
Fターム[5L096BA16]の内容
イメージ分析 (61,341) | 入力画像・用途の種類 (5,501) | 特定画像 (1,491) | 音声 (62)
Fターム[5L096BA16]に分類される特許
1 - 20 / 62
映像付加情報関係性学習装置、方法、及びプログラム
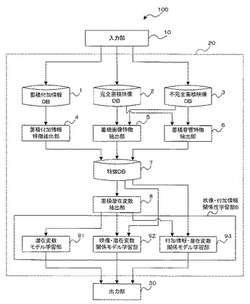
【課題】映像に含まれる画像情報と音響情報との双方を利用し、かつその相互の共起関係を考慮して、それら情報と言語情報との関係性の学習をより高精度に行うことができるようにする。
【解決手段】蓄積画像特徴抽出部5によって、完全蓄積映像及び不完全蓄積映像の各々から、完全蓄積画像特徴及び不完全蓄積画像特徴を抽出する。蓄積音響特徴抽出部6によって、完全蓄積映像及び不完全蓄積映像の各々から、完全蓄積音響特徴及び不完全蓄積音響特徴を抽出する。蓄積付加情報特徴抽出部4によって、蓄積付加情報の各々から蓄積付加情報特徴を抽出する。蓄積潜在変数抽出部8によって、映像と付加情報の関係性を記述するための変数の集合である蓄積潜在変数集合を抽出する。映像・付加情報間関係性学習部9によって、映像と付加情報との関係性を記述するモデルである映像・付加情報関係モデルを学習する。
(もっと読む)
情報処理装置、および情報処理方法、並びにプログラム

【課題】不確実で非同期な入力情報に基づく情報解析により、ユーザ位置や識別情報、発話者情報などを生成する構成を実現する。
【解決手段】画像情報や音声情報に基づいてユーザの推定位置および推定識別データを含むイベント情報を入力し、入力イベント情報に基づいて、各ユーザの位置およびユーザ識別情報を含むターゲット情報と、イベント発生源の確率値を示すシグナル情報を生成する情報統合処理部を有し、情報統合処理部は、発話源確率算出部を有し、発話源確率算出部は、各ターゲットの発話源確率を示す指標値としての発話源スコアを、イベント検出部から入力する複数の異なる情報に対して発話状況に応じた重みを乗算して算出する処理を行う。
(もっと読む)
コミュニケーション支援システム
【課題】誤認識の場合でも誤ったメッセージが話し相手に伝わることを避けることができる発話障害者のための、あるいは異なる言語間の通訳のための、読唇技術を利用した実用性の高いコミュニケーション支援システムを提供する。
【解決手段】事前に登録した発話内容の中から話し相手に伝えたい発話内容を、その口唇の動きに基づきその特徴量をリアルタイムに計測し、この計測された特徴量とデータベースに登録されている特徴量を比較して、発話内容を判断して認識結果をコントローラに出力する。コントローラの指示に基づき正しい認識結果を出力部に出力する。
(もっと読む)
画像処理プログラム、画像処理方法、画像処理装置、撮像装置
【課題】動画像コンテンツの内容を的確に反映した要約動画像を自動作成すること
【解決手段】本発明の画像処理プログラムは、動画像を入力する入力ステップ(S11)と、前記動画像を複数のセグメントに分割する分割ステップ(S12)と、前記複数のセグメントの各々の特徴量に応じて、それら複数のセグメントを複数のクラスタにクラスタリングするクラスタリングステップ(S14)と、前記複数のクラスタの各々から代表セグメントを選出する選出ステップ(S15)と、前記複数のクラスタの各々から選出された代表セグメントを連結することにより、前記動画像の要約動画像を作成する作成ステップ(S16)と、をコンピュータに実行させる。
(もっと読む)
画像処理装置、画像処理方法及び画像処理プログラム
【課題】被写体の画像情報や画像外情報だけでは区別できない別々の被写体を区別して、主要被写体を認識できるようにすること。
【解決手段】画像処理装置は、認識対象画像から計算される画像特徴量を生成する画像特徴量算出部31と、画像以外の情報から得られる画像外特徴量を取得する画像外特徴量算出部32と、上記画像特徴量と上記画像外特徴量とから、該画像のシーン情報の認識を行うシーン認識部33と、シーン情報と該シーン情報に対して典型的な主要被写体との対応関係を蓄積しておくシーン・主要被写体対応関係蓄積部42と、上記認識されたシーン情報と、上記蓄積された対応関係とを利用して、主要被写体候補を推定する主要被写体認識部34と、を備える。
(もっと読む)
状態認識装置、傾聴対話持続システム、状態認識プログラムおよび状態認識方法
【構成】傾聴対話持続システム100に含まれるPC10は、ロボット12の腹部カメラ14およびモニタカメラ22によって撮影された画像とマイク20によって集音された音声とから、ユーザの行動データを取得する。また、特定のユーザの行動データからサンプリングされた個人学習サンプルおよびSVMを構築するための一般学習サンプルに基づいて、境界線(超平面)の位置が調整された個人化SVMが構築される。そして、個人化SVMに、特定のユーザの行動からサンプリングされた認識サンプルが入力されると、特定のユーザの集中状態が認識される。
【効果】PC10は、特定のユーザの集中状態を容易に正しく認識できる。
(もっと読む)
テレビジョン受像装置及びテレビジョン受像方法
【課題】画像情報を利用して精度を向上させた音声翻訳を行なうテレビジョン受像装置及びテレビジョン受像方法を提供する。
【解決手段】入力音声から話者が話す指示代名詞を抽出する音声データ処理手段と、入力画像よりオブジェクトを切り出す画像データ処理手段と、話者が話す指示代名詞の変化と、入力画像上における話者とオブジェクトの位置関係の変化に基づいて、切り出したオブジェクトから指示対象物を認識する認識手段とを具備することを特徴とする。
(もっと読む)
情報処理装置、および情報処理方法、並びにプログラム
【課題】カメラやマイクを介する入力情報の解析により、発話者の特定処理を行う構成を実現する。
【解決手段】音声ベースの発話認識処理と画像ベース発話認識処理を実行する。さらに、音声ベース発話認識処理部において発話可能性が高いと判定した単語情報を入力し、画像ベース発話認識処理において解析されたユーザ単位の口の動き情報である口形素情報を入力して、単語を構成する音素単位で各音素の発話の口の動きに近い場合に高いスコアを設定してユーザ単位のスコアを設定する。さらに、ユーザ単位のスコアを適用してスコアに基づく発話者特定処理を実行する。この処理により発話内容に近い口の動きを示すユーザを発話源として特定可能となり、精度の高い発話者特定が実現される。
(もっと読む)
人間とコンピューターのインターフェースのためのインタラクションの処理
ユーザーと画面上のオブジェクトとの間のインタラクションを制御するために画面上のグラフィカルなハンドルを提供するシステムが開示される。ハンドルは、例えばテキスト又はグラフィカルなナビゲーションメニュー内をスクロールするなど、ユーザーがオブジェクトに対してどのようなアクションを実行することができるかを定義する。ハンドルとのインタラクションのプロセスを通じてユーザーを導くためにアフォーダンスが提供される。  (もっと読む)
(もっと読む)
ディスプレイ環境の装飾
ディスプレイ環境を装飾するためのシステム及び方法が本明細書において開示される。1つの実施態様において、ユーザは、1又は複数のジェスチャをすること、音声コマンドを用いること、適切なインターフェース装置を用いること、及び/又はそれらの組み合わせによって、ディスプレイ環境を装飾することができる。ディスプレイ環境を装飾するための例えば色、テクスチャ、オブジェクト、及び視覚効果等の芸術的特徴をユーザが選択するために、音声コマンドを検出することができる。ユーザはまた、装飾すべきディスプレイ環境の一部分を選択するためにジェスチャをすることもできる。次に、選択された芸術的特徴に従って、ディスプレイ環境の選択された一部分を変更することができる。ユーザの動作をディスプレイ環境においてアバターに反映させることができる。加えて、仮想キャンバス又は3次元オブジェクトをユーザによる装飾のためにディスプレイ環境に表示することができる。 (もっと読む)
テレビジョン受像装置及びテレビジョン受像方法
【課題】画像情報を利用して精度を向上させた音声翻訳を行なうテレビジョン受像装置及びテレビジョン受像方法を提供する。
【解決手段】入力音声から指示代名詞を抽出する音声データ処理装置と、入力画像よりオブジェクトを切り出す画像データ処理装置と、前記指示代名詞が示す位置関係によりこの指示代名詞と前記オブジェクトを対応付ける音声画像比較翻訳装置とを具備することを特徴とするテレビジョン受像装置。また入力音声から指示代名詞を抽出し、入力画像よりオブジェクトを切り出し、前記指示代名詞が示す位置関係によりこの指示代名詞と前記オブジェクトを対応付ける音声と画像を比較・翻訳することを特徴とするテレビジョン受像方法。
(もっと読む)
情報処理装置、情報処理方法、およびプログラム
【課題】動画像を用いた読唇技術において、不特定話者の発話内容を高い精度で認識する。
【解決手段】発話認識装置10は、学習処理を実行する学習系11、登録処理を行う登録系12、および認識処理を行う認識系13から構成される。学習系11では、口形素ラベルが付加された唇画像を学習サンプルとし、入力された唇画像に対応する口形素を判別する口形素判別器31が生成される。登録系12では、登録用発話単語を話す話者の唇の動きに対応する時系列特徴量が生成されてモデル化されて登録される。認識系13では、話者の動画像から時系列特徴量が生成されて、登録されているモデルと比較され、発話内容が認識される。本発明は、話者をビデオ撮影した動画像から、その発話内容を認識する場合に適用することができる。
(もっと読む)
楽譜表示装置、楽譜表示方法、コンピュータプログラム及び記録媒体
【課題】同時に演奏する楽器及び人数によらず、特別な動作を行なわなくても所望するタイミングに自動的にページ切替えが可能な楽譜表示装置を提供する。
【解決手段】楽譜表示装置は、楽譜の一連のページ画像を楽譜名とページ画像の順番とともに記憶する記憶機能と、被写体を撮像した一連の画像データをリアルタイムで出力する画像取込機能(S422)と、あるフレーズを演奏した時の演奏者の動きの特徴を楽譜名に対応するページ画像と関連付けフレーズデータとして記憶するフレーズデータ記憶機能と、表示装置に楽譜のページ画像が表示されている時に、画像取込機能の出力から抽出される演奏者の動きの特徴が表示されているページ画像と関連付けられたフレーズデータと一致するときは、表示されているページ画像の次の順番のページ画像を表示するページ変更機能(S426、S430)とを含む。
(もっと読む)
車載カメラシステム
【課題】 カーナビゲーションシステムに対し、口形の変形量から識別される目的地を示す言葉を送信可能な車載カメラシステムを提供する。
【解決手段】 車内に着座する人物を撮像する撮像部6,8と、前記撮像部6,8により撮像される前記人物の口形及び前記口形の変形量を検出する検出部20と、前記検出部20の検出結果から前記人物の発した言葉を識別する識別部20と、前記識別部20の識別結果をカーナビゲーションシステムに対して送信する送信部22とを備える。
(もっと読む)
画像処理装置、画像処理方法、及びプログラム
【課題】音声が画像に対し遅れるシーンであっても、撮影動作のみで画像と音声のタイミングを一致させた音声付動画を得られるようにする。
【解決手段】撮影画像から対象とする特定の被写体の画像を検出するとともに、その対象の被写体から発生される音声を検出し、検出された対象の被写体の画像の変化を検出してその変化を基に、対象の被写体の画像と被写体から発生された音声との時間ずれを調整して画像及び音声を記録するようにして、撮影後に編集処理を行うことなく、画像と音声のタイミングを一致させた音声付動画を得ることができるようにする。
(もっと読む)
電子機器
【課題】画像や音楽等のコンテンツを正確に評価できるようにする。
【解決手段】コンテンツとしての画像を再生すると、サブカメラによって鑑賞者の顔が撮像されるとともに、鑑賞者の声が録音される。取得された顔画像データに基づいて表情認識および体動認識が行われ、その結果に基づいて点数付けがなされる。一方、録音された鑑賞者の音声に基づいて音声認識が行われ、その結果に基づいて点数付けがなされる。両点数付けの結果の合計値に基づいて当該画像の評価が決まる。決定された評価は、当該画像データに対応づけられて記憶される。
(もっと読む)
国籍判定装置、方法およびプログラム
【課題】個人の人種・形質のような生物学的特性、民族といった文化人類学的特性、発声した言語の属する母国語ないし方言といった言語学的特性その他の個人の外部的特徴を客観的に測定し、その測定結果に基づいて個人の国籍を自動的・総合的に判定し、それに応じたアクションを実行する。
【解決手段】国籍判定装置5は、画像解析装置2または音声解析装置4による個々の解析結果に対応する国籍情報を国籍情報DB6から抽出する。次に、国籍判定装置5は、国籍情報DB6から抽出された個々の国籍情報に基づいて人物の最終的な国籍を判定する。これは例えば、各解析結果に対応する個別の国籍情報に優先度を予め国籍情報DB6などの記憶媒体に定義しておき、最も高い優先度を有する個別の国籍情報を最終的な国籍とする。
(もっと読む)
パターン認識辞書作成装置及びプログラム
【課題】 辞書を記憶する記憶容量が小さな装置であっても、画像パターンの認識精度を向上させることができるパターン認識辞書作成装置を提供する。
【解決手段】 入力画像の特徴量を求めて特徴ベクトルを生成する特徴ベクトル生成部111と、各画像の特徴ベクトル同士を比較して類似度の高い画像をグループとしてまとめるグループ化部114と、特徴ベクトル生成部で生成された特徴ベクトルに基づいて、画像の画素分布の情報を含む複数の特徴データを生成する主成分分析部113と、パターン認識用辞書を作成する場合に、グループに含まれない画像の特徴データのデータ量よりもグループに含まれる画像の特徴データのデータ量が多くなるように記憶装置23にデータを記憶させる辞書生成・登録部115とを有している。
(もっと読む)
音声及び映像に基づく性別−年齢識別方法及びその装置
【課題】音声及び映像に基づく性別−年齢識別方法及びその装置を提供する。
【解決手段】性別情報と年齢情報との相互関連性を考慮して音声認識及び顔認識を組み合わせて行うことによって性別及び年齢を正確に演算することができる識別装置及び方法に関する。性別−年齢識別方法は、映像情報及び音声情報を収集するステップと、前記収集された音声情報に対して一つ以上の特徴値を抽出し、前記抽出された特徴値を用いて性別及び年齢を識別する音声情報を用いた性別及び年齢識別ステップと、前記収集された映像情報に対して一つ以上の特徴値を抽出し、前記抽出された特徴値を用いて性別及び年齢を識別する顔情報を用いた性別及び年齢識別ステップと、前記音声情報を用いて識別された性別及び年齢と前記顔情報を用いて識別された性別及び年齢とを組み合わせ演算を行って性別及び年齢を最終決定するステップと、を含む。
(もっと読む)
音声認識の誤認識判定装置及び音声認識の誤認識判定プログラム
【課題】音声認識結果が誤認識か否かを判定する音声認識の誤認識判定装置を提供する。
【解決手段】音声認識の誤認識判定装置は、音声データと音声コマンド辞書21とに基いて音声コマンドを認識する音声認識部12と、音声認識部12による認識結果に対する応答処理を実行する認識結果応答部と、応答処理後一定時間内にユーザの顔画像データを取得する顔画像取得部15と、発声データを取得する発声データ取得部16と、顔画像取得部15により取得された顔画像データに基いて予め定めた表情及び頭部動作を画像認識する顔画像認識部17と、発声データ取得部16により取得された発声データと無意識発話辞書22とに基いて無意識発話を認識する無意識発話認識部18と、顔画像認識部17により予め定めた表情か頭部動作が認識された場合又は無意識発話認識部18により無意識発話が認識された場合に認識結果が誤認識と判定する誤認識判定部19とを備えている。
(もっと読む)
1 - 20 / 62
[ Back to top ]