
Fターム[5D015GG02]の内容
Fターム[5D015GG02]に分類される特許
1 - 20 / 37
放送受信システム
ユーザの発話を認識するための方法及び装置
【課題】音声認識とクオリファイアとを用いた、ユーザの発話を認識するための方法及び装置の実現。
【解決手段】装置を用いてユーザの発話を認識するための方法は、発話のある集合モデルが予め記憶され、音声認識を行うために、ユーザの発話が受信され、ユーザの発話が予め記憶されたモデルと比較され、比較に基づいて認識決定が行われ、装置に触れることによって、ユーザが比較を限定するクオリファイアを提供することができ、クオリファイアが装置のメニュー構造中の項目を識別し、ユーザが与えたクオリファイアに基づいて記憶されたモデルの中から部分集合モデルが選択され、部分集合モデルがメニュー構造の下位項目を識別し、ユーザの発話を部分集合モデルと比較することによって認識決定を行うための比較を行う。
(もっと読む)
携帯電子機器

【課題】読み仮名の変更に伴う認識辞書の更新をユーザに意識させることなく行うことができる携帯電子機器を提供すること。
【解決手段】携帯電話機1は、所定の処理と編集可能な読み仮名とが対応付けられたアドレス帳データを記憶するアドレス帳DB51と、音声認識の結果と照合する読み仮名の選択肢を含む認識辞書データを、アドレス帳データと関連付けて記憶する認識辞書DB52と、音声認識結果と照合された読み仮名に対応する所定の処理を実行する実行部41と、アドレス帳データと認識辞書データとの読み仮名の差分を示す更新データを記憶する更新情報DB53と、アドレス帳データが更新された場合に、当該更新の内容を示す更新データを更新情報DB53へ記憶し、当該更新後の所定のタイミングで、更新データに基づいて認識辞書データを更新する更新部42と、を備える。
(もっと読む)
ユーザ辞書作成システム、方法、及び、プログラム
【課題】新たな単語をユーザ辞書に登録する際に、誤認識の発生を回避しつつ、登録の効率が高い、ユーザ辞書登録に関するシステム、方法およびプログラムを提供する。
【解決手段】ユーザ辞書作成システムは、文字列を入力するテキスト入力手段11と、入力された文字列から未知語を抽出する未知語抽出手段22と、抽出された未知語と辞書に既に登録されている登録単語との類似度を算出する類似度算出手段32と、類似度が所定値以上のときには、未知語の前後の単語の情報を含む環境情報を抽出する環境情報抽出手段33と、未知語及び環境情報を辞書に登録する登録手段41とを備える。
(もっと読む)
音声認識装置およびデータ更新方法
【課題】地図情報の更新の際に、装置への負荷をかけずに音声認識の差分情報を端末に送信し、音声認識装置を更新する。
【解決手段】サーバと通信網によって接続された端末に備わる音声認識装置であり、端末は目標物を含む地図情報を保持し、音声認識装置は地図情報に含まれる目標物の名称に対応した語彙を含む識別用データを備え、更新対象とされる地図情報の領域を示す更新領域情報と領域の更新情報とをサーバへ送信し、サーバは端末から送信された更新領域情報が示す領域の識別用データが、更新情報が示す時点より後に変更されている場合は、その時点における識別用データと最新の識別用データとの差分情報を生成し、更新領域情報が示す領域の地図情報と差分情報とを端末に送信し、端末はサーバから送信された地図情報に基づいて地図情報を更新し、音声認識装置は差分情報に基づいて端末に保持された識別用データを更新する。
(もっと読む)
情報処理装置及び音声認識辞書生成方法
【課題】音声認識辞書に登録される不要な単語を減らすことが可能な「情報処理装置及び音声認識辞書生成方法」を提供すること。
【解決手段】音声認識用辞書を生成する機能を備えた情報処理装置において、記憶手段に格納されている楽曲情報の種別を判定するステップ(S12)と、楽曲情報の種別に応じて、前記記憶手段に格納されている前記楽曲情報の文字列に対して音声認識辞書用の文字列に変換する変換規則を選択するステップと、選択された変換規則に従って、楽曲情報を音声認識辞書用の文字列に変換するステップ(S16〜S19)と、変換された文字列を音声データに変換して読みデータを取得するステップ(S20)と、読みデータを前記楽曲情報と関連付けて音声認識用辞書に登録するステップと、を有する。
(もっと読む)
音声認識装置、音声認識方法及びコンピュータプログラム
【課題】音声認識処理の精度を向上させる音声認識装置、音声認識方法及びコンピュータプログラムを提供する。
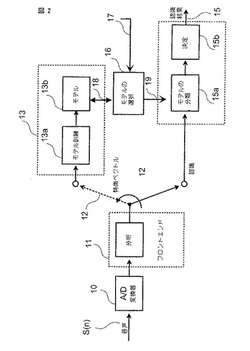
【解決手段】単語辞書13cに登録してある認識単語に棄却単語を付与する場合、音声分析部10aは、複数の棄却単語候補のそれぞれに対する複数の音声データのそれぞれから特徴パラメータを抽出する。音声照合部10bは、音声分析部10aによって抽出された特徴パラメータと、単語モデル生成部10cによって生成された各認識単語の単語モデルとの尤度を算出する。結果判定部10dは、各特徴パラメータに対して、尤度が最も高い単語モデルを認識結果とする。棄却単語生成部10eは、各特徴パラメータに対する認識結果に基づいて、棄却単語候補毎に、棄却単語を登録したい認識単語が認識結果であった発声数を計数し、計数した発声数が最も多い棄却単語候補を、前記認識単語に対応する棄却単語として単語辞書13cに登録する。
(もっと読む)
辞書修正装置、システム、およびコンピュータプログラム
【課題】必要のない読みを自動的に判定して発音辞書から削除することで音声処理における正解率向上やサーチ時間短縮を目的とし、そのための辞書修正装置を提供する。
【解決手段】辞書修正装置が、第一閾値を記憶する閾値記憶部と、表記と、読みと、当該表記および当該読みが発生する頻度である発生頻度との組をエントリとして有する頻度データを読み込み、前記閾値記憶部から前記第一閾値を読み込み、前記発生頻度が前記第一閾値以上である前記エントリが存在する前記表記に関して、その表記を有して且つ前記発生頻度が所定の第二閾値以下となるような前記エントリを、削除対象エントリとして抽出する削除対象エントリ抽出部と、表記と読みとの組を有する発音辞書データから、前記削除対象エントリ抽出部によって抽出された前記削除対象エントリに対応するデータを削除して、修正発音辞書データを作成する辞書修正処理部を具備する。
(もっと読む)
音声認識制御装置
【課題】音声認識率を向上させ、且つ誤認識及びこれによる誤動作を抑制する。
【解決手段】ユーザが発話する音声が所定の音声コマンド又は当該音声コマンドをなまけて発話した時の音声に対応するなまけコマンドに該当すると認識した場合、認識した音声コマンド又はなまけコマンドに対応する制御を実行する音声認識制御装置10であり、音声コマンド及びなまけコマンドの照合用データを格納する照合用データ記憶部14と、ユーザが発話する音声を入力し、この音声を所定の音声信号に変換する音声入力部40と、変換された音声信号と照合用データ記憶部14に格納された照合用データとを照合して、入力された音声が所定の音声コマンド又はなまけコマンドに該当するか否かを判定する音声認識部12と、音声認識部12による判定結果に基づいてユーザが必要のないなまけコマンドを特定し音声認識部12の照合対象から削除する照合対象削除部16とを備える。
(もっと読む)
動画検索方法および動画検索システム
【課題】 インターネットなどの動画サイト上に登録された大量の動画に対するキーワード検索について、時間の経過等による検索キーワードの陳腐化を防ぎ、時代に即したキーワードを用いて動画を検索することを可能にする。
【解決手段】 インターネットなどの動画サイト上に登録された大量の動画の検索について、読み仮名を入力する動画登録インタフェースと、該読み仮名から生成された音素列を基に動画データベース上の動画ファイルについて音声認識を行う音声認識部と、音声認識結果から得られた新たな語彙を追加するインデックスデータベースと各データベースへSQL文を発行することなどによりシステム全体を制御するデータ処理部とを有する構成である。
(もっと読む)
音声対話装置
【課題】従来、大語彙検索用音声対話インタフェースは、検索精度の向上ためジャンルにより検索対象を絞るが、検索失敗時に対象外ジャンルの発声か、装置の誤認識かが不明、複数回操作で絞込む場合、絞込み用のジャンル名等検索対象分類数が多いと選択が困難であり、また言い方が多い場合に対応が困難であった。
【解決手段】入力音声を音声認識手段で音声認識し、音声認識結果によりジャンル推定辞書参照し、ジャンル推定手段で対応ジャンルを推定し、検索手段が音声認識結果と属性条件に基づき、検索データベースから検索候補を取得し、検索の候補とジャンル推定結果をユーザが選択可能な動作とともに提示手段が示し、上記検索手段は、検索の候補が目的外のときユーザが選択したジャンル属性に応じて検索対象の属性条件を変更して検索データベースから候補を再度検索する。
(もっと読む)
音声認識装置及びコンピュータプログラム
【課題】発話者と他者との会話が存在し得る環境下で、発話者の発話部分のみを信頼性高く音声認識する。
【解決手段】音声認識装置40は、音響モデル記憶部64と、予め想定された発話に対応するテキストDB44から作成されたバイグラム、トライグラム言語モデルをそれぞれ記憶する記憶部66、68と、音響モデル及び言語モデルを用いた統計的手法で音声認識を行ない、N−ベスト仮説を出力する音声認識部42と、N−ベスト仮説に含まれる各単語につき、一般化単語事後確率(GWPP)を算出するGWPP計算処理部76と、GWPP計算処理部76により算出されたGWPPがしきい値以下の単語を削除する単語削除部78と、単語が削除された後の各仮説に含まれる単語の一般化単語事後確率に基づいた再スコアリングを各仮説に対し行ない、上位の所定個数の仮説を音声認識結果として出力する再スコアリング部82とを含む。
(もっと読む)
車載表示装置
【課題】ユーザの言葉を確実に音声認識することができる車載表示装置を提供する。
【解決手段】マイク19に設けられたPTT( Press to Talk )スイッチ19aを押下すると、目的地ボタンと経由地ボタンとが表示モニタ16に表示される。目的ボタンを押圧すると、音声認識部110で音声認識するときに使用する辞書の範囲が、目的地を設定するときや変更するときに発せられる言葉など、目的地に関する言葉の範囲に限定される。そして、押圧を止めると限定が解除される。経由地ボタンを押圧すると、音声認識部110で音声認識するときに使用する辞書の範囲が、経由地を設定するときや削除するときに発せられる言葉など、経由地に関する言葉の範囲に限定される。そして、押圧を止めると限定が解除される。
(もっと読む)
施設検索装置
【課題】音声による施設検索を効率的に行うことができる施設検索装置を提供する。
【解決手段】施設名の認識語彙を記憶した固定施設辞書121aと、固定施設辞書に記憶されている施設名の認識語彙の一部が動的に記憶される動的施設辞書121bと、目的地として設定された地点を目的地履歴として記憶する目的地履歴記憶手段17と、この記憶されている目的地履歴によって示される地点を含む地域に属する施設名の認識語彙を固定施設辞書から読み出して動的施設辞書に格納する施設辞書変更手段18と、音声を入力する音声入力手段11と、入力された音声を、動的施設辞書を参照することにより認識して施設名を出力する音声認識手段13と、施設情報を記憶する施設データベース14と、音声認識手段から出力される施設名に対応する施設情報を施設データベースから検索する施設検索手段15と、検索された施設情報を出力する検索結果出力手段16を備えている。
(もっと読む)
車載ナビゲーションシステム
【課題】これから車両が走行しようとする経路上の交通ニュースをユーザに適切に提供する。
【解決手段】車載ナビゲーションシステム1は、経路を計算すると、その計算した経路上の地名(例えば市町村名など)や交通設備名称(例えばインターチェンジ名など)を記憶し、ラジオ放送局から送信されてラジオチューナー12により受信されたラジオ放送の音声を音声認識し、予め記憶されている交通情報に関係する語彙(例えば「混雑」や「通行止め」など)と先に記憶した地名や交通設備名称とを含むラジオ放送の音声を交通ニュースとして抽出し、その抽出した交通ニュースを再生してスピーカ14から出力させたり経路を再計算したりする。
(もっと読む)
キーワード選択方法、音声認識方法、キーワード選択システム、およびキーワード選択装置
【課題】様々な発話内容を待ち受けることができるキーワードを選択すること。
【解決手段】音声認識部112は、ディスク151に記録された音声認識対象単語の中から音響的な共通部分をキーワードとして選択し、選択したキーワードを用いてマイク130を介して入力された発話音声を認識する。
(もっと読む)
音声認識装置および音声認識プログラム
【課題】ユーザが煩わしい操作をしなくとも、認識性能を向上することができる音声認識装置および音声認識プログラムを提供する。
【解決手段】複数の語彙を予め格納した語彙辞書記憶部11と、認識対象語彙を抽出する語彙辞書管理部12と、受け付けた音声に基づいて、認識対象語彙との一致度を算出する照合部13と、一致度の算出結果から最もスコアの良かった語彙を認識結果として出力する結果出力部14と、監視制御部15の監視結果に応じて、抽出基準情報を変更する抽出基準情報管理部12cとを備え、語彙辞書記憶部11は、更に、認識対象語彙を抽出する際の尺度となる尺度情報20を格納した尺度情報記憶部と、認識対象語彙を抽出する際の認識対象語彙20の基準を示す抽出基準情報24を格納した抽出基準情報記憶部とを含み、抽出基準情報24が変更されることにより、語彙辞書管理部12は、認識対象語彙の数を増減する。
(もっと読む)
電子機器
【課題】音声認識の誤認識による誤作動を未然に防止することができる電子機器を提供することである。
【解決手段】ディジタルテレビ受像機100において、表示制御手段(CPU121、表示制御プログラム123c)によって、音声認識結果に基づくコマンド情報に対応する制御内容を表示手段(受像部10)に表示し、音声認識結果に基づくコマンド情報に対応する制御内容が表示手段に表示開始されてからの所定の待ち時間内に、指定手段(音声情報取得部11)による制御内容に対する制御を中止する旨の指定がない場合、制御手段(CPU121、制御プログラム123d)によって、所定の待ち時間経過後に音声認識結果に基づくコマンド情報に基づいて制御を行い、中止する旨の指定がある場合、音声認識結果に基づくコマンド情報に基づく制御を中止する。
(もっと読む)
音声認識装置、音声認識方法、音声認識プログラム
【課題】 メモリに制約のある装置において、補助記憶装置からの、単語辞書を読み込みによる音声認識処理の遅延を削減することができる音声認識装置を提供する。
【解決手段】音声に含まれる複数の連続する単語を認識する音声認識装置は、音響モデル11を読み込む音響モデル読み込み部5と、辞書データ12から、必要なデータを読み込む辞書管理部9と、音響モデル11を用いて、辞書データ12が表す単語群と、入力された前記音声とを照合することで、連続する単語を順次認識する認識部7とを備え、辞書データ11は、単語の語頭を示す語頭辞書と、語末を示すデータが記録された語末辞書群とを含み、認識部7が認識した単語に応じて、語末辞書および/または語頭辞書を読み込み、認識部7は、辞書管理部9が語末辞書および/または語頭辞書を読み込む間に、後に続く音声と、語頭辞書に含まれる単語の語頭とを照合する。
(もっと読む)
音声認識装置
【課題】音声認識率を向上させる。
【解決手段】ユーザが発したコマンドと同一機能に分類された他の音声認識コマンドがコマンド一覧情報にあるか否かを判定し(S108)、ユーザが発したコマンドと同一機能に分類された他の音声認識コマンドがコマンド一覧情報にあると判定(S108でYESと判定)した場合、コマンドと同一機能に分類された他の音声認識コマンドをコマンド一覧情報から削除する(S112)。
(もっと読む)
1 - 20 / 37
[ Back to top ]