整指示手段と、出力された第一音量調整情報を用いて入力された音の音量を調整する。
(もっと読む)
レベル調整判定装置、その方法、およびそのプログラム
【課題】入力信号の波形の振幅を正確に過大、過小であるかを判断できる。
【解決手段】入力信号のレベルLを算出し(102、S2)、レベルLが予め定められた第1閾値Amax以上/より大きいか否かを判定し(104、S4)、レベルLが第1閾値Amax以上/より大きいと判定されると、過去の予め定められた判定時間Tf内で、レベルLが第1閾値Amax以上/より大きい時間の合計時間である閾値大時間THを算出し(108、S8)、閾値大時間THを用いて、第1閾値Amax以上/より大きいレベルについての相加平均である閾値大平均レベルMHを算出し(112、S10)、閾値大平均レベルが予め定められた第2閾値Bmax以上/より大きいか否かを判定し(116、S12)、この判定結果に応じた入力信号のレベルを調整するための調整命令信号を生成、出力する(124、S14、S16)。
(もっと読む)
電話端末装置及びこれを用いた音声認識システム
【課題】内線電話端末として利用可能としつつ、音声認識処理に適した符号化を行う。
【解決手段】IP電話機能を備え、当該IP電話機能を用いて構内に敷設されたネットワークを介して内線電話端末として利用可能な電話端末装置1であって、IP電話機能の利用時に通信データの符号化を行うIP電話用コーデック10と、ユーザから入力された音声データの音声認識処理に適した符号化を行う音声認識用コーデック11と、IP電話用コーデック10と音声認識用コーデック11とを切り替えるコーデック切替部9とを備える。
(もっと読む)
ロボット
【課題】本発明は、音声合成部と音声認識部の設定およびセリフとなる文字列を自動的に適切に調整し、ユーザの作業を簡易化することができるロボットを提供する。
【解決手段】出力音声を合成する音声合成部3と、入力音声の認識を行う音声認識部4と、前記音声合成部3および前記音声認識部4の設定を調整する調整部5とを備えたロボット1において、前記調整部5は、前記出力音声を前記音声認識部4の入力音声とした認識結果を基に調整するものである。
(もっと読む)
情報処理装置及び情報処理方法
【課題】 ユーザが特定のオブジェクトに音声を登録し、その音声を発声することでオブジェクトを呼び出すことができる音声操作において、前記オブジェクトが表現しにくい概念(操作マクロ、検索クエリ等)であった場合を考える。登録したオブジェクトを発声で呼び出した際には、呼び出したオブジェクトがユーザが求める内容であるかどうかを効果的に確認する手段がない。
【解決手段】 オブジェクトへの音声登録時に、識別情報データベースから識別情報を選択する。そして、オブジェクト、登録音声、選択された識別情報からなる登録情報を登録データベースに格納する。音声呼び出し時は、呼び出された登録情報に含まれる識別情報をユーザに提示する。
(もっと読む)
音声処理装置および音声処理方法
【課題】 アナログ音声信号の増幅とデジタル音声信号の増幅が可能な音声処理装置において、入力される音声信号が所望の音量になるような最適なアナログ音声信号の増幅値とデジタル音声信号の増幅値を設定する。
【解決手段】 目標増幅値に対するアナログ増幅値とデジタル増幅値を設定する際に、アナログ増幅とデジタル増幅を組み合わせて得られる増幅値が目標増幅値と等しく、かつアナログ増幅値が設定可能な範囲で最大になるようにアナログ増幅値とデジタル増幅値とを設定することを特徴とする。
(もっと読む)
収音装置
【課題】 音声信号を受け取って処理する側の装置が負う音声信号の解析のための負担を軽減する。
【解決手段】 抽出部20−k(k=1〜m)は、マイクロフォン11−k(k=1〜m)により得られたデジタルオーディオ信号S−k(k=1〜m)から音声強度信号Es−k(k=1〜m)と雑音強度信号En−k(k=1〜m)を各々抽出する。S/N比信号生成部50は、音声強度信号Es−k(k=1〜m)と雑音強度信号En−k(k=1〜m)からS/N比信号を演算する。出力部60は、デジタルオーディオ信号S−k(k=1〜m)から合成されたデジタルオーディオ信号SSとS/N比信号とを出力する。
(もっと読む)
音声入力装置
【課題】音声認識の精度をより向上することのできる「音声入力装置」を提供する。
【解決手段】ゲイン制御部10は、オーディオ信号のスピーカ3への出力を増幅する出力調整アンプ22のゲインを、発話音声抽出部7で推定されるA/D変換器6が出力するデジタル信号中のオーディオ信号成分のレベルの大きさが、発話音声抽出部7が過去に推定した、A/D変換器6が出力するデジタル信号中の発話音声信号成分のレベルの大きの最小値よりも小さくなるように設定する。また、A/D変換器6へ入力する信号を増幅する入力調整アンプ5のゲインを、発話音声抽出部7が推定した、A/D変換器6が出力するデジタル信号中の発話音声信号成分のレベルの大きさと、A/D変換器6の出力可能な最大レベルとの比率が、1:2となるように設定する。
(もっと読む)
入力レベルの自動調整のための音声認識システム及びこれを用いた音声認識方法
【課題】 ユーザが発声した音声を分析し、音声認識期間で音声として認識することができるように、音声入力レベルを自動的及び能動的に調整することができる音声認識システム等を提供する。
【解決手段】 本発明の音声認識システムは、外部から話者の音声を読み取る音声読み取り部220と、読み取られた音声を、音声認識部300から供給される音声入力レベルで受信し、音声認識部300に出力する音声レベル制御部240と、 音声レベル制御部240で出力される音声から音声認識に必要な音声信号期間を検出する音声検出部310と、検出した音声信号期間内の音声信号の有無を、閾値を基準にして判定する音声飽和検出部350と、音声信号期間の音声信号が飽和したと判定されると、音声レベル制御部240が音声を飽和しない状態で受信するように、新たな音声入力レベルを決定し、該新たな音声入力レベル情報を音声レベル制御部240に出力する音声レベル決定部370と、を含む。
(もっと読む)
音声認識装置、方法及び音声認識方法を用いた携帯型情報端末装置
【課題】携帯型情報端末装置の使用状態に応じて入力した音声レベルを適切な音声レベルに増幅し、認識率低下の防止を行う。
【解決手段】マイクロフォンに入力する音声を認識する音声認識装置に、マイクロフォンから出力される音声信号を増幅する増幅器108と、増幅された音声レベルを検出する音声レベル検出部103Aと、送話ゲイン、適正音声レベル、送話ゲイン更新用の時定数を記憶する送話ゲイン情報記憶部106Aと、送話ゲイン、適正音声レベル、時定数を読み出し、増幅器に送話ゲインを設定し、検出された音声レベルを適正音声レベルにすべきゲインに時定数を乗じた値を送話ゲインに加算して送話ゲインを更新し、更新した送話ゲインを送話ゲイン情報記憶部に記憶させる送話ゲイン設定制御部103Bと、増幅された音声信号を入力して音声認識を行う音声認識部111とを備える。
(もっと読む)
1 - 17 / 17
[ Back to top ]