
Fターム[5D015LL00]の内容
音声認識 (5,191) | 音声認識装置の制御 (1,048)
Fターム[5D015LL00]の下位に属するFターム
後処理 (238)
認識結果の表示・出力 (271)
他の情報入力装置の援用 (113)
多重処理 (13)
動作モードの設定、切換 (73)
音声認識装置の用途 (261)
Fターム[5D015LL00]に分類される特許
1 - 20 / 79
音声処理装置及び音声処理装置の制御方法
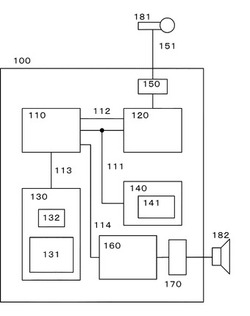
【課題】話者に対して音声認識の可能な期間を正確に明示できる音声処理装置を提供する。
【解決手段】入力された話者の音声を用いる音声処理装置が、中央制御部と、前記中央制御部により制御される音声認識部と、表示部と、前記音声認識部で用いられる選択肢情報と、を含み、前記選択肢情報は、選択肢データと、前記選択肢データに対応した表示タイミングデータと、を有し、前記表示タイミングデータは、前記表示部に対する所定の制御に用いられ、前記所定の制御は、前記音声認識部における音声認識処理の実行が可能である期間を前記話者に明示する制御であることを特徴とする。
(もっと読む)
半導体集積回路装置及び電子機器

【課題】音声合成処理の終了から音声認識処理の開始までの間に適切な時間間隔を設ける処理に対するホスト装置の負荷を低減する。
【解決手段】半導体集積回路が、音声認識部と、外部から入力された制御コマンドを記憶する第1の記憶部と、前記制御コマンドの内容の解釈を行い、前記解釈の結果に基づいて前記音声認識部の制御を行う第1の制御部と、を含み、前記音声認識部は、前記第1の制御部からの動作開始の指示の後、所定の時間の経過後に音声認識の処理を開始することを特徴とする。
(もっと読む)
音声認識システム
【課題】クライアントとサーバとで分散して音声認識処理を行う場合に認識結果が得られるまでに要する時間を短縮するとともに、音声認識処理に関するクライアントの規模および処理負担の軽減が可能な音声認識システムを提供すること。
【解決手段】車載装置1において入力された利用者の音声に対して、この車載装置1あるいはネットワーク3を介して接続されたサーバ2による音声認識処理が行われる。車載装置1は、マイクロホン22と、あらかじめ用意された複数の単語あるいは文章を対象に音声認識処理を行う音声認識処理部100と、入力された音声について音声認識処理部100において音声認識処理を行うものとサーバ2において音声認識処理を行うものとを振り分ける振り分け判定部102と、サーバ2側で音声認識処理を行う場合に音声データをサーバ2に送信する音声データ送信部56とを備える。
(もっと読む)
音声認識装置
【課題】同じシナリオであっても使用したい音声認識部を使い分けることが出来る音声認識装置を提供すること。
【解決手段】本発明の音声認識装置は、一又は複数の接続機器と接続されて音声認識を行う音声認識装置であって、音声を取り込むマイクと、前記一又は複数の接続機器と接続するための接続部と、前記一又は複数の接続機器より取得した音声認識対象の文字データを記憶する記憶部と、前記記憶部の音声認識対象の文字データから音声認識処理用の音素への変換を行う変換部と、前記変換部が変換した音素を含み音声認識に利用される音声認識辞書と、前記音声認識辞書と前記マイクより取り込んだ音声を利用して音声認識を実施する音声認識部と、前記一又は複数の接続機器から前記音声認識対象の文字データを取得しているか否かを判断し、その判断結果に基づいて前記マイクより取り込んだ音声を前記音声認識部で認識させるか否かを制御する制御部とを備える。
(もっと読む)
文脈依存性推定装置、発話クラスタリング装置、方法、及びプログラム
【課題】対話データについて、文脈に依存している度合いを推定することができるようにする。
【解決手段】特徴量抽出部30によって、複数の発話の時系列である対話データから、各発話の特徴量を抽出する。CRPクラスタリング部31によって、抽出された各発話の特徴量に基づいて、CRPの手法を用いて、複数の発話をクラスタリングする。無限HMMクラスタリング部32によって、抽出された各発話の特徴量に基づいて、無限HMMの手法を用いて、複数の発話をクラスタリングする。文脈依存度算出部23によって、CRPのクラスタリング結果及び無限HMMのクラスタリング結果に基づいて、発話の文脈依存度を算出する。
(もっと読む)
移動体における音声認識装置および方法
【課題】 音声認識を行う遠隔のサーバシステムに接続する場合に、通信状況が悪化してサーバからの応答が得られない場合に、即時にユーザにその旨を通知する「移動体における音声認識装置および方法」を提供する。
【解決手段】 本発明の音声認識装置は、ユーザの発話をサーバシステム260に送信してその解析を依頼する手段302と、移動体の通信環境に関する情報を取得する手段312と、サーバシステムからの解析結果を一定時間待ち受ける手段304と、待ち受け時間内に解析結果を受信した場合に、これをユーザに通知する手段308と、取得した通信環境に関する情報に基づいて、前記待ち受け時間内における通信状況を予測する手段314と、待ち受け時間内における通信状況が良好でないと判断される場合に、前記解析結果の待ち受けを中止し、その旨をユーザに通知する手段308とを有する。
(もっと読む)
音声入力装置
【課題】音声入力機能の使用に慣れたユーザーや慣れていないユーザーに対し、適切なタイミングでガイダンス機能を実行し、ユーザーの煩わしさを解消することができる音声入力装置を提供する。
【解決手段】音声入力モードとして、予め登録された登録済発話内容を前記ユーザーに提示するガイド有り入力モードと、登録済発話内容が非提示とされるガイド無し入力モードとを有する音声入力装置10において、制御部11は、ユーザーの、音声入力に係る習熟レベルを特定するとともに、音声入力の入力受け付けが開始されるに伴い設定するガイド無し入力モードを、特定された習熟レベルが高いほど、より遅いタイミングで、ガイド有り入力モードに切り替える。
(もっと読む)
音声処理装置、及び音声処理方法
【課題】操作負担を軽減する。
【解決手段】実施形態の音声処理装置は、音声入力手段と、情報入力手段と、音声認識手段と、アプリケーション制御手段と、を備える。音声入力手段は、音声を、音声信号として入力処理する。情報入力手段は、自装置のハードウェアにおける状態変化を示す状態情報を入力処理する。音声認識手段は、情報入力手段が入力した前記状態情報に基づいてハードウェアの状態変化が生じた場合に、音声入力手段により入力処理された前記音声信号に対して音声認識を行い、音声認識結果情報を生成する。アプリケーション制御手段は、前記音声認識手段により生成された前記音声認識結果情報を利用するアプリケーションを起動する。
(もっと読む)
音声認識装置及び音声認識処理方法
【課題】 音声認識処理を行う場合に、優先度に応じて音声認識処理を行うことができる音声認識装置及び音声認識処理方法を提供することを目的とする。
【解決手段】 音声認識装置300は、音声データを外部から取得し、取得した音声データを一次出力データベース303へ記録し、一次出力データベース303に記録される音声データを、処理すべき優先度に応じた条件を記憶する優先度メモリ305に記憶される条件と比較し、条件に一致した音声データをその条件の優先度に応じて音声認識処理を行わせるとともに、その音声データに対する追加処理を音声認識処理部306に対して指示する。音声認識処理された音声認識結果は、格納処理部307によって音声認識結果データベース300Dへ優先度と関連付けされて格納される。
(もっと読む)
エレベーター制御システム
【課題】音声認識による呼び登録機能を備えたエレベーターにおいて、アナウンス装置からの音声によって呼びが誤登録されてしまうことを防止できるようにする。
【解決手段】本制御システムは、エレベーターの運転を制御する制御手段3と、音声認識の結果に基づいて、制御手段3に行き先情報を出力する音声認識装置1と、音声認識装置1の近傍に設けられたアナウンス装置2と、制御手段3からのアナウンス発報指令に基づいて、アナウンス装置2からアナウンスを発報させるアナウンス制御手段4とを備える。アナウンス制御手段4は、音声を認識するための所定の音声認識処理を音声認識装置1が行っている場合は、通常音量よりも音量を低減させてアナウンス装置2からアナウンスを発報させる。
(もっと読む)
音声認識操作装置及び音声認識操作方法
【課題】周囲の雑音に影響されることなくユーザの音声指示を正確に認識することができ、ひいては被制御機器をユーザの所望する通りに正しく制御することを可能とした音声認識操作装置及び音声認識操作方法を提供すること。
【解決手段】実施の形態によれば、音声認識操作装置は、音検出手段とキーワード検出手段と音声ミュート手段と送信手段とを備える。音検出手段は、音を検出する。キーワード検出手段は、音検出手段で音が検出された場合、特定のキーワードを音声認識により検出する。音声ミュート手段は、キーワード検出手段でキーワードが検出された場合、音声ミュートを指示する操作信号を送信する。送信手段は、キーワード検出手段でキーワードが検出された後の音声指示を認識し、当該音声指示に対応する操作信号を送信する。
(もっと読む)
音声認識装置、音声認識方法および音声認識装置を搭載したテレビ受像機
【課題】ローカル型と分散型の音声認識の切り替えをユーザに意識させることなく、音声認識の使い分けを実現することである。
【解決手段】実施形態の音声認識装置は、音声を入力する音声入力手段と、当該音声入力手段に入力された音声を認識する第1の音声認識手段と、外部サーバと通信する通信手段と、当該通信手段で接続された外部サーバ上で前記音声入力手段に入力された音声を認識する第2の音声認識手段と、リモコン信号を入力するリモコン信号入力手段と、当該リモコン信号入力手段に入力されたリモコン信号から認識開始指示を検出した場合は前記第2の音声認識手段で前記音声入力手段に入力された音声を認識し、前記音声入力手段に入力された音声から認識開始指示を検出した場合は前記第1の音声認識手段で前記音声入力手段に入力された音声を認識するよう第1と第2の音声認識手段を切り替える音声認識切替手段とを備える。
(もっと読む)
高速音声検索の方法および装置
【課題】高速音声検索の方法および装置を提供する。
【解決手段】マルチプロセッサシステム内の大きい音声データベースを検索してターゲット音声クリップを特定する。大きい音声データベースは複数のより小さいグループに分割されて、これら複数の小グループがシステム内の複数の利用可能なプロセッサに対して動的にスケジューリングされる。プロセッサは、各グループを複数のより小さいセグメントに分割して、セグメントから音声特徴を抽出して、共通成分ガウス混合モデル(CCGMM)を用いてセグメントをモデル化することによって、スケジューリングされた複数のグループを並列に処理する。1つのプロセッサはさらに、ターゲット音声クリップから音声特徴を抽出してCCGMMを用いて抽出した音声特徴をモデル化する。ターゲット音声クリップと各セグメントとの間のKL距離に基づいて、セグメントがターゲット音声クリップに一致するか否か判断する。
(もっと読む)
音声認識システム、音声認識端末、およびセンター
【課題】センターの認識辞書を利用して音声認識端末の認識辞書を拡充しつつも、音声認識端末における認識辞書のサイズの無駄な増大を抑える。
【解決手段】音声認識端末1は、ユーザの発話音声を自機で音声認識することに失敗した場合を選んで、センター2から当該発話音声の音声認識結果の単語と共に、センター側認識辞書における当該単語の比較用音声特徴データを受信し、受信した当該単語の比較用音声特徴データを端末側認識辞書に追加する。
(もっと読む)
音声認識システム及び音声認識方法
【構成】 マイクロホンからの音声信号を音声認識ユニットで音声認識する。IDリーダを設けて、音声認識のオンオフ用のID媒体を読み取ることにより、音声認識を中止及び開始する。
【効果】 移動中に雑音が多い箇所を通過しても誤認識しない。
(もっと読む)
音声認識装置および音声認識方法
【課題】複数の音声認識処理をより適切に使い分けることを目的とする。
【解決手段】音声認識装置10は、予め定めた1以上の特定語を記憶する特定語記憶部11と、入力された音声データを認識することで第1言語データを生成する第1音声認識部12と、第1言語データに特定語が少なくとも一つ存在するか否かを判定する判定部13と、第1言語データに少なくとも一つの特定語が含まれていると判定された場合に、音声データを認識することで第2言語データを生成する第2音声認識部15と、判定部13による判定結果と第1言語データおよび/または第2言語データとに基づく認識結果データを出力する認識結果出力部16と、を備える。
(もっと読む)
ナビゲーション装置
【課題】ナビゲーション情報の表示に用いられている言語での音声認識が可能でないことを容易に判断することができる「ナビゲーション装置」を提供することである。
【解決手段】予め定められた複数の言語のいずれかにてナビゲーション情報を表示部に表示可能で、前記複数の言語に含まれる一または複数の言語については、前記ナビゲーション情報の表示とともに、音声認識が可能となるナビゲーション装置であって、前記表示部に表示されるナビゲーション情報の言語の音声が認識可能か否かを判定する判定手段(S16)と、前記判定手段によって、前記表示部に表示されるナビゲーション情報の言語の音声が認識可能ではないと判定されたときに、所定の情報を出力する報知手段(S18)とを有する構成となる。
(もっと読む)
認証装置、認証方法及びプログラム
【課題】サービスやシステムが第三者に不正に利用されてしまうことを防止する。
【解決手段】入力を受け付けた音声信号に基づく音声と、予め記憶された音声とが、同一人物によって発声された音声であるかどうかを判定することで、ユーザ認証を行う認証装置であって、ユーザを一意に識別するIDと、当該ユーザが発声した複数の言葉毎に生成された複数の音声データとを対応付けて記憶し、さらに、複数の音声データのそれぞれと、ID毎に固有の情報である複数の固有情報とを対応付けて記憶し、端末からIDを受信すると、受信したIDの複数の固有情報のいずれかを特定するための特定情報を当該端末へ送信し、その後、当該端末から送信された音声信号を受信すると、特定情報にて特定される固有情報に対応する音声データを変換した音声信号の特徴と、受信した音声信号の特徴とを比較することにより、同一人物によって発声された音声であるかどうかを判定する。
(もっと読む)
情報処理装置
【課題】音声翻訳機能を備えた情報処理装置であって、使用可能なRAMサイズに制約がある場合においても、モジュールの初期化タイミングを制御することで、音声翻訳処理時間を最小限に抑えた情報処理装置を提供する。
【解決手段】翻訳処理に使用できるRAMの空き領域を算出する第1の算出手段と、空き領域および複数のモジュールの各々が処理を行う際にRAMの記憶領域を占有する最大サイズとモジュールの各々の初期化に必要なRAMの記憶領域とモジュールの各々の初期化に要する時間とに基づいて初期化可能なモジュールを選択する選択手段と、翻訳処理が実行される前に初期化する第1の初期化手段(S101)と、翻訳処理の実行に伴っていずれかのモジュールが処理を行う際、初期化されていなかった場合、このモジュールの処理開始時にこのモジュール初期化するとともに翻訳処理終了時に解放する第2の初期化手段(S109乃至S113)とを備える。
(もっと読む)
外国語会話支援装置、方法、プログラム、および電話端末装置
【課題】会話を阻害することなく、状況に応じて適切に会話を支援するための翻訳支援情報を提示する。
【解決手段】外国語会話支援装置20において、言語識別部21で、入力音声31の言語の種別を識別するとともに、音声出力部24で、会話相手への出力音声として出力し、判定部22で、入力音声31が会話相手との会話で使用している会話言語か否かを判定し、入力音声31が会話相手との会話で使用している会話言語でなかった場合、会話支援部25で、入力音声31を会話言語に翻訳するための翻訳支援情報33を生成し、その翻訳支援情報33を画面表示する。
(もっと読む)
1 - 20 / 79
[ Back to top ]