
Fターム[5D015GG00]の内容
音声認識 (5,191) | 標準パターンの学習 (485)
Fターム[5D015GG00]の下位に属するFターム
標準パターンの置換、更新 (134)
標準パターンの削除 (37)
標準パターンの追加 (100)
学習処理時にパターン照合を行うもの (17)
音声パターンの加算、平均化 (12)
標準パターン学習モードの設定、切換 (19)
Fターム[5D015GG00]に分類される特許
1 - 20 / 166
対話モデル構築装置、方法、及びプログラム
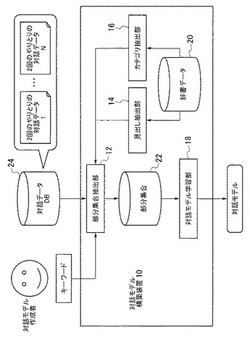
【課題】3回以上のやりとりが少ない対話データを学習データとして用いた場合でも、精度の良い対話モデルを構築する。
【解決手段】部分集合抽出部12は、2回のやりとりの対話データを複数取得する。辞書データ20から見出し抽出部14が見出し語を抽出し、カテゴリ抽出部16がカテゴリ情報を抽出して、見出し語・カテゴリ情報のペアを作成する。部分集合抽出部12は、取得した対話データ内の各単語に見出し語・カテゴリ情報に基づいてカテゴリ情報を付与し、入力されたキーワードを単語及びカテゴリ情報に含む対話データを部分集合として抽出する。対話モデル学習部18は、部分集合を用いて、学習過程において2回のやりとりから、内容が近い発話データをクラスタリングすることで2回を超えるやりとりを構成しながらHMMを学習し、学習したHMMを対話モデルとして出力する。
(もっと読む)
認識装置、認識プログラム、認識方法、生成装置、生成プログラムおよび生成方法

【課題】精度良く音声の認識を行うこと。
【解決手段】認識装置20は、記憶部24と、第一の算出部26aと、第二の算出部26bと、決定部26cとを有する。記憶部24は、文章に含まれる単語と単語の文章内の位置を示す位置情報とを記憶する。第一の算出部26aは、入力された音声信号と、記憶部24に記憶された複数の単語を接続した文字列の読み情報とを比較して、類似度を算出する。第二の算出部26bは、記憶部24に記憶された各単語の位置情報に基づいて、接続した複数の単語間の近さを示す接続スコアを算出する。決定部26cは、類似度および接続スコアに基づいて、音声信号に対応する文字列を決定する。
(もっと読む)
音響モデル適応装置、音響モデル適応方法、およびプログラム
【課題】パラメータ修正への寄与が大きく、かつ適応効果を低下させにくいデータを使って音響モデルの適応を行うことができる音響モデル適応装置を提供する。
【解決手段】本発明の音響モデル適応装置10は、音声認識部100が、入力された音声から、適応前音響モデルを用いて、音声認識結果テキストと信頼度を出力する。音声認識結果登録部200が、話者IDと音声と音声認識結果テキストと信頼度からなる音声認識結果を記憶する。苦手話者検出部300が、他の話者よりも音声認識精度が低い苦手話者の話者IDを抽出する。適応用データ選択部400が、話者IDが苦手話者の話者IDであり、かつ、信頼度が予め設定された信頼度閾値以上である音声認識結果を読み込み、適応用データを抽出する。音響モデル適応部500が、予め設定された適応パラメータを用いて、適応後音響モデルを出力する。
(もっと読む)
音響モデル生成装置、音響モデル生成方法、プログラム
【課題】識別対象となるデータに含まれる非音声区間に影響を受けずに男女識別を行うことができる音響モデル生成装置を提供する。
【解決手段】男性音声データと、女性音声データと、非音声データとを音響モデルの生成に用いる音響モデル生成装置100であって、音響モデルの生成に用いられるデータから特徴量を抽出する特徴量抽出部930と、男性音声データから抽出された特徴量から男性音声区間モデルを、女性音声データから抽出された特徴量から女性音声区間モデルを、非音声データから抽出された特徴量から非音声区間モデルを学習するモデル学習部940と、男性音声区間モデルと非音声区間モデルを統合して男声音響モデルを生成し、女性音声区間モデルと非音声区間モデルを統合して女声音響モデルを生成するモデル統合部150とを備える。
(もっと読む)
話者クラスタリング方法、話者クラスタリング装置、プログラム
【課題】同一クラスタ内の話者間の知覚的類似度を高くできる話者クラスタリング方法を提供する。
【解決手段】N名の話者による同一内容の発話の音声データのうちk番目とj番目(1≦k,j≦N)の話者の発話の音声データの知覚的類似度の主観評価値をj番目の要素として有する話者ベクトルを生成する話者ベクトル生成サブステップと、話者ベクトルのベクトル間距離に基づいて、N名の話者をクラスタ数Mにクラスタリングするクラスタリングサブステップと、話者の属するクラスタ毎に当該話者の発話の音声データから選択用モデルを学習する選択用モデル学習サブステップと、任意の話者の音声データを入力とし当該入力された任意の話者の音声データと各クラスタの選択用モデルとの尤度を計算する尤度計算サブステップと、計算された尤度が最も高いクラスタを入力された音声データの話者が属するクラスタとして選択するクラスタ選択サブステップとを有する。
(もっと読む)
音響モデル作成装置の制御方法、音響モデル作成装置
【課題】 多言語音声認識において、音響モデル作成に用いる音声データベースの言語ごとのサイズの違いに起因する言語間の音声認識の性能差を生じさせない音響モデルの作成方法を提供する。
【解決手段】 音声データベースから第一の音響モデルを作成するステップと、少なくとも2つ以上の言語からなる多言語音声データベースと前記第一の音響モデルから得られるデータを用いてデータを正規化するデータ正規化ステップと、前記正規化されたデータと前記多言語音声データベースを用いて第二の音響モデルを作成するステップとを有する。
(もっと読む)
モデルパラメータ配列装置とその方法とプログラム
【課題】モデルの要素集合Θのパラメータ要素をその重要度順に配列するモデルパラメータ配列装置を提供する。
【解決手段】初期化部は、選択サブセット候補を空集合で初期化して集合Θと選択サブセット候補を出力する。要素選択部は、集合Θと選択サブセット候補を入力として、サブセット候補として選択サブセット候補と他のパラメータ要素との全ての組を出力する。サブセット評価値記憶部は、サブセット候補を入力として、当該サブセット候補のそれぞれのスコアEtの最大値若しくは最小値と、上記集合Θのスコア値である評価値Eとの差分を求め、その差分が最小若しくは最大となるサブセット候補を選択サブセット候補として記憶する。
(もっと読む)
言語モデル生成装置、言語モデル生成方法および言語モデル生成プログラム
【課題】音声認識精度の高い話者の発話に対して応答する話者の発話音声の音声認識精度が低い場合においても、音声認識精度を高める言語モデルを生成することができる言語モデル生成装置を提供する。
【解決手段】会話に参加する音声認識精度が高い話者の発話の特徴である発話特徴を抽出する発話特徴抽出手段101と、発話特徴抽出手段101が抽出した発話特徴と、特定の会話における発話音声を書き起こしたテキスト、発話音声ないし会話から得られる音声特徴量、および発話音声ないし会話から得られる話者情報を対応づけた会話コーパスとを用いて、言語モデル生成用の学習データを選別する言語モデル学習データ選別手段102と、言語モデル学習データ選別手段102が選別した学習データを優先的に用いて、言語モデルを生成する言語モデル生成手段103とを備えたことを特徴とする。
(もっと読む)
音声認識装置、音声認識方法及びプログラム
【課題】様々な分割の粒度に対応した音声単位列を取得し、そのうちから音声データに対応する音声単位列を登録する。
【解決手段】音声入力部201は、音声データを入力する。分割部203は、分割の粒度に係る複数の変数を設定し、変数毎に前記音声データを複数の区間に分割する。認識部204は、変数毎に前記各区間の音声単位を認識する。接続部205は、変数毎に各区間の音声単位を接続することにより、前記変数毎の音声単位列を取得する。尤度計算部206は、変数毎の音声単位列の夫々について音声データに対する尤度を計算する。登録部207は、計算された尤度に基づいて、変数毎の音声単位列から前記音声データに対応する音声単位列を登録する。
(もっと読む)
音響モデル学習装置及びコンピュータプログラム
【課題】SVMを用いた音響モデルの学習装置を提供する。
【解決手段】学習装置は、学習データ記憶部102と、各音素の内部状態のSVMパラメータを記憶するSVMパラメータ記憶部116と、学習データの各々と、対応する音響モデル内の内部状態との間を初期アライメントする初期アライメント処理部110と、初期アライメント済の学習データを記憶する、書換え可能な記憶部112と、アライメント済の学習データを用いて音響モデルの各内部状態のSVMの学習を行なうアライメント処理部118と、学習データの各々について、SVM学習部114により学習された音響モデルを用いて各音響モデル内の内部状態とアライメントを行ない、記憶部112の学習データを更新する学習データ更新部122と、終了条件が成立するまで、SVM学習と学習データのアライメントとを繰返し実行させる比較部126とを含む。
(もっと読む)
コーパス選別装置、コーパス選別方法、およびプログラム
【課題】言語モデルの品質の向上と、記憶領域の使用量の削減と、を両立できる学習コーパスを選別するコーパス選別装置、コーパス選別方法、およびプログラムを提供すること。
【解決手段】コーパス選別装置AAは、学習コーパス(全体)を学習コーパス(サブセット1)〜学習コーパス(サブセット3)に分割し、言語モデリングにより、学習コーパス(サブセット1)〜学習コーパス(サブセット3)のそれぞれに対応するサブセット言語モデル1〜3を生成する。そして、サブセット言語モデル1〜3のそれぞれについて、タスク表現コーパスを用いてperplexityを算出して、perplexity−1〜perplexity−Yを求める。そして、perplexityの低いサブセット言語モデルに対応する学習コーパスを、学習コーパス(全体)から除去して、学習コーパス(選別済み)を選別する。
(もっと読む)
高速音声検索の方法および装置
【課題】高速音声検索の方法および装置を提供する。
【解決手段】マルチプロセッサシステム内の大きい音声データベースを検索してターゲット音声クリップを特定する。大きい音声データベースは複数のより小さいグループに分割されて、これら複数の小グループがシステム内の複数の利用可能なプロセッサに対して動的にスケジューリングされる。プロセッサは、各グループを複数のより小さいセグメントに分割して、セグメントから音声特徴を抽出して、共通成分ガウス混合モデル(CCGMM)を用いてセグメントをモデル化することによって、スケジューリングされた複数のグループを並列に処理する。1つのプロセッサはさらに、ターゲット音声クリップから音声特徴を抽出してCCGMMを用いて抽出した音声特徴をモデル化する。ターゲット音声クリップと各セグメントとの間のKL距離に基づいて、セグメントがターゲット音声クリップに一致するか否か判断する。
(もっと読む)
音響モデル作成方法とその装置とプログラム
【課題】識別学習法において、音声認識誤りを含む音声認識結果ラティスの大きさを自動的に最適化する。
【解決手段】部分学習データ選択部が、学習用音声データベースの中から部分学習用音声データを選択し、部分認識パラメータ判定部がその部分学習用音声データが所定の大きさの部分ラティスとなる決定認識パラメータを求める。そして、ラティス作成用認識部が、その決定認識パラメータを用いて音声認識結果ラティスを生成する。識別学習部が、音声認識結果ラティスと正解シンボル系列を対比させて識別学習を行い識別学習済音響モデルを生成する。
(もっと読む)
パターン分類装置の学習装置及びそのためのコンピュータプログラム
【課題】ベイズ誤り推定と直結した損失関数を用い,高い認識率が得られるようなパターン分類装置のための学習装置を提供する.
【解決手段】学習装置42は,学習パターン集合を記憶する記憶装置64と,各クラスに対し定義される判別関数を,学習パターンにより学習する学習装置66とを含む.判別関数は,入力パターンと,複数個のプロトタイプとの間のカーネル演算の線形和により表される.カーネルは,入力パターンの空間より高次元の空間に入力パターンを変換する特徴変換を定めたときに,変換後の入力パターンと,変換後のプロトタイプとの間の内積により定義され,プロトタイプ相互間でのカーネル演算により構成されるグラム行列が正定値行列となる.学習装置は,高次元空間において学習パターンと係数ベクトル集合との関数として定義される平均分類誤り数損失が最小となるよう係数ベクトルを調整する.
(もっと読む)
音声選択装置、発話選択装置、音声選択システム、音声選択方法および音声選択プログラム
【課題】複数のモデルが存在する場合に、ある特定のモデルを強化することを目的とした学習に有効な学習用データを効率的に選択することができる音声選択装置を提供することを目的とする。
【解決手段】音声データと、特定のモデルを含む複数のモデルとを入力し、入力した音声データを複数のモデルを用いて音声認識処理を実行する音声認識手段103と、特定のモデルと特定のモデル以外のモデルとを用いて認識した認識結果を比較し、認識結果の一致度を示す認識結果一致度を算出する認識結果一致度算出手段104と、認識結果一致度に基づいて、音声データから特定のモデルの学習に用いる音声を選択する音声選択手段106とを備えたことを特徴とする。
(もっと読む)
言語モデル生成装置、その方法及びそのプログラム
【課題】音声認識対象の内容と類似するコーパスを効率よく収集して言語モデルを作成する。
【解決手段】Web(world wide web)ページの集合を含むコーパス内のテキストを分析する。当該分析結果に基づいて、音声認識対象に応じて設定された文書形式に適合する少なくとも1つの単語を抽出する。抽出された少なくとも1つの単語から単語セットを生成する。生成された単語セットをインターネット上の検索エンジンへの検索クエリーとし、当該検索エンジンに検索処理を行わせ、検索結果のリンク先のWebページを取得する。
取得されたWebページから、音声認識のための言語モデルを作成する。
(もっと読む)
言語モデル処理装置および音声認識装置、ならびにプログラム
【課題】統計的言語モデルを構築するためのコストを削減することのできる言語モデル処理装置を提供する。
【解決手段】正解なし認識結果記憶部は、正解のない音声認識結果データを記憶する。言語モデル記憶部は、言語表現の出現確率を表すデータである言語モデルを記憶する。正解なし誤り傾向学習部は、入力される所定の言語モデルと、正解のない音声認識結果データとに基づいて、音声認識の誤り傾向の学習処理を行い、この誤り傾向の学習結果によって言語モデルを更新して、更新された言語モデルを言語モデル記憶部に書き込む。
(もっと読む)
対話学習装置、要約装置、対話学習方法、要約方法、プログラム
【課題】要約装置構築のコストを低減し、要約の精度を向上する。
【解決手段】本発明の対話学習装置は、各対話に含まれる発話にトピックラベルが付与されたN個の対話と各対話がK種類のドメインのいずれに該当するのかを示したドメインラベルを用いて、ドメインごとに、話者の発話を出力する状態を持つ隠れマルコフモデルを学習し、隠れマルコフモデルのすべての状態をエルゴディックに接続して、隠れマルコフモデルを作成する。本発明の要約装置は、特徴量抽出部、トピックラベル付与部、ドメイン推定部、選択部を備える。トピックラベル付与部は、発話ごとに、当該発話に含まれる単語から尤もらしいトピックを推定して、トピックラベルとして当該発話に付与する。ドメイン推定部は、各発話のドメインを推定する。選択部は、対話とドメインが一致する発話を、当該対話の中から選択する。
(もっと読む)
読み推定装置、読み推定方法、および読み推定プログラム
【課題】誤った読み仮説と読み推定対象単語の表記がたまたま同一文書内に現れていることが原因で読み推定の精度が劣ることを防止し、高精度で読み推定を行うこと。
【解決手段】読み仮説生成部101は、読み推定対象単語に対し、複数の読み仮説を生成する。また、共起スコア計算部103は、複数の読み仮説の各々について、予め準備された文書群における読み推定対象単語との共起関係を用いて共起スコアを求める。そして、仮説選択部105は、共起スコアに基づき、複数の読み仮説から1つ以上の読み仮説を選択する。ここで、共起スコア計算部103は、読み推定対象単語および読み仮説の双方が現れる文書の数のみならず、該文書内における読み推定対象単語と読み仮説との間の距離を上記共起関係として求め、当該求めた共起関係に基づき共起スコアを求める。
(もっと読む)
音響モデル学習用ラベル作成装置、その方法及びプログラム
【課題】既存音声DBに対し、音声データを追加する場合に、効率良く、音素環境カバレッジの向上を図ることを可能とする。
【解決手段】音響モデル学習用の既存音声DB10中のラベルから既存音声DB音素環境頻度を計算して出力する第1の音素環境頻度計算部23と、元テキストDB30中のテキストから元テキストDB音素環境頻度を計算して出力する第2の音素環境頻度計算部33と、既存音声DB音素環境頻度と元テキストDB音素環境頻度とから、既存音声DB10に含まれず、元テキストDB30に含まれている新出音素環境を抽出し、その抽出した新出音素環境を追加収録音素環境として出力する新出音素環境抽出部35と、元テキストDB30から追加収録音素環境を含むテキストを選択し、選択したテキストを追加収録用ラベルセットとして出力するテキスト選択部36とよりなる。
(もっと読む)
1 - 20 / 166
[ Back to top ]