
Fターム[5D015GG01]の内容
Fターム[5D015GG01]に分類される特許
1 - 20 / 134
放送受信システム
発音辞書作成装置、発音辞書の生産方法、およびプログラム
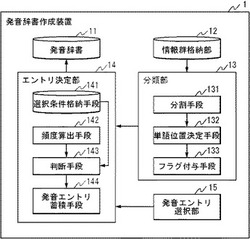
【課題】多様な発音変化、特に単語の位置に依存して生起する発音変化に対応できる発音辞書が存在しなかった。
【解決手段】一の言語の単語情報と、当該単語情報の単語情報群内における位置示す分類フラグと、単語の発音情報とを有する1以上の発音エントリを格納し得る発音辞書と、単語情報群と発音情報群との組である情報群を1組以上格納し、1以上の単語情報群を単語に分割し、単語の位置を特定する分類フラグを決定し、単語情報に対応付ける分類部と、単語情報と分類フラグごとに、当該単語情報と当該分類フラグとに対応する各発音情報の頻度を算出し、頻度が予め決められた条件を満たすほど高い発音情報を有する発音エントリを選択して、前記発音辞書に蓄積するエントリ決定部とを具備する発音辞書作成装置により、多様な発音変化、特に単語の位置に依存して生起する発音変化に対応できる発音辞書を作成できる。
(もっと読む)
言語モデル切替装置およびそのプログラム

【課題】少ない計算量で入力音声の話題を高精度に推定し、また話題の変化にも追従しながら、話題の推定結果に応じた最適な言語モデルを選択する。
【解決手段】話題特徴量記憶部は、言語表現の出現頻度の特徴を表わす話題特徴量データを話題毎に記憶する。フィードバック特徴量生成部は、音声認識結果データに基づいて言語表現の出現頻度の特徴を表わすフィードバック特徴量データを生成する。類似度計算部は、フィードバック特徴量データと話題特徴量記憶部から読み出した話題特徴量データとに基づく類似度を計算し、類似度に基づいて音声認識結果データの話題を推定する。言語モデル切替制御部は、類似度計算部によって推定された話題に対応する言語モデルを使用して入力音声を音声認識処理するよう言語モデルを切り替える。
(もっと読む)
音声認識装置および音声認識プログラム
【課題】話題に応じて、高精度な音声認識結果を得る。
【解決手段】音声データに基づいて音響特徴量を算出する音響分析部50と、音響特徴量と発音ネットワークに対応する音響モデルとに基づき言語表現ごとの音響スコアを求め、また言語スコアを求め、音響スコアと言語スコアとに基づいて正解候補単語列を探索して認識結果テキスト情報を生成する正解単語探索部60と、話題情報から認識結果テキスト情報に対応する発話対応テキストを抽出する話題トラッキング部80と、話題情報から、発話対応テキストを含む発話相当付近テキストを抽出し、発話相当付近テキストに関連する関連テキスト情報をテキスト情報源2から取得し、言語モデルを関連テキスト情報に基づき適応化して更新する言語モデル適応化部90と、更新した際に適応化言語モデルに基づいて発音ネットワークおよび言語スコアメモリを更新する更新部62とを備える。
(もっと読む)
音素ラベリングデータ音素継続時間長変換方法とその装置とプログラム
【課題】少量の音素ラベリングデータから新音素体系の大量の音素ラベリングデータを精度良く生成する音素ラベリングデータ音素継続時間長変換装置を提供する。
【解決手段】音素継続時間長分布推定部は、変換対象話者の新音素体系における少数の音素ラベリングデータである参照ラベリングデータと、複数話者のある音素体系における音素種別の音素継続時間長の平均値・分散値を、統計的に信頼できる値として得ることが可能な数の複数話者ラベリングデータを入力として、参照ラベリングデータを複数話者ラベリングデータで直線回帰し、複数話者ラベリングデータの全ての音素種別に対応する変換対象話者の音素継続時間長の平均値と分散値である音素継続時間長分布を求め、1個の音素継続時間長に対して複数の音素情報を持つ音素ラベリングデータを、音素情報毎に時間長を分割して新音素ラベリングデータとして出力する。
(もっと読む)
音声命令語処理装置及びその方法
【課題】使用者との相互作用(Interaction)に基づき音声命令語テーブルを更新することにより、別の音声命令語を入力する過程を必要とせずに、音声認識率を高める音声命令語処理装置及びその方法を提供する。
【解決手段】
本発明は、音声命令語テーブルを格納している格納手段、使用者から音声命令語の入力を受ける音声命令語入力手段、前記音声命令語テーブルに基づき、前記音声命令語入力手段を介して入力された音声命令語を認識する音声命令語認識手段、及び前記音声命令語認識手段が非正常音声命令語と認識した場合、前記入力された音声命令語に係る類似命令語を前記使用者に提供し、前記使用者から選択された類似命令語に前記入力された音声命令語をリンクさせ、前記音声命令語テーブルを更新する音声命令語処理手段を含むことを特徴とする。
(もっと読む)
音声認識装置、音声認識方法及び音声認識プログラム
【課題】検索対象語が発声された箇所を音声データから検索して抽出するにあたり、検索対象語の派生語を棄却したり、一部の派生語のみを出力対象とすることを可能とする。
【解決手段】検索対象語取得部12は指定された検索対象語を取得し、第1認識辞書16に登録する。派生語取得部14は、検索対象語の品詞と対応付けられた派生語生成ルールを派生語辞書28から読み出し、読み出したルールに基づき検索対象語の派生語を生成すると共に、個々の派生語が出力対象か棄却対象かを表す出力/棄却情報を設定して第2認識辞書18に登録する。音声認識部20はTV番組DB24に記憶されている映像データから検索対象語又は派生語が発声された箇所を音声認識によって検出し、検出した箇所のうち棄却対象の派生語の発声箇所を棄却し検索結果として出力する。
(もっと読む)
情報処理装置およびプログラム
【課題】複数の言語で設定されたガイダンス情報から、利用者の理解可能な言語に合わせたガイダンス情報を特別な選択操作をさせることなく選択可能とする。
【解決手段】情報処理装置は、複数の言語で設定されたガイダンス情報を一定の時間間隔で各言語を切り替えて出力する情報出力手段と、各言語を切り替えながらガイダンス情報を出力している際に、ガイダンス情報に対する応答を検出する応答検出手段と、ガイダンス情報に対する応答を検出した言語を、処理を実行する言語として確定する処理言語確定手段と、を備える。
(もっと読む)
音処理装置および音処理方法
【課題】日常音のモデルの自動的な更新を可能とする。
【解決手段】日常音を特性に基づきクラスタに分類し、クラスタに基づき異常音の判定を行う。クラスタをガウス分布の表現に変換したガウス分布を決定するパラメータを、新たに採取した採取音の特性を用いて更新する。更新の際に、採取音の特性がガウス分布に含まれる確率が、パラメータに決定されるガウス分布に含まれる確率を示す値で表される学習閾値の範囲内にある場合に、パラメータの更新を行う。また、採取音の特性がガウス分布に含まれる確率が、学習閾値よりも低い確率を表す異常音検出閾値未満である場合に、採取音が異常音であると判定する。
(もっと読む)
音響モデル学習装置、および音響モデル学習方法
【課題】マイナーな言語において学習データが十分ではない音響モデルを用いた音声認識の精度は低かった。
【解決手段】第一言語の第一音響モデルと、第二言語の第二音響モデルと、第一言語の第一発音辞書と、第二言語の第二音素関連情報を選択し、第一単語発音情報が有する音素識別子列に含まれる音素識別子を選択された第二音素関連情報が有する音素識別子に置換して、仮第一単語発音情報を構成し、第一音響モデルと第一発音辞書に仮第一単語発音情報を加えた仮第一発音辞書とを用いて、音声認識処理を行い1以上の認識結果を取得し、仮第一単語発音情報の置換数情報を取得し、置換数情報が大きい場合に第二言語の音素情報と置換された第一単語発音情報の音素識別子とを対応付けた新第一音素関連情報を構成し、新第一音素関連情報を第一音響モデルに蓄積する音響モデル学習装置により、数多くの言語の音響モデルを効率よく構築できる。
(もっと読む)
車両の統合操作装置による携帯端末の遠隔的な操作方法、および車両の統合操作装置
【課題】音声を使用して、統合操作装置からの携帯端末を制御するための方法と装置とを提供する。
【解決手段】統合操作装置100は、携帯端末120の現在のユーザーインターフェース(UI)画面122、222、262の画像表現を受け取る。統合操作装置100は、現在のUI画面122、222、262の画像表現を調べることにより、入力機構124−130、224−234、264−274の候補の位置を決定する。入力機構124−130、224−234、264−274の候補は文字認識処理を用いて調べられる。これにより、入力機構124−130、224−234、264−274のための音声認識コマンドが決定される。決定された音声認識コマンドと、それらのUI画面における位置は、音声認識データベースに格納される。それらは、音声認識の間に発声された音声コマンドで検索され、関連付けられる。
(もっと読む)
音声認識装置及び車載システム
【課題】 音声認識装置の作動制御が破綻してしまうことを抑制する。
【解決手段】 ユーザが触れて操作するトークスイッチの操作回数(クリック回数c)に基づいて音声認識エンジンが参照すべき認識辞書を選択する。これにより、音声の誤認識に起因して参照すべき認識辞書の選択ミスが発生することはないので、音声認識装置の作動制御が破綻してしまうことを抑制することができる。
(もっと読む)
広告配信システム、広告配信方法及び広告配信プログラム
【課題】デジタルサイネージにおいて配信した広告のターゲット層に属する視聴者からのフィードバックをより適切に収集して利用することができる広告配信システムを提供する。
【解決手段】広告配信システムは、顧客情報を記憶する顧客情報記憶手段と、広告を表示する広告表示手段と、前記広告を視聴する視聴者の会話を入力する音声入力手段と、前記入力された会話に対して音声認識を行う音声認識手段と、前記音声認識された音声認識結果を収集する収集手段と、前記収集した音声認識結果に基づいて前記顧客情報記憶手段に記憶されている顧客情報を更新する更新手段と、を備える。
(もっと読む)
電子機器及び制御方法
【課題】複数の動作モードのいずれかに設定可能な場合に、各動作モードにおいて音声認識による操作性を向上させる電子機器及び制御方法を提供する。
【解決手段】携帯電話機1は、通常モードで起動可能な複数の機能と音声認識時に参照される当該機能の読み仮名とがそれぞれ対応付けられた通常辞書データ71、及びかんたんモードで起動可能な複数の機能と音声認識時に参照される当該機能の読み仮名とがそれぞれ対応付けられたかんたん辞書データ72を記憶する記憶部70と、音声認識機能起動時において、通常モード又はかんたんモードの内のいずれに設定されているかを判定するモード判定部50と、通常モードに設定されていると判定された場合には通常辞書データ71を参照して音声認識を行い、一方でかんたんモードに設定されていると判定された場合にはかんたん辞書データ72を参照して音声認識を行う音声認識部60と、を備える。
(もっと読む)
音声処理システム及び方法
【課題】学習とテストとの間の話者ミスマッチ及び環境ミスマッチを解決する音声処理。
【解決手段】音響モデルをミスマッチした音声入力に適応させる。適応させることは、話者の環境と、音響モデルがその下で学習された環境との間の相違を主としてモデリングするためのミスマッチ関数fと、ミスマッチした話者入力の話者の間の相違を主としてモデリングするための話者変換Fとを使用して、y=f(F(x,v),u)となるように、ミスマッチした話者入力からの音声を、音響モデルを学習するために使用される音声に関連付けることと、u及びvを同時に推定することを含む。ここで、yは、ミスマッチした話者入力からの音声を表し、xは、音響モデルを学習するために使用される音声であり、uは、環境の変化をモデリングするための少なくとも一つのパラメータを表し、vは、話者の間の相違をマッピングするために使用される少なくとも一つのパラメータを表す。
(もっと読む)
情報検索手法による統一化されたタスク依存の言語モデルの生成
【課題】タスク独立のコーパスから言語モデルを生成するための方法(20)が提供される。
【解決手段】一実施例では、タスク依存の統一化された言語モデル(140)が生成される。統一化された言語モデル(140)には、ノンターミナルを持つ複数の文脈自由文法(144)およびそこに組み込まれた同一のノンターミナルの少なくともいくつかを持つハイブリッドNグラムモデル(142)が含まれる。
(もっと読む)
車載用電子装置およびその音楽データの音声認識辞書生成方法
【課題】 音声による指示に基づいて楽曲選択を可能とするオーディオ再生機能を備えた「車載用電子装置およびその音楽データの音声認識辞書生成方法」において、異なるデバイスに格納されている音楽データに対する音声認識辞書の作成が競合した場合の解決策を提供する。
【解決手段】 HDD内の音楽データおよび接続された外部デバイス内の音楽データから、楽曲選択のための音声認識辞書を生成する際に、音声認識辞書の生成における音楽データ格納デバイス単位での辞書生成進捗度を測定し、一方のデバイスの音楽データに対して音声認識辞書が生成されているときに、他方のデバイスの音楽データに対する音声認識辞書の生成要求がなされた場合に、その辞書生成進捗度に応じて、優先的に音声認識辞書を生成する音楽データの格納デバイスを決定し、決定された音楽データ格納デバイスを、その音楽データの音声認識辞書の生成が優先的になるように処理の対象デバイスを切換える。
(もっと読む)
音響モデル構築装置、音声認識装置、音響モデル構築方法、およびプログラム
【課題】学習データが十分ではない音響モデルを用いた音声認識処理の精度は低い。
【解決手段】一の言語の音響モデルを格納している音響モデル格納部と、1以上の他の言語の1以上の音素の音声データを音声データ格納部と、各音素識別子の音素頻度を取得する音素頻度取得部と、音素頻度に関する条件に各音素頻度を適用し、音素頻度が条件を満たすほど低いか否かを判断する判断部と、条件を満たすほど音素頻度が低い1以上の各音素識別子に対応する音素識別子を有する1以上の音声データを取得する音声データ取得部と、取得された1以上の各音声データから1以上の特徴量を取得し、1以上の特徴量と音素識別子とを有する1以上の他言語音素情報を取得する学習部と、1以上の他言語音素情報を蓄積する音響モデル構築部とを具備する音響モデル構築装置により、数多くの言語の音響モデルを効率よく構築できる。
(もっと読む)
信号分類装置
【課題】多量のメモリを用いずに分類可能な信号分類装置を提供する。
【解決手段】 入力された信号に含まれるN個の識別対象の特徴量を取得する取得部と、 前記特徴量毎に、前記特徴量からk個(1≦k≦N)の前記特徴量を第1近傍特徴として選択する第1の選択部と、互いに類似する前記特徴量から特徴群を生成し、取得したN個の前記特徴量から異なる前記特徴群に属するu個(1≦k+u≦N−2)の前記特徴量を第2の近傍特徴として選択する第2の選択部と、前記特徴量の類似性を比較するための閾値と、前記特徴量毎に算出した周辺密度とを用いて、同じ分類となる前記特徴量を決定する決定部と、前記特徴量の決定結果から分類を行う分類部と、前記閾値を管理する管理部と、を備える。
(もっと読む)
言語モデル生成装置、そのプログラムおよび音声認識システム
【課題】本発明は、精度が良い音声認識を可能とする言語モデルを生成する言語モデル生成装置を提供する。
【解決手段】言語モデル生成装置1は、学習テキストを記憶する学習テキスト記憶部11と、同意単語・連鎖語選択部21と、学習テキストに含まれる単語または連鎖語の少なくとも一方の出現確率を示す言語モデルを生成する言語モデル生成部22と、同一の意味を有する同意語について、言語モデルの出現確率に基づいて確率値を算出し、同意語の出現確率をこの確率値で更新する言語モデル変換部23と、発音辞書を記憶する発音辞書記憶部17と、発音辞書を変換する発音辞書変換部24とを備える。
(もっと読む)
1 - 20 / 134
[ Back to top ]