
国際特許分類[G06F17/28]の内容
物理学 (1,541,580) | 計算;計数 (381,677) | 電気的デジタルデータ処理 (228,215) | 特定の機能に特に適合したデジタル計算またはデータ処理の装置または方法 (34,028) | 自然言語データの取扱い (7,890) | 自然言語の処理または翻訳 (1,147)
国際特許分類[G06F17/28]に分類される特許
61 - 70 / 1,147
ロシア語検索装置およびプログラム
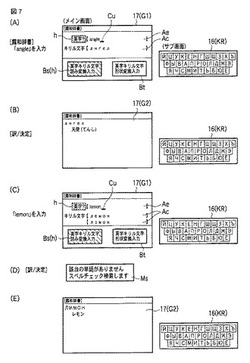
【課題】電子辞書等によるロシア語検索装置において、アルファベット文字の入力からロシア語辞書の見出し語を容易且つ迅速に検索することを可能にする。
【解決手段】[英字キリル文字読み変換入力]モードを設定した検索語入力画面G1の英字検索語入力エリアAeにおいて、ロシア語の読みに応じた英字の文字列[lemon]を入力すると、当該入力された英字の文字列は英字キリル文字類似音声変換テーブルに従いキリル文字の文字列[лемон(第1候補)][лэмон(第2候補)]に変換される。そして、当該変換されたキリル文字の文字列と一致するロシア語の見出し語が[露和辞書]に存在するか否かスペルチェックに掛けられ、一致する見出し語が存在しない場合には、最も近似する見出し語と一致する検索文字列[лимон]に訂正された後、該当する見出し語の説明情報[лимон レモン」が読み出されて説明情報表示画面G2として表示される。
(もっと読む)
通信装置

【課題】 要求される言語で記述される情報を含む画像を表わす画像データを、表示部に適切に供給し得る技術を提供する。
【解決手段】 多機能機10は、英語で記述されるウェブページデータが要求される場合に、ROM内の英語文字列テーブルを用いて得られる英語のウェブページデータを、PC300に供給する。多機能機10は、日本語で記述されるウェブページデータが要求される場合に、取得済みの日本語文字列データ用いて得られる日本語のウェブページデータを、PC300に供給する。
(もっと読む)
文書処理装置
【課題】特定フォーマットに依存せずに要求仕様書と自社技術体系とを比較し、要注意箇所または合致箇所を抽出することが課題となる。
【解決手段】評価対象である評価対象テキスト文書の記述内容が含まれる知識分野を構成する語句群における、相互の関連性が高い語句どうしをネットワーク接続した標準知識ネットワークデータを保持し、前記テキスト文書を構成する語句群について関連性の高い語句どうしをネットワーク接続した評価対象文書知識ネットワークデータを作成する文書知識作成機能を有し、評価対象文書知識ネットワークデータの構造と標準知識ネットワークデータの構造に対し、それらを構成する特定語句に着目し、当該特定語句にネットワーク接続している語句群の情報が相互に異なる場合に、当該特定語句の情報を含む差異情報とを出力する。
(もっと読む)
用語対訳抽出装置、用語対訳抽出方法、および用語対訳辞書の生産方法
【課題】従来、正しい用語対訳を自動抽出する場合、学習データや対訳辞書が必要であった。
【解決手段】対訳データベースから1以上の品詞情報パターンに合致する1以上の対訳フレーズを取得する対訳フレーズ取得部と、対訳フレーズ取得部が取得した1以上の対訳フレーズから、第一言語の用語と用語に対応する第二言語の用語の組の候補である1以上の用語対訳候補を取得する用語対訳候補取得部と、2以上の異なる方法により、2以上の各用語対訳候補に対して、スコアを算出し、2以上のスコアを取得するスコア算出部と、2以上のスコアを用いて、2以上の用語対訳候補のうちの一部を選択して蓄積する用語対訳蓄積部とを具備する用語対訳抽出装置により、正しい用語対訳を自動抽出する場合、学習データや対訳辞書が不要である。
(もっと読む)
電子機器
【課題】入力した文章を有効に活用することができる電子機器を提供することにある。
【解決手段】文章を入力可能な入力部と、文章中の単語を所定の規則に基づいて項目ごとに分類する解析部と、単語が分類された項目の種類を当該単語と共に記憶する記憶部と、文章を翻訳する翻訳アプリケーションを実行する制御部と、を備え、制御部は、入力部により入力された文章を翻訳アプリケーションにより翻訳する際に、文章中の単語ごとに翻訳し、翻訳される言語における項目の配列規則に従って翻訳された単語を並び変えることで上記課題を解決する。
(もっと読む)
翻訳結果表示方法、翻訳結果表示システム、翻訳結果生成装置および翻訳結果表示プログラム
【課題】翻訳結果を原文の領域に対応づけて出力する場合に、原文の領域のサイズに応じて見やすい翻訳結果を表示できる翻訳結果表示方法を提供する。
【解決手段】フォント記憶手段81は、予め定められた単語ごとに複数種類のフォントを記憶する。文字領域抽出手段82は、画像から文字列が含まれる領域である文字領域を抽出する。翻訳文字列生成手段83は、文字領域内の文字列を翻訳した翻訳文字列を生成する。翻訳結果生成制御手段84は、翻訳文字列に含まれる単語に対応するフォントをフォント記憶手段81に記憶された複数種類のフォントの中から選択して翻訳結果画像を生成する。また、翻訳結果生成制御手段84は、文字領域に収まるサイズのフォントの中からより大きいサイズのフォントを選択して翻訳結果画像を生成し、文字領域が抽出された画像における当該文字領域に、生成した翻訳結果画像を表示する。
(もっと読む)
参加者応答システム及び方法
【課題】フレキシブルで、設定変更可能な参加者応答システムを提供する。
【解決手段】参加者応答システムは、イベントの参加者が応答を入力することを可能とする複数のハンドセットを備える。各ハンドセットは、ユーザによる応答の入力を可能とするキーボードを有する無線ハンドセットを備える。ハンドセットは、参加者による応答の入力を可能とする参加者応答ハンドセットとして、或いは、基地局として構成することができる。また、ハンドセットは、参加者による音声の受信及び入力を可能とするオーディオ能力を含んでいる。
(もっと読む)
機械翻訳装置、機械翻訳方法および機械翻訳プログラム
【課題】
利用者の現在の利用シーンに対応する適応モデルをオンラインで動的に生成する機械翻訳装置を実現することである。
【解決手段】
実施形態の機械翻訳装置は、第1言語を入力する言語入力手段と、前記言語入力手段に入力された第1言語の利用者もしくは利用場所に関する付加情報を取得する付加情報取得手段と、第2言語と当該第2言語を取得した際の利用者もしくは利用場所に関する付加情報を対応付けた第2言語の参照データを格納する参照データ格納手段と、前記付加情報取得手段で取得された第1言語の付加情報の全部あるいは一部と同一な内容の付加情報を有する第2言語のテキスト情報を取得するテキスト情報取得手段と、前記テキスト情報取得手段によって取得された第2言語のテキスト情報を利用して、前記言語入力手段に入力された第1言語を第2言語に翻訳する翻訳手段とを備える。
(もっと読む)
言語変換装置、言語変換方法及び言語変換プログラム
【課題】トレーサビリティマトリクスを容易に作成すること。
【解決手段】抽出部は、文字ファイルに含まれる文字列を相互の関連性に従って解析することで求めた文字ファイルの木構造において、各ノードに配置された文字列から第1の言語で示された所定の文字列群である第1文字列群と第2の言語で示された所定の文字列群である第2文字列群とをそれぞれ抽出する。配置状態算出部は、第1文字列群及び第2文字列群に含まれる文字列それぞれについて、木構造における配置状態から文字列相互の影響度を算出する。類似度算出部は、影響度に基づいて、第1文字列群に含まれる第1文字列に対する第2文字列群に含まれる第2文字列の関連性の高低を示す類似度をそれぞれ算出する。変換部は、文字ファイルにおける第1文字列を類似度が最も高い第2文字列に変換する。
(もっと読む)
同一意図テキスト生成装置、意図推定装置および同一意図テキスト生成方法
【課題】異なる意図を示すテキストから新たなテキストを生成する。
【解決手段】テキスト解析部1はテキスト解析用辞書2を用いてテキストを形態素列にし、一致/差分テキスト抽出部3は意図の関係性に従って階層化した意図階層データ4を用いて、上位下位関係または同位の兄弟関係にある意図を抽出してこれら意図に対応付いたテキストから一致部分および不一致部分を抽出し、意図一致テキスト生成部6が一致部分および不一致部分を用いて、上位下位関係のいずれか一方の意図または兄弟関係のいずれか一方の意図を示す新たなテキストを生成する。
(もっと読む)
61 - 70 / 1,147
[ Back to top ]