
Fターム[5D015KK04]の内容
Fターム[5D015KK04]に分類される特許
1 - 20 / 119
対話装置
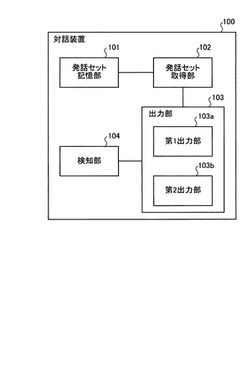
【課題】自然な対話を実現することを課題とする。
【解決手段】対話装置は、発話セット記憶部と、発話セット取得部と、第1出力部と、検知部と、第2出力部とを有する。発話セット記憶部は、第1発話と、第1発話に対する応答として想定されるユーザによる発話に対する応答の発話を表す第2発話とを含んだ発話セットを記憶する。発話セット取得部は、発話セットを取得する。第1出力部は、取得された発話セットに含まれる第1発話を出力する。検知部は、第1発話が出力された後のユーザによる発話を検知する。第2出力部は、ユーザによる発話が検知された場合に、取得された発話セットに含まれる第2発話を出力する。
(もっと読む)
音声処理装置

【課題】対話シナリオを実行する音声処理装置を使用している利用者が居眠りに陥った場合に、利用者を目覚めさせることが可能な音声処理装置を提供する。
【解決手段】音声出力部と、音声認識部と、第1の制御部と、対話シナリオ及び音声出力データが記憶された第1の記憶部と、を含み、前記第1の制御部は、前記対話シナリオに基づき前記音声出力データを用いて前記音声出力部から音声を発声させると共に、前記音声認識部からの音声認識結果に基づき前記対話シナリオを進行させ、前記対話シナリオにおける返答待ちの場面において、前記音声認識結果が所定の時間を経過しても前記第1の制御部に伝達されないときは、前記第1の制御部は前記音声出力部を用いて警告を示す音声を発声させることを特徴とする。
(もっと読む)
運転支援システム
【課題】運転者に対して同乗者がいるような感覚を与えることができ、これにより運転者に対して緊張とリラックスをバランス良く与えることができ、特に高齢者ドライバーの交通事故の削減に高い効果を発揮することが可能である運転支援システムの提供。
【解決手段】運転者の音声を認識するための音声認識手段と、運転者に対して音声を出力するための音声出力手段と、前記音声出力手段から出力される音声の元になる音声データを記憶する音声データ記憶手段と、前記音声認識手段により認識された音声に応じて、前記音声データ記憶手段に記憶された音声データの中から適当な音声データを読み出して、前記音声出力手段から音声出力を行わせる音声制御手段と、を備えており、前記音声データは、運転者に注意を喚起する文言からなる第一音声データと、運転者を褒める文言からなる第二音声データとを含んでいることを特徴とする運転支援システムである。
(もっと読む)
入出力デバイス情報を考慮したマルチモーダル対話プログラム、システム及び方法
【課題】1つの対話シナリオを設計するだけで、様々な入出力デバイスを搭載した端末毎に、異なる対話シナリオを進行させるマルチモーダル対話プログラムを提供する。
【解決手段】状態sで可用な各デバイス行動aにおけるデバイス行動確率r(sd0,ad0)を蓄積したデバイス行動確率蓄積手段と、デバイス種別の有無を取得するデバイス種別取得手段と、端末のデバイス種別の有無とr(sd0,ad0)とを乗算し、デバイス可用報酬値r(sd,ad)を算出するデバイス可用報酬値算出手段と、状態sに、行動aを実行した際に得られる報酬期待値r(s0,a0)に対して、r(sd,ad)を重み付けた報酬期待値r(s,a)を算出する報酬期待値算出手段と、報酬期待値rを用いて、報酬Vtが最大となるように、状態sにおける行動aを決定する部分観測マルコフ決定過程POMDP手段と、行動aに基づく対話シナリオを端末へ送信する対話シナリオ送信手段とを有する。
(もっと読む)
音声対話装置、方法、プログラム
【課題】実施形態によれば、ユーザからのバージイン発声を精度よく認識することが可能な音声対話装置、方法、及びプログラムが提供される。
【解決手段】検出部は、ユーザの音声を検出する検出する。認識部は、音声を認識する。出力部は、音声の認識結果に対応した応答音声を出力する。制御部は、応答音声の出力中に、ユーザから割り込まれて入力されたバージイン発声が起こる確率の時間変化を表すバージイン確率変動に基づいて、応答音声の出力中にユーザから割り込まれて入力されたバージイン発声が起こる確率の時間変化を表すバージイン確率変動に基づいて、バージイン発声を採用するか否かを判定することを特徴とする。
(もっと読む)
音声翻訳装置、方法、及びプログラム
【課題】円滑なコミュニケーションを実現できる。
【解決手段】音声翻訳装置は、入力部、音声認識部、感情認識部、平静文生成部、翻訳部、補足文生成部、及び音声合成部を含む。入力部は、第1言語の音声を音声信号に変換する。音声認識部は、音声信号を音声認識処理し文字列を生成する。感情識別部は、文字列がどの感情種別を含むかを識別して1以上の感情種別を含む感情識別情報を得る。平静文生成部は、感情に伴って語句が変化した非平静語句と、非平静語句に対応しかつ感情による変化を伴わない平静語句とを対応付けたモデルより、文字列に第1言語の非平静語句が含まれる場合、第1言語の非平静語句を対応する第1言語の平静語句に変換した平静文を生成する。翻訳部は、平静文を第2言語に翻訳した訳文を生成する。補足文生成部は、感情識別情報の感情種別を第2言語で説明する補足文を生成する。音声合成部は、訳文と補足文とを音声信号に変換する。
(もっと読む)
対話処理装置、対話処理方法、及び対話処理プログラム
【課題】利用者の発話に適したエキスパート部を選択する。
【解決手段】音声入力部は音声を入力し、音声認識部は入力した音声を認識し、予め定めた処理を行う場合、音声認識部が認識した認識結果に基づいて前記処理を継続するか否かを判定し、前記処理を行わない場合、音声認識部が認識した認識結果に基づいて適合性を推定する複数のエキスパート部と、複数のエキスパート部のうち前記処理を行うエキスパート部が処理を継続しないと判断した場合、前記処理を行わない場合に推定した適合性に基づいて前記処理を行うエキスパート部を選択する動作理解部とを備える。
(もっと読む)
音声情報提示装置および音声情報提示方法
【課題】ユーザに提示する情報を、ユーザにとって適切な音声で提示することができる音声情報提示装置を提供する。
【解決手段】
ユーザの音声を取得する取得手段120と、取得されたユーザの音声を保持する保持手段130と、ユーザの音声の基本周波数を検出する基本周波数検出手段120と、音声に係るユーザの性別を識別する識別手段120と、ユーザが女性であると識別された場合に、ユーザの音声において、基本周波数を男性の一般的な基本周波数の周波数帯域にシフトさせることにより、ユーザの音声を変更して情報提示用音声を生成する第1生成手段120と、ユーザが男性であると識別された場合に、ユーザの音声において、基本周波数を女性の一般的な基本周波数の周波数帯域にシフトさせることにより、ユーザの音声を変更して情報提示用音声を生成する第2生成手段120と、情報提示用音声を、ユーザに提示する提示手段140とを有することを特徴とする音声情報提示装置。
(もっと読む)
音響通信方法を用いたホームページ誘導方法およびシステム
【課題】ラジオCMまたはテレビCMから、携帯端末をホームページに誘導するためのシステムを提供する。
【解決手段】放送局12から放送される番組中のコマーシャルにURL対応番号を含ませておき、ラジオ14またはテレビ16などの音響出力機器で受信する。音響出力機器が出力するコマーシャル(音響)を携帯電話機18などの携帯端末で受けて、携帯端末内でURL対応番号を再生し、管理センター20に送信する。管理センターでは、受信した番号に対応するURLを検出して、携帯端末に送信する。携帯端末は受信したURLに接続して、携帯端末のユーザをホームページに誘導する。
(もっと読む)
コミュニケーション装置
【課題】 本発明は、発せられた音声の音量に応じたメッセージを生成し出力することができるコミュニケーション装置を提供することを目的とする。
【解決手段】 人物から発せられた音声をマイク70によって集音することにより得られた音声データが与えられると、音声データの音量を判定する音量判定手段80と、音量判定手段80から出力された判定結果に基づいて、音声データの音量に応じたメッセージからなる音声を生成し、これをスピーカ60から出力する音声生成手段100とを備える。
(もっと読む)
ビデオ会議に翻訳を追加するための方法及びシステム
【課題】会議参加者の発話を所望の1又は複数の言語にリアルタイム翻訳する多言語多地点ビデオ会議システムを提供する。
【解決手段】発話を含む音声ストリームがテキストに変換され(220,250)、ビデオストリームに字幕として挿入される(250,240)。発話は或る言語から別の言語に翻訳され(240)、翻訳された発話がビデオストリームに挿入され、字幕を選ぶか、又は、音声合成エンジンによって生成された別の言語の発話に、元の音声ストリームを置き換える(220,240,250)。種々の会議参加者は、それぞれ会議参加者により提供された所望の言語の情報に基づく同じ発話の種々の翻訳を受信する(210)。
(もっと読む)
音声対話装置及び音声対話プログラム
【課題】ユーザ発話の誤認識や不認識を低減して、検索効率の高い音声対話装置及びプログラムを提供する。
【解決手段】音声対話装置は、音声コマンドである語とそれを示す分類との対からなる音声コマンドリストと、検索対象データベースの検索キーワードである語とそれを示す分類との対からなる検索キーワードリストと、音声コマンドでも検索キーワードでもなく検索対象外ワードである語とそれを示す分類との対からなる対象外ワードリストと、を有する音声認識辞書16と、ユーザにより入力された音声データを音声認識して、音声認識辞書16に含まれる語とその分類を抽出する音声認識部17と、抽出された語の分類が検索対象外ワードである場合には、抽出された語が対象外ワードであることを示す応答を生成する対話制御部18と、対話制御部18により生成された応答を提示する提示部20と、を備えている。
(もっと読む)
外国語学習補助方法及び装置
【課題】
外国語学習を容易にする。
【解決手段】
質問データベース(10)は、外国語の質問、及び、当該質問に対する1以上の日本語の回答例を収容する。質問をマイク(16)又は表示装置(18)により学習者に提示する。学習者は、回答をマイク(20)で入力する。音声分析装置(22)はマイクからの音声信号を分析して発音を定量評価する。音声認識装置(24)はマイクからの音声信号を音声認識し、回答文に変換し、翻訳装置(26)は回答文を日本語に翻訳する。対比装置(28)は、翻訳装置(26)による日本語の翻訳文を質問に対する回答例と対比することにより内容を定量的に評価し、内容評価点を出力する。表示装置(18)は、回答例、回答文、発音評価点及び当該内容評価点を表示する。
(もっと読む)
音声認識装置及び音声変換装置
【課題】高速で音声認識を行うことができる音声認識装置を提供する。
【解決手段】音声波形信号をフレーム単位で解析して音声の特徴量を表す特徴ベクトルを抽出する特徴ベクトル抽出部231と、特徴ベクトルを時系列的に複数フレーム分記憶する特徴ベクトル記憶部232と、音声認識候補となる複数の音声を記憶する認識候補音声記憶部233と、特徴ベクトル記憶部に記憶された複数フレーム分における特徴ベクトルに基づき音声認識候補となる各音声の尤度を算出する第1解析部234と、複数フレーム分における特徴ベクトルからフレーム単位あたりの平均特徴ベクトルを算出し当該平均特徴ベクトルから音声認識候補となる音声の尤度を算出する第2解析部235と、第1解析部において算出した音声認識候補となる各音声の尤度及び第2解析部において算出した音声認識候補となる各音声の尤度に基づき一つの音声を決定する音声決定部236とを備える音声認識装置。
(もっと読む)
音声対話装置及びプログラム
【課題】音声認識結果又は感情推定結果が誤っていてもユーザの発話に対して適切な応答を生成する。
【解決手段】音声対話装置は、ユーザが発話した音声を認識して、当該音声に含まれる単語を抽出し、当該音声に含まれる単語の信頼度を算出する音声認識部10と、認識結果又は音声の韻律情報を用いてユーザの音声の感情を推定し、推定した感情の信頼度を算出する感情推定部20と、抽出された単語と予め定められた応答テンプレートとを用いて応答候補を生成し、さらに、推定された感情と予め定められた応答テンプレートとを用いて応答候補を生成する応答候補生成部30と、応答候補生成部30で生成された応答候補のうち、信頼度が最も高い単語又は感情に基づく応答候補を選択する応答候補選択部40と、を備えている。
(もっと読む)
ロボット、対話装置及び対話装置の動作方法
【課題】従来よりも対話時の応答のレスポンス性を高めること。
【解決手段】ロボットは、受信した音声に対する応答文を生成する応答文生成部22と、応答文生成部22で生成された応答文の入力に応じて、入力した応答文に対応した波形を有する波形データを生成する波形データ生成部24と、応答文とこの応答文に基づいて波形データ生成手段24で生成された波形データとを互いに関連付けて保持する波形データテーブル格納部25と、を備え、波形データ生成部24は、今回の応答文の入力に応じて、入力した応答文に関連付けられた波形データが波形データテーブル格納部25に存在するか否かを判断し、波形データテーブル格納部25に対象とした波形データが存在すれば、対象とした波形データを波形データテーブル格納部25から読み出し、読み出した波形データを出力する。
(もっと読む)
対話装置
【課題】対話処理のためにもともと備わっている音声入力手段や音声出力手段を活用して、操作者までの距離検出を行う。
【解決手段】受付端末20は、音声を入力するためのマイク207と、音声を出力するためのスピーカ208とを有し、周囲で発生しマイク207で取得された雑音情報に基づきスピーカ208を介し距離検出用の疑似雑音を出力し、マイク207を介し入力された疑似雑音の対象物での反射音により対応する振幅あるいは周波数を含む反射音情報を取得し、取得された反射音情報に基づき所定の演算処理を行い、対象物が来訪者Mであると推測して来訪者Mまでの距離を検出し、この検出結果に基づき来訪者Mとの対話による受付処理を開始する。
(もっと読む)
通話システム、通話方法、通話プログラム、電話端末及び交換機
【課題】周囲にいる第三者に通話内容を聞かれずに、通話相手との会話を成立させるようにする。
【解決手段】本発明の通話システムは、音声データを入力する音声入力手段と、通話先に向けて音声データを出力する音声出力手段と、秘匿性のある第1キーワードと、これとは別の第2キーワードと対応付けたキーワード変換情報を記憶するデータベースと、入力された音声データを認識してテキストデータに変換する音声認識手段と、テキストデータから第2キーワードに該当するデータを検索する検索手段と、第2キーワードが検索された場合、入力された音声データにおける第2キーワードの位置に、第2キーワードに対応する第1キーワードの音声データを合成して出力させる音声合成手段とを備えることを特徴とする。
(もっと読む)
音声認識装置
【課題】操作性をより向上することが可能な音声認識装置を提供する。
【解決手段】本発明の一実施形態に係る音声認識装置20は、ユーザの発話を認識する音声認識装置であって、ユーザの発話を単語ごとに分解する形態素解析手段33と、所望の情報を管理する情報管理手段であって、単語のうちの当該所望の情報を表す単語を取り込む情報管理手段34と、所望の情報を表す単語が不足している場合に、不足している情報を表す単語をユーザに発話させるように音声ガイダンスを行う対話制御手段35とを備える。
(もっと読む)
携帯端末、音声合成方法、及び音声合成用プログラム
【課題】音声通信可能な携帯端末において、特定のキーワードに基づいた音声合成の切換、生の音声へのフィルタリング、特定キーワードの自動登録を行う。
【解決手段】音声合成手段の前段に音声分析手段と音声変換手段を有する。音声合成手段は、受信音声をタレント等の特定の人を真似た合成音に変換する。また、受信音声の発信元が音声合成の切り替え相手かどうか判断する。また、受話の音声の感情を分析する。変換手段は、キーワードデータベースに予め登録された特定のキーワードの音声を認識すると、音声合成を中止して受話音そのままの音声を出力する。また、キーワードがNGワードとして登録されていた場合、相手に対し、決められたNGワードを通知する。また、受話の音声の感情が怒り等の特定の感情であるとの結果を得たら、音声合成を中止して元の音声にフィルタをかけた音声を出力する処理を行う。
(もっと読む)
1 - 20 / 119
[ Back to top ]