
Fターム[5D015JJ07]の内容
音声認識 (5,191) | パターン照合によらない認識 (78) | 音声パターンの出現確率を利用するもの (39)
Fターム[5D015JJ07]に分類される特許
1 - 20 / 39
適応化音響モデル生成装置及びプログラム
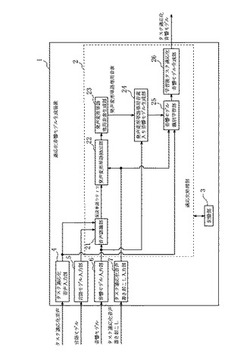
【課題】第1タスクの音声で学習して生成された音響モデルを用いて該第1タスクとは異なる第2タスクの音声に適応化させた音響モデルを生成する適応化音響モデル生成装置及びプログラムを提供する。
【解決手段】本発明の適応化音響モデル生成装置(1)は、第1タスクの音響モデルと、第2タスクの音声の音声認識用の言語モデルとを用いて、第2タスクの音声について音声認識処理を実行し、認識結果としての仮説単語ラティスを生成する音声認識手段(21)と、仮説単語ラティスと第2タスクの音声用の書き起こしを用いて、第2タスクの音声中の発声変形の部分を特定し、該発声変形の単語専用の音素を生成する発声変形単語専用音素生成手段(22,23)と、発声変形の単語専用の音素を第1タスクの音響モデルに付加して学習し、タスク適応化音響モデルを生成するタスク適応化音響モデル生成手段(24,25,26)とを備える。
(もっと読む)
隠れマルコフモデル探索装置及び方法及びプログラム

【課題】 離散型隠れマルコフモデルの探索コストを低減する。
【解決手段】 本発明は、シーケンスを確率密度関数に従う発生モデルを有する状態の遷移として表現する探索対象となる隠れマルコフモデルを格納するデータ記憶手段から読み出された探索対象である隠れマルコフモデルについて、近似の粒度を固定して、それぞれの粒度に対する尤度を計算し、計算された尤度と所定の閾値とを比較して該尤度が該閾値より小さくなるまで該尤度計算を繰り返し、該閾値より小さくなった尤度を新たな解候補として探索結果記憶手段に格納する。
(もっと読む)
オーディオ信号補正装置及びオーディオ信号補正方法
【課題】入力オーディオ信号の高音質化に優れたオーディオ信号補正装置を提供する。
【解決手段】オーディオ信号補正装置は、入力オーディオ信号から特徴パラメータを算出する特徴パラメータ算出手段と、前記特徴パラメータと複数の参照モデルとを照合し、前記特徴パラメータが前記複数の参照モデルの中の所定の参照モデルに属する尤度を算出する照合手段と、前記尤度が閾値条件を満たす場合に、前記所定の参照モデルが示すオーディオ信号の種類を前記特徴パラメータが示すオーディオ信号の種類と判定する第1判定手段と、前記尤度が前記閾値条件を満たさない場合に、前記特徴パラメータから音声成分と非音声成分の混合度合いを判定する第2判定手段と、前記第1判定手段により判定された前記オーディオ信号の種類に応じて前記入力オーディオ信号を補正し、また前記混合度合いに応じて前記入力オーディオ信号を補正する補正手段と、を備えている。
(もっと読む)
音声認識装置及び音響モデル作成装置とそれらの方法と、プログラムと記録媒体
【課題】突発性雑音の影響を受け難い音声認識装置と音響モデル作成装置を提供する。
【解決手段】GMM尤度計算部が、GMMと音声特徴量を照合してフレーム毎にGMM尤度を計算し、GMM尤度判定部が、GMM尤度が所定の範囲内であるか否かを判定してその判定結果とGMM尤度とを出力する。音声認識処理部は、所定の範囲内のフレームについては音声特徴量に対応する音響尤度に基づいて音声認識処理を行い、所定の範囲外のフレームについてはGMM尤度を音響尤度に代用して音声認識処理を行う。
(もっと読む)
言語モデル特定装置、言語モデル特定方法、音響モデル特定装置、および音響モデル特定方法
【課題】短時間で最適な言語モデルを判別する。
【解決手段】言語モデル特定装置100は、IDによって区別される複数の言語モデル(LM)から統合された統合LMを利用し、入力音声に対して音声認識を行う音声認識部102と、音声認識の結果の文字列に付されたIDに基づき、音声認識が複数のLMのうち何れのLMを用いて行われたかを判断する判断部103とを備える。好ましくは、各LMに含まれた「読み」フィールドに、当該LMを特定するIDをそれぞれ付与する第1ID付与部107および第2ID付与部109と、IDが付与された「読み」フィールドを含む各LMを統合し統合LMを生成するLM統合部106と、を更に備える。音声認識部102は、統合LMを利用し入力音声に対し音声認識を行い、複数のLMのうち何れかのLMを特定するIDが付された文字列を音声認識の結果として判断部103に出力する。
(もっと読む)
音声認識装置及びその方法
【課題】雑音下でも安定して音声認識を行う音声認識装置を提供する。
【解決手段】入力したノイジー音声から、ノイジー音声特徴ベクトルをフレーム毎に抽出し、前記ノイジー音声に重畳されたノイズに関するノイズ特徴ベクトルのノイズ特徴分布パラメータを推定し、前記ノイズ特徴分布パラメータと、予め記憶したクリーン音声特徴ベクトルの事前分布パラメータとから、アンセンテッド変換を用いて、前記クリーン音声特徴ベクトルと前記ノイジー音声特徴ベクトルの結合ガウス分布パラメータを算出し、前記結合ガウス分布パラメータを用いて、前記ノイジー音声特徴ベクトルから、前記クリーン音声特徴ベクトルの事後分布パラメータを算出し、前記事後分布パラメータと、予め記憶した単語の標準パターンとを前記フレーム毎に照合し、前記照合結果に基づいて前記ノイジー音声の単語列を出力する。
(もっと読む)
音響分析パラメータ生成装置とその方法と、それを用いた音声認識装置と、プログラムと記録媒体
【課題】音響分析パラメータ生成装置を高速・省メモリ化する。
【解決手段】この発明の音響分析パラメータ生成装置の出力確率計算部は、調整パラメータを用いて算出されたフレーム単位の音響特徴量と音響モデルとを入力としてフレーム毎の各状態の出力確率を計算する。スコア計算部が、出力確率の最尤状態系列を所定フレーム数に渡って累積して出力確率スコアを求める。スコア評価部は、出力確率スコアを評価して出力確率スコアが最大になる調整パラメータを最適調整パラメータ候補として出力する。最適調整パラメータ候補記録部が、その最適調整パラメータ候補を記録する。所定フレーム数に対して調整パラメータをそれぞれ出力した後に記録した最適調整パラメータ候補を調整パラメータとして出力する。
(もっと読む)
音声認識装置とその方法と、プログラムとその記録媒体
【課題】音声認識装置を高速・省メモリ化する。
【解決手段】この発明の音声認識装置は、特徴量算出部と、音響モデルパラメータメモリと、言語モデルパラメータメモリと、音声認識部と、フレーム内統計量蓄積部と、音響モデル更新部とを具備する。フレーム内統計量蓄積部は、音響特徴量と状態尤度と音響モデルとを入力としてフレーム毎に最尤状態の統計量を蓄積する。音響モデル更新部は、蓄積された統計量が所定値より大きい場合に音響モデルパラメータメモリの音響モデルを、蓄積された統計量を用いて求めた音響モデルに更新する。
(もっと読む)
学習装置、学習方法、及び、プログラム
【課題】複雑な対象について、適切な状態遷移モデルを得る。
【解決手段】初期構造設定部116は、状態遷移モデルの構造を、スパースな構造に初期化する。データ調整部112は、学習の進行に応じて、学習に用いられる時系列データを調整し、調整後の時系列データを出力する。パラメータ推定部113は、調整後の時系列データを用い、状態遷移モデルのパラメータを推定し、構造調整部117は、状態遷移モデルの構造を調整する。データ調整部112、パラメータ推定部113、及び、構造調整部117は、適宜処理を繰り返す。本発明は、例えば、HMM等の状態遷移モデルの学習に適用できる。
(もっと読む)
音声認識装置、方法、プログラム及びその記録媒体
【課題】音声認識処理を高速化する。
【解決手段】フレーム数決定部90が、フレーム数Kを状態jごとに適宜定める。例えば、自己遷移確率ajjが高いほど、状態jのフレーム数Kを大きくする。状態尤度計算部31が、状態jのフレームtについての状態状態尤度bj(Xt)を計算するときに、状態jのフレームt+1,…,t+Kについての状態尤度bj(Xt+1),…,bj(Xt+K)をついでに計算して状態尤度記憶部80に格納する。状態尤度参照部32が、状態尤度bj(Xt+1),…,bj(Xt+K)の何れかが必要になったときに、状態尤度記憶部80を参照して、その状態尤度を求める。
(もっと読む)
音声認識装置、方法、プログラム及びその記録媒体
【課題】音声認識処理を高速化する。
【解決手段】フレーム数決定部90が、フレーム数Kを状態jごとに適宜定める。例えば、尤度計算率qjが高いほど、状態jのフレーム数Kを大きくする。状態尤度計算部31が、状態jのフレームtについての状態状態尤度bj(Xt)を計算するときに、状態jのフレームt+1,…,t+Kについての状態尤度bj(Xt+1),…,bj(Xt+K)をついでに計算して状態尤度記憶部80に格納する。状態尤度参照部32が、状態尤度bj(Xt+1),…,bj(Xt+K)の何れかが必要になったときに、状態尤度記憶部80を参照して、その状態尤度を求める。
(もっと読む)
音声認識誤り分析装置、方法、プログラム及びその記録媒体
【課題】言語モデルにおいて認識誤りを起こしやすい部分を特定する。
【解決手段】言語モデルを用いて音声信号に対して音声認識処理を行い、認識単語列を割り当てる。認識単語列内の、その認識単語列に対応する正解単語列と一致しない1つ又は連続する複数の単語から構成される認識誤り単語列と、その認識誤り単語列及びその前後一単語から構成される認識誤り区間とを認識単語列から抽出する。認識誤り区間の最初の単語と、認識誤り単語列の最初の単語とから構成される開始部誤り二単語組を抽出する。認識誤り区間の最初の単語と、認識誤り単語列に対応する正解単語列の最初の単語とから構成される開始部正解二単語組を抽出する。言語モデルを用いて、開始部誤り二単語組と開始部正解二単語組の単語連鎖確率をそれぞれ計算する。開始部誤り二単語組の単語連鎖確率よりも単語連鎖確率が低開始部正解二単語組を抽出する。
(もっと読む)
分布共有化音響モデル作成方法、装置、およびそのプログラム
【課題】分布共有化音響モデルを迅速に作成可能とする。
【解決手段】分布間距離テーブル作成手段11が複数の基底分布から重複無く選んだ2つの基底分布の全てのペアを生成するとともに、当該ペアを構成する2つの基底分布の分布間距離を求めて、それぞれの分布ペアとその分布間距離との対応を示す分布間距離テーブルを作成し、N−best作成手段13が分布間距離テーブルから分布間距離が短い分布ペアから順に上位Nペアを抽出してN−bestリストを作成し、分布統合手段17と分布間距離テーブル18がN−bestリストの最上位の分布ペアを統合して1つの新しい分布を生成し、分布間距離テーブルを再構成する。そして、再構成した分布間距離テーブルに基づきN−best更新手段20がN−bestリストを更新し、その結果、最小分布間距離がしきい値以下であれば分布統合処理を継続し、しきい値以上であれば処理を終了する。
(もっと読む)
音素モデルをクラスタリングする装置、方法およびプログラム
【課題】類似する音素モデルを適切にクラスタリングする装置を提供する。
【解決手段】音素モデルを入力する入力部101と、入力された音素モデルを含むルートノードを生成するノード初期化部111と、子ノードを有さないノードに対してノードに含まれる音素モデルの集合を2つに分割した子集合の組の候補を生成する候補生成部112と、子集合の少なくとも一方が学習用の音声データが少ないことを表す判定情報が付与された音素モデルのみを含む候補を削除する候補削除部113と、子集合に含まれる音素モデル間の類似度の和を算出する類似度算出部114と、和が最大となる候補を選択する候補選択部115と、選択した候補に含まれる2つの子集合を含む2つのノードを生成するノード生成部116と、ノードに含まれる音素モデルの集合を単位として音素モデルをクラスタリングするクラスタリング部120と、を備えた。
(もっと読む)
パタン認識方法および装置ならびにパタン認識プログラムおよびその記録媒体
【課題】認識率を低下させることなく状態仮説を効率良く枝刈りして状態仮説数を削減できるパタン認識方法および装置ならびにパタン認識プログラムおよびその記録媒体を提供する。
【解決手段】探索部15の枝刈り部154は、状態遷移モデルの探索空間を複数の領域に分割する領域分割部154aと、同一時刻で遷移する状態仮説を前記分割された領域のいずれかに振り分ける状態仮説振り分け部154bと、前記分割された各領域の枝刈り条件を設定する枝刈り条件設定部154cと、前記分割された領域ごとに、同一領域内で尤度の低い状態仮説を探索対象から除外する領域別枝刈り部154dとを含む。
(もっと読む)
データ処理装置、データ処理方法、及びプログラム
【課題】誤差を適切に考慮した処理を行う。
【解決手段】本体学習モジュール101は、データDを学習する。誤差学習モジュール102は、データDと、本体学習モジュール101がデータDを再構成した再構成データDRとの誤差ΔDを学習する。また、本体学習モジュール101は、データDの入力があると、そのデータDを再構成して、再構成データDRを出力し、誤差学習モジュール102は、データDと、再構成データDRとの誤差データΔDを再構成して、再構成誤差データΔDRを出力する。そして、学習モジュール100は、再構成データDRと、再構成誤差データΔDRをとを加算して出力する。本発明は、例えば、ロボット等に適用できる。
(もっと読む)
ゲーム装置、ゲームの進行方法、およびゲーム進行プログラム、並びに音声認識装置、および音声認識方法
【課題】入力される不特定話者の音声言語に応じてキャラクタを探索し、捕獲し、収集するというゲーム内容に、特定の「言葉」あるいは「フレーズ」が入力された場合に限ってある特定のキャラクタが探索されるという興趣を加味したゲーム装置を提供する。
【解決手段】CPUコア11は、音声言語の再入力を促す画像表示に続いて再入力された音声言語のデジタル信号に対して音声解析エンジンが音声解析を実行し生成する、その再入力された音声言語の特徴情報に関するデータを、第2の解析結果のデータとして取得し、WORK RAM14の解析結果カウントバッファに格納する。CPUコア11は、最初の音声言語の入力に対する第1の解析結果と第2の解析結果とを照合し、両者が一致するか否かを判定する。両者が一致する場合その解析結果を正解として返す。一致しない場合、一致する解析結果が連続して2回取得されるまで音声言語の入力を繰り返し促す処理を行う。
(もっと読む)
知識源を組込むための確率計算装置及びコンピュータプログラム
【課題】利用可能なトレーニングデータを用いて,音声信号の音素の確率を頑健に計算することが可能な確率計算装置を提供する.
【解決手段】確率計算装置516は、統計的音響モデル及び知識源を利用して音声信号における各音素の確率を計算する。統計的音響モデル及び知識源はベイズネットワーク(BN)により示される因果関係を有し、BNは、クラスタノード及びセパレータノードを含むジャンクションツリーに対応する。本装置516は、局部的音響モデルR3,C1,L3の記憶装置520と、フレームの各々に対して観測データを計算するモジュールと、局部的音響モデルR3,C1,L3を利用して、観測データを発生する各音素の局部的確率を計算する右、中央、及び左コンテキスト計算装置570、572及び574と、局部的確率の関数として各音素の確率を計算するPDF計算装置576とを含む。
(もっと読む)
パターン認識装置、パターン認識方法、及びプログラム
【課題】状態数及び各状態の出力分布を自動的に決定して、時系列データの頑健なモデル化をすることができるパターン認識装置、パターン認識方法、及びプログラムを提供すること。
【解決手段】本発明に係るパターン認識装置1は、入力パターンの一部又は全部を入力ベクトルとしてニューラルネットワークに順次入力し、当該入力ベクトル、及び当該ニューラルネットワークに配置される多次元ベクトルで記述されるノードに基づいて、当該ノードを自動的に増加させる自己増殖型ニューラルネットワーク12を用いて、入力パターンの特徴量に応じたテンプレートモデルを生成するテンプレートモデル生成部10と、生成されたテンプレートモデルと入力パターンをマッチングして当該入力パターンを認識する認識部20とを有するものである。
(もっと読む)
統計的言語モデル生成装置及び方法、及びこれを用いた音声認識装置
【課題】強い言語的制約性を単音節単語に付与することにより、少ない単語数で未知語を単音節単語の列として正しく認識するための統計的言語モデルを生成する。
【解決手段】複数の単漢字列を含むテキスト中の各単漢字の読みを単音節単語に分割することにより、複数の単音節単語と、各単音節単語について単音節単語を含む単漢字の読みが音読みと訓読みのいずれであるかを示す読み種類とを求める手段と101;テキスト中での各単音節単語の出現回数と、連続する複数の単音節単語の組合せ毎の出現回数とを基に、組合せ毎の出現確率を計算する計算手段102と;複数の単音節単語と、各単音節単語の読み種類と、組合せ毎の出現確率とを含む統計的言語モデルを記憶する記憶手段122と;を具備する。
(もっと読む)
1 - 20 / 39
[ Back to top ]