
Fターム[5D015LL01]の内容
Fターム[5D015LL01]の下位に属するFターム
判定処理 (81)
誤認識の訂正のためのもの (115)
Fターム[5D015LL01]に分類される特許
1 - 20 / 42
談話要約テンプレート作成システムおよび談話要約テンプレート作成プログラム
音声認識装置とその方法とプログラム
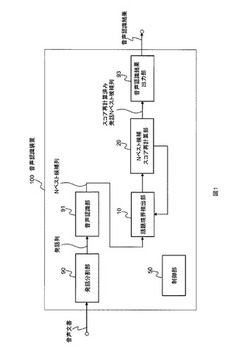
【課題】話題境界を跨がない長距離文脈情報を用いて認識スコアを再計算する音声認識装置を提供する。
【解決手段】話題境界検出部が、Nベスト候補列を入力として、当該Nベスト候補列中の現在発話区間を中心として当該現在発話区間から音声文書の冒頭方向にある順位1位の認識結果候補を過去発話単語集合として抽出すると共に、当該現在発話区間を中心として当該現在発話区間から音声文書の末尾方向にある順位1位の認識結果候補を未来発話単語集合として抽出し、過去・未来間関連度平均値と所定の閾値とを比較して音声文書の話題境界を判定する。Nベスト候補スコア再計算部は、話題境界検出部において話題境界と判定されなかった現在発話区間の認識スコアを、過去・現在間関連度合計値と現在・未来間関連度合計値の平均値を用いた値に再計算し、現在発話区間のNベスト候補を並べ替える処理を行う。
(もっと読む)
音声認識装置、音声認識方法及びプログラム

【課題】設定された音声認識率と実際の音声認識率との間で大きな誤差が生じないようにする。
【解決手段】音声認識装置10は、複数の単語それぞれの特徴量を記録した記憶部12と、外部から入力された音声の特徴量と記憶部12に記録された複数の単語の特徴量とから各単語の類似度を算出し、算出した各単語の類似度から類似度の最大値を取得する類似度最大値取得部11bと、類似度最大値取得部11bが取得した類似度の最大値と所定値とを用いて類似度の範囲を決定する類似度範囲決定部11cと、類似度範囲決定部11cが決定した類似度の範囲に含まれる類似度を有する単語を選択し、選択した単語を認識結果として表示部15に表示する制御を行う表示制御部11dとを備える。
(もっと読む)
音声記録装置、方法及びプログラム
【課題】音声信号を記録する音声記録装置において、ユーザの作業負荷を軽減することができる音声記録装置、方法及びプログラムを提供する。
【解決手段】音声記録装置は、音声信号を記憶する音声記憶部と、音声信号について音声認識する音声認識部と、音声記憶部に記憶された音声信号に対する編集内容として、音声信号の並べ替えと補完と削除の少なくとも一つを音声認識を用いて推定する編集内容推定部と、編集内容推定部によって推定された編集内容に従って、音声記憶部に記憶された音声信号を編集し、編集結果を記録する音声編集部を備える。
(もっと読む)
音声翻訳システム、音声翻訳装置、音声翻訳方法、およびプログラム
【課題】音声認識結果に誤りがある場合、翻訳精度は著しく劣化していた。
【解決手段】音素列と文字列とを有する2以上の固有表現情報を格納し得る固有表現情報格納部と、音声を受け付ける音声受付部と、音声受付部が受け付けた音声を音声認識し、音素列を取得する音声認識部と、音声認識部が取得した音素列に類似する音素列を、固有表現情報格納部から取得する類似音素列取得部と、類似音素列取得部が取得した音素列に対応する文字列である類似文字列を取得する類似文字列取得部と、類似文字列取得部が取得した類似文字列を翻訳し、翻訳結果を取得する機械翻訳部と、機械翻訳部が取得した翻訳結果を音声合成し、音声合成結果を取得する音声合成部と、音声合成結果を用いて音声出力する合成音声出力部とを具備する音声翻訳装置により、音声認識結果に誤りがある場合でも、良好な翻訳結果を得ることができる。
(もっと読む)
音声認識結果検索装置、音声認識結果検索方法および音声認識結果検索プログラム
【課題】 音声認識辞書の単語単位とキーワードの単語単位とが異なる場合でも、音声認識結果に所定のキーワードが含まれるかどうかを精度よく判定できる音声認識結果検索装置を提供する。
【解決手段】 音声認識結果検索装置は、入力音声に対する認識処理の結果の候補である認識候補と、該各認識候補に付与された前記入力音声と類似する度合いを示す音声認識スコアとを、音声認識結果として取得すると共に、前記各音声認識スコアを、互いに共通の所定の特徴を有する認識候補にそれぞれ付与された音声認識スコアを用いて再計算する音声認識スコア再計算手段と、前記再計算された音声認識スコアに基づいて、所定のキーワードと前記音声認識結果との距離を算出する距離計算手段と、前記算出された距離に基づいて、前記所定のキーワードが前記音声認識結果に含まれるか否かを判定するキーワード探索手段とを備える。
(もっと読む)
モデルパラメータ推定装置、方法及びプログラム
【課題】従来より高精度にモデルパラメータを推定することを可能とする。
【解決手段】それぞれ重要度ei,jが割り当てられ素性ベクトルで表現された複数のシンボル系列fi,jからなる1以上のリストiとそれぞれ重要度ei,0が割り当てられ素性ベクトルで表現された各リストiの正解シンボル系列fi,0とが入力され、モデルパラメータwを推定する装置であり、重要度変換部とモデルパラメータ推定部とを備える。重要度変換部は、重要度ei,jをリストごとに所定のシンボル系列の重要度の値が上記所定のシンボル系列以外のシンボル系列の重要度の値に比べ相対的に大きな値になるように変換する。モデルパラメータ推定部は、シンボル系列fi,jと正解シンボル系列fi,0と変換後の重要度とからモデルパラメータwを推定する。
(もっと読む)
入力誤り警告装置
【課題】聞き取り間違いや読み取り間違いに基づく誤入力を検出してユーザに警告する。
【解決手段】入力誤り警告装置は、定められた文字情報である正解語と、パターン認識処理により文字情報を検出する処理対象である処理対象データに含まれる正解語の数を示す第1の出現数と、ユーザに入力された文字情報に含まれる正解語の数を示す第2の出現数と、正解語が誤読された結果である誤り語と、パターン認識処理によって正解語が誤り語として誤読された数を示す第1の誤り数と、ユーザによって正解語が誤り語として誤読された数を示す第2の誤り数と、第1の誤り数に対する第2の誤り数の信頼性の度合いを示す重み係数とに基づいて、正解語が誤り語として誤読される誤り率を算出し、ユーザから入力される文字情報が誤り語として記憶されており、かつ誤り語に応じて算出した誤り率が予め定められた閾値を超えていると判定すると、誤り語に対応する正解語を出力する。
(もっと読む)
音声認識システム、音声認識方法および音声認識プログラム
【課題】音声認識誤りの原因を推測するのに役立つ例文を、ユーザに提示することのできる音声認識システムを提供すること。
【解決手段】音声認識手段21は、入力音声を音響モデル31と言語モデル32とを使って、音声認識する。単語選択手段22は、音声認識手段21の音声認識結果から、1つもしくは複数の単語を選択する。文生成手段23は、選択された1つもしくは複数の単語と言語モデル32とを使って文を生成し、この生成した文をユーザに提示する。
(もっと読む)
口語技能の評価
【課題】 話者の1つ又は複数の口語言語技能を評価するための技術を提供すること。
【解決手段】 本技術は、話者により発声された音声パッセージにおいて、1つ又は複数の対象となる時間的位置を識別するステップと、1つ又は複数の音響パラメータを計算するステップであって、1つ又は複数の音響パラメータが、1つ又は複数の対象となる位置の1つ又は複数の音響音声学的特徴の1つ又は複数の特性を捉えるステップと、口語言語技能評価の出力を修正するために1つ又は複数の音響パラメータを自動音声認識装置の出力と組み合わせるステップとを含む。
(もっと読む)
音声認識の誤認識判定装置及び音声認識の誤認識判定プログラム
【課題】音声認識結果が誤認識か否かを判定する音声認識の誤認識判定装置を提供する。
【解決手段】音声認識の誤認識判定装置は、音声データと音声コマンド辞書21とに基いて音声コマンドを認識する音声認識部12と、音声認識部12による認識結果に対する応答処理を実行する認識結果応答部と、応答処理後一定時間内にユーザの顔画像データを取得する顔画像取得部15と、発声データを取得する発声データ取得部16と、顔画像取得部15により取得された顔画像データに基いて予め定めた表情及び頭部動作を画像認識する顔画像認識部17と、発声データ取得部16により取得された発声データと無意識発話辞書22とに基いて無意識発話を認識する無意識発話認識部18と、顔画像認識部17により予め定めた表情か頭部動作が認識された場合又は無意識発話認識部18により無意識発話が認識された場合に認識結果が誤認識と判定する誤認識判定部19とを備えている。
(もっと読む)
姓名解析方法、姓名解析装置、音声認識装置、および姓名頻度データ生成方法
【課題】姓名が結合して成る文字列の姓と名との区切りをより確実に判定することができる姓名解析方法を提供すること。
【解決手段】本発明に係る姓名解析方法は、複数の姓データの集合を用いて予め取得した、各々の姓を構成する文字列の末尾の文字列毎の出現頻度を表す姓頻度データを用いる姓名解析方法であって、姓名が結合して成る姓名文字列をその先頭から順次2分割する工程(S1100、S1400、S1500)と、前記姓頻度データを参照して、前記分割位置の前半の末尾の文字列と一致する文字列の出現頻度を、前記分割位置毎に順次取得する工程(S1200)と、前記出現頻度が高い前記分割位置を、前記姓名文字列における姓と名との区切り位置であると判定する工程(S1600)とを有する。
(もっと読む)
個人情報削除装置、個人情報削除方法、個人情報削除プログラム、記録媒体
【課題】個人情報の含まれる音声信号の保管等には大きな負担が必要となる。本発明は、音声信号中に含まれる個人情報を削除し、音声信号の保管等に伴う負担を軽減することができる個人情報削除装置等を提供することを目的とする。
【解決手段】本発明の個人情報削除装置は、単語と、その単語の読みと、その単語が個人情報か否かが記録される認識辞書記録部を参照して、音声信号に対し音声認識処理を行い認識結果として、単語列、その単語列の各単語の始端時刻及び終端時刻を出力する音声認識部と、認識辞書記録部を参照して、単語列の各単語が個人情報か否かを判断し、個人情報の場合には、その単語の始端時刻及び終端時刻を出力する個人情報検出部と、音声信号のうち、個人情報と判断された単語の始端時刻から終端時刻までを所定の信号に変換する個人情報変換部とを有する。
(もっと読む)
データ生成装置及びデータ生成プログラム、並びに、再生装置
【課題】読みが付与されない文字列を含むテキストを音声の再生に合わせた所定のタイミングで表示するための連動表示用データを生成するデータ生成装置を提供すること。
【解決手段】音声の再生に合わせてテキストを所定のタイミングで表示するための連動表示用データを生成するデータ生成装置は、音源データに含まれる音声帯域のスペクトル成分から特徴パラメータを抽出して言語列を生成し、テキストを複数の文字列に区分けして各文字列に読みを付与し、読みが付与された各文字列と、読みが一致する言語列内の文字列が再生されるタイミングを示すタイムスタンプ情報とを含む連動表示用データを生成し、読みが付与されなかった文字列の直前の文字列のタイムスタンプ情報に基づいて、読みが付与されなかった文字列に所定長の時間帯を割り当てて、当該読みが付与されなかった文字列と、この文字列に割り当てた時間帯を示すタイムスタンプ情報とを連動表示用データに含める。
(もっと読む)
選択式情報提示装置および選択式情報提示処理プログラム
【課題】ユーザの作業や会話の支援に適した情報を提示する。
【解決手段】会議を行なっているユーザが新たな発話を行なった場合、検出部5は、発話情報の音声認識を行なって発話者、対話者、発話内容の文章などを抽出する。メタデータ生成部6は、抽出済みの発話内容の特徴を示す検出データを生成する。検索処理部7は、作成済みファイルのそれぞれのメタデータを読み出し、当該メタデータと検出データとを照合し、作成済みファイルのうち、当該ファイルの特徴情報と検出データ中の各種情報との一致割合が基準値以上である複数のファイルを提示対象のファイルとして決定する。提示処理部8は、提示対象のファイルのうち、一度に提示可能な一定数のファイルを纏めて提示する。
(もっと読む)
音声検索装置および音声検索方法
【課題】音声認識精度の向上を図ると共に、利用者が理解しやすい認識結果を提示する音声検索装置および音声検索方法を得る。
【解決手段】音響標準パタンデータベース2および認識用単語辞書3を参照して、音声認識部4が入力音声について音声認識を行う。データベース検索部9は検索用データベース8を参照して認識結果に対応する検索結果を取得し、認識結果との類似度を示す検索スコアと共に検索結果データ格納部10に格納する。認識結果補正部11は、検索結果に含まれる単語をノードにしたネットワークに認識結果を通して照合し、類似する単語に置き換える補正を行うと共に、補正した認識結果に基づいて検索スコアを補正して検索結果の順位付けを行う。候補提示部12は、検索スコア順の検索結果と、各検索結果に対応する補正した認識結果とを利用者に提示する。
(もっと読む)
音声ベースのユーザインタフェースを介してユーザと対話するための、コンピュータによって実現される方法
【課題】コンピュータによって実現される方法は、音声ベースのユーザインタフェースを介するユーザの対話を円滑にする。
【解決手段】本方法は、1つ又は複数の単語から成るフレーズの形式においてユーザからの発話入力を取得する。さらに本方法は、フレーズがクエリであるか又はコマンドであるかを、複数の異なるドメインを使用して判断する。フレーズがクエリである場合、本方法は複数のデータベースから関連性のあるアイテムを検索し、提示する。フレーズがコマンドである場合、本方法は動作を実行する。
(もっと読む)
頻度補正装置とその方法、それらを用いた情報抽出装置と情報抽出方法、それらのプログラム
【課題】頻度情報の正確性を高める。
【解決手段】この発明による頻度補正装置は、認識した文書に対応する正しい文書を用いて、認識した文書を記憶したデータベースから、認識した各単語の確からしさを表わす統計数値情報を生成し、その統計数値情報を用いて頻度情報を修正する。正しい文書を用いて各単語の頻度情報を修正するので、頻度情報の正確性を高めることが出来る。この頻度補正装置は、例えば、データベースから情報を抽出する情報抽出装置に応用が可能である。
(もっと読む)
音声処理サーバ
【課題】聞き起こし作業の作業者の負担と、作業者によって使用される端末の負担とを従来より低減することができる聞き起こしシステムを提供する。
【解決手段】管理サーバ40は、取得した元音声データを分割し音声認識処理を実行して得た分割文字データを、分割した元音声データとともに複数の聞き起こし端末60に順次配信する一方、編集された文字データを複数の聞き起こし端末60から順次受信する。また、管理サーバ40は、分割文字データをそれぞれ読み出し可能に記憶する文字データ記憶部と、それぞれの聞き起こし端末60からの要求に応じて、文字データ記憶部から読み出された分割文字データを、聞き起こし端末60に順次配信する配信手段とを有し、音声認識処理により得た文字データの編集を、複数の聞き起こし端末60により、並行して実行する。
(もっと読む)
対話装置及び方法
【課題】過去のユーザ入力に対する誤った解釈を、その後のユーザ入力により容易にしかも正確に訂正することができる対話装置及び方法を提供する。
【解決手段】対話状態の履歴を記憶する記憶手段と、現在の対話状態におけるシステム応答を出力する応答出力手段と、入力されたユーザ発話を音声認識して、該ユーザ発話に対する1または複数の認識候補とその尤度を求める音声認識手段と、前記記憶手段に記憶されている現在の対話状態及びその1つ前の対話状態を含む複数の対話状態のそれぞれについて、前記ユーザ発話との適合度を算出する算出手段と、各対話状態の前記適合度と各認識候補の前記尤度との組合せを基に、前記複数の対話状態のうちの1つと、前記1または複数の認識候補のうちの1つとを選択する選択手段と、選択された対話状態及び認識候補を基に新たな対話状態へ遷移する遷移手段とを備える。
(もっと読む)
1 - 20 / 42
[ Back to top ]