
Fターム[5D015LL07]の内容
Fターム[5D015LL07]の下位に属するFターム
キー入力装置 (26)
Fターム[5D015LL07]に分類される特許
1 - 20 / 87
音声認識装置及び音声認識方法

【課題】本装置を含む機器本体の動き又は状態の少なくとも一方を検出して、容易にかつ確実に動作モード切替えを行える音声認識装置を提供する。
【解決手段】実施形態によれば、音声入力部11と、加速度センサを備え、機器本体の動き又は状態もしくはその両方を検出する状態検出部12と、予め定めた機器本体の動き又は状態の動き・状態パターンモデルとそのモデルに対応する予め定めた複数の音声認識処理パターンとを記憶する保持部13と、状態検出部からの機器本体の動きまたは状態もしくはその両方と、保持部13に記憶された動き・状態パターンモデルとがマッチングするか否かを検出し、そのマッチングしたモデルに対応した音声認識処理パターンを検出するパターン検出部14と、検出された音声認識処理パターンに従い、音声入力部からのデジタル信号に対して音声認識処理を実行する音声認識処理実行部15と、を具備する。
(もっと読む)
生体信号を用いた発話支援装置、発話支援システム、及びプログラム

【課題】生体信号を用いた発話支援装置において、生体信号の検出精度が低いという課題がある。
【解決手段】被支援者Aは、生体信号センサ部1を装着している。生体信号センサ部1は、被支援者Aの生体信号を検出し、検出後生体信号を、波形整形部2に出力する。波形整形部2は、検出後生体信号に対して、雑音除去、干渉除去、波形整形処理を行った解析信号を語候補検出部3に出力する。取得部5は、生体信号センサ1と波形整形部2で構成される。複数語型語検出部は、解析信号に対して、各語ごとの特徴情報を用いるだけでなく、複数語にまたがる特徴情報を用いる事によって、高精度に語列を検出し、検出後語列を出力部4に出力する。出力部は、スピーカー、もしくは表示部、もしくはネットワーク接続器(例えば、コンピューター)、もしくは無線送信器などの出力装置であり、検出後語列を出力する。
(もっと読む)
車両用入力装置、車両用入力方法、及び車両用入力プログラム
【課題】走行中における入力時の操作性を向上させることができる、車両用入力装置、車両用入力方法、及び車両用入力プログラムを提供すること。
【解決手段】車両用入力装置1は、利用者から手動入力を受け付ける手動入力部61と、利用者の音声を認識して音声入力を受け付ける音声入力部62と、利用者を特定する利用者特定部63と、手動入力の受け付けを制限する制限条件が満たされている場合、手動入力部61による手動入力の受け付けを制限する入力制御部64とを備え、入力制御部64は、利用者特定部63により特定された利用者が車両の運転者ではない場合には、制限条件が満たされている場合であっても、音声入力部62による音声入力の受け付けに加え手動入力部61による手動入力の受け付けも可能とする。
(もっと読む)
ユーザ指示取得装置、ユーザ指示取得プログラムおよびテレビ受像機
【課題】ユーザの自然な発話、動作によって機器を的確に指示制御することができ、ユーザが実際に指示を行っている場合のみ指示を取得するユーザ指示取得装置、ユーザ指示取得プログラムおよびテレビ受像機を提供する。
【解決手段】カメラCrによって撮影された映像から予め登録された複数のユーザのそれぞれを認識するとともにその顔の変化を検出し、当該顔の変化から複数のユーザのそれぞれの発話期間を生成する顔分析手段20と、映像から複数のユーザの手の動作を認識する手動作分析手段30と、発話期間に基づいて機器の周囲の音声を検出し、音響特徴量を用いて音声の内容および話者を認識する音声分析手段10と、顔分析手段20によって認識された複数のユーザに話者が含まれている場合、ユーザの顔の変化、手の動作、音声の内容に対して予め定められたコマンドを生成するコマンド生成手段40と、を備える。
(もっと読む)
音声入力野帳管理システム
【課題】施工管理業務で使用する複数の備品(図面、測量器具一式、野帳、関数電卓機、鉛筆)を持って行う煩わしい作業、例えば、水準測量作業では、集計作業を行いながら測量データを野帳(測量用手帳)に記述するため、計算間違いによるやり直し作業や、作業終了後にツール(EXCELなど)を使用して報告書を纏める二度手間作業の減少を可能とする。
【解決手段】端末(携帯、PC)を使用し、音声入力野帳管理システムを使用すれば、野帳を電子データ化でき、複数の備品を一纏めにして煩わしい作業を解消し、迅速で正確な作業が可能となる。また、図3のFS(測量実測値計算機能)機能、GH(地盤高計算機能)機能を使用することで、計算間違いが減少できる。
(もっと読む)
コマンド認識装置、コマンド認識方法、及びコマンド認識ロボット
【課題】ユーザが意図した場合に発話によりロボットの動作を制御するためのコマンドを認識する、コマンド認識装置、コマンド認識方法及びコマンド認識ロボットを提供する。
【解決手段】発話情報から単語列情報を決定又は選択する発話理解部21と、前記発話情報と前記文に基づいて音声確信度を算出する音声確信度算出部221と、画像情報と前記文に含まれる語句情報に基づいて語句確信度を算出する語句確信度算出部22と、音声確信度及び語句確信度に基づいて、前記単語列情報のコマンドを実行するか否かを判断する動作制御指示部225とを備える。
(もっと読む)
音声認識システム、音声認識方法および音声認識プログラム
【課題】発話区間検出の処理負荷を少なくし、ユーザの誤操作を精度よく検知することができる音声認識システムを提供する。
【解決手段】本発明の音声認識システムは、発話開始の指示を含むユーザによる発話タイミングの指示を取得する発話タイミング指示取得手段と、入力される音声信号を保持し、前記発話タイミング指示取得手段により発話開始の指示が取得された場合、保持している音声信号およびそれ以降に入力される音声信号を出力する音声信号保持手段と、前記音声信号保持手段により出力された音声信号から発話区間を検出する発話区間検出手段と、前記発話区間検出手段により検出された発話区間と、前記発話タイミング指示取得手段により取得された発話タイミングの指示とに基づいて、ユーザの誤操作を検知する誤操作検知手段と、を備える。
(もっと読む)
情報処理装置、情報処理方法、およびプログラム
【課題】動画像を用いた読唇技術において、不特定話者の発話内容を高い精度で認識する。
【解決手段】発話認識装置10は、学習処理を実行する学習系11、登録処理を行う登録系12、および認識処理を行う認識系13から構成される。学習系11では、口形素ラベルが付加された唇画像を学習サンプルとし、入力された唇画像に対応する口形素を判別する口形素判別器31が生成される。登録系12では、登録用発話単語を話す話者の唇の動きに対応する時系列特徴量が生成されてモデル化されて登録される。認識系13では、話者の動画像から時系列特徴量が生成されて、登録されているモデルと比較され、発話内容が認識される。本発明は、話者をビデオ撮影した動画像から、その発話内容を認識する場合に適用することができる。
(もっと読む)
車載カメラシステム
【課題】 カーナビゲーションシステムに対し、口形の変形量から識別される目的地を示す言葉を送信可能な車載カメラシステムを提供する。
【解決手段】 車内に着座する人物を撮像する撮像部6,8と、前記撮像部6,8により撮像される前記人物の口形及び前記口形の変形量を検出する検出部20と、前記検出部20の検出結果から前記人物の発した言葉を識別する識別部20と、前記識別部20の識別結果をカーナビゲーションシステムに対して送信する送信部22とを備える。
(もっと読む)
音声情報処理装置
【課題】人の発話音声の中から、有意性の高い要点部分を客観的かつ容易に抽出する。
【解決手段】発話特徴解析制御部50が、音声認識部41により発話音声から生成されたテキスト情報、区間種別情報等、瞳孔径解析部42により眼球映像を解析して得られた瞳孔径、顔面動き量推定部43により通常顔映像から推定された顔面動きを入力し、発話音声の相対音量及び相対音高、発話速度、無意区間、テキスト化不可部分、発話者情動反応値及び聴取者情動反応値を発話特徴の解析結果として求める。また、表示装置20は、発声音の強弱及び高低、発声速度、無意区間の有無、テキスト化不可部分及び発話者情動反応値(または/及び聴取者情動反応値)を発話音声のテキスト情報の特性として、テキスト文字の形態に反映し、テキスト文字に対応した箇所に表現する。
(もっと読む)
話者特定装置および話者特定プログラム
【課題】
音声信号から話者の特定を行う話者特定装置において、話者特定のための精度向上を図る。
【解決手段】
音響モデルに個人名称を対応付けた個人別話者認識情報26aを記憶する記憶部26と、入力される音声信号と音響モデルを比較して、類似度が高い音響モデルを有する話者を抽出する話者認識部25と、入力される音声信号を音声認識する音声認識部22と、音声認識部22での認識結果から個人名称を抽出する解析部23と、話者認識部22での抽出結果、及び、解析部23で抽出した個人名称に基づいて話者を特定する話者特定部24を備える。
(もっと読む)
音声推定インタフェースおよび通信システム
ユーザが騒々しい環境または社会的に敏感な環境で、声を出さずに、または聞こえるように話す間、ユーザの音声を推定するために、閾値下の音波でユーザの声道を探る音声推定(VE)インタフェースを有する装置。一実施形態では、VEインタフェースは携帯電話に組み込まれ、携帯電話がネットワークを通じて推定音声信号を遠隔通話相手に送り、(i)ユーザは、例えばミーティング、会議、映画、または公演において他の人々に迷惑をかけることなく遠隔通話相手と会話することができるようになる、(ii)遠隔通話相手は、そうでなければユーザが例えばナイトクラブ、ディスコ、もしくは飛行中の航空機にいることによる比較的大きな周囲雑音によってかき消されることになるユーザの声をより明瞭に聞くことができるようになる。 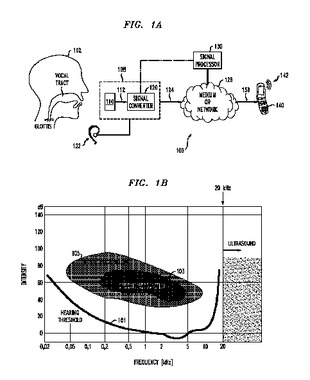 (もっと読む)
(もっと読む)
言語処理装置
【課題】
入力言語の設定の手間を省く。
【解決手段】
入力部(14)は、文字画像を含む映像を認識部(16)に入力する。認識部(16)は、入力部(149からの映像の文字画像を認識し、この文字画像に対応する文字情報、及びその言語を示す言語情報を出力する。ユーザは、言語選択手段(12)により出力言語を選択する。言語処理部(18)は、認識手段(16)で認識された文字情報を出力言語に機械翻訳する。出力部(20)は、言語処理部(18)の翻訳結果を出力する。
(もっと読む)
音声認識装置、音声認識方法および音声認識プログラム
【課題】話者が運動した場合に、音声認識誤りが発生している可能性の高い箇所を抽出することができる音声認識装置を提供する。
【解決手段】話者の発話する音声を入力するマイクロフォン1と、マイクロフォン1で入力した音声から、その発話に対応する文字符号列を抽出する音声認識部2と、話者の動きを検出する話者運動情報取得部4と、話者運動情報取得部4で検出した話者の動きが所定の大きさを超えた場合に、その話者の動きが発生したときの発話から音声認識部2で抽出した文字符号列が、話者の発話する内容に適合していない可能性が高いと判断する音声認識修正スコア計算部5および要修正判定部6と、を備える。
(もっと読む)
音声翻訳装置、音声翻訳方法、及びプログラム
【課題】フィラーも翻訳する音声翻訳装置を提供する。
【解決手段】原言語音声情報を受け付ける音声情報受付部11、原言語音声情報を音声認識する音声認識部13、音声認識結果情報を機械翻訳する機械翻訳部15、翻訳結果情報に対応する目的言語音声情報を生成する音声生成部17、原言語音声情報でのフィラー位置を特定するフィラー時間位置特定部20、フィラーのパラ言語を含む原言語フィラー情報を抽出するフィラー情報抽出部21、音声認識結果情報でのフィラー位置を特定するフィラーテキスト位置特定部22、目的言語音声情報でのフィラー位置であるフィラー挿入位置を特定するフィラー挿入位置特定部23、原言語フィラー情報に対応する目的言語フィラー情報をフィラー挿入位置に挿入するフィラー情報挿入部25、目的言語フィラー情報を含む目的言語音声情報を出力する音声情報出力部19を備える。
(もっと読む)
通信システム、端末装置、通信制御装置及び機械翻訳サーバ
【課題】端末装置の使い勝手を一段と向上し得る通信システム、端末装置、通信制御装置及び機械翻訳サーバを提供する。
【解決手段】グルーピングされた端末装置13からの発言権要求に基づいて、該端末装置13に発言権を付与し、該発言権が付与された端末装置13から送信された音声メッセージをグルーピングされた機械翻訳サーバ18に送信すると共に、機械翻訳サーバ18からの発言権要求に基づいて、該機械翻訳サーバ18に発言権を付与し、該機械翻訳サーバ18から送信された翻訳結果をグルーピングされた端末装置13に送信する通信制御装置と、端末装置13の居所の特定結果に基づいて、音声メッセージの言語を推定し、該推定された言語に基づいて音声メッセージを解析して所定の言語に翻訳すると共に、発言権要求により発言権を取得して翻訳の結果を送信する機械翻訳サーバ18とを具備する。
(もっと読む)
車両用対話システム
【課題】 ユーザの感性や好みなどのキャラクタを反映した適切な対話制御が行われる車両用対話システムの提供。
【解決手段】 検出手段は、車両の乗員を検出する。判定手段は、検出された乗員の発話に基づいて該乗員の嗜好を判定する。決定手段は、判定手段により判定された乗員の嗜好に基づいて、対話内容を決定する。制御手段は、決定手段により決定された対話内容に基づき、乗員との対話を制御する。
(もっと読む)
音声認識を用いた情報提供システム
【課題】通信端末から音声を入力して必要情報を入手する場合、効率的な情報提供を可能にする、音声認識を用いた情報提供システムを提供する。
【解決手段】本発明の音声認識を用いた情報提供システムは、複数の通信端末からの音声情報を受信し、その音声内容を認識する音声認識部22と、音声認識部22で認識された特定音声と関連付けされた1つ以上の関連情報を格納した情報管理部23と、関連付けされた1つ以上の関連情報の優先順位を決定し、通信端末の通信番号毎に、音声認識された特定音声と、この特定音声に対応する1つ以上の関連情報を、優先順位をつけて登録する操作者管理DB26とを具備する音声応答管理装置20を有し、通信端末10から操作者管理DB26に登録された特定音声が入力された場合、登録されている関連情報を、優先順位に従って当該通信端末10に送信する。
(もっと読む)
音声認識装置および音声認識方法
【課題】車載装置へ向かってその制御のために発話する発話者をトークスイッチの押下操作のわずらわしさから開放し、該発話が車載装置に対するものであるか否かを明確に認識して誤作動を起こさない音声認識装置および音声認識方法を提供する。
【解決手段】本発明の音声認識装置10aは、音声認識処理結果判定処理部13bが音声認識処理部13aによって受け付けられた発話語彙がキーワード辞書12aに含まれていると判定する場合は、音声認識処理部13aは、音声認識辞書12bを参照して対応するコマンドへと変換しカーナビゲーション装置20へと出力するコマンド変換出力処理部13cへ音声認識結果を受け渡し、音声認識処理結果判定処理部13bが音声認識処理部13aによって受け付けられた発話語彙がキーワード辞書12aに含まれていると判定されない場合は、音声認識処理部13aは、音声認識結果をコマンド変換出力処理部13cへ受け渡さない。
(もっと読む)
読唇装置および方法、情報処理装置および方法、検出装置および方法、プログラム、データ構造、並びに、記録媒体
【課題】口の動きに基づいて正確に言葉を認識する。
【解決手段】類似度検出部181は、口形画像におけるユーザの口形と複数の種類の基本口形との類似度を検出する。口形期間検出部191は、類似度に基づいて、初口形が出現する初口形期間、および、終口形が出現する終口形期間を検出する。基本スコア算出部192は、各期間におけるユーザの口形と各基本口形との類似度を示す基本スコアを算出する。認識部172は、基本スコアを用いて、口形辞書に登録されている各語句が、ユーザが発した言葉である確率を示す認識スコアを算出する。本発明は、口の動きに基づいて言葉を認識する読唇装置に適用できる。
(もっと読む)
1 - 20 / 87
[ Back to top ]