
国際特許分類[G06F17/28]の内容
物理学 (1,541,580) | 計算;計数 (381,677) | 電気的デジタルデータ処理 (228,215) | 特定の機能に特に適合したデジタル計算またはデータ処理の装置または方法 (34,028) | 自然言語データの取扱い (7,890) | 自然言語の処理または翻訳 (1,147)
国際特許分類[G06F17/28]に分類される特許
1,001 - 1,010 / 1,147
対話処理装置

【課題】自然の流れに沿った対話が行なわれるようにする。
【解決手段】ユーザの発話を認識し、認識された発話と記憶手段に記憶されたユーザの発話に対する応答用の発話を事象と事象、事象と評価、及び評価と評価の各組合からなるルールに従った応答知識とに基づいて、ユーザの発話に対する応答用の発話を生成し、生成した応答用の発話を音声合成して出力する。
(もっと読む)
機械翻訳装置

【課題】 再翻訳が不要なときは片方向の翻訳手段のみを起動させる省メモリ対策はそのままに、ユーザに対する作業負担を軽減させて作業効率を向上させることができる機械翻訳装置を提供すること。
【解決手段】 日英翻訳アプリケーションウインドウと英日翻訳アプリケーションウインドウとが重なり合うと(S12:YES)、又は、表示装置上の表示制御用アイコンが選択されると(S11:YES)、日英翻訳アプリケーションウインドウと英日翻訳アプリケーションウインドウの表示サイズを自動的に揃えて表示するとともに、日英翻訳アプリケーションの英訳結果が表示されている日英翻訳アプリケーション英文ウインドウに対して、英日翻訳アプリケーションの英訳対象が表示されている英日翻訳アプリケーション英文ウインドウが自動的に重ね合わされた状態で表示する(S16)。
(もっと読む)
対訳対抽出装置および対訳対抽出プログラム
【課題】 理想的な対訳関係ではない2言語の文書から固有名詞などの対訳対を自動的に抽出できる対訳対抽出装置を提供する。
【解決手段】 固有表現の出現の類似傾向を示す情報を記憶した記憶部70と、記憶部58に記憶された固有表現と記憶部60に記憶された固有表現との間に対応関係を仮定する仮定部81と、仮定された対応関係に対し、記憶部58に記憶された固有表現と記憶部60に記憶された固有表現との間の対応の良さの尤もらしさを、記憶部70に記憶された類似傾向を示す情報に基づいて算出する尤度算出手段82,83,84と、尤度算出手段82,83,84により算出された尤度に基づいて評価値を算出する尤度統合部85と、評価値に基づいて、記憶部58に記憶された固有表現と記憶部60に記憶された固有表現との間の対応関係を選択することにより対訳対を抽出する選択部86とを備える。
(もっと読む)
自動換言装置、自動換言方法及び換言処理プログラム
【課題】簡易な構成でしかも開発者の知識能力に左右されることなく、入力された原文に対して最適な換言文を自動的に生成可能な自動換言装置を提供する。
【解決手段】自動換言装置80は、用例コーパスC1中の表現素片を出現度数とともに記憶する表現素片データベース(DB)D1と、対訳コーパスC2中の用例文に対する換言文を、換言の態様を示す換言情報とともに記憶する換言文DBD2と、対訳コーパスC2中の用例文から換言文への換言情報を適用頻度とともに記憶する換言情報DBD3と、表現素片の少なくとも一つを原文と共有する換言文を換言文DBD2から検索する類似文検索部84と、検索された換言文に対し、元の用例文との間の換言と、原文との間の換言に関する妥当性スコアを評価する表現検証部85と、妥当性スコアが最も高い換言文に対応する換言情報を原文に対し逆方向に適用し換言文を生成する原文換言部83とを含む。
(もっと読む)
対訳文対応付け装置
確定リンク編集部(42)は、ユーザにより指定される確定リンクを受け付ける。パラグラフ対応付け部(43)は、確定リンクに基づいて、英語文テキストおよび日本語文テキストをそれぞれ複数のパラグラフに分割する。セグメント対応付け計算部(44)は、パラグラフ毎に、英語セグメントと日本語セグメントとの対応付けを行う。対応関係編集部(45)は、セグメント対応付け計算部(44)により求められた対応関係をユーザに提示し、ユーザからの修正指示があれば、その指示に従って対応関係を編集する。 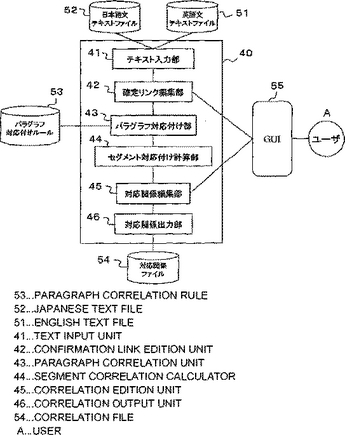 (もっと読む)
(もっと読む)
文章表示方法、情報処理装置、情報処理システム、プログラム
【課題】 母国語でない文章を表示する方法であって、ユーザに単語誤使用の発見容易性を提供し、また、誤使用単語の修正方法を提供することを目的とする。
【解決手段】
情報処理装置を用いて、第一言語で記述された文章を表示する方法であって、第一言語で記述された文章の入力を受ける入力受信段階と、入力を受けた文章を構成単語ごとに分離する分離段階と、構成単語が所定の特定語であるかを判別する判別段階と、構成単語が所定の特定語であったことに応答して、構成単語の第二言語を表示する表示段階と、を備えることを特徴とする方法。
(もっと読む)
言い換え表現獲得システム、言い換え表現獲得方法及び言い換え表現獲得プログラム
【課題】同じ意味内容を異なる表現で言い表す言い換え表現を、構文解析を必要とせず、また予め特定の関係にある事例を与えることなく、文書集合から獲得すること。
【解決手段】共起単語対文脈収集部12により文書集合DB1に格納された文書集合から任意の共起単語対を含む文脈を収集し、共起単語対毎に個々の文脈を共起単語対文脈DB2に格納し、文脈ベクトル生成部14により各共起単語対に対応する個々の文脈を構成する単語の単語頻度を求め、重みを計算して文脈ベクトルを文脈ベクトルDB4に格納し、文脈ベクトル類似度計算部15により2つの文脈ベクトル間の全ての類似度を求め、共起単語対クラスタリング部16により文脈ベクトル間の類似度が近い共起単語対をクラスタリングし、関係ラベル獲得部17により各クラスタを表す単語を獲得し、クラスタ内文脈選択部18によりDB2から当該単語を含む文脈を言い換え表現として選択する。
(もっと読む)
自然言語解析装置、自然言語解析方法、及び、自然言語解析プログラム
【課題】入力文に含まれる複数の節や複数の文の相互の意味的な対応関係を自動的に解釈することを課題とする。
【解決手段】複数の節又は複数の文によって構成された入力文の意味を解釈するための自然言語解析装置1であって、複数の節又は複数の文の中から、これら各節又は各文が示す現象又は述語に基づいて、各節又は各文の意味を位置付けて解釈するための場面を提示する問題枠を設定する問題枠設定節を特定する問題枠設定節特定手段と、この問題枠設定節特定手段にて特定された問題枠設定節に対して、当該問題枠設定節以外の節又は文を意味的に対応付けるための所定の処理を行う節意味表現対応付け手段とを備える。
(もっと読む)
関連文字列生成装置、プログラム、及び記憶媒体
【課題】 文書データから適切な意味的関連を有する文字列対を自動的に抽出する。
【解決手段】 言語解析手段22は、文書データを複数の連続する文節列に分割する。文節領域識別手段23は、この分割した文節列を用い、所定の条件の第一の文節列と所定の条件の1つ以上の文節からなる第二の文節列とを囲む文節対を含む連続する文節領域を識別する。具体的には、第一の文節列に関する所定の条件を、第一の文節列を構成する全文節が体言又はこれに相当する品詞を有する自立語を持つこととし、また、第二の文節列を囲む文節対に関する条件を、文節対を構成する2つの文節の自立語が一対の関係を有する記号文字であることとしている。文節列間関係同定手段24は、この識別された第一の文節列と第二の文節列との関係を同定する。
(もっと読む)
通訳装置、通訳方法、通訳プログラムを記録した記録媒体、および通訳プログラム
【課題】話者の声質にあったより近い合成音声を出力することが可能な通訳装置、通訳方法、通訳プログラムを記録した記録媒体、および通訳プログラムを提供する。
【解決手段】第1の言語で入力された入力音声を音声認識する音声認識部101と、音声認識された結果を第2の言語に翻訳する翻訳部102と、翻訳された第2の言語を音声合成する音声合成部103と、第1の言語の声質を分析する声質分析部104と、第1の言語の声質と第2の言語の声質との類似性を計量する声質類似性計量部105と、声質類似性計量部105で得られた声質類似性計量結果に基づいて、音声合成部103で音声合成される第2の言語の声質を制御する声質制御部106とを備えることにより、第1の言語の声質と第2の言語の声質とが比較的類似したものになり、違和感を生じるのを極力少なくすることができる。
(もっと読む)
1,001 - 1,010 / 1,147
[ Back to top ]